




































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Cosco: An Efficient Facebook-Scale Shuffle Service
Cosco is an efficient shuffle-as-a-service that powers Spark (and Hive) jobs at Facebook warehouse scale. It is implemented as a scalable, reliable and maintainable distributed system. Cosco is based on the idea of partial in-memory aggregation across a shared pool of distributed memory. This provides vastly improved efficiency in disk usage compared to Spark’s built-in shuffle. Long term, we believe the Cosco architecture will be key to efficiently supporting jobs at ever larger scale. In this talk we’ll take a deep dive into the Cosco architecture and describe how it’s deployed at Facebook. We will then describe how it’s integrated to run shuffle for Spark, and contrast it with Spark’s built-in sort-based shuffle mechanism and SOS (presented at Spark+AI Summit 2018).
展开查看详情
1 .
2 .Cosco: an efficient facebook-scale shuffle service Brian Cho & Dmitry Borovsky Spark + AI Summit 2019
3 .Disaggregated compute and storage • Advantages • Compute clusters • Server types optimized for • CPU, RAM, no disks for data compute or storage • Spark executors • Separate capacity management • Storage clusters and configuration • Spindle disks • Different hardware cycles • DFS (Warm Storage) • Permanent data: size dominant, uses less IO • Temporary data: IO dominant, uses less space
4 .Spindle disk storage 20 15 • A single spindle is used to 4 MiB, 8s Read request 10 1 MiB, 14s size (MiB) read/write data on the drive 5 256 KiB, 128 KiB, 64 KiB, 39 s 73s 140s • Small IO sizes cause low throughput 0 as seek times dominate 0 50 100 150 Time (s) .
5 .Spindle disk storage 20 15 • A single spindle is used to 4 MiB, 8s Read request 10 1 MiB, 14s size (MiB) read/write data on the drive 5 256 KiB, 128 KiB, 64 KiB, 39 s 73s 140s • Small IO sizes cause low throughput 0 as seek times dominate 0 50 100 150 Time (s) • Drive sizes increase over time 10 MiBs/TiB 15 15 TB drive • Must increase IO size to maintain the 7 MiB IO Avg IO size (MiB) 10 7 TB drive size same throughput per TB 1 MiB IO 5 size 0 0 5 10 15 20 HDD capacity (TiB)
6 .Spindle disk storage 20 15 • A single spindle is used to 4 MiB, 8s Read request 10 1 MiB, 14s size (MiB) read/write data on the drive 5 256 KiB, 128 KiB, 64 KiB, 39 s 73s 140s • Small IO sizes cause low throughput 0 as seek times dominate 0 50 100 150 Time (s) • Drive sizes increase over time 10 MiBs/TiB 8 MiBs/TiB 6 MiBs/TiB • Must increase IO size to maintain the 15 Avg IO size (MiB) 10 same throughput per TB, or 5 • Read/write less data to reduce 0 throughput demand 0 5 10 15 20 HDD capacity (TiB)
7 .Spindle disk storage: key metrics • A single spindle is used to ØDisk service time read/write data on the drive • Small IO sizes cause low throughput ØAverage IO size as seek times dominate • Drive sizes increase over time • Must increase IO size to maintain the same throughput, or • Read/write less data to reduce ØWrite amplification throughput demand
8 .Spark shuffle recap Mappers Map Output Files Reducers Partition Map 0 Reduce 0 Map 1 Reduce 1 Map m Reduce r
9 .Spark shuffle recap Mappers Map Output Files Reducers Partition Map 0 Reduce 0 Map 1 Reduce 1 Map m Reduce r
10 .Spark shuffle recap Mappers Map Output Files Reducers Sort by Partition key Map 0 Reduce 0 Iterator Map 1 Reduce 1 Iterator Map m Reduce r Iterator
11 .Spark shuffle recap: Write amplification Mappers Map Output Files Reducers Sort by Partition key Map 0 Reduce 0 Iterator Map 1 Reduce 1 Iterator Write amplification is 3x Map m Reduce r Iterator
12 .Spark shuffle recap: Small IOs problem Mappers Map Output Files Reducers Sort by Partition key Map 0 Reduce 0 Iterator Map 1 Reduce 1 Iterator MxR Avg IO size is 200 KiB Map m Reduce r Iterator
13 .Spark shuffle recap: SOS Mappers Map Output Files Reducers Sort by Partition key Map 0 Reduce 0 Iterator Map 1 Reduce 1 Iterator SOS: merge map outputs 10-way merge increases Avg IO size to 2 MiB Map m Reduce r Iterator
14 .Spark shuffle using Cosco • Mappers share a write-ahead buffer per reduce partition • Reducers can read the written data sequentially • Solves the small IOs problem • Sequential reads: Avg IO size 200 KiB à 2.5 MiB • Solves the write amplification problem • Avoiding spills: Write amplification 3x à 1.2x
15 .Results / Current status • Hive • Rolled out to 90%+ of Hive workloads, in production for 1+ year • 3.2x more efficient disk service time • Spark • Analysis shows potential 3.5x more efficient disk service time • Analysis shows CPU neutral • Integration is complete, rollout planned during next few months
16 .Cosco deep dive Dmitry Borovsky Spark + AI Summit 2019
17 .Problem • Shuffle exchange on spinning disks (disaggregated compute and storage) • Single shuffle exchange scale: PiBs size, 100Ks of mappers, 10Ks reducers • Write amplification is ~3x (1PiB shuffle does 3PiB writes to disk) • Small Average IO size: ~200KiB (at least MxR reads) • IO is spiky (all readers may start at the same time and do MxR reads) • Cosco is shared between users
18 .Sailfish: a framework for large scale data processing SoCC '12 Proceedings of the Third ACM Symposium on Cloud Computing, Article No. 4, San Jose, California — October 14 - 17, 2012 Source code: https://code.google.com/archive/p/sailfish/
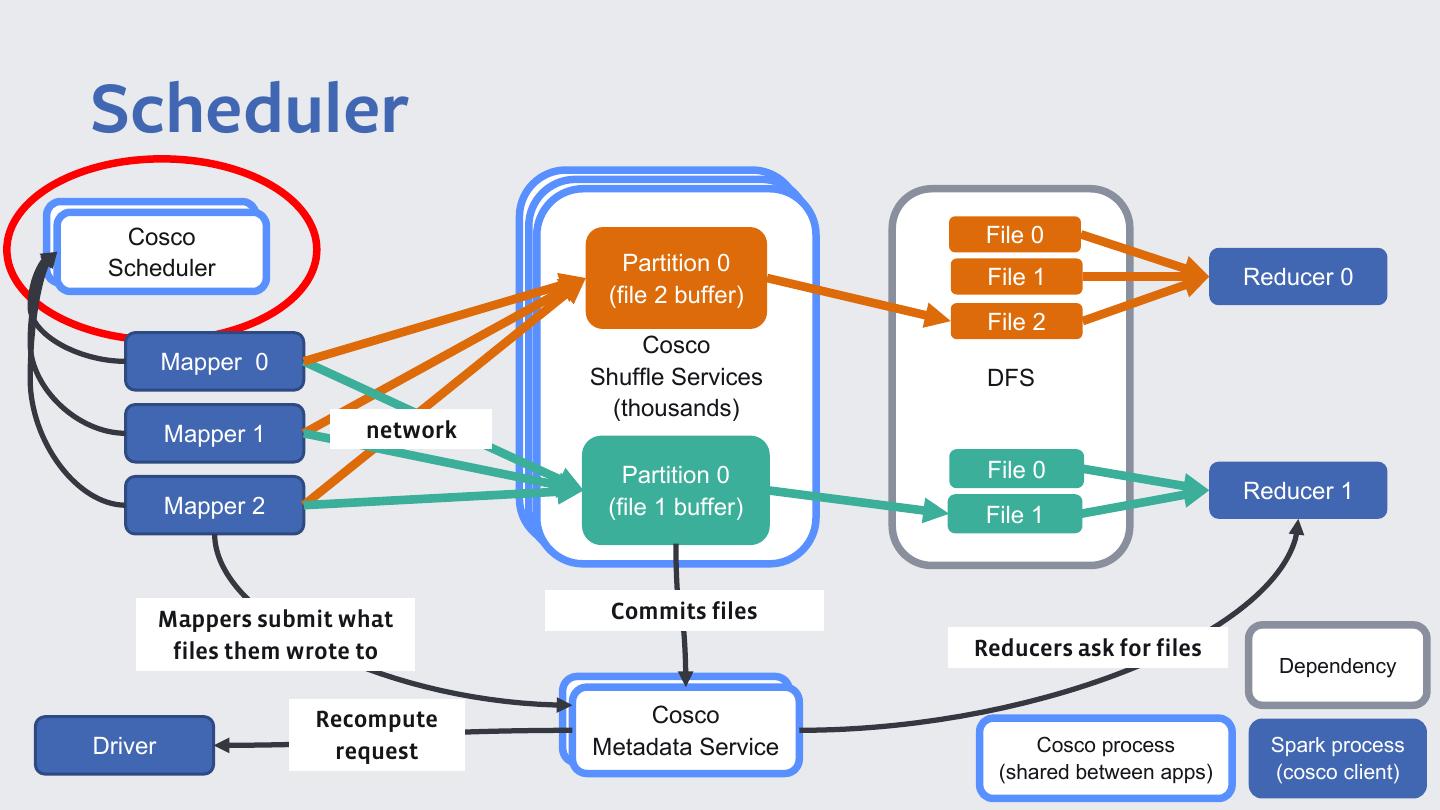
19 .Write-ahead buffers File 0 Partition 0 File 1 Reducer 0 (file 2 buffer) File 2 Cosco Cosco Mapper 0 Shuffle ShuffleServices Services DFS (thousands) (thousands) Mapper 1 network Partition 0 File 0 Reducer 1 Mapper 2 (file 1 buffer) File 1 Sorts (if needed) Dependency Cosco process Spark process (shared between apps) (cosco client)
20 .Exactly once delivery Cosco File 0 Partition Shuffle 0 Services File 1 Reducer 0 (file 2 buffer) (thousands) Data File 2 Mapper 0 Ack DFS Failover Partition 0’ (file 3 buffer) File 3 Dependency Cosco process Spark process (shared between apps) (cosco client)
21 .Exactly once delivery Cosco File 0 Partition Shuffle 0 Services File 1 Reducer 0 (file 2 buffer) (thousands) Data 1 File 2 Mapper 0 2 Ack DFS Failover Partition 0’ (file 3 buffer) File 3 Dependency Cosco process Spark process (shared between apps) (cosco client)
22 .At least once delivery and deduplication Cosco File 0 Partition Shuffle 0 Services File 1 Reducer 0 (file 2 buffer) (thousands) Data 1 File 2 Mapper 0 2 Ack DFS Failover De-duplicates Partition 0’ (file 3 buffer) resends non-acked data File 3 Adds row_id and mapper_id to each row Dependency Cosco process Spark process (shared between apps) (cosco client)
23 .Replication Partition 0 File 0 (file 2 buffer) File 1 Reducer 0 Data File 2 Mapper 0 Ack Data DFS Ack Partition 0’ (file 2’ buffer) Dependency Cosco process Spark process (shared between apps) (cosco client)
24 .Replication Partition 0 File 0 (file 2 buffer) File 1 Reducer 0 Data File 2 Mapper 0 Ack Data DFS Ack Partition 0’ (file 2’ buffer) File 2’ Dependency Cosco process Spark process (shared between apps) (cosco client)
25 .// Driver shuffle = new CoscoExchange( shuffleId: String, partitions: int, recomputeWritersCallback: (mappers: long[], reason: String) -> void); // end of exchange shuffle.close(); // Mapper // Reducer writer = new CoscoWriter( reader = new CoscoReader( shuffleId: String, shuffleId: String, mapper: long); mappers: long[], partition: int); writer.collect( partition: int, row: byte[]); while (reader.next()) { // ... // using row writer.collect( row = reader.row(); partition: int, row: byte[]); } writer.close(); reader.close();
26 .// Driver shuffle = new CoscoExchange( shuffleId: String, partitions: int, recomputeWritersCallback: (mappers: long[], reason: String) -> void); // end of exchange shuffle.close(); // Mapper // Reducer writer = new CoscoWriter( reader = new CoscoReader( shuffleId: String, shuffleId: String, mapper: long); mappers: long[], partition: int); writer.collect( partition: int, row: byte[]); while (reader.next()) { // ... // using row writer.collect( row = reader.row(); partition: int, row: byte[]); } writer.close(); reader.close();
27 .Metadata File 0 Partition 0 File 1 Reducer 0 (file 2 buffer) File 2 Cosco Cosco Mapper 0 Shuffle ShuffleServices Services DFS (thousands) (10Ks) Mapper 1 network Partition 0 File 0 Reducer 1 Mapper 2 (file 1 buffer) File 1 Mappers submit what Commits files files them wrote to Reducers ask for files Dependency Cosco Metadata Service Cosco process Spark process (shared between apps) (cosco client)
28 .Metadata Mapper 0 File 0 File 0 Mapper 1 Partition 0 File 1 File 1 Reducer 0 (file 2 buffer) File 2 Mapper 2 Cosco Cosco File 2 Mapper 0 Shuffle ShuffleServices Services DFS Mapper 3 (thousands) (10Ks) File 0 Mapper 1 network Partition 0 File 0 Mapper 4 File 1 Reducer 1 Mapper 2 (file 1 buffer) File 1 Mappers submit what Commits files files them wrote to Reducers ask for files Dependency Cosco Metadata Service Cosco process Spark process (shared between apps) (cosco client)
29 .Metadata Mapper 0 File 0 File 0 Mapper 1 Partition 0 File 1 File 1 Reducer 0 (file 2 buffer) File 2 Mapper 2 Cosco Cosco File 2 Mapper 0 Shuffle ShuffleServices Services DFS Mapper 3 (thousands) (10Ks) File 0 Mapper 1 network Partition 0 File 0 Mapper 4 File 1 Reducer 1 Mapper 2 (file 1 buffer) File 1 Mapper 3’ (recompute) File 3 Mappers submit what Commits files Mapper 4’ (recompute) File 2 files them wrote to Reducers ask for files Dependency Cosco Metadata Service Cosco process Spark process (shared between apps) (cosco client)
3秒后跳转登录页面
去登陆

