展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Blue Pill / Red Pill :
The Matrix of thousands
of data streams
Knoldus Inc.
#UnifiedDataAnalytics #SparkAISummit
�
3 .About Me
●
My name is Himanshu Gupta
●
Lead Consultant at Knoldus Inc.
●
Twitter: @himanshug735
●
LinkedIn: https://www.linkedin.com/in/himanshu-gupta-25189629/
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .Agenda
●
The Need
●
Challenges
●
Our Solution
●
Future Work
#UnifiedDataAnalytics #SparkAISummit 4
�
5 .The Need: Make Better Use of Real-Time Data
#UnifiedDataAnalytics #SparkAISummit 5
�
6 .The Need: Make Better Use of Real-Time Data
#UnifiedDataAnalytics #SparkAISummit 6
�
7 .Benefits of Real-Time Data
●
In 2014, real-time data analysis reduced crude mortality rate from 7.75% to
6.42% in Queen Alexandra Hospital in Portsmouth and University Hospital
Coventry.
●
World's largest Hedge Fund, Bridgewater, uses Twitter For Real-Time
Economic Modeling.
#UnifiedDataAnalytics #SparkAISummit 7
�
8 .Solution: One Platform
An End-to-end real-time
data platform which can
analyze and prepare data
in a single platform-as-a-
service.
#UnifiedDataAnalytics #SparkAISummit 8
�
9 .Challenge
●
Collecting data from 1000s of
streams is difficult.
●
Using each stream for different
purpose makes processing
harder.
●
Managing data of mission critical
value is a challenge.
#UnifiedDataAnalytics #SparkAISummit 9
�
10 .How to overcome the challenges?
#UnifiedDataAnalytics #SparkAISummit 10
�
11 .Stream Data
●
Streaming data into 1000s of streams is a resource intensive process.
●
Since streaming requires dedicated resources, the number of streams
supported by a system gets limited by the resources available.
●
However, if combined, streams can be managed much more efficiently.
●
Also, starting/stopping a stream becomes easy since data is managed by
group.
#UnifiedDataAnalytics #SparkAISummit 11
�
12 .Group Data
For example, consider a Power
plant which has 100s of devices
emitting data in real-time. The data
contains information about different
parameters of device like
temperature, speed, etc. Since the
data is coming from one source
(power plant) it becomes a good
candidate for grouping data into one
stream.
#UnifiedDataAnalytics #SparkAISummit 12
�
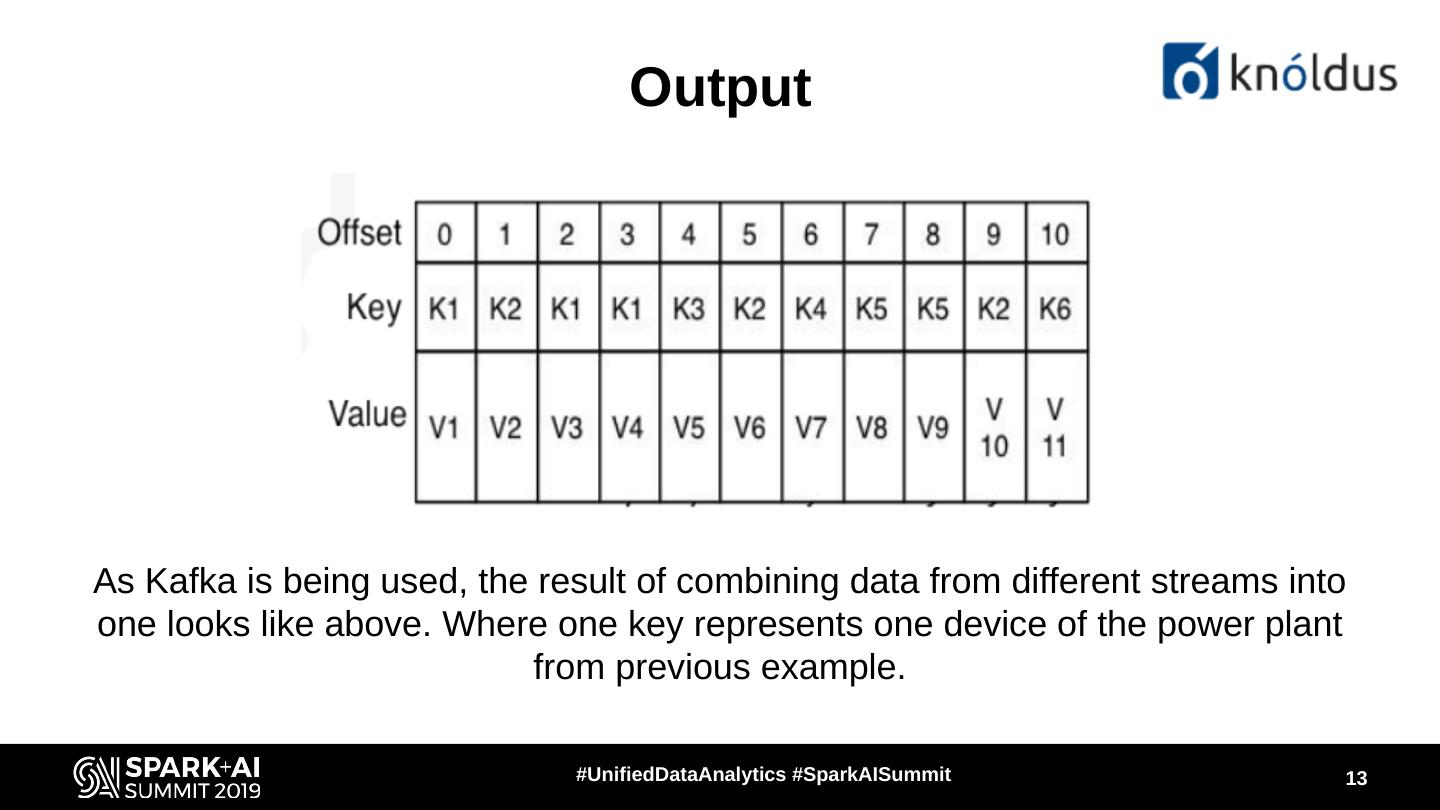
13 . Output
As Kafka is being used, the result of combining data from different streams into
one looks like above. Where one key represents one device of the power plant
from previous example.
#UnifiedDataAnalytics #SparkAISummit 13
�
14 .Analyze Data
●
Analyzing combined/grouped data have
many challenges.
●
For example, applying different analytics
on different data source.
●
Or, managing state of each data source.
#UnifiedDataAnalytics #SparkAISummit 14
�
15 .Use Spark
Since the introduction of
Structured Streaming in
Apache Spark 2.0, the way
processing streams has
changed a lot. As it has
brought a lot of features
which were earlier unheard.
#UnifiedDataAnalytics #SparkAISummit 15
�
16 .Why Spark?
●
Provides support for ad-hoc queries, i.e.,
helps in applying different analytics on
different data source.
●
Manages state of each data source
which via Arbitrary Stateful Operations.
#UnifiedDataAnalytics #SparkAISummit 16
�
17 .Store Data
●
Storing data might look an easy task but
it is not.
●
Because after analysis of multiple data
sources is done it is difficult to
materialize it and save it in different
locations.
●
And, also saving in such a way that
retrieving data becomes Easy.
#UnifiedDataAnalytics #SparkAISummit 17
�
18 .Again! Use Spark
Apache Spark comes to
rescue here as well. Spark
Structured Streaming has
support for 6 different types
of output sinks.
#UnifiedDataAnalytics #SparkAISummit 18
�
19 . Result
The data is saved in a hierarchical file system manner in AWS S3. Each sub file
represents a device/data source in the power plant example.
#UnifiedDataAnalytics #SparkAISummit 19
�
20 .#UnifiedDataAnalytics #SparkAISummit 20
�
21 .Future Work
#UnifiedDataAnalytics #SparkAISummit 21
�
22 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�