展开查看详情
1 .Reimagining Devon Energy’s Data Estate
NYSE: DVN
devonenergy.com
�
2 . About Devon Energy
Devon Energy is a leading
independent oil and natural
gas exploration and
production company.
• 2,800 employees
• $14 billion market cap
• Produce 541,000 Boe per
day
2
�
3 . Business Challenges
As a producer of unconventional oil and gas reserves we face both technical
and business challenges.
• Our wells wells can be more than
12,000 feet long, horizontally
• The oil and gas industry is under
tremendous pressure be cost
efficient
• How can we ramp up activity while
maintaining technical excellence?
3
�
4 .Historical Integration Landscape
Historically, we have used an ETL
engine to move data from one
application to another, usually
nightly.
This mesh makes applications
difficult to upgrade, integrations
difficult to regression test and data
flows across the environment
arbitrarily complex and slow.
4
�
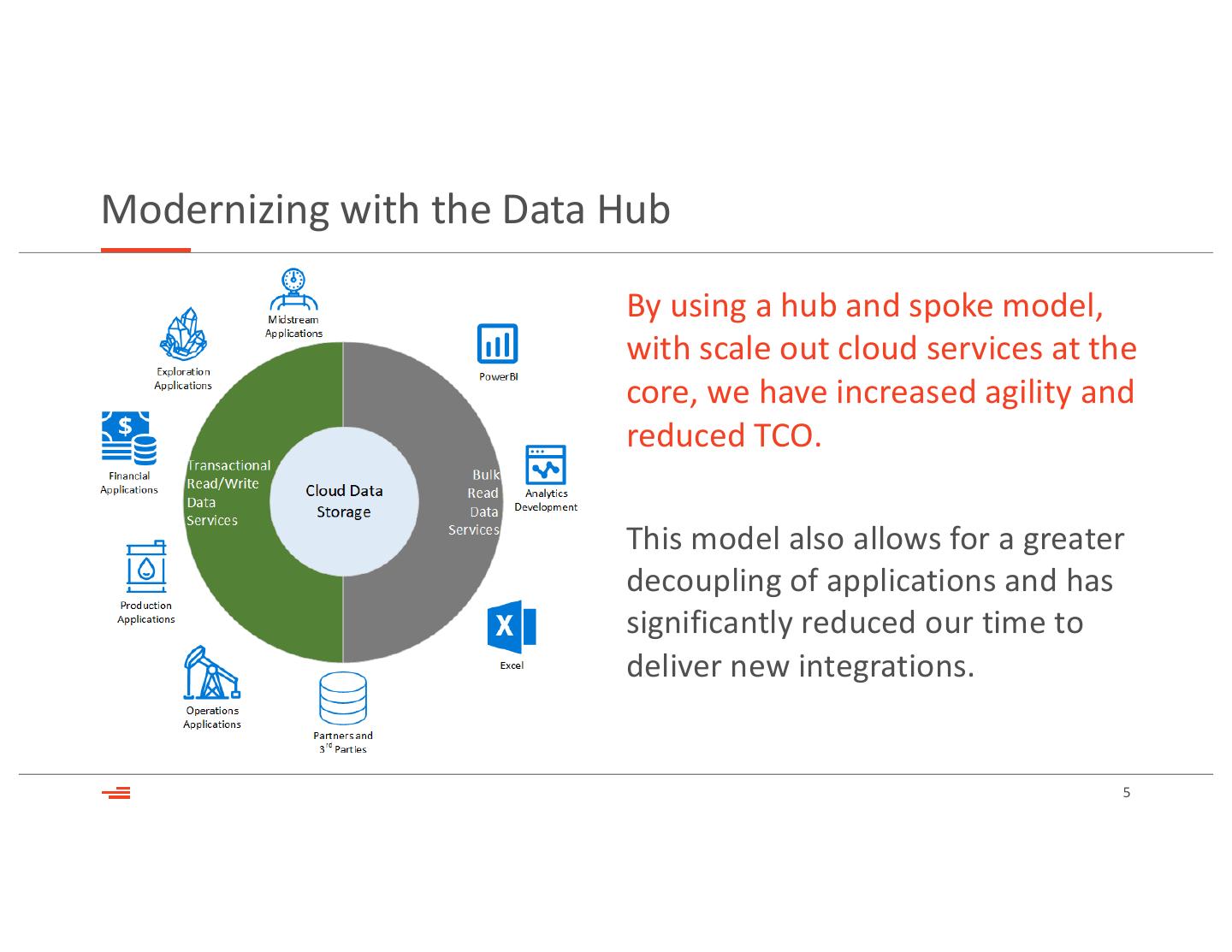
5 .Modernizing with the Data Hub
By using a hub and spoke model,
with scale out cloud services at the
core, we have increased agility and
reduced TCO.
This model also allows for a greater
decoupling of applications and has
significantly reduced our time to
deliver new integrations.
5
�
6 . Data Hub Architecture
Code Repository Log
Reporting &
& Automation Aggregation
Analytics
Azure DevOps Azure Monitor The Data Hub reinvents
our Data Warehouse and
Integration landscape.
This allows anyone to build
Data Data Data Transform Orchestration their own data and analytics
Replication Warehouse and Analytics & Monitoring
Source
Attunity Snowflake Databricks Azure Data solutions and share insights.
Factory
Systems
6
�
7 . Operations for Data Engineering & Analytics
We have begun replatforming our integration and data warehouse
solutions to the Data Hub, this has meant we had to rapidly mature our
code management, monitoring and orchestration.
• There are more than 25,000 tables in Snowflake and Databricks,
growing by several thousand per month.
• The Data Hub serves over 70 million queries per month, growing by 5-
10 million per month.
• We use the platform for data engineering, analytics, machine learning
and deep learning workflows and must support and monitor them.
7
�
8 . Continuous Deployment
When we started, most of our solutions were not checked into source
control, were not properly promoted and were not being monitored.
• Now we use the Azure DevOps integration with Databricks to check
notebooks into source control, and have a custom notebook for bulk
check-ins of large projects.
• With custom DevOps widgets, we have automated our release
management pipelines, allowing our teams to do continuous
deployment in the platform.
8
�
9 . Continuous Integration
For robust, modular applications written by a developer, we see
consistent use of unit testing, but other data pipelines and data science
workloads are not developed with testability in mind.
• We have written a suite of tools to perform data validation in order to
test full data engineering pipelines.
• These consist of equivalence tests for datasets and routine jobs that
check the day over day change in a dataset against an established
baseline.
9
�
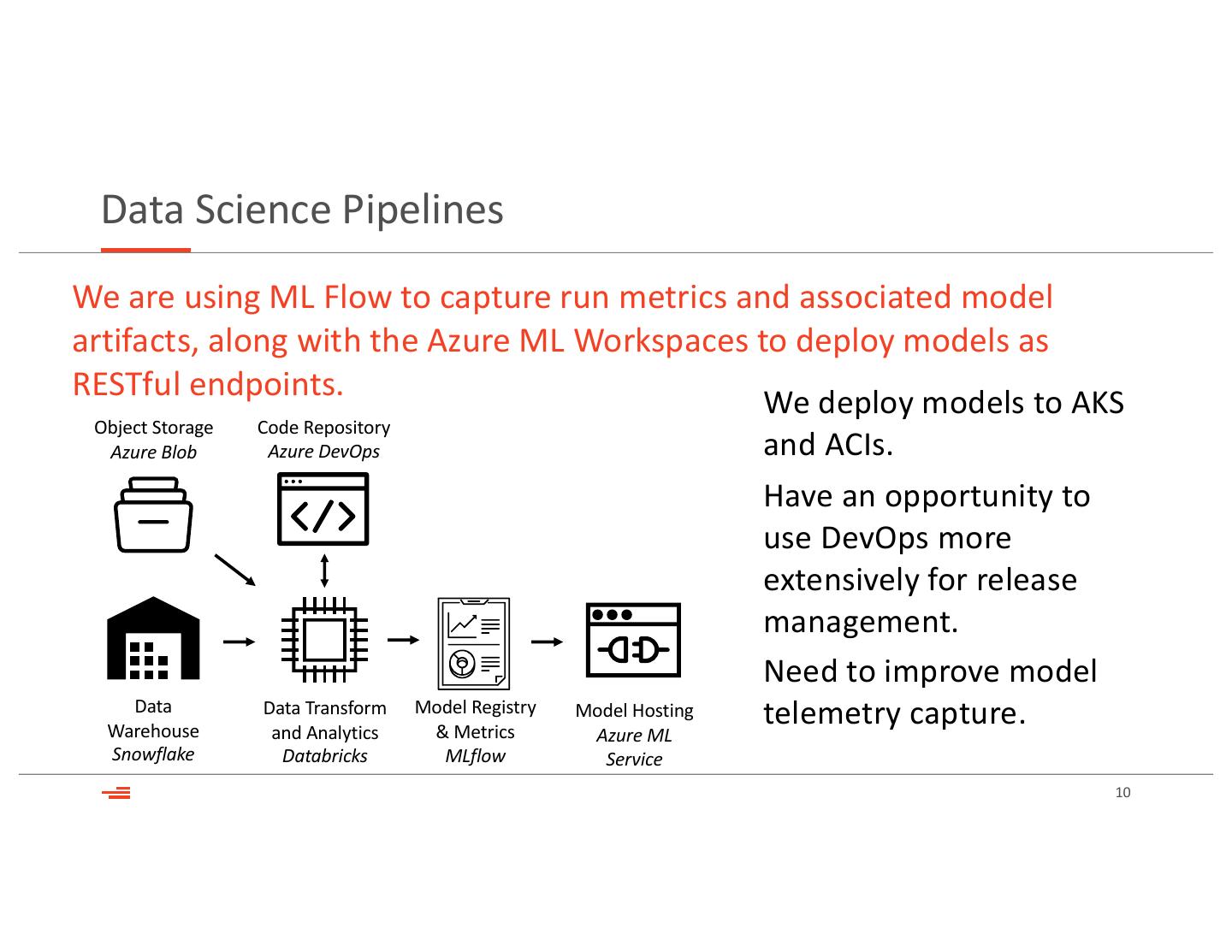
10 . Data Science Pipelines
We are using ML Flow to capture run metrics and associated model
artifacts, along with the Azure ML Workspaces to deploy models as
RESTful endpoints.
We deploy models to AKS
Object Storage Code Repository
Azure Blob Azure DevOps and ACIs.
Have an opportunity to
use DevOps more
extensively for release
management.
Need to improve model
Data
Warehouse
Data Transform Model Registry
and Analytics & Metrics
Model Hosting telemetry capture.
Azure ML
Snowflake Databricks MLflow Service
10
�
11 . Unifying Data Science & Engineering
We have successfully reduced the number of tools our data engineers,
analysts and data scientists use, providing a common platform for most
use cases.
• Previously, our data engineering and machine learning platforms were
disparate, forcing break points as use cases matured
• Using AutoML in the AML Python SDK and the ML runtime we can
provide a broad spectrum of capability
• Distributed model selection and tuning, combined with support for
sequential data unlocked many new use cases
• Support for PyTorch with Horovod and LightGBM has been very useful
11
�
12 . Use Cases
Last year we focused on implementation and prototyping, this year has
been one of rapid expansion and adoption of the platform with many of
our core data services being hosted out of it.
• The Hub has been used to populate our new integrated geoscience suite
• It has been used by technicians to perform scenario planning in order to
optimize our field development
• The platform is mastering and hosting our enterprise data objects
• Petrotechnical professionals are using it to collect data and build subsurface
models
• Regulatory emissions reporting query reduced to 30 min, down from 2 days
12
�