展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Performance Analysis of
Apache Spark and Presto in
Cloud Environments
Víctor Cuevas-Vicenttín,
Barcelona Supercomputing Center
#UnifiedDataAnalytics #SparkAISummit
�
3 .About BSC
The Barcelona Supercomputing Center (BSC) is the Spanish
national supercomputing facility, and a top EU research institution,
established in 2005 by the Spanish government, the Catalan
government and the UPC/BarcelonaTECH university.
The mission of BSC is to be at the service of the international
scientific community and of industry in need of HPC resources.
BSC's research lines are developed within the framework of
European Union research funding programmes, and the centre
also does basic and applied research in collaboration with
companies like IBM, Microsoft, Intel, Nvidia, Repsol, and Iberdrola.
3
�
5 . TPC-DS Benchmark Work
The BSC collaborated with Databricks to benchmark
comparisons on large-scale analytics computations, using
the TPC-DS Toolkit v2.10.1rc3
The Transaction Processing Performance Council (TPC)
Benchmark DS (1) has the objective of evaluating decision
The TPC is a non-profit support systems, which process large volumes of data in
corporation focused on order to provide answers to real-world business questions.
developing data-centric Our results are not official TPC Benchmark DS results.
benchmark standards and
disseminating objective,
verifiable performance data to Databricks provided BSC an account and credits, which
the industry. BSC then independently used for the benchmarking study
with other analytics products on the market.
5
�
6 .Context and motivation
• Need to adopt data analytics in a cost-effective
manner
– SQL still very relevant
– Open-source based analytics platforms
– On-demand computing resources from the Cloud
• Evaluate Cloud-based SQL engines
#UnifiedDataAnalytics #SparkAISummit 6
�
7 .Systems Under Test (SUTs)
• Databricks Unified Analytics Platform
– Based on Apache Spark but with optimized
Databricks Runtime
– Notebooks for interactive development and
production Jobs
– JDBC and custom API access
– Delta storage layer supporting ACID transactions
#UnifiedDataAnalytics #SparkAISummit 7
�
8 .Systems Under Test (SUTs)
• AWS EMR Presto
– Distributed SQL engine created by Facebook
– Connectors non-relational and relational sources
– JDBC and CLI access
– Based on in-memory, pipelined parallel execution
• AWS EMR Spark
– Based on open-source Apache Spark
#UnifiedDataAnalytics #SparkAISummit 8
�
9 .Plan
• TPC Benchmark DS
• Hardware and software configuration
• Benchmarking infrastructure
• Benchmark results and their analysis
• Usability and developer productivity
• Conclusions
#UnifiedDataAnalytics #SparkAISummit 9
�
10 .TPC Benchmark DS
• Created around 2006 to evaluate decision
support systems
• Based on a retailer with several channels of
distribution
• Process large volumes of data to answer
real-world business questions
#UnifiedDataAnalytics #SparkAISummit 10
�
11 .TPC Benchmark DS
• Snowflake schema: fact tables associated
with multiple dimension tables
• Data produced by data generator
• 99 queries of various types
– reporting
– ad hoc
– iterative
– data mining
#UnifiedDataAnalytics #SparkAISummit 11
�
12 .#UnifiedDataAnalytics #SparkAISummit 12
�
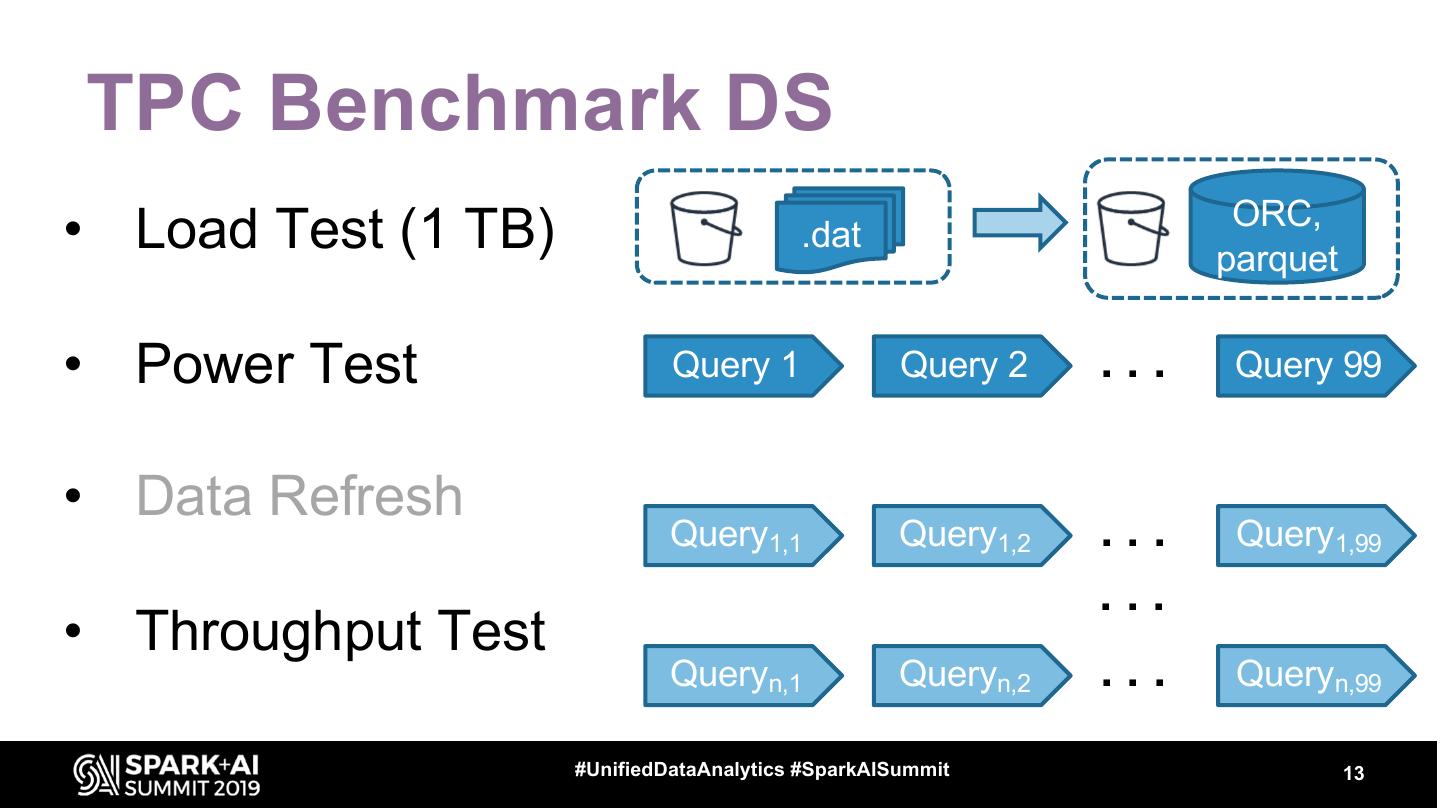
13 .TPC Benchmark DS
ORC,
• Load Test (1 TB) .dat
parquet
• Power Test Query 1 Query 2 ... Query 99
• Data Refresh
Query1,1 Query1,2 ... Query1,99
...
• Throughput Test
Queryn,1 Queryn,2 ... Queryn,99
#UnifiedDataAnalytics #SparkAISummit 13
�
14 .Hardware configuration
Type vCPUs Memory Local storage
i3.2xlarge 8 (2.3 GHz Intel 61 GiB 1 x 1,900 GB
Xeon E5 2686 v4) NVMe SSD
1 master node 8 worker nodes
#UnifiedDataAnalytics #SparkAISummit 14
�
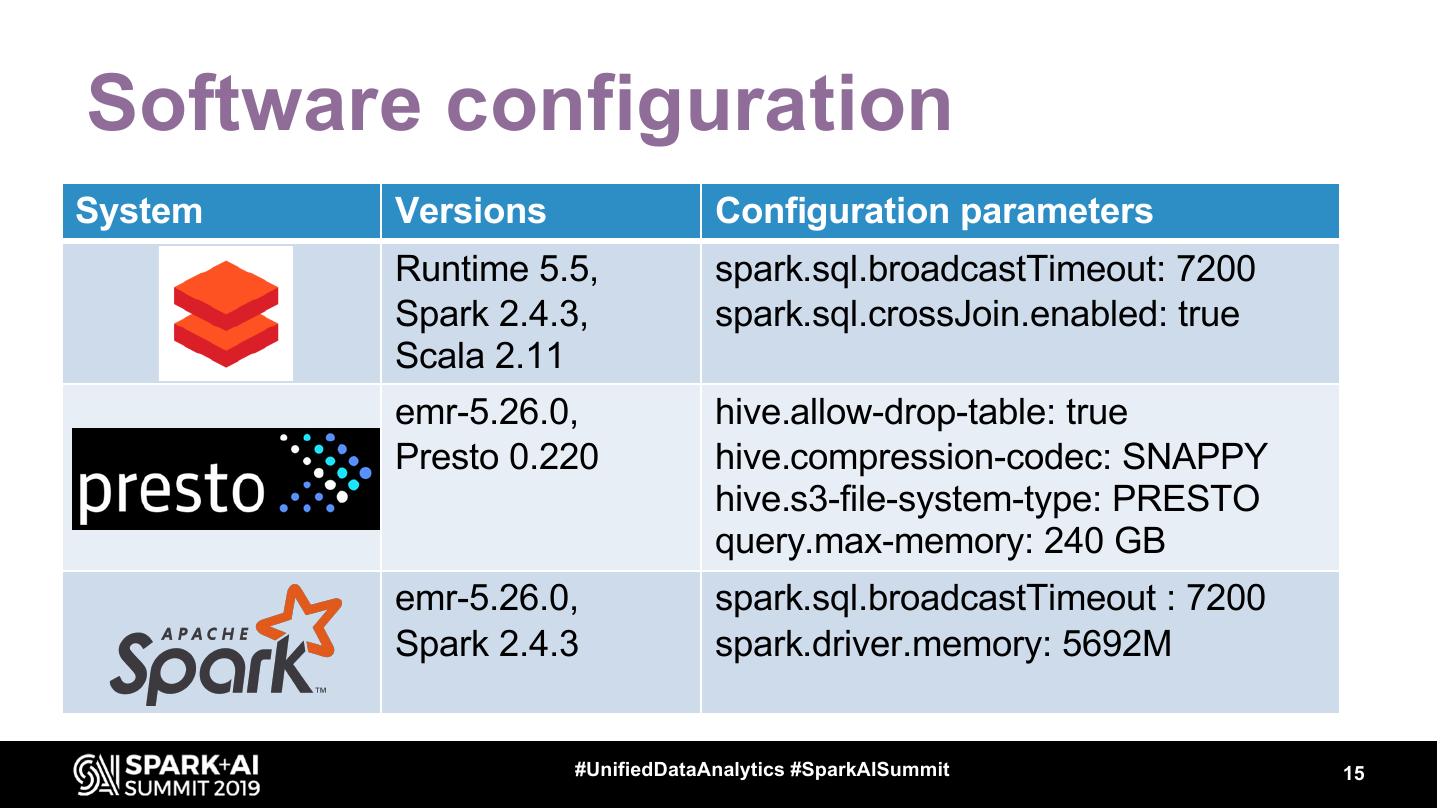
15 .Software configuration
System Versions Configuration parameters
Runtime 5.5, spark.sql.broadcastTimeout: 7200
Spark 2.4.3, spark.sql.crossJoin.enabled: true
Scala 2.11
emr-5.26.0, hive.allow-drop-table: true
Presto 0.220 hive.compression-codec: SNAPPY
hive.s3-file-system-type: PRESTO
query.max-memory: 240 GB
emr-5.26.0, spark.sql.broadcastTimeout : 7200
Spark 2.4.3 spark.driver.memory: 5692M
#UnifiedDataAnalytics #SparkAISummit 15
�
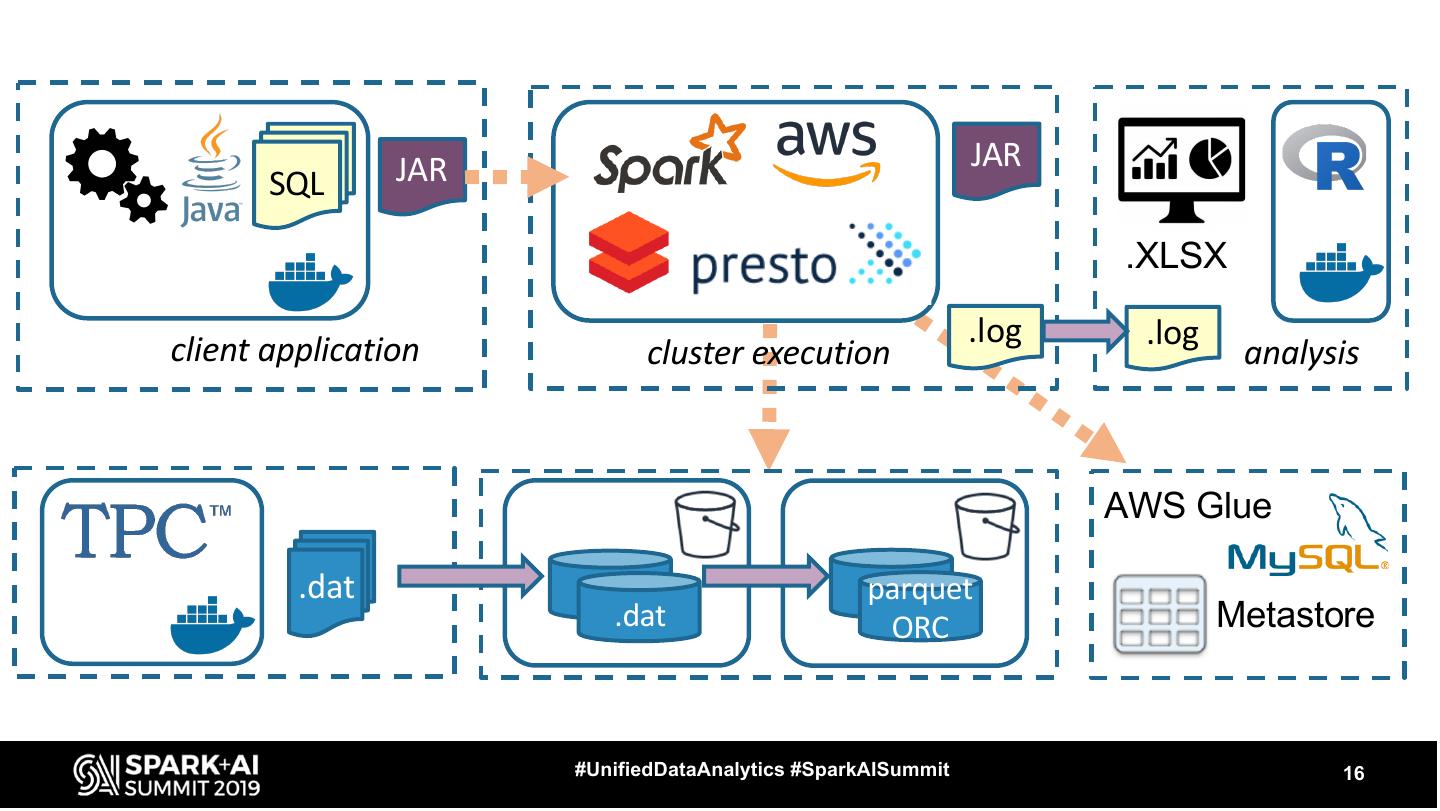
16 . JAR JAR
SQL
.XLSX
client application .log .log
cluster execution analysis
AWS Glue
.dat parquet
.dat ORC Metastore
#UnifiedDataAnalytics #SparkAISummit 16
�
17 .Benchmark execution time (base)
#UnifiedDataAnalytics #SparkAISummit 17
�
18 .Cost-Based Optimizer (CBO) stats
• Collect table and column-level statistics to
create optimized query evaluation plans
– distinct count, min, max, null count
#UnifiedDataAnalytics #SparkAISummit 18
�
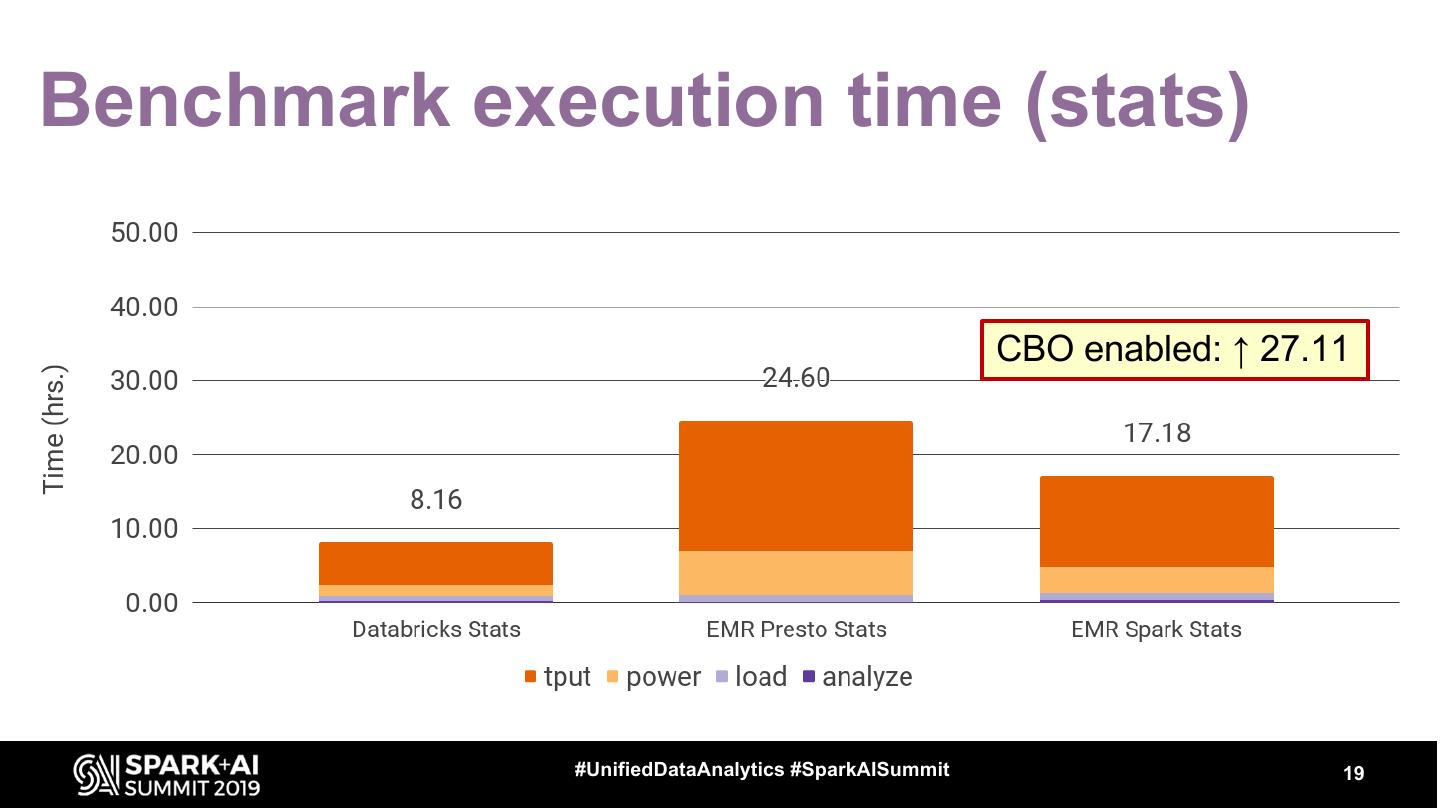
19 .Benchmark execution time (stats)
CBO enabled: ↑ 27.11
#UnifiedDataAnalytics #SparkAISummit 19
�
20 .Speedup with table and column stats
CBO enabled: ↓ 0.60
#UnifiedDataAnalytics #SparkAISummit 20
�
21 .TPC-DS Power Test – geom. mean
#UnifiedDataAnalytics #SparkAISummit 21
�
22 .TPC-DS Power Test – arith. mean
#UnifiedDataAnalytics #SparkAISummit 22
�
23 .Additional configuration for Presto
Query modifications (carried on to all systems)
72 manual join re-ordering
95 add distinct clause
Session configuration for all queries
query_max_stage_count: 102
join_reordering_strategy: AUTOMATIC
join_distribution_type: AUTOMATIC
Query-specific configuration parameters
5, 75, 78, and 80 join_distribution_type: PARTITIONED
78 and 85 join_reordering_strategy: NONE
67 task_concurrency: 32
18 join_reordering_strategy=ELIMINATE_CROSS_JOINS
#UnifiedDataAnalytics #SparkAISummit 23
�
24 .TPC-DS Power Test – Query 72
• Original benchmark join order
catalog_sales ⋈ inventory ⋈ warehouse ⋈ item ⋈ customer_demographics ⋈
household_demographics ⋈ date_dim ⋈ date_dim ⋈ date_dim ⟕ promotion ⟕ catalog_returns
• Manually modified join order
catalog_sales ⋈ date_dim ⋈ date_dim ⋈ inventory ⋈ date_dim ⋈ warehouse ⋈ item
⋈ customer_demographics ⋈ household_demographics ⟕ promotion ⟕ catalog_returns
• Databricks optimized join order no stats
Same as modified join order + pushed down selections and projections
#UnifiedDataAnalytics #SparkAISummit 24
�
25 . TPC-DS Power Test – Query 72
• Databricks optimized join order with stats
(((((((catalog_sales ⋈ household_demographics) ⋈ date_dim) ⋈ customer_demographics) ⋈ item)
⋈
(((date_dim ⋈ date_dim) ⋈ inventory) ⋈ warehouse))
⟕ promotion) ⟕ catalog_returns) +pushed down selections and projections
• EMR Spark optimized join order with stats
and CBO enabled/disabled
Same as modified join order + pushed down selections and projections
but different physical plans
#UnifiedDataAnalytics #SparkAISummit 25
�
26 . Dynamic data partitioning
• Splits a table based on the value of a particular
column
– Split only 7 largest tables by date surrogate keys
– One S3 bucket folder for each value
• Databricks and EMR Spark: limit number of files
per partition
• EMR Presto: out of memory error for largest table
– Use Hive with TEZ to load data
#UnifiedDataAnalytics #SparkAISummit 26
�
27 .Benchmark exec. time (part + stats)
Power Test: 2 failed queries
Throughput Test: 6 failed queries
#UnifiedDataAnalytics #SparkAISummit 27
�
28 .Speedup with partitioning and stats
#UnifiedDataAnalytics #SparkAISummit 28
�
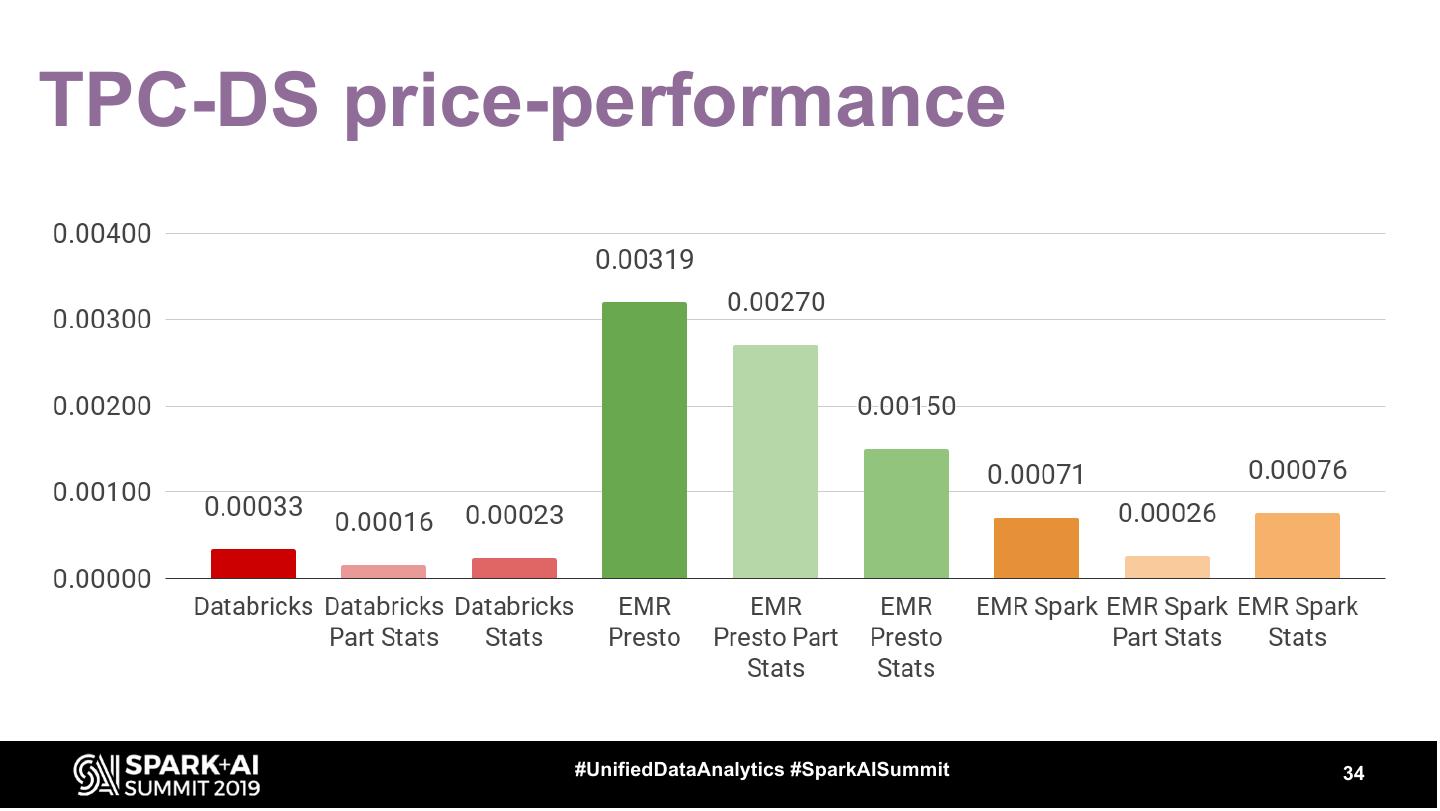
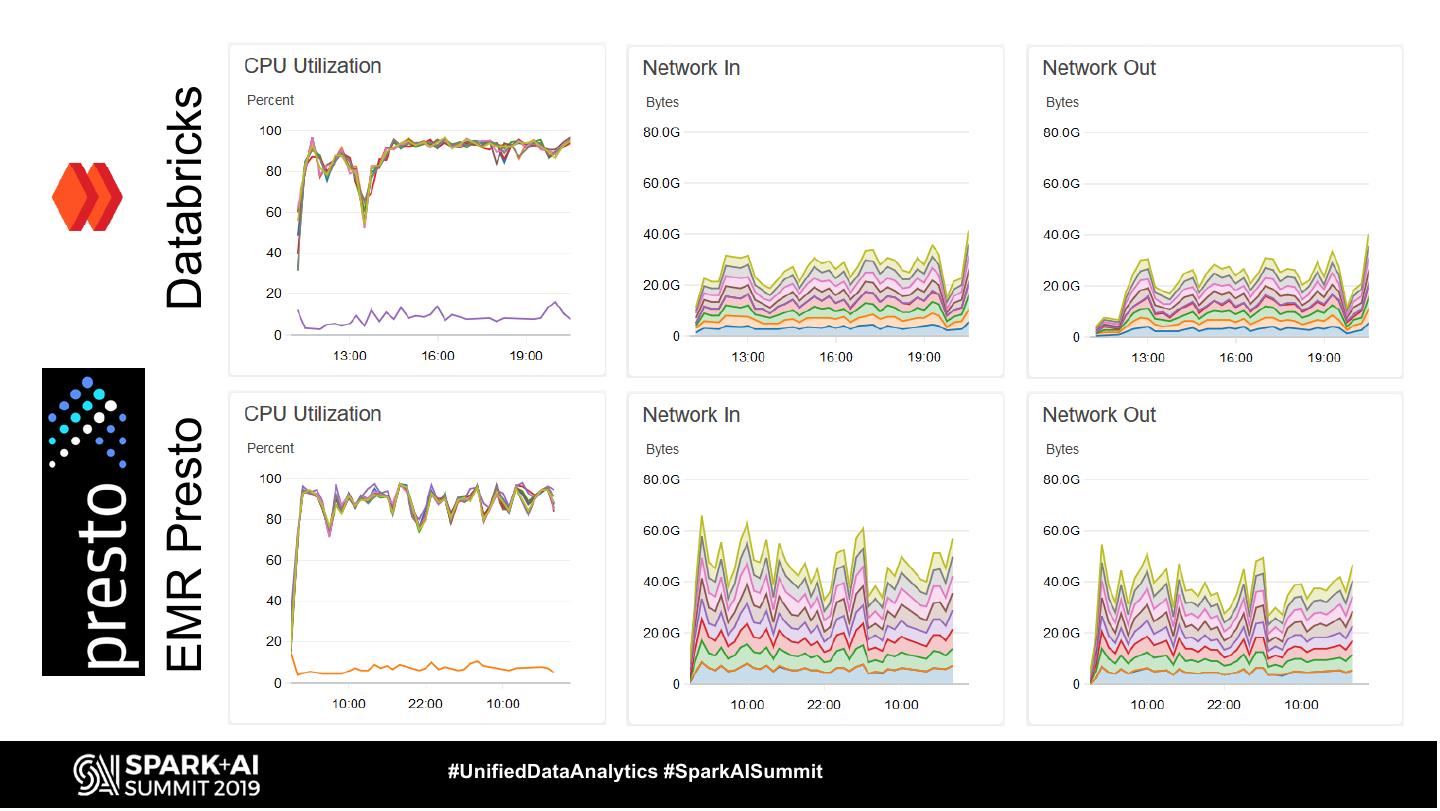
29 .TPC Benchmark total execution time
#UnifiedDataAnalytics #SparkAISummit 29
�