展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Improving Apache Spark by Taking
Advantage of Disaggregated Architecture
Chenzhao Guo(Intel) Carson Wang(Intel)
�
3 .About me
• Chenzhao Guo
• Big Data Software Engineer at Intel
• Contributor of Spark, committer of OAP and HiBench
• Our group’s work: enabling and optimizing Spark on
exascale High Performance Computer
3
�
4 .Agenda
• Limitations on default Spark shuffle
• Enabling Spark shuffle on disaggregated compute &
storage
• Challenges & optimizations
• Performance
• The future of
4
�
5 .Agenda
• Limitations on default Spark shuffle
•
•
•
•
5
�
6 . What is shuffle?
• Shuffle is an intermediate phrase between a map stage and a
reduce stage, when executors of Spark exchange data
• Shuffle is I/O(both disk and network) intensive
• Industry mostly deploys HDD and 10Gb/s – network today, making
shuffle an expensive operation, affects end-to-end time a lot
Map task 0 Map task 1
Shuffle write
Map output 0 Map output 1
Shuffle read
reduce task 0 reduce task 1 reduce task 0
6
�
7 .Pain point 1: performance
Shuffle drags down the end-to-end performance
• slow due to random disk I/Os
• may fail due to no space left or disk failure
Mechanical structure performs
slow seek operation
What if I upgrade the HDDs to larger capacity or SSDs?
7
�
8 . Pain point 2: Easy management & cost
efficiency
What if I upgrade the HDDs to larger capacity or SSDs?
• Scaling out/up the storage resources affects
the compute resource
• Scaling the disks to accommodate shuffle’s
need may make storage resources under-
utilized under other(like CPU-intensive)
workloads: not cost efficient
Collocated compute & storage architecture
8
�
9 . Limitations on default Spark shuffle
Cluster Software
essence diagram Scale out/up
utilization management
Hard to scale
Tightly Under-utilized
Traditional out/upgrade Debugging an
coupled one of the 2
collocated without affecting issue may be
compute & resources
architecture the other resource complicated
storage
?
9
�
10 .Agenda
•
• Enabling Spark shuffle on disaggregated compute &
storage architecture
•
•
•
10
�
11 .Disaggregated architecture
• Compute and storage resources are separated,
interconnected by high-speed(usually) network
• Common in HPC world and large companies who own
thousands of servers, for better efficiency and easier
management
Fabrics network Storage cabinet with
Compute cabinet with CPU,
NVMe SSD, running
Memory and accelerators
DAOS storage system
Disaggregated
architecture in HPC
11
�
12 . Collocated vs disaggregated compute &
storage architecture
Cluster Software
essence diagram Scale out/up
utilization management overhead
Hard to scale
Tightly Under-utilized
Traditional out/upgrade Debugging an
coupled one of the 2
collocated without affecting issue may be
compute & resources
architecture the other resource complicated
storage
Efficient for
? Independent
diverse
Disaggregat Decoupled scaling per Different team
workloads with Extra
ed compute compute & compute & only needs to
& storage storage
different
storage needs care their own
network
architecture
storage/comput
separately cluster
transfer
e needs
12
�
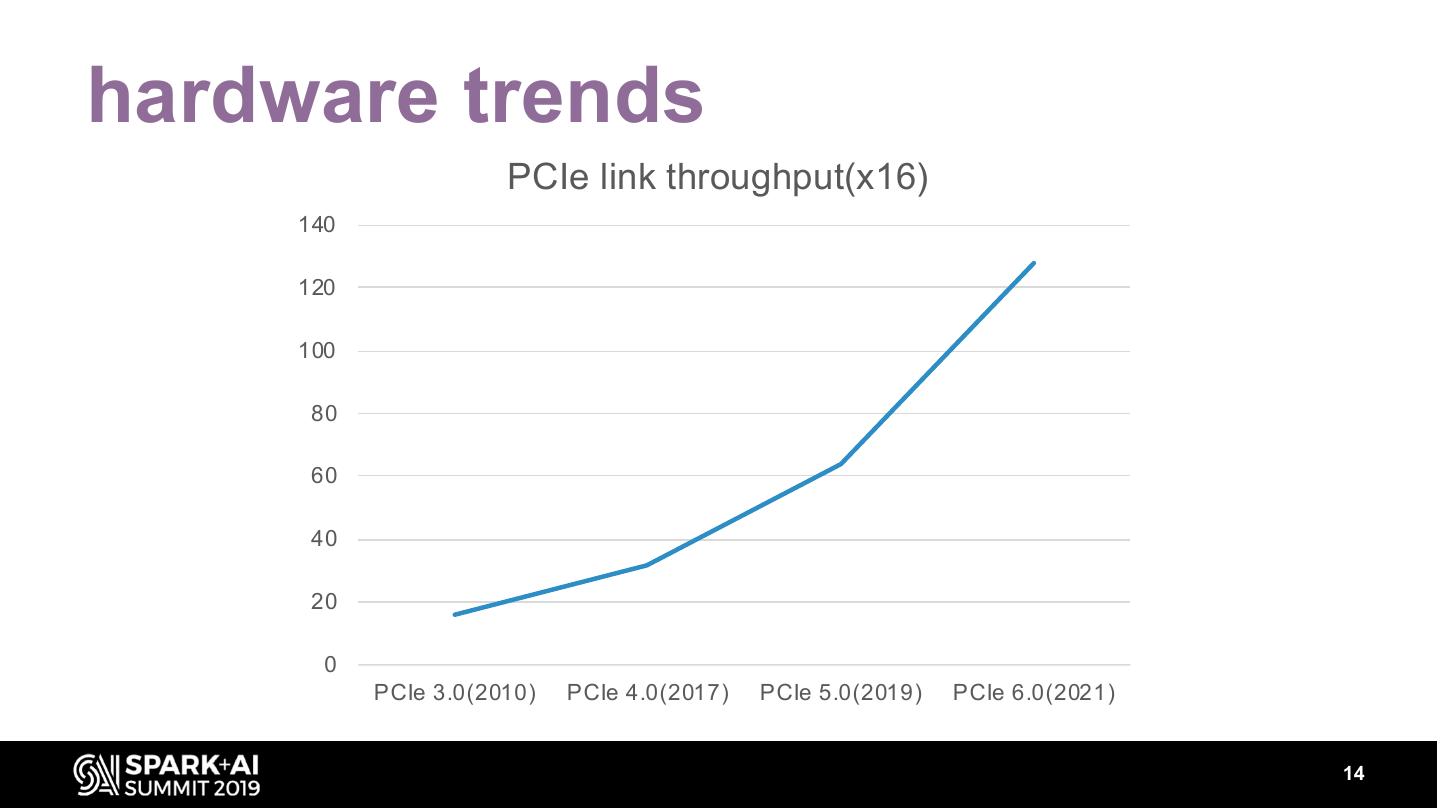
13 .Why network transfer is no longer a big deal?
• Software:
I/O bottleneck,
– Efficient compression algorithms
CPU bottleneck,
– Columnar file format
– Other optimizations for less I/O
• Hardware:
– Network bandwidth is doubled every 18 months
13
�
14 .hardware trends
PCIe link throughput(x16)
140
120
100
80
60
40
20
0
PCIe 3.0(2010) PCIe 4.0(2017) PCIe 5.0(2019) PCIe 6.0(2021)
14
�
16 .What brings us here?
• Limitations of default Spark shuffle
• Challenges to resolve enabling & optimizing Spark on
HPC:
– data source & storage on DAOS
– network on high-performance fabrics
– scalability issues when there are ~10000 nodes
– intermediate(shuffle, etc.) storage on disaggregated
compute & storage architecture
16
�
17 .How Spark shuffle works?
SortShuffleManager
• Map stage: writes data to local disks
Netty fetch using Java File API
• Reduce stage: reads data by fetching
Writer BlockManager Reader from the executor who wrote the map
files, through network
• BlockManager(& MapOutputTracker)
Java File API write Java File API read
managed the shuffle data
Local disk Local disk Local disk
17
�
18 .A remote shuffle manager
RemoteShuffleManager 1. Duplicate the sort, partition, aggregation
algorithms in the new remote shuffle
manager
2. Map stage/reduce stage: replace Java
Writer Reader File API with Hadoop API to write/read
3. Doesn’t need other components to
Hadoop OutputStream Hadoop InputStream manage shuffle data, the global file path
can be derived from applicationId,
Globally-accessible Hadoop-compatible Filesystem mapId and reduceId
4. Spill to remote storage
HDFS Lustre … DAOS FS
18
�
19 .A remote shuffle I/O
• No need to maintain full shuffle algorithms including
sort, partition, aggregation logics, but only cares about
shuffle storage
• Based on the new shuffle abstraction layer introduced in
SPARK-25299
19
�
20 .Agenda
•
•
• Challenges & optimizations
•
•
20
�
21 .What have we offered until now?
• A ShuffleManager/(ShuffleI/O) that
– targets globally-accessible Hadoop-compatible storage without
extra transfer
– Doesn’t afraid of executor failures naturally due to shuffle data is
managed by the remote storage system
– is reliable due to the shuffle data in storage can be replicated
– is easy to scale and cost-efficient due to taking advantages of
disaggregated compute and storage architecture
– adds more network transferring overhead for data files and index
files Index files are small, however, some
Hadoop storage system like HDFS are not
designed for small files I/O
21
�
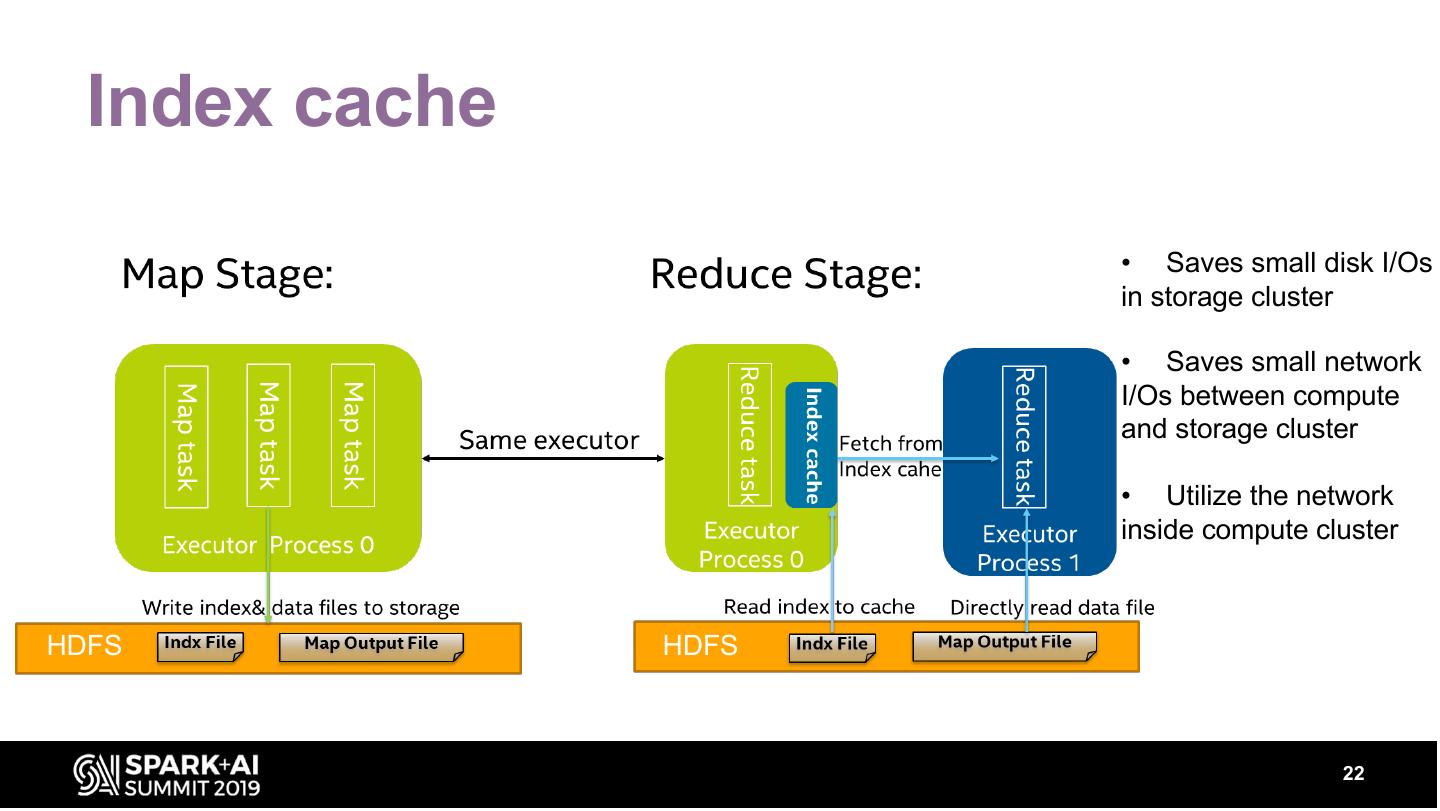
22 . Index cache
• Saves small disk I/Os
in storage cluster
• Saves small network
I/Os between compute
and storage cluster
• Utilize the network
inside compute cluster
HDFS HDFS
22
�
23 .Index cache: fall back to read index files
from remote storage
23
�
24 .Remote shuffle over DAOS
• Distributed Asynchronous Object Storage (DAOS)
– Architected from the ground up for next-generation NVMe SSD,
unlike traditional storage stacks which are for rotating media
– Operates in user space with full OS bypass RemoteShuffleManager
– Fine-grained, low-latency I/O
– Non-blocking data and metadata operations DAOS Filesystem
to allow I/O and compute to overlap DAOS API Java
Wrapper
DAOS
24
�
25 .Performance benchmarks
25
�
26 .Thoughts
• Disaggregated architecture can improve
performance/easy management not only for Spark
shuffle
• Towards a fully disaggregated world – CPU, memory
and disks are disaggregated, connected through
network
• A fully hashed-based shuffle manager that can bypass
sort operation
26
�
27 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�
28 .backup Host 1 Host 2
Executor Executor
Cluster 1
Cluster 1
Executor Executor
Local Disk LocalHost
Disk1 Host 2
Cluster 2 Executor Executor
disk disk
Local Disk Local Disk
28
�
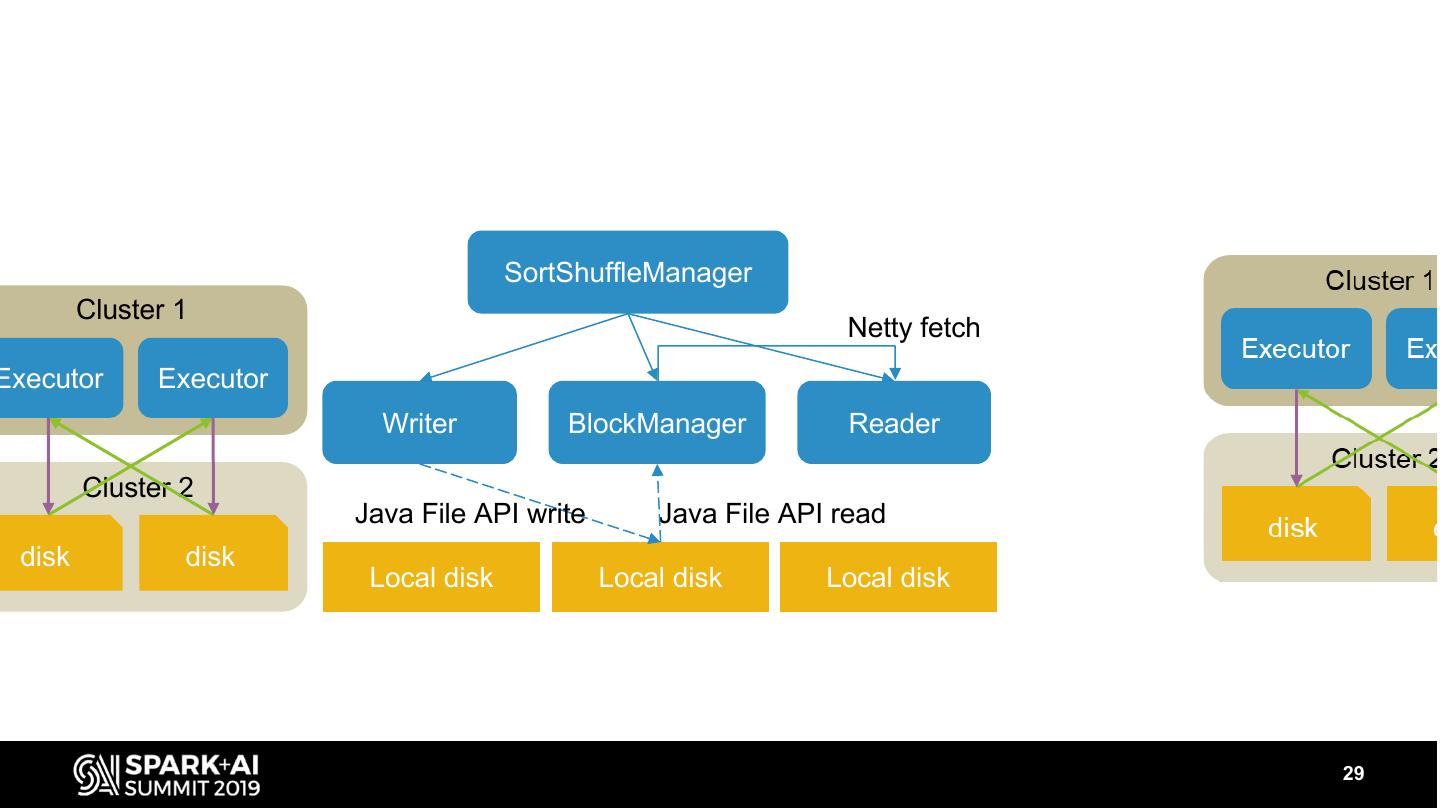
29 . SortShuffleManager
Cluster 1
Netty fetch
Executor Executor
Writer BlockManager Reader
Cluster 2
Java File API write Java File API read
disk disk
Local disk Local disk Local disk
29
�