How McAfee Built High-Quality Pipelines with Azure Databricks to Power Customer
分享
点赞
0
收藏
0
下载 1
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
How do you make over 250TB of data useful to data scientists? Bring a lot of CPUs? If only it were so simple!
Understanding customer behavior requires having high quality, reliable data. Any data quality challenges are magnified with high volumes of data, limiting data scientists’ ability to understand, clean, and use data. If you have to clean up 600 million events per day, it’s like cleaning Moscone West’s floors: as soon as you’re done, you have to start all over again.
Come learn how McAfee built a data-driven pipeline using Azure Databricks to maintain high data quality and comprehensive lineage to enable data scientists to be more productive and make sound statistical inferences.
展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
�
2 .Customer Insights from 250TB+ of Data:
Lessons Learned in Data Governance and Lineage
David Newell & Geoff Oitment, McAfee
#UnifiedAnalytics #SparkAISummit
�
3 .“
At the heart of [AI] technology is data.
– Henry Schuck, Forbes
https://www.forbes.com/sites/forbestechcouncil/2018/05/02/why-data-accuracy-is-critical-to-the-evolution-of-artificial-intelligence-in-b2b-sales/#57bebedf466d
#UnifiedAnalytics #SparkAISummit 3
�
4 .What’s so hard about Big Data?
Finding Signal in the Noise
Limited Big Data Skills
Technology Moves Fast
Siloed Data Sources
#UnifiedAnalytics #SparkAISummit 4
�
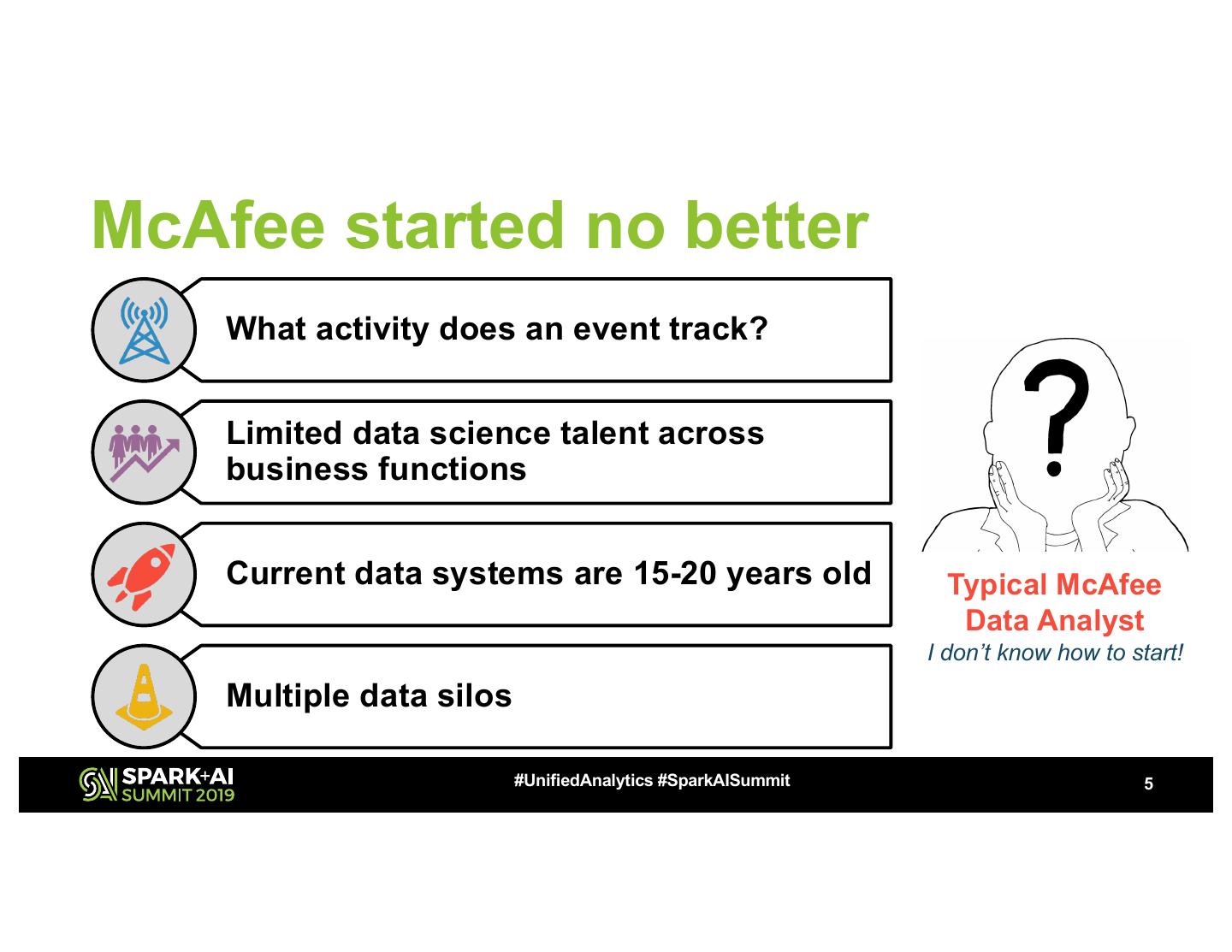
5 .McAfee started no better
What activity does an event track?
Limited data science talent across
business functions
Current data systems are 15-20 years old Typical McAfee
Data Analyst
I don’t know how to start!
Multiple data silos
#UnifiedAnalytics #SparkAISummit 5
�
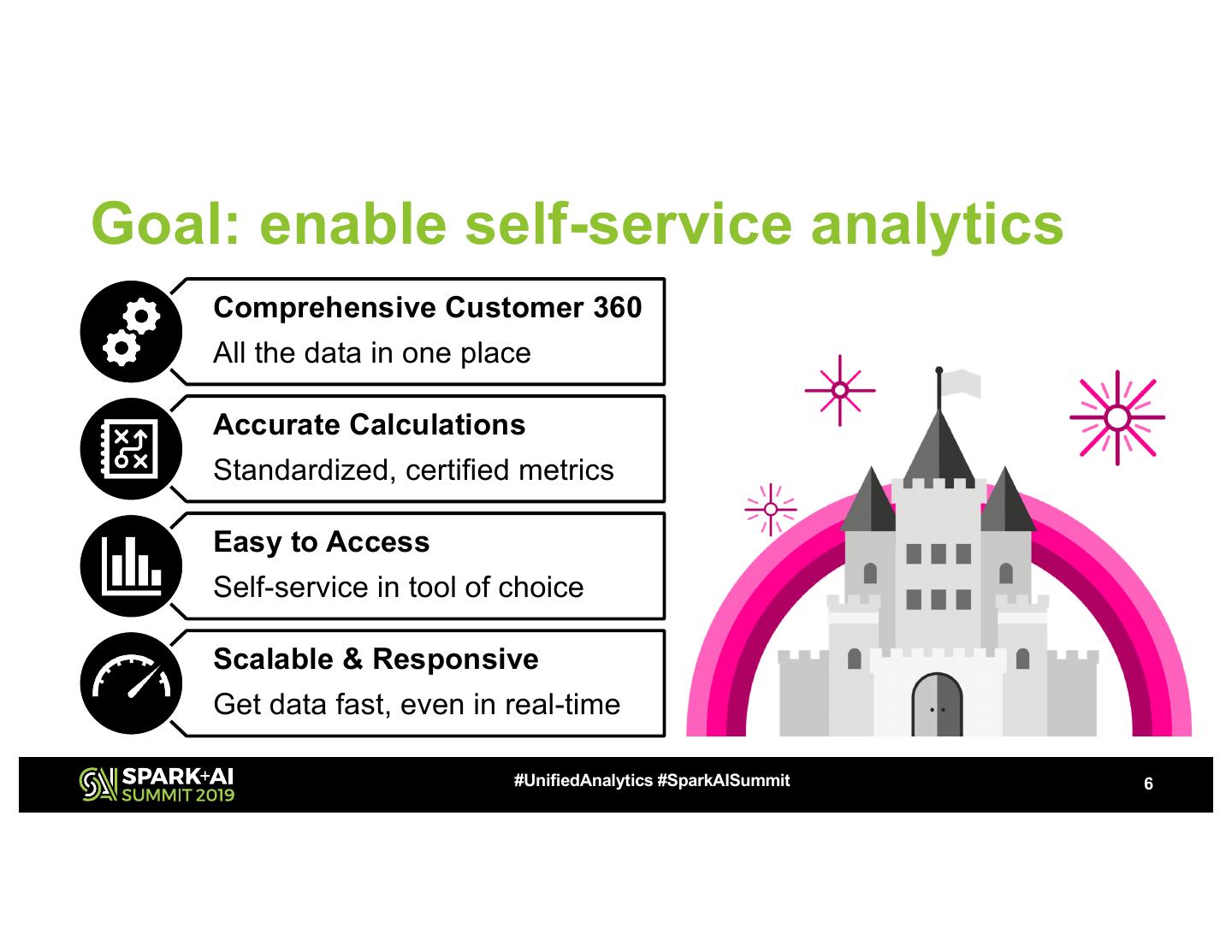
6 .Goal: enable self-service analytics
Comprehensive Customer 360
All the data in one place
Accurate Calculations
Standardized, certified metrics
Easy to Access
Self-service in tool of choice
Scalable & Responsive
Get data fast, even in real-time
#UnifiedAnalytics #SparkAISummit 6
�
7 .The data lake fallacy: it’s magic!
vs
A data lake is not a magic wand:
• Veracity still dependent on data quality
• Volume still dependent on inputs
• Value still dependent on skill set
These photos by Unknown Authors are licensed under CC BY-NC-SA
#UnifiedAnalytics #SparkAISummit 7
�
8 .How we kept the data lake clean:
portal for systematic data governance
Comprehensive documentation Centralized governance &
at all ingestion points documentation system
• Data validation rules • Automatic documentation and
• Source data collection driven governance enforcement
by documentation • Generated tracking manifests
• Data cleaned at the source
#UnifiedAnalytics #SparkAISummit 8
�
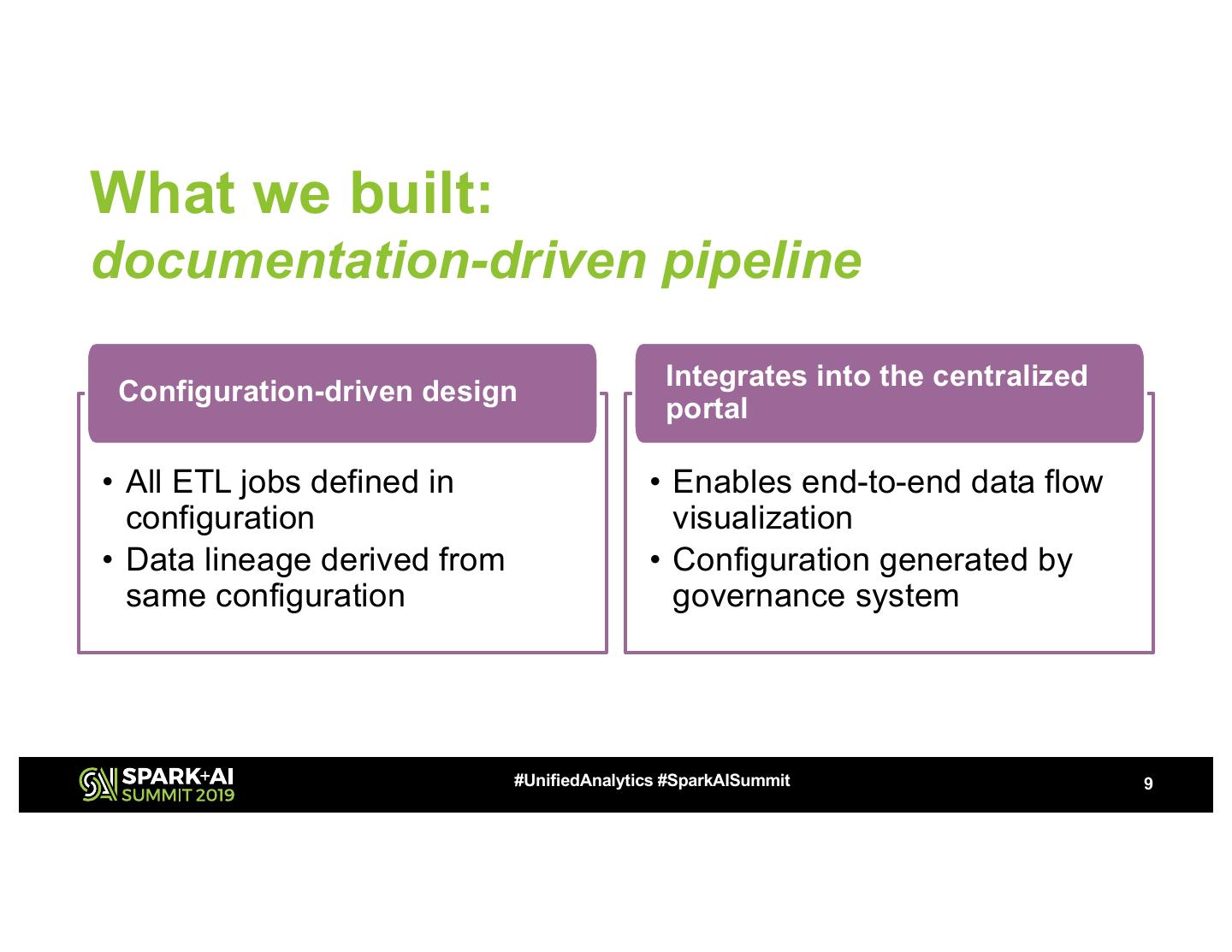
9 .What we built:
documentation-driven pipeline
Integrates into the centralized
Configuration-driven design
portal
• All ETL jobs defined in • Enables end-to-end data flow
configuration visualization
• Data lineage derived from • Configuration generated by
same configuration governance system
#UnifiedAnalytics #SparkAISummit 9
�
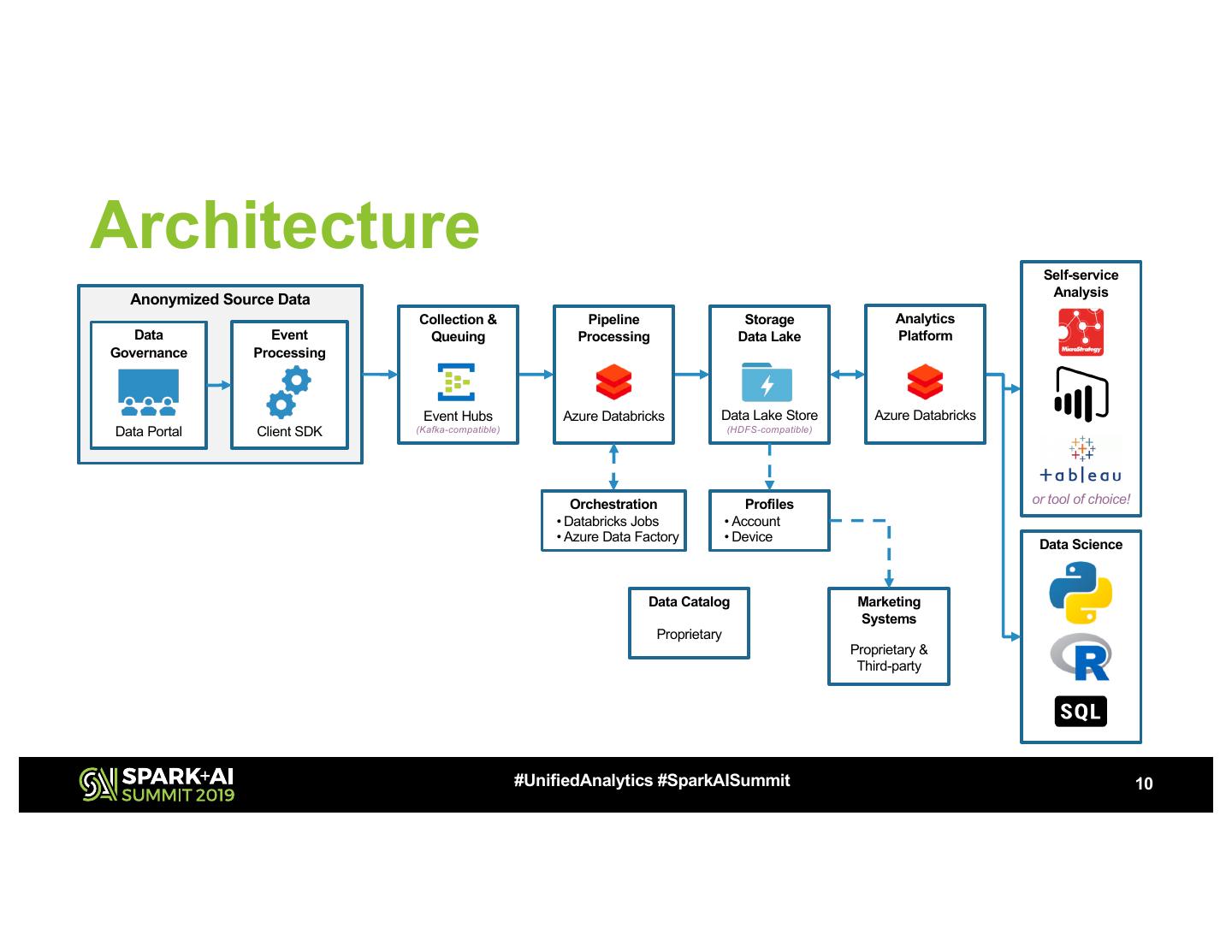
10 .Architecture Self-service
Analysis
Anonymized Source Data
Collection & Pipeline Storage Analytics
Data Event Queuing Processing Data Lake Platform
Governance Processing
Event Hubs Azure Databricks Data Lake Store Azure Databricks
Data Portal Client SDK (Kafka-compatible) (HDFS-compatible)
Orchestration Profiles or tool of choice!
• Databricks Jobs • Account
• Azure Data Factory • Device
Data Science
Data Catalog Marketing
Systems
Proprietary
Proprietary &
Third-party
#UnifiedAnalytics #SparkAISummit 10
�
11 .Lessons Learned
Don’t compromise on data quality;
you’ll regret it later
Create small, manageable features that
enable quick iteration
Think ahead; don’t do something that will
handicap future development
#UnifiedAnalytics #SparkAISummit 11
�
12 .Don’t compromise on data quality;
you’ll regret it later
#UnifiedAnalytics #SparkAISummit 12
�
13 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�