展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Data Warehousing with
Spark Streaming @
Zalando
Sebastian Herold, Zalando SE
#UnifiedDataAnalytics #SparkAISummit
�
3 . # Principal Data Engineer / Architect
# 7y @ Immo-/Scout24
# DataDevOps Manifesto
# Data Platform
Sebastian Herold # 2y @ Zalando
# ML Productivity
# Streaming DWH
@heroldamus
3 Data Warehousing with Spark Streaming
�
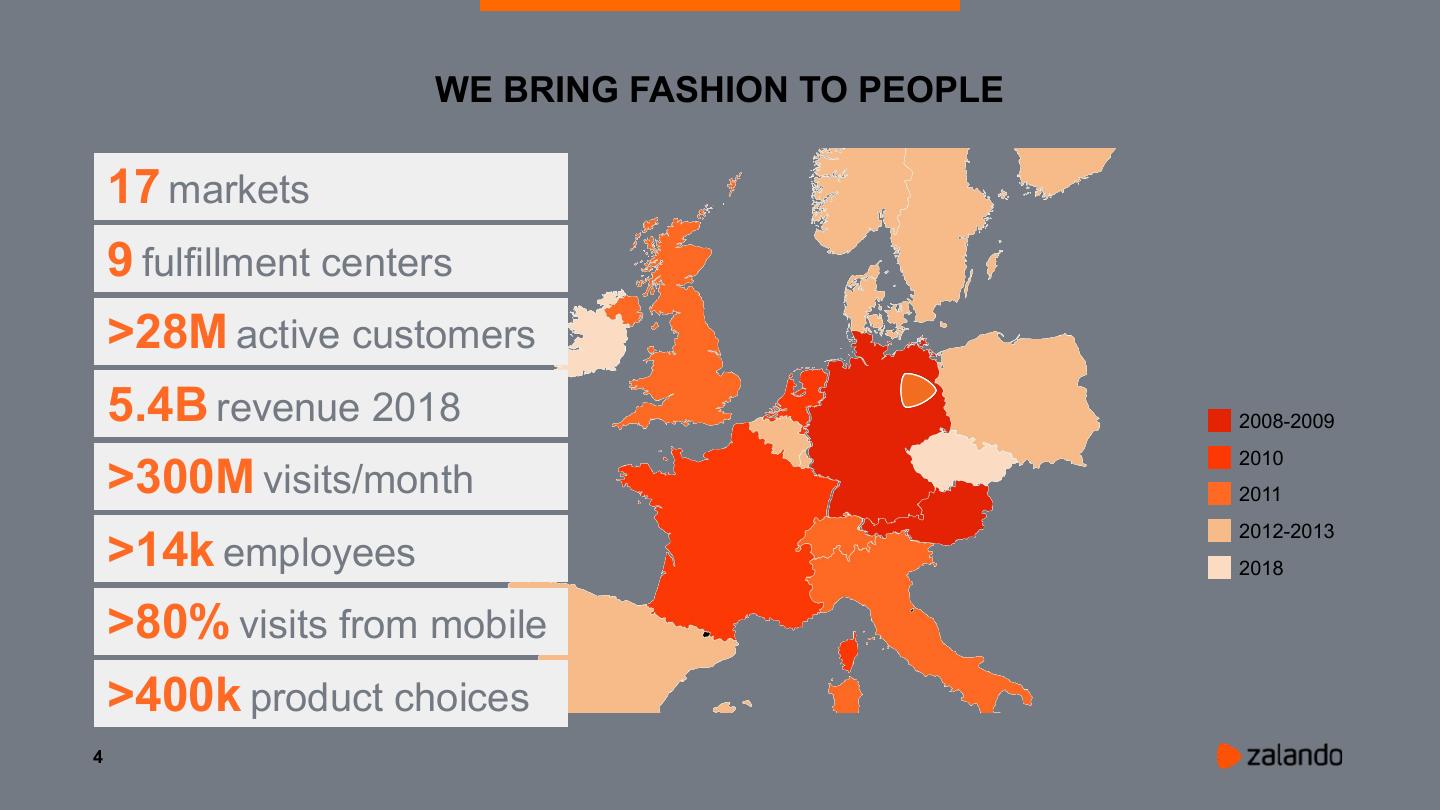
4 . WE BRING FASHION TO PEOPLE
17 markets
9 fulfillment centers
>28M active customers
5.4B revenue 2018 2008-2009
2010
>300M visits/month 2011
2012-2013
>14k employees 2018
>80% visits from mobile
>400k product choices
4
�
5 . TECH@SCALE
>350 accounts
>5 data lakes
API >100 clusters
>250 teams
>800 micro services
5 Data Warehousing with Spark Streaming - Spark + AI Summit Amsterdam ‘19
�
6 .WHY OUR CENTRAL DWH
DOES NOT SUCCEED
ANYMORE?
�
7 .DRAWBACKS OF CENTRAL DWH
HEAVY INTEGRATION OF
UNSTRUCTURED DATA
INTO RELATIONAL TABLES
�
8 .DRAWBACKS OF CENTRAL DWH
DATASETS ARE NEEDED
DISTRIBUTED
�
9 .DRAWBACKS OF CENTRAL DWH
LOWER LATENCY REQUIRED BY
AI USE-CASES,
OTHER DATA WAREHOUSES,
NEAR-REALTIME USE-CASES
�
10 . DRAWBACKS OF CENTRAL DWH
MULTIPLE TEAMS DO SAME
LOW-LATENCY EVENT INTEGRATION
�
11 . HEAVY INTEGRATION OF
DATASETS ARE NEEDED
UNSTRUCTURED DATA
STR
INTO RELATIONAL TABLES
DISTRIBUTED
EAM
LOWER LATENCY REQUIRED BY
AI USE-CASES,
ING
MULTIPLE TEAMS DO SAME
OTHER DATA WAREHOUSES, LOW-LATENCY EVENT
NEAR-REALTIME USE-CASES INTEGRATION
�
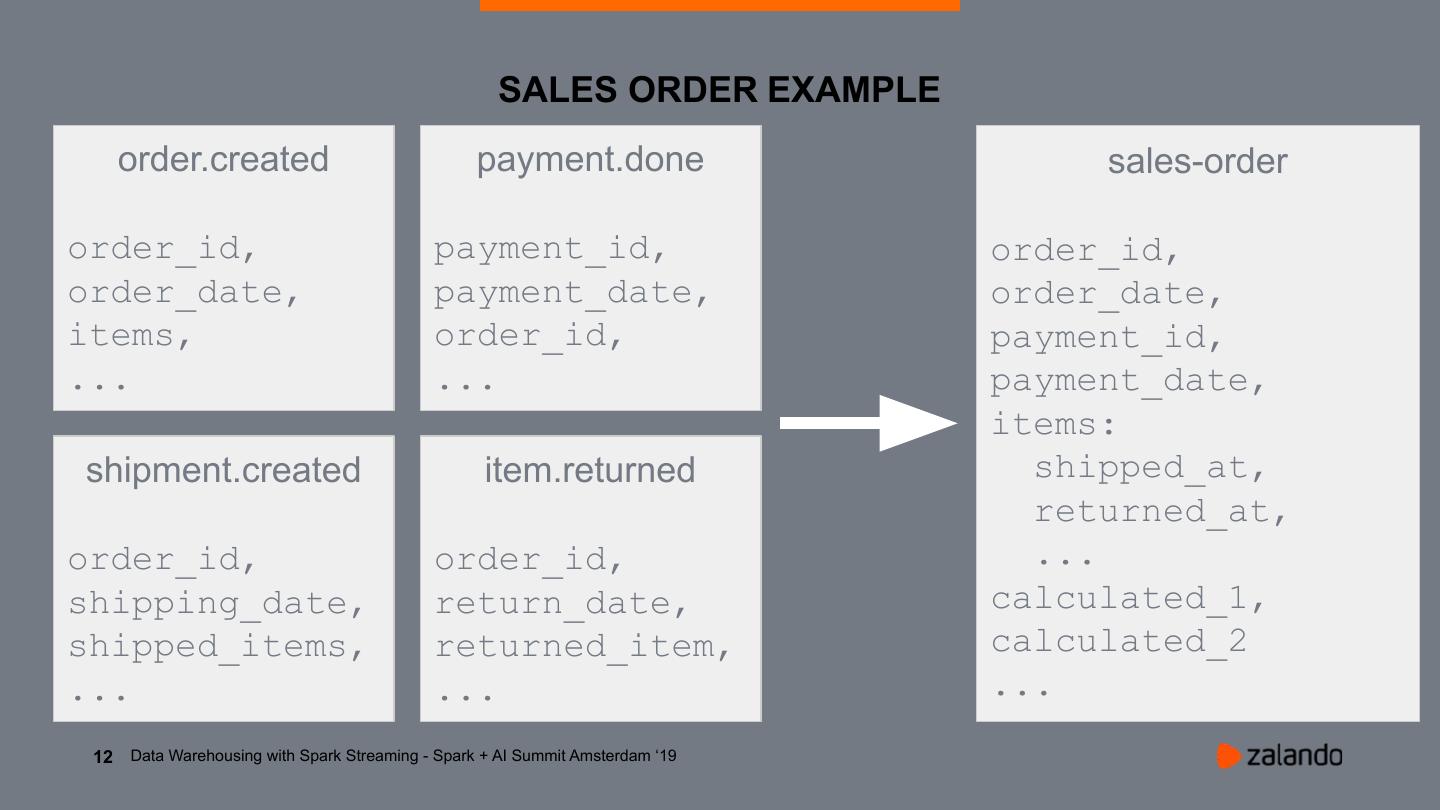
12 . SALES ORDER EXAMPLE
order.created payment.done sales-order
order_id, payment_id, order_id,
order_date, payment_date, order_date,
items, order_id, payment_id,
... ... payment_date,
items:
shipment.created item.returned shipped_at,
returned_at,
order_id, order_id, ...
shipping_date, return_date, calculated_1,
shipped_items, returned_item, calculated_2
... ... ...
12 Data Warehousing with Spark Streaming - Spark + AI Summit Amsterdam ‘19
�
13 . HOW WE STARTED?
Topics
nakadi.io
WAI S3
T!
Streaming
S3 Delta Table
Downstream
13 Data Warehousing with Spark Streaming - Spark + AI Summit Amsterdam ‘19
�
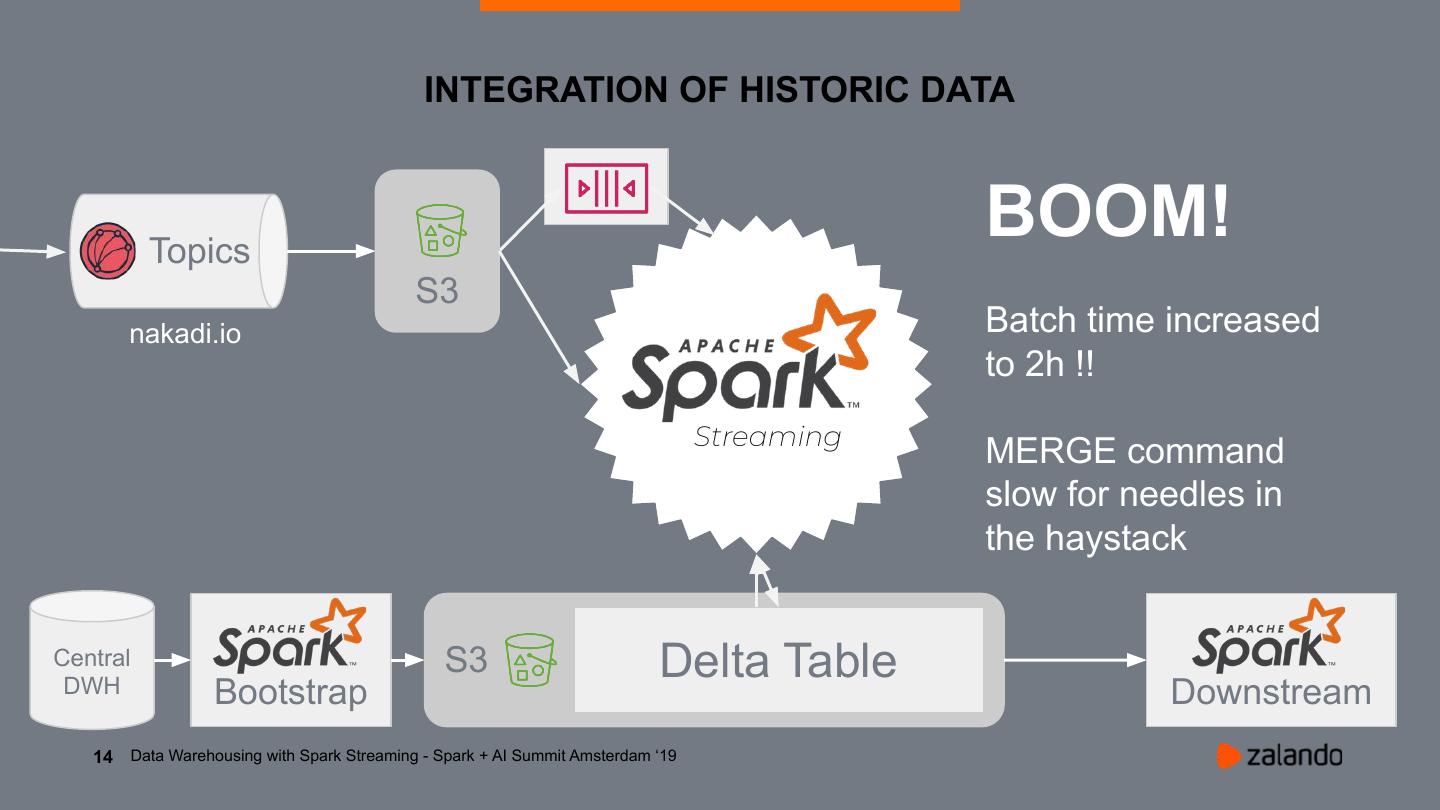
14 . INTEGRATION OF HISTORIC DATA
Topics
BOOM!
S3
nakadi.io Batch time increased
to 2h !!
Streaming
MERGE command
slow for needles in
the haystack
Central
DWH
S3 Delta Table
Delta Table
Bootstrap Downstream
14 Data Warehousing with Spark Streaming - Spark + AI Summit Amsterdam ‘19
�
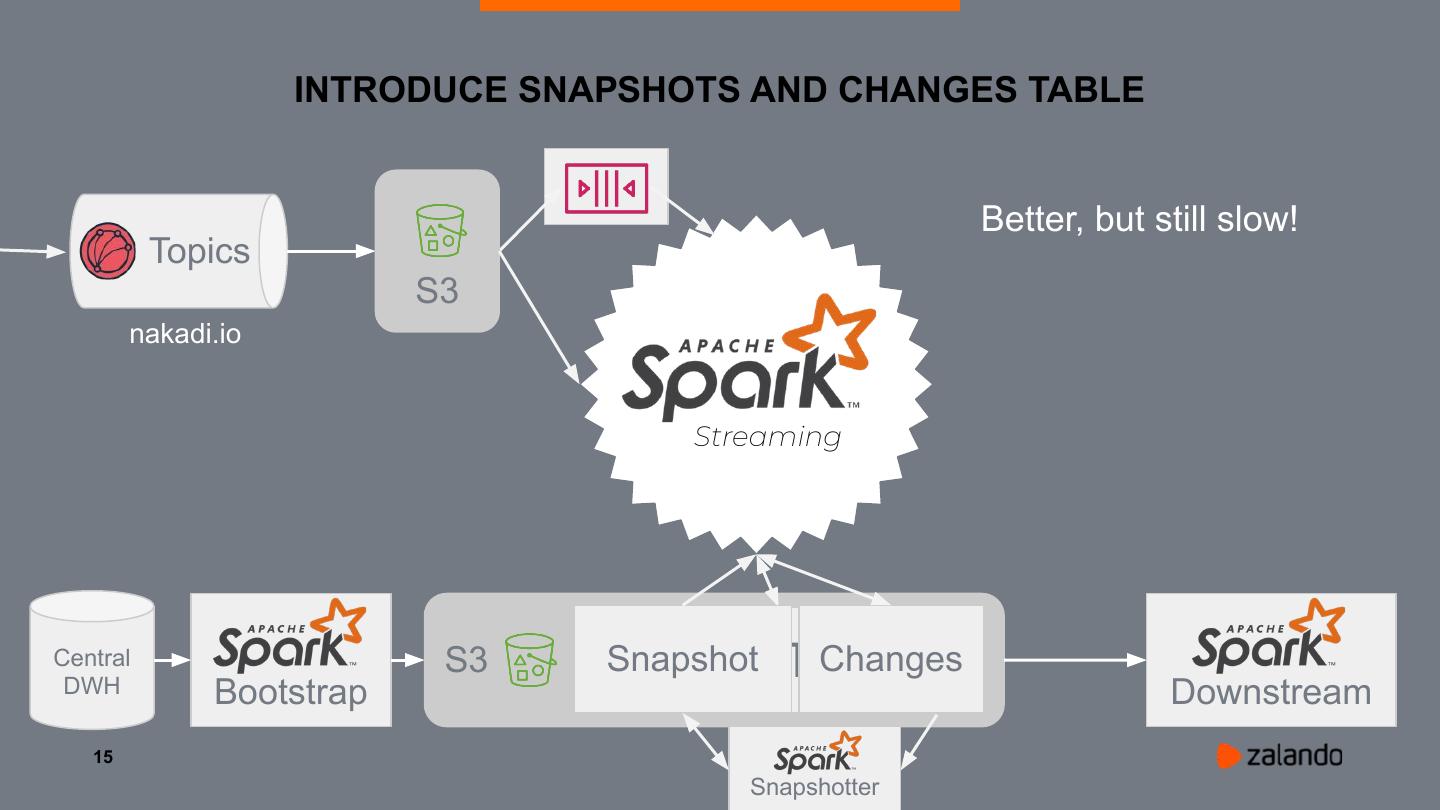
15 . INTRODUCE SNAPSHOTS AND CHANGES TABLE
Better, but still slow!
Topics
S3
nakadi.io
Streaming
Central
DWH
S3 Delta
Snapshot Table
Changes
Bootstrap Downstream
15
Snapshotter
�
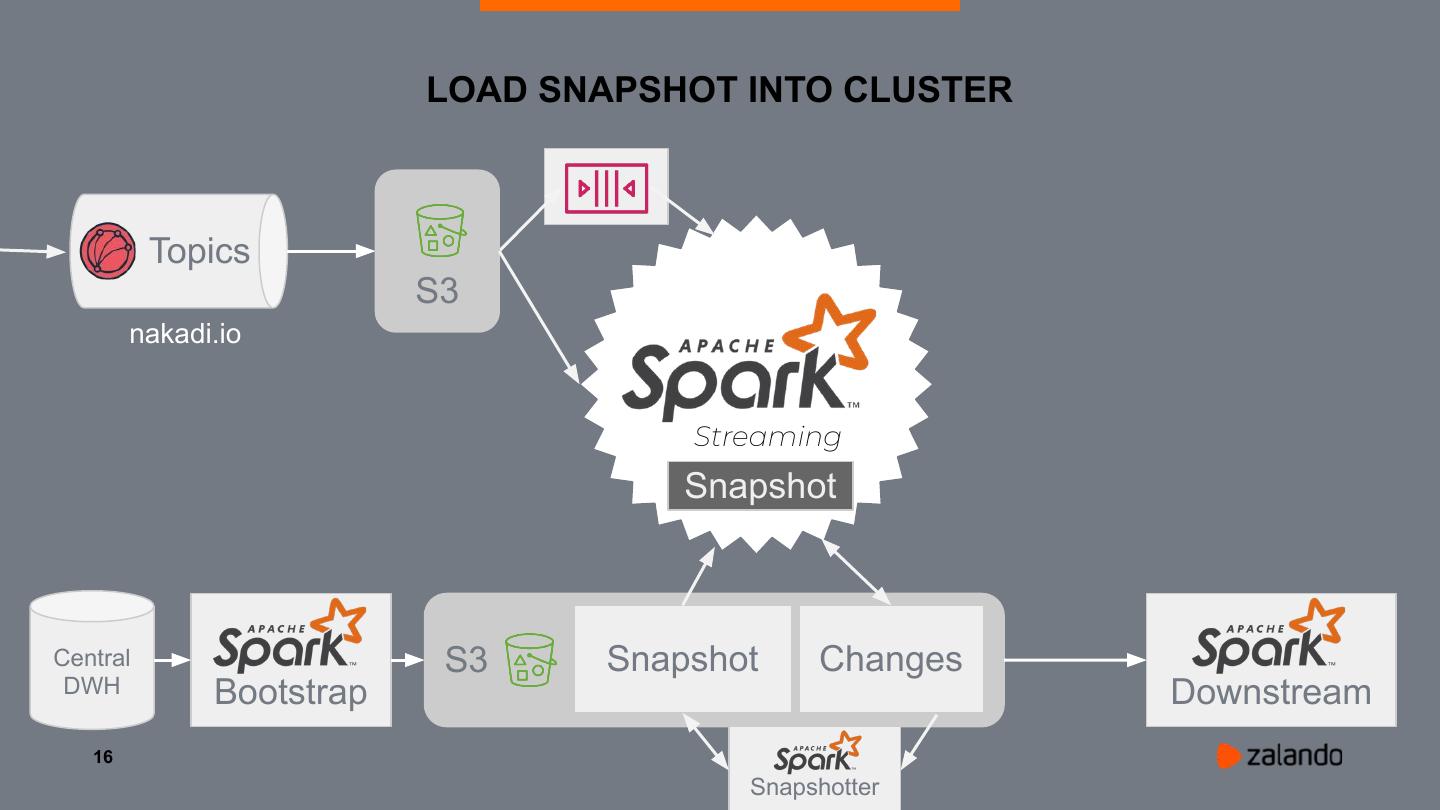
16 . LOAD SNAPSHOT INTO CLUSTER
Topics
S3
nakadi.io
Streaming
Snapshot
Central S3 Snapshot Changes
DWH Bootstrap Downstream
16
Snapshotter
�
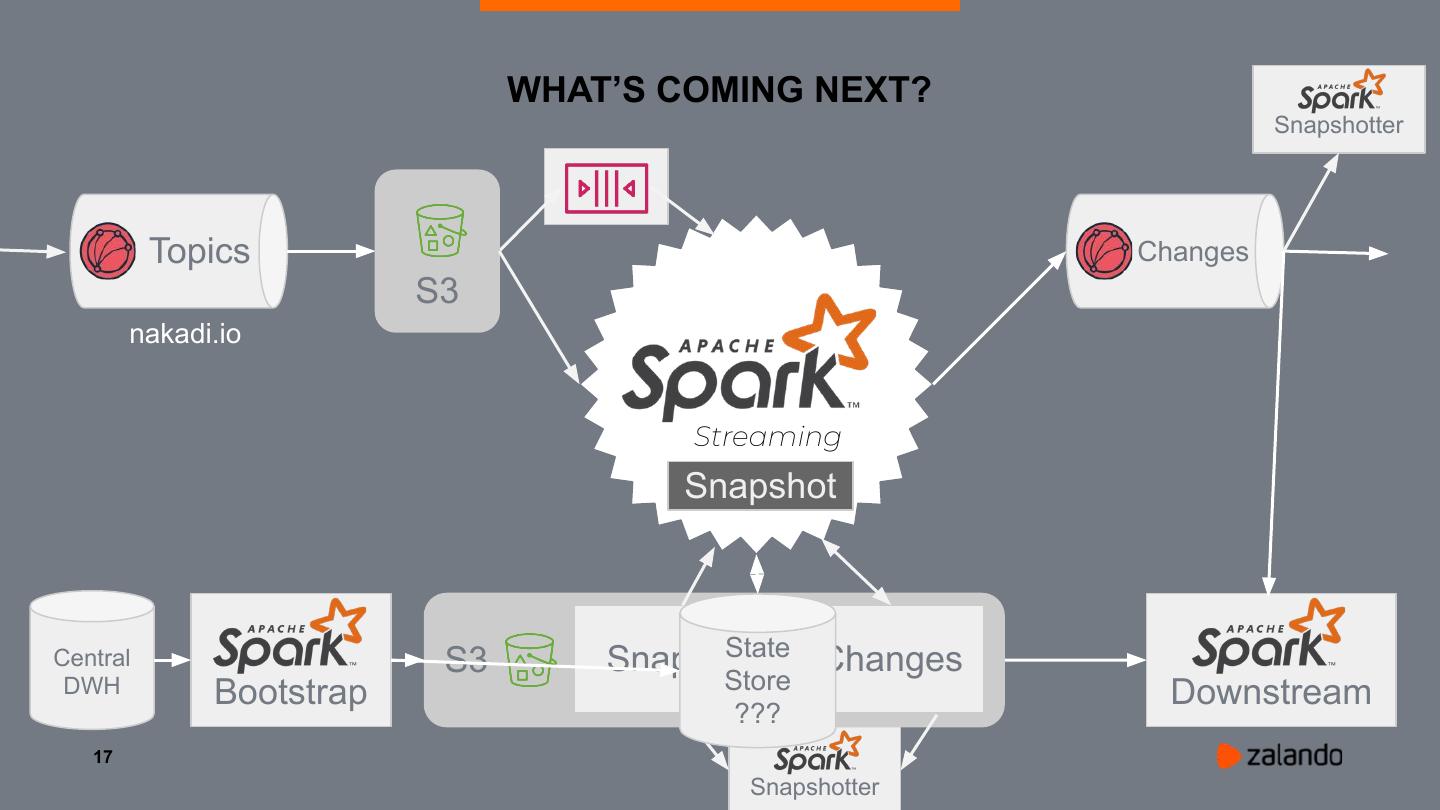
17 . WHAT’S COMING NEXT?
Snapshotter
Topics Changes
S3
nakadi.io
Streaming
Snapshot
State
Central S3 Snapshot Changes
DWH Bootstrap Store Downstream
???
17
Snapshotter
�
18 . SQL vs SCALA
# Started with 200 lines of SQL
LA # Grew fast to 400 lines
# Violated DRY principle
CA # Hard to unit-test
S # Hard to refactor
# Bad support for nested structures
18 Data Warehousing with Spark Streaming - Spark + AI Summit Amsterdam ‘19
�
19 . LESSONS LEARNED
# Streaming needs different thinking
# DWH ~ Backend Programming
# Don’t start with SQL because it’s easy
# Databricks Delta succeeds Parquet
# Make sure all data is available in S3
19 Data Warehousing with Spark Streaming - Spark + AI Summit Amsterdam ‘19
�
20 .THANKS A LOT!
QUESTIONS?
WE ARE HIRING!
�