



























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Cobrix: A Mainframe Data Source for Spark SQL and Streaming
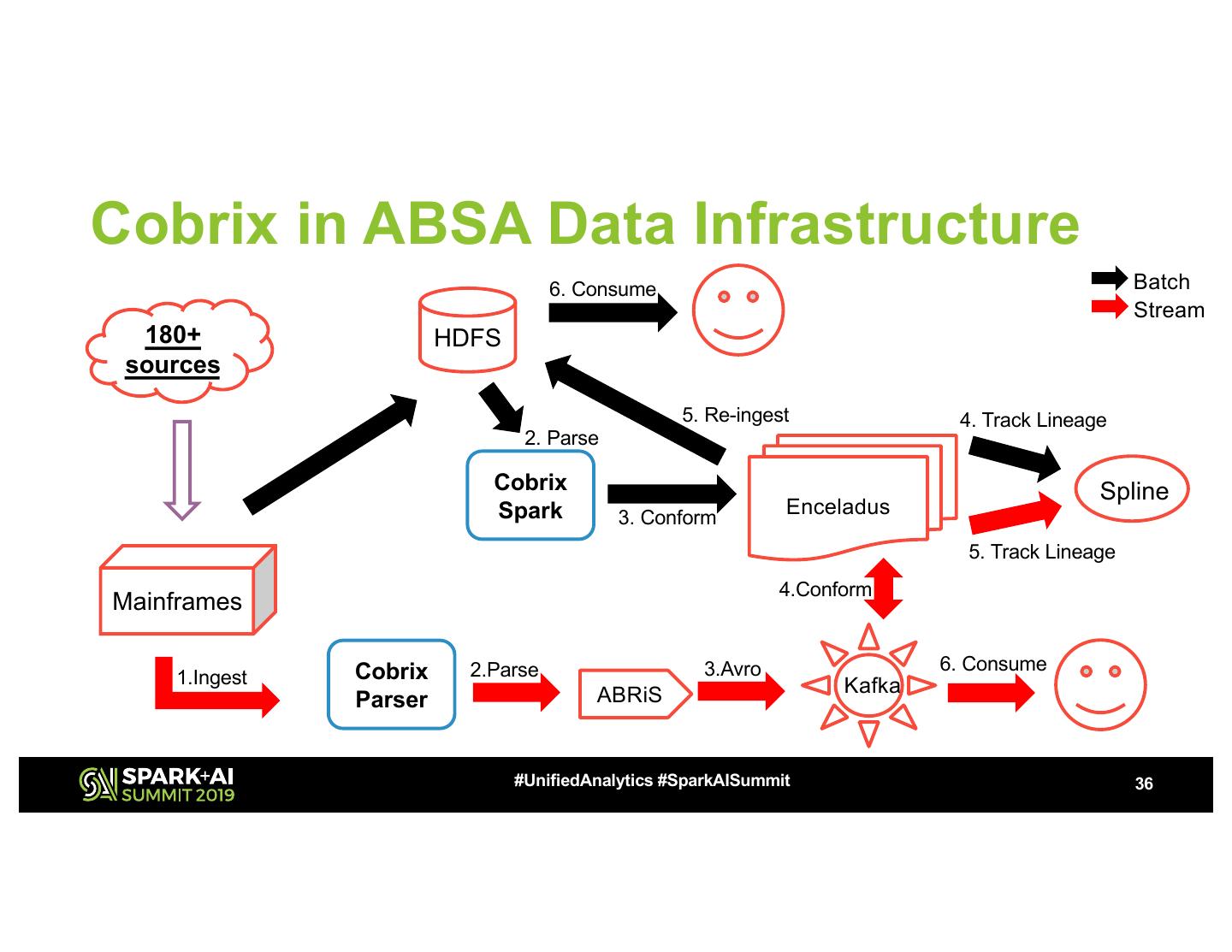
Seamless integration of diverse data sources into an enterprise data lake has a great value for data-driven companies. In financial and banking industries, where our company ABSA belongs, mainframes are among the most common platforms. However, their interoperability with other platforms remains challenging. In this talk, we introduce a new data source for Spark called Cobrix (https://github.com/AbsaOSS/cobrix) which radically simplifies consuming mainframe data from Spark. Currently, a wide range of approaches is used to integrate mainframe data with analytics platform such as message queues, direct ODBC/JDBC connectors, tools like Sqoop and LegStar, or running Spark directly on mainframes. But these approaches have several limitations. For instance, the existing tools primarily focus on relational data, therefore, the original hierarchical schema is flattened, exploded and/or projected. As a consequence, the resulting table may become extremely wide (~10k columns) which complicates its further processing. Our solution, Cobrix, extends Spark SQL API with a Data Source for mainframe data. It allows reading binary files stored in HDFS having a native mainframe format, and parsing it into Spark DataFrames, with the schema being provided as a COBOL copybook. Spark’s native support for nested structures and arrays allows retention of the original schema. As a result, Cobrix offers a new and convenient way of processing mainframe data. In this talk we first review the difference in data definition models between mainframes and PCs. Then we explain schema mapping between COBOL and Spark in Cobrix. Further, we demonstrate Cobrix usage for reading simple and multi-segment files and present performance and scalability characteristics of the data source. Finally, we discuss the broad picture of mainframe integration through Cobrix, Spark, Avro, Kafka, etc. through use case examples.
展开查看详情
1 .WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
2 .Cobrix: A Mainframe Data Source for Spark SQL and Streaming Ruslan Iushchenko, ABSA Jan Scherbaum, ABSA #UnifiedAnalytics #SparkAISummit
3 .About us • ABSA is a Pan-African financial services provider – With Apache Spark at the core of its data engineering • We fill gaps in the Hadoop ecosystem, when we find them • Contributions to Apache Spark • Spark-related open-source projects (https://github.com/AbsaOSS) - Spline - a data lineage tracking and visualization tool - ABRiS - Avro SerDe for structured APIs - Atum - Data quality library for Spark - Enceladus - A dynamic data conformance engine - Cobrix - A Cobol library for Spark (focus of this presentation) #UnifiedAnalytics #SparkAISummit 3
4 .Business Motivation • The market for Mainframes is strong, with no signs of cooling down. Mainframes – Are used by 71% of Fortune 500 companies – Are responsible for 87% of all credit card transactions in the world – Are part of the IT infrastructure of 92 out of the 100 biggest banks in the world – Handle 68% of the world’s production IT workloads, while accounting for only 6% of IT costs. • For companies relying on Mainframes, becoming data-centric can be prohibitively expensive – High cost of hardware – Expensive business model for data science related activities Source: http://blog.syncsort.com/2018/06/mainframe/9-mainframe-statistics/ #UnifiedAnalytics #SparkAISummit 4
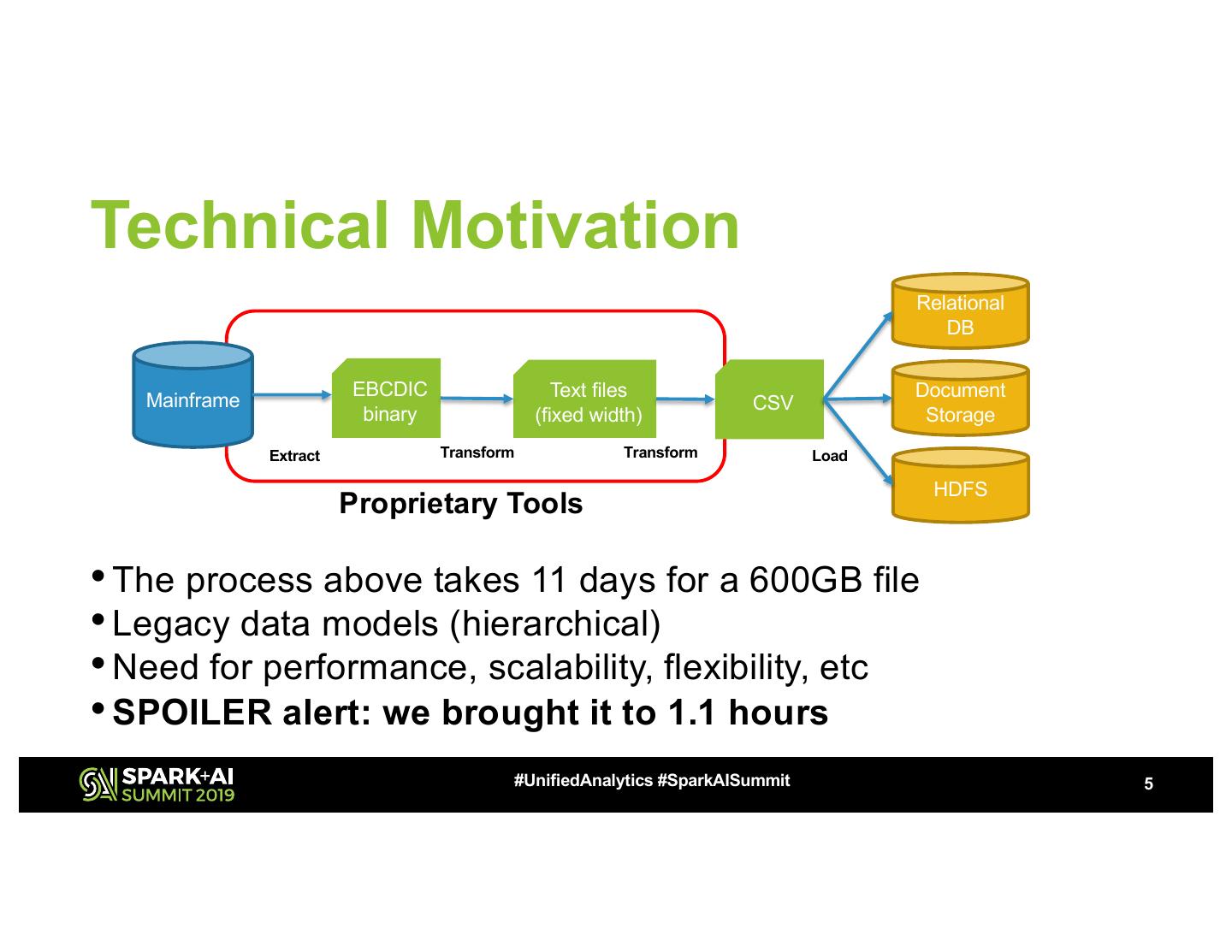
5 .Technical Motivation Relational DB EBCDIC Text files Document Mainframe CSV binary (fixed width) Storage Extract Transform Transform Load HDFS Proprietary Tools • The process above takes 11 days for a 600GB file • Legacy data models (hierarchical) • Need for performance, scalability, flexibility, etc • SPOILER alert: we brought it to 1.1 hours #UnifiedAnalytics #SparkAISummit 5
6 .What can you do? • Run analytics / Spark on mainframes • Message Brokers (e.g. MQ) • Sqoop • Proprietary solutions • But ... • Pricey • Slow • Complex (specially for legacy systems) • Require human involvement #UnifiedAnalytics #SparkAISummit 6
7 . How Cobrix can help • Decreasing human involvement –Fewer people are required… –No proprietary tool-specific knowledge • Simplifying the manipulation of hierarchical structures –No intermediate data structures • Providing scalability • Open-source #UnifiedAnalytics #SparkAISummit 7
8 .Cobrix – a Spark data source Apache Mainframe file Spark Application (EBCDIC) transformations Output Cobrix df df df Writer (Parquet, JSON, Schema CSV…) ... (copybook) #UnifiedAnalytics #SparkAISummit 8
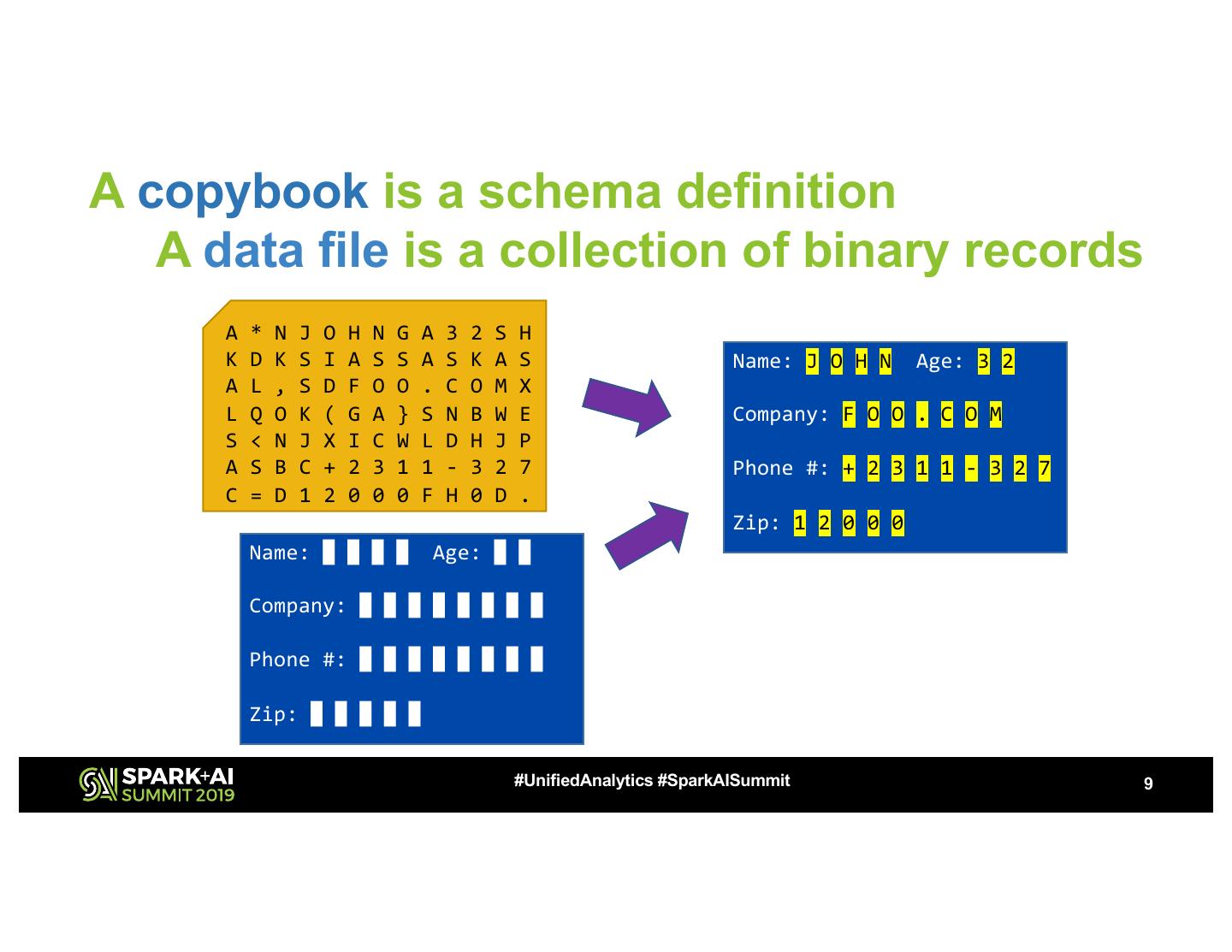
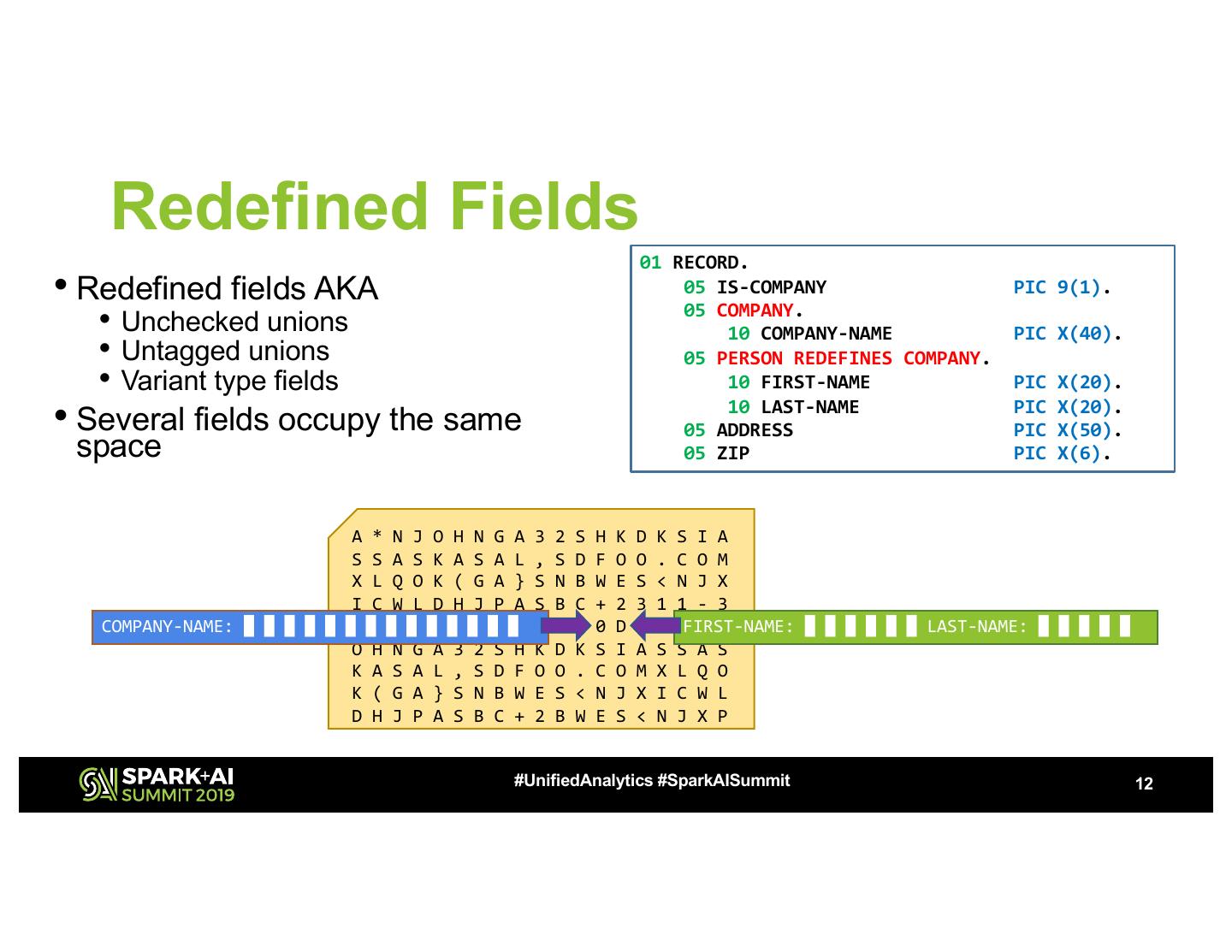
9 .A copybook is a schema definition A data file is a collection of binary records A * N J O H N G A 3 2 S H K D K S I A S S A S K A S Name: J O H N Age: 3 2 A L , S D F O O . C O M X L Q O K ( G A } S N B W E Company: F O O . C O M S < N J X I C W L D H J P A S B C + 2 3 1 1 - 3 2 7 Phone #: + 2 3 1 1 - 3 2 7 C = D 1 2 0 0 0 F H 0 D . Zip: 1 2 0 0 0 Name: █ █ █ █ Age: █ █ Company: █ █ █ █ █ █ █ █ Phone #: █ █ █ █ █ █ █ █ Zip: █ █ █ █ █ #UnifiedAnalytics #SparkAISummit 9
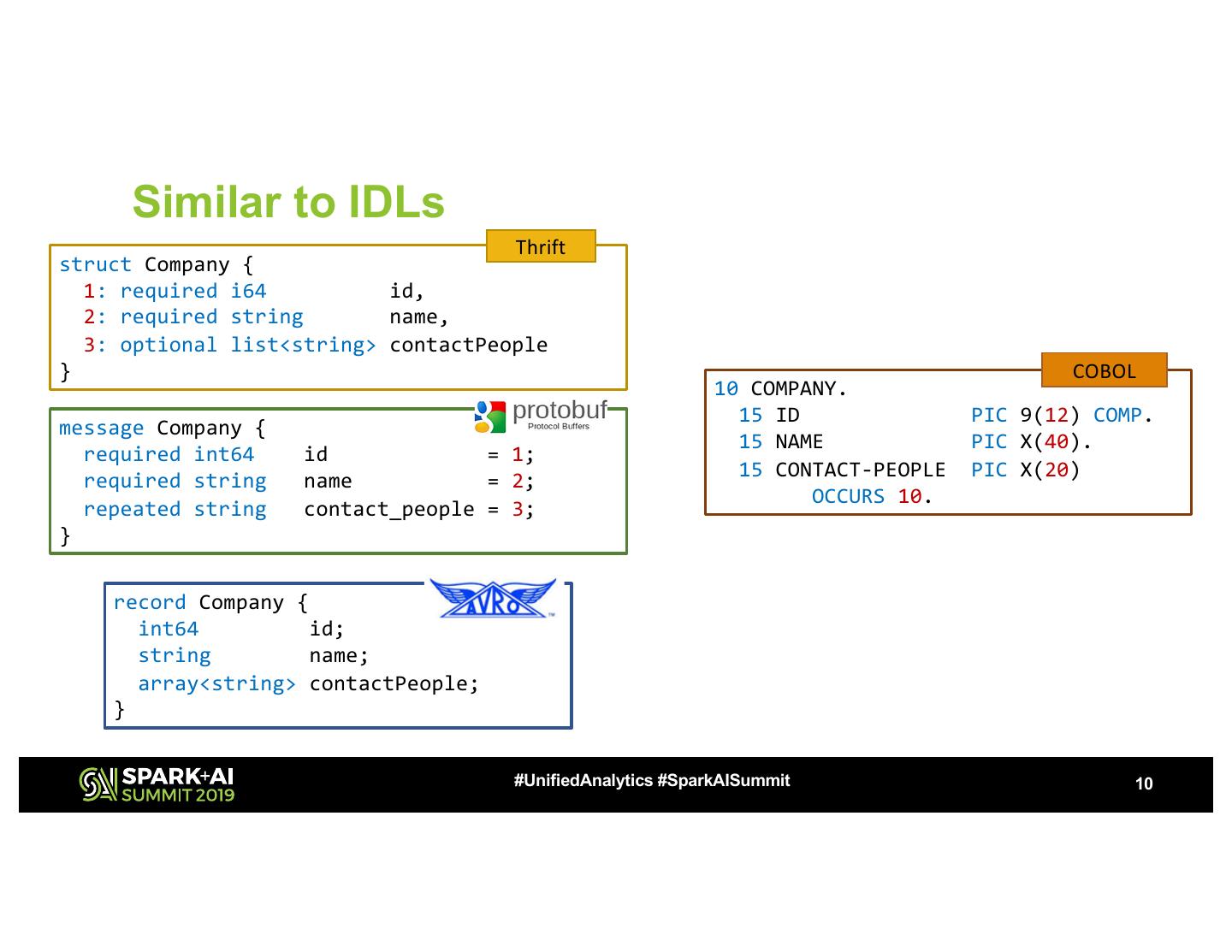
10 . Similar to IDLs Thrift struct Company { 1: required i64 id, 2: required string name, 3: optional list<string> contactPeople } COBOL 10 COMPANY. 15 ID PIC 9(12) COMP. message Company { 15 NAME PIC X(40). required int64 id = 1; required string name = 2; 15 CONTACT-PEOPLE PIC X(20) OCCURS 10. repeated string contact_people = 3; } record Company { int64 id; string name; array<string> contactPeople; } #UnifiedAnalytics #SparkAISummit 10
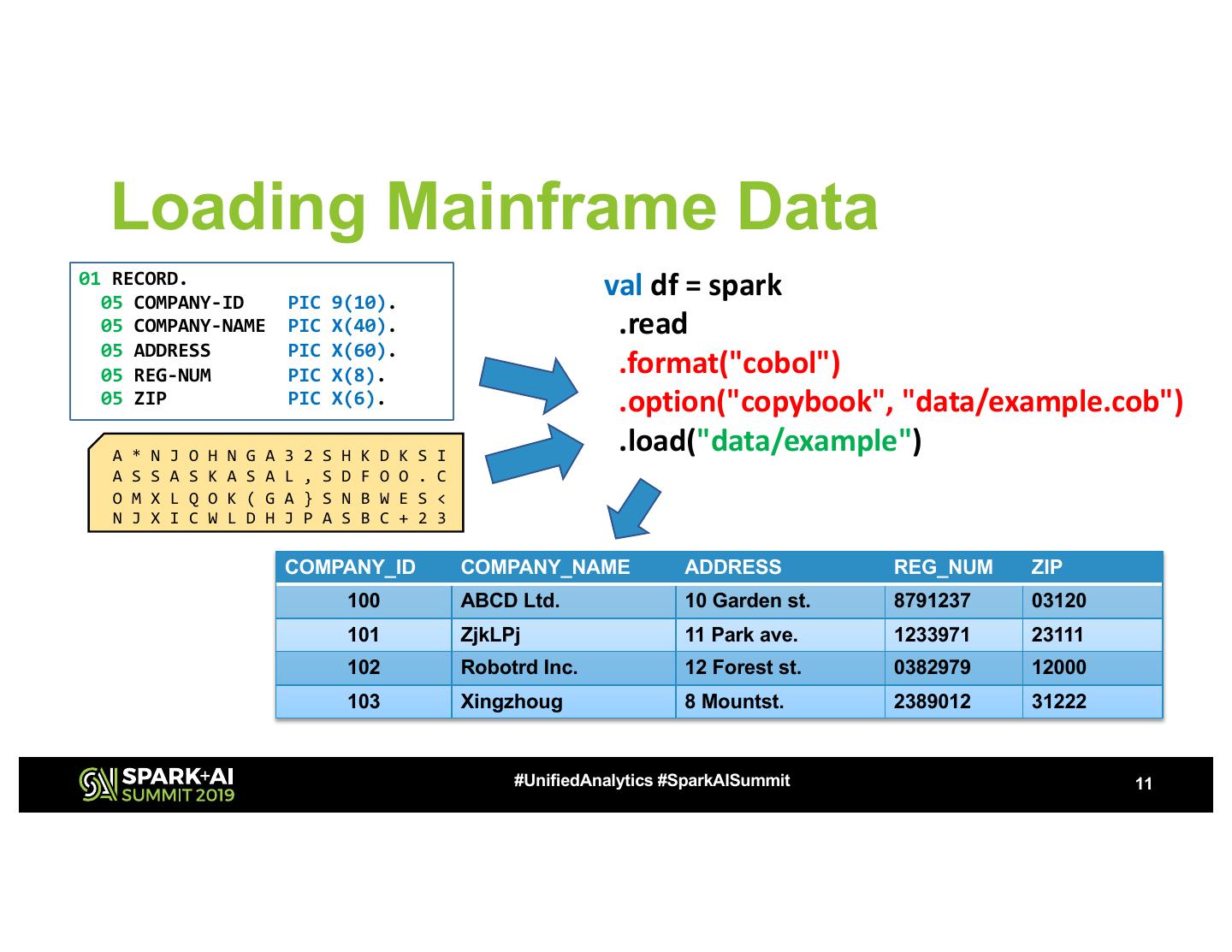
11 . Loading Mainframe Data 01 RECORD. 05 COMPANY-ID PIC 9(10). val df = spark 05 COMPANY-NAME PIC X(40). .read 05 ADDRESS 05 REG-NUM PIC PIC X(60). X(8). .format("cobol") 05 ZIP PIC X(6). .option("copybook", "data/example.cob") A * N J O H N G A 3 2 S H K D K S I .load("data/example") A S S A S K A S A L , S D F O O . C O M X L Q O K ( G A } S N B W E S < N J X I C W L D H J P A S B C + 2 3 COMPANY_ID COMPANY_NAME ADDRESS REG_NUM ZIP 100 ABCD Ltd. 10 Garden st. 8791237 03120 101 ZjkLPj 11 Park ave. 1233971 23111 102 Robotrd Inc. 12 Forest st. 0382979 12000 103 Xingzhoug 8 Mountst. 2389012 31222 #UnifiedAnalytics #SparkAISummit 11
12 . Redefined Fields 01 RECORD. • Redefined fields AKA 05 IS-COMPANY PIC 9(1). • Unchecked unions 05 COMPANY. 10 COMPANY-NAME PIC X(40). • Untagged unions 05 PERSON REDEFINES COMPANY. • Variant type fields 10 FIRST-NAME PIC X(20). • Several fields occupy the same 10 LAST-NAME 05 ADDRESS PIC PIC X(20). X(50). space 05 ZIP PIC X(6). A * N J O H N G A 3 2 S H K D K S I A S S A S K A S A L , S D F O O . C O M X L Q O K ( G A } S N B W E S < N J X I C W L D H J P A S B C + 2 3 1 1 - 3 COMPANY-NAME: █ █ █ █ █ █2 █7 █C █= █D █1 █2 █0 █0 0 F H 0 D . A *FIRST-NAME: N J █ █ █ █ █ █ LAST-NAME: █ █ █ █ █ O H N G A 3 2 S H K D K S I A S S A S K A S A L , S D F O O . C O M X L Q O K ( G A } S N B W E S < N J X I C W L D H J P A S B C + 2 B W E S < N J X P #UnifiedAnalytics #SparkAISummit 12
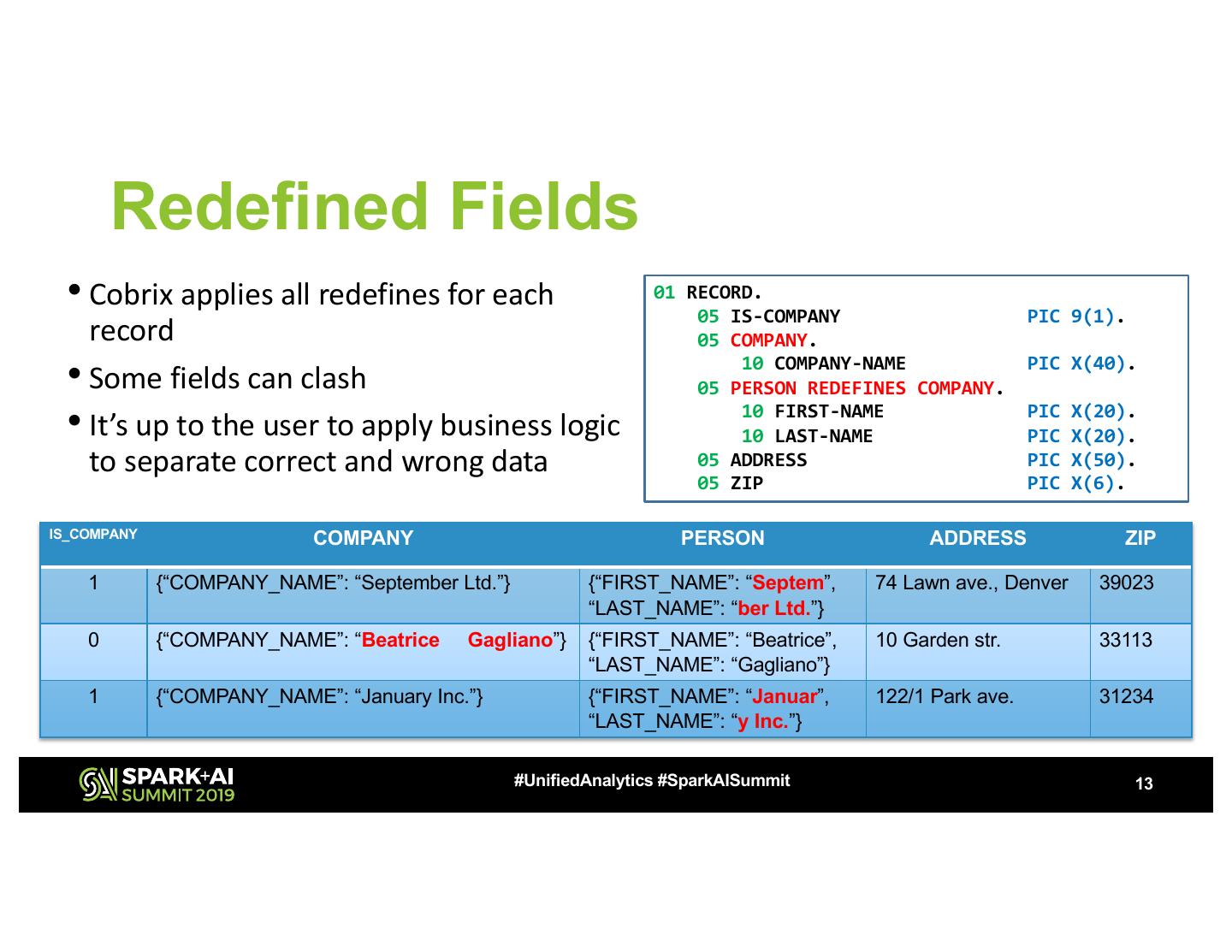
13 . Redefined Fields • Cobrix applies all redefines for each 01 RECORD. 05 IS-COMPANY PIC 9(1). record 05 COMPANY. • Some fields can clash 10 COMPANY-NAME 05 PERSON REDEFINES COMPANY. PIC X(40). • It’s up to the user to apply business logic 10 FIRST-NAME 10 LAST-NAME PIC PIC X(20). X(20). to separate correct and wrong data 05 ADDRESS PIC X(50). 05 ZIP PIC X(6). IS_COMPANY COMPANY PERSON ADDRESS ZIP 1 {“COMPANY_NAME”: “September Ltd.”} {“FIRST_NAME”: “Septem”, 74 Lawn ave., Denver 39023 “LAST_NAME”: “ber Ltd.”} 0 {“COMPANY_NAME”: “Beatrice Gagliano”} {“FIRST_NAME”: “Beatrice”, 10 Garden str. 33113 “LAST_NAME”: “Gagliano”} 1 {“COMPANY_NAME”: “January Inc.”} {“FIRST_NAME”: “Januar”, 122/1 Park ave. 31234 “LAST_NAME”: “y Inc.”} #UnifiedAnalytics #SparkAISummit 13
14 . Redefined Fields clean up df.select($"IS_COMPANY", when($"IS_COMPANY" === true, "COMPANY_NAME") .otherwise(null).as("COMPANY_NAME"), when($"IS_COMPANY" === false, "CONTACTS") .otherwise(null).as("FIRST_NAME")), ... IS_COMPANY COMPANY_NAME FIRST_NAME LAST_NAME ADDRESS ZIP 1 September Ltd. 74 Lawn ave., Denver 39023 0 Beatrice Gagliano 10 Garden str. 33113 1 January Inc. 122/1 Park ave. 31234 #UnifiedAnalytics #SparkAISummit 14
15 .Hierarchical DBs COMPANY Root segment • Several record types ID: █ █ █ █ █ █ █ █ █ Name: █ █ █ █ █ █ █ █ █ █ █ █ – AKA segments Address: █ █ █ █ █ █ █ █ █ Child segment • Each segment type has CONTACT-PERSON Name: █ █ █ █ █ █ █ █ its own schema █ █ █ █ █ █ █ █ █ Phone #: █ █ █ █ █ █ █ • Parent-child CONTACT-PERSON Child segment relationships between Name: █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ segments … Phone #: █ █ █ █ █ █ █ #UnifiedAnalytics #SparkAISummit 15
16 .Variable Length Records (VLRs) • When transferred from a mainframe a hierarchical database becomes – A sequence of records • To read next record a previous record should be read first • A sequential format by it's nature PERSON COMPANY COMPANY PERSON Name: █ █ █ █ █ █ █ █ ID: █ █ █ █ █ █ █ █ █ ID: █ █ █ █ █ █ █ █ █ Name: █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ Name: █ █ █ █ █ █ █ █ █ █ █ █ Name: █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ PERSON Phone #: █ █ █ █ █ █ █ Address: █ █ █ █ █ █ █ █ █ Address: █ █ █ █ █ █ █ █ █ Phone #: █ █ █ █ █ █ █ Name: █ █ █ █ █ █ █ █ COMPANY PERSON A * N J O H N GName:A J 3 ID: 2 8 0 0 0 3 9 4 1 2 S H K█ █ D A N E █ █ █ █ K S I A S S A S K A S A L , S D F O O . C O M X L Q O K ( █ █ █ █ █ █ █ Phone #: █ █ █ █ █ █ █ G A } S N B W ER O SB E < Name: E x a m p l e . c o m █ N J X I C W L D H J P A S B C + 2 3 1 1 - 3 2 7 C = D 1 2 0 0 0 F H R T S █ █ 0 D . K A I O DPhoneA #:P+ 9D3 5 F2 8 C0 J S C D C D C W E P 1 9 1 2 3 – 3 1 2 2 1 . 3 1 F A D F L 1 7 Address: 1 0 █ G a r d e n A data file #UnifiedAnalytics #SparkAISummit 16
17 .Step 1. Define a copybook The combined copybook has to contain all the segments as redefined fields: 01 COMPANY-DETAILS. 05 SEGMENT-ID PIC X(5). Common fields 05 COMPANY-ID PIC X(10). 05 COMPANY. 10 NAME PIC X(15). Segment 1 redefines 10 ADDRESS PIC X(25). 10 REG-NUM PIC 9(8) COMP. 05 CONTACT REDEFINES COMPANY. 10 PHONE-NUMBER PIC X(17). Segment 2 10 CONTACT-PERSON PIC X(28). #UnifiedAnalytics #SparkAISummit 17
18 .Step 2. Specify the VLR option • The code snippet for reading the data: val df = spark .read .format("cobol") .option("copybook", "/path/to/copybook.cpy") .option("is_record_sequence", "true") .load("examples/multisegment_data") #UnifiedAnalytics #SparkAISummit 18
19 .Step 3. Reading all the segments • The dataset for the whole copybook: SEGMENT_ID COMPANY_ID COMPANY CONTACT C 1005918818 [ ABCD Ltd. ] [ invalid ] P 1005918818 [ invalid ] [ Cliff Wallingford ] C 1036146222 [ DEFG Ltd. ] [ invalid ] P 1036146222 [ invalid ] [ Beatrice Gagliano ] C 1045855294 [ Robotrd Inc. ] [ invalid ] P 1045855294 [ invalid ] [ Doretha Wallingford ] P 1045855294 [ invalid ] [ Deshawn Benally ] P 1045855294 [ invalid ] [ Willis Tumlin ] C 1057751949 [ Xingzhoug ] [ invalid ] P 1057751949 [ invalid ] [ Mindy Boettcher ] #UnifiedAnalytics #SparkAISummit 19
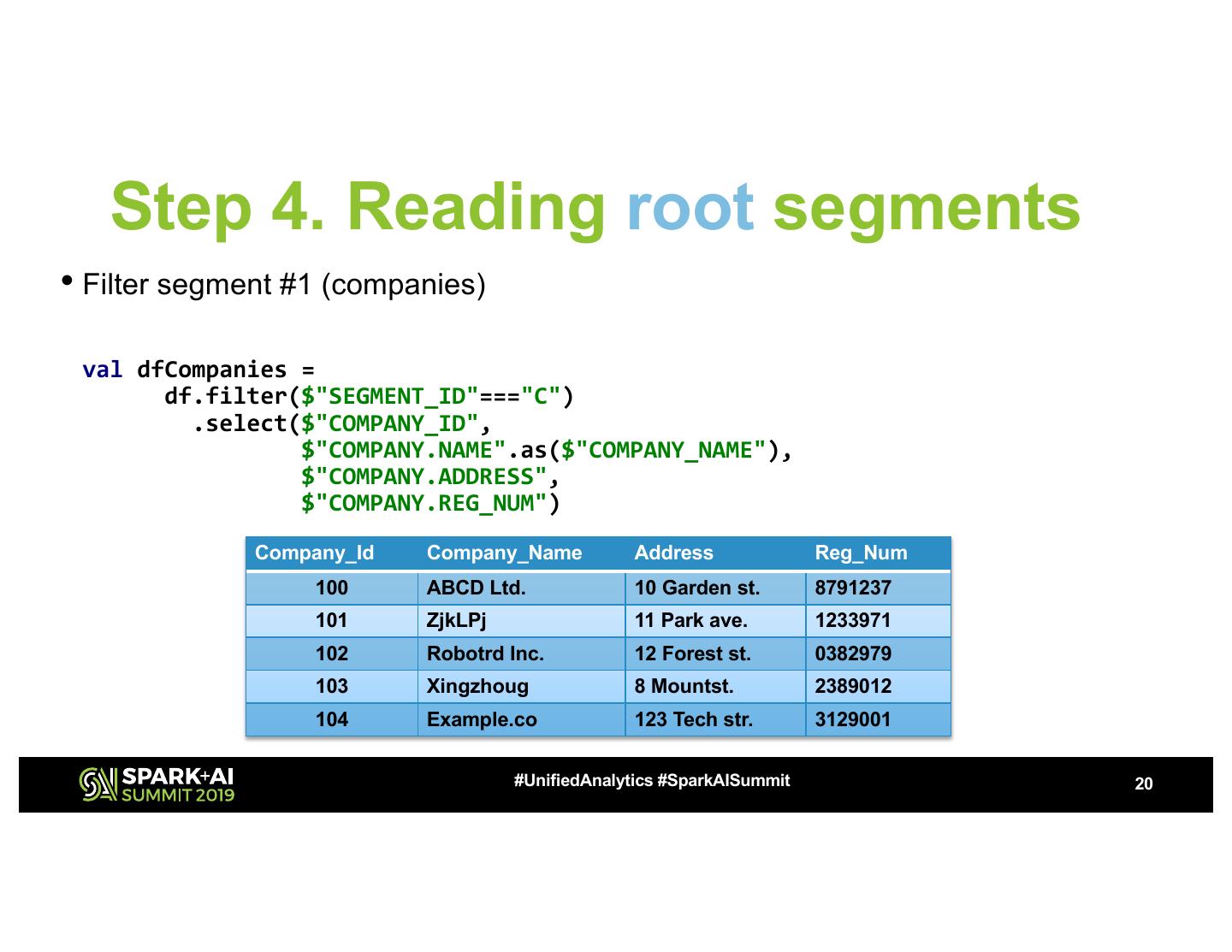
20 . Step 4. Reading root segments • Filter segment #1 (companies) val dfCompanies = df.filter($"SEGMENT_ID"==="C") .select($"COMPANY_ID", $"COMPANY.NAME".as($"COMPANY_NAME"), $"COMPANY.ADDRESS", $"COMPANY.REG_NUM") Company_Id Company_Name Address Reg_Num 100 ABCD Ltd. 10 Garden st. 8791237 101 ZjkLPj 11 Park ave. 1233971 102 Robotrd Inc. 12 Forest st. 0382979 103 Xingzhoug 8 Mountst. 2389012 104 Example.co 123 Tech str. 3129001 #UnifiedAnalytics #SparkAISummit 20
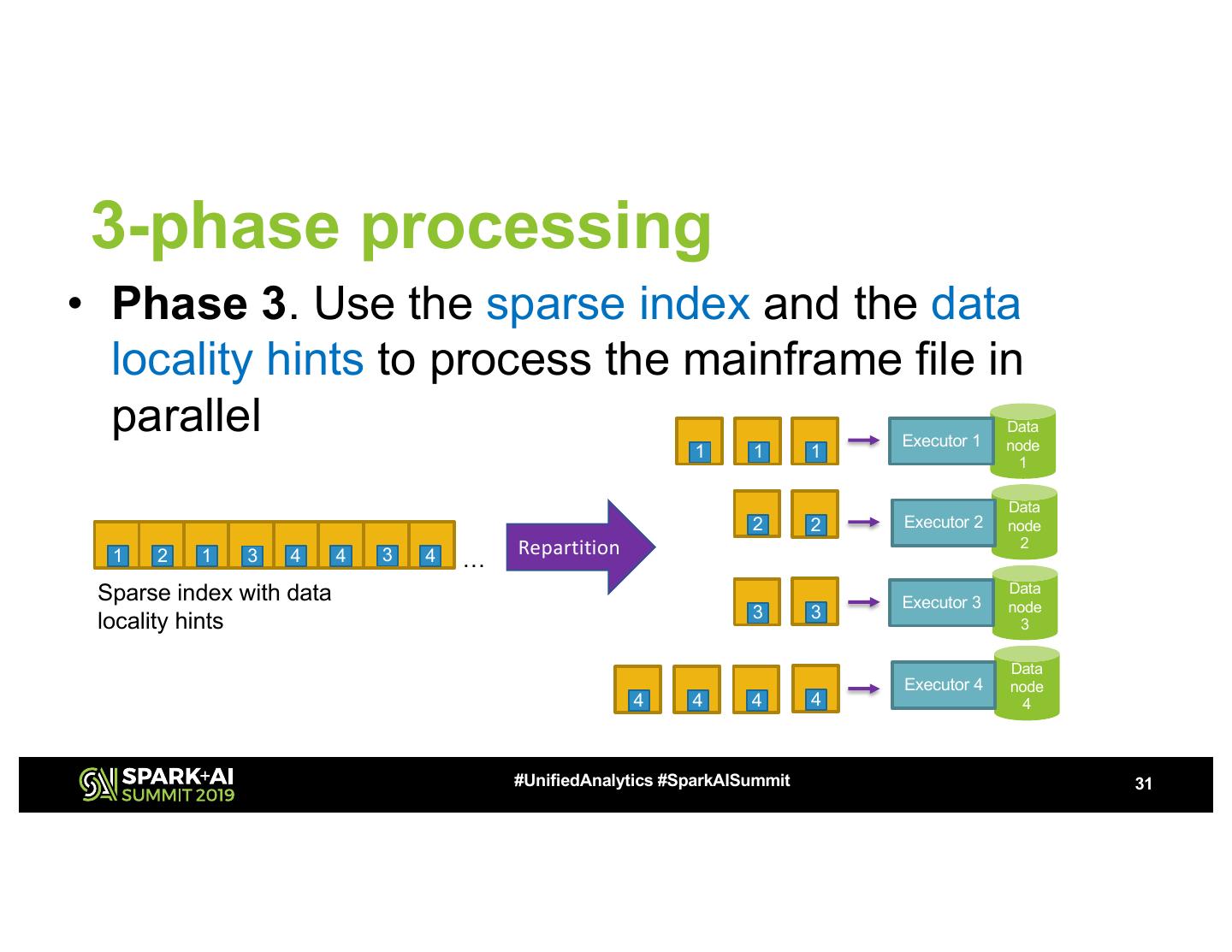
21 . Step 5. Reading child segments • Filter segment #2 (people) using segment filter pushdown val dfContacts = spark.read.format("cobol")… .option("segment_filter”, "P") .select($"COMPANY_ID", $”CONTACT.CONTACT_PERSON", $”CONTACT.PHONE_NUMBER") Company_Id Contact_Person Phone_Number 100 Marry +32186331 100 Colyn +23769123 102 Robert +12389679 102 Teresa +32187912 102 Laura +42198723 #UnifiedAnalytics #SparkAISummit 21
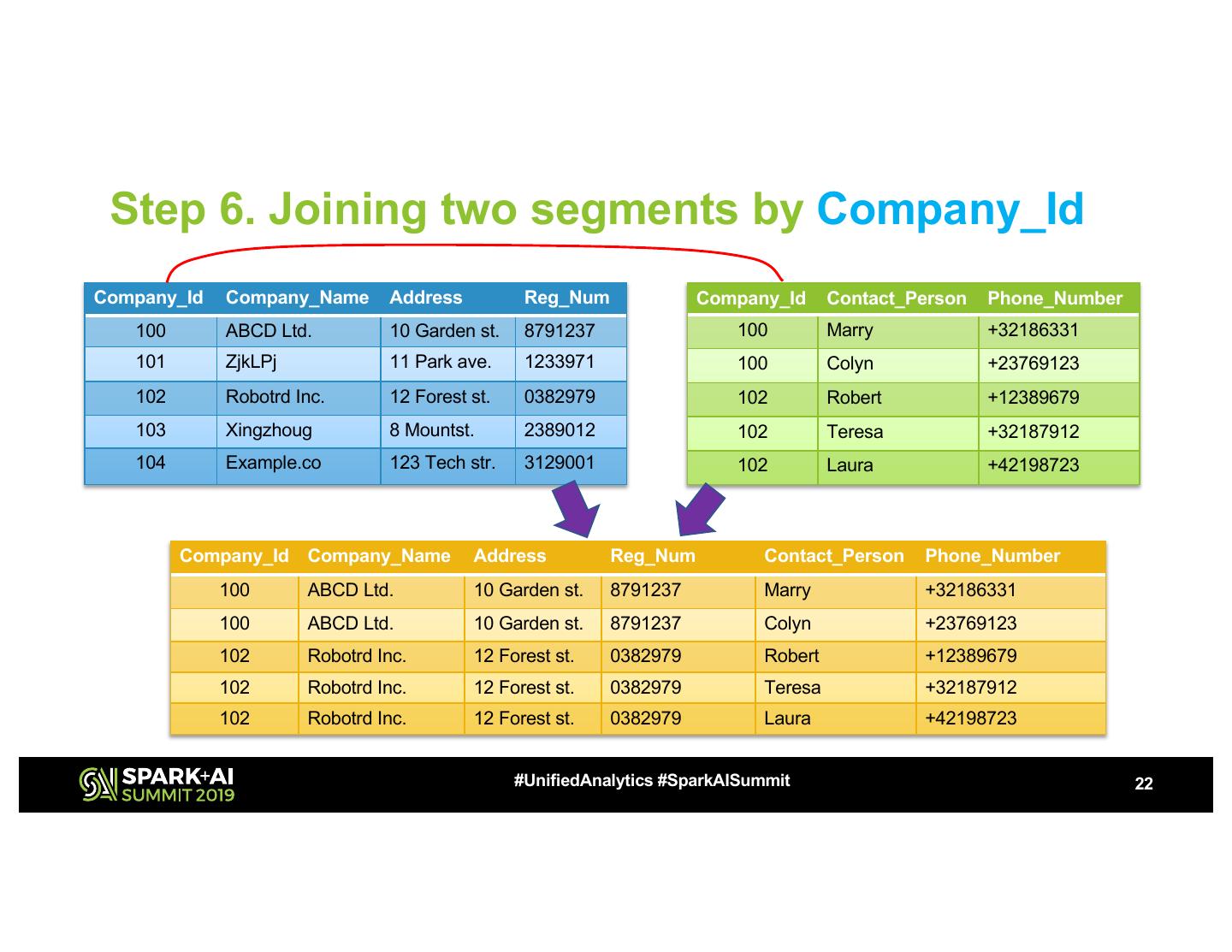
22 . Step 6. Joining two segments by Company_Id Company_Id Company_Name Address Reg_Num Company_Id Contact_Person Phone_Number 100 ABCD Ltd. 10 Garden st. 8791237 100 Marry +32186331 101 ZjkLPj 11 Park ave. 1233971 100 Colyn +23769123 102 Robotrd Inc. 12 Forest st. 0382979 102 Robert +12389679 103 Xingzhoug 8 Mountst. 2389012 102 Teresa +32187912 104 Example.co 123 Tech str. 3129001 102 Laura +42198723 Company_Id Company_Name Address Reg_Num Contact_Person Phone_Number 100 ABCD Ltd. 10 Garden st. 8791237 Marry +32186331 100 ABCD Ltd. 10 Garden st. 8791237 Colyn +23769123 102 Robotrd Inc. 12 Forest st. 0382979 Robert +12389679 102 Robotrd Inc. 12 Forest st. 0382979 Teresa +32187912 102 Robotrd Inc. 12 Forest st. 0382979 Laura +42198723 #UnifiedAnalytics #SparkAISummit 22
23 . Step 7. Denormalize data • The joined table can also be denormalized for document storage { val dfCombined = "COMPANY_ID": "8216281722", "COMPANY_NAME": "ABCD Ltd.", dfJoined "ADDRESS": "74 Lawn ave., New York", .groupBy($"COMPANY_ID", ”REG_NUM": "33718594", $"COMPANY_NAME", "CONTACTS": [ $"ADDRESS", { $"REG_NUM") "CONTACT_PERSON": "Cassey Norgard", .agg( "PHONE_NUMBER": "+(595) 641 62 32" collect_list( }, struct($"CONTACT_PERSON", { "CONTACT_PERSON": "Verdie Deveau", $"PHONE_NUMBER")) "PHONE_NUMBER": "+(721) 636 72 35" .as("CONTACTS")) }, { "CONTACT_PERSON": "Otelia Batman", "PHONE_NUMBER": "+(813) 342 66 28" } ] } #UnifiedAnalytics #SparkAISummit 23
24 .Restore parent-child relationships Root segment • In our example we had COMPANY ID: █ █ █ █ █ █ █ █ █ COMPANY_ID field that Name: █ █ █ █ █ █ █ █ █ █ █ █ is present in all segments Address: █ █ █ █ █ █ █ █ █ Child segment • In real copybooks this is CONTACT-PERSON Name: █ █ █ █ █ █ █ █ not the case █ █ █ █ █ █ █ █ █ Phone #: █ █ █ █ █ █ █ CONTACT-PERSON Child segment • What can we do? Name: █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ █ … Phone #: █ █ █ █ █ █ █ #UnifiedAnalytics #SparkAISummit 24
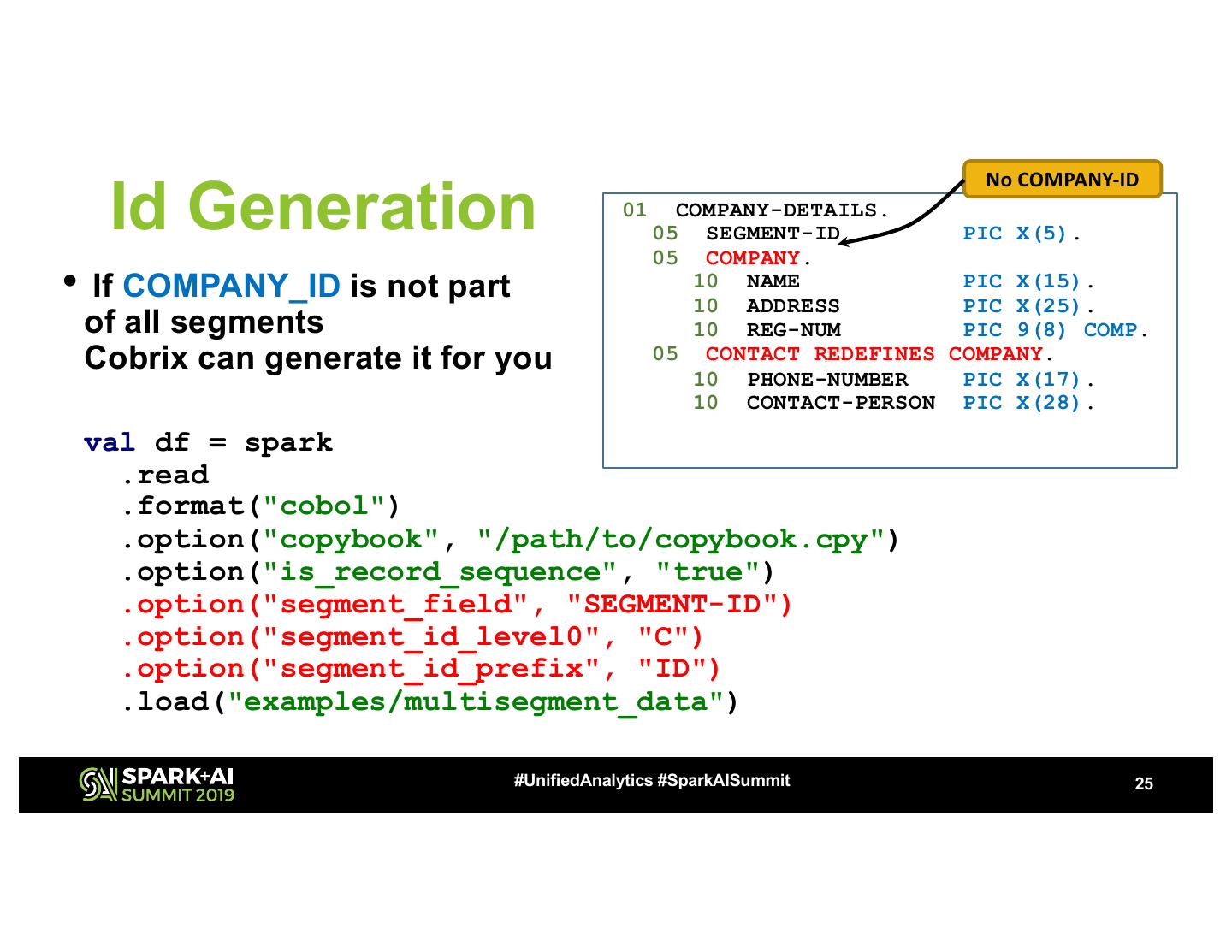
25 . No COMPANY-ID Id Generation 01 COMPANY-DETAILS. 05 SEGMENT-ID PIC X(5). 05 COMPANY. • If COMPANY_ID is not part 10 NAME 10 ADDRESS PIC X(15). PIC X(25). of all segments 10 REG-NUM PIC 9(8) COMP. Cobrix can generate it for you 05 CONTACT REDEFINES COMPANY. 10 PHONE-NUMBER PIC X(17). 10 CONTACT-PERSON PIC X(28). val df = spark .read .format("cobol") .option("copybook", "/path/to/copybook.cpy") .option("is_record_sequence", "true") .option("segment_field", "SEGMENT-ID") .option("segment_id_level0", "C") .option("segment_id_prefix", "ID") .load("examples/multisegment_data") #UnifiedAnalytics #SparkAISummit 25
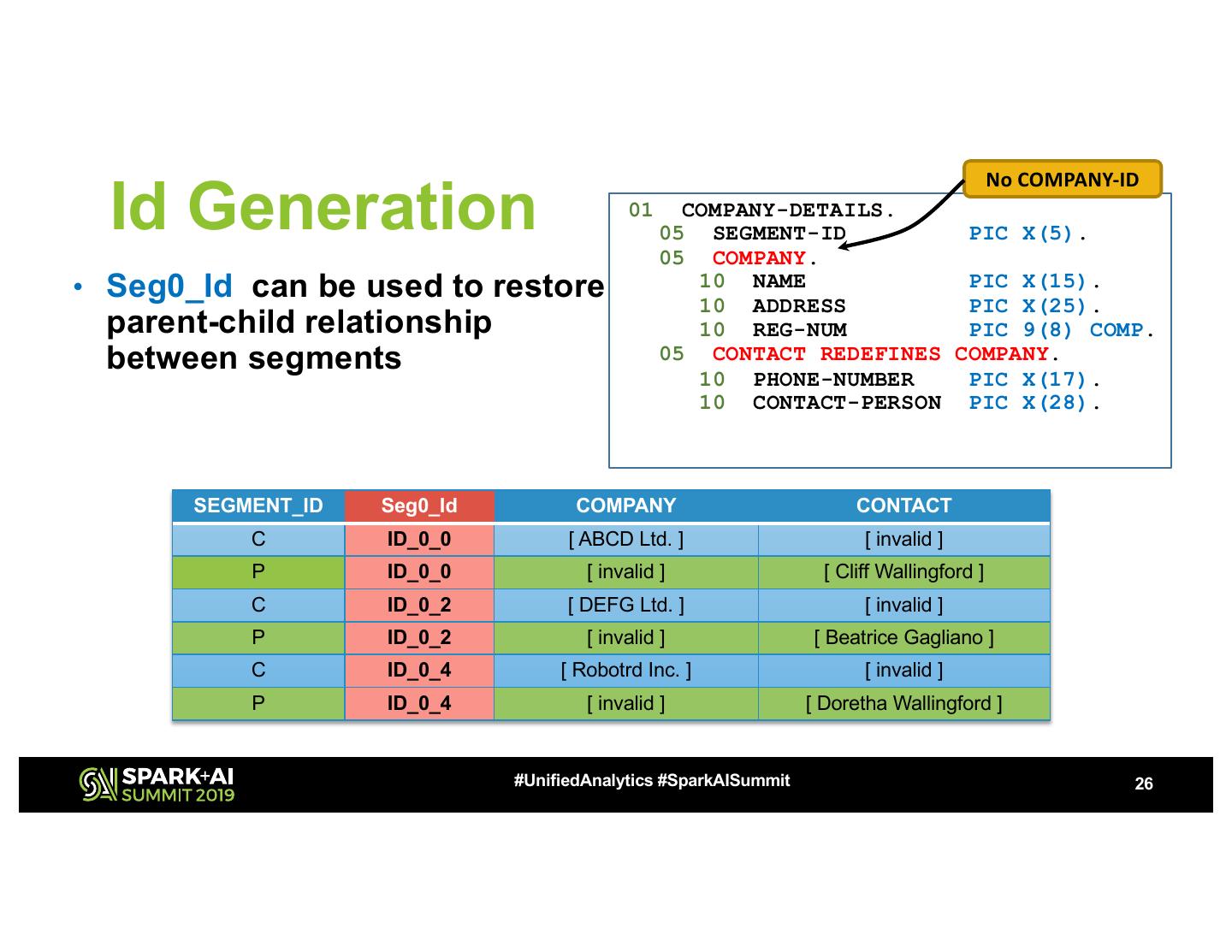
26 . No COMPANY-ID Id Generation 01 COMPANY-DETAILS. 05 SEGMENT-ID PIC X(5). 05 COMPANY. • Seg0_Id can be used to restore 10 NAME PIC X(15). 10 ADDRESS PIC X(25). parent-child relationship 10 REG-NUM PIC 9(8) COMP. between segments 05 CONTACT REDEFINES COMPANY. 10 PHONE-NUMBER PIC X(17). 10 CONTACT-PERSON PIC X(28). SEGMENT_ID Seg0_Id COMPANY CONTACT C ID_0_0 [ ABCD Ltd. ] [ invalid ] P ID_0_0 [ invalid ] [ Cliff Wallingford ] C ID_0_2 [ DEFG Ltd. ] [ invalid ] P ID_0_2 [ invalid ] [ Beatrice Gagliano ] C ID_0_4 [ Robotrd Inc. ] [ invalid ] P ID_0_4 [ invalid ] [ Doretha Wallingford ] #UnifiedAnalytics #SparkAISummit 26
27 . Segment-Redefine Filter Pushdown • Allows to resolve segment redefines on parsing stage for performance val df = spark .read .format("cobol") .option("copybook", "/path/to/copybook.cpy") .option("is_record_sequence", "true") .option("segment_field", "SEGMENT-ID") .option("redefine_segment_id_map:0", ”COMPANY => C") .option("redefine_segment_id_map:1", ”CONTACT => P") .load("examples/multisegment_data") #UnifiedAnalytics #SparkAISummit 27
28 . Performance challenge of VLRs • Naturally sequential files Throughput, variable record length – To read next record the 180 prior Sequential processing record need to be read first 160 • Each record had a length 140 field 120 – Acts as a pointer to the next 100 record MB/s • No record delimiter when 80 reading a file from the 60 middle 40 10 MB/s 20 VLR structure 0 0 10 20 30 40 50 60 70 Number of Spark cores #UnifiedAnalytics #SparkAISummit 28
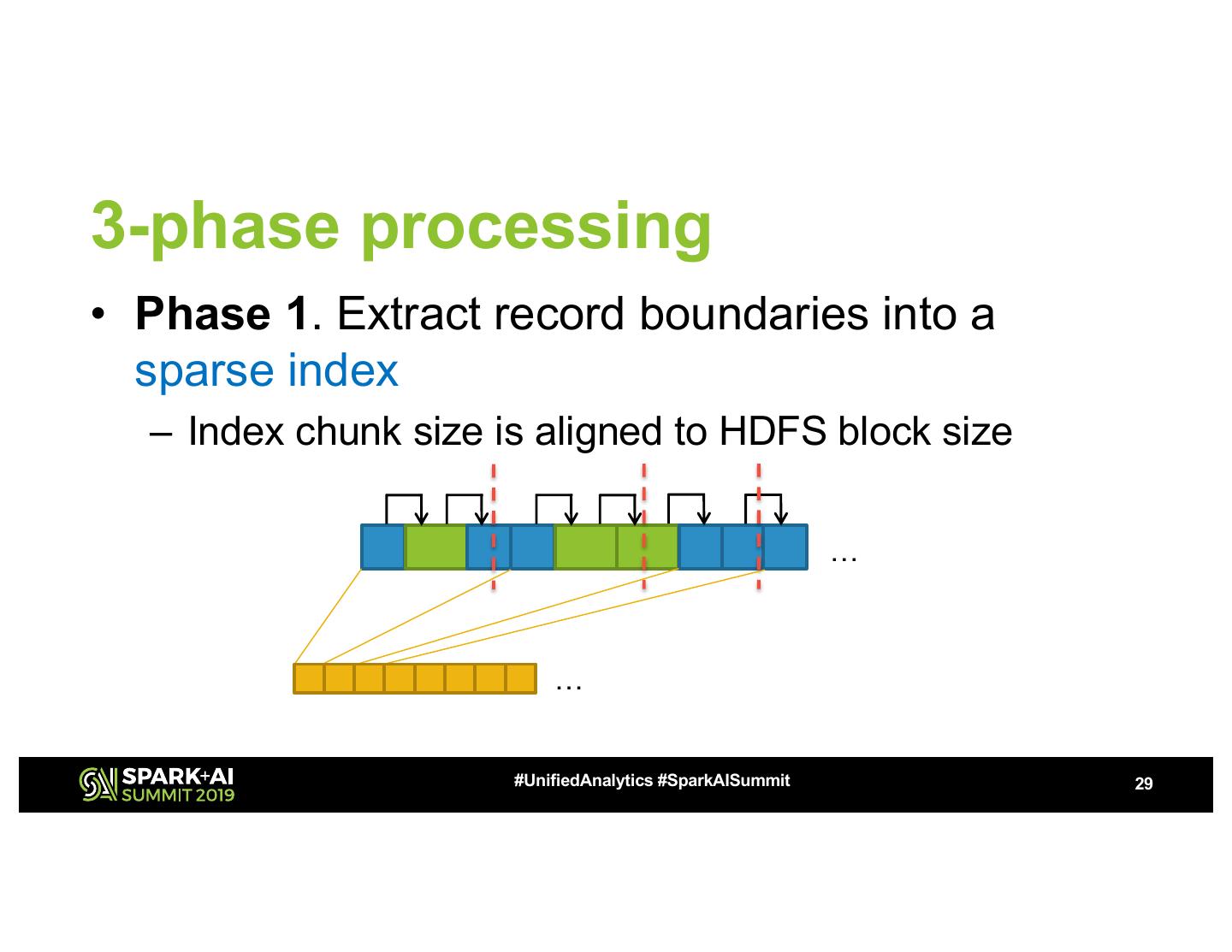
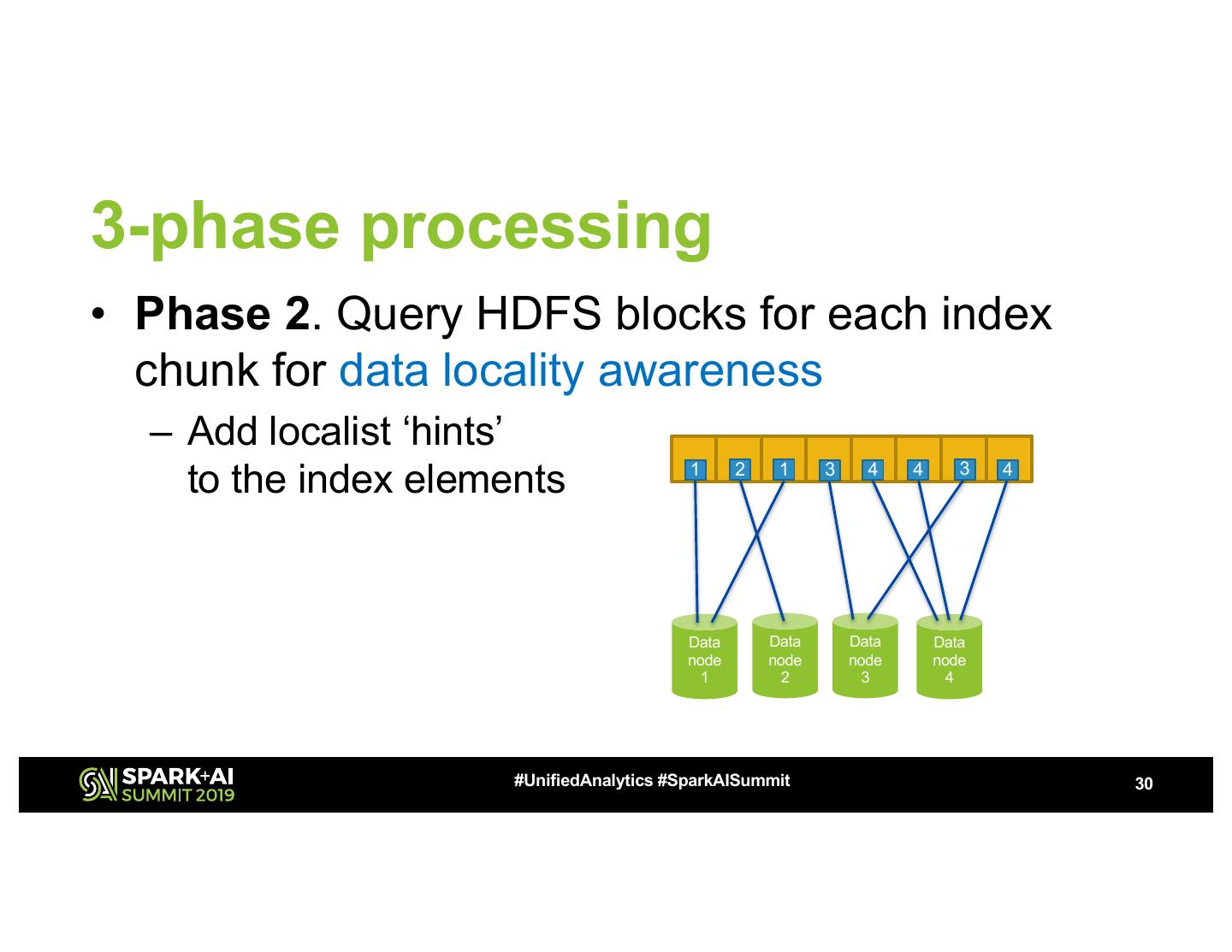
29 .3-phase processing • Phase 1. Extract record boundaries into a sparse index – Index chunk size is aligned to HDFS block size … … #UnifiedAnalytics #SparkAISummit 29
3秒后跳转登录页面
去登陆

