展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
�
2 .DASK and Apache Spark
Gurpreet Singh, Microsoft
#UnifiedAnalytics #SparkAISummit
�
3 .…this talk is also about Scaling Python for Data Analysis & Machine Learning!
We’ll start with
briefly reviewing
the Scalability
Challenge in the
PyData stack…
…before Comparing
and Contrasting …
#UnifiedAnalytics #SparkAISummit 3
�
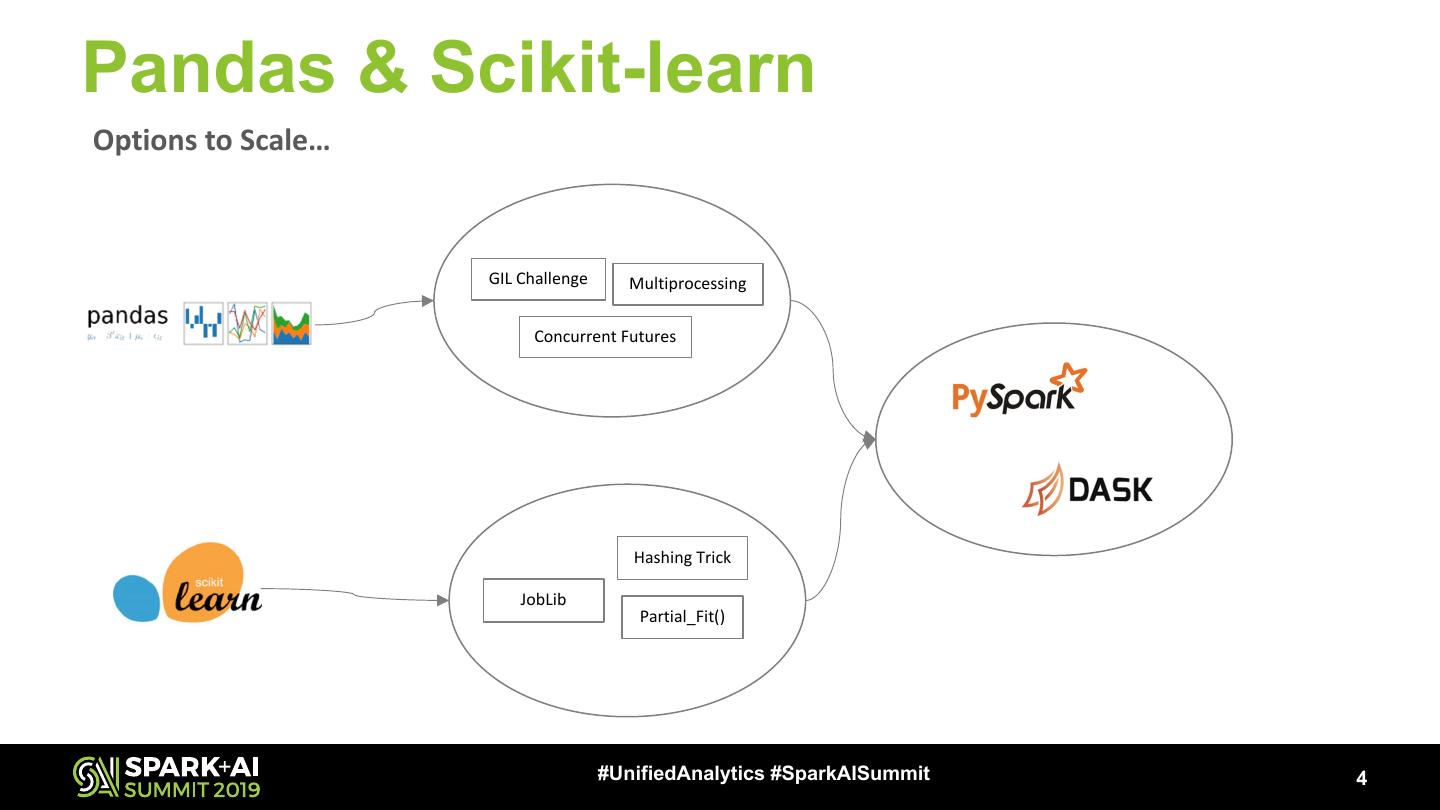
4 .Pandas & Scikit-learn
Options to Scale…
GIL Challenge Multiprocessing
Concurrent Futures
Hashing Trick
JobLib
Partial_Fit()
#UnifiedAnalytics #SparkAISummit 4
�
5 .Design DASK Arrays
[Parallel NumPy]
GraphX
d
support oesn’t
Python
Approach DASK Bag
[Parallel Lists]
DASK-ML
[Parallel Scikit-learn]
Spark SQL /
GraphFrames
Spark Streaming
DASK DataFrames Custom Custom DataFrames
[Parallel Pandas] Algorithms Graphs Spark MLlib
High Level APIs
DASK Delayed DASK Futures RDD
Low Level APIs
it
Subm s
a
graph n
Pytho y
nar
Dictio ct
obje
Lazy n
tio
Execu
Directed Acyclic Graph (DAG)
Pluggable Task Scheduling System
Local Scheduler
Local Spark Standalone
Synchronous
Multiprocessing Mesos YARN
Threaded Distributed
Task Scheduler
#UnifiedAnalytics #SparkAISummit 5
�
6 .DASK DataFrame & PySpark
DASK DataFrames
[Parallel Pandas]
Challenges Challenges
§ DASK DataFrames API is not identical with Pandas API § Performance Concerns due to the PySpark Design
§ Performance Concerns with Operations involving Shuffling
§ Inefficiencies of Pandas are carried over
Recommendations Recommendations
§ Follow the Pandas Performance tips § Use DataFrames API
§ Avoid Shuffle, Use pre-sorting, Persist the Results § Use Vectorized/Pandas UDF (Spark v2.3 onwards)
#UnifiedAnalytics #SparkAISummit 6
�
7 .Code Review
Wildcard
Wildcard Additional Details
#UnifiedAnalytics #SparkAISummit 7
�
8 .Code Review While Pandas display
a sample of the data,
DASK and PySpark
show metadata of
the DataFrame.
The npartitions value shows
how many partitions the
DataFrame is split into.
DASK created a DAG with 99 nodes to process
the data.
#UnifiedAnalytics #SparkAISummit 8
�
9 .Code Review
.compute() or
.head() method tells Dask
to go ahead and run the
computation and display
the results.
.show() displays the
DataFrame in a tabular
form.
#UnifiedAnalytics #SparkAISummit 9
�
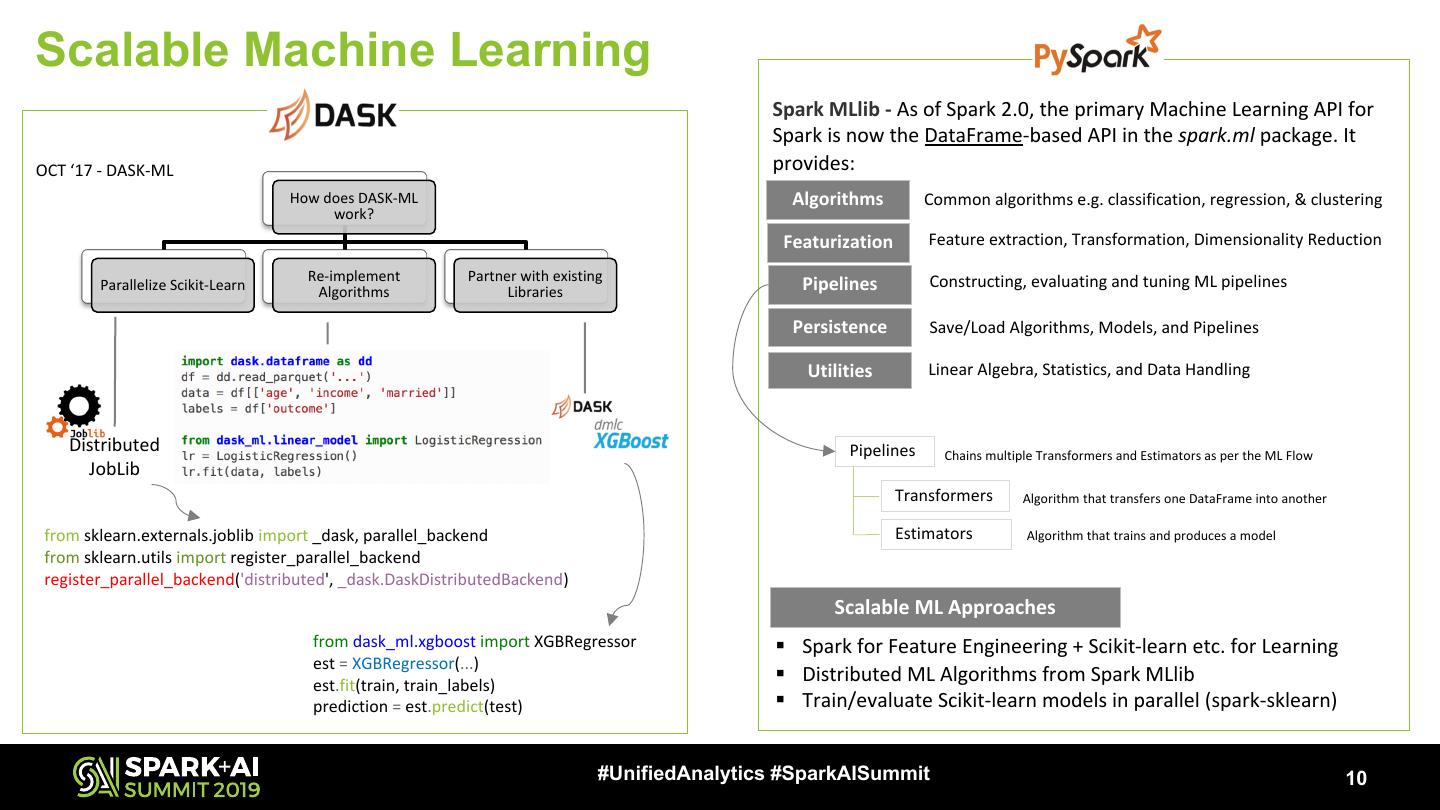
10 .Scalable Machine Learning
Spark MLlib - As of Spark 2.0, the primary Machine Learning API for
Spark is now the DataFrame-based API in the spark.ml package. It
OCT ‘17 - DASK-ML provides:
How does DASK-ML Algorithms Common algorithms e.g. classification, regression, & clustering
work?
Featurization Feature extraction, Transformation, Dimensionality Reduction
Re-implement Partner with existing Constructing, evaluating and tuning ML pipelines
Parallelize Scikit-Learn Algorithms Libraries Pipelines
Persistence Save/Load Algorithms, Models, and Pipelines
Utilities Linear Algebra, Statistics, and Data Handling
Distributed Pipelines Chains multiple Transformers and Estimators as per the ML Flow
JobLib
Transformers Algorithm that transfers one DataFrame into another
from sklearn.externals.joblib import _dask, parallel_backend Estimators Algorithm that trains and produces a model
from sklearn.utils import register_parallel_backend
register_parallel_backend('distributed', _dask.DaskDistributedBackend)
Scalable ML Approaches
from dask_ml.xgboost import XGBRegressor § Spark for Feature Engineering + Scikit-learn etc. for Learning
est = XGBRegressor(...)
est.fit(train, train_labels)
§ Distributed ML Algorithms from Spark MLlib
prediction = est.predict(test) § Train/evaluate Scikit-learn models in parallel (spark-sklearn)
#UnifiedAnalytics #SparkAISummit 10
�
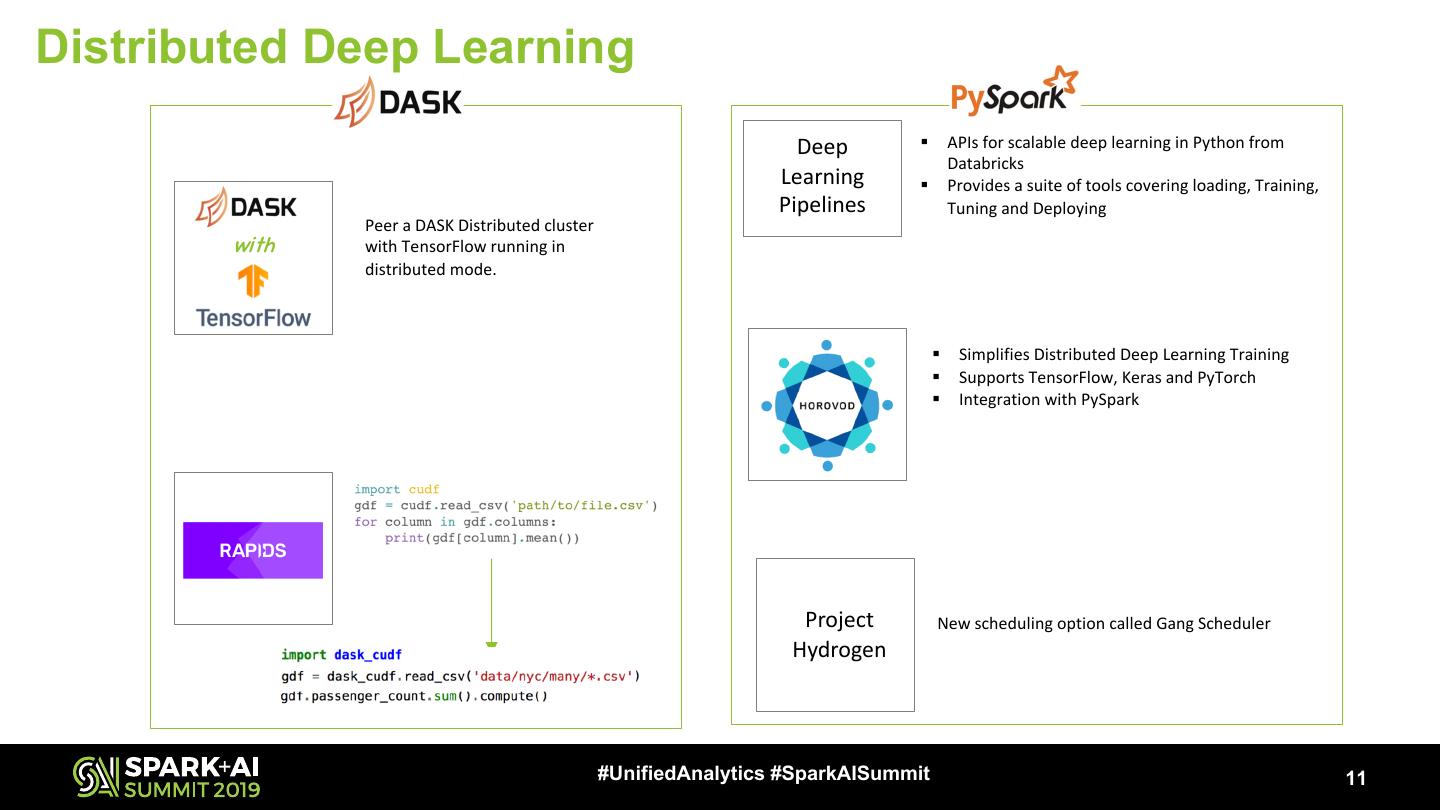
11 .Distributed Deep Learning
Deep § APIs for scalable deep learning in Python from
Databricks
Learning § Provides a suite of tools covering loading, Training,
Pipelines Tuning and Deploying
Peer a DASK Distributed cluster
with with TensorFlow running in
distributed mode.
§ Simplifies Distributed Deep Learning Training
§ Supports TensorFlow, Keras and PyTorch
§ Integration with PySpark
Project New scheduling option called Gang Scheduler
Hydrogen
#UnifiedAnalytics #SparkAISummit 11
�
12 .Other Dev Considerations…
§ Workloads/APIs
§ Custom Algorithms (only in DASK)
§ SQL, Graph (only in Spark)
§ Debugging Challenges
§ DASK Distributed may not align with normal Python Debugging Tools/Practices
§ PySpark errors may have a mix of JVM and Python Stack Trace
§ Visualization Options
§ Down-sample and use Pandas DataFrames
§ Use open source Libraries e.g. D3, Seaborn, Datashader (only for DASK) etc.
§ Use Databricks Visualization Feature
#UnifiedAnalytics #SparkAISummit 12
�
13 .Which one to Use?
There Are No Solutions, There Are Only Tradeoffs! – Thomas Sowell
#UnifiedAnalytics #SparkAISummit 13
�
14 .Questions?
#UnifiedAnalytics #SparkAISummit 14
�
15 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�