展开查看详情
1 .Leveraging NLP and Deep
Learning for Document
Recommendation in the Cloud
Guoqiong Song, Intel
#UnifiedAnalytics #SparkAISummit
�
2 . Agenda
• Job/Resume Search Challenges and Opportunity
• Analytics Zoo and BigDL Overview
• Resume Search Analytics Zoo Solution
• Takeaways
�
3 . Agenda
• Job/Resume Search Challenges and Opportunity
• Analytics Zoo and BigDL Overview
• Resume Search Analytics Zoo Solution
• Takeaways
�
4 .Job search
#UnifiedAnalytics #SparkAISummit 4
�
5 . Personalize Results Value
Job Seekers Employers
Find the right job faster Find the right person
Resume Job description
5
�
6 . Traditional Information Retrieval Sufferings
Warehouse
Solution challenges:
stemming, synonyms, Warehouse
ontologies, sensitivity
6
�
7 .Stemming
Accountant =!= Accounting
7
�
8 .Stemming Solution
Accountant =!= Accounting
Accountant = Accounting
8
�
9 .Stemming Sufferings
Accountant =!= Accounting
Accountant = Accounting
Account
Accountant = Accounting =
Representative
9
�
10 .Synonyms
Registered =!= RN
Nurse
10
�
11 .Synonyms Solution
Registered =!= RN
Nurse
Registered RN → registered nurse
=
Nurse
11
�
12 .Synonym Sufferings
Registered =!= RN
Nurse
Registered RN → registered nurse
=
Nurse
...
12
�
13 .Ontologies
Dishwasher =!= Back of House
13
�
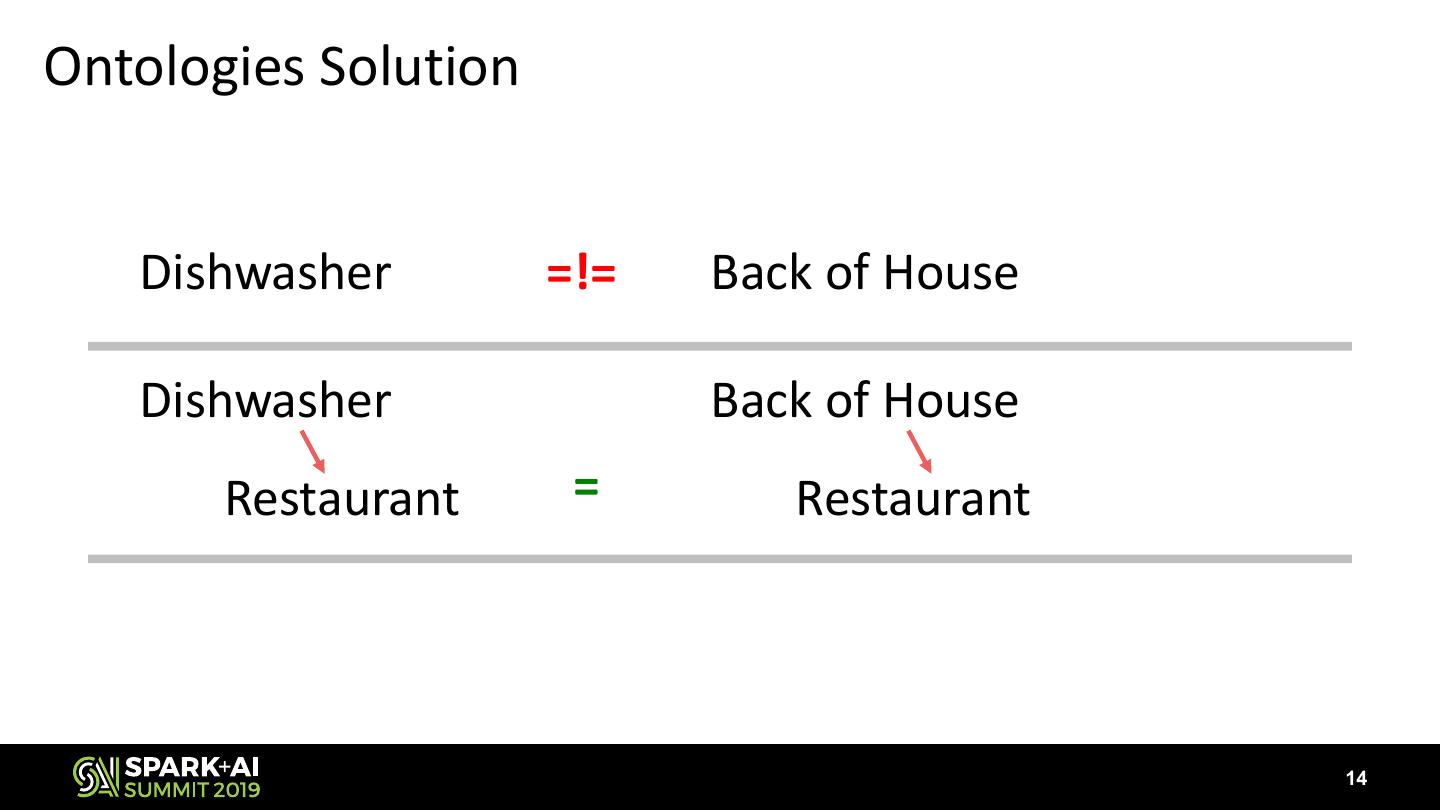
14 .Ontologies Solution
Dishwasher =!= Back of House
Dishwasher Back of House
Restaurant = Restaurant
14
�
15 .Ontologies Sufferings
Dishwasher =!= Back of House
Dishwasher Back of House
Restaurant = Restaurant
...
15
�
16 .Specificity Suffering
16
�
17 . Personalize Results Value
Job Seekers Employers
Find the right job faster Find the right person
Resume Job description
17
�
18 . Agenda
• Job/Resume Search Challenges and Opportunity
• Analytics Zoo and BigDL Overview
• Resume Search Analytics Zoo Solution
• Takeaways
�
19 . AI on
Distributed TensoRflow, Keras and BigDL on Spark
Distributed, High-Performance Reference Use Cases, AI Models,
Deep Learning Framework High-level APIs, Feature Engineering, etc.
for Apache Spark https://github.com/intel-analytics/analytics-zoo
https://github.com/intel-analytics/bigdl
Unifying Analytics + AI on Apache Spark
�
20 .Unified Big Data Analytics Platform
Apache Hadoop & Spark Platform
Machine Graph
Leaning SQL Notebook Spreadsheet
Analytics
Batch Streaming Interactive R Java Python
DataFrame Flink Storm
Data ML Pipelines
Processing SQL SparkR Streaming MLlib GraphX
& Analysis
MR Giraph
Spark Core
Resource Mgmt YARN ZooKeeper
& Co-ordination
Data
Flume Kafka Storage HDFS Parquet Avro HBase
Input
�
21 . Chasm b/w Deep Learning and Big Data
Communities
The
Chasm
Deep learning experts Average users (big data users, data scientists, analysts, etc.)
�
22 . Bridging the Chasm
Make deep learning more accessible to big data and data
science communities
• Continue the use of familiar SW tools and HW infrastructure to build deep learning
applications
• Analyze “big data” using deep learning on the same Hadoop/Spark cluster where the
data are stored
• Add deep learning functionalities to large-scale big data programs and/or workflow
• Leverage existing Hadoop/Spark clusters to run deep learning applications
• Shared, monitored and managed with other workloads (e.g., ETL, data warehouse, feature
engineering, traditional ML, graph analytics, etc.) in a dynamic and elastic fashion
�
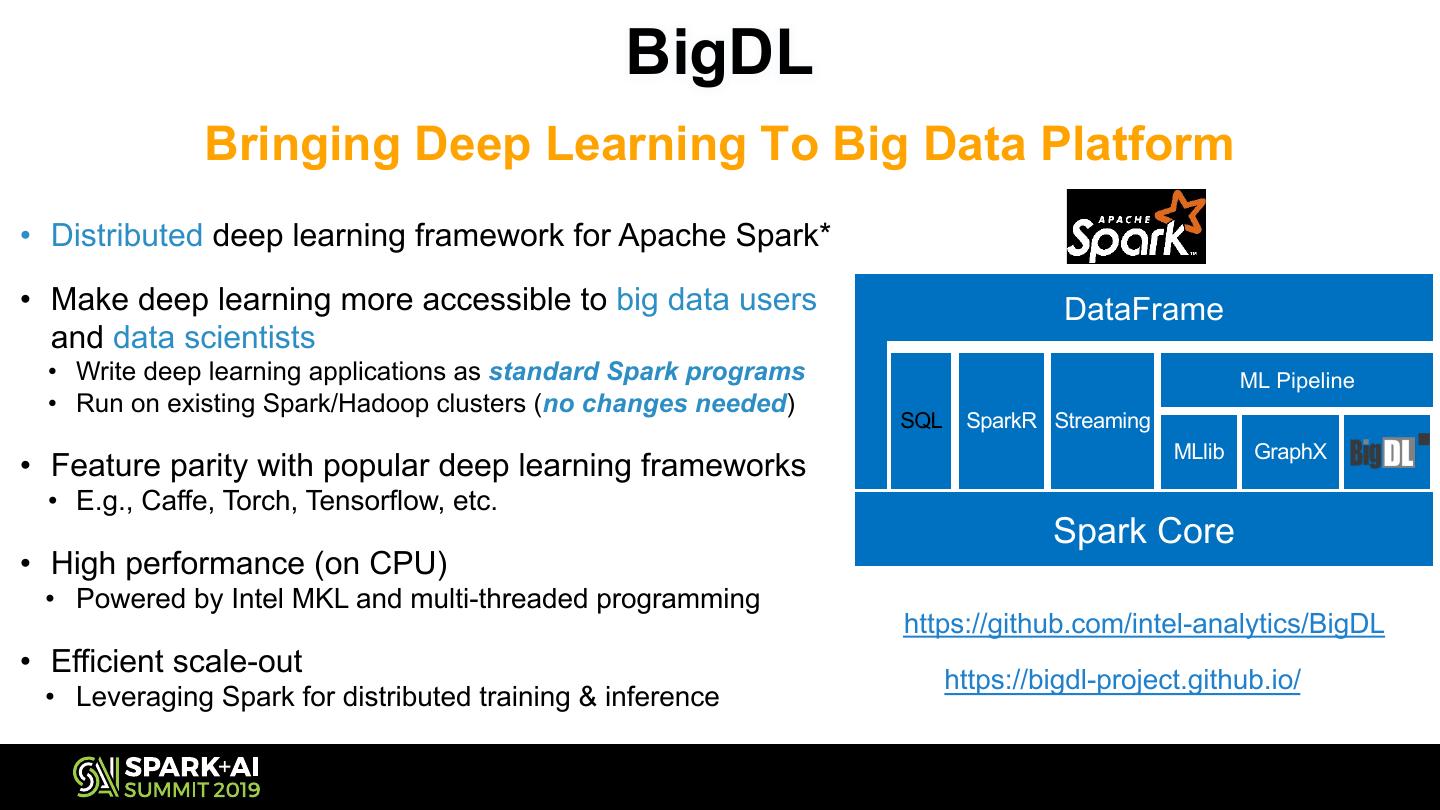
23 . BigDL
Bringing Deep Learning To Big Data Platform
• Distributed deep learning framework for Apache Spark*
• Make deep learning more accessible to big data users DataFrame
and data scientists
• Write deep learning applications as standard Spark programs ML Pipeline
• Run on existing Spark/Hadoop clusters (no changes needed)
SQL SparkR Streaming
MLlib GraphX
• Feature parity with popular deep learning frameworks
• E.g., Caffe, Torch, Tensorflow, etc.
Spark Core
• High performance (on CPU)
• Powered by Intel MKL and multi-threaded programming
https://github.com/intel-analytics/BigDL
• Efficient scale-out
https://bigdl-project.github.io/
• Leveraging Spark for distributed training & inference
�
24 .BigDL Run as Standard Spark Programs
Standard Spark jobs
• No changes to the Spark or Hadoop clusters needed
Iterative
• Each iteration of the training runs as a Spark job
Data parallel
• Each Spark task runs the same model on a subset of the data (batch)
�
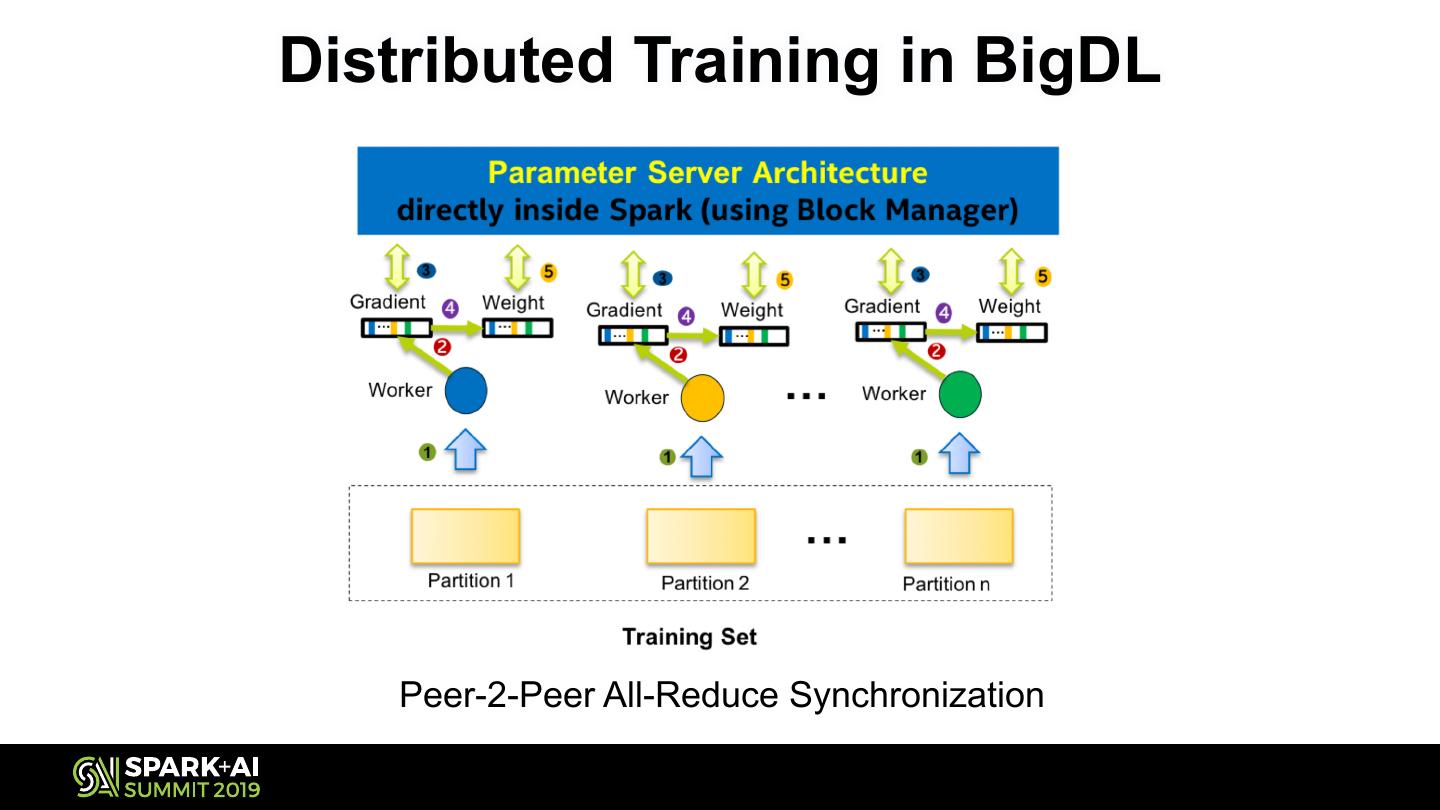
25 .Distributed Training in BigDL
Peer-2-Peer All-Reduce Synchronization
�
26 . Analytics Zoo
Unified Analytics + AI Platform for Big Data
Distributed TensorFlow, Keras and BigDL on Spark
• Anomaly detection, sentiment analysis, fraud detection, image
Reference Use Cases generation, chatbot, etc.
Built-In Deep Learning • Image classification, object detection, text classification, text matching,
Models recommendations, sequence-to-sequence, anomaly detection, etc.
Feature transformations for
Feature Engineering • Image, text, 3D imaging, time series, speech, etc.
• Distributed TensorFlow and Keras on Spark
High-Level Pipeline APIs • Native support for transfer learning, Spark DataFrame and ML Pipelines
• Model serving API for model serving/inference pipelines
Backbends Spark, TensorFlow, Keras, BigDL, OpenVINO, MKL-DNN, etc.
https://github.com/intel-analytics/analytics-zoo/ https://analytics-zoo.github.io/
�
27 . Analytics Zoo
Build end-to-end deep learning applications for big data
• Distributed TensorFlow on Spark
• Keras-style APIs (with autograd & transfer learning support)
• nnframes: native DL support for Spark DataFrames and ML Pipelines
• Built-in feature engineering operations for data preprocessing
Productionize deep learning applications for big data at scale
• Model serving APIs (w/ OpenVINO support)
• Support Web Services, Spark, Storm, Flink, Kafka, etc.
Out-of-the-box solutions
• Built-in deep learning models and reference use cases
�
28 . What Can you do with Analytic Zoo?
Anomaly Detection
• Using LSTM network to detect anomalies in time series data
Fraud Detection
• Using feed-forward neural network to detect frauds in credit card
transaction data
Recommendation
• Use Analytics Zoo Recommendation API (i.e., Neural Collaborative
Filtering, Wide and Deep Learning) for recommendations on data with
explicit feedback.
Sentiment Analysis
• Sentiment analysis using neural network models (e.g. CNN, LSTM, GRU,
Bi-LSTM)
Variational Autoencoder (VAE)
• Use VAE to generate faces and digital numbers
https://github.com/intel-analytics/analytics-zoo/tree/master/apps
�
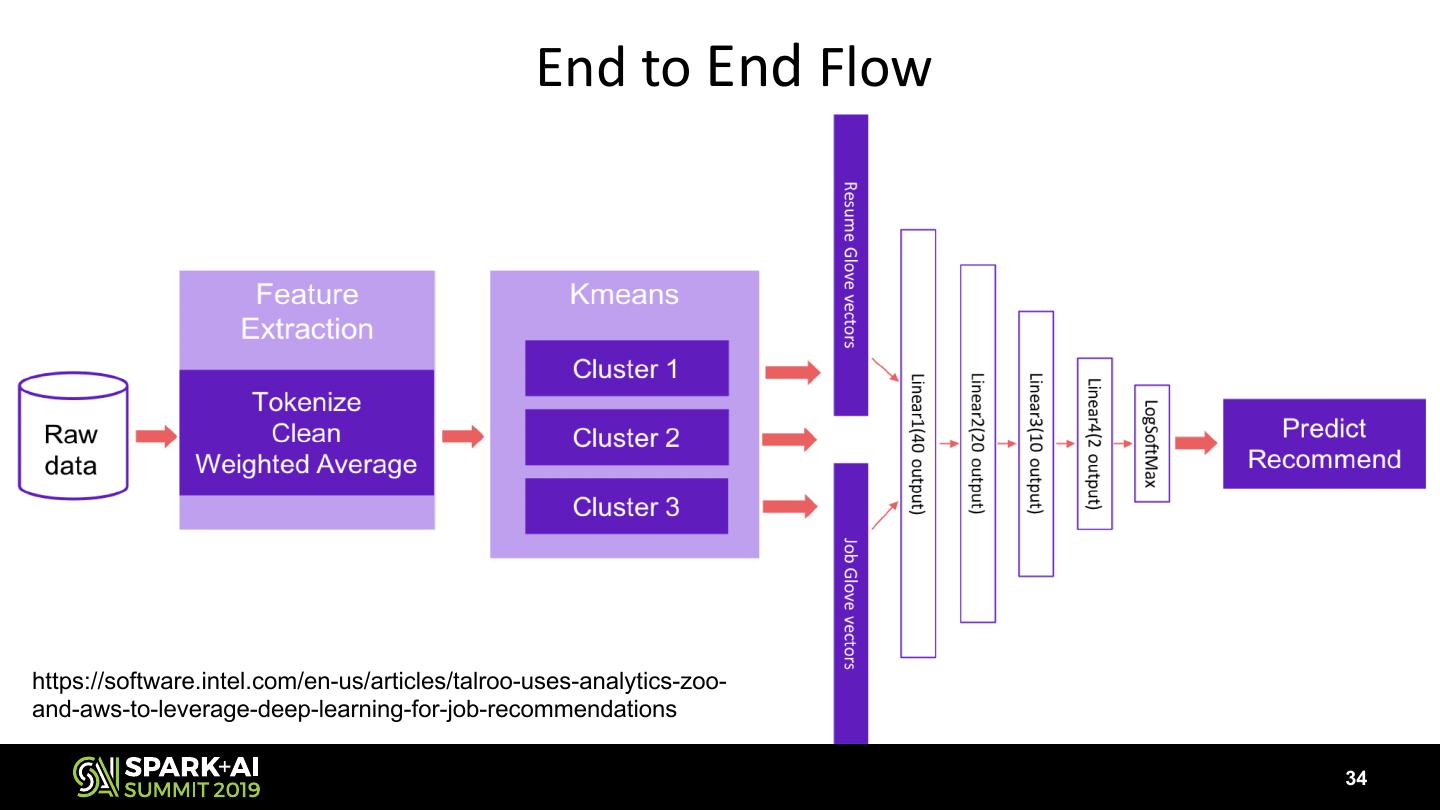
29 .Building and Deploying with BigDL/Analytics Zoo
http://software.intel.com/bigdl/build
Not a Full List
�