展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
�
2 .Large-scale Malicious
Domain Detection with
Spark
Hao Guo, Tencent
Ting Chen, Tencent
#UnifiedAnalytics #SparkAISummit
�
3 .About The Speakers
Hao Guo
• Applied Research Scientist @ Tencent Security
• Master degree in Computer Science from HIT with research
interest in NLP, deep learning and large-scaled machine
learning
Ting Chen
• Director, Applied Machine Learning @ Tencent Jarvis Lab
• PhD degree in Computer Science from UFL with research
interest in computer vision and machine learning
• Previously, Senior ML engineer and DS manager at Uber
#UnifiedAnalytics #SparkAISummit 3
�
4 . Agenda
• DDoS Attack & Advance Persistent Threat
• Sequence based detection
• Crypto Mining Malware
• Locality Sensitivity Hashing based detection
• Conclusion
#UnifiedAnalytics #SparkAISummit 4
�
5 .What is DDoS Attack
https://medium.com/@kapil.sharma91812/understanding-ddos-attack
#UnifiedAnalytics #SparkAISummit 5
�
6 .DDoS Attack Trend
2018 https://securelist.com/ddos-attacks-in-q4-2018/89565/
#UnifiedAnalytics #SparkAISummit 6
�
7 .DDoS Attack Trend
http://francescomolfese.it/en/2018/12/la-protezione-da-attacchi-ddos-in-azure/
#UnifiedAnalytics #SparkAISummit 7
�
8 .What is APT
Symantec APT white paper
#UnifiedAnalytics #SparkAISummit 8
�
9 .APT Activities
https://www.fireeye.com/current-threats/annual-threat-report.html
#UnifiedAnalytics #SparkAISummit 9
�
10 .Behind The Attacks: C&C
#UnifiedAnalytics #SparkAISummit 10
�
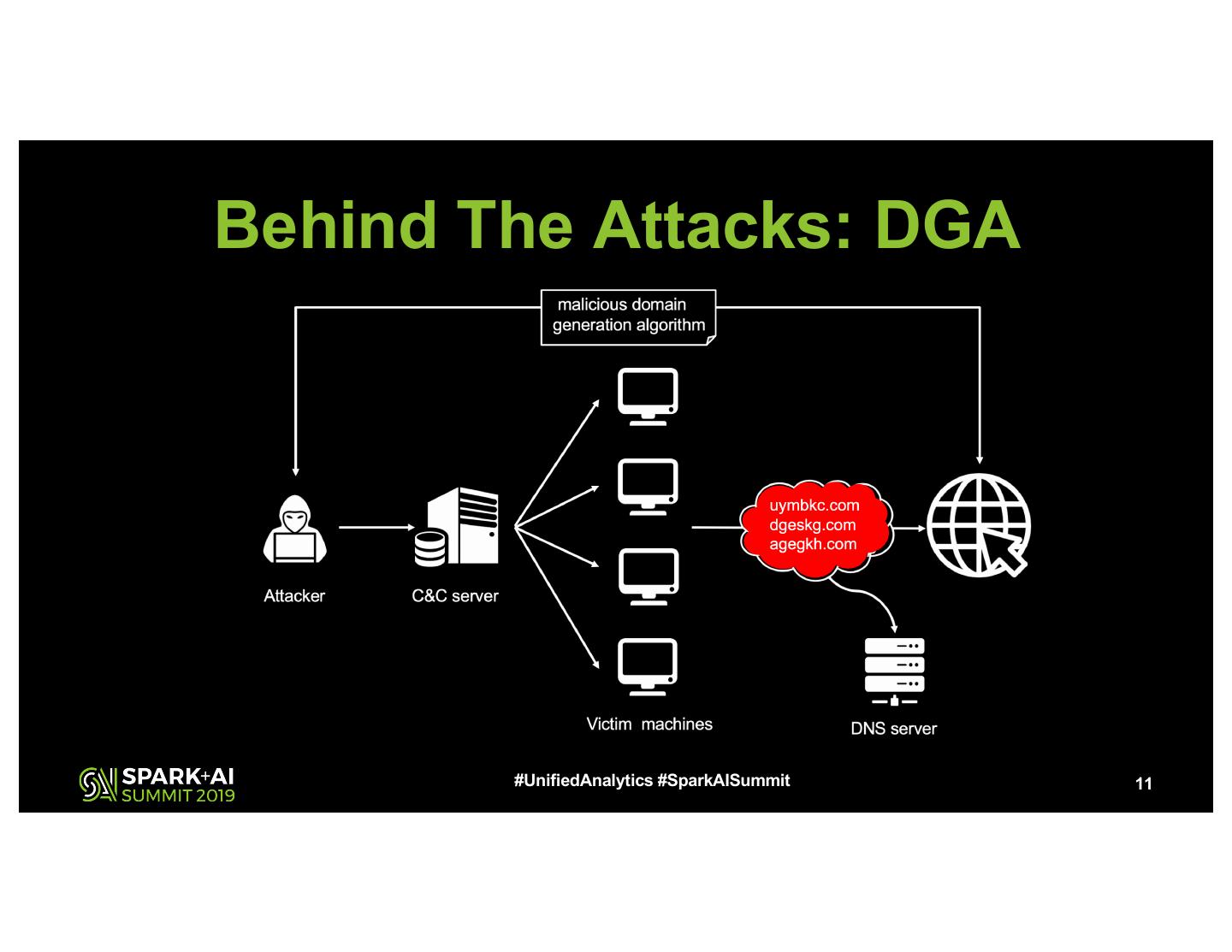
11 .Behind The Attacks: DGA
#UnifiedAnalytics #SparkAISummit 11
�
12 . Malicious Domain Detection
Scenario 1: DGA
uuybcc.com
igmgdc.com
lpppxa.com
Victim
hosts Sequences of domains accessed for each host swdosv.com
grevun.com
djiyei.com
cvevrm.com
vyjyui.com
#UnifiedAnalytics #SparkAISummit 12
�
13 .Crypto Mining Malware
#UnifiedAnalytics #SparkAISummit 13
�
14 . Malicious Domain Detection
Scenario 2: Crypto mining domains
Victim hosts cab217f6.space
6850c644.space
cbb21989.space
c8b214d0.space
ceb21e42.space
cfb21fd5.space
c9b21663.space
d4b227b4.space
#UnifiedAnalytics #SparkAISummit 14
�
15 .#UnifiedAnalytics #SparkAISummit
Data Scale @ Tencent
DNS Records Domains IPs/Hosts Storage
Tens
Billions Billions TB
(day) (day)
Millions
(day)
Spark enables large-scale data analysis.
#UnifiedAnalytics #SparkAISummit 15
�
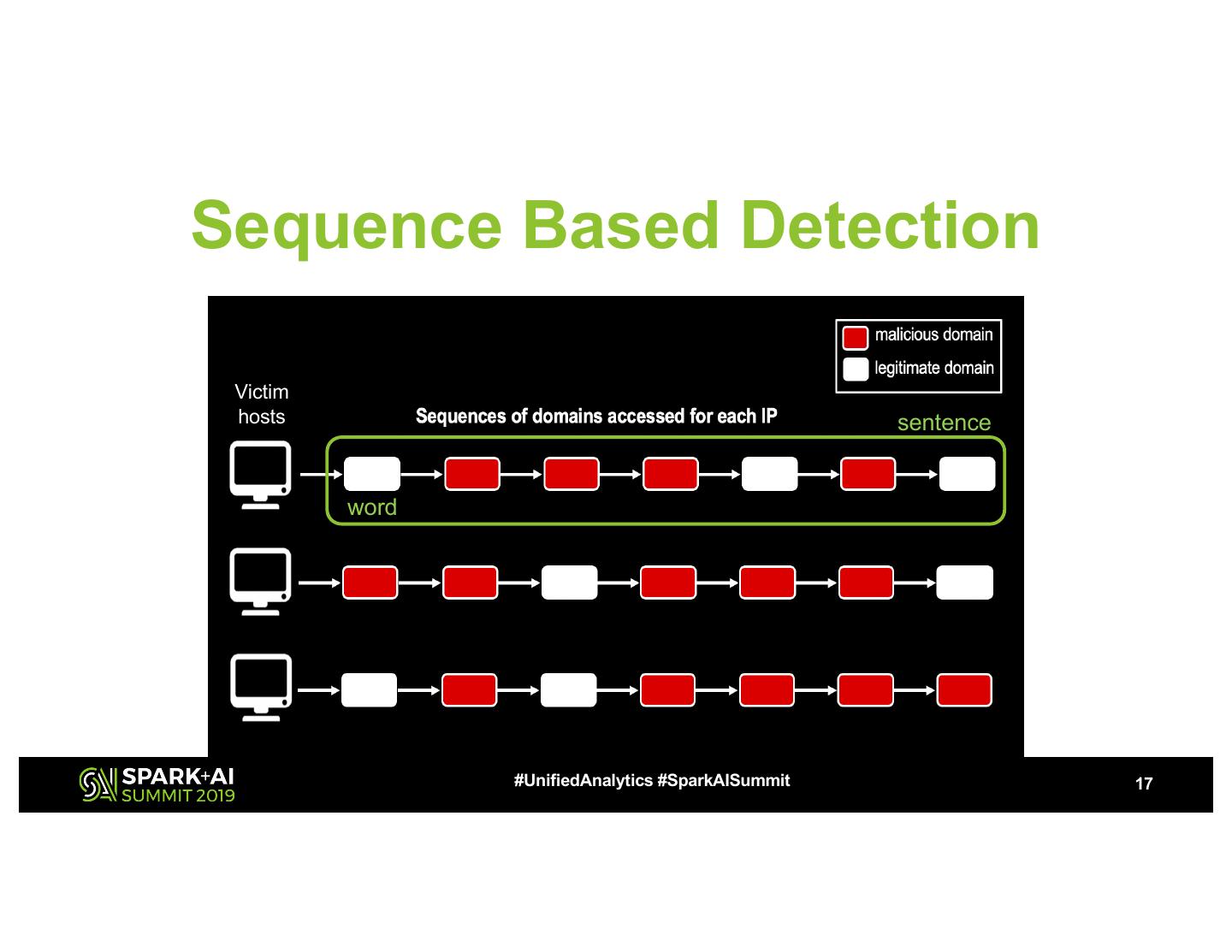
16 .Sequence Based Detection
#UnifiedAnalytics #SparkAISummit 16
�
17 .Sequence Based Detection
Victim
hosts sentence
word
#UnifiedAnalytics #SparkAISummit 17
�
18 .Sequence Based Detection
Victim
hosts document
#UnifiedAnalytics #SparkAISummit 18
�
19 . Domain2Vec Representation
Key Idea
• Estimate the domain2vec (work2vec)
Victim
hosts
representation of each domain with CBOW
CBOW framework
i-2 i-1 i i+1 i+2
Example domain2vec representation
• uymbkc.com
-0.10 0.58 -0.04 … 0.29 0.26 -0.17
#UnifiedAnalytics #SparkAISummit 19
�
20 .Domain Clustering
• Start with seed domains (known malicious
domains)
• Find most similar domains
𝑑𝑜𝑚𝑎𝑖𝑛𝑉𝑒𝑐4 5 𝑑𝑜𝑚𝑎𝑖𝑛𝑉𝑒𝑐6
𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦 = cos θ =
||𝑑𝑜𝑚𝑎𝑖𝑛𝑉𝑒𝑐4 ||||𝑑𝑜𝑚𝑎𝑖𝑛𝑉𝑒𝑐6 ||
#UnifiedAnalytics #SparkAISummit 20
�
21 .Domain Clustering
#UnifiedAnalytics #SparkAISummit 21
�
22 .Example Clustering Results
Virus Domains Nymaim Domains Conficker Domains
uuybcc.com pjbgwwt.ru kicuxexj.org
igmgdc.com mphsnkjgnfh.biz xiaxyvyn.net
lpppxa.com nkposroyfkr.net jhpruj.biz
swdosv.com uusuux.ru cvlyfcz.org
grevun.com dsvlvlnkcj.ru dsvevamq.biz
djiyei.com jtduakh.ru blqdisrp.cc
cvevrm.com ... ... eujyvcvj.org
vyjyui.com ... ....
... ...
#UnifiedAnalytics #SparkAISummit 22
�
23 . Implementation Framework
billions/day
#UnifiedAnalytics #SparkAISummit 23
�
24 . Key Functions
from pyspark.sql import SparkSession, Row
from pyspark.ml.feature import Word2Vec, Word2VecModel
Domain Sequence Generation
domain_sequence_rdd = \
input_rdd.combineByKey(to_list, append, extend, numPartitions = N).mapValues(sortbytime)
Domain2Vec Calculation
domain_sequence_rdd = domain_sequence _rdd.map( lambda r:Row(r) )
domain_sequence = spark.createDataFrame(domain_sequence_rdd,[”domainSequence”])
domain2vec = Word2Vec(vectorsize=100, minCount=3, numPartitions =N, seed=42, \
inputCol=”domainSequce”, outputCol=”model”, windowSize=8, maxSentenceLength=1000)
model = domain2vec.fit(domain_sequence)
Similarity Domain Clustering
model.findSynonyms(domain_seed, M).select("word", fmt("similarity", m).alias("similarity"))
#UnifiedAnalytics #SparkAISummit 24
�
25 .LSH Based Detection
#UnifiedAnalytics #SparkAISummit 25
�
26 . LSH based detection
Victim hosts
Jaccard similarity
host IP sets for accessing domain1:
𝑆9 = {𝐼𝑃0, 𝐼𝑃1, 𝐼𝑃2, 𝐼𝑃3}
host IP sets for accessing domain2:
𝑆C = {𝐼𝑃1, 𝐼𝑃2, 𝐼𝑃3, 𝐼𝑃4}
Similarity of domain1 and domain2 is:
| EF9,EFC,EFG |
𝑠𝑖𝑚 𝑑𝑜𝑚𝑎𝑖𝑛1, 𝑑𝑜𝑚𝑎𝑖𝑛2 = | EFH,EF9,EFC,EFG,EFI |
= 3/5
#UnifiedAnalytics #SparkAISummit 26
�
27 . Why LSH
• High dimensional and sparse
– tens of millions hosts
• O(N*N) comparisons
– million unique domains
• Spark provides Locality Sensitivity Hashing for fast near-duplicate detection
#UnifiedAnalytics #SparkAISummit 27
�
28 . LSH
With hight probablity domain1 and doman2 are
hashed into the same buckets .
With high probablity domain1 and domain2 are
hashed into the different buckets.
#UnifiedAnalytics #SparkAISummit 28
�
29 .Minhash and Jaccard Similarity
• There is a suitable hash function for
the Jaccard similarity : minhash
• The probability that
minhash(domain1) = minhash(domain2)
is equal to the similarity of
Jaccard(domain1, domain2)
#UnifiedAnalytics #SparkAISummit 29
�