展开查看详情
1 . STREAMING ANALYTICS
FOR FINANCIAL ENTERPRISES
Bas Geerdink | October 16, 2019 | Spark + AI Summit
�
2 . WHO AM I?
{
"name": "Bas Geerdink",
"role": "Technology Lead",
"background": ["Artificial Intelligence",
"Informatics"],
"mixins": ["Software engineering",
"Architecture",
"Management",
"Innovation"],
"twitter": "@bgeerdink",
"linked_in": "bgeerdink"
}
�
3 . AGENDA
1. Fast Data in Finance
2. Architecture and Technology
3. Deep dive:
Event Time, Windows, and Watermarks
Model scoring
4. Wrap-up
�
4 .BIG DATA
Volume
Variety
Velocity
�
5 . FAST DATA USE CASES
Sector Data source Pattern Noti cation
Finance Payment data Fraud detection Block money
transfer
Finance Clicks and page Trend analysis Actionable insights
visits
Insurance Page visits Customer is stuck in a web Chat window
form
Healthcare Patient data Heart failure Alert doctor
Traf c Cars passing Traf c jam Update route info
Internet of Machine logs System failure Alert to sys admin
Things
�
6 . FAST DATA PATTERN
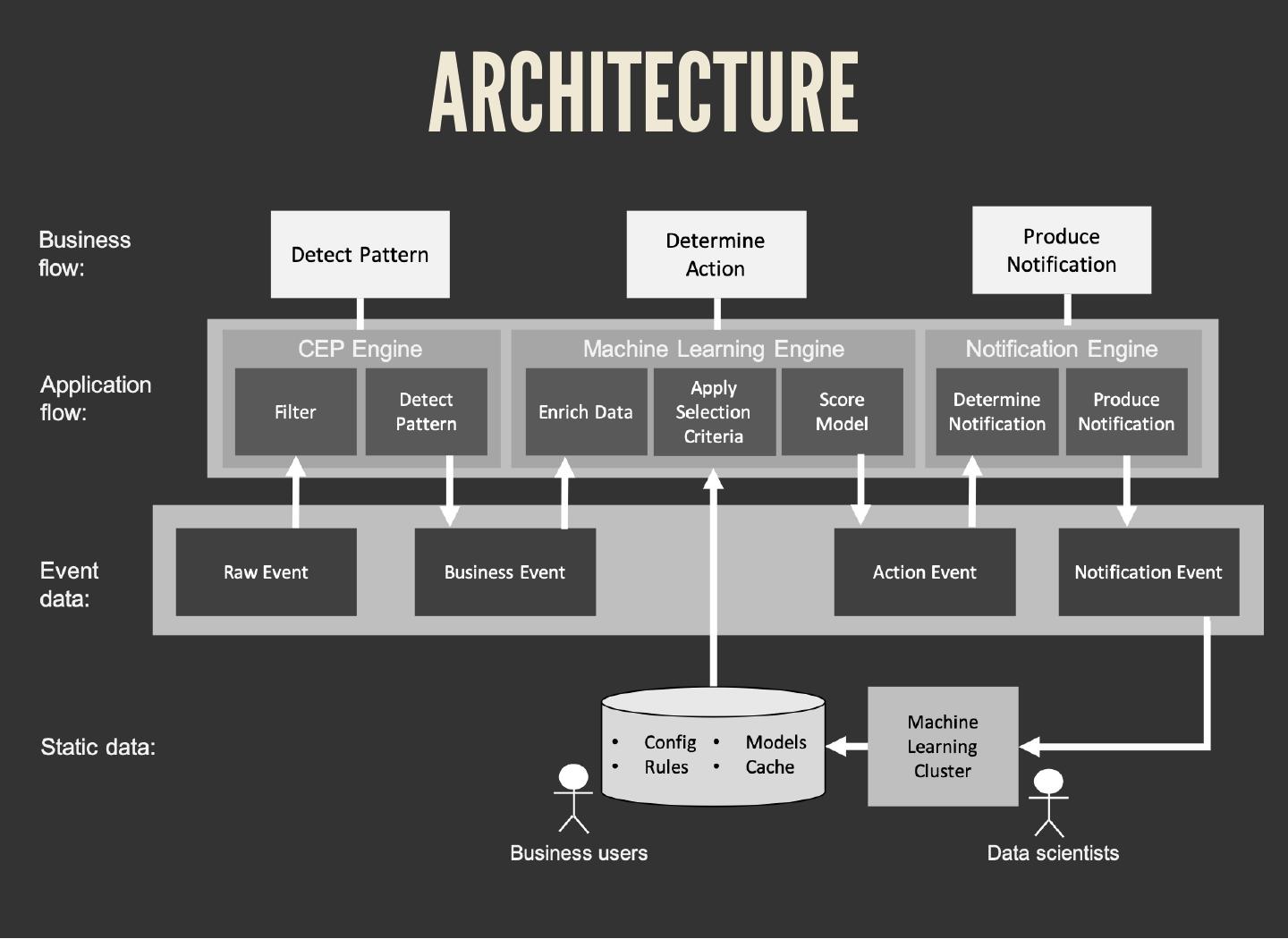
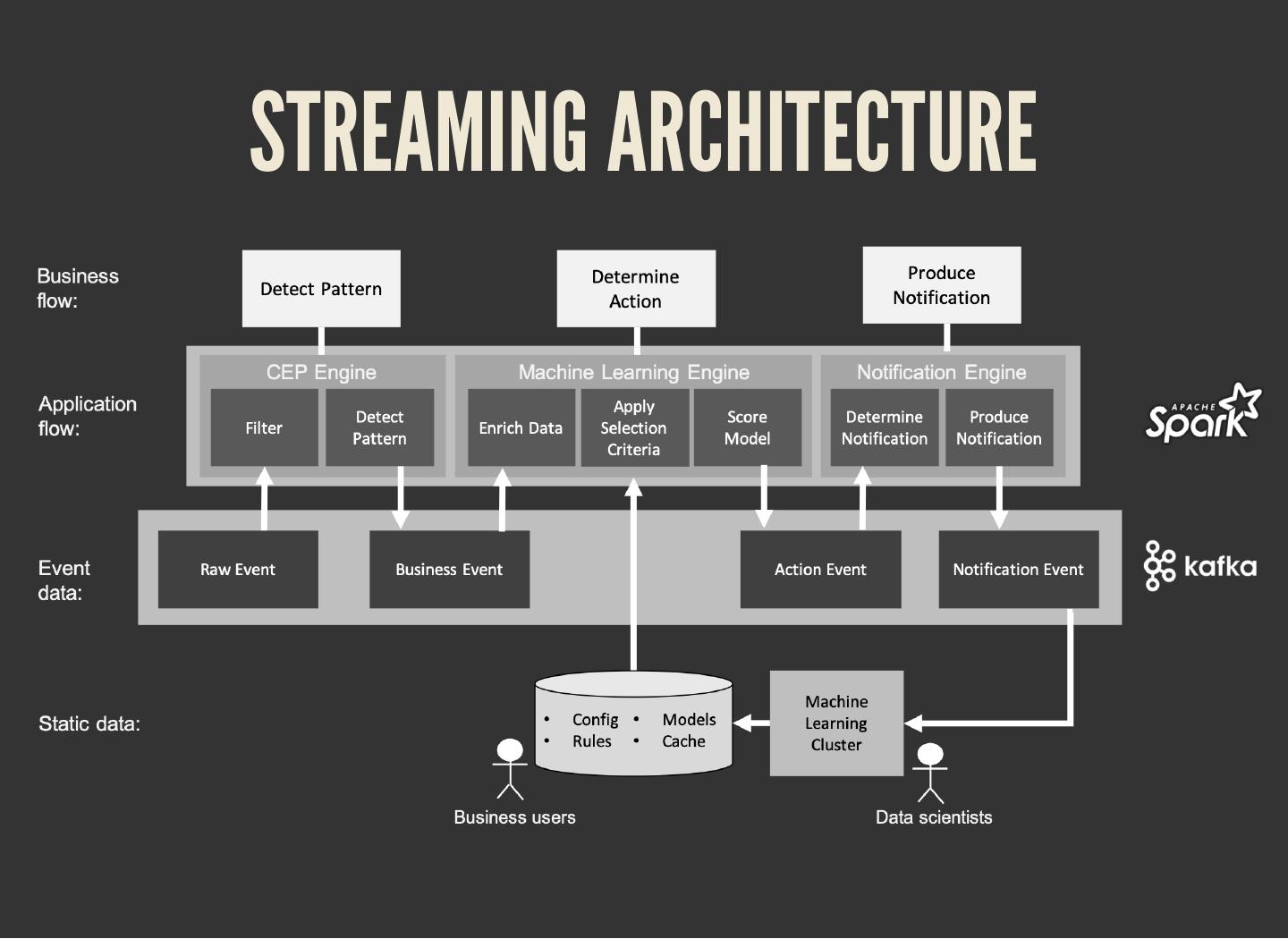
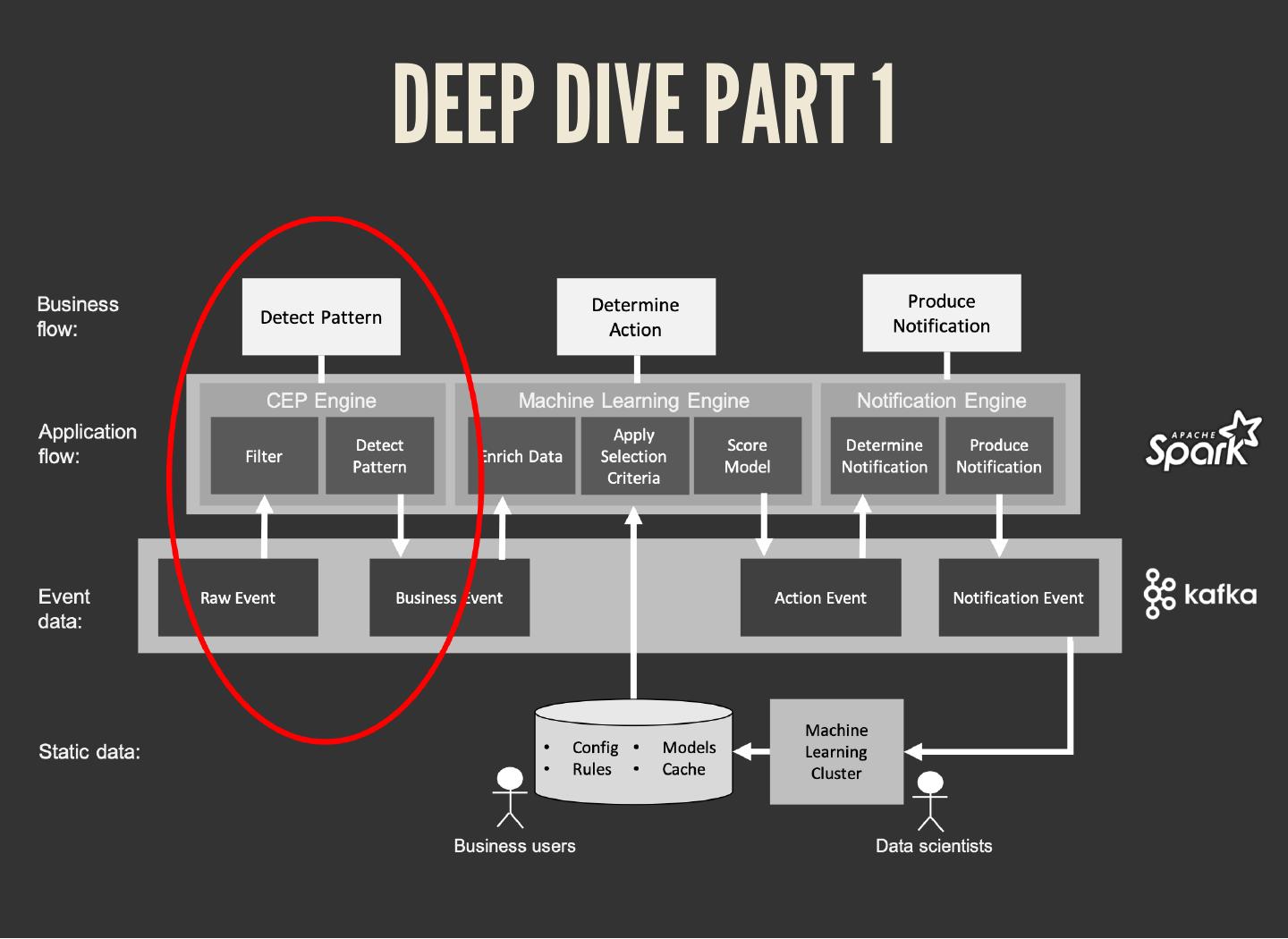
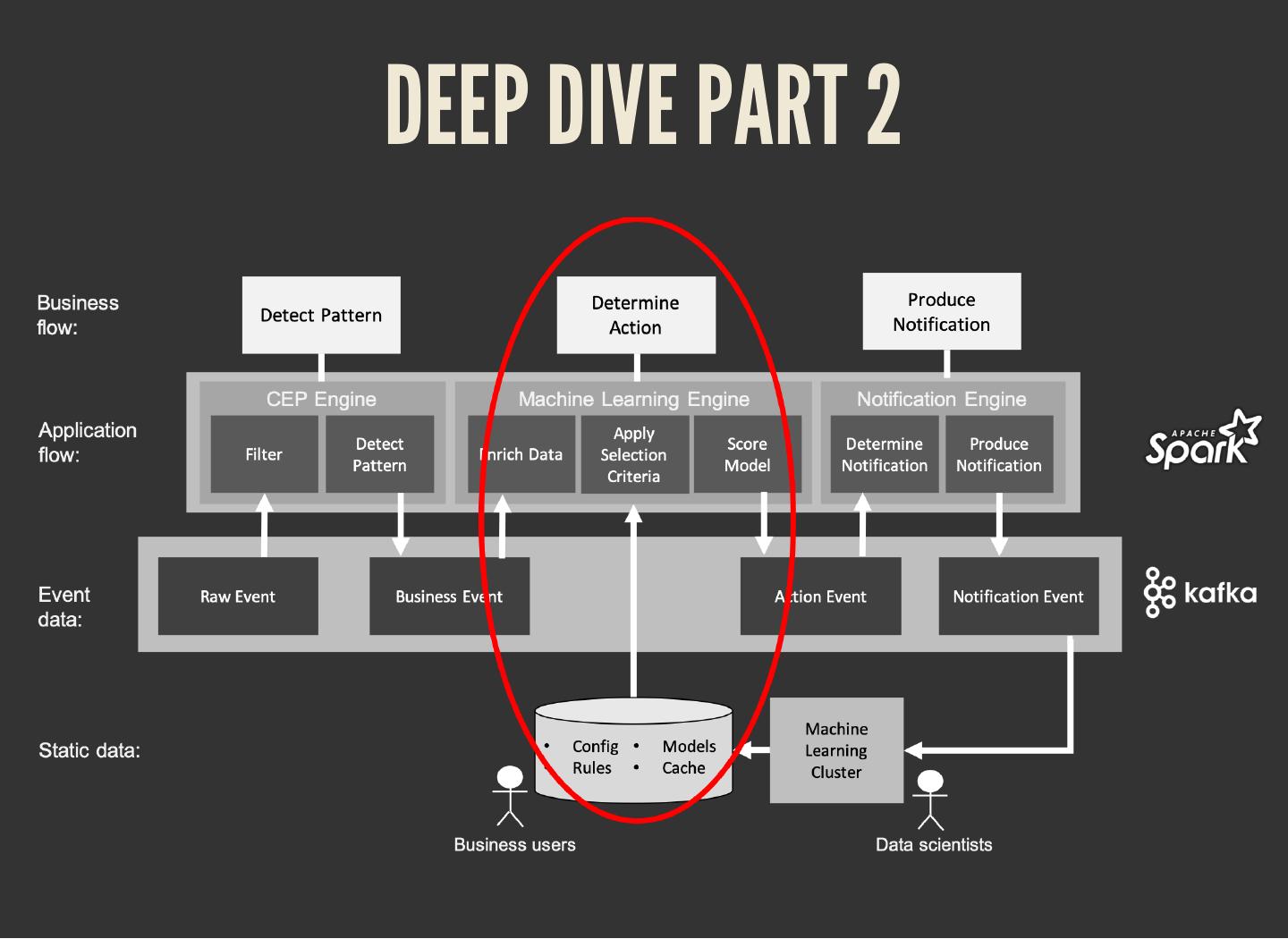
The common pattern in all these scenarios:
1. Detect pattern by combining data (CEP)
2. Determine relevancy (ML)
3. Produce follow-up action
�
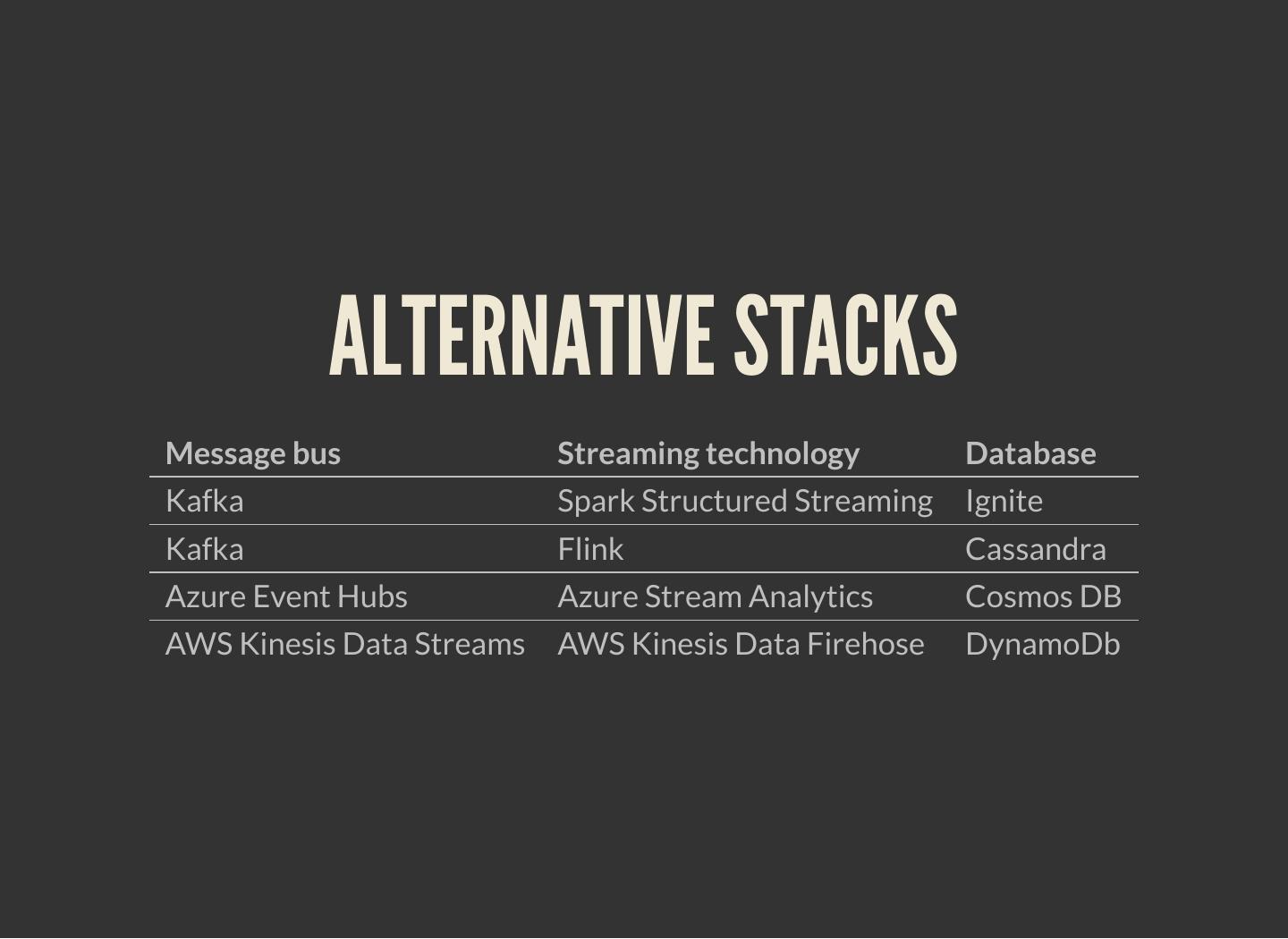
8 . THE SOFTWARE STACK
Data stream storage: Kafka
Persisting cache, rules, models, and con g:
Cassandra or Ignite
Stream processing: Spark Structured Streaming
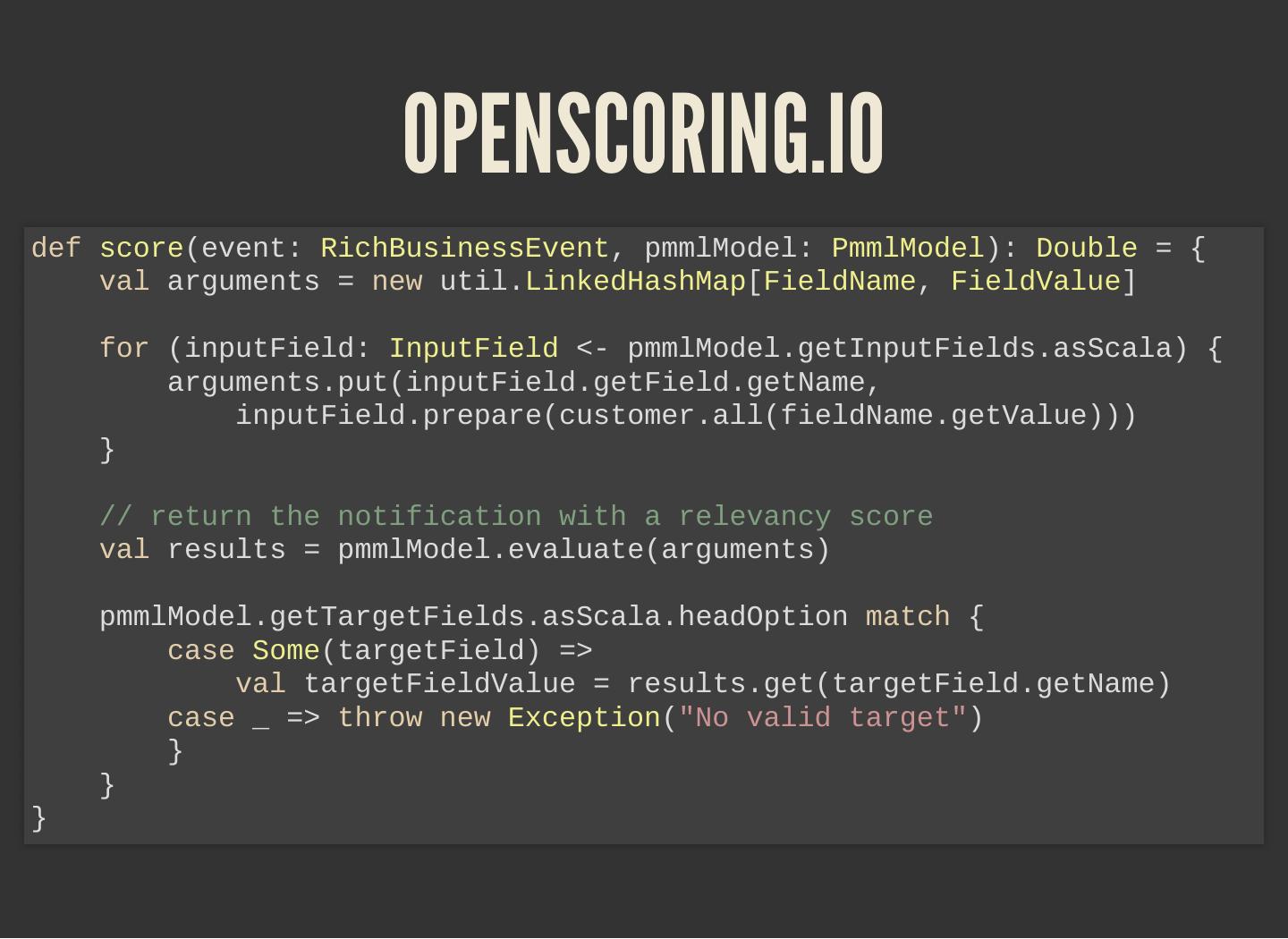
Model scoring: PMML and Openscoring.io
�
9 .APACHE SPARK LIBRARIES
�
10 .STREAMING ARCHITECTURE
�
12 . SPARK-KAFKA INTEGRATION
A Fast Data application is a running job that
processes events in a data store (Kafka)
Jobs can be deployed as ever-running pieces of
software in a big data cluster (Spark)
�
13 . SPARK-KAFKA INTEGRATION
A Fast Data application is a running job that
processes events in a data store (Kafka)
Jobs can be deployed as ever-running pieces of
software in a big data cluster (Spark)
The basic pattern of a job is:
Connect to the stream and consume events
Group and gather events (windowing)
Perform analysis (aggregation) on each window
Write the result to another stream (sink)
�
14 . PARALLELISM
To get high throughput, we have to process the
events in parallel
Parallelism can be con gured on cluster level (YARN)
and on job level (number of worker threads)
val conf = new SparkConf()
.setMaster("local[8]")
.setAppName("FraudNumberOfTransactions")
./bin/spark-submit --name "LowMoneyAlert" --master local[4]
--conf "spark.dynamicAllocation.enabled=true"
--conf "spark.dynamicAllocation.maxExecutors=2" styx.jar
�
15 . HELLO SPEED!
// connect to Spark
val spark = SparkSession
.builder
.config(conf)
.getOrCreate()
// for using DataFrames
import spark.sqlContext.implicits._
// get the data from Kafka: subscribe to topic
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "transactions")
.option("startingOffsets", "latest")
.load()
�
16 . EVENT TIME
Events occur at certain time
... and are processed later
�
17 . EVENT TIME
Events occur at certain time ⇛ event time
... and are processed later ⇛ processing time
�
18 . EVENT TIME
Events occur at certain time ⇛ event time
... and are processed later ⇛ processing time
�
20 . WINDOWS
In processing in nite streams, we usually look at a
time window
A windows can be considered as a bucket of time
�
21 . WINDOWS
In processing in nite streams, we usually look at a
time window
A windows can be considered as a bucket of time
There are different types of windows:
Sliding window
Tumbling window
Session window
�
23 . WINDOW CONSIDERATIONS
Size: large windows lead to big state and long
calculations
Number: many windows (e.g. sliding, session) lead to
more calculations
Evaluation: do all calculations within one window, or
keep a cache across multiple windows (e.g. when
comparing windows, like in trend analysis)
Timing: events for a window can appear early or late
�
24 . WINDOWS
Example: sliding window of 1 day, evaluated every 15
minutes over the eld 'customer_id'. The event time is
stored in the eld 'transaction_time'
// aggregate, produces a sql.DataFrame
val windowedTransactions = transactionStream
.groupBy(
window($"transaction_time", "1 day", "15 minutes"),
$"customer_id")
.agg(count("t_id") as "count", $"customer_id", $"window.end")
�
25 . WATERMARKS
Watermarks are timestamps that trigger the
computation of the window
They are generated at a time that allows a bit of slack
for late events
�
26 . WATERMARKS
Watermarks are timestamps that trigger the
computation of the window
They are generated at a time that allows a bit of slack
for late events
Any event that reaches the processor later than the
watermark, but with an event time that should
belong to the former window, is ignored
�
27 . EVENT TIME AND WATERMARKS
Example: sliding window of 60 seconds, evaluated
every 30 seconds. The watermark is set at 1 second,
giving all events some time to arrive.
val windowedTransactions = transactionStream
.withWatermark("created_at", "1 second")
.groupBy(
window($"transaction_time", "60 seconds", "30 seconds"),
$"customer_id")
.agg(...) // e.g. count/sum/...
�
28 .FAULT-TOLERANCE AND CHECKPOINTING
Data is in one of three stages:
Unprocessed
In transit
Processed
�
29 .FAULT-TOLERANCE AND CHECKPOINTING
Data is in one of three stages:
Unprocessed ⇛ Kafka consumers provide offsets
that guarantee no data loss for unprocessed data
In transit ⇛ data can be preserved in a checkpoint,
to reload and replay it after a crash
Processed ⇛ Kafka provides an acknowledgement
once data is written
�