展开查看详情
1 .What’s Next for in 2019
Matei Zaharia, Corey Zumar, Sid Murching
February 12, 2019
�
2 .Outline
MLflow overview
Feedback so far
Databricks’ development themes for 2019
Demos of upcoming features
�
3 .Outline
MLflow overview
Feedback so far
Databricks’ development themes for 2019
Demos of upcoming features
�
4 . ML Development is Harder than
Traditional Software Development
�
5 .Traditional Software Machine Learning
Goal: meet a functional specification Goal: optimize a metric (e.g. accuracy)
5
�
6 .Traditional Software Machine Learning
Goal: meet a functional specification Goal: optimize a metric (e.g. accuracy)
Quality depends only on code Quality depends on data, code & tuning
→ Must regularly update with fresh data
6
�
7 .Traditional Software Machine Learning
Goal: meet a functional specification Goal: optimize a metric (e.g. accuracy)
Quality depends only on code Quality depends on data, code & tuning
→ Must regularly update with fresh data
Typically one software stack Constantly experiment w/ new libraries +
models (and must productionize them!)
7
�
8 .What is ?
Open source platform to manage ML development
• Lightweight APIs & abstractions that work with any ML library
• Designed to be useful for 1 user or 1000+ person orgs
• Runs the same way anywhere (e.g. any cloud)
Key principle: “open interface” APIs that work with any
existing ML library, app, deployment tool, etc
�
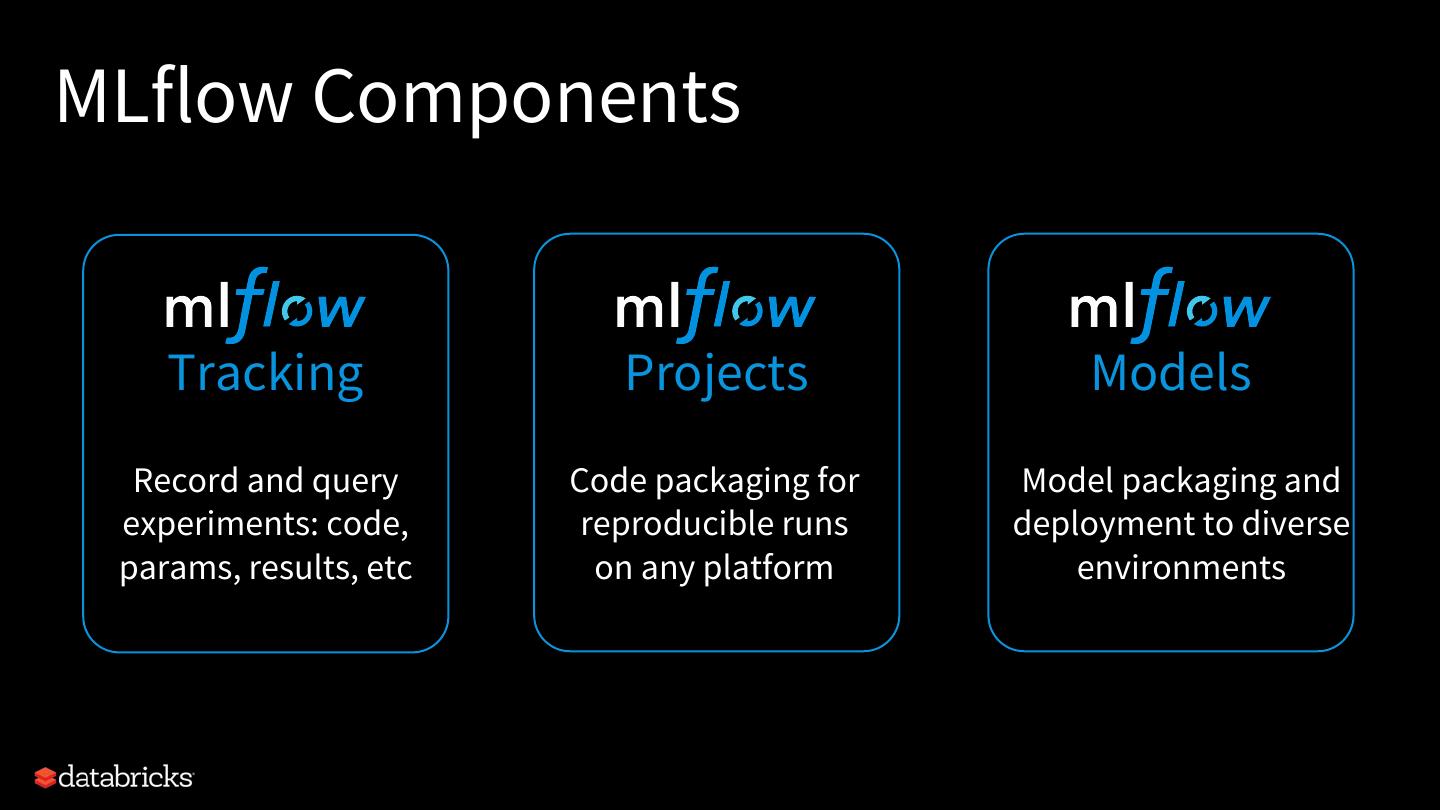
9 .MLflow Components
Tracking Projects Models
Record and query Code packaging for Model packaging and
experiments: code, reproducible runs deployment to diverse
params, results, etc on any platform environments
9
�
10 .Learning
pip install mlflow to get started in Python
(APIs also available in Java and R)
Docs and tutorials at mlflow.org
• Hyperparameter tuning, REST serving, batch scoring, etc
�
11 .Outline
MLflow overview
Feedback so far
Databricks’ development themes for 2019
Demos of upcoming features
�
12 .Running a user survey at mlflow.org (fill it in if you haven’t!)
�
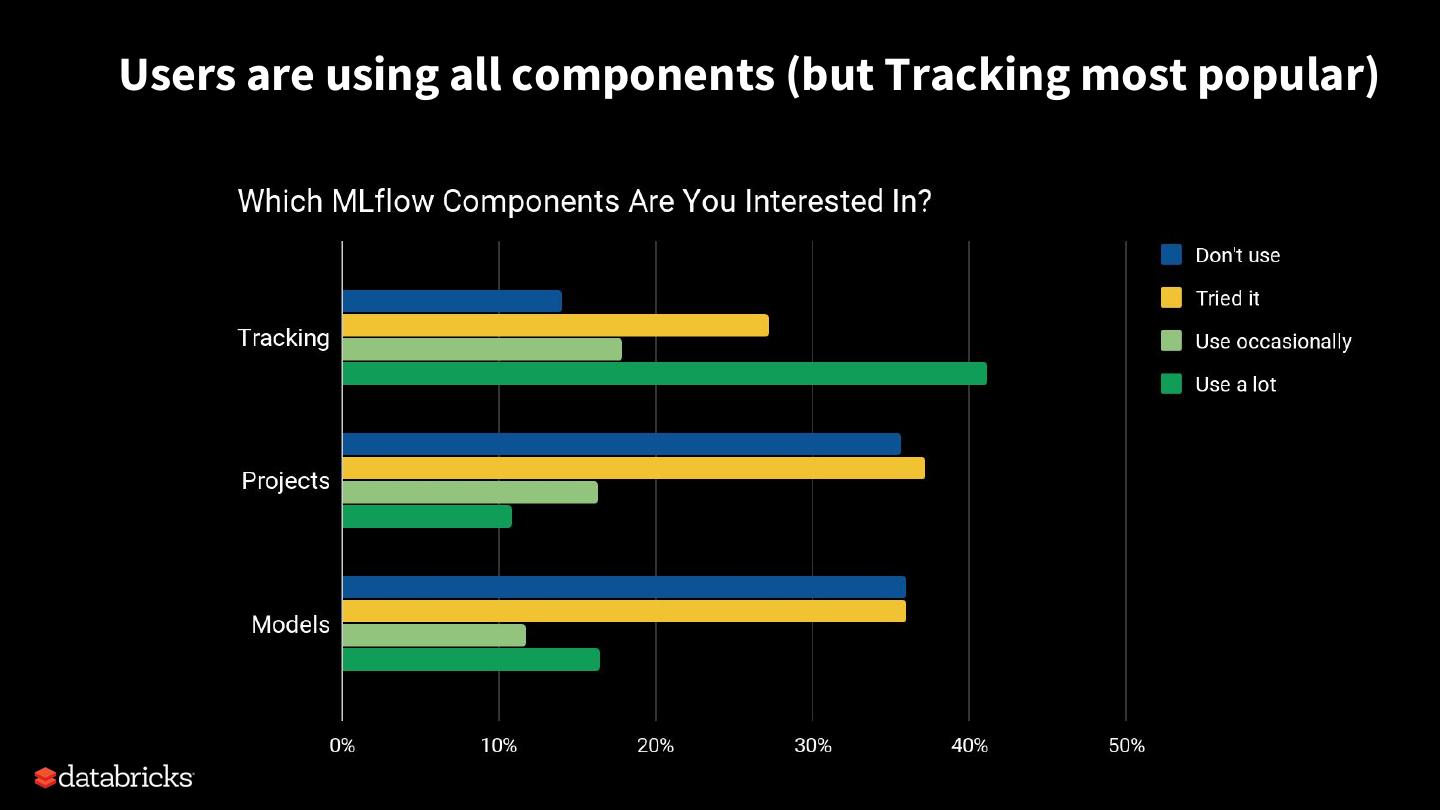
13 .Users are using all components (but Tracking most popular)
�
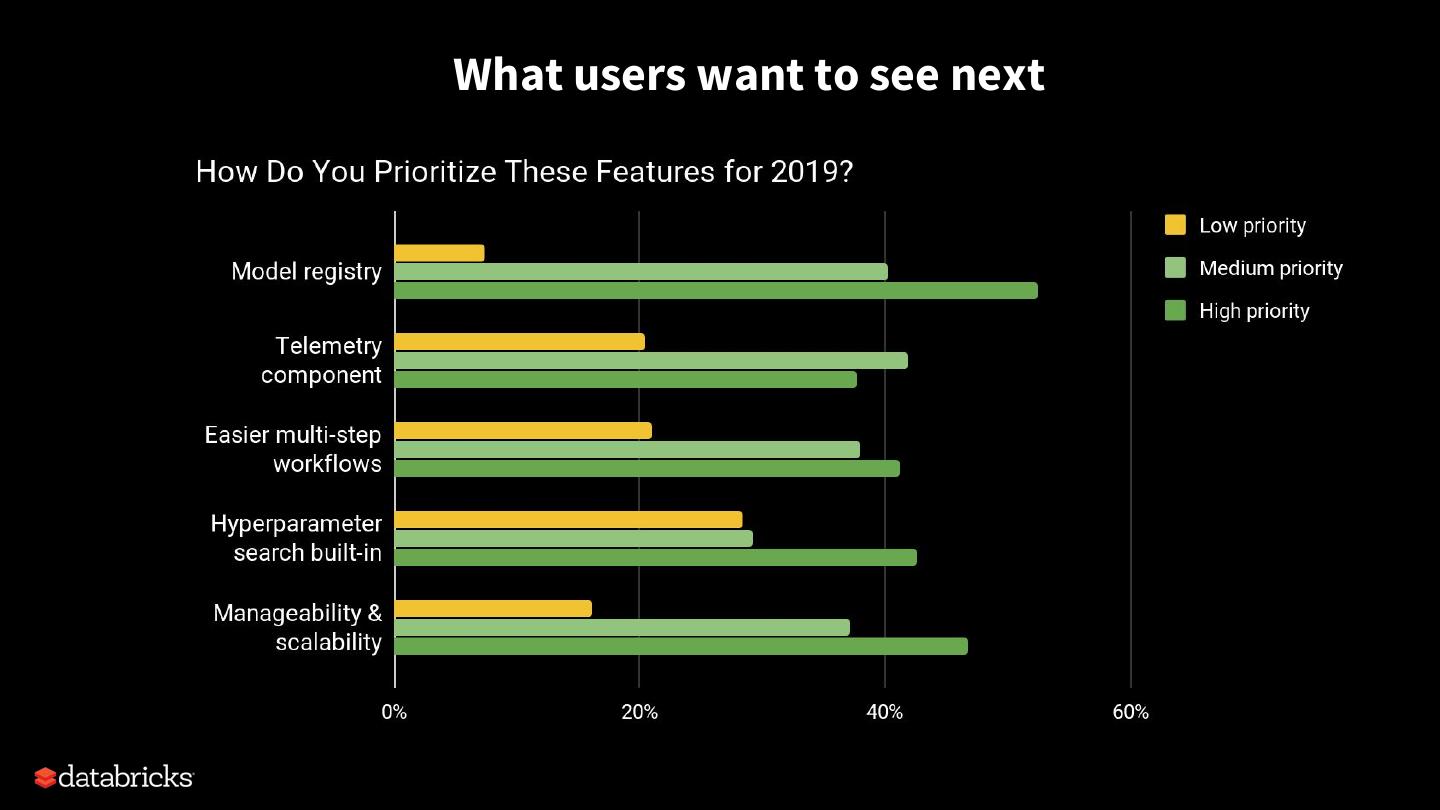
14 .What users want to see next
�
15 .Outline
MLflow overview
Feedback so far
Databricks’ development themes for 2019
Demos of upcoming features
�
16 .High-Level Themes
1) Update existing components based on feedback
2) Stabilize the APIs and dev process (MLflow 1.0)
3) Add new features for more of the ML lifecycle
�
17 .Rough Development Timeline
MLflow 0.9, 0.10, etc: in the next few months
MLflow 1.0 and API stabilization: end of April
(stabilize core APIs and mark others as experimental)
After 1.0: continue releasing regularly to get features out
�
18 .Updating Existing Components
MLflow Tracking
• SQL database backend for scaling the tracking server (0.9)
• UI scalability improvements (0.8, 0.9, etc)
• X-coordinate logging for metrics & batched logging (1.0)
• Fluent API for Java and Scala (1.0)
�
19 .Updating Existing Components
MLflow Projects
• Docker-based project environment specification (0.9)
• X-coordinate logging for metrics & batched logging (1.0)
• Packaging projects with build steps (1.0+)
�
20 .Updating Existing Components
MLflow Models
• Custom model logging in Python, R and Java (0.8, 0.9, 1.0)
• Better environment isolation when loading models (1.0)
• Logging schema of models (1.0+)
�
21 .New Components in Discussion
Model registry
• A way to name and manage models, track deployments, etc
• Could be new abstraction or tags on existing runs (need feedback!)
Multi-step workflow GUI
• UI to view or even edit multi-step workflows (do you want this?)
MLflow telemetry component
• Standard API for deployed models to log metrics wherever they run
• Data collection and analytics tools downstream (need feedback!)
�
22 .Outline
MLflow overview
Feedback so far
Databricks’ development themes for 2019
Demos of upcoming features
�
23 .Demo: Model Customization
Motivating example: MLflow flower classification
f(petal_attribs) -> classification
f(petal_attribs) -> probabilities
23
�
24 .Demo: Model Customization
Motivation: ML teams want to capture
mathematical models and business logic in a single
MLflow model.
mlflow.sklearn.save_model,
mlflow.pytorch.log_model,
….
24
�
25 .Demo: Model Customization
MLflow 0.9: Users can easily customize models,
introducing inference logic and data dependencies
25
�
26 .class PythonModel:
def load_context(self, context):
# The context object contains paths to
# files (artifacts) that can be loaded here
def predict(self, context, input_df):
# Inference logic goes here
26
�
27 .class ToyModel(mlflow.pyfunc.PythonModel):
def __init__(self, return_value):
self.return_value = return_value
def predict(self, context, input_df):
return self.return_value
mlflow.pyfunc.save_model(
python_model=ToyModel(pd.DataFrame([42])),
dst_path="toy_model")
27
�
28 .class ProbaModel(mlflow.pyfunc.PythonModel):
def predict(self, context, input_df):
sk_model = mlflow.sklearn.load_model(
context.artifacts["sk_model"])
return sk_model.predict_proba(input_df)
mlflow.pyfunc.save_model(
dst_path="proba_model",
python_model=ProbaModel(),
artifacts={"sk_model": "s3://model/path"})
28
�
29 .Demo: Model Customization
We will fit a model that identifies iris flowers based
on their petals, emitting a probability distribution
f(pwidth, plength) -> probabilities
across 3 flower types
29
�