
























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
PayPal merchant ecosystem using Apache Spark, Hive, Druid,
As one of the few closed-loop payment platforms, PayPal is uniquely positioned to provide merchants with insights aimed to identify opportunities to help grow and manage their business. PayPal processes billions of data events every day around our users, risk, payments, web behavior and identity. We are motivated to use this data to enable solutions to help our merchants maximize the number of successful transactions (checkout-conversion), better understand who their customers are and find additional opportunities to grow and attract new customers.
展开查看详情
1 .PayPal Merchant ecosystem using Spark, Hive, Druid, HBase & Elasticsearch
2 .Who we are? • Big Data Technologist for over a decade • Focused on building scalable platforms with Hadoop ecosystem – Map Reduce, HBase, Spark, Elasticsearch, Druid • Senior Engineering Manager - Merchant Analytics at PayPal • Contributed to Druid for the Spark Streaming integration Deepika Khera • 15+ years of industry experience • Spark Engineer @PayPal Merchant Analytics • Building solutions using Apache Spark, Scala, Hive, HBase, Druid and Spark ML. • Passionate about providing Analytics at scale from Big Data platforms Kasi Natarajan 2
3 .Agenda PayPal Data & Scale Merchant Use Case Review Data Pipeline Learnings - Spark & HBase Tools & Utilities Behavioral Driven Development Data Quality Tool using Spark BI with Druid & Tableau 3
4 .PayPal Data & Scale 4
5 .PayPal is more than a button CBT Mobile In-Store Online Loyalty Credit APV Lift Offers Faster Reduction Customer Invoicing Conversion in Cart Acquisition Abandonment 5
6 .PayPal Datasets Transactio n Consumer Partners Credit Merchants Risk Reversals CBT Activity Disputes Invoice Email Applicatio n Logs Payment Demo- Location Products graphics Social Media Marketing Spending 6
7 .The power of our platform 7.6 ~60 BILLION 19M Dedicated to with a 0 payments/ PayPal operates one of payments in second at peak* merchants customer focused, the largest 2017** strong performance, PRIVATE highly scalable, CLOUDS in the world* 200 237M 42 continuously available PLATFORM. + markets active customer accounts** petabytes of data* PayPal operates one of the largest Hadoop PayPal has one of the top five Kafka deployments in the world. deployments in the world, handling over A 1600 Node Hadoop Cluster with 230TB of Memory, 78PB of Storage 200 billion messages per day Running 50,000 Jobs Per day 7
8 .Merchant Use Case Review 8
9 .Use Case Overview INSIGHTS .com MARKETING SOLUTIONS PAYPAL ANALYTICS • Revenue & transaction trends • Help Merchants engage their • Products performance • Cross-Border Insights customers by personalized • Checkout Funnel • Customer Shopping Segments shopping experience • Behavior analysis • Offers & Campaigns • Measuring effectiveness • Shoppers Insights Merchant Data Platform 1. Fast Processing platform crunching multi-terabytes of data 2. Scalable, Highly available, Low latency Serving platform 9
10 .Technologies Processing Serving Movement 10
11 .Merchant Analytics Merchant Pre-aggregated Data Cubes Platform Analytics Denormalized Schema 11
12 .Data Pipeline 12
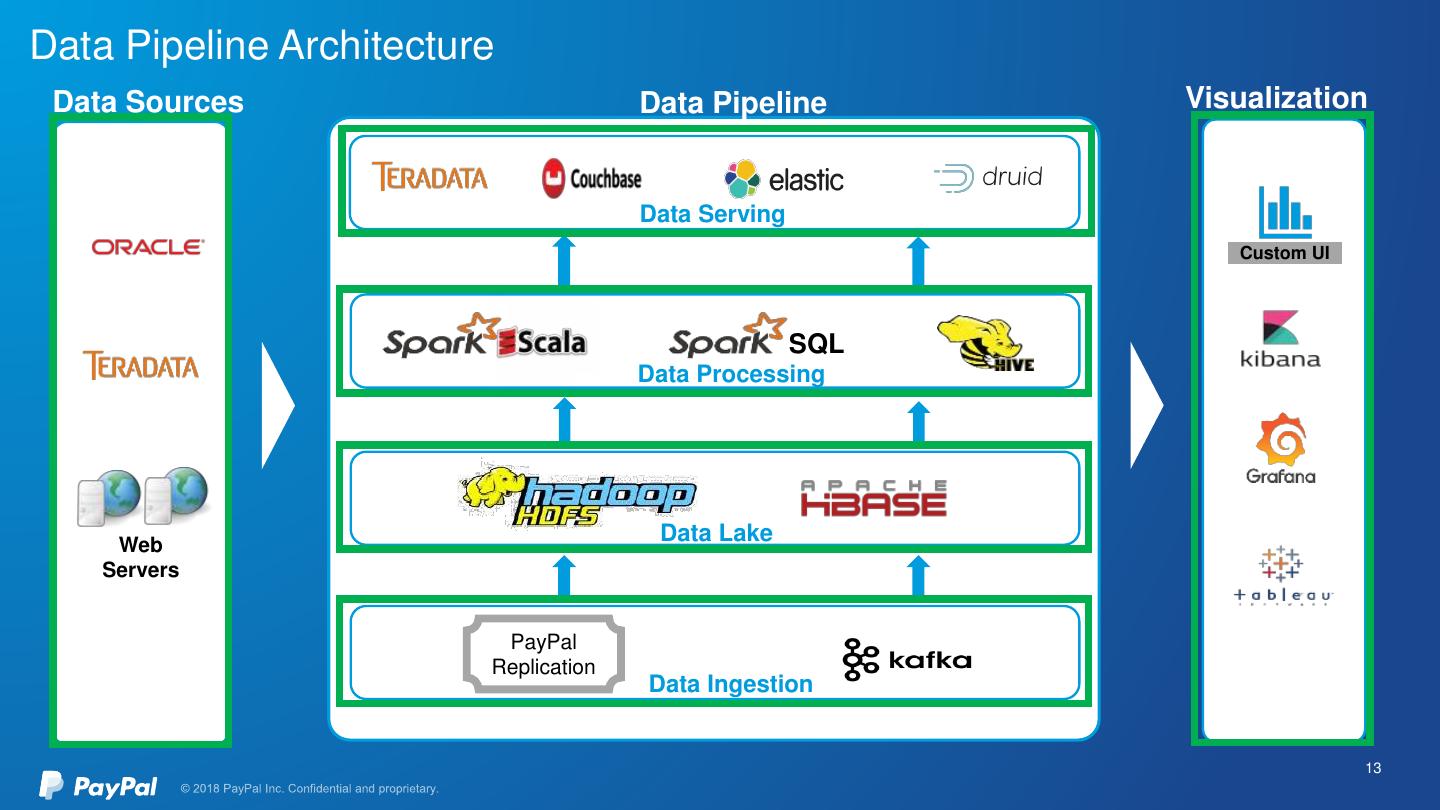
13 .Data Pipeline Architecture Data Sources Data Pipeline Visualization Data Serving Custom UI SQL Data Processing Web Data Lake Servers PayPal Replication Data Ingestion 13
14 .Learnings – Spark & HBase 14
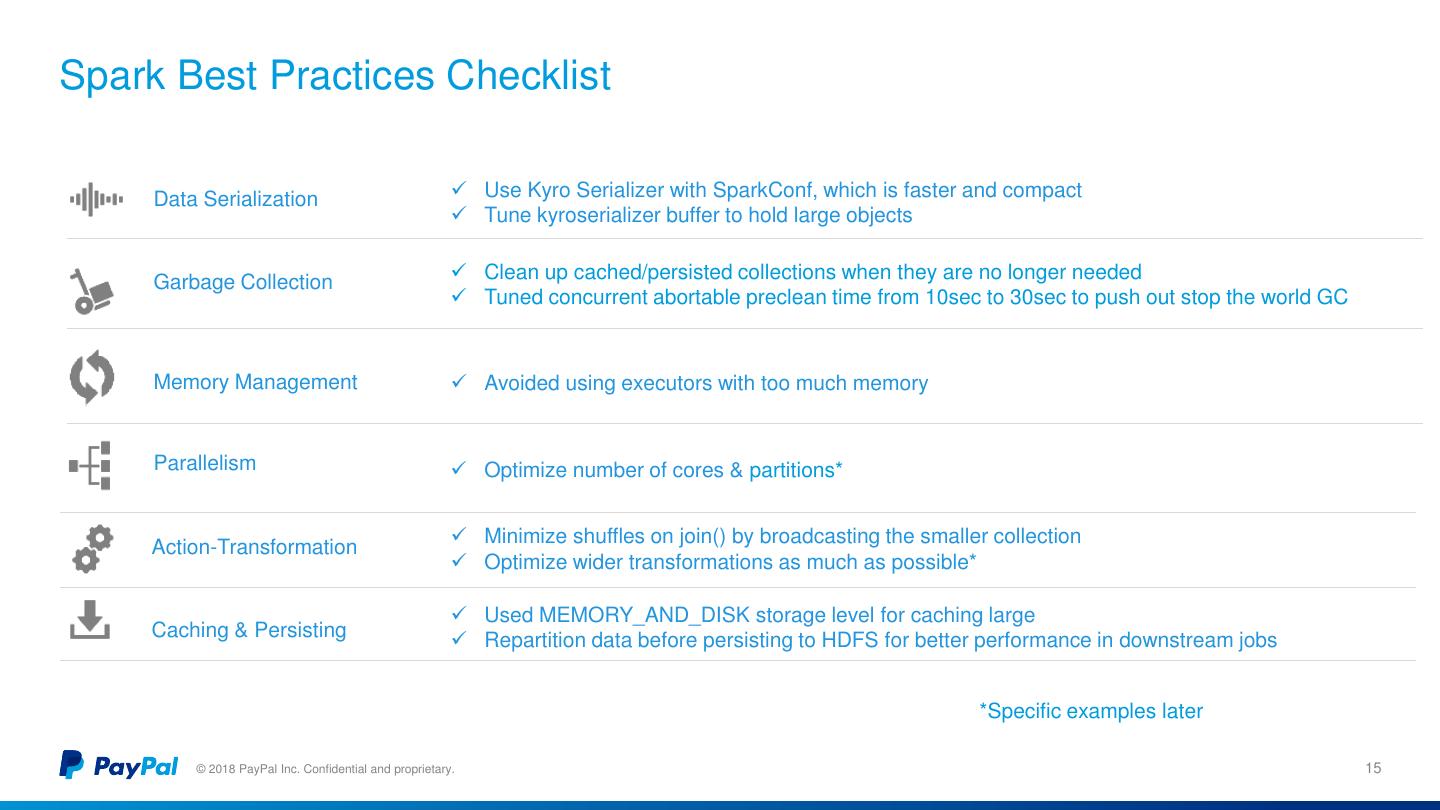
15 .Design Spark Best Practices Checklist Considerations for Spark Data Serialization Use Kyro Serializer with SparkConf, which is faster and compact Tune kyroserializer buffer to hold large objects Garbage Collection Clean up cached/persisted collections when they are no longer needed Tuned concurrent abortable preclean time from 10sec to 30sec to push out stop the world GC Memory Management Avoided using executors with too much memory Parallelism Optimize number of cores & partitions* Action-Transformation Minimize shuffles on join() by broadcasting the smaller collection Optimize wider transformations as much as possible* Used MEMORY_AND_DISK storage level for caching large Caching & Persisting Repartition data before persisting to HDFS for better performance in downstream jobs *Specific examples later © 2018 PayPal Inc. Confidential and proprietary. 15
16 .Learnings Spark job failures with Fetch Exceptions Long shuffle read times Observations • Executor spends long time on shuffle reads. Then times out , terminates and results in job failure • Resource constraints on executor nodes causing delay in executor node Resolution To address memory constraints, tuned 1. config from 200 executor * 4 cores to 400 executor * 2 cores 2. executor memory allocation (reduced) © 2018 PayPal Inc. Confidential and proprietary. 16
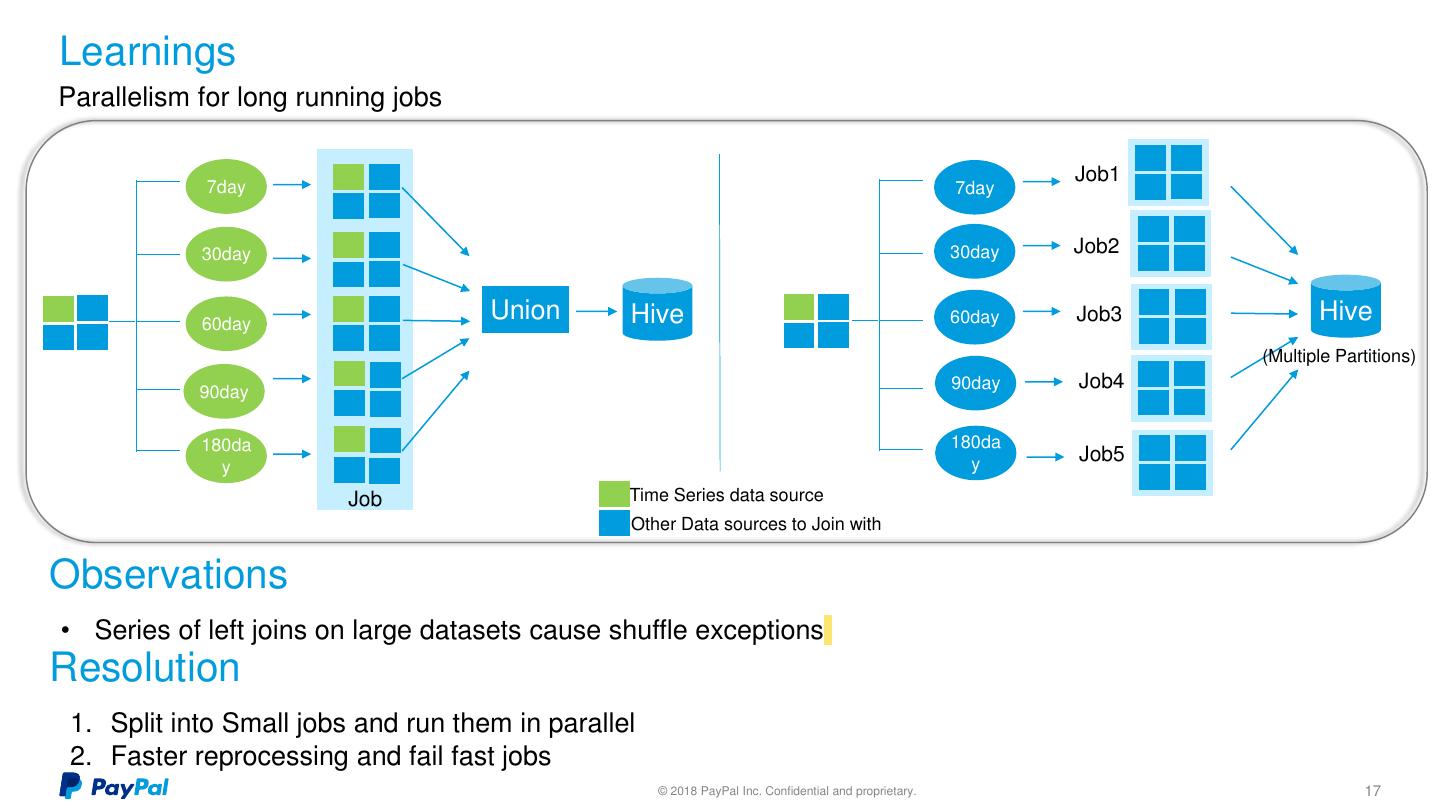
17 .Learnings Parallelism for long running jobs Job1 7day 7day 30day 30day Job2 60day Union Hive 60day Job3 Hive (Multiple Partitions) 90day 90day Job4 180da 180da y Job5 y Job Time Series data source Other Data sources to Join with Observations • Series of left joins on large datasets cause shuffle exceptions Resolution 1. Split into Small jobs and run them in parallel 2. Faster reprocessing and fail fast jobs © 2018 PayPal Inc. Confidential and proprietary. 17
18 .Learnings Tuning between Spark driver and executors Yarn RM Executor Waiting on Driver Executor Driver Executor Heartbeats heartbeats Executor Observations • Spark Driver was left with too many heartbeat requests to process even after the job was complete • Yarn kills the Spark job after waiting on the Driver to complete processing the Heartbeats Resolution • The setting “spark.executor.heartbeatInterval” was set too low. Increasing it to 50s fixed the issue • Allocate more memory to Driver to handle overheads other than typical Driver processes © 2018 PayPal Inc. Confidential and proprietary. 18
19 .Learnings Optimize joins for efficient use of cluster resources (Memory, CPU etc..,) Start Read Read Table Table 2 1 Join Process Observation With the default shuffle partitions of 200, the Join Stage was running with too many tasks causing performance overhead Resolution Reduce the spark.sql.shuffle.partitions settings to a lower threshold © 2018 PayPal Inc. Confidential and proprietary. 19
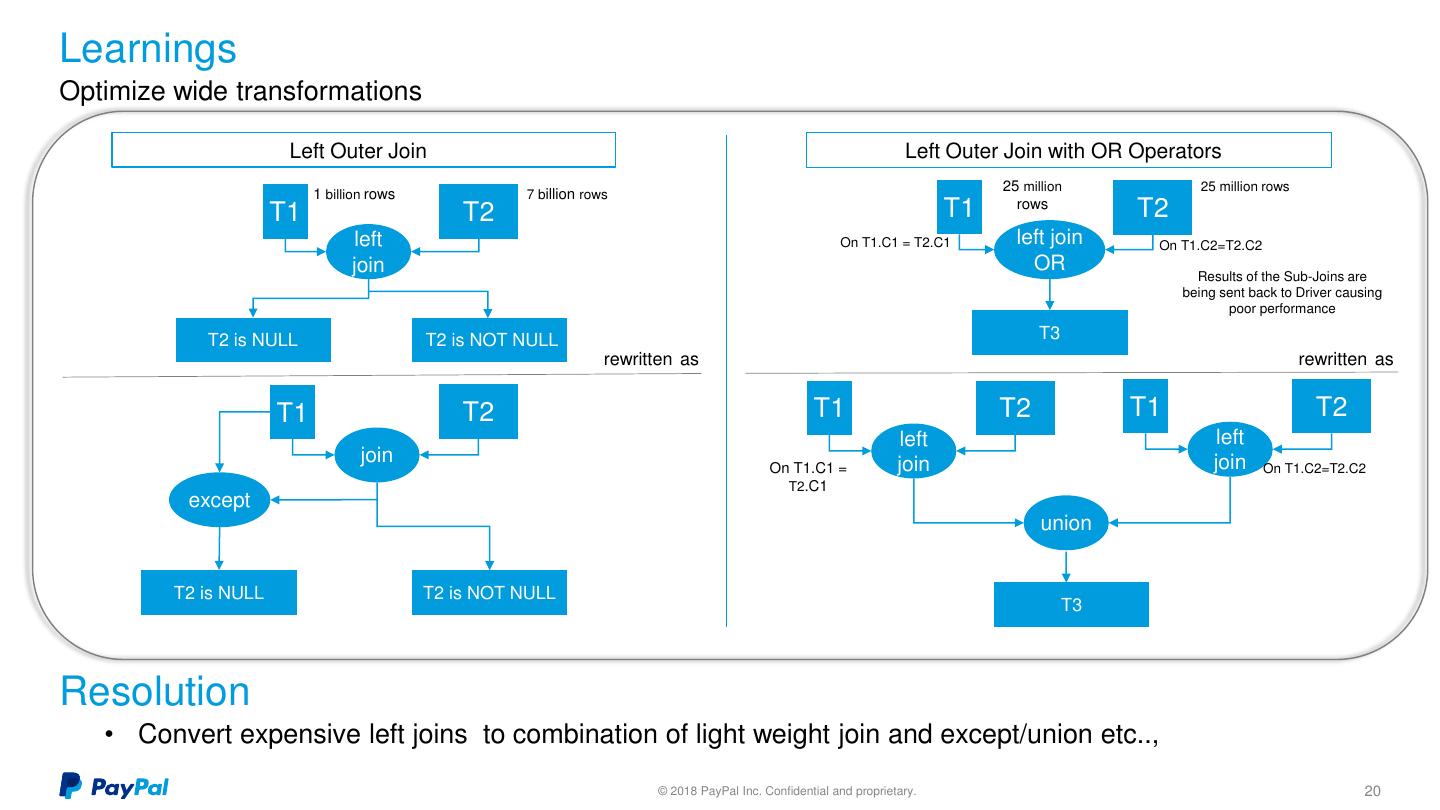
20 .Learnings Optimize wide transformations Left Outer Join Left Outer Join with OR Operators 25 million 25 million rows 1 billion rows 7 billion rows T1 T2 T1 rows T2 left On T1.C1 = T2.C1 left join On T1.C2=T2.C2 join OR Results of the Sub-Joins are being sent back to Driver causing poor performance T2 is NULL T2 is NOT NULL T3 rewritten as rewritten as T1 T2 T1 T2 T1 T2 left left join join join On T1.C1 = On T1.C2=T2.C2 T2.C1 except union T2 is NULL T2 is NOT NULL T3 Resolution • Convert expensive left joins to combination of light weight join and except/union etc.., © 2018 PayPal Inc. Confidential and proprietary. 20
21 .Learnings Optimize throughput for HBase Spark Connection Observations • Batch puts and gets slow due to HBase overloaded connections • Since our HBase row was wide, HBase operations for partitions containing larger groups were slow Example Repartition Val rePartitionedRDD: RDD[Event] = RDD filledRDD.repartition(2000) ….. ….. For each groupedEventRDD.mapPartitions( p => RDD partition p.sliding(2000,2000)..foreach( For each Sliding Create Hbase Connection Window Batch Hbase Read or Write Perform HBase Close Hbase Connection ) batch operation ) Resolution • Implemented sliding window for HBase Operations to reduce HBase connection overload © 2018 PayPal Inc. Confidential and proprietary. 21
22 .Tools & Utilities 22
23 .Behavioral Driven Development • While Unit tests are more about the implementation, BDD emphasizes more on the behavior of the code • Writing “Specifications” in pseudo-English. • Enables testing at external touch-points of your application Feature : Identify the activity related to an event pseudo code import cucumber.api.scala.{EN, ScalaDsl} Scenario: Should perform an iteration on events and join to activity table and identify the activity name import cucumber.api.DataTable import org.scalatest.Matchers Given I have a set of events |cookie_id:String |page_id:String|last_actvty:String| Given("""^I have a set of events$""") { (data:DataTable) => |263FHFBCBBCBV|login_provide |review_next_page| eventdataDF = dataTableToDataFrame(data) |HFFDJFLUFBFNJL|home_page |provide_credent| } And I have a Activity table Given("""^I have a Activity table$""") { (data:DataTable) => |last_activity_id:String|activity_id:String|activity_name:String| activityDataDF = dataTableToDataFrame(data) |review_next_page | 1494300886856 |Reviewing Next Page | } |provide_credent | 2323232323232 |Provide Credentials | When("""^I implement Event Activity joins$"""){ () => When I implement Event Activity joins eventActivityDF = Activity.findAct(eventdataDF, activityDataDF) } } Then the final result is Then("""^the final result is $"""){ (expectedData:DataTable) => |cookie_id:String |activity_id:String|activity_name:String| val expectedDf = dataTableToDataFrame(expectedData) |last_activity_id:String|activity_id:String|activity_name:String| val resultDF = eventActivityDF |263FHFBCBBCBV | 1494300886856 |Reviewing Next Page | resultDF.except(expectedDF).count |HFFDJFLUFBFNJL | 2323232323232 |Provide Credentials | © 2018 PayPal Inc. Confidential and proprietary. 23
24 .Data Quality Tool • Config driven automated tool written in Spark for Quality Control • Used extensively during functional testing of the application and once live, used as quality check for our data pipeline • Feature to compare tables (schema agnostic and at Scale) for data validation and helping engineers troubleshoot effectively Quality Tool Flow Source Tables Output Table …….. Operation Source Target Key Column Query Query Config in SQL 1. Define Source ,Target Query, Test Operation in Config file Count Select c1 Select c1,c2,c3 C1 … …. format Values Select Select c1,c2,c3 C1 c1….… from t1 Quality operations 2. Spark Job that takes the config and runs the test cases Count Aggreagtion DuplicateRows MissingInLookup Values Reports Alerts 24 © 2018 PayPal Inc. Confidential and proprietary.
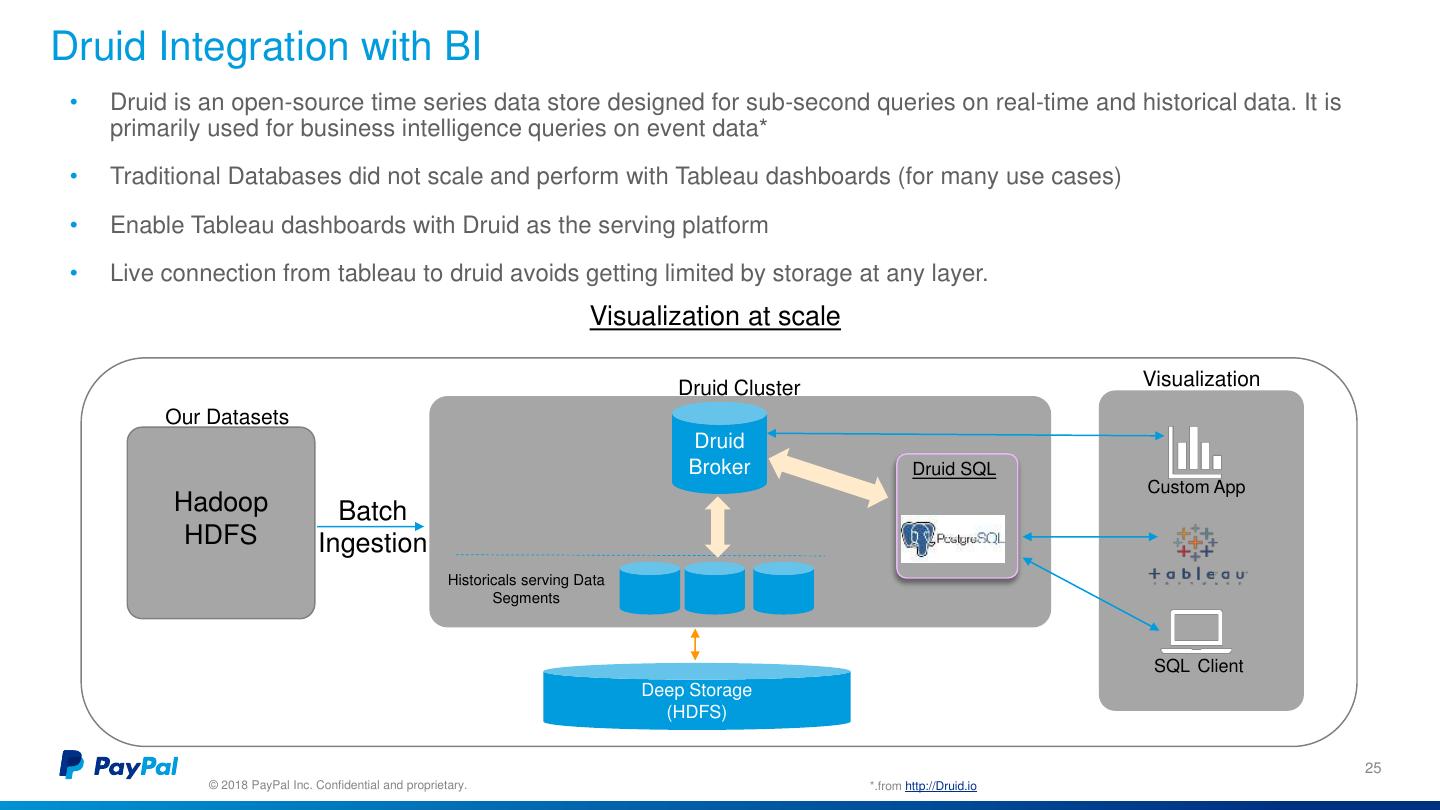
25 .Druid Integration with BI • Druid is an open-source time series data store designed for sub-second queries on real-time and historical data. It is primarily used for business intelligence queries on event data* • Traditional Databases did not scale and perform with Tableau dashboards (for many use cases) • Enable Tableau dashboards with Druid as the serving platform • Live connection from tableau to druid avoids getting limited by storage at any layer. Visualization at scale Druid Cluster Visualization Our Datasets Druid Broker Druid SQL Custom App Hadoop Batch HDFS Ingestion Historicals serving Data Segments SQL Client Deep Storage (HDFS) 25 © 2018 PayPal Inc. Confidential and proprietary. *.from http://Druid.io
26 .Conclusion Conclusion Spark Applications on Yarn (Hortonworks distribution). Spark jobs were easy to write and had excellent performance (though little hard to troubleshoot) Spark-HBase optimization improved performance Pre-aggregated datasets to Elasticsearch Denormalized datasets to Druid Pushed lowest-granularity denormalized datasets to Druid Behavior Driven Development a great add-on for Product-backed applications © 2018 PayPal Inc. Confidential and proprietary. 26
27 .QUESTIONS?
3秒后跳转登录页面
去登陆

