
































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
New Developments in Open Source Ecosystem: Apache Spark 3.0, Koalas, Delta Lake
Apache Spark 生态圈的2019年报告:Apache Spark 3.0, Delta Lake and Koalas
2019, Spark迎来了它第十个年头。本次演讲将着重介绍Spark生态圈的最新动向。我们首先介绍Spark 3.0预览版的众多特性。特别是,我们将深入讲解动态和静态的查询优化是如何让Spark更加容易使用并且快速执行。我们也将介绍Delta Lake这个最新的Spark data source是如何解决Spark的各种痛点。最后,我们还将demo最新的Koalas,看它是如何可以取代Pandas,来帮助科学家们更快地分析和洞察数据的。
展开查看详情
1 .New Developments in Open Source Ecosystem: Apache Spark 3.0, Koalas, Delta Lake 李 潇 (@gatorsmile) 2019-09-26 @ Hangzhou
2 .Dr. Matei Zaharia
3 . Spark 起源于加州伯克利分校 Spark 开源 Spark 原创团队成立 Databricks Spark 被捐赠给 Apache Foundation 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 Spark 成为 Apache 顶级项目 Spark 2.0 发布 Spark 3.0 10 Years
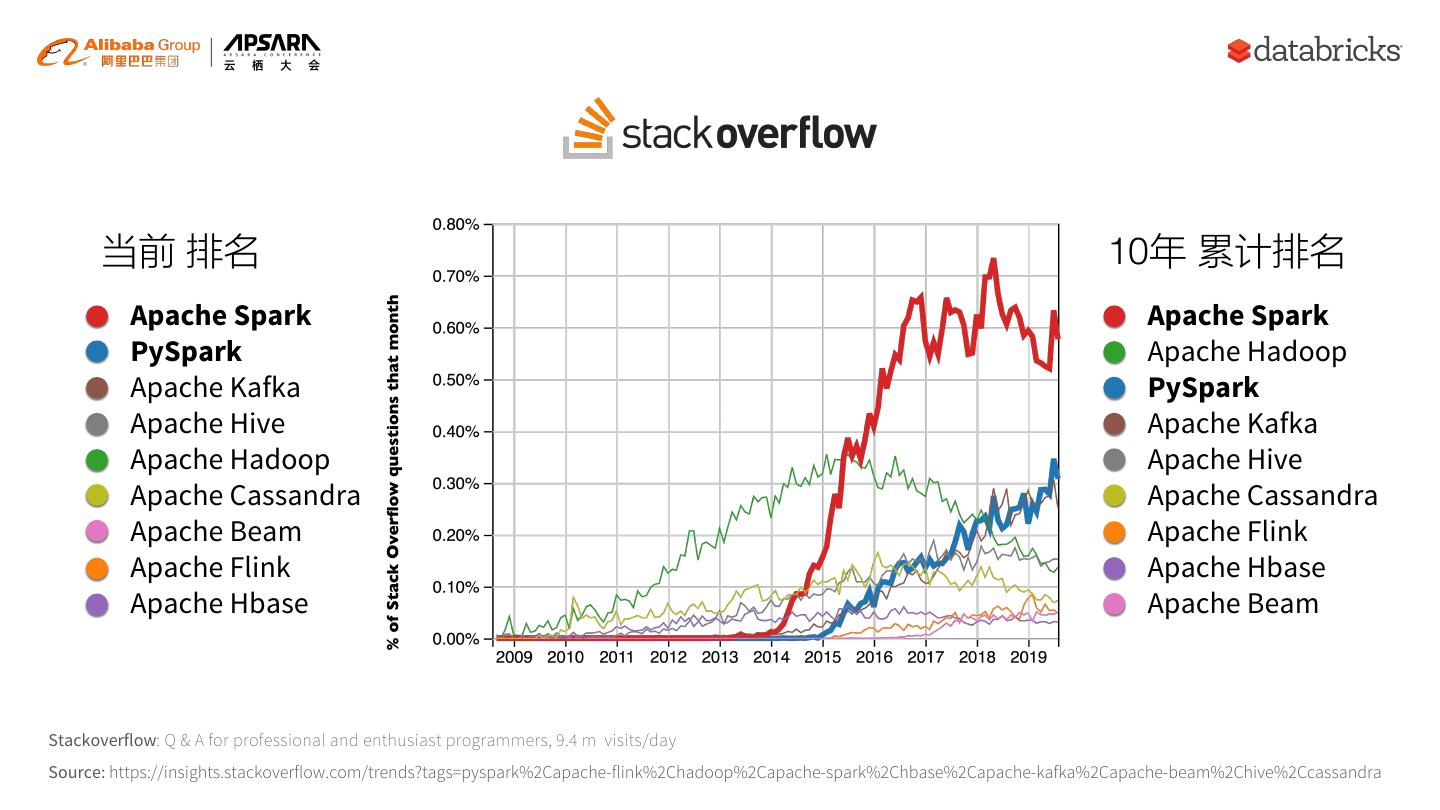
4 . 当前 排名 10年 累计排名 Apache Spark Apache Spark PySpark Apache Hadoop Apache Kafka PySpark Apache Hive Apache Kafka Apache Hadoop Apache Hive Apache Cassandra Apache Cassandra Apache Beam Apache Flink Apache Flink Apache Hbase Apache Hbase Apache Beam Stackoverflow: Q & A for professional and enthusiast programmers, 9.4 m visits/day Source: https://insights.stackoverflow.com/trends?tags=pyspark%2Capache-flink%2Chadoop%2Capache-spark%2Chbase%2Capache-kafka%2Capache-beam%2Chive%2Ccassandra
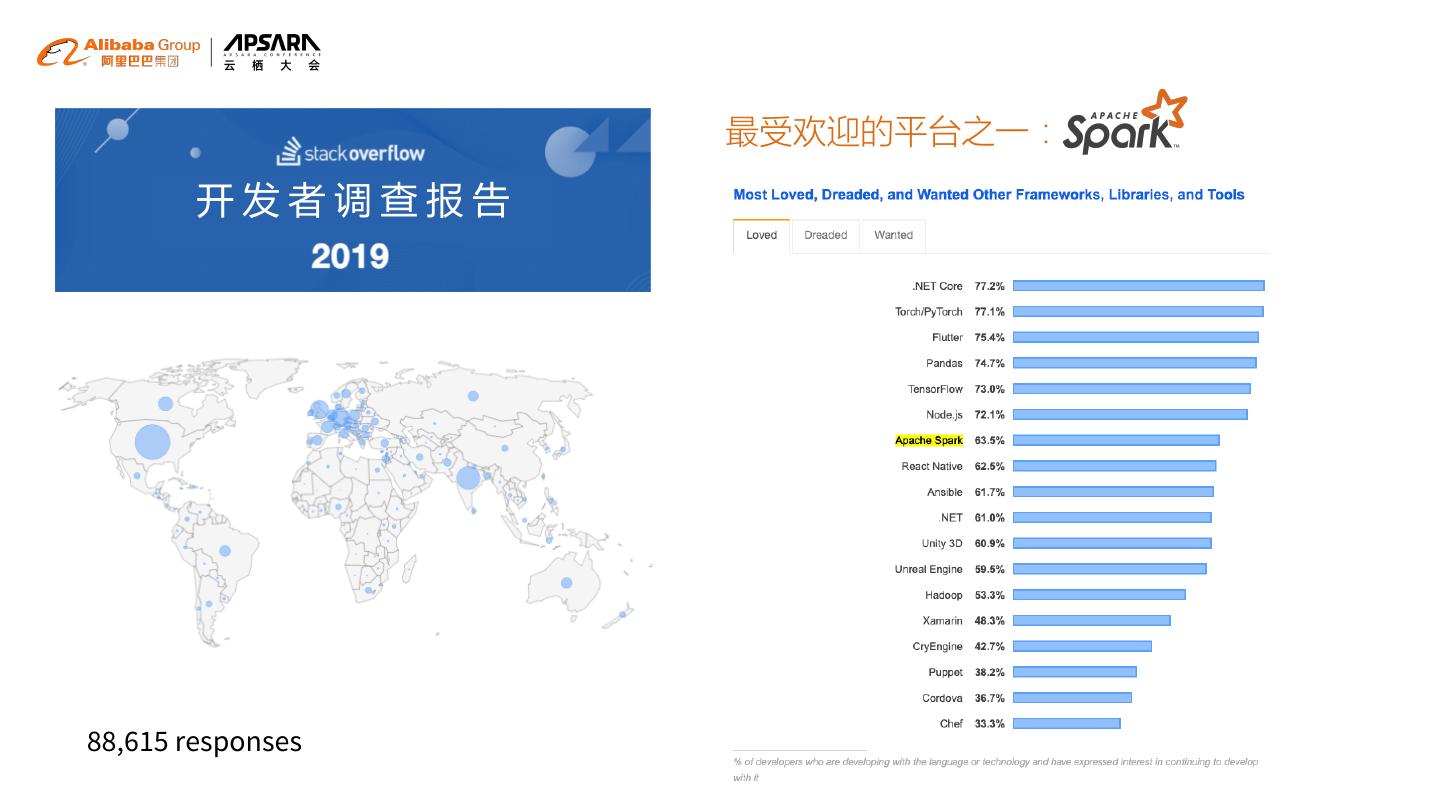
5 . 最受欢迎的平台之一: 开发者调查报告 88,615 responses
6 .3.0
7 . Will resolve 2000+ JIRAs Dynamic Partition Adaptive Query Spark Graph Accelerator-aware Spark on Data Source API with Pruning Execution Scheduling Kubernetes Catalog Supports ANSI SQL SQL Hints Vectorization in JDK 11 Hadoop 3 Scala 2.12 Compliance SparkR
8 . Query Optimization in Spark 2.X Missing Statistics (一次性计算 ETL workloads) Out-of-date Statistics (存储与计算分离) Misestimated Costs (多样部署环境 + UDFs)
9 . Query Optimization Spark 1.x, Rule Spark 2.x, Rule + Cost Spark 3.0, Rule + Cost + Runtime
10 .Dynamic Partition Pruning Project SELECT t1.id, t2.pKey FROM t1 Join t1.pKey = t2.pKey JOIN t2 ON t1.pKey = t2.pKey Filter t2.id < 2 AND t2.id < 2 Scan Scan t2: a dimension t1: a large fact table table with a filter with many partitions
11 .Dynamic Partition Pruning Project SELECT t1.id, t2.pKey FROM t1 Join t1.pKey = t2.pKey JOIN t2 t1.pkey IN ( Filter SELECT t2.pKey ON t1.pKey = t2.pKey FROM t2 AND t2.id < 2 t2.id < 2 WHERE t2.id < 2) Filter + Scan Scan Filter pushdown Scan all the partitions
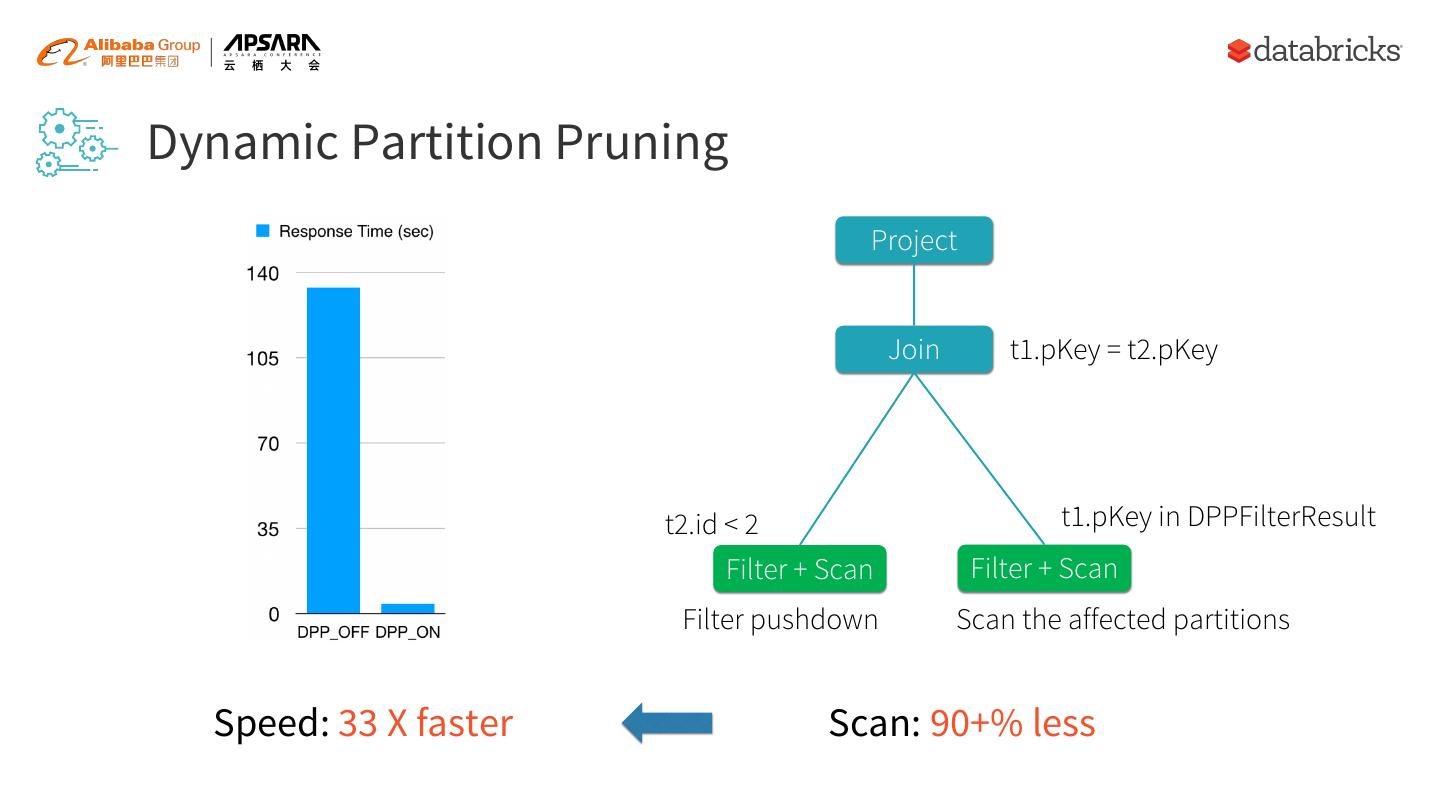
12 .Dynamic Partition Pruning Project Join t1.pKey = t2.pKey t2.id < 2 t1.pKey in DPPFilterResult Filter + Scan Filter + Scan Filter pushdown Scan the affected partitions Speed: 33 X faster Scan: 90+% less
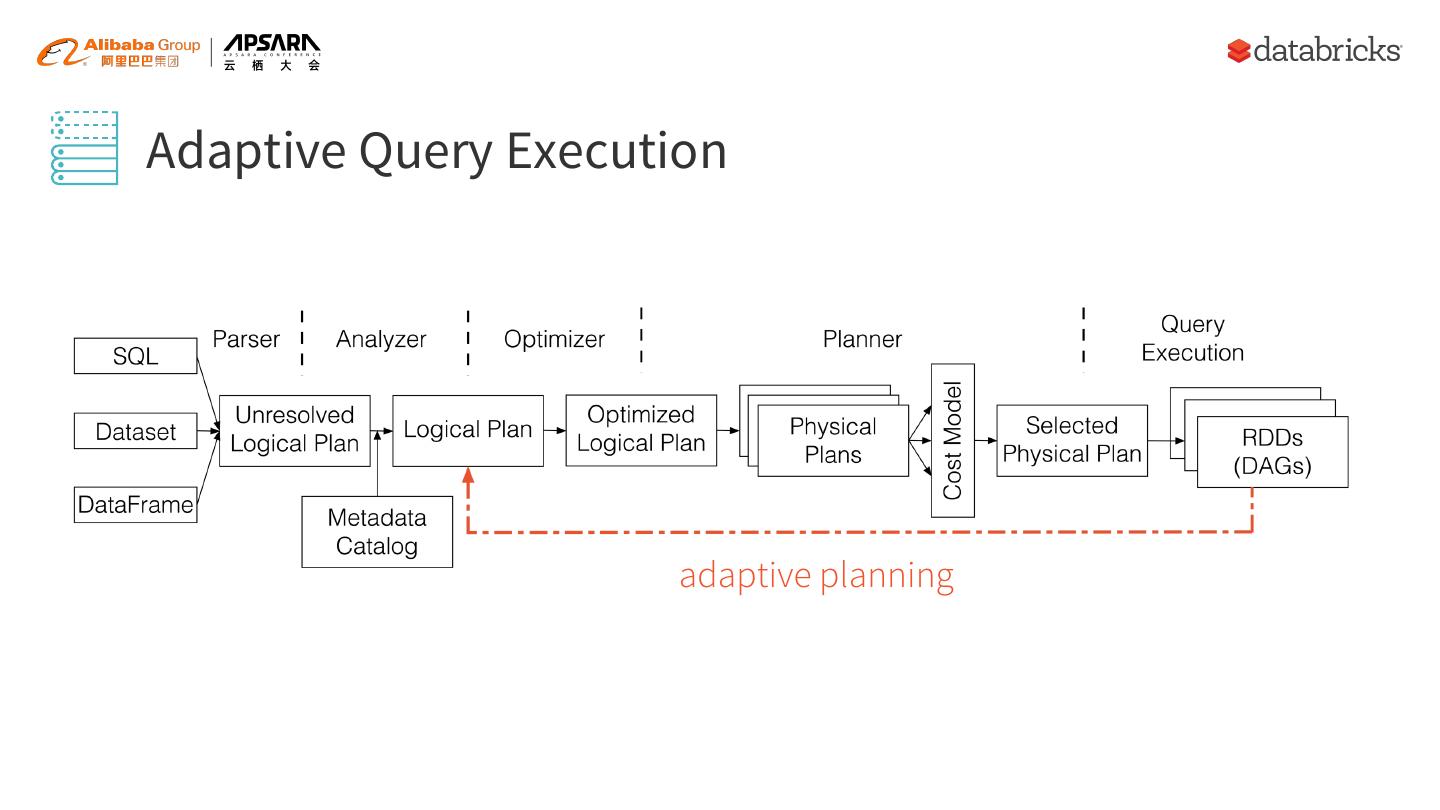
13 .Adaptive Query Execution adaptive planning
14 . Adaptive Query Execution SELECT * SortMergeJoin t1.key = t2.key FROM t1 Sort Sort JOIN t2 ON t1.key = t2.key Exchange Exchange AND t2.col2 LIKE '9999%' t2.col2 LIKE Scan Filter + Scan ‘9999%’ QueryStrage1 QueryStrage0
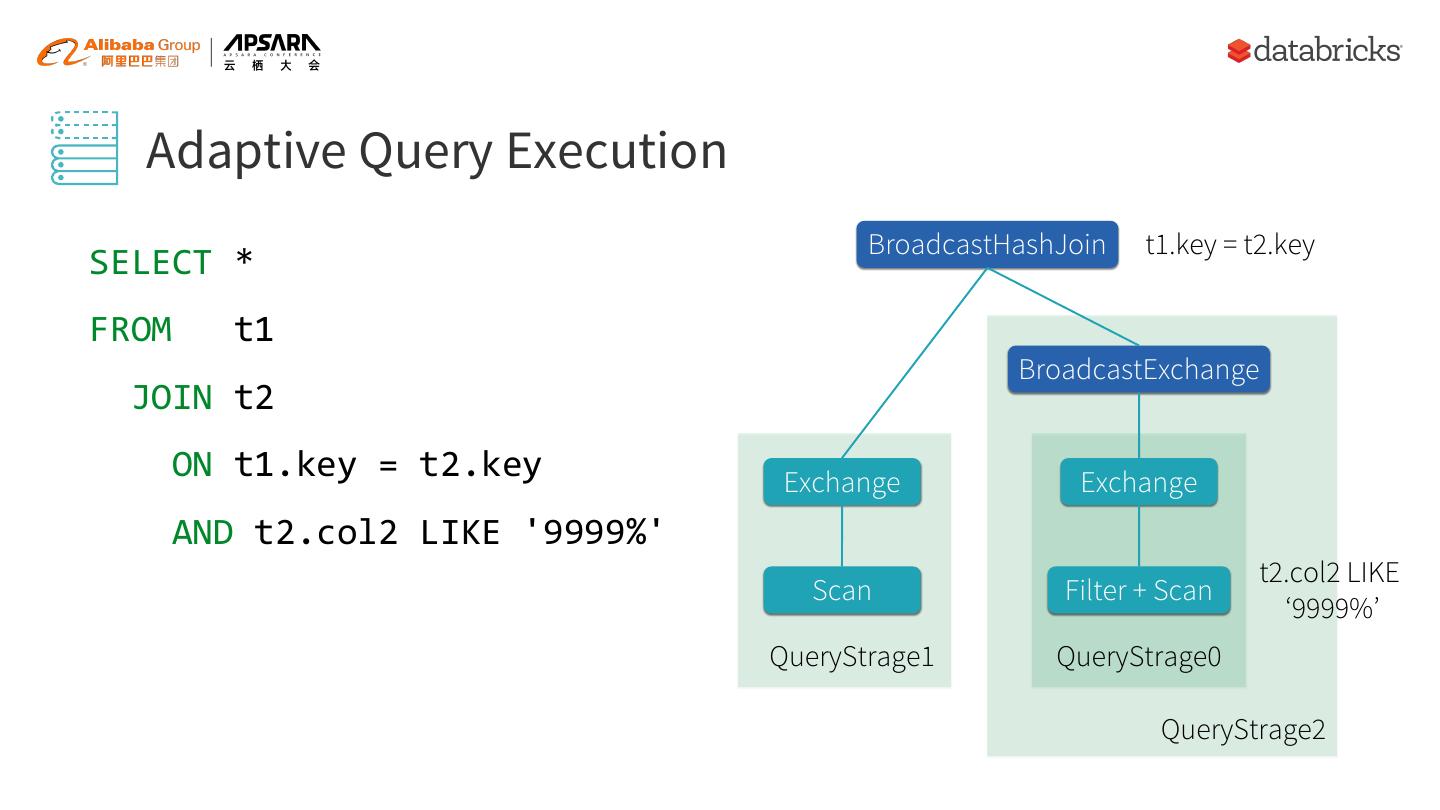
15 . Adaptive Query Execution BroadcastHashJoin t1.key = t2.key SELECT * FROM t1 BroadcastExchange JOIN t2 ON t1.key = t2.key Exchange Exchange AND t2.col2 LIKE '9999%' t2.col2 LIKE Scan Filter + Scan ‘9999%’ QueryStrage1 QueryStrage0 QueryStrage2
16 .生态
17 .Dr. Ion Stoica & Dr. Matei Zaharia
18 . BUSINESS INTELLIGENCE BIG DATA ANALYTICS UNIFYING DATA + AI Autonomous Decisions Advanced ML / AI - Make the Predictive Analytics decision for me Proactive Analytics - Predict what’s going to happen Spark as a unifying technology - Data Warehouses Data processing at scale + Reactive Analytics - What just analytics + AI happened? 18
19 .数据工程 数据科学
20 . Accelerate innovation by unifying data science and engineering 数据工程 数据科学
21 .数据科学
22 .Traffic for major programming languages Image source: Stack Overflow
23 .koalas PySpark koalas Image source: pypistats.org
24 . pandas PySpark DataFrame DataFrame Column df['col'] df['col'] Mutability Mutable Immutable Add a df['c'] = df['a'] + df['b'] df.withColumn('c', df['a'] + df['b']) column Rename df.columns = ['a','b'] df.select(df['c1'].alias('a'), df['c2'].alias('b')) columns Value df.groupBy(df['col']).count() df['col'].value_counts() count .orderBy('count', ascending = False)
25 . pandas PySpark import pandas as pd df = (spark.read df = pd.read_csv("my_data.csv") .option("inferSchema", "true") df.columns = ['x', 'y', 'z1'] .option("comment", True) .csv("my_data.csv")) df['x2'] = df.x * df.x df = df.toDF('x', 'y', 'z1') df = df.withColumn('x2', df.x*df.x)
26 .import pandas as pd import databricks.koalas as ks df = pd.read_csv("my_data.csv") df = ks.read_csv("my_data.csv") df.columns = ['x', 'y', 'z1'] df.columns = ['x', 'y', 'z1'] df['x2'] = df.x * df.x df['x2'] = df.x * df.x
27 .数据工程
28 .A New Standard for Building Data Lakes Open Format Based on Parquet With Transactions Apache Spark™ APIs
29 .Instead of parquet … … simply say delta dataframe dataframe .write .write .format("parquet") .format("delta") .save("/data") .save("/data")
3秒后跳转登录页面
去登陆

