展开查看详情
1 .MONITORING OF GPU USAGE
WITH TENSORFLOW MODEL TRAINING USING PROMETHEUS
Diane Feddema, Principal Software Engineer
Zak Hassan, Senior Software Engineer
#RED_HAT #AICOE #CTO_OFFICE
�
2 .YOUR SPEAKERS
DIANE FEDDEMA
PRINCIPAL SOFTWARE ENGINEER - ARTIFICIAL INTELLIGENCE CENTER OF EXCELLENCE, CTO OFFICE
● Currently focused on developing and applying Data Science and Machine Learning techniques for performance
analysis, automating these analyses and displaying data in novel ways.
● Previously worked as a performance engineer at the National Center for Atmospheric Research, NCAR, working on
optimizations and tuning in parallel global climate models.
ZAK HASSAN
SENIOR SOFTWARE ENGINEER - ARTIFICIAL INTELLIGENCE CENTER OF EXCELLENCE, CTO OFFICE
● Leading the log anomaly detection project within the aiops team and building a user feedback service for improved
accuracy of machine learning predictions.
● Developing data science apps and working on improved observability of machine learning systems such as spark and
tensorflow.
#RED_HAT #AICOE #CTO_OFFICE
�
3 .Outline
● Story
● Concepts
○ Comparing CPU vs GPU
○ What Is Cuda and anatomy of cuda on kubernetes
○ Monitoring GPU and custom metrics with pushgateway
○ TF with Prometheus integration
○ What is Tensorflow and Pytorch
○ A Pytorch example from MLPerf
○ Tensorflow Tracing
● Examples:
○ Running Jupyter (CPU, GPU, targeting specific gpu type)
○ Mounting Training data into notebook/tf job
○ Uses of Nvidia-smi
● Demo
○ Running Detectron on a Tesla V100 with Prometheus & Grafana
monitoring
�
4 . “Design the factory like you
would design an advanced
computer… In fact use
engineers that are used to doing
that and have them work on
this.”
-- Elon Musk (2016)
https://youtu.be/f9uveu-c5us
Source: https://flic.kr/p/chEftd
�
5 .WHY IS DEEP LEARNING A BIG
DEAL ?
Online Automotive Mobile
• Netflix.com • self driving • unlocking
phones
• Amazon.com • voice assistant
• Targeted ads
�
6 .Source: https://bit.ly/2I8zIcs
�
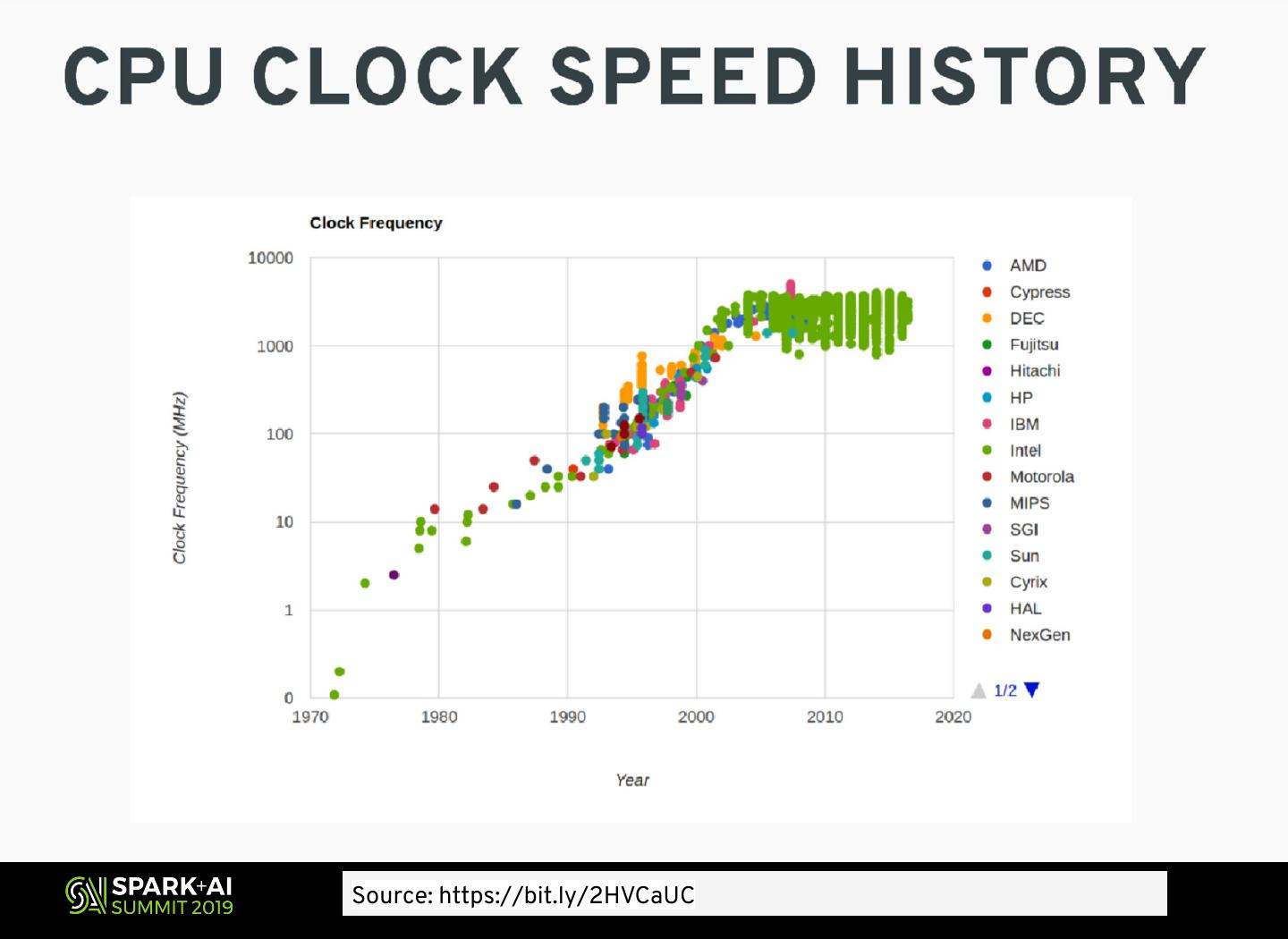
7 .Source: https://bit.ly/2HVCaUC
�
8 .PARALLEL PROCESSING
MOST LANGUAGES
SUPPORT CPU
● MODERN HARDWARE SUPPORT ARITHMETRIC
LOGIC UNIT
EXECUTION OF PARALLEL
PROCESSES/THREADS AND HAVE APIS INSTRUCTION CONTROL DATA
MEMORY UNIT
TO SPAWN PROCESSES IN PARALLEL MEMORY
● YOUR ONLY LIMITS IS HOW MANY CPU
CORES YOU HAVE ON YOUR MACHINE
● CPU USED TO BE A KEY COMPONENT OF
HPC Input/Output
● GPU HAS DIFFERENT ARCHITECTURE &
# OF CORES
�
12 .Hardware accelerators
● GPU
○ CUDA
○ OpenCL
● TPU
�
13 .Performance Goals
Latency Bandwidth Throughput
Decreased Increased Increased
�
15 .WHAT IS CUDA?
PROPRIETARY TOOLING
● hardware/software for HPC
● prerequisite is that you have nvidia cuda supported graphics cards
● ML frameworks like tensorflow, theanos, pytorch utilize cuda for leveraging
hardware acceleration
● You may get a 10x faster performance for machine learning jobs by utilizing
cuda
�
16 .ANATOMY OF A CUDA TENSORFLOW JUPYTER
WORKLOAD ON K8S
CUDA LIBS
CONTAINER
CONTAINER RUNTIME
NVIDIA LIBS /dev/nvidaX
HOST OS
HARDWARE
SERVER GPU
�
17 .Cli monitoring tool
Nvidia-Smi
● Tool used to display
usage metrics on
what is running on
your gpu.
�
18 .TFJob + Prometheus
GPU NODE PUSH
PULL TENSORFLOW
EXPLORER GATEWAY
JOBS
PUSH
NOTIFICATION
PROMETHEUS
EMAIL
MESSAGING TRAINING
ALERT DATA
MANAGER
WEBHOOK
�
19 .Idle GPU Alert
groups:
● Alert Manager can - name: nvidia_gpu.rules
notify: rules:
○ slack chat notification - alert: UnusedResources
expr: nvidia_gpu_duty_cycle == 0
○ email for: 10m
○ web hook labels:
○ more severity: critical
● Get notified when your annotations:
description: GPU is not being utilized you
GPU isn’t being utilized should scale down your gpu node
summary: GPU Node isn't being utilized
and shut down your
VM’s in the cloud to
save on cost.
�
23 .Jupyter +TF on CPU
apiVersion: v1
kind: Pod
metadata:
name: jupyter-tf-gpu
spec:
restartPolicy: OnFailure
containers:
- name: jupyter-tf-gpu
image: "quay.io/zmhassan/fedora28:tensorflow-cpu-2.0.0-alpha0"
�
24 .Jupyter+TF on GPU
apiVersion: v1
kind: Pod
metadata:
name: jupyter-tf-gpu
spec:
restartPolicy: OnFailure
containers:
- name: jupyter-tf-gpu
image: "tensorflow/tensorflow:nightly-gpu-py3-jupyter"
resources:
limits:
nvidia.com/gpu: 1
�
25 .Specific GPU Node Target
apiVersion: v1
kind: Pod
metadata:
name: jupyter-tf-gpu
spec:
containers:
- name: jupyter-tf-gpu
image: "tensorflow/tensorflow:nightly-gpu-py3-jupyter"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
accelerator: nvidia-tesla-v100
�
26 .Relabel kubernetes node
kubectl label node <node_name> \
accelerator=nvidia-tesla-k80
# or
kubectl label node <node_name> \
accelerator=nvidia-tesla-v100
�
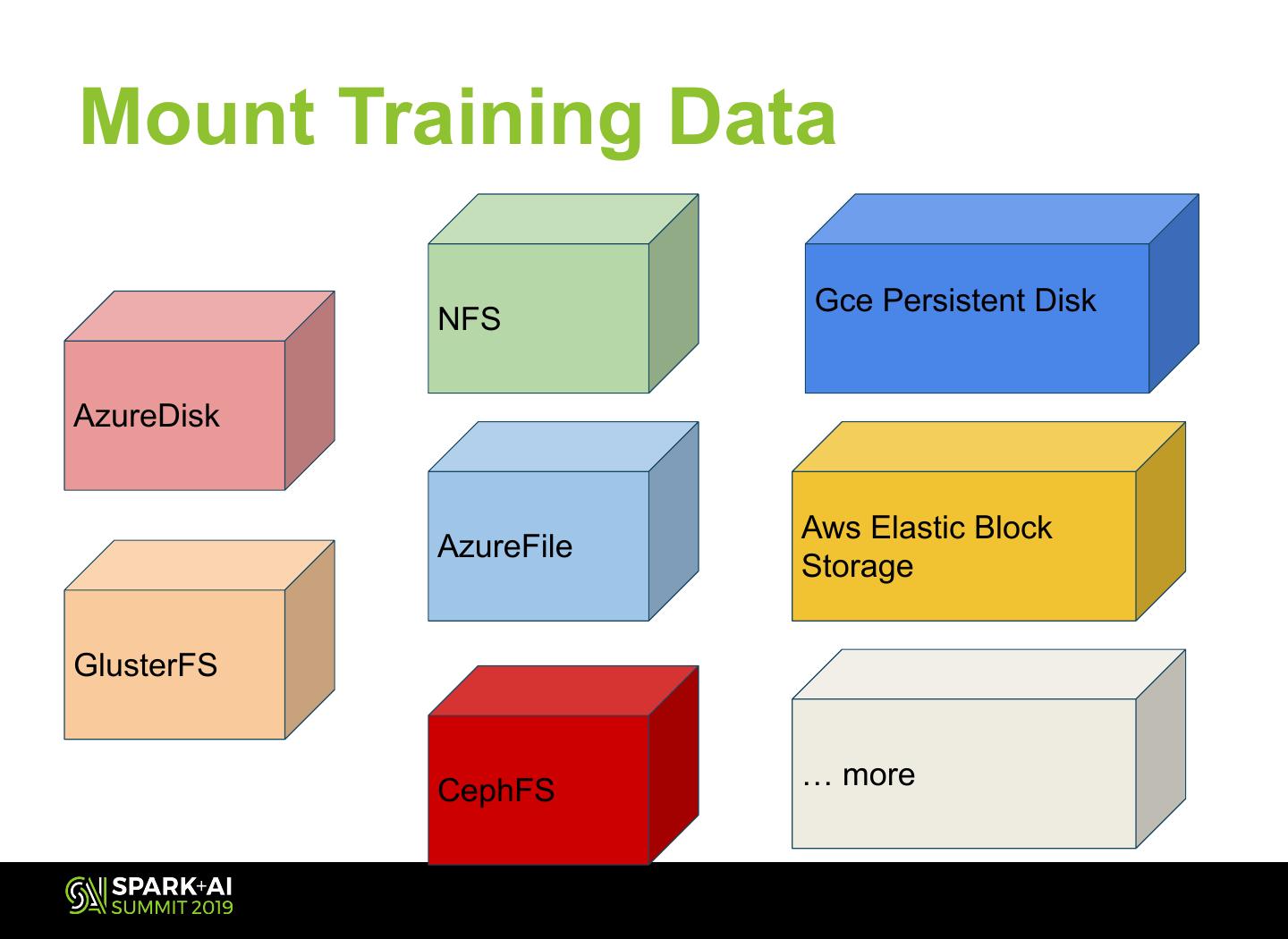
27 .Mount Training Data
Gce Persistent Disk
NFS
AzureDisk
Aws Elastic Block
AzureFile
Storage
GlusterFS
… more
CephFS
�
28 .Persistent Volume Claim
● Native k8s resource kind: PersistentVolumeClaim
apiVersion: v1
● lets you access pv
metadata:
● can be used to share name: nfs
data cross different spec:
pods. accessModes:
- ReadWriteMany
storageClassName: ""
resources:
requests:
storage: 100Gi
�
29 .Persistent Volume
● native k8s resource apiVersion: v1
kind: PersistentVolume
● can be readonly,
metadata:
readWriteOnce or name: nfs
readwritemany spec:
capacity:
storage: 100Gi
accessModes:
- ReadWriteMany
nfs:
server: 0.0.0.0
path: "/"
�