

























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Deploying Enterprise Scale Deep Learning in Actuarial Modeling at Nationwide
“The traditional approach to insurance pricing involves fitting a generalized linear model (GLM) to data collected on historical claims payments and premiums received. The explosive growth in data availability and increasing competitiveness in the marketplace are challenging actuaries to find new insights in their data and make predictions with more granularity, improved speed and efficiency, and with tighter integration among business units to support strategic decisions.
In this session we will share our experience implementing deep hierarchical neural networks using TensorFlow and PySpark on Databricks. We will discuss the benefits of the ML Runtime, our experience using the goofys mount, our process for hyperparameter tuning, specific considerations for the large dataset size and extreme volatility present in insurance data, among other topics.”
展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
2 .Deploying Enterprise Scale Deep Learning in Actuarial Modeling Krish Rajaram & Bryn Clarke, Nationwide Insurance #UnifiedAnalytics #SparkAISummit
3 .Agenda • About Nationwide • About Enterprise Data Office • Nationwide’s journey with Databricks • Use case deep dive #UnifiedAnalytics #SparkAISummit 3
4 .Nationwide Ranks with the Best in 457 retirement plans, based 8th largest auto insurer 1 A.M. Best, 2016 DWP on number of plans PLANSPONSOR, 2017 Recordkeeping Survey Total small business insurer # Conning, 2014; Conning Strategic Study: The Small Business Sector for Property-Casualty Insurance: Market Shift Coming Writer of farms and ranches #1 writer of corporate life 7th largest commercial 8th largest life insurer A.M. Best, 2016 DWP IBIS Associates, Inc., February 2018 lines insurer LIMRA, YE 2016. Based on total premiums A.M. Best, 2016 DWP 2nd largest #1 pet insurer Domestic specialty (Excess & Surplus) commercial lines insurer #9 provider North American Pet Health Insurance Assn., 2016 A.M. Best, 2016 DWP of defined contribution retirement plans 7th largest Nationwide is committing more than PLANSPONSOR, 2017 Recordkeeping Survey 7th largest writer of variable $100 million homeowners insurer A.M. Best, 2016 DWP annuities Morningstar, YE 2016, Based on total flows Of venture capital to invent and reinvent customer-centric solutions.
5 .Fortune 100 Company FORTUNE 100 Best Companies to Work For $49 billion in total sales/direct written premium 2018 Catalyst Award honoree $26.9 billion in net operating revenue Black Enterprise 50 Best Companies for Diversity $1.2 billion in net operating income Human Rights Campaign Best Place to Work for $225.5 billion in total assets LGBTQ Equality A+ A.M. Best received 10/17/2002 A+ Standard & Poor’s received 12/22/2008 A1 Moody’s received 3/10/2009 affirmed 10/2/2017 affirmed 5/24/2017 affirmed 11/7/2017
6 .Lines of Business FINANCIAL SERVICES COMMERCIAL LINES PERSONAL LINES Individual Life Standard Commercial Standard Auto Annuities Farm and Ranch Homeowners and Renters Retirement Plans Commercial Agribusiness Pet Corporate Life Excess and Sport Vehicles Mutual Funds Surplus/Specialty Personal Liability Banking
7 .Enterprise Data Office Purpose: Mission: The EDO is dedicated to empowering the business of Give data a voice Nationwide by delivering trusted solutions through complete data & analytics services. Chief Data Officer (CDO) Data Governance Data Analytics Data Advisory Data Architecture and Quality Data Management and Decision Services and Strategy Assurance Sciences Manages relationships with Oversees and optimizes data Owns the One Nationwide Manages Enterprise data Deploys data and analytics our IT and business integrity, availability, usability, data strategy, enabling the allowing for insights into tools and processes to solve partners and trustworthiness Enterprise’s ability to leverage business activities, enabling complex business problems. data as a competitive asset achievement of business goals
8 .Analytical Lab IT Architecture team identified the growing need for a minimally governed, self-provisioned scalable environment for conducting analytical experiments. Databricks Notebook Model Feature training Start/Create EDA/ Data Engineer Communicate/ SSO Read Data Clusters Prep Export model Validate/ re-train Visualize Terminate the cluster 8
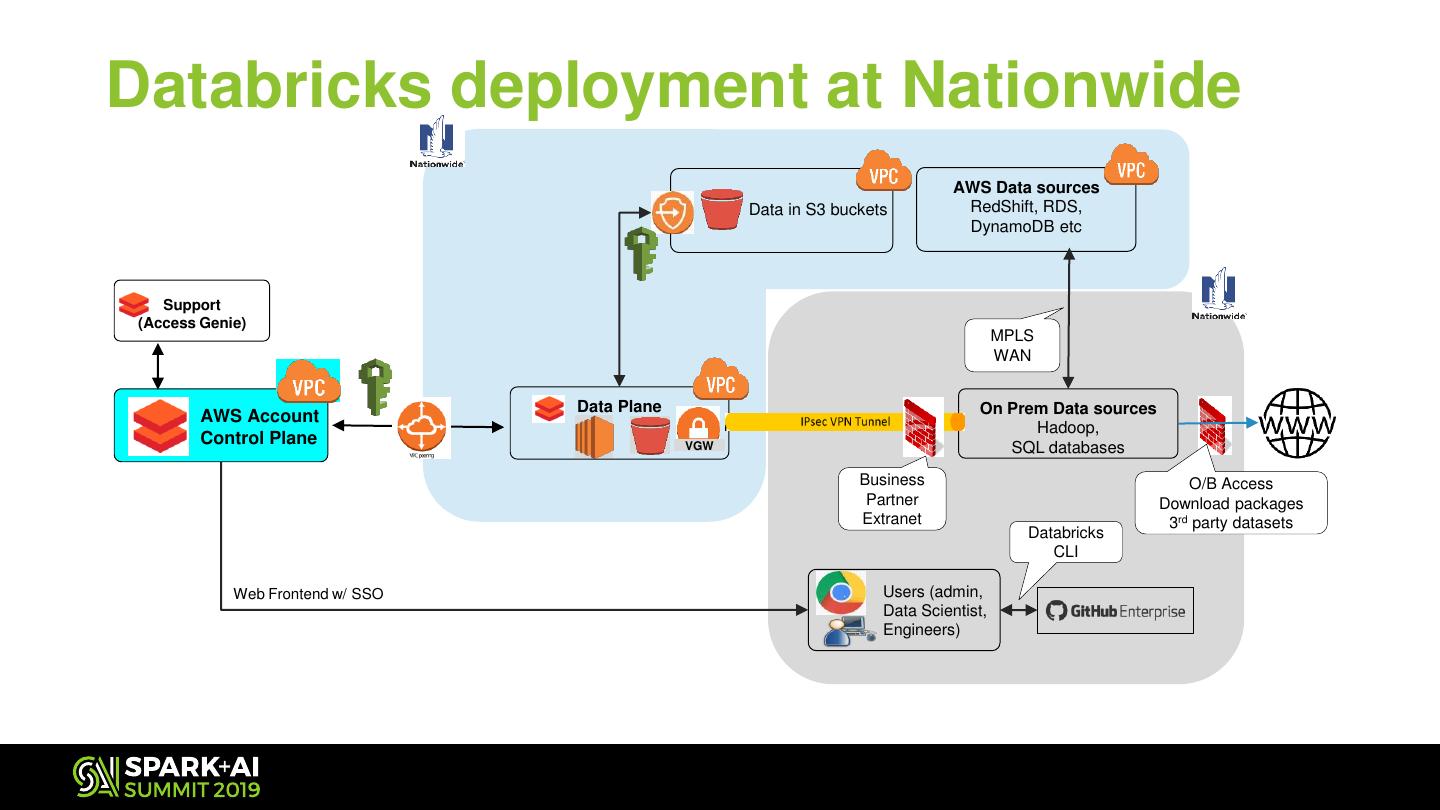
9 .Databricks deployment at Nationwide AWS Data sources Data in S3 buckets RedShift, RDS, DynamoDB etc Support (Access Genie) MPLS WAN Data Plane On Prem Data sources AWS Account Hadoop, Control Plane VGW SQL databases Business O/B Access Partner Download packages Extranet 3rd party datasets Databricks CLI Web Frontend w/ SSO Users (admin, Data Scientist, Engineers)
10 .Databricks adoption at Nationwide Information worker Data Analyst Data Engineer Data Scientist Use Cases 1-3 4-5 6+ 1-3 4-5 6+ 1-3 4-5 6+ 1-3 4-5 6+ Number of tools Number of tools Number of tools Number of tools 2 Standard Emerging Specialized Standard Emerging Specialized Standard Emerging Specialized Standard Emerging Specialized 1 5 Tools Tools Tools Tools Well Known Variable Well Known Variable Well Known Variable Well Known Variable Data Sources Data Sources Data Sources Data Sources Efficiency gain De-risk Not applicable Experiment Dev Prod Experiment Dev Prod Experiment Dev Prod Revenue Generating Databricks adoption Databricks adoption Databricks adoption Databricks adoption Excel Access SAS R & R Studio Python & Jupyter SAS/ SAS Grid Tableau Paxata Python/R IBM SPSS H2O, DriverlessAI Tensorflow SQL Hadoop/Hive/Spark/Zeppelin SQL 10
11 .Enterprise Analytics Office Utilizing methodologies to accelerate decision-making... We deliver wisdom in data Statistical AI & Experimental Modeling & by interacting with partners Modeling Machine Learning Design Forecasting to translate problems into • Bayesian Hierarchical • Ensembled Machine • Text & Speech Analytics analytical solutions • Modeling Segmentation Modeling • Learning Traditional Statistical • GPU Acceleration • Recommender • Survivor Modeling Learning What is the tangible benefit of our data • Regression • Model-as-Service • Deep Learning product solutions? • Time Series Forecasting • Tailored support combing business knowledge & statistical expertise ...by leveraging cutting edge data & technology • Easy understanding of the data for instant & actionable usability Data Technology • Automated & seamless access that • Nationwide internal • Financial • R • Java integrates with your processes data • Macro-economic • Python • SPSS • Scalable utility solving advanced analytical • Social Modeler • H20 problems across domains • Demographic • Tensorflow • Tableau • Geographic 11
12 .Focus Use Case • Predict insurance claims frequency and severity (average cost of claims) • Large dataset (100s of millions of records) • Volatile data – Insurance claims are infrequent – Most often arise due to chance #UnifiedAnalytics #SparkAISummit 12
13 .Traditional Approach • Batch (1-5 years) of data aggregated across linear predictors (state, vehicle model year, driver age, etc.) • Trained actuary fits a Generalized Linear Model (GLM) to determine slope/intercept for each linear predictor • Result is a multiplicative “rating plan” #UnifiedAnalytics #SparkAISummit 13
14 .Novel Approach • Deep learning (hierarchical neural network) • Adequately models non-linearity of latent variables • Multiple heads – Frequency & Severity – Coverage Type & Cause of Loss • Compare to traditional GLM #UnifiedAnalytics #SparkAISummit 14
15 .Performance Evaluation • Custom loss functions – Poisson, Gamma negative loglikelihood • Custom metric functions – Normalized Gini index / AUC • Online monitoring using TensorBoard #UnifiedAnalytics #SparkAISummit 15
16 .Model Search Space is Vast • Size and number of layers • Embedding dimensionality • Activation functions (ReLU, tanh, linear) • Regularization (L1/L2, dropout) • Many others (autoencoder, combining levels of prediction, skip connections, etc.) #UnifiedAnalytics #SparkAISummit 16
17 .Why Spark? • Many aspects of preprocessing are embarrassingly parallel – Conversion between data formats (SAS, CSV, Parquet, TFRecords) – Encoding of category labels • Scoring is also embarrassingly parallel • Primary limitation is hyperparameter/model configuration search #UnifiedAnalytics #SparkAISummit 17
18 .Why Spark? sas7bdat spark-sas7bdat pandas csv parquet NumPy memmap Spark SQL featurized parquet featurized Python memmap PySpark LOCAL BATCHES TFRecords DISTRIBUTED #UnifiedAnalytics #SparkAISummit 18
19 .Benchmark Timings Local Workstation Spark CSV Conversion 10-12 hrs < 5 mins Random Shuffling ~ 8 hrs < 5 mins Featurization ~ 5 hrs 20 mins TFRecords Examples ~ 5 hrs < 5 mins Model Training ~ 6 hrs ~ 3 hrs (single node*) Model Scoring ~ 3 hrs < 5 mins * Utilizing Spark we are able to test many model configurations concurrently. In a local workstation environment, each configuration needs to be tested consecutively. #UnifiedAnalytics #SparkAISummit 19
20 .Lessons Learned • Loading/exporting data • Conversion of the model from Keras to TensorFlow • Initializing TensorFlow models on individual nodes • Using goofys mounts • Syncing with DBFS to store model checkpoints • Utilizing Databricks Jobs/notebook parameters #UnifiedAnalytics #SparkAISummit 20
21 .Conclusion & Next Steps • Utilizing Spark on Databricks with ML runtime we reduced the modeling pipeline timings from ~ 34 hours to less than 4hrs • Further opportunity exists in utilizing Horovod for multi-GPU training – Reduce time needed to evaluate individual model configurations #UnifiedAnalytics #SparkAISummit 21
22 .General Observation • Using Databricks ML Runtime, Notebooks, scalable compute instances and scheduling features we were able to rapidly prototype the methodology. • Work in progress for Path to production and integration with current Model deployment framework. • Challenging to predict DBU consumption by different business units; hence difficult to forecast cost. • No automatic integration with GitHub enterprise. #UnifiedAnalytics #SparkAISummit 22
23 .Questions? #UnifiedAnalytics #SparkAISummit 23
24 .DON’T FORGET TO RATE AND REVIEW THE SESSIONS SEARCH SPARK + AI SUMMIT
3秒后跳转登录页面
去登陆

