End-to-End Spark-TensorFlow-PyTorch Pipelines with Databricks DeltaLake
分享
点赞
6
收藏
2
下载 0
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
Hopsworks is an open-source data platform that can be used to both develop and operate horizontally scalable machine learning pipelines. A key part of our pipelines is the world’s first open-source Feature Store, based on Apache Hive, that acts as a data warehouse for features, providing a natural API between data engineers – who write feature engineering code in Spark (in Scala or Python) – and Data Scientists, who select features from the feature store to generate training/test data for models. In this talk, we will discuss how Databricks Delta solves several of the key challenges in building both feature engineering pipelines that feed our Feature Store and in managing the feature data itself.
Firstly, we will show how expectations and schema enforcement in Databricks Delta can be used to provide data validation, ensuring that feature data does not have missing or invalid values that could negatively affect model training. Secondly, time-travel in Databricks Delta can be used to provide version management and experiment reproducability for training/test datasets. That is, given a model, you can re-run the training experiment for that model using the same version of the data that was used to train the model.
We will also discuss the next steps needed to take this work to the next level. Finally, we will perform a live demo, showing how Delta can be used in end-to-end ML pipelines using Spark on Hopsworks.
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .End-to-End ML Pipelines
with Databricks Delta and
Hopsworks Feature Store
Kim Hammar, Logical Clocks AB KimHammar1
Jim Dowling, Logical Clocks AB jim_dowling
#UnifiedDataAnalytics #SparkAISummit
�
3 .Machine Learning in the Abstract
3
�
4 .Where does the Data come from?
4
�
5 .Where does the Data come from?
“Data is the hardest part of ML and the most important piece to get
right. Modelers spend most of their time selecting and transforming
features at training time and then building the pipelines to deliver
those features to production models.” [Uber on Michelangelo]
5
�
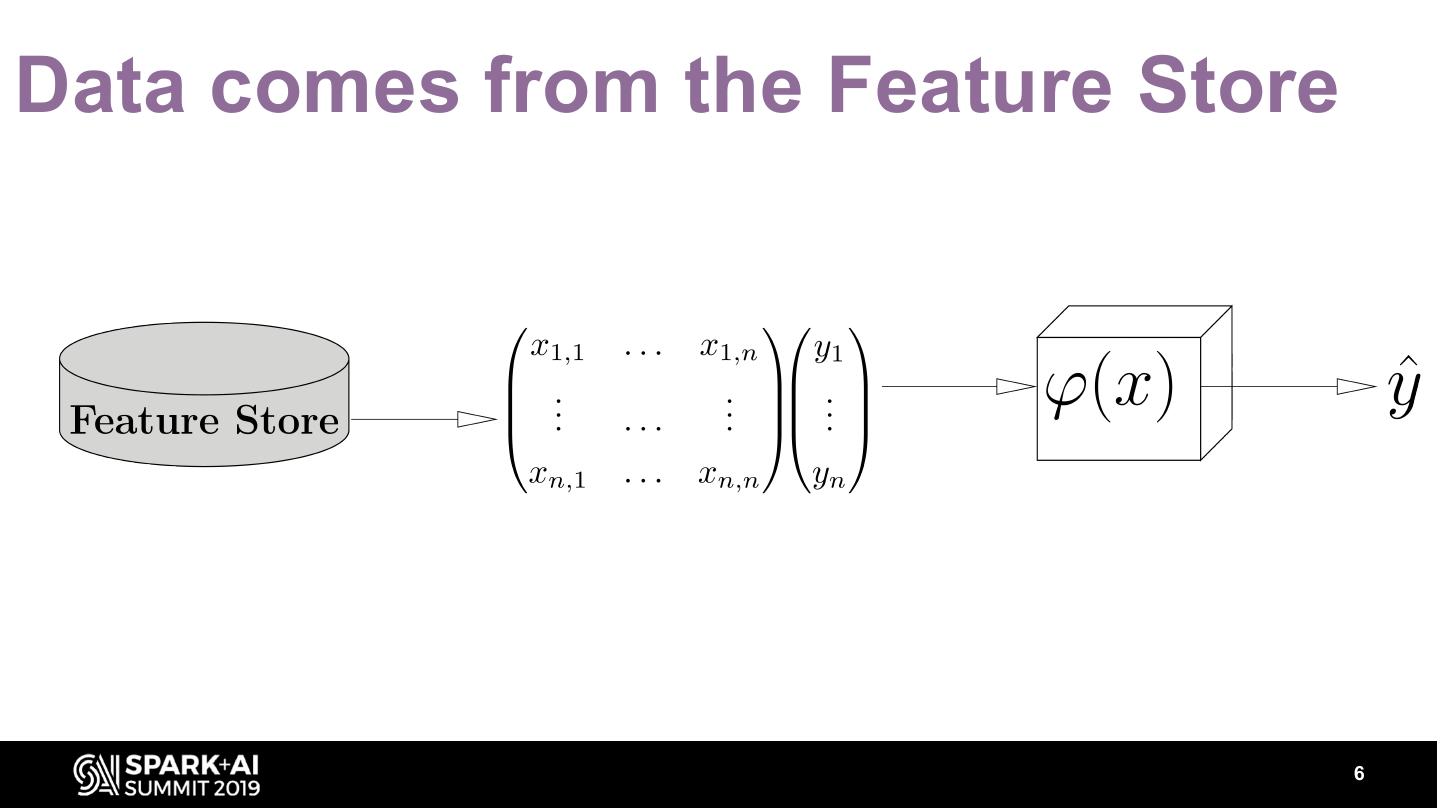
6 .Data comes from the Feature Store
6
�
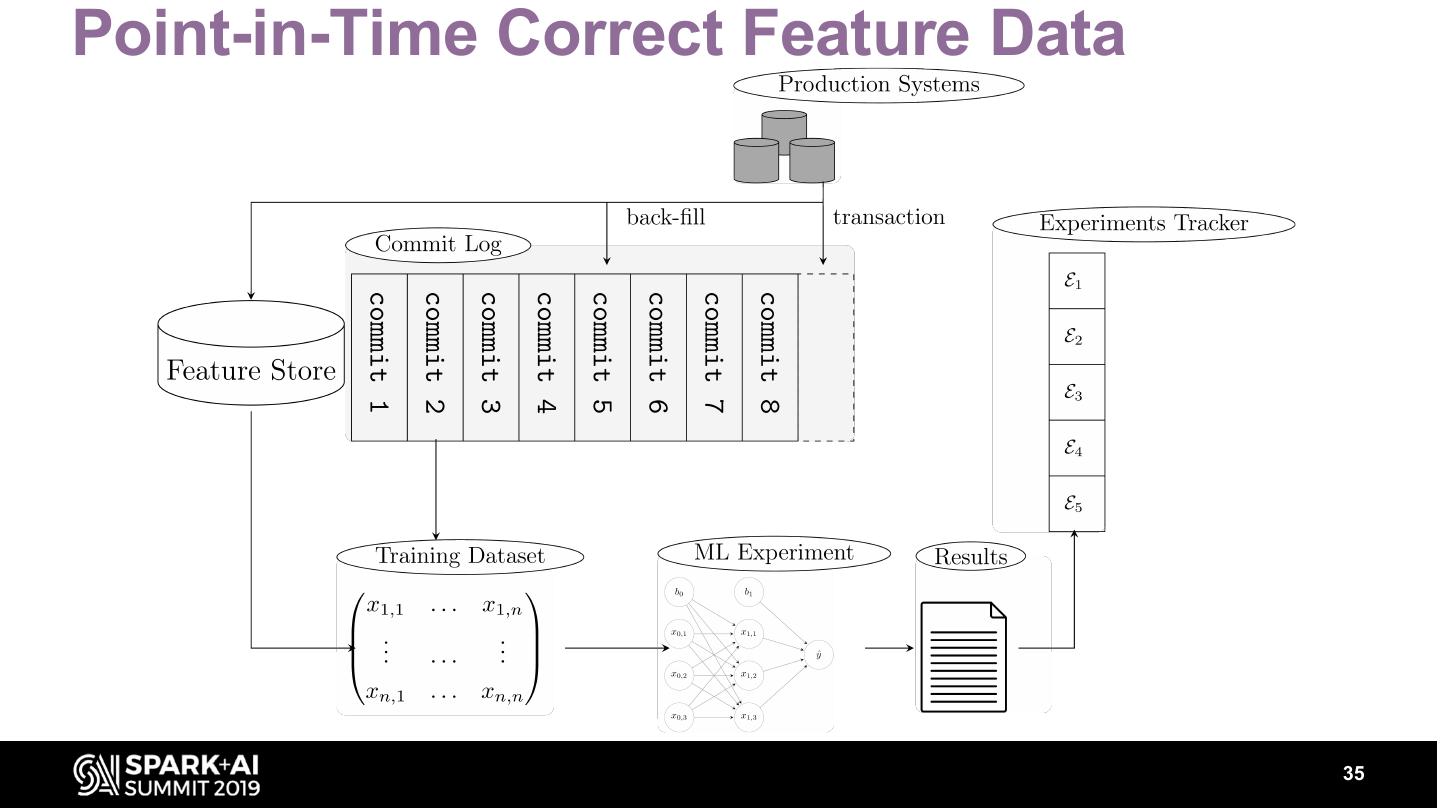
7 .How do we feed the Feature Store?
7
�
8 .Outline
1. Hopsworks
2. Databricks Delta
3. Hopsworks Feature Store
4. Demo
5. Summary
8
�
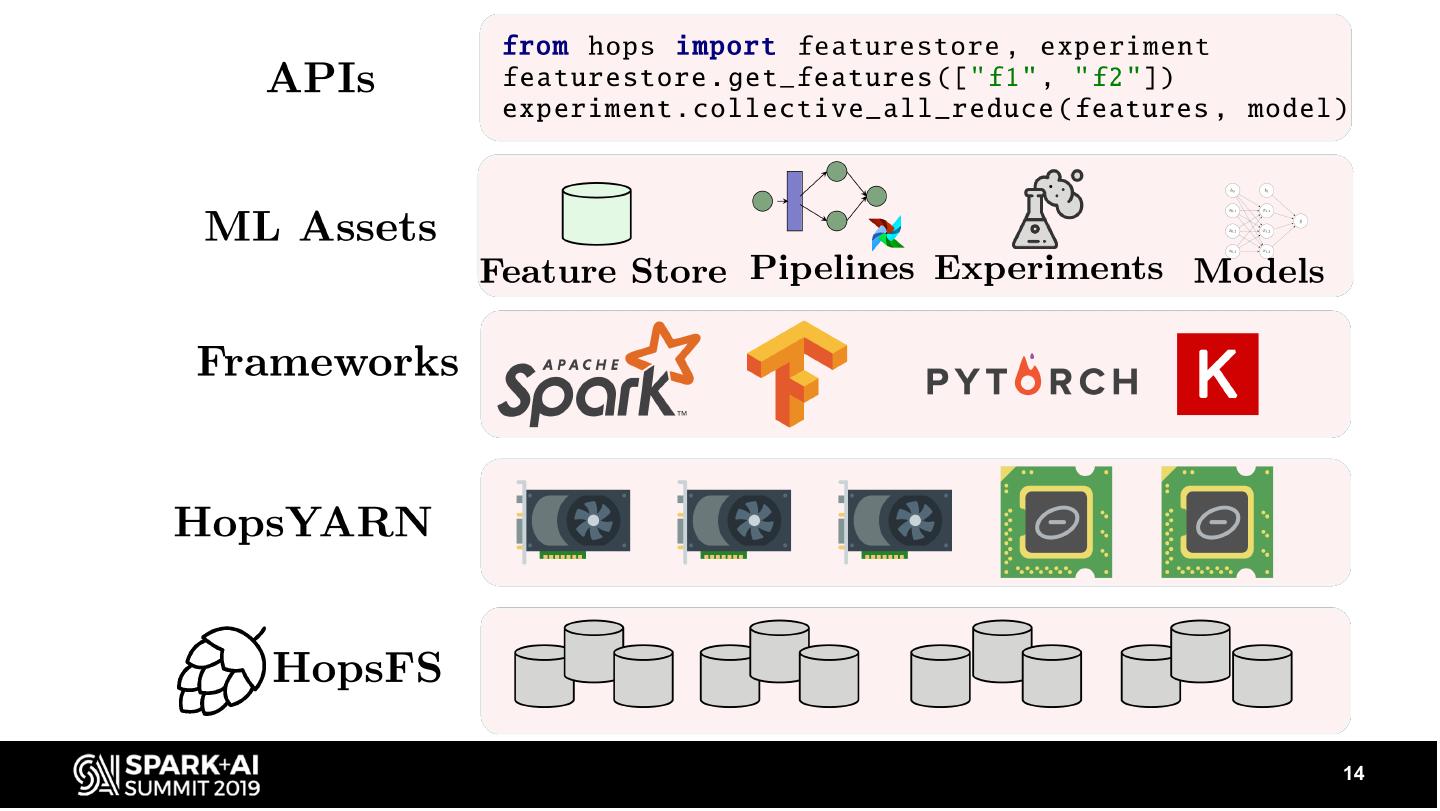
9 . Hops works
Orches tration in Airflow
Batch Dis tributed Model
ML & DL Serving
Apache Beam
Apache Spark Pip Kubernetes
Conda
Tensorflow
s cikit-learn
Hops works Applications
Datas ources Keras
Feature Store API
Strea ming J upyter Model Das hboards
Notebooks Monitoring
Apache Bea m Kafka +
Apache Spark Tensorboard Spark
Apache Flink Streaming
Files ys tem and Metada ta s tora ge
Hops FS
Data Preparation Experimentation Deploy
& Inges tion & Model Training & Productionalize
9
�
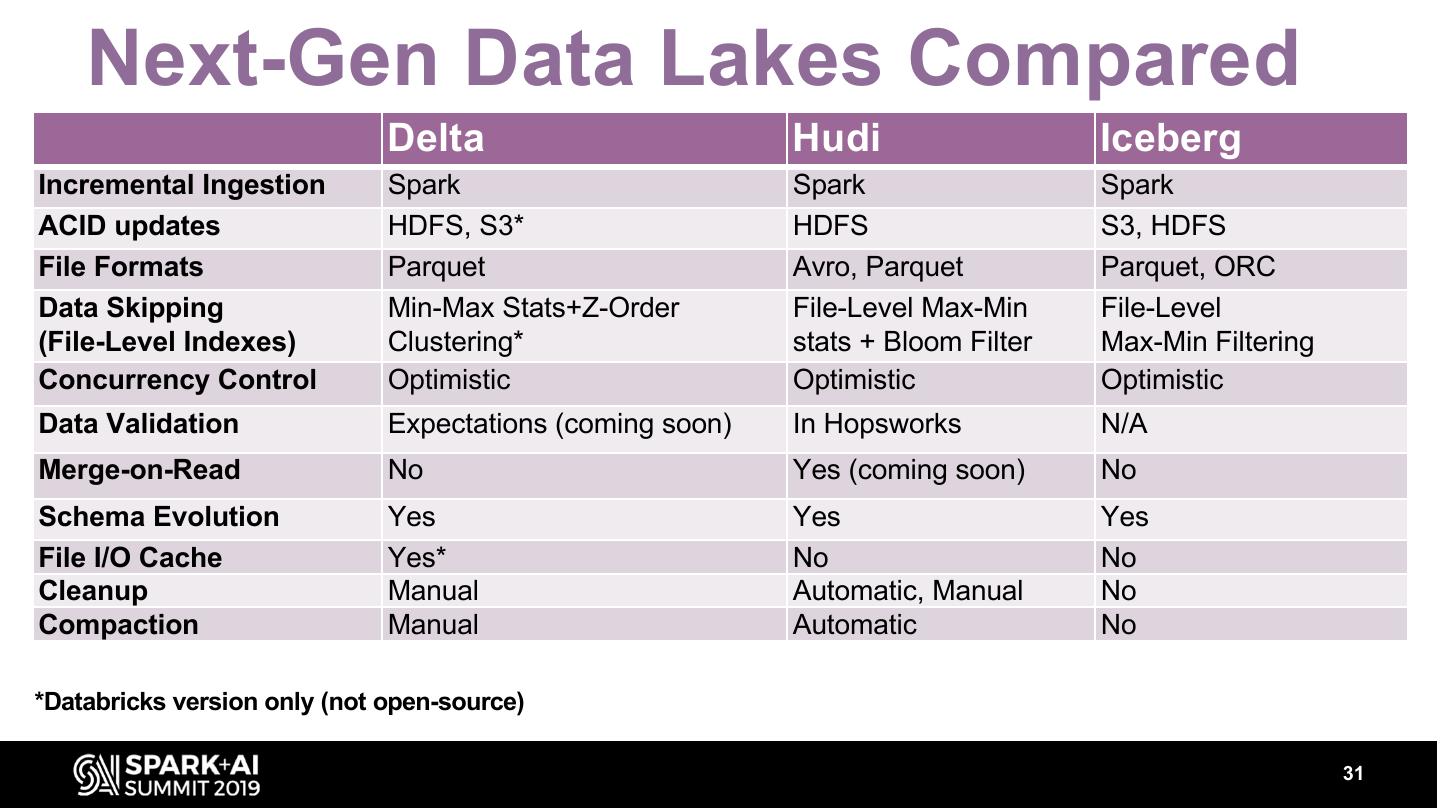
16 .Next-Gen Data Lakes
Data Lakes are starting to resemble databases:
– Apache Hudi, Delta, and Apache Iceberg add:
• ACID transactional layers on top of the data lake
• Indexes to speed up queries (data skipping)
• Incremental Ingestion (late data, delete existing records)
• Time-travel queries
16
�
17 .Problems: No Incremental Updates, No rollback
on failure, No Time-Travel, No Isolation.
17
�
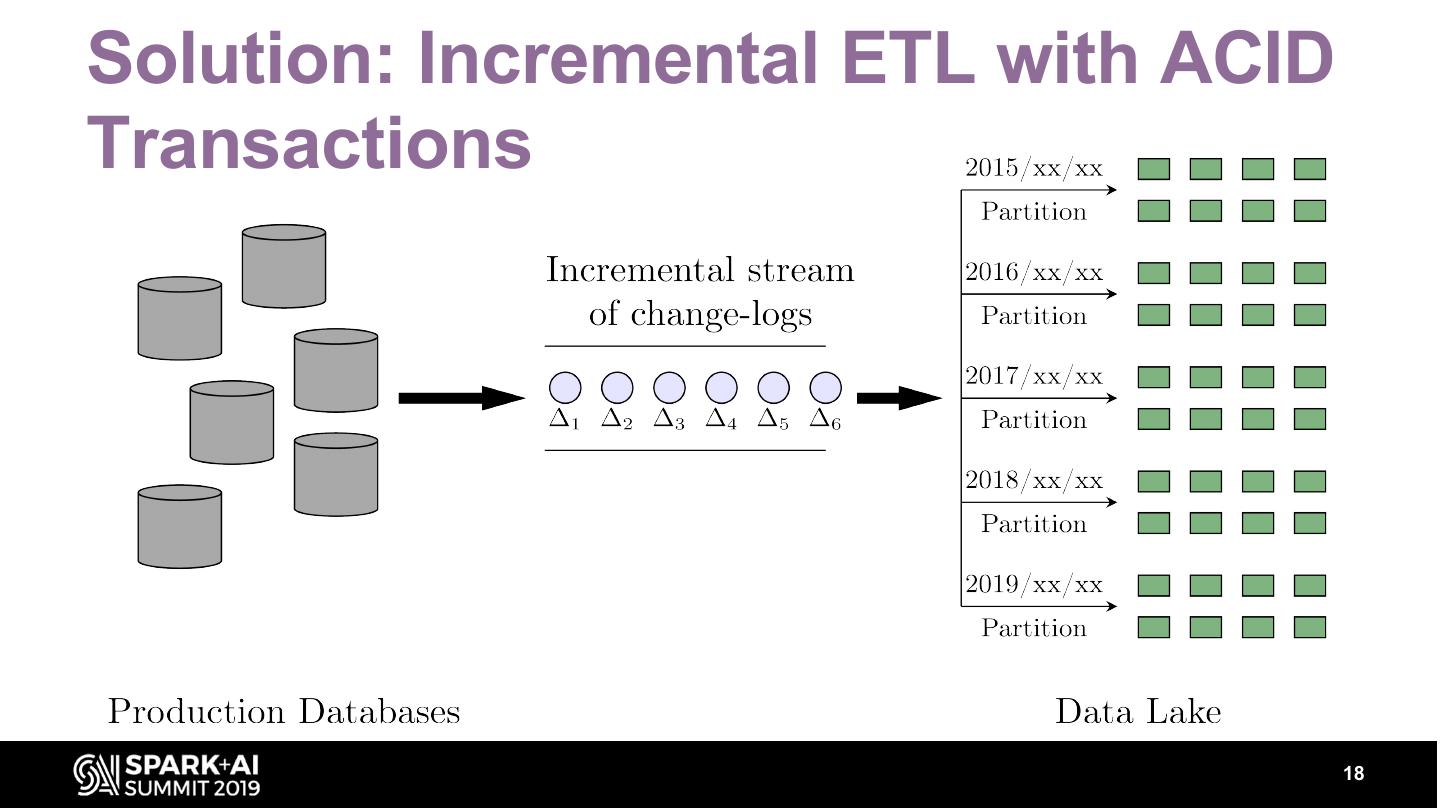
18 .Solution: Incremental ETL with ACID
Transactions
18
�
19 .Upsert & Time Travel Example
19
�
20 .Upsert & Time Travel Example
20
�
21 .Upsert ==Insert or Update
21
�
22 .Version Data By Commits
22
�
23 .Delta Lake by Databricks
• Delta Lake is a Transactional Layer that sits on
top of your Data Lake:
– ACID Transactions with Optimistic Concurrency
Control
– Log-Structured Storage
– Open Format (Parquet-based storage)
– Time-travel
23
�
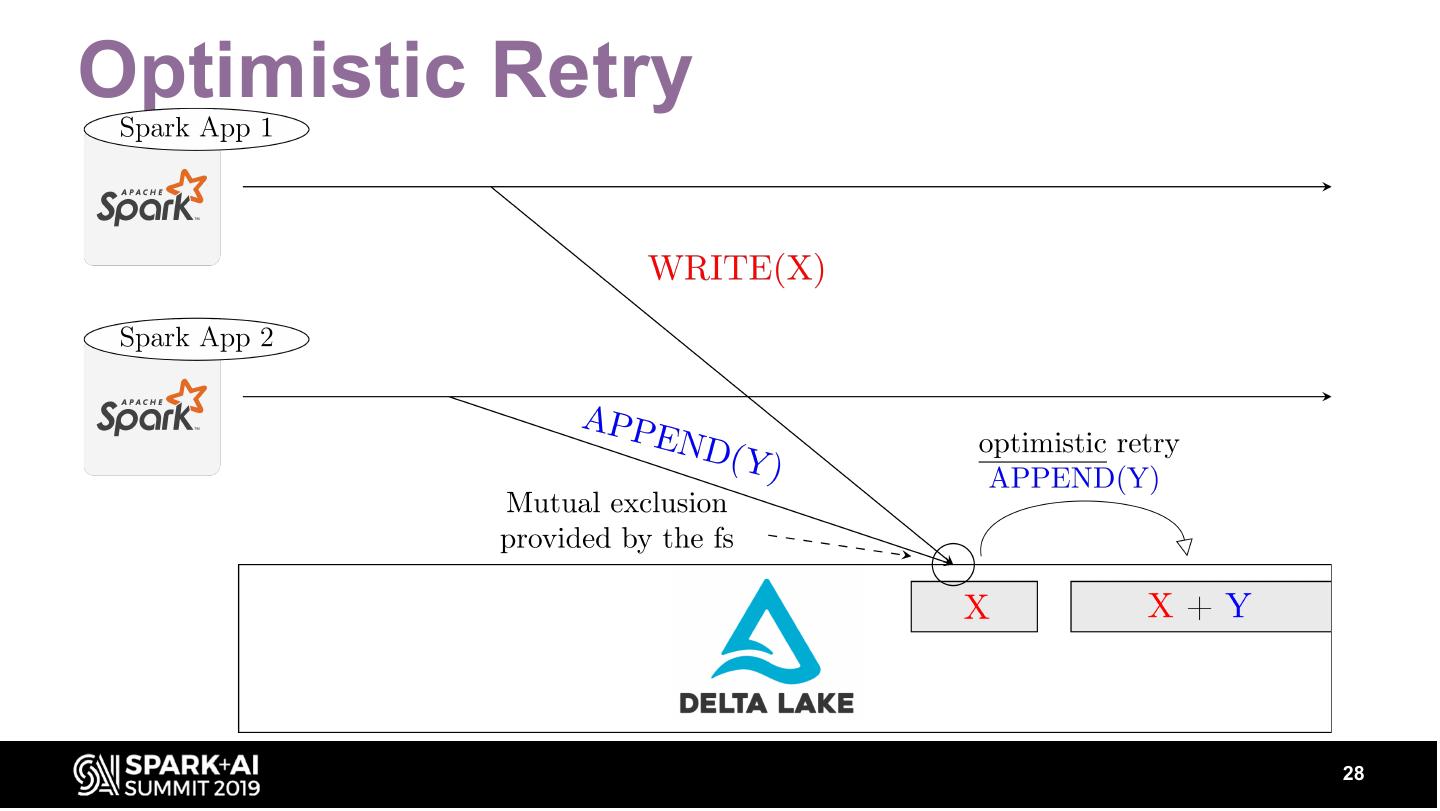
25 .Optimistic Concurrency Control
25
�
26 .Optimistic Concurrency Control
26
�
27 .Mutual Exclusion for Writers
27
�
29 .Scalable Metadata Management
29
�