




































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spark+Parquet In Depth
当年Weather.com 的Spark团队分享使用Spark的经验。。。Weather.com在alexa排名全美也有top 35。实至名归的大数据公司。 2017年给talk的Robbie和【长发过腰的】Emily,随着2016年的收购,也加入了IBM。视频:https://www.youtube.com/watch?v=_0Wpwj_gvzg 后记,这场IBM的大手笔收购,大家最初都认为是个笑话,一个想要做云计算的公司,花了二十亿美金买了家天气预报的公司。。。随后的几年,无论如何解释当时的决策,这场收购都是一个败笔。当初的总总,现在回看,值得反思。
展开查看详情
1 .Spark + Parquet in Depth Robbie Strickland VP, Engines & Pipelines, Watson Data Platform @rs_atl Emily May Curtin Software Engineer, IBM Spark Technology Center @emilymaycurtin
2 .Atlanta…
3 .Atlanta!!!!
4 . Outline • Why Parquet • Parquet by example • How Parquet works • How Spark squeezes out efficiency • What’s the catch • Tuning tips for Spark + Parquet
5 .
6 .
7 . Goals for Data Lake Storage • Good Usability • AFFORDABLE – Easy to backup – Minimal learning curve • CA$$$H MONEY – Easy integration with existing tools • DEVELOPER HOURS à $$$ • Resource efficient • COMPUTE CYCLES à $$$ – Disk space – Disk I/O Time – Network I/O •FAST QUERIES
8 .Little Costs Matter at Actual Scale “Very Large Dataset” Weather-Scale Data
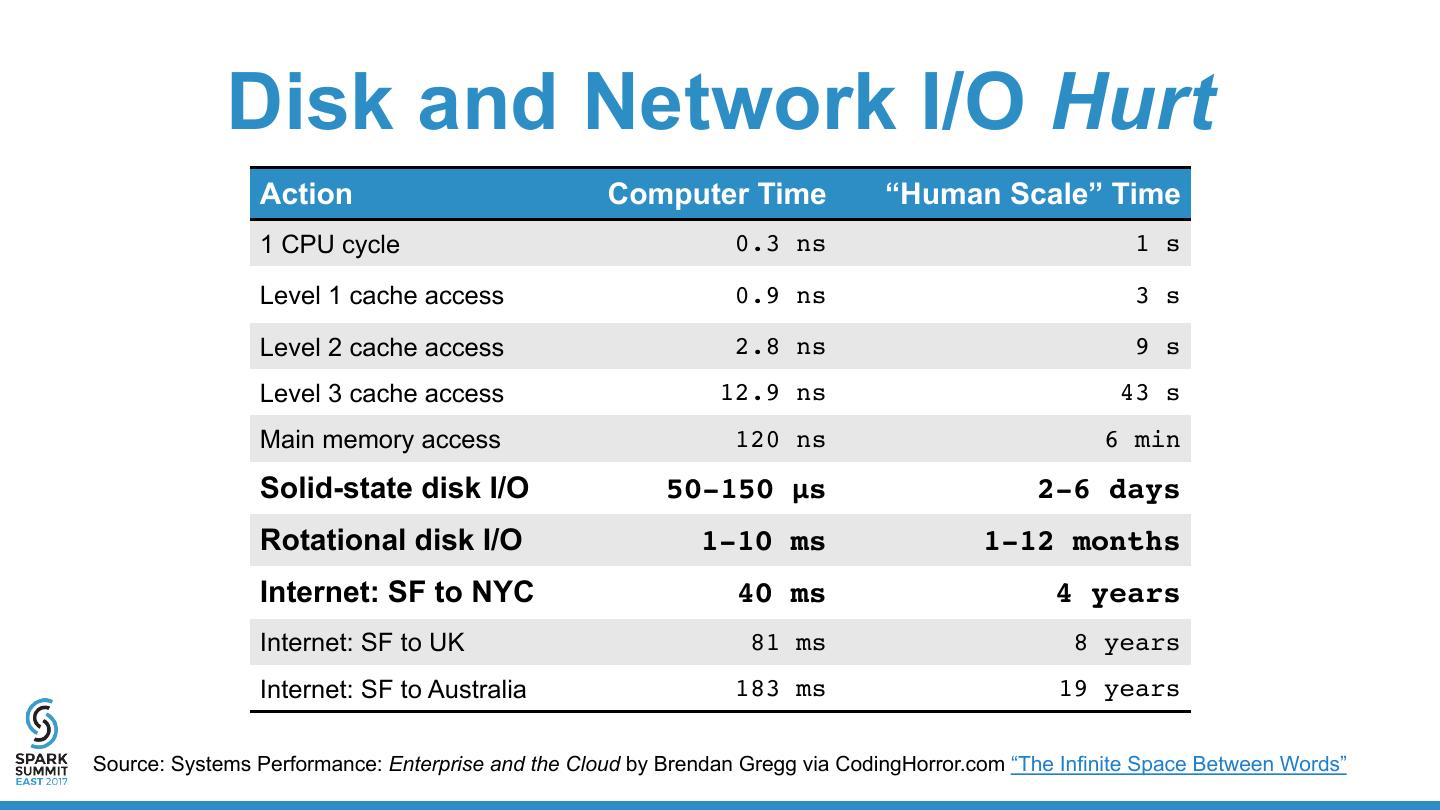
9 . Disk and Network I/O Hurt Action Computer Time “Human Scale” Time 1 CPU cycle 0.3 ns 1 s Level 1 cache access 0.9 ns 3 s Level 2 cache access 2.8 ns 9 s Level 3 cache access 12.9 ns 43 s Main memory access 120 ns 6 min Solid-state disk I/O 50-150 μs 2-6 days Rotational disk I/O 1-10 ms 1-12 months Internet: SF to NYC 40 ms 4 years Internet: SF to UK 81 ms 8 years Internet: SF to Australia 183 ms 19 years Source: Systems Performance: Enterprise and the Cloud by Brendan Gregg via CodingHorror.com “The Infinite Space Between Words”
10 .Options For Multi-PB Data Lake Storage Files Compressed Files Databases Usability Great! Great! OK to BAD (not as easy as a file!) Administration None! None! LOTS Spark Integration Great! Great! Varies Resource Efficiency BAD (Big storage, heavy I/O) OK… (Less storage) BAD (Requires storage AND CPU) Scalability Good-ish Good-ish BAD (For multi-petabyte!) CO$$$$T OK… OK… TERRIBLE QUERY TIME TERRIBLE BAD Good!
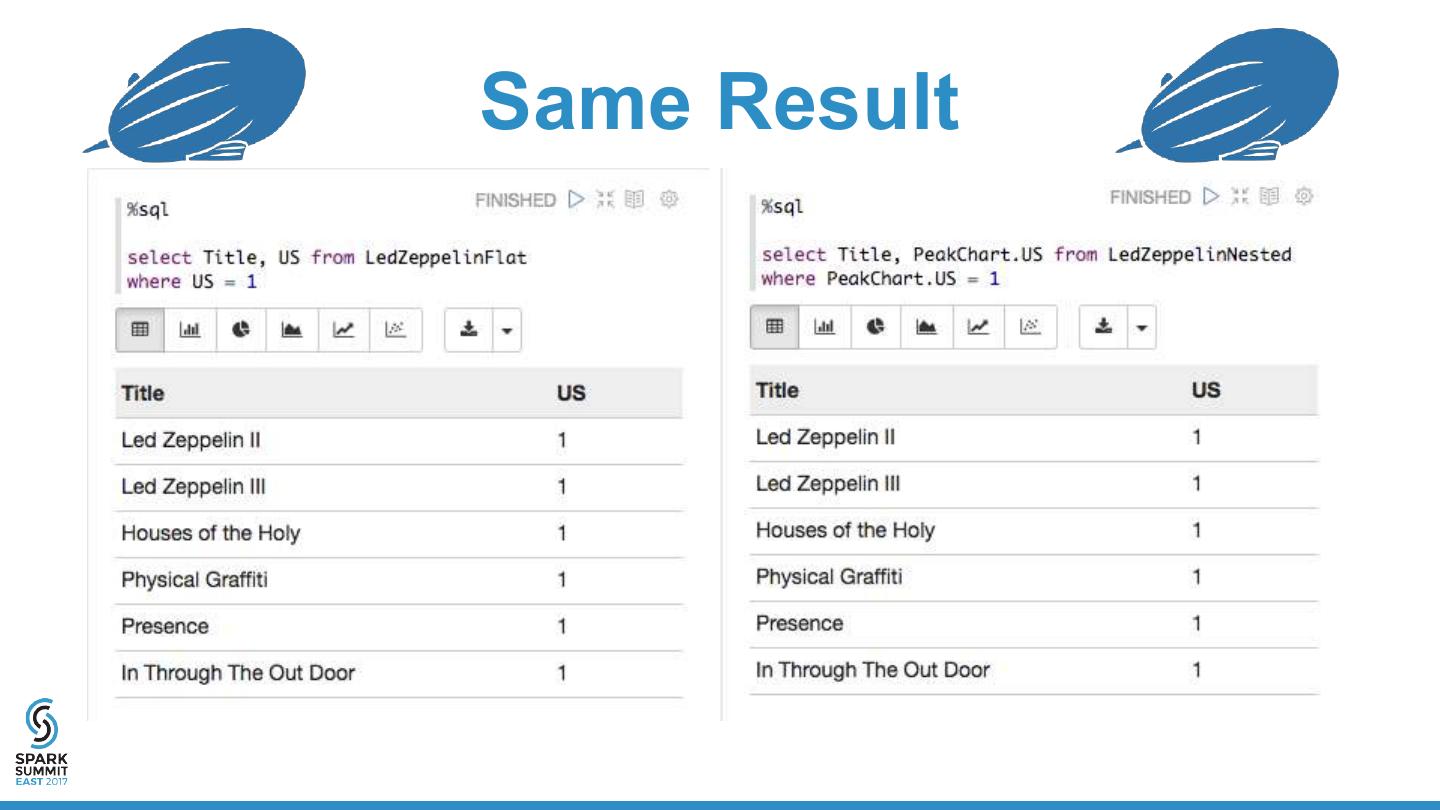
11 . CSV vs. Parquet Column Selection Query Query Time (seconds) 3000 SELECT cacheStatus, bytesSent from ADatasetThatHasToDoWithCDNs 2500 2892.3 WHERE cacheStatus LIKE 'stale' AND bytesSent < 500 2000 1500 1000 500 0 50.6 43.4 40.3 28.9 CSV Parquet: LZO Parquet: Parquet: GZIP Parquet: Snappy Uncompressed
12 . CSV vs. Parquet Table Scan Query Query Time (seconds) 2000 SELECT * from ADatasetThatHasToDoWithCDNs 2059 WHERE cacheStatus LIKE 'stale' AND bytesSent < 500 1500 1000 500 0 50 49.1 44.2 39.6 CSV Parquet: LZO Parquet: Snappy Parquet: Parquet: GZIP Uncompressed
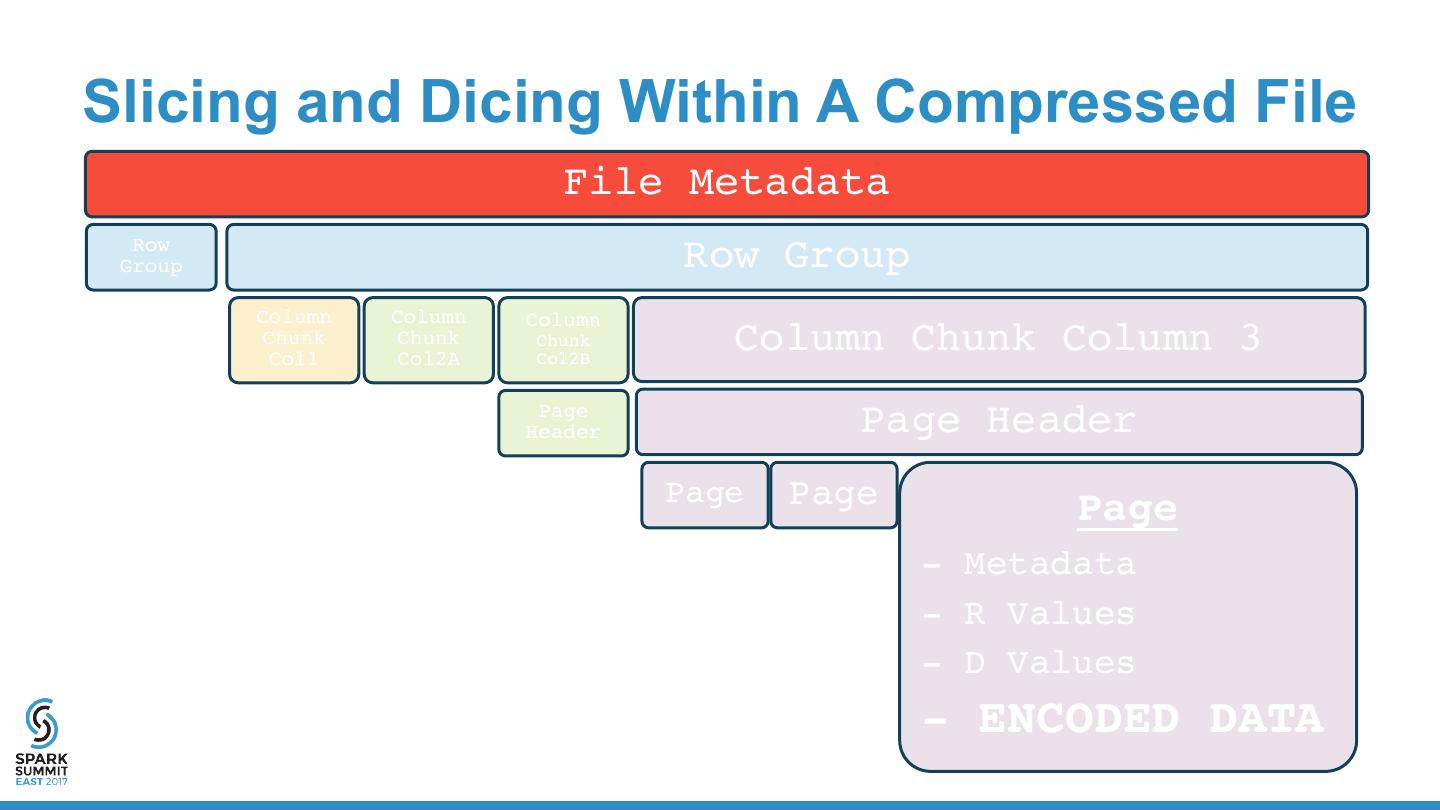
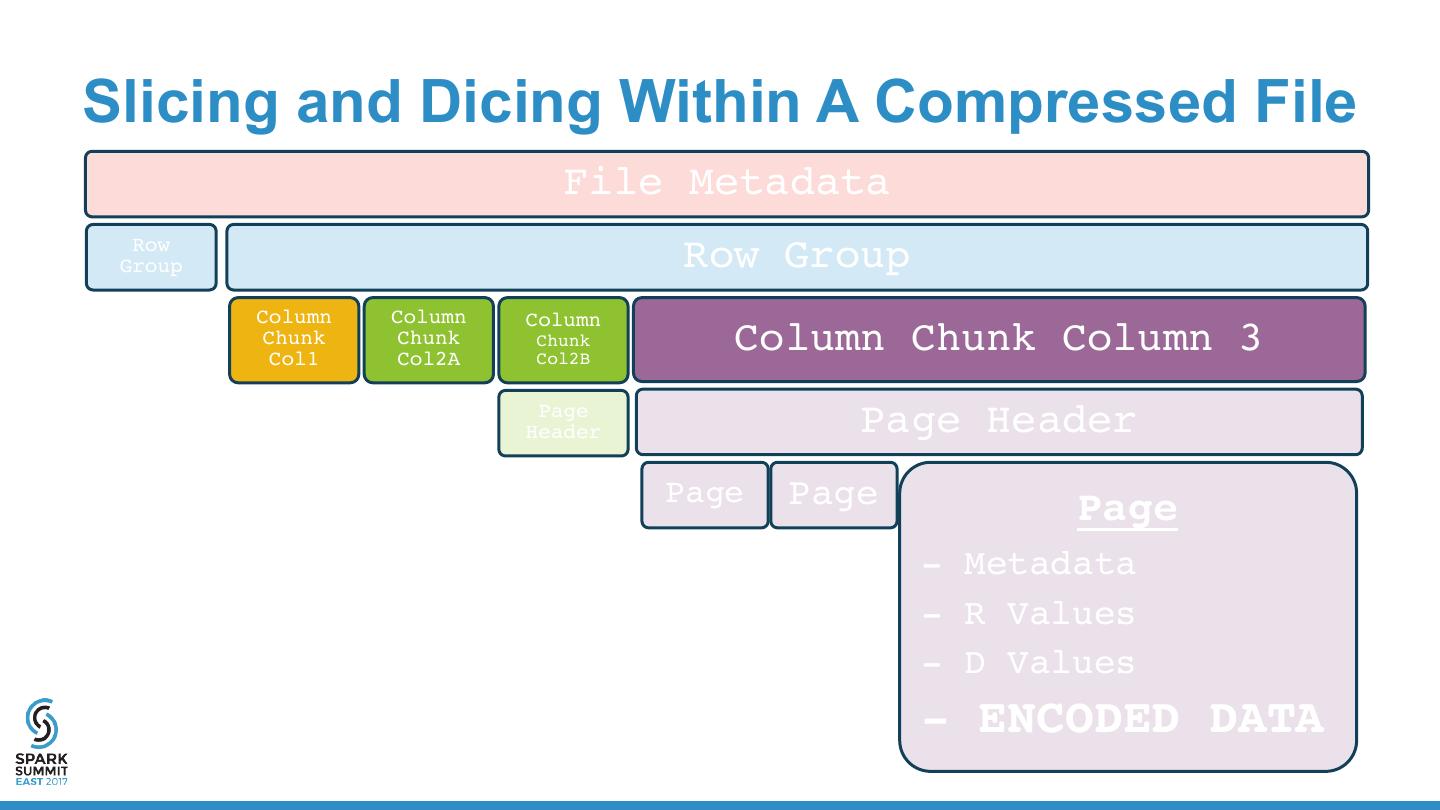
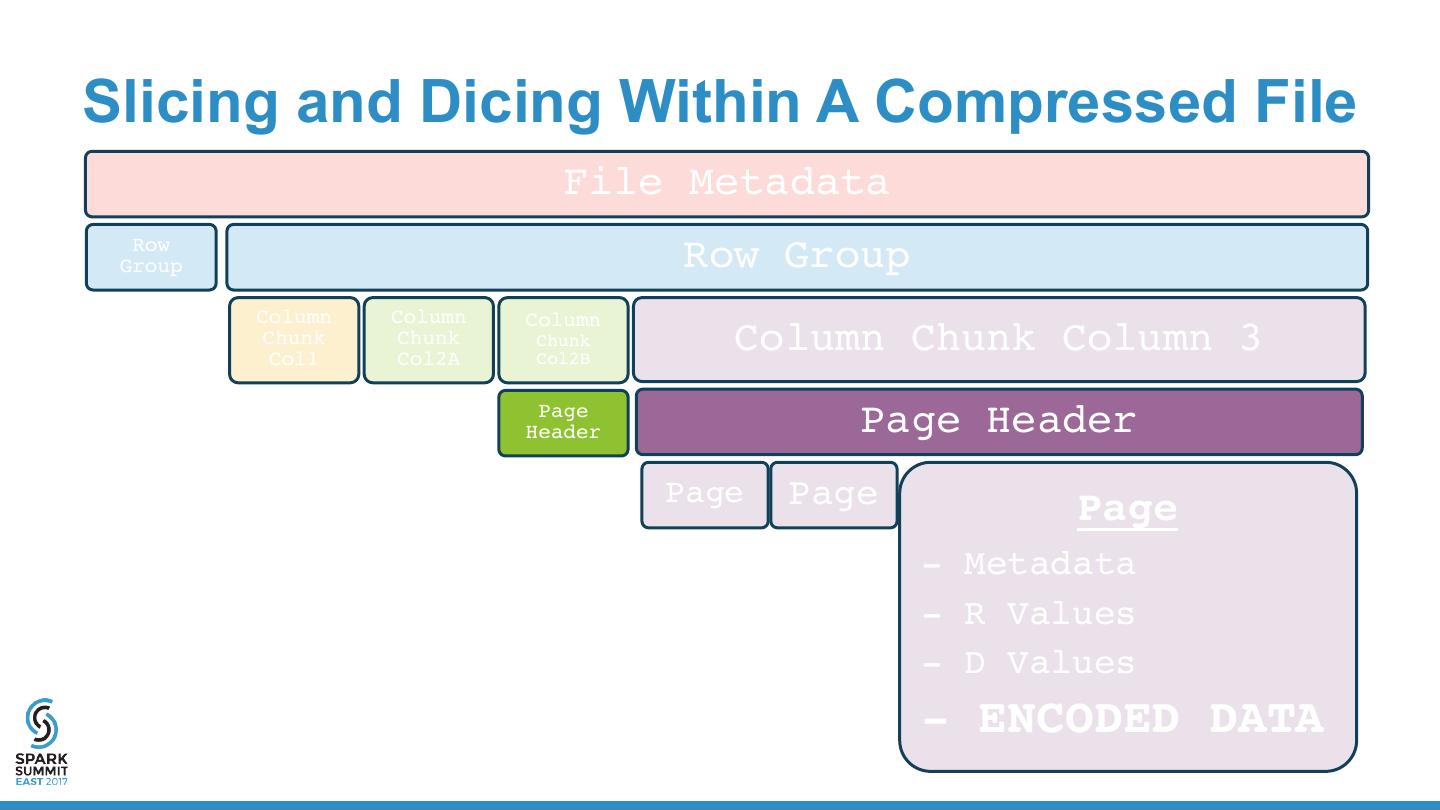
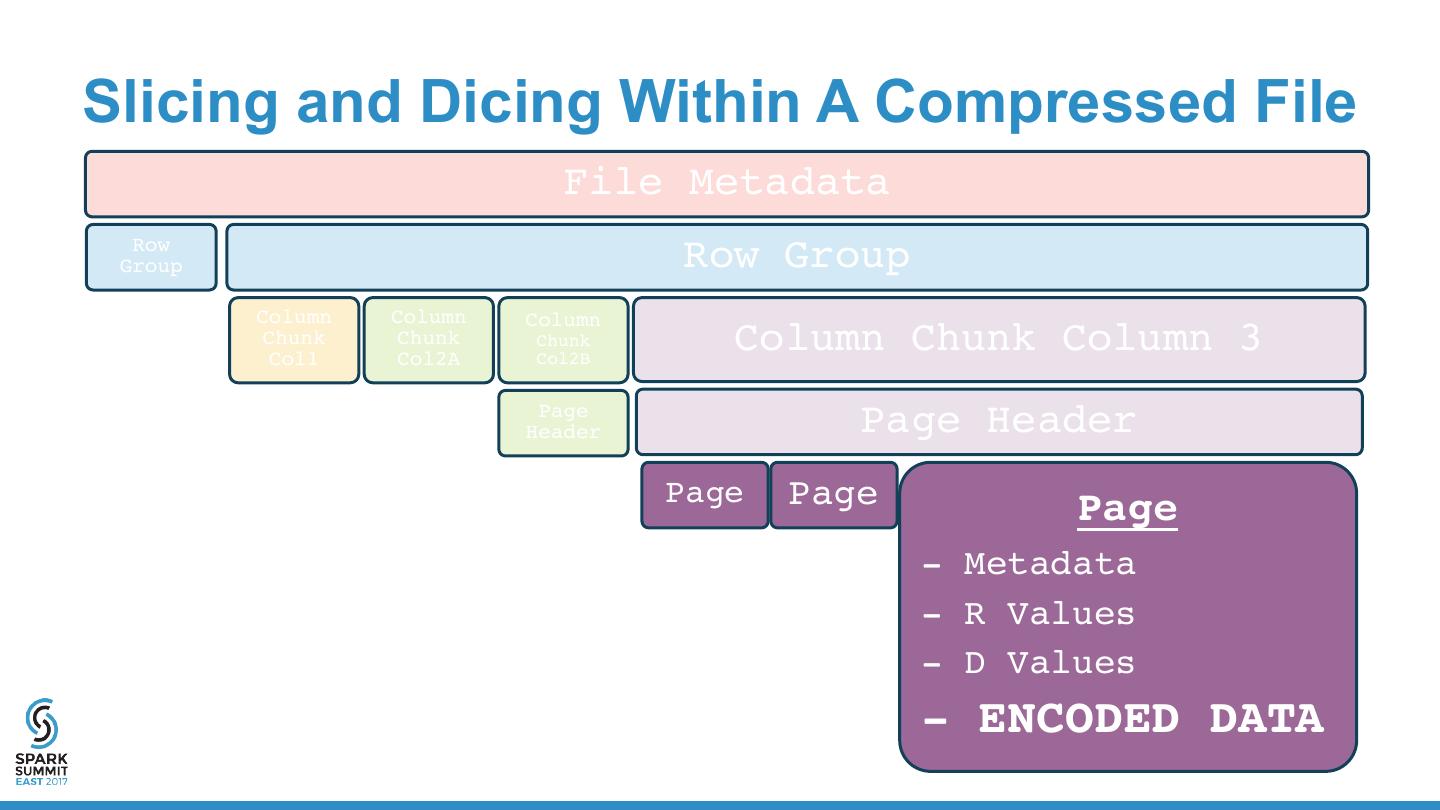
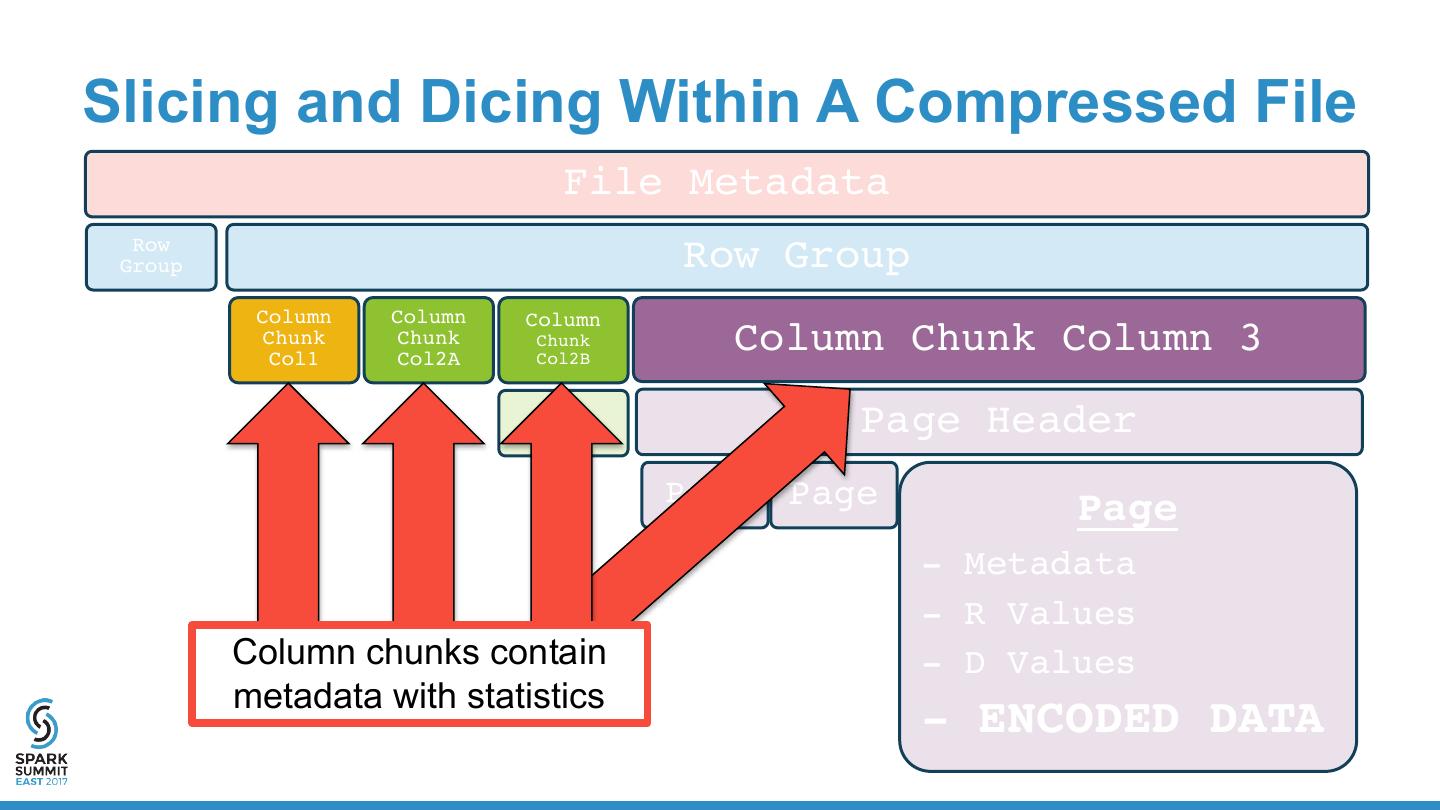
13 . Parquet Format “Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.” • Binary Format • Encoded • API for JVM/Hadoop & C++ • Compressed • Columnar • Machine-Friendly
14 .Parquet By Example Introducing the Dataset
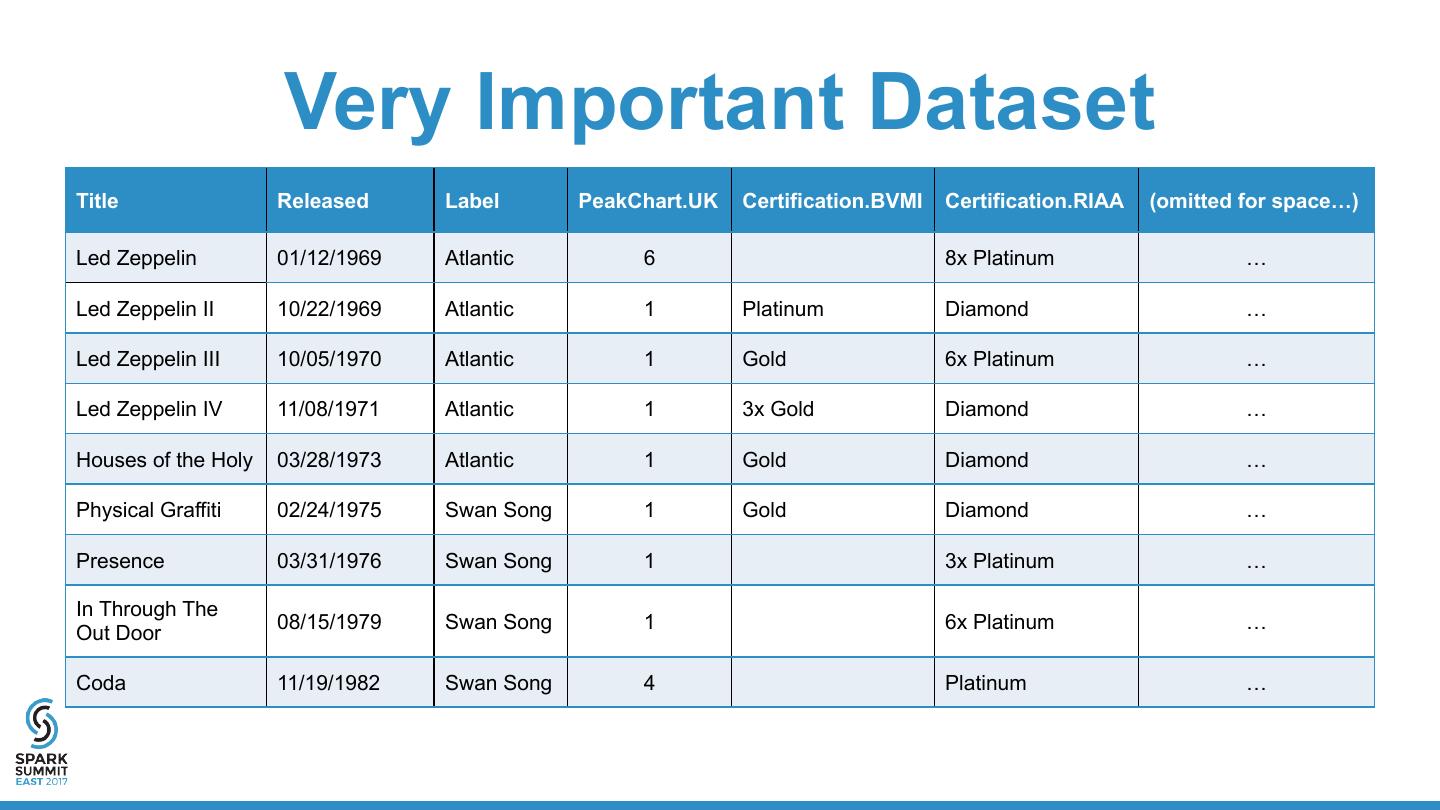
15 . Very Important Dataset Title Released Label PeakChart.UK Certification.BVMI Certification.RIAA (omitted for space…) Led Zeppelin 01/12/1969 Atlantic 6 8x Platinum … Led Zeppelin II 10/22/1969 Atlantic 1 Platinum Diamond … Led Zeppelin III 10/05/1970 Atlantic 1 Gold 6x Platinum … Led Zeppelin IV 11/08/1971 Atlantic 1 3x Gold Diamond … Houses of the Holy 03/28/1973 Atlantic 1 Gold Diamond … Physical Graffiti 02/24/1975 Swan Song 1 Gold Diamond … Presence 03/31/1976 Swan Song 1 3x Platinum … In Through The 08/15/1979 Swan Song 1 6x Platinum … Out Door Coda 11/19/1982 Swan Song 4 Platinum …
16 . One Row, Two Different Ways { { "Title" : "Led Zeppelin IV", "TITLE": "LED ZEPPELIN IV", "Released" : "11/8/1971", "RELEASED": "11/8/1971", "Label" : "Atlantic", "PeakChart.UK" : 1, "LABEL": "ATLANTIC", "PeakChart.AUS" : 2, "PEAKCHART": { "PeakChart.US" : 2, "UK": 1, "Certification.ARIA" : "9x Platinum", "AUS": 2, "Certification.BPI" : "6x Platinum", "US": 2 }, "Certification.BVMI" : "3x Gold", "Certification.CRIA" : "2x Diamond", "CERTIFICATION": { "Certification.IFPI" : "2x Platinum", "ARIA": "9X PLATINUM", "Certification.NVPI" : "Platinum", "BPI": "6X PLATINUM", "Certification.RIAA" : "Diamond", "BVMI": "3X GOLD", "Certification.SNEP" : "2x Platinum" "CRIA": "2X DIAMOND", } "IFPI": "2X PLATINUM", "NVPI": "PLATINUM", "RIAA": "DIAMOND", "SNEP": "2X PLATINUM“ } }
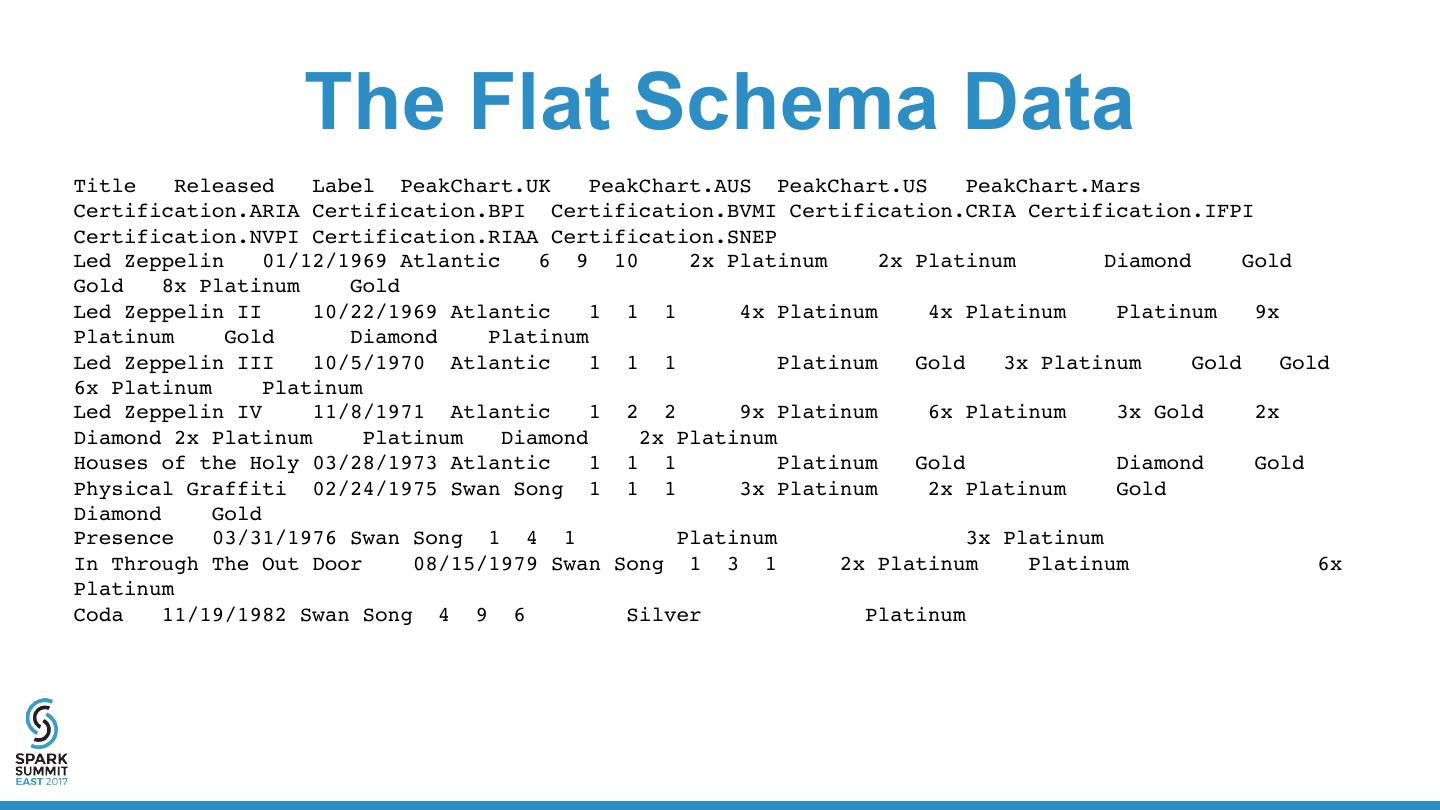
17 . The Flat Schema Data Title Released Label PeakChart.UK PeakChart.AUS PeakChart.US PeakChart.Mars Certification.ARIA Certification.BPI Certification.BVMI Certification.CRIA Certification.IFPI Certification.NVPI Certification.RIAA Certification.SNEP Led Zeppelin 01/12/1969 Atlantic 6 9 10 2x Platinum 2x Platinum Diamond Gold Gold 8x Platinum Gold Led Zeppelin II 10/22/1969 Atlantic 1 1 1 4x Platinum 4x Platinum Platinum 9x Platinum Gold Diamond Platinum Led Zeppelin III 10/5/1970 Atlantic 1 1 1 Platinum Gold 3x Platinum Gold Gold 6x Platinum Platinum Led Zeppelin IV 11/8/1971 Atlantic 1 2 2 9x Platinum 6x Platinum 3x Gold 2x Diamond 2x Platinum Platinum Diamond 2x Platinum Houses of the Holy 03/28/1973 Atlantic 1 1 1 Platinum Gold Diamond Gold Physical Graffiti 02/24/1975 Swan Song 1 1 1 3x Platinum 2x Platinum Gold Diamond Gold Presence 03/31/1976 Swan Song 1 4 1 Platinum 3x Platinum In Through The Out Door 08/15/1979 Swan Song 1 3 1 2x Platinum Platinum 6x Platinum Coda 11/19/1982 Swan Song 4 9 6 Silver Platinum
18 . The Nested Schema Data {"Title":"Led Zeppelin", "Released":"01/12/1969", "Label":"Atlantic", "PeakChart":{"UK":6, "AUS":9, "US":10}, "Certification":{"ARIA":"2x Platinum", "BPI":"2x Platinum", "CRIA":"Diamond", "IFPI":"Gold", "NVPI":"Gold", "RIAA":"8x Platinum", "SNEP":"Gold"}} {"Title":"Led Zeppelin II", "Released":"10/22/1969", "Label":"Atlantic", "PeakChart":{"UK":1, "AUS":1, "US":1}, "Certification":{"ARIA":"4x Platinum", "BPI":"4x Platinum", "BVMI":"Platinum", "CRIA":"9x Platinum", "IFPI":"Gold", "RIAA":"Diamond", "SNEP":"Platinum"}} {"Title":"Led Zeppelin III", "Released":"10/5/1970", "Label":"Atlantic", "PeakChart":{"UK":1, "AUS":1, "US":1}, "Certification":{"BPI":"Platinum", "BVMI":"Gold", "CRIA":"3x Platinum", "IFPI":"Gold", "NVPI":"Gold", "RIAA":"6x Platinum", "SNEP":"Platinum"}} {"Title":"Led Zeppelin IV", "Released":"11/8/1971", "Label":"Atlantic", "PeakChart":{"UK":1, "AUS":2, "US":2}, "Certification":{"ARIA":"9x Platinum", "BPI":"6x Platinum", "BVMI":"3x Gold", "CRIA":"2x Diamond", "IFPI":"2x Platinum", "NVPI":"Platinum", "RIAA":"Diamond", "SNEP":"2x Platinum"}} {"Title":"Houses of the Holy", "Released":"03/28/1973", "Label":"Atlantic", "PeakChart":{"UK":1, "AUS":1, "US":1}, "Certification":{"BPI":"Platinum", "BVMI":"Gold", "RIAA":"Diamond", "SNEP":"Gold"}} {"Title":"Physical Graffiti", "Released":"02/24/1975", "Label":"Swan Song", "PeakChart":{"UK":1, "AUS":1, "US":1}, "Certification":{"ARIA":"3x Platinum", "BPI":"2x Platinum", "BVMI":"Gold", "RIAA":"Diamond", "SNEP":"Gold"}} {"Title":"Presence", "Released":"03/31/1976", "Label":"Swan Song", "PeakChart":{"UK":1, "AUS":4, "US":1}, "Certification":{"BPI":"Platinum", "RIAA":"3x Platinum"}} {"Title":"In Through The Out Door", "Released":"08/15/1979", "Label":"Swan Song", "PeakChart":{"UK":1, "AUS":3, "US":1}, "Certification":{"ARIA":"2x Platinum", "BPI":"Platinum", "RIAA":"6x Platinum"}} {"Title":"Coda", "Released":"11/19/1982", "Label":"Swan Song", "PeakChart":{"UK":4, "AUS":9, "US":6}, "Certification":{"BPI":"Silver", "RIAA":"Platinum"}}
19 .Parquet By Example Writing Parquet Using Spark
20 .Writing To Parquet: Flat Schema val flatDF = spark .read.option("delimiter", "\t") .option("header", "true").csv(flatInput) .rdd .map(r => transformRow(r)) .toDF flatDF.write .option("compression", "snappy") .parquet(flatOutput)
21 . Writing To Parquet: Flat Schema /*Oh crap, the Ints are gonna get pulled in as Strings unless we transform*/ case class LedZeppelinFlat( Title: Option[String], Released: Option[String], Label: Option[String], UK: Option[Int], AUS: Option[Int], US: Option[Int], ARIA: Option[String], BPI: Option[String], BVMI: Option[String], CRIA: Option[String], IFPI: Option[String], NVPI: Option[String], RIAA: Option[String], SNEP: Option[String] )
22 . Writing To Parquet: Flat Schema def transformRow(r: Row): LedZeppelinFlat = { def getStr(r: Row, i: Int) = if(!r.isNullAt(i)) Some(r.getString(i)) else None def getInt(r: Row, i: Int) = if(!r.isNullAt(i)) Some(r.getInt(i)) else None LedZeppelinFlat( getStr(r, 0), getStr(r, 1), getStr(r, 2), getInt(r, 3), getInt(r, 4), getInt(r, 5), getStr(r, 7), getStr(r, 8), getStr(r, 9), getStr(r, 10), getStr(r, 11), getStr(r, 12), getStr(r, 13), getStr(r, 14) ) }
23 .Writing To Parquet: Flat Schema val outDF = spark .read.option("delimiter", "\t") .option("header", "true").csv(flatInput) .rdd .map(r => transformRow(r)) .toDF outDF.write .option("compression", "snappy") .parquet(flatOutput)
24 .Writing To Parquet: Flat Schema
25 .Writing To Parquet: Flat Schema… In Java
26 .Writing To Parquet: Flat Schema… With MapReduce
27 .Writing To Parquet: Nested Schema val nestedDF = spark.read.json(nestedInput) nestedDF.write .option("compression", "snappy") .parquet(nestedOutput)
28 .Writing To Parquet: Nested Schema
29 .Parquet By Example Let’s See An Example!
3秒后跳转登录页面
去登陆

