






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Cooperative Task Execution for Apache Spark
Apache Spark has enabled a vast assortment of users to express batch, streaming, and machine learning computations, using a mixture of programming paradigms and interfaces. Lately, we observe that different jobs are often implemented as part of the same application to share application logic, state, or to interact with each other. Examples include online machine learning, real-time data transformation and serving, low-latency event monitoring and reporting. Although the recent addition of Structured Streaming to Spark provides the programming interface to enable such unified applications over bounded and unbounded data, the underlying execution engine was not designed to efficiently support jobs with different requirements (i.e., latency vs. throughput) as part of the same runtime. It therefore becomes particularly challenging to schedule such jobs to efficiently utilize the cluster resources while respecting their requirements in terms of task response times. Scheduling policies such as FAIR could alleviate the problem by prioritizing critical tasks, but the challenge remains, as there is no way to guarantee no queuing delays. Even though preemption by task killing could minimize queuing, it would also require task resubmission and loss of progress, leading to wasted cluster resources. In this talk, we present Neptune, a new cooperative task execution model for Spark with fine-grained control over resources such as CPU time. Neptune utilizes Scala coroutines as a lightweight mechanism to suspend task execution with sub-millisecond latency and introduces new scheduling policies that respect diverse task requirements while efficiently sharing the same runtime. Users can directly use Neptune for their continuous applications as it supports all existing DataFrame, DataSet, and RDD operators. We present an implementation of the execution model as part of Spark 2.4.0 and describe the observed performance benefits from running a number of streaming and machine learning workloads on an Azure cluster.Gare
展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
2 .Cooperative Task Execution for Apache Spark Panagiotis Garefalakis (Imperial College London) Konstantinos Karanasos (Microsoft) Peter Pietzuch (Imperial College London) #UnifiedAnalytics #SparkAISummit
3 .Evolution of analytics Batch frameworks Frameworks Unified with hybrid stream/batch stream/batch Stream frameworks frameworks applications 2010 2014 2018 Structured Streaming #UnifiedAnalytics #SparkAISummit 3
4 . Unified application example Inference Job Real-time Low-latency data responses Training Job Stream Job Stages Historical Trained data Model Batch Application Iterate #UnifiedAnalytics #SparkAISummit 4
5 .Unified applications Advantages > Sharing application logic & state > Result consistency > Sharing of computation Stream/Batch = unified applications combining > latency-sensitive (stream) jobs with > latency-tolerant (batch) jobs as part of the same application #UnifiedAnalytics #SparkAISummit 5
6 .Structured Streaming API #UnifiedAnalytics > Unified processing platform on top of Spark SQL fast, scalable, fault tolerant > Large ecosystem of data sources integrate with many storage systems > Rich, unified, high-level APIs deal with complex data and complex workloads val trainData = context.read("malicious−train−data") val streamingData = context val pipeline = new Pipeline().setStages(Array( .readStream("kafkaTopic") Stream Batch new OneHotEncoderEstimator(), .groupBy("userId") new VectorAssembler(), .schema() /* input schema */ new Classifier(/* select estimator */))) val streamRates = pipelineModel val pipelineModel = pipeline.fit(trainData) .transform(streamingData) streamRates.start() /* start streaming */ #UnifiedAnalytics #SparkAISummit 6
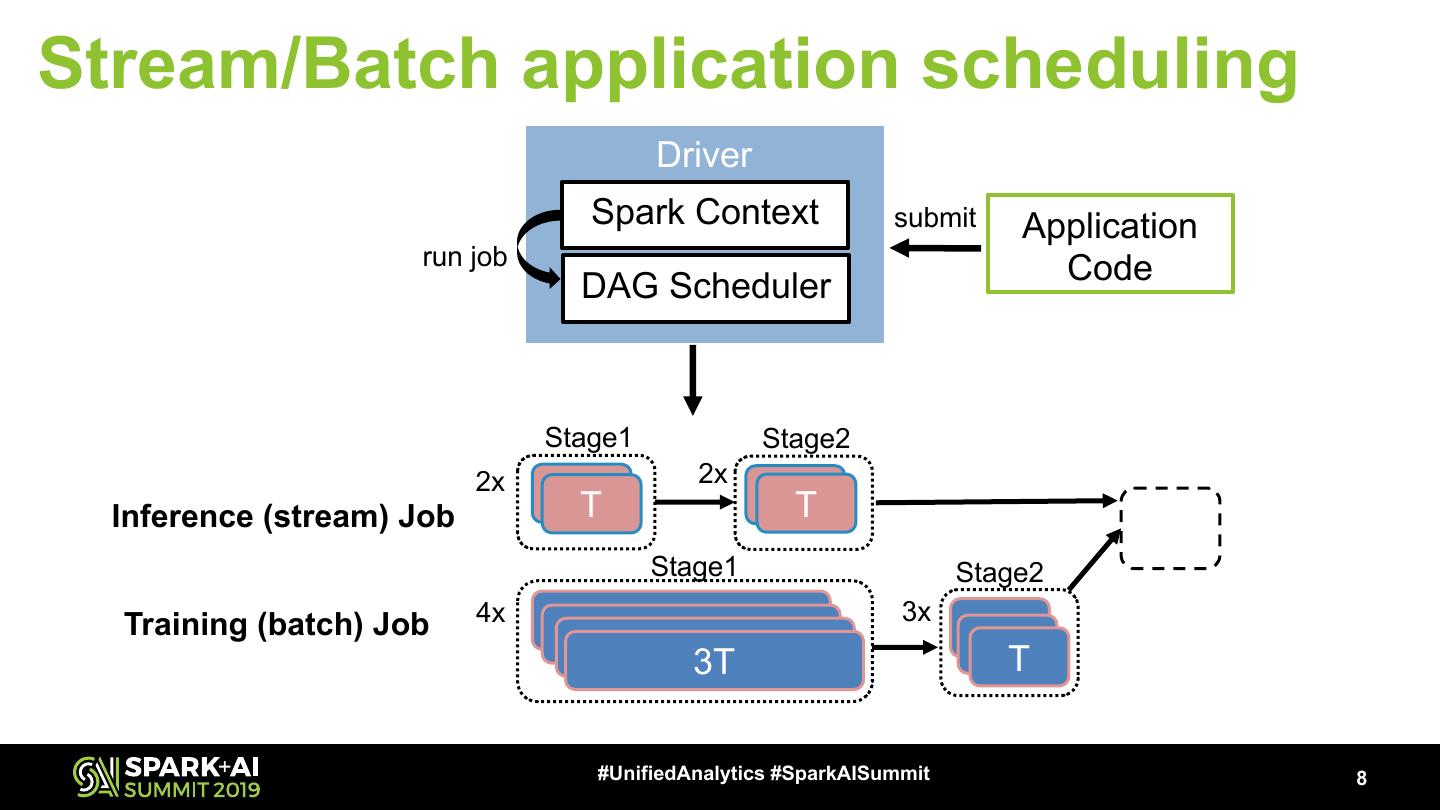
7 .Scheduling of Stream/Batch jobs Requirements > Latency: Execute inference job with minimum delay > Throughput: Batch jobs should not be compromised > Efficiency: Achieve high cluster resource utilization Challenge: schedule stream/batch jobs to satisfy their diverse requirements #UnifiedAnalytics #SparkAISummit 7
8 .Stream/Batch application scheduling Driver Spark Context submit Application run job Code DAG Scheduler Stage1 Stage2 2x 2x 2xT T 2xT T Inference (stream) Job Stage1 Stage2 Training (batch) Job 4x 3T 3x 3T TT 3T 3T T #UnifiedAnalytics #SparkAISummit 8
9 . Stage1 Stage2 Stream/Batch scheduling 2x 2x 2xT T 2xT T Stage1 Stage2 4x 3x 3T 3T TT 3T 3T T > Static allocation: dedicate resources to each job executor 2 T T T T Cores 3T T executor 1 Wasted 3T resources T 3T 3T T 2 4 6 8 Resources cannotTime be(T)shared across jobs #UnifiedAnalytics #SparkAISummit 9
10 . Stage1 Stage2 Stream/Batch scheduling 2x 2x 2xT T 2xT T Stage1 Stage2 4x 3x 3T 3T TT 3T 3T T > FIFO: first job runs to completion 3T shared executors T Cores 3T T 3T T T 3T T T T 2 4 6 8 Long batch jobs increase Time (T) stream job latency #UnifiedAnalytics #SparkAISummit 10
11 . Stage1 Stage2 Stream/Batch scheduling 2x 2x 2xT T 2xT T Stage1 Stage2 4x 3x 3T 3T TT 3T 3T T > FAIR: weight share resources across jobs T 3T shared executors Cores T 3T T 3T T T 3T T T 2 4 6 8 Better packing with non-optimal queuing Time (T) latency #UnifiedAnalytics #SparkAISummit 11
12 . Stage1 Stage2 Stream/Batch scheduling 2x 2x 2xT T 2xT T Stage1 Stage2 4x 3x 3T 3T TT 3T 3T T > KILL: avoid queueing by preempting batch tasks T 3T T shared executors Cores T 3T T T 3T 3T T 3T 3T T 2 4 6 8 Better latency at the Time expense (T) of extra work #UnifiedAnalytics #SparkAISummit 12
13 . Stage1 Stage2 Stream/Batch scheduling 2x 2x 2xT T 2xT T Stage1 Stage2 4x 3x 3T 3T TT 3T 3T T > NEPTUNE: minimize queueing and wasted work T 3T shared executors T Cores T 3T T T 3T 2T 3T T 2T T 2 4 6 8 Time (T) #UnifiedAnalytics #SparkAISummit 13
14 .Challenges > How to minimize queuing for latency-sensitive jobs and wasted work? Implement suspendable tasks > How to natively support stream/batch applications? Provide a unified execution framework > How to satisfy different stream/batch application requirements and high-level objectives? Introduces custom scheduling policies #UnifiedAnalytics #SparkAISummit 14
15 .NEPTUNE Execution framework for Stream/Batch applications > How to minimize queuing for latency-sensitive jobs and wasted work? Implement suspendable tasks Support suspendable tasks > How to natively support stream/batch applications? Provide a unified execution framework Unified execution framework on top of Structure Streaming > How to satisfy different stream/batch application requirements and high-level objectives? Introduces custom scheduling policies Introduce pluggable scheduling policies #UnifiedAnalytics #SparkAISummit 15
16 .Spark tasks Executor Stack > Tasks: apply a function to a partition of data State Iterator > Subroutines that run in executor to completion Context > Preemption problem: Function > Loss of progress (kill) > Unpredictable preemption times Value (checkpointing) Task run #UnifiedAnalytics #SparkAISummit 16
17 . Coroutine Suspendable tasks State Stack > Idea: use coroutines Iterator > Separate stacks to store task state > Yield points handing over control to Context Executor executor Stack Function > Cooperative preemption: > Suspend and resume in milliseconds yield call > Work-preserving 17 Value > Transparent to the user https://github.com/storm-enroute/coroutines Task run #UnifiedAnalytics #SparkAISummit
18 .Suspendable tasks Subroutine Coroutine val collect (TaskContext, Iterator[T]) => (Int, val collect (TaskContext, Iterator[T]) => (Int, Array[T]) = { Array[T]) = { coroutine {(context: TaskContext, itr: Iterator[T]) => { val result = new mutable.ArrayBuffer[T] val result = new mutable.ArrayBuffer[T] while (itr.hasNext) { while (itr.hasNext) { result.append(itr.next) result.append(itr.next) } if (context.isPaused()) result.toArray yieldval(0) } } result.toArray }} #UnifiedAnalytics #SparkAISummit 18
19 . Execution framework Executor Executor Executor DAG scheduler Tasks Tasks Running Paused Incrementalizer Optimizer Low-pri job High-pri job launch suspend & task run task Task Scheduler High Low Scheduling policy App + job priorities #UnifiedAnalytics #SparkAISummit 19
20 .Scheduling Policies > Idea: policies trigger task suspension and resumption > Guarantee that stream tasks bypass batch tasks > Satisfy higher-level objectives i.e. balance cluster load > Avoid starvation by suspending up to a number of times > Load-balancing: equalize the number of tasks per node & reduce preemption > Cache-aware load-balancing: respect task locality preferences in addition to load-balancing #UnifiedAnalytics #SparkAISummit 20
21 .Implementation > Built as an extension to 2.4.0 (code to be open-sourced) > Ported all ResultTask, ShuffleMapTask functionality across programming interfaces to coroutines > Extended Spark’s DAG Scheduler to allow job stages with different requirements (priorities) #UnifiedAnalytics #SparkAISummit 21
22 .Demo > Run a simple unified application with > A high-priority latency-sensitive job > A low-priority latency-tolerant job > Schedule them with default Spark and Neptune > Goal: show benefit of Neptune and ease of use #UnifiedAnalytics #SparkAISummit 22
23 .Azure deployment > Cluster – 75 nodes with 4 cores and 32 GB of memory each > Workloads – TPC-H decision support benchmark – Yahoo Streaming Benchmark: ad-analytics on a stream of ad impressions – LDA: ML training/inference application uncovering hidden topics from a group of documents #UnifiedAnalytics #SparkAISummit 23
24 .Benefit 6 of NEPTUNE in stream latency Streaming latency (s) 5 4 37% 3 61% 2 54% 13% 1 0 NEPTUNE achieves latencies comparable to DIFF-EXEC Static FIFO FIFO FAIR FAIR KILL NEP-CL CLB NEP-LB LB PRI-ONLY Isolation the ideal for the latency-sensitive allocation jobs Neptune Neptune #UnifiedAnalytics #SparkAISummit 24
25 . Suspension mechanism effectiveness Pause latency Resume latency Task runtime 10000.0 1000.0 100.0 ms - logscale 10.0 1.0 0.1 0.01 Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10 Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q18 Q19 Q20 Q21 Q22 TCPH Scale Factor 10 > TPCH: Task runtime distribution for each query ranges from 100s of milliseconds to 10s of seconds #UnifiedAnalytics #SparkAISummit 25
26 . Suspension mechanism effectiveness Pause latency Resume latency Task runtime 10000.0 1000.0 100.0 ms - logscale 10.0 1.0 0.1 0.01 Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10 Q11 Q12 Q13 Q14 Q15 Q16 Q17 Q18 Q19 Q20 Q21 Q22 TCPH Scale Factor 10 > TPCH: Continuously Effectively pausetransition tasks from and resume withPaused sub- to Resumed states until millisecond completion latency #UnifiedAnalytics #SparkAISummit 26
27 .Impact of resource demands in performance Streaming latency (s) 6 3.95 Batch (M events/s) 3.92 4 1.5% 3.90 2 3.88 0 3.85 0% 20% Efficiently share40% 60% with resources 80% low 100% impact on Cores Past throughput usedtofor Streaming future #UnifiedAnalytics #SparkAISummit 27
28 .Summary Neptune supports complex unified applications with diverse job requirements! > Suspendable tasks using coroutines > Pluggable scheduling policies > Continuous analytics Thank you! Panagiotis Garefalakis Questions? pgaref@imperial.ac.uk #UnifiedAnalytics #SparkAISummit 28
29 .DON’T FORGET TO RATE AND REVIEW THE SESSIONS SEARCH SPARK + AI SUMMIT
3秒后跳转登录页面
去登陆

