展开查看详情
1 .Deploying end-to-end
deep learning
pipelines with ONNX
—
Nick Pentreath
Principal Engineer
@MLnick
�
2 .About
– @MLnick on Twitter & Github
– Principal Engineer, IBM CODAIT (Center for
Open-Source Data & AI Technologies)
– Machine Learning & AI
– Apache Spark committer & PMC
– Author of Machine Learning with Spark
– Various conferences & meetups
IBM Developer / © 2019 IBM Corporation 2
�
3 .Center for Open Source
Data & AI Technologies
CODAIT aims to make AI solutions dramatically
easier to create, deploy, and manage in the
CODAIT
enterprise.
We contribute to and advocate for the open-source
technologies that are foundational to IBM’s AI
offerings.
Improving the Enterprise AI Lifecycle in Open Source
30+ open-source developers!
IBM Developer / © 2019 IBM Corporation 3
�
4 .The Machine Learning
Workflow
IBM Developer / © 2019 IBM Corporation 4
�
5 .Perception
IBM Developer / © 2019 IBM Corporation 5
�
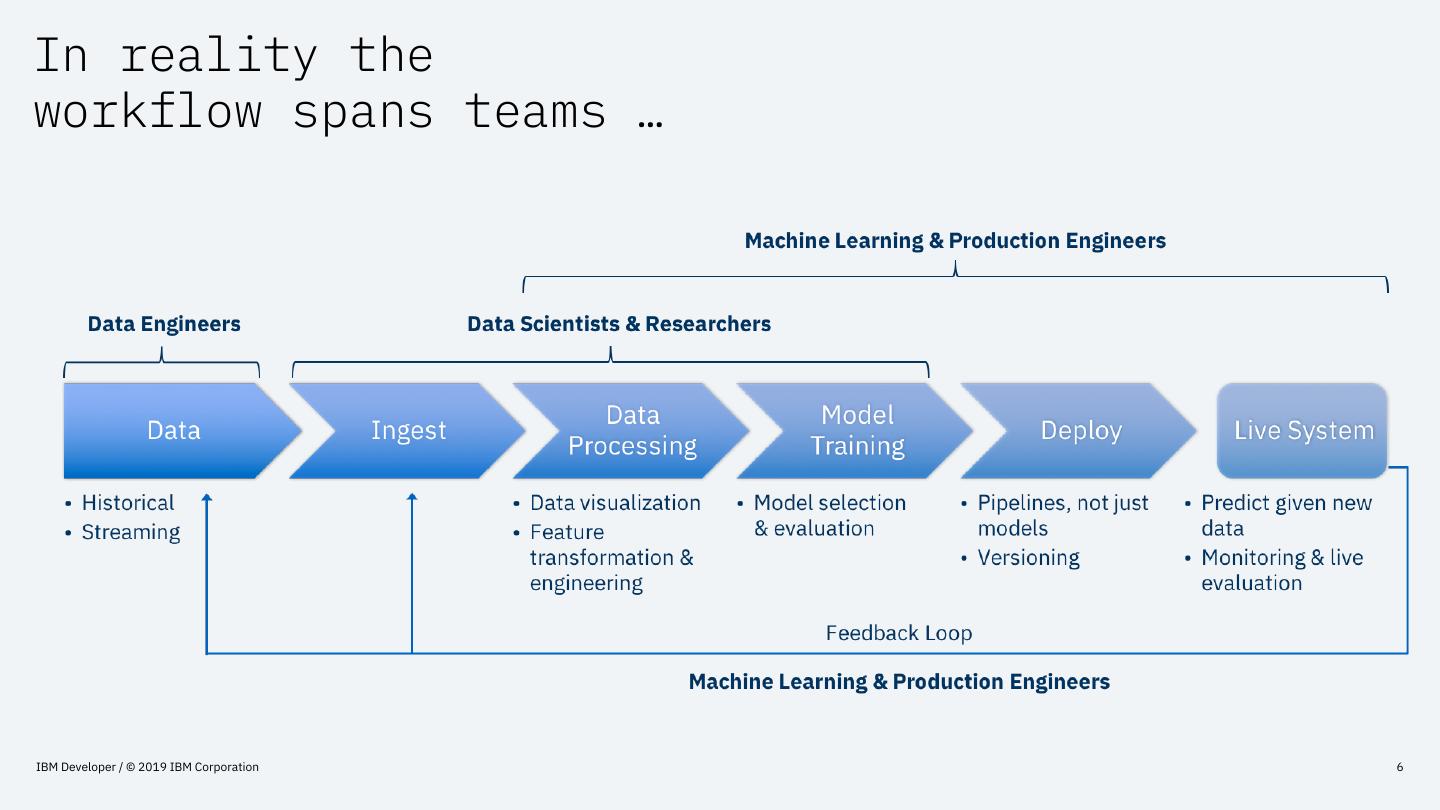
6 .In reality the
workflow spans teams …
IBM Developer / © 2019 IBM Corporation 6
�
7 .… and tools …
IBM Developer / © 2019 IBM Corporation 7
�
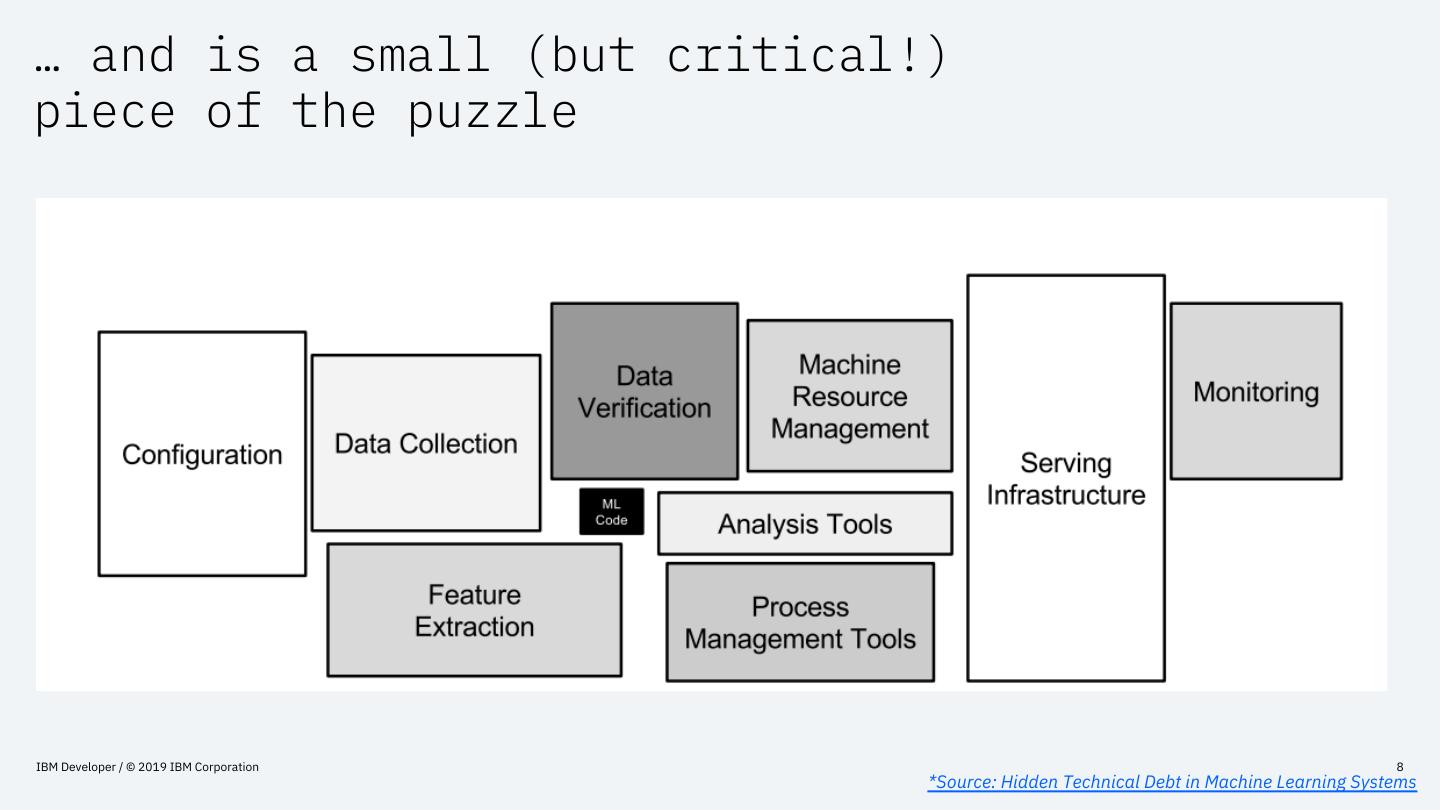
8 .… and is a small (but critical!)
piece of the puzzle
IBM Developer / © 2019 IBM Corporation 8
*Source: Hidden Technical Debt in Machine Learning Systems
�
9 .Machine Learning
Deployment
IBM Developer / © 2019 IBM Corporation 9
�
10 .What, Where, How?
– What are you deploying?
• What is a “model”
We will talk mostly about the what
– Where are you deploying?
• Target environment (cloud, browser, edge)
• Batch, streaming, real-time?
– How are you deploying?
• “devops” deployment mechanism
• Serving framework
IBM Developer / © 2019 IBM Corporation 10
�
11 .What is a “model”?
IBM Developer / © 2019 IBM Corporation 11
�
12 .Deep Learning doesn’t need
feature engineering or data
processing …
right?
IBM Developer / © 2019 IBM Corporation 12
�
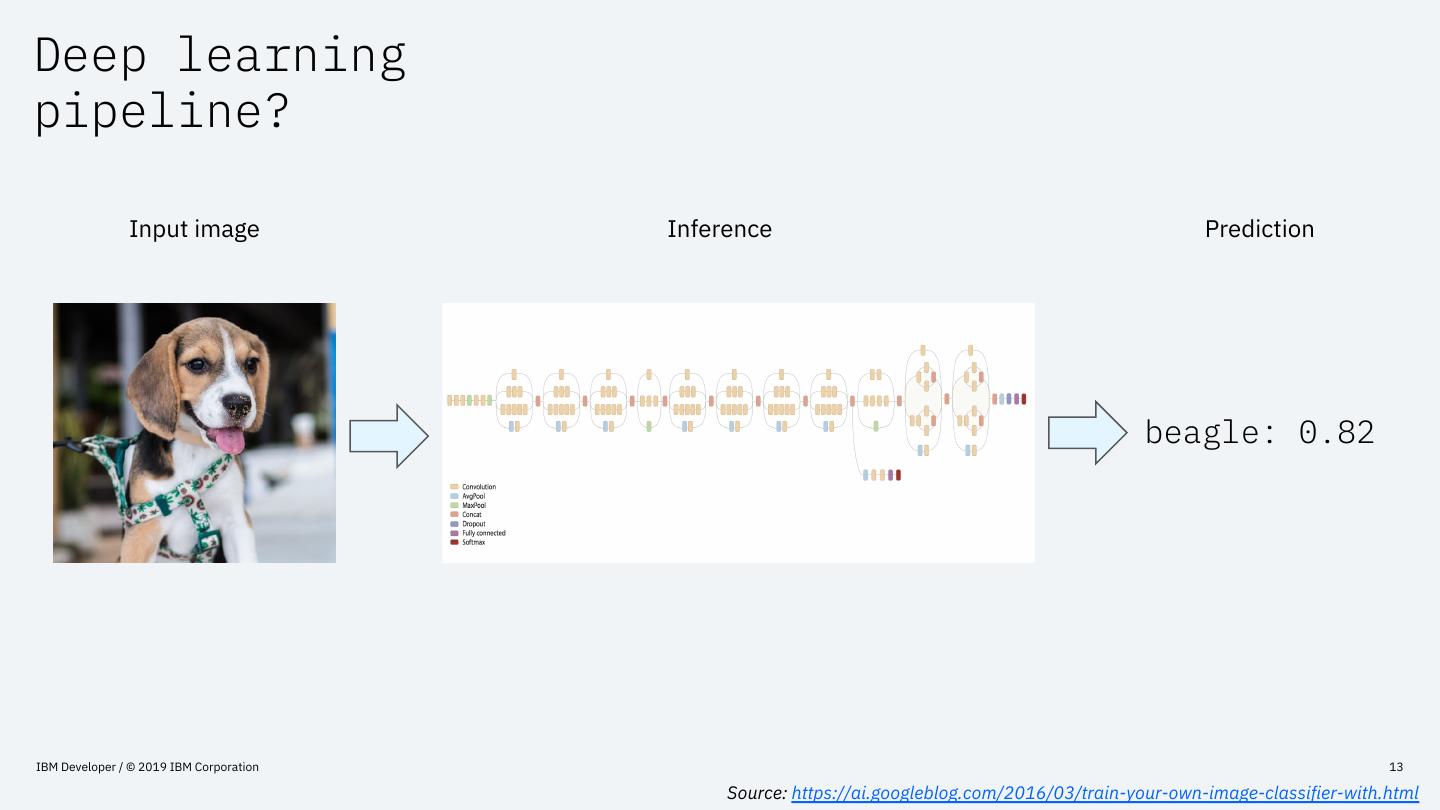
13 .Deep learning
pipeline?
Input image Inference Prediction
beagle: 0.82
IBM Developer / © 2019 IBM Corporation 13
Source: https://ai.googleblog.com/2016/03/train-your-own-image-classifier-with.html
�
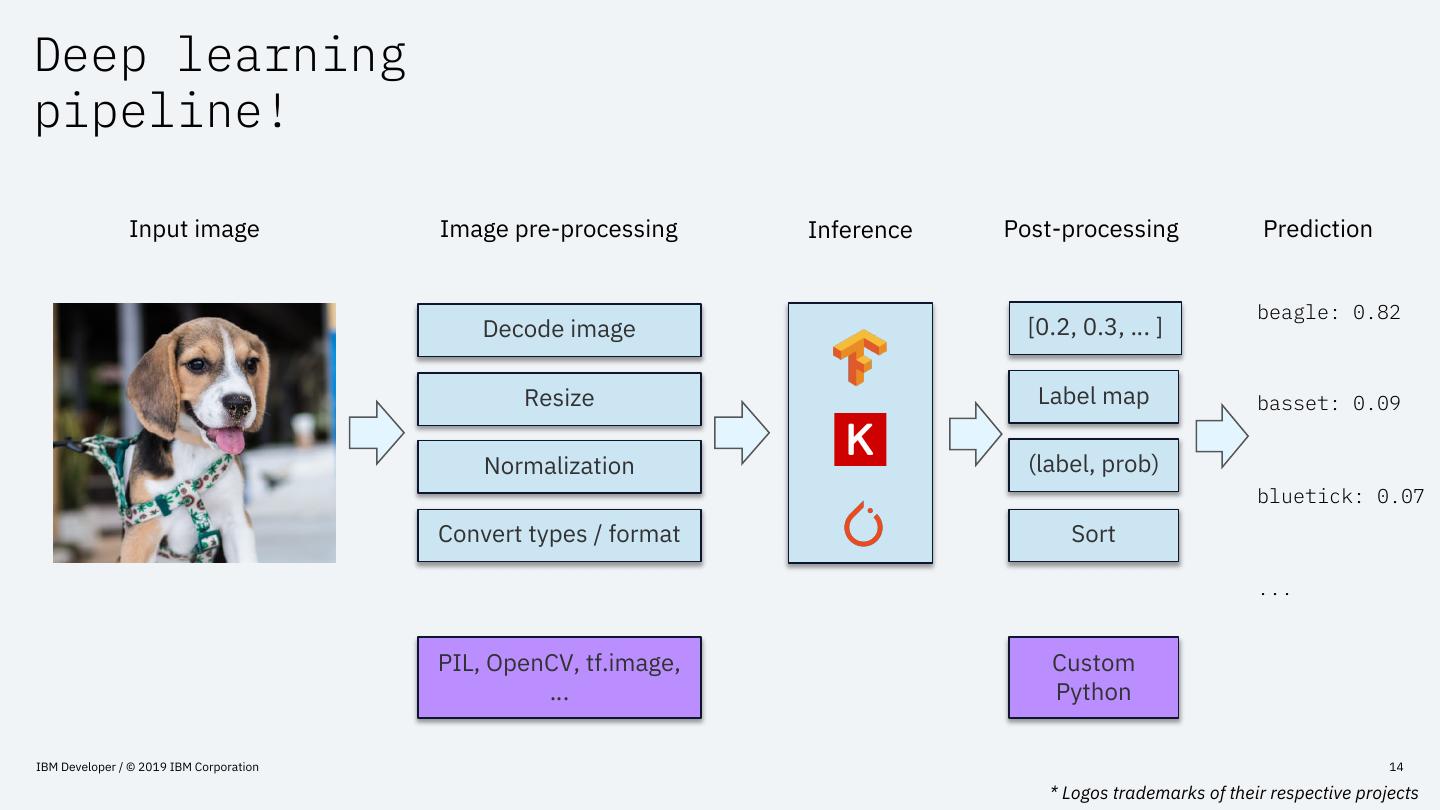
14 .Deep learning
pipeline!
Input image Image pre-processing Inference Post-processing Prediction
beagle: 0.82
Decode image [0.2, 0.3, … ]
Resize Label map basset: 0.09
Normalization (label, prob)
bluetick: 0.07
Convert types / format Sort
...
PIL, OpenCV, tf.image, Custom
… Python
IBM Developer / © 2019 IBM Corporation 14
* Logos trademarks of their respective projects
�
15 .Image pre-processing
Decoding lib PIL vs OpenCV vs tf.image vs skimage
libJPEG vs OpenCV
INTEGER_FAST vs INTEGER_ACCURATE
Decode image
RGB BGR
Resize
Color mode cat: 0.45
Normalization
vs
Convert types / format beagle: 0.34
Data layout
NCHW vs NHWC
IBM Developer / © 2019 IBM Corporation 15
�
16 .Image pre-processing
Operation order
Normalize INT pixels (128) Convert Float32
Decode image
Resize
Convert Float32 Normalize float (0.5)
Normalization
Convert types / format
IBM Developer / © 2019 IBM Corporation 16
�
17 .Inference post-
processing
Convert to numpy array
[0.2, 0.3, … ]
Custom loading label mapping / vocab / …
Label map
TF SavedModel (assets)
(label, prob)
Keras decode_predictions
Sort Custom code
Custom code
IBM Developer / © 2019 IBM Corporation 17
�
18 .Pipelines, not Models
– Deploying just the model part of the – Pipelines in frameworks
workflow is not enough • scikit-learn
– Entire pipeline must be deployed • Spark ML pipelines
• Data transforms • TensorFlow Transform
• Feature extraction & pre-processing • pipeliner (R)
• DL / ML model
• Prediction transformation
– Even ETL is part of the pipeline!
IBM Developer / © 2019 IBM Corporation 18
�
19 .Challenges
– Need to manage and bridge many different: – Formats
• Languages - Python, R, Notebooks, Scala / Java / C • Each framework does things differently
• Frameworks – too many to count! • Proprietary formats: lock-in, not portable
• Dependencies – Lack of standardization leads to custom
• Versions solutions and extensions
– Performance characteristics can be highly
variable across these dimensions
– Friction between teams
• Data scientists & researchers – latest & greatest
• Production – stability, control, minimize changes,
performance
• Business – metrics, business impact, product must
always work!
IBM Developer / © 2019 IBM Corporation 19
* Logos trademarks of their respective projects
�
20 .Containers for ML
Deployment
IBM Developer / © 2019 IBM Corporation 20
�
21 .Containers are “The Solution”
… right?
– Container-based deployment has – But …
significant benefits • What goes in the container is still the most
• Repeatability important factor
• Ease of configuration • Performance can be highly variable across
language, framework, version
• Separation of concerns – focus on what, not
how • Requires devops knowledge, CI / deployment
pipelines, good practices
• Allow data scientists & researchers to use their
language / framework of choice • Does not solve the issue of standardization
• Container frameworks take care of (certain) • Formats
monitoring, fault tolerance, HA, etc. • APIs exposed
• A serving framework is still required on top
IBM Developer / © 2019 IBM Corporation 21
�
22 .Open Standards for
Model Serialization &
Deployment
IBM Developer / © 2019 IBM Corporation 22
�
23 .Why a standard?
Single stack
Execution
Standard
Optimization
Format
Tooling
(Viz, analysis, …)
IBM Developer / © 2019 IBM Corporation 23
�
24 .Why an Open Standard?
– Open-source vs open standard – However there are downsides
• Standard needs wide adoption and critical mass
– Open source (license) is only one to succeed
aspect • A standard can move slowly in terms of new
• OSS licensing allows free use, modification features, fixes and enhancements
• Inspect the code etc • Design by committee
• … but may not have any control • Keeping up with pace of framework development
– Open governance is critical
• Avoid concentration of control (typically by large
companies, vendors)
• Visibility of development processes, strategic
planning, roadmaps
IBM Developer / © 2019 IBM Corporation 24
�
25 .Open Neural Network Exchange
(ONNX)
– Championed by Facebook & Microsoft
– Protobuf for serialization format and type
specification
– Describes
• computation graph (inputs, outputs, operators) - DAG
• values (weights)
– In this way the serialized graph is “self-
contained”
– Focused on Deep Learning / tensor operations
– Baked into PyTorch from 1.0.0 / Caffe2 as the
serialization & interchange format
IBM Developer / © 2019 IBM Corporation 25
�
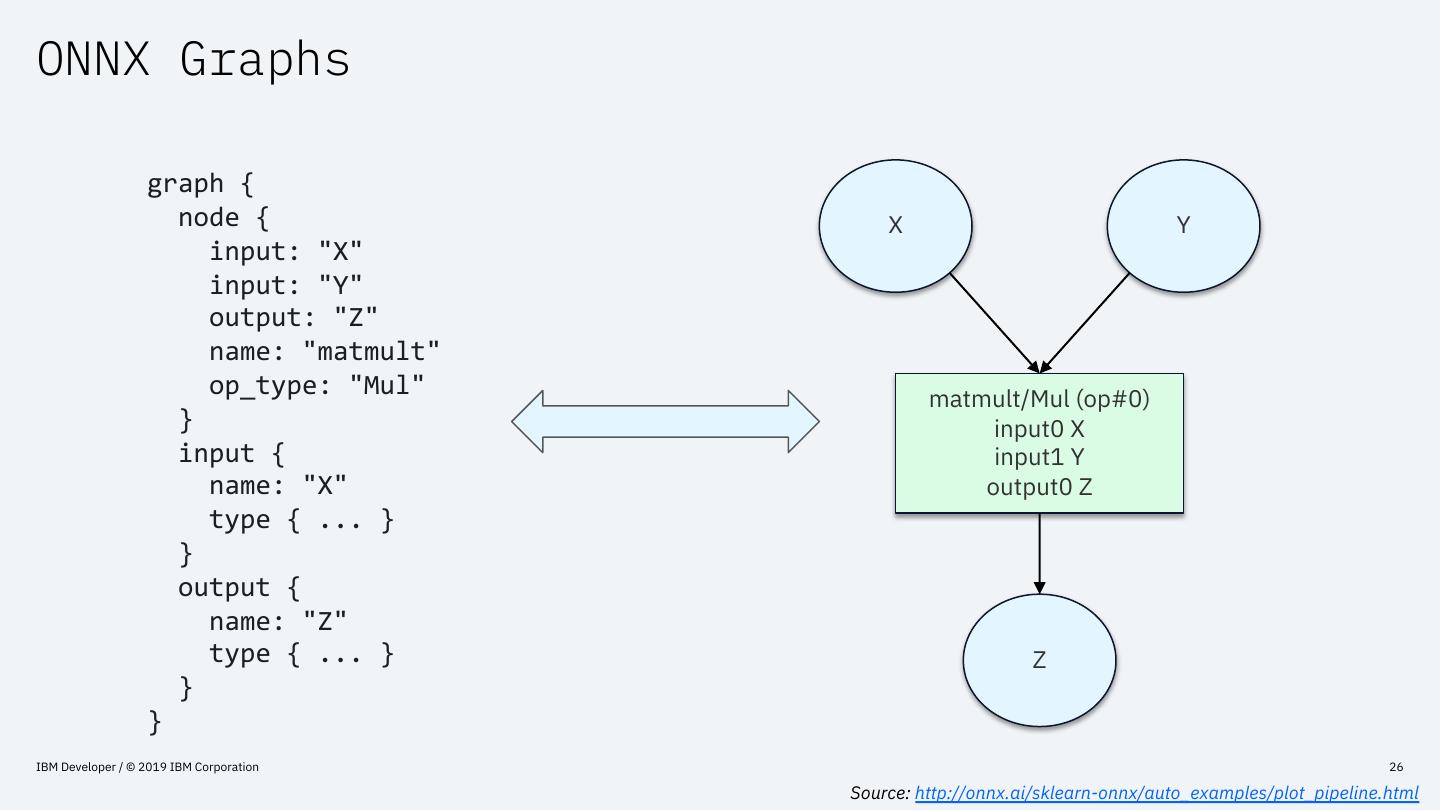
26 .ONNX Graphs
graph {
node { X Y
input: "X"
input: "Y"
output: "Z"
name: "matmult"
op_type: "Mul" matmult/Mul (op#0)
} input0 X
input { input1 Y
name: "X" output0 Z
type { ... }
}
output {
name: "Z"
type { ... } Z
}
}
IBM Developer / © 2019 IBM Corporation 26
Source: http://onnx.ai/sklearn-onnx/auto_examples/plot_pipeline.html
�
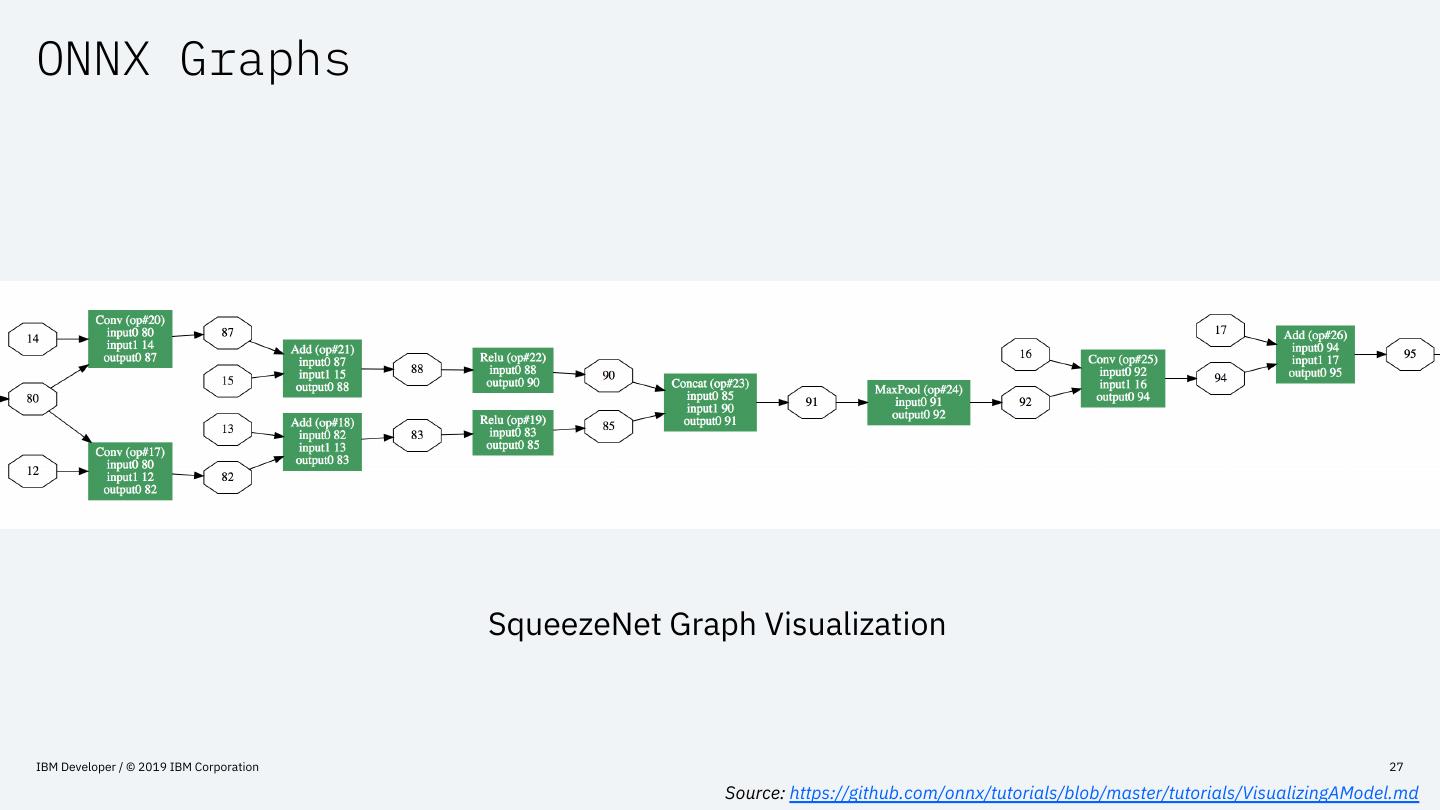
27 .ONNX Graphs
SqueezeNet Graph Visualization
IBM Developer / © 2019 IBM Corporation 27
Source: https://github.com/onnx/tutorials/blob/master/tutorials/VisualizingAModel.md
�
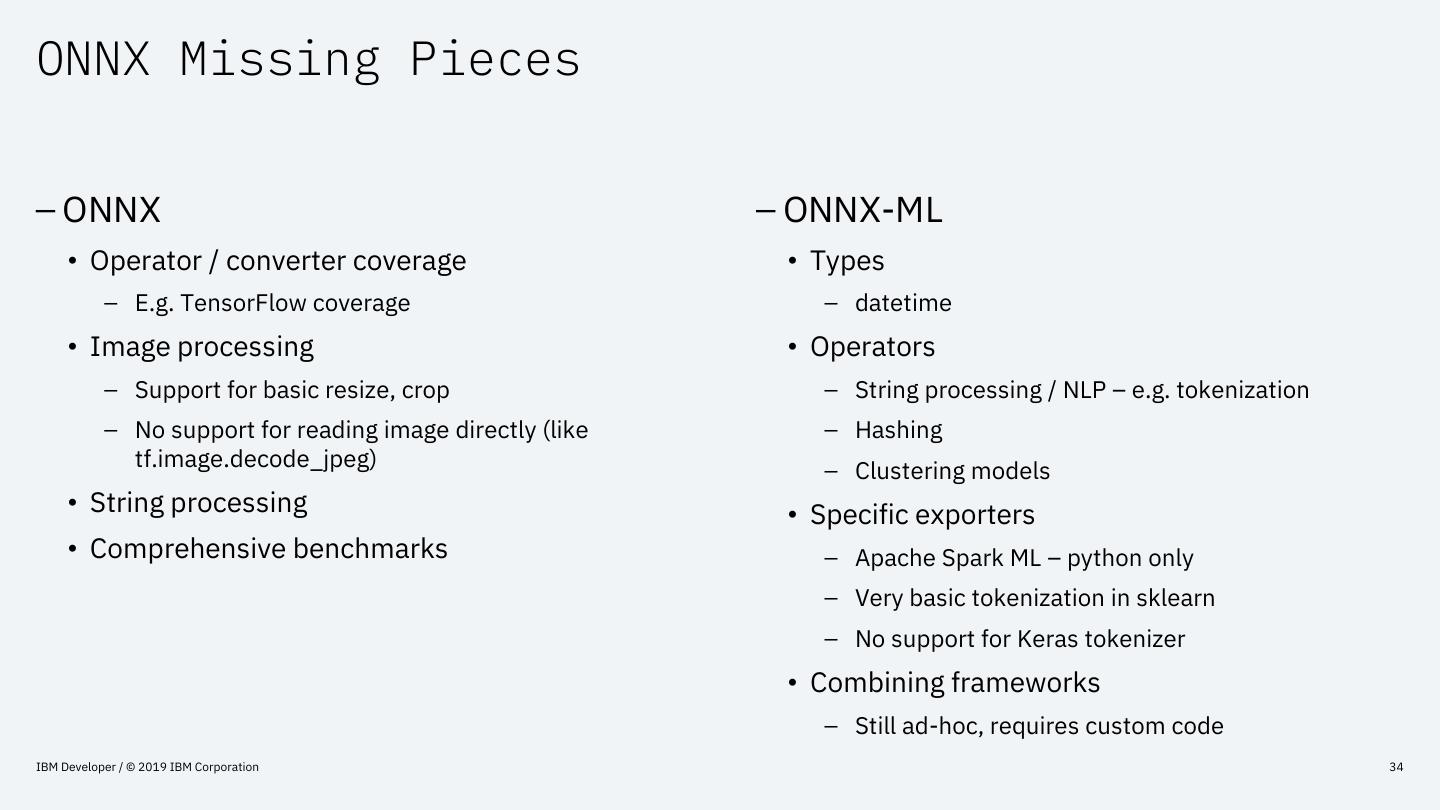
28 .ONNX-ML
– Provides support for (parts of)
“traditional” machine learning
• Additional types
– sequences
– maps
• Operators
• Vectorizers (numeric & string data)
• One hot encoding, label encoding
• Scalers (normalization, scaling)
• Models (linear, SVM, TreeEnsemble)
• …
https://github.com/onnx/onnx/blob/master/docs/Operators-ml.md
IBM Developer / © 2019 IBM Corporation 28
�
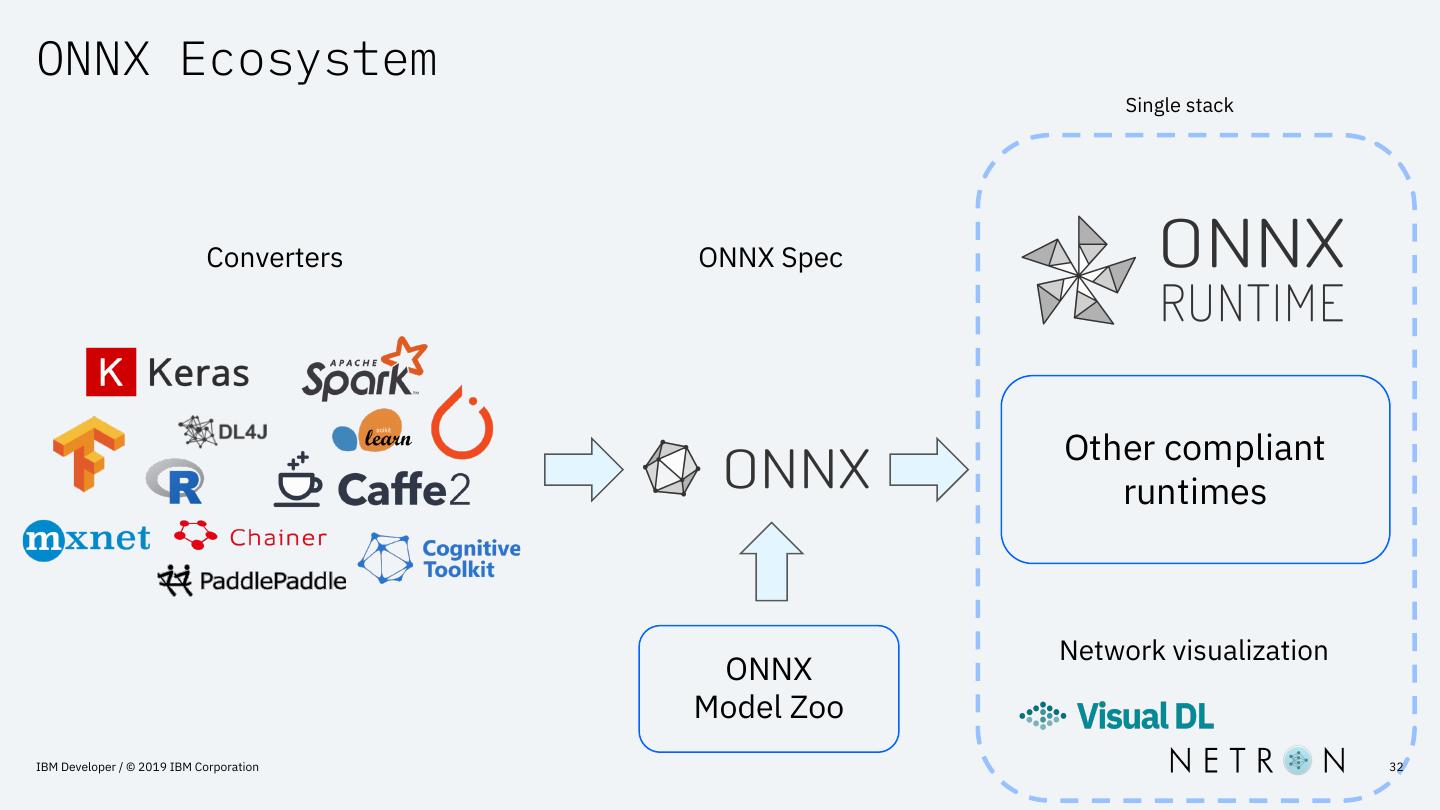
29 .ONNX-ML
– Exporter support
• Scikit-learn – 60+
• LightGBM
• XGBoost
• Apache Spark ML – 25+
• Keras – all layers + TF custom layers
• Libsvm
• Apple CoreML
https://github.com/onnx/onnxmltools/
http://onnx.ai/sklearn-onnx/index.html
https://github.com/onnx/keras-onnx
IBM Developer / © 2019 IBM Corporation 29
�