展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Tactical Data Science Tips:
Python and Spark Together
Bill Chambers, Databricks
#UnifiedDataAnalytics #SparkAISummit
�
3 .Overview of this talk
Set Context for the talk
Introductions
Discuss Spark + Python + ML
5 Ways to Process Data with Spark & Python
2 Data Science Use Cases and how we implemented them
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .Setting Context: You
Data Scientists vs Data Engineers?
Years with Spark?
1/3/5+
Number of Spark Summits?
1/3/5+
Understanding of catalyst optimizer?
Yes/No
Years with pandas?
1/3/5+
Models/Data Science use cases in production?
1/10/100+
#UnifiedDataAnalytics #SparkAISummit 4
�
5 .Setting Context: Me
4 years at Databricks
~0.5 yr as Solutions Architect,
2.5 in Product,
1 in Data Science
Wrote a book on Spark
Master’s in Information Systems
History undergrad
#UnifiedDataAnalytics #SparkAISummit 5
�
6 .Setting Context: My Biases
Spark is an awesome(but a sometimes complex) tool
Information organization is a key to success
Bias for practicality and action
#UnifiedDataAnalytics #SparkAISummit 6
�
7 .5 ways of processing data
with Spark and Python
�
8 .5 Ways of Processing with Python
RDDs
DataFrames
Koalas
UDFs
pandasUDFs
#UnifiedDataAnalytics #SparkAISummit 8
�
9 .Resilient Distributed Datasets (RDDs)
rdd = sc.parallelize(range(1000), 5)
rdd.map(lambda x: (x, x * 10)).take(10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[(0, 0), (1, 10), (2, 20), (3, 30), (4, 40), (5, 50), (6, 60), (7, 70), (8,
80), (9, 90)]
#UnifiedDataAnalytics #SparkAISummit 9
�
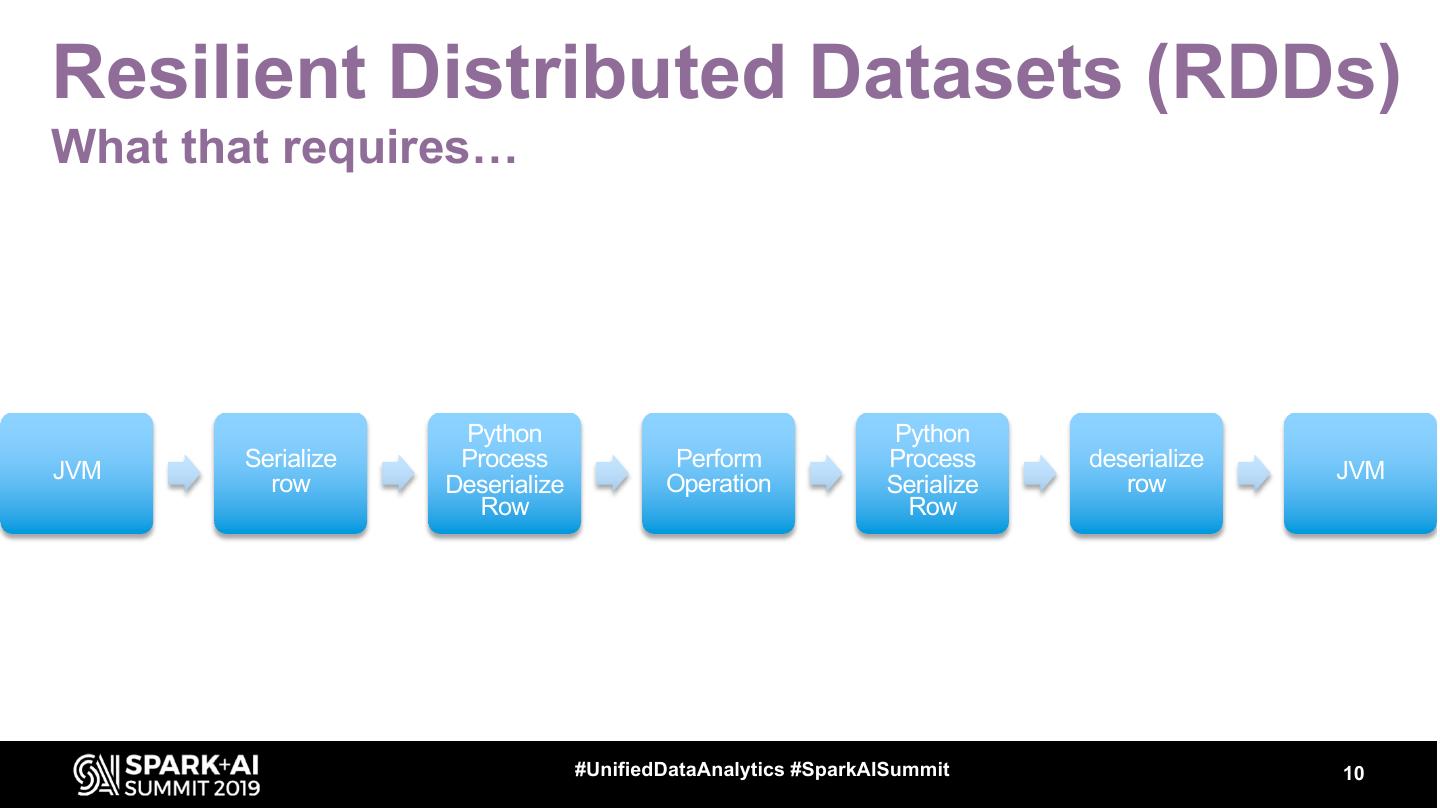
10 .Resilient Distributed Datasets (RDDs)
What that requires…
Python Python
Serialize Process Perform Process deserialize
JVM JVM
row Deserialize Operation Serialize row
Row Row
#UnifiedDataAnalytics #SparkAISummit 10
�
11 .Key Points
Expensive to operate (starting and shutting down
processes, pickle serialization)
Majority of operations can be performed using
DataFrames (next processing method)
Don’t use RDDs in Python
#UnifiedDataAnalytics #SparkAISummit 11
�
12 .DataFrames
df = spark.range(1000)
print(df.limit(10).collect())
df = df.withColumn("col2", df.id * 10)
print(df.limit(10).collect())
[Row(id=0), Row(id=1), Row(id=2), Row(id=3), Row(id=4), Row(id=5), Row(id=6),
Row(id=7), Row(id=8), Row(id=9)]
[Row(id=0, col2=0), Row(id=1, col2=10), Row(id=2, col2=20), Row(id=3,
col2=30), Row(id=4, col2=40), Row(id=5, col2=50), Row(id=6, col2=60),
Row(id=7, col2=70), Row(id=8, col2=80), Row(id=9, col2=90)]
#UnifiedDataAnalytics #SparkAISummit 12
�
13 .DataFrames
df = spark.range(1000)
print(df.limit(10).collect())
df = df.withColumn("col2", df.id * 10)
print(df.limit(10).collect())
[Row(id=0), Row(id=1), Row(id=2), Row(id=3), Row(id=4), Row(id=5), Row(id=6),
Row(id=7), Row(id=8), Row(id=9)]
[Row(id=0, col2=0), Row(id=1, col2=10), Row(id=2, col2=20), Row(id=3,
col2=30), Row(id=4, col2=40), Row(id=5, col2=50), Row(id=6, col2=60),
Row(id=7, col2=70), Row(id=8, col2=80), Row(id=9, col2=90)]
#UnifiedDataAnalytics #SparkAISummit 13
�
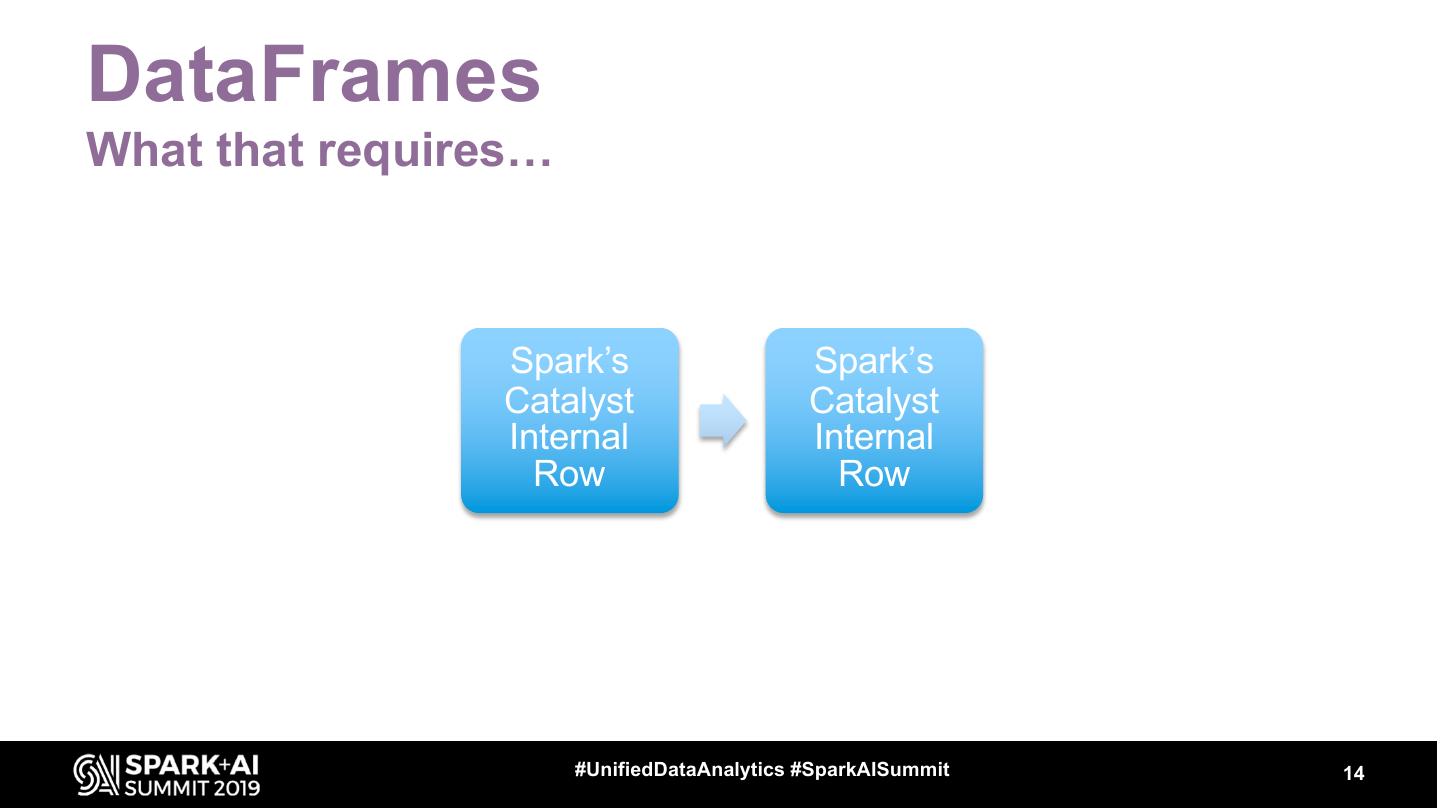
14 .DataFrames
What that requires…
Spark’s Spark’s
Catalyst Catalyst
Internal Internal
Row Row
#UnifiedDataAnalytics #SparkAISummit 14
�
15 .Key Points
Provides numerous operations (nearly anything
you’d find in SQL)
By using an internal format, DataFrames give
Python the same performance profile as Scala
#UnifiedDataAnalytics #SparkAISummit 15
�
16 .Koalas DataFrames
import databricks.koalas as ks
kdf = ks.DataFrame(spark.range(1000))
kdf['col2'] = kdf.id * 10 # note pandas syntax
kdf.head(10) # returns pandas dataframe
#UnifiedDataAnalytics #SparkAISummit 16
�
17 .Koalas: Background
Use Koalas - a library that aims
to make the pandas API
available on Spark.
pip install koalas
pyspark pandas
�
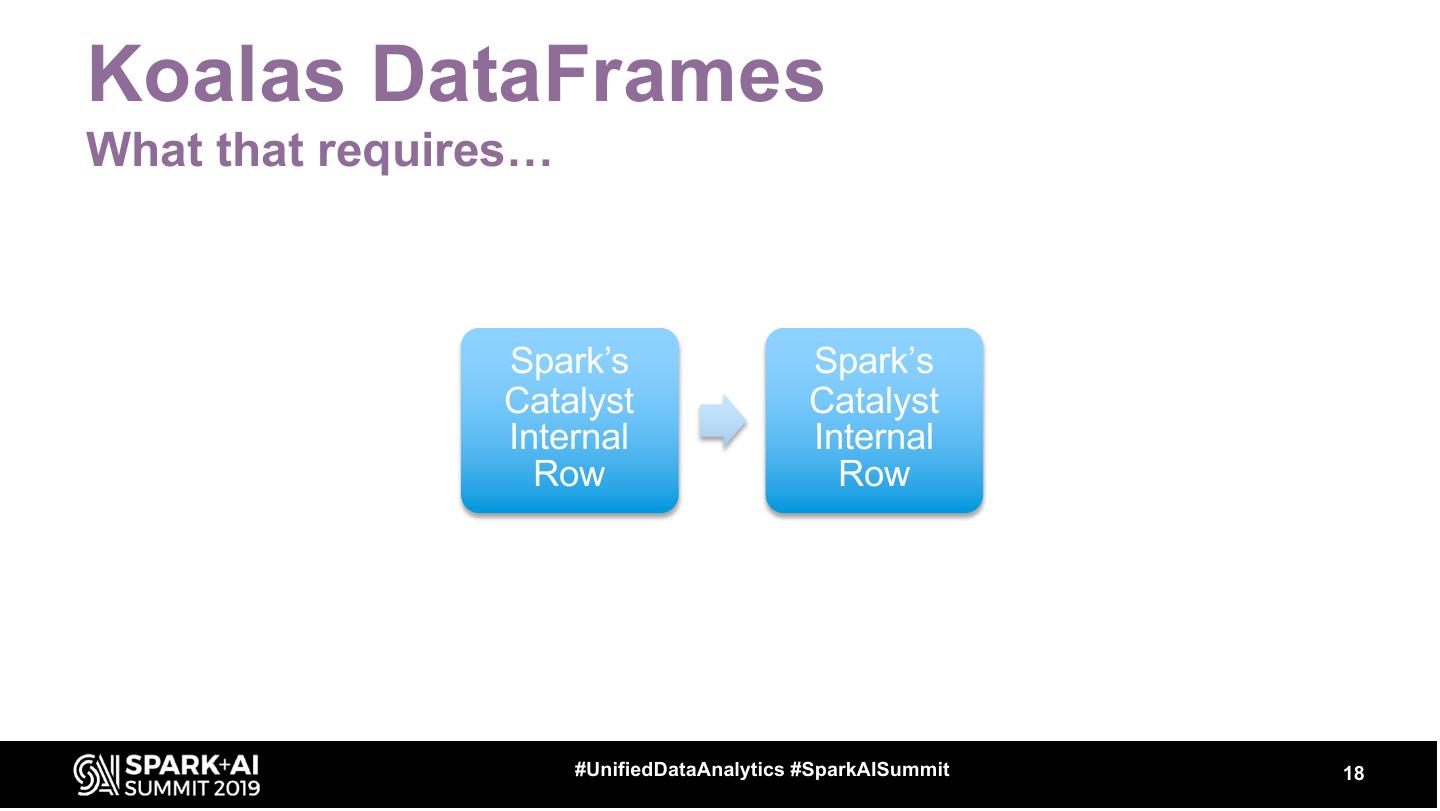
18 .Koalas DataFrames
What that requires…
Spark’s Spark’s
Catalyst Catalyst
Internal Internal
Row Row
#UnifiedDataAnalytics #SparkAISummit 18
�
19 .Key Points
Koalas gives some API consistency gains between
pyspark + pandas
It’s never go to match either pandas or PySpark fully
Try it and see if it covers your use case, if not move
to DataFrames
#UnifiedDataAnalytics #SparkAISummit 19
�
20 .Key gap between RDDs + DataFrames
No way to run “custom” code on a row or a subset
of the data
Next two transforming methods are “user-defined
functions” or “UDFs”
#UnifiedDataAnalytics #SparkAISummit 20
�
21 .DataFrame UDFs
df = spark.range(1000)
from pyspark.sql.functions import udf
@udf
def regularPyUDF(value):
return value * 10
df = df.withColumn("col3_udf_", regularPyUDF(df.col2))
#UnifiedDataAnalytics #SparkAISummit 21
�
22 .DataFrame UDFs
What it requires…
Python Python
JVM Serialize Process Perform Process deserialize JVM
row Deserialize Operation Serialize row
Row Row
#UnifiedDataAnalytics #SparkAISummit 22
�
23 .Key Points
Legacy Python UDFs are essentially the same as
RDDs
Suffer from nearly all the same inadequacies
Should never be used in place of PandasUDFs
(next processing method)
#UnifiedDataAnalytics #SparkAISummit 23
�
24 .DataFrames + PandasUDFs
df = spark.range(1000)
from pyspark.sql.functions import pandas_udf, PandasUDFType
@pandas_udf('integer', PandasUDFType.SCALAR)
def pandasPyUDF(pandas_series):
return pandas_series.multiply(10)
# the above could also be a pandas DataFrame
# if multiple rows
df = df.withColumn("col3_pandas_udf_", pandasPyUDF(df.col2))
#UnifiedDataAnalytics #SparkAISummit 24
�
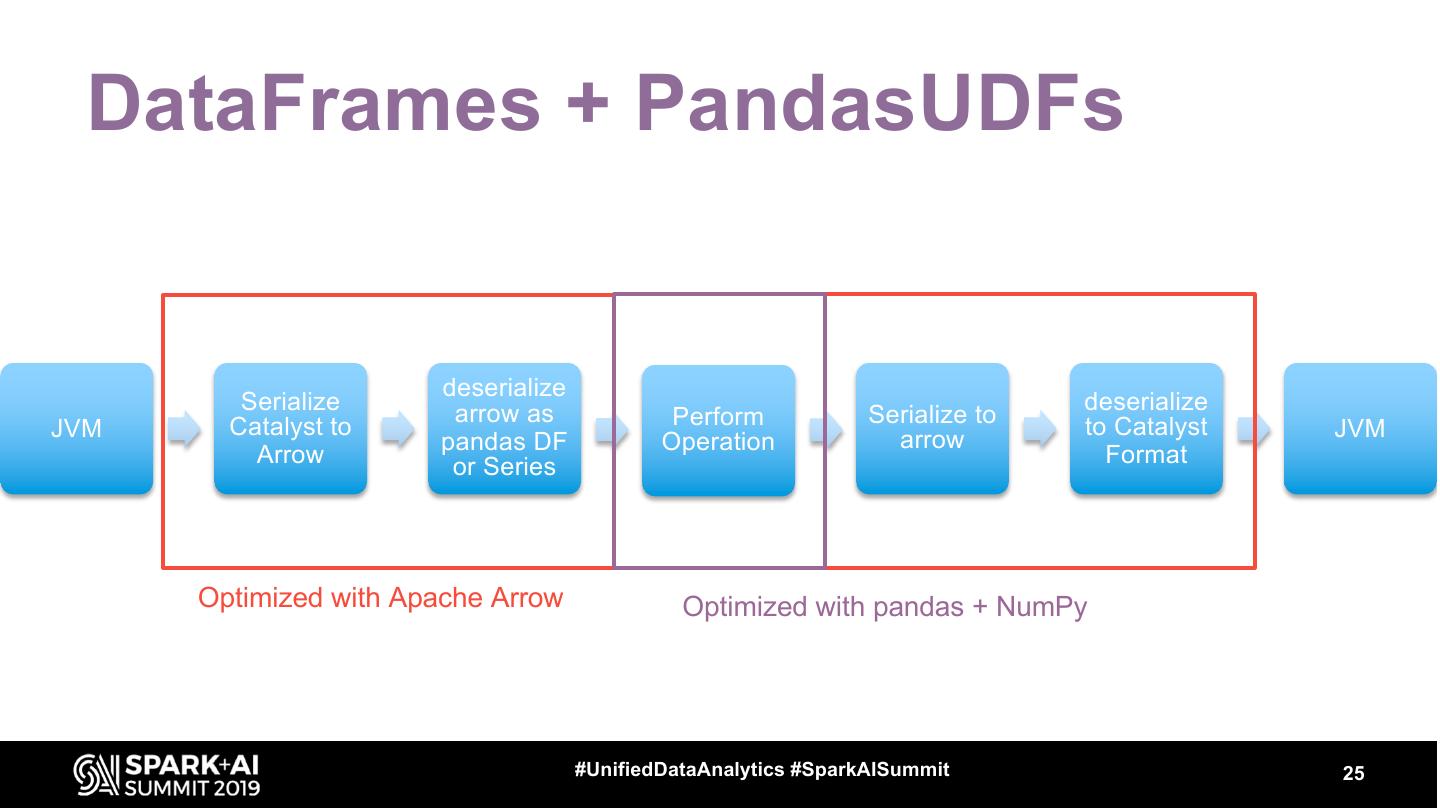
25 . DataFrames + PandasUDFs
deserialize
Serialize arrow as deserialize
Catalyst to Perform Serialize to to Catalyst
JVM arrow JVM
pandas DF Operation
Arrow or Series Format
Optimized with Apache Arrow Optimized with pandas + NumPy
#UnifiedDataAnalytics #SparkAISummit 25
�
26 .Key Points
Performance won’t match pure DataFrames
Extremely flexible + follows best practices (pandas)
Limitations:
Going to be challenging when working with GPUs + Deep Learning
Frameworks (connecting to hardware = challenge)
Batch size to pandas must fit in memory of executor
#UnifiedDataAnalytics #SparkAISummit 26
�
27 .Conclusion from 5 ways of processing
Use Koalas if it works for you, but Spark
DataFrames are the “safest” option
Use pandasUDFs for user-defined functions
#UnifiedDataAnalytics #SparkAISummit 27
�
28 .2 Data Science use cases
and how we implemented
them
�
29 . 2 Data Science Use Cases
Growth Forecasting Churn Prediction
2 methods for implementation: Low n, low k, low m
a. Use information about a single
customer
– Low n, low k, high m
b. Use information about all
customers
– High n, low k, low m
29
�