






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
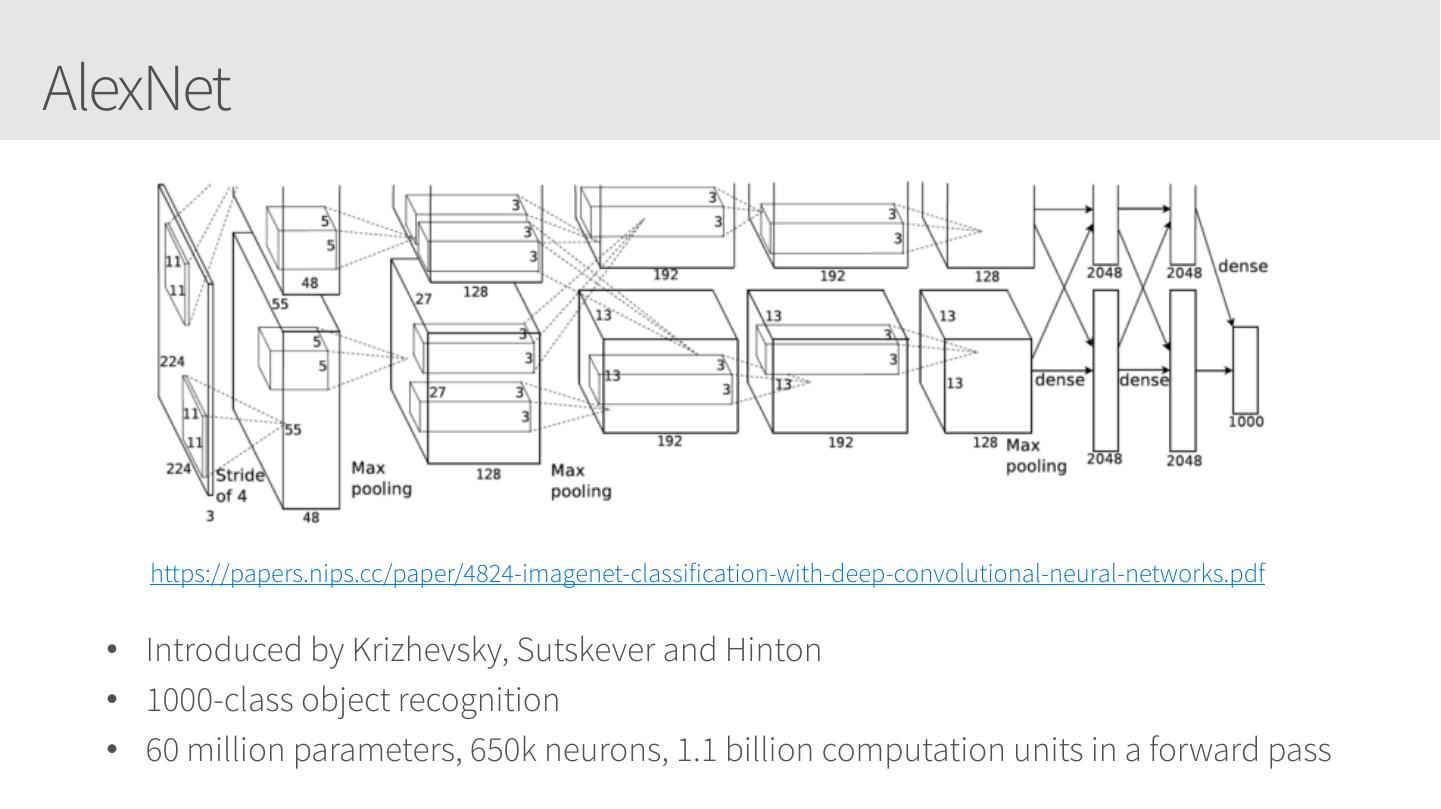
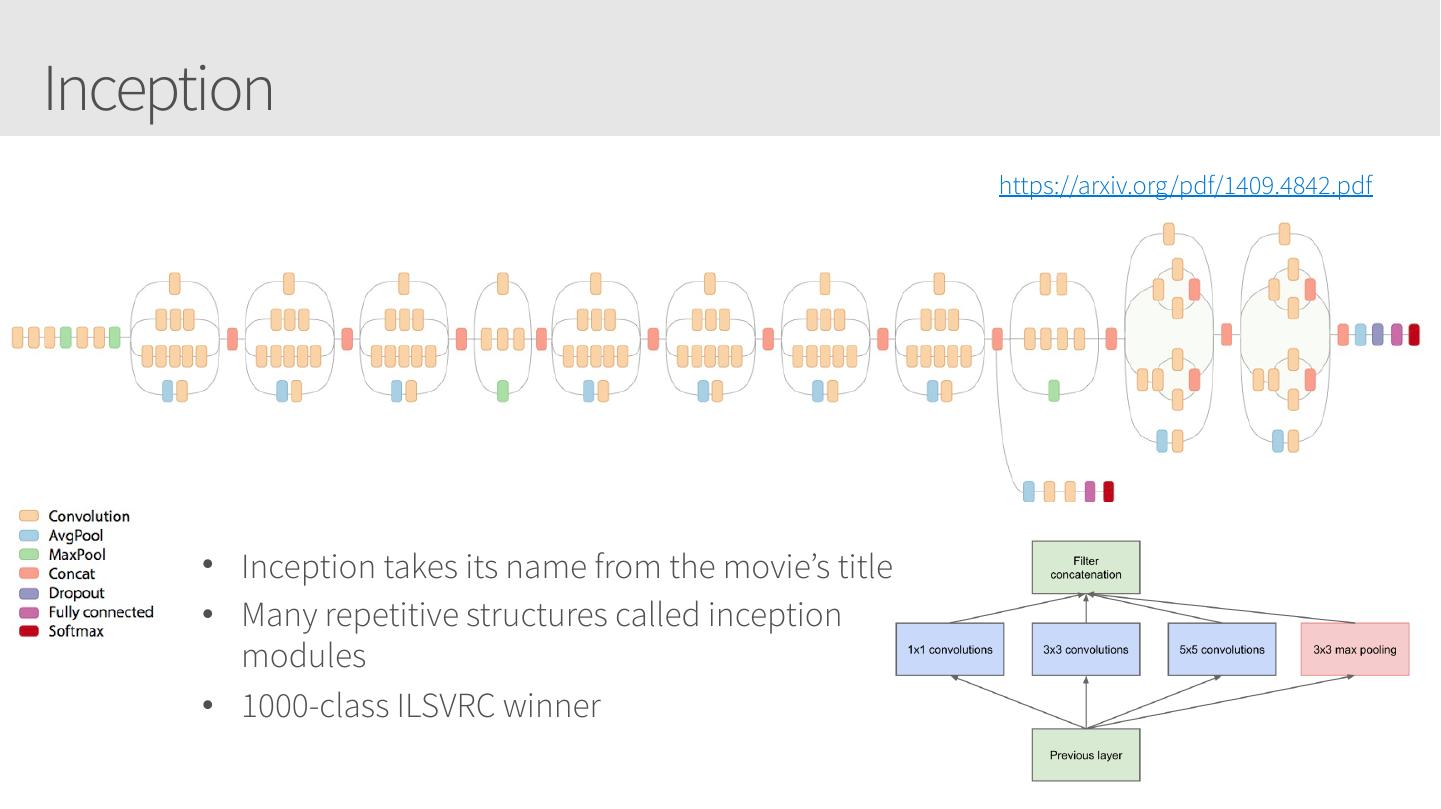
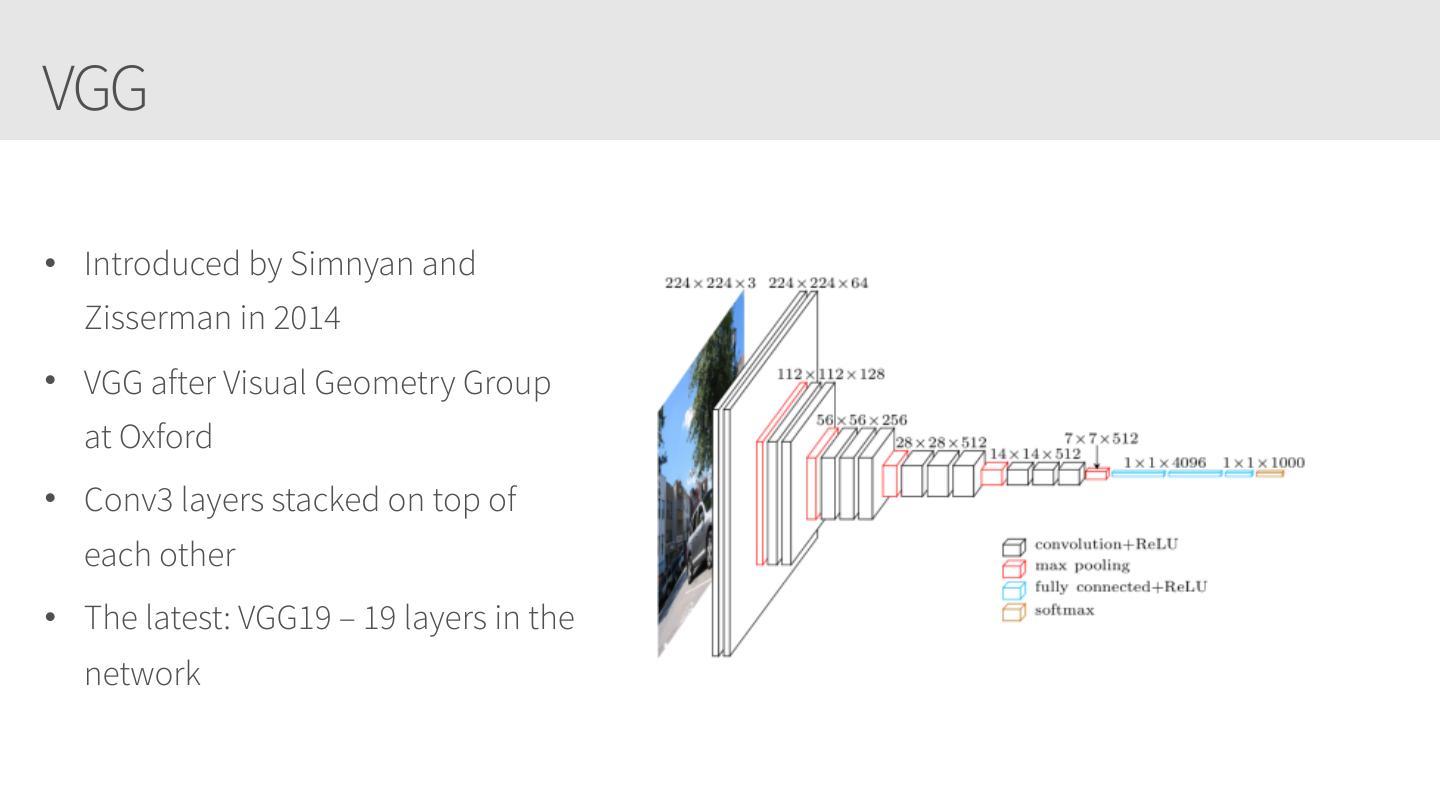
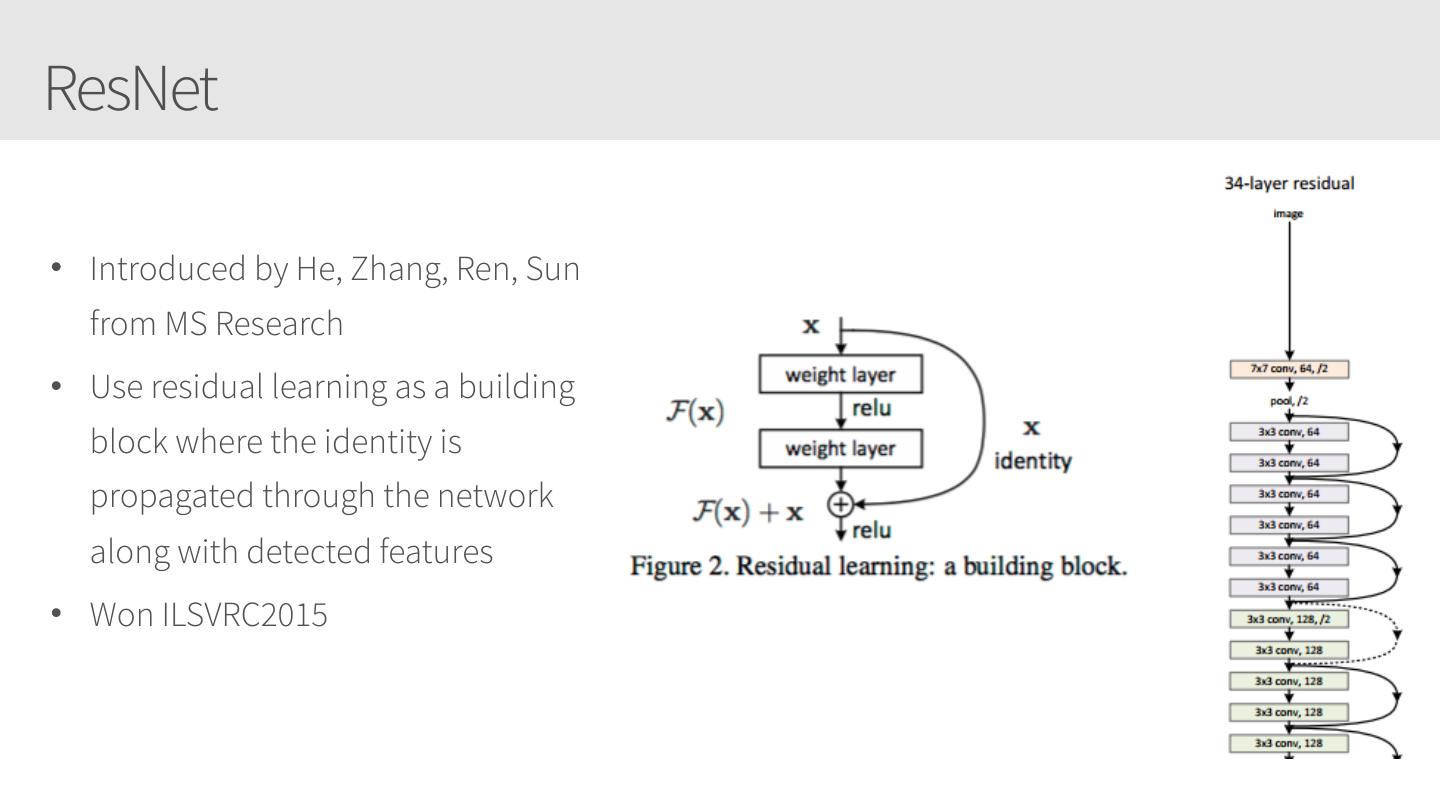
Applying your Convolutional Neural Networks
本Slide以深度学习基础系列的第3部分开始,简要介绍了激活功能,学习速率,优化器和反向传播。 然后它深入研究卷积神经网络,讨论卷积(包括内核,局部连接,步幅,填充和激活函数),汇集(或子采样以减小图像大小)和完全连接的层。 该会议还提供了一些CNN架构的高级概述。 这些PPT中包含的演示在Drasricks上使用TensorFlow后端在Keras上运行。
展开查看详情
1 .Applying your Convolutional Neural Networks
2 .Logistics • We can’t hear you… • Recording will be available… • Slides will be available… • Code samples and notebooks will be available… • Queue up Questions…
3 .VISION Accelerate innovation by unifying data science, engineering and business PRODUCT Unified Analytics Platform powered by Apache Spark™ WHO WE ARE • Founded by the original creators of Apache Spark • Contributes 75% of the open source code, 10x more than any other company • Trained 100k+ Spark users on the Databricks platform
4 .About our speaker Denny Lee Technical Product Marketing Manager Former: • Senior Director of Data Sciences Engineering at SAP Concur • Principal Program Manager at Microsoft • Azure Cosmos DB Engineering Spark and Graph Initiatives • Isotope Incubation Team (currently known as HDInsight) • Bing’s Audience Insights Team • Yahoo!’s 24TB Analysis Services cube
5 .Deep Learning Fundamentals Series This is a three-part series: • Introduction to Neural Networks • Training Neural Networks • Applying your Convolutional Neural Network This series will be make use of Keras (TensorFlow backend) but as it is a fundamentals series, we are focusing primarily on the concepts.
6 .Current Session: Applying Neural Networks • Diving further into CNNs • CNN Architectures • Convolutions at Work!
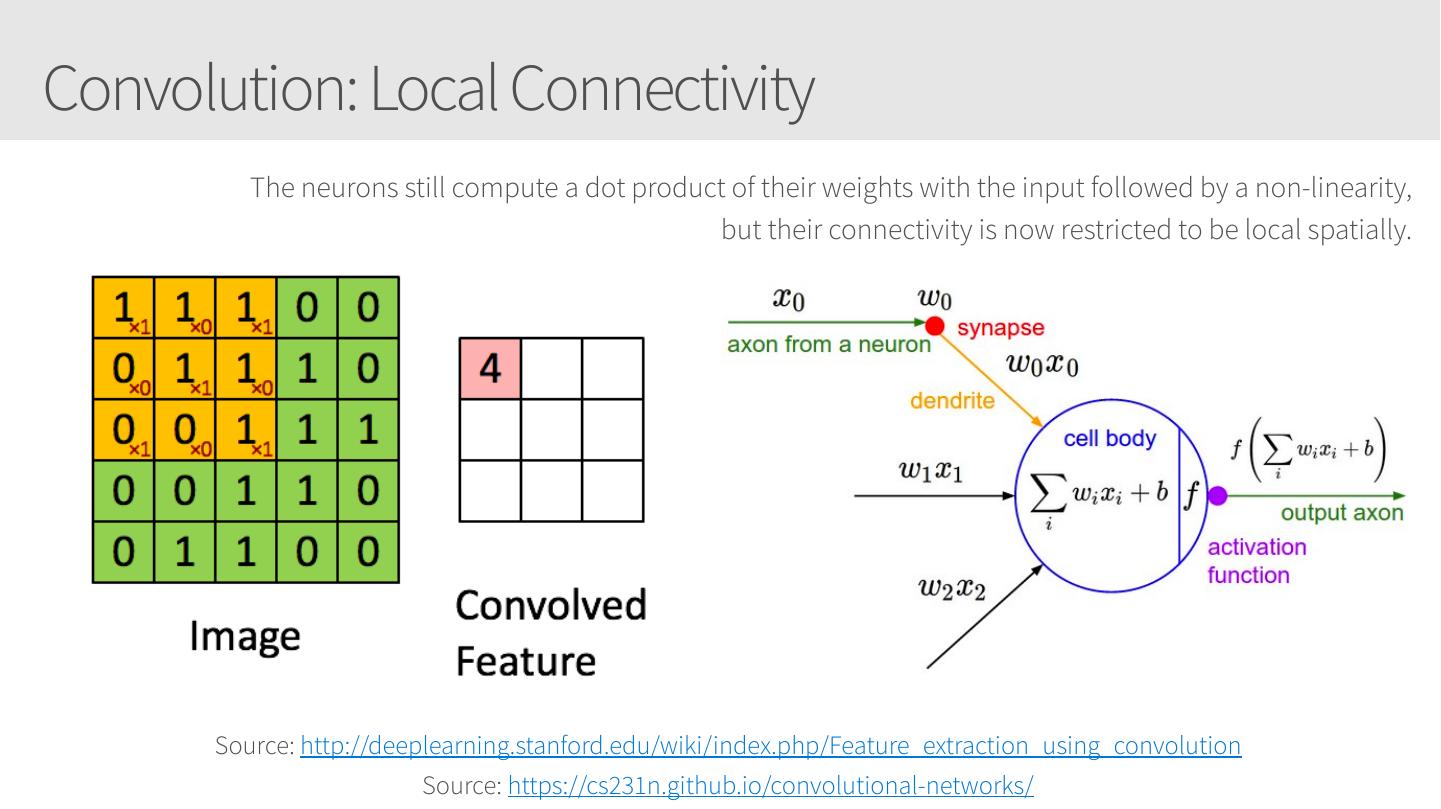
7 .A quick review
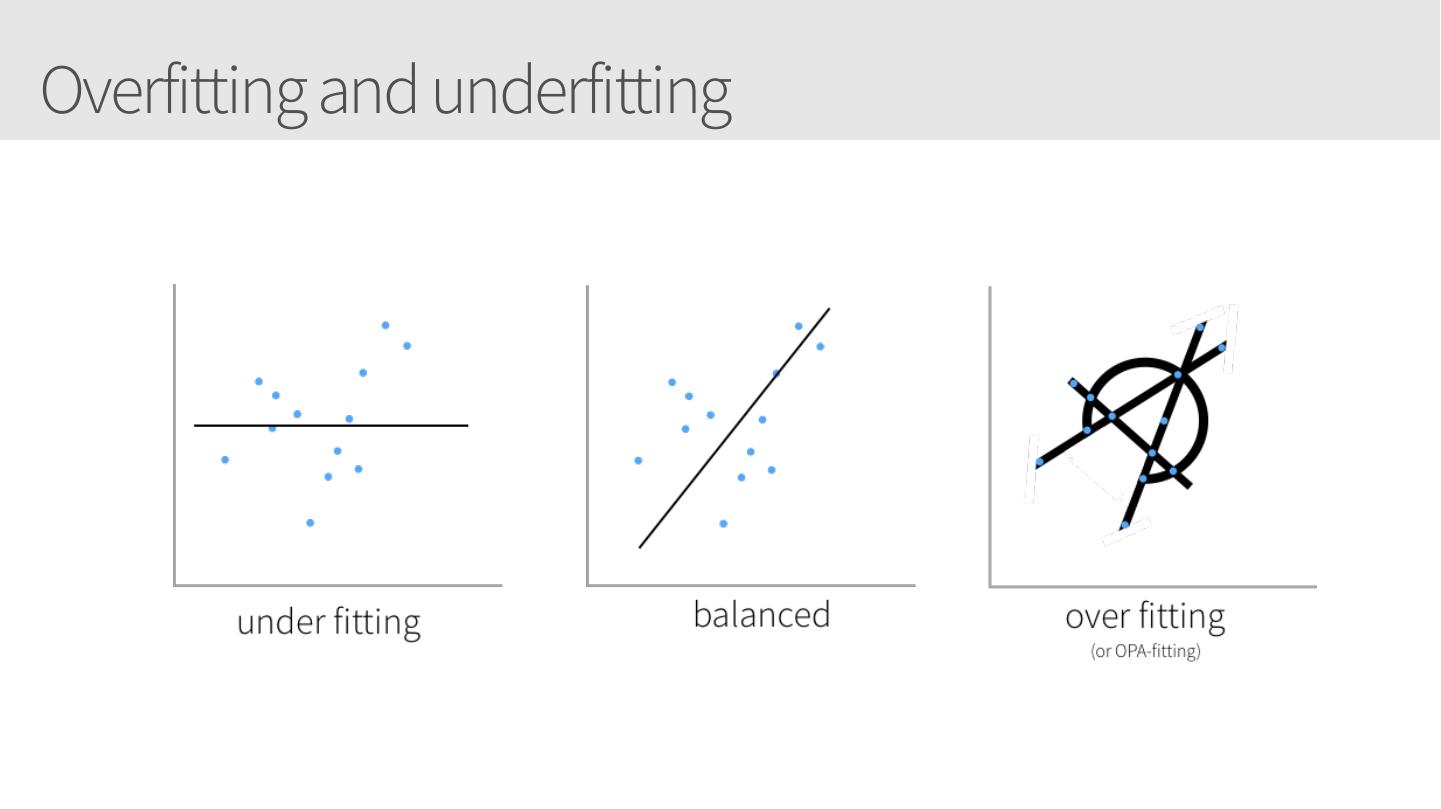
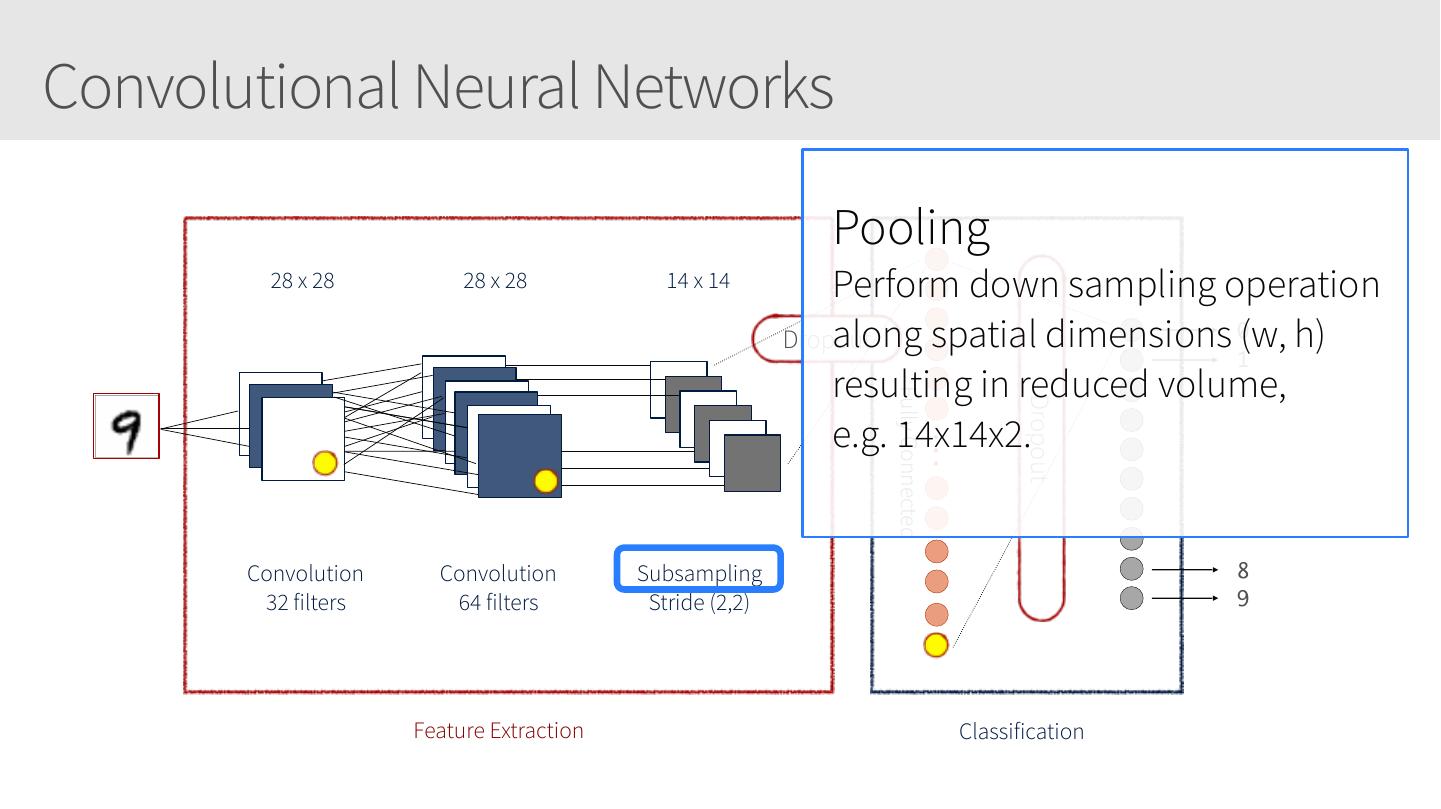
8 .Overfitting and underfitting
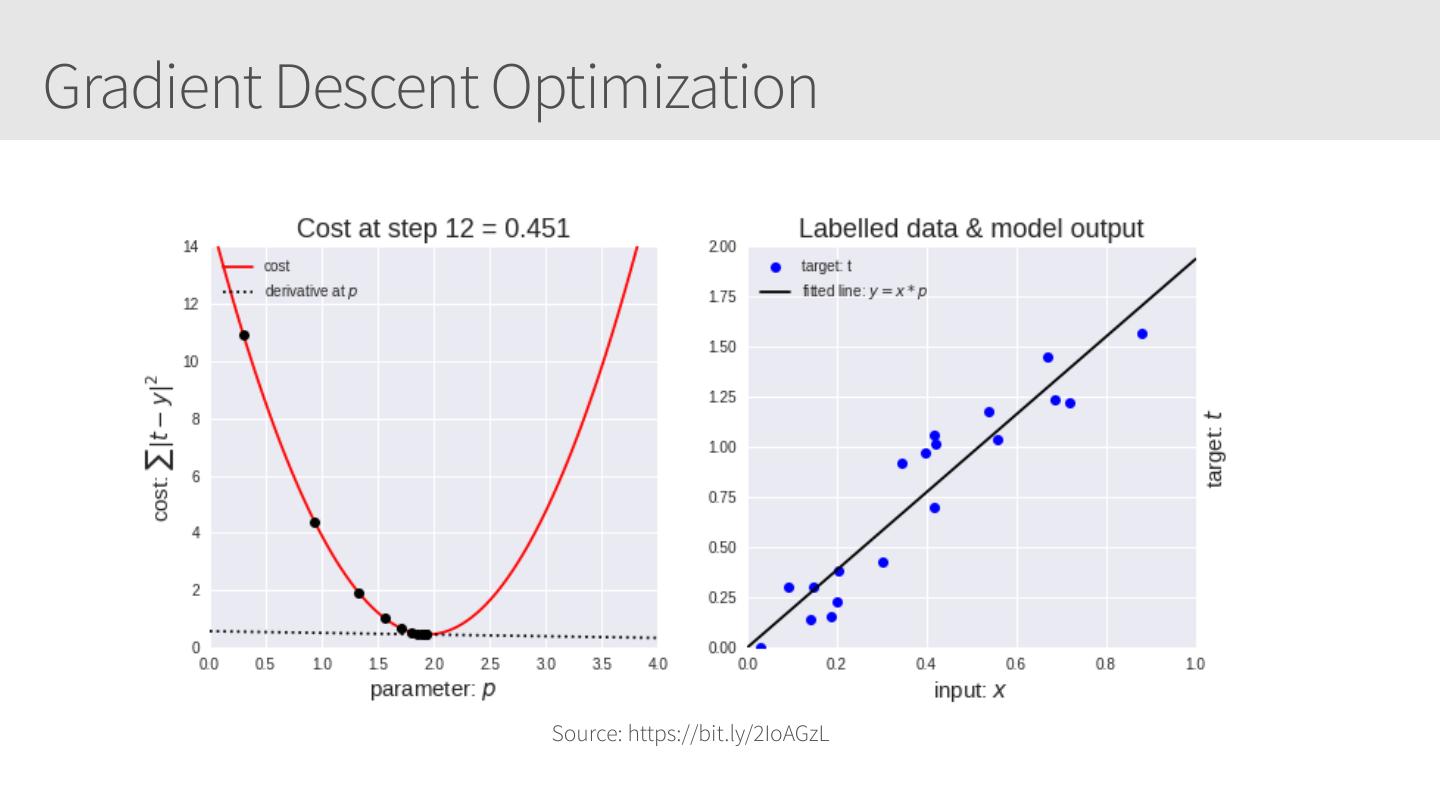
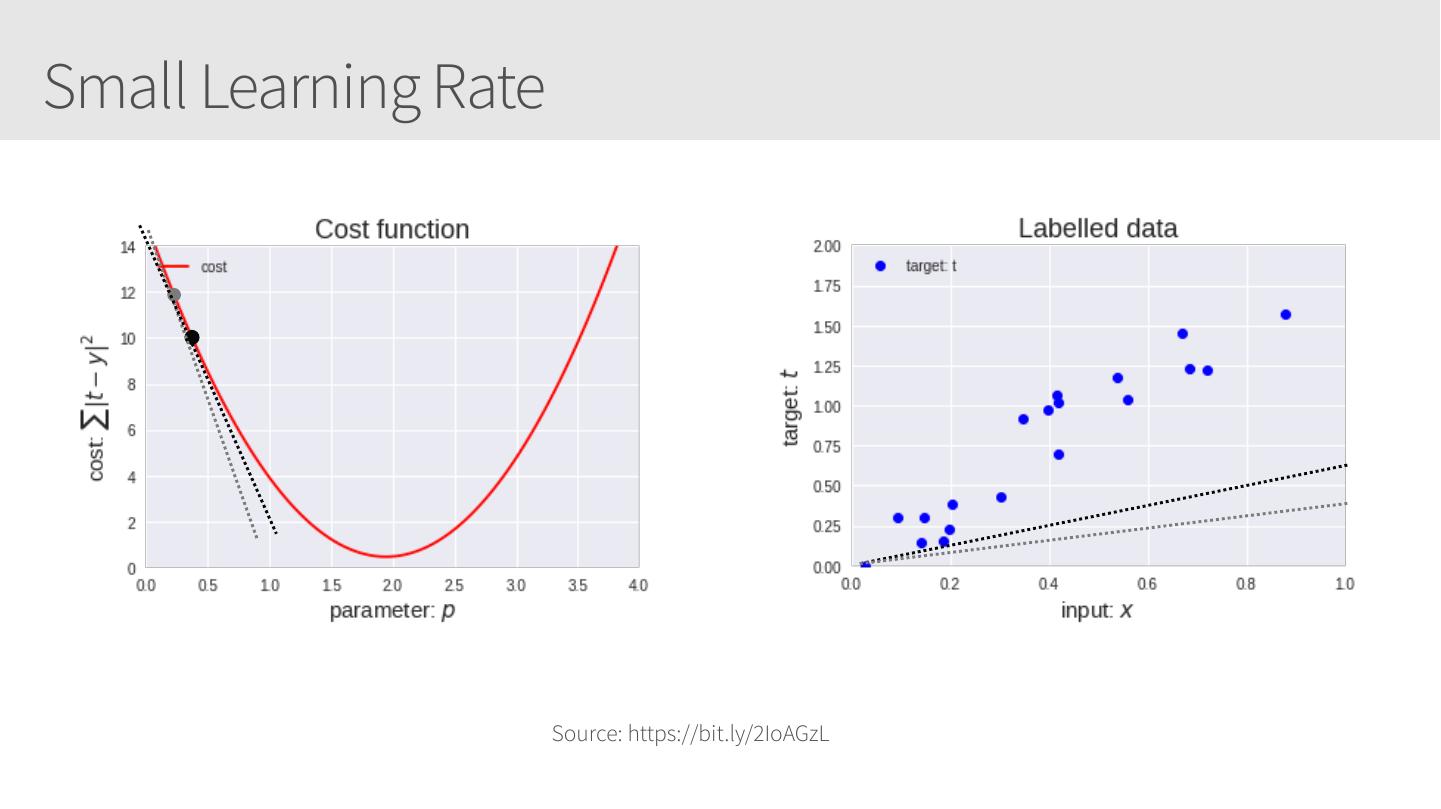
9 .Cost function For this linear regression example, to determine the best p (slope of the line) for y=x⋅p we can calculate the cost function, such as Mean Square Error, Mean absolute error, Mean bias error, SVM Loss, etc. For this example, we’ll use sum of squared absolute differences | t − y |2 ∑ cost = Source: https://bit.ly/2IoAGzL
10 .Gradient Descent Optimization Source: https://bit.ly/2IoAGzL
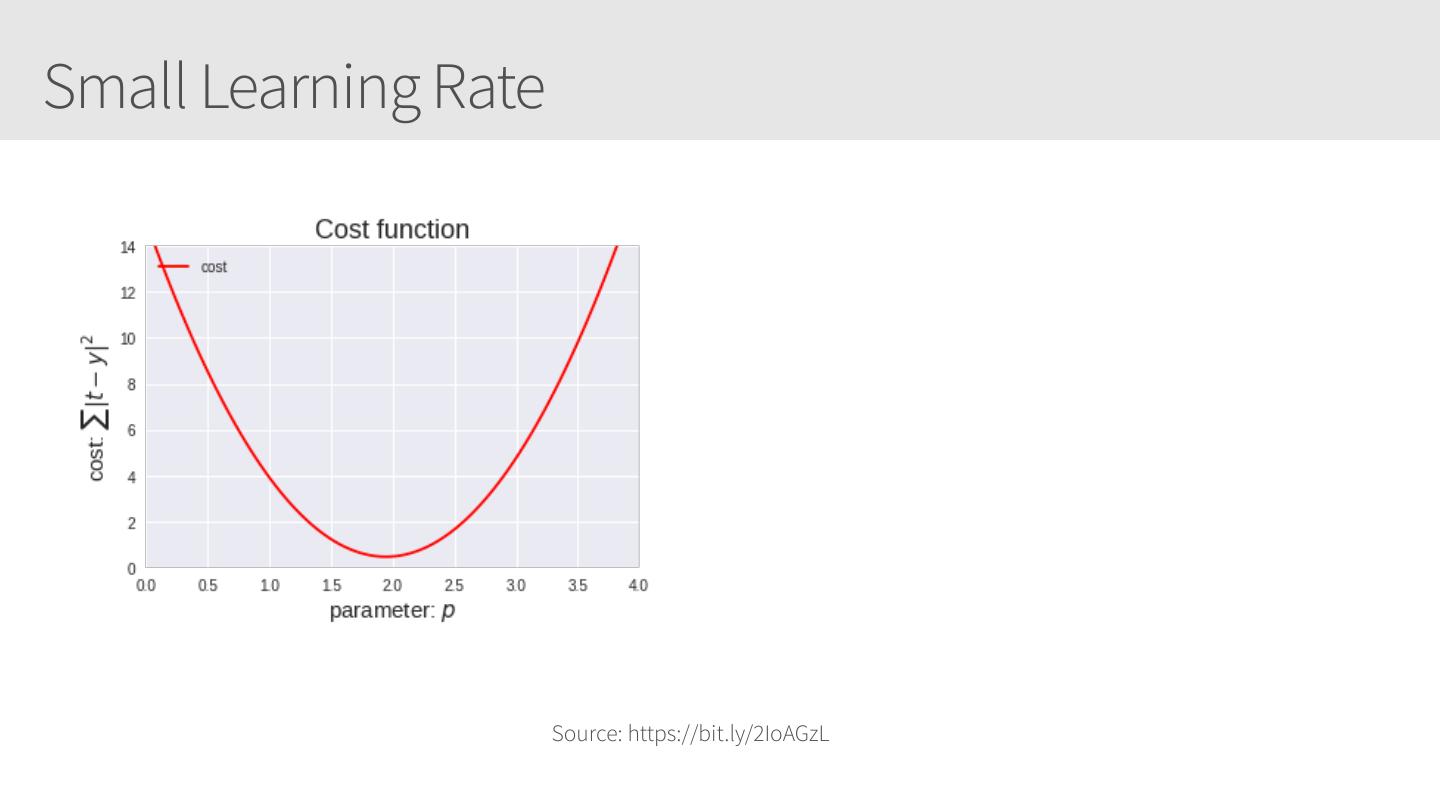
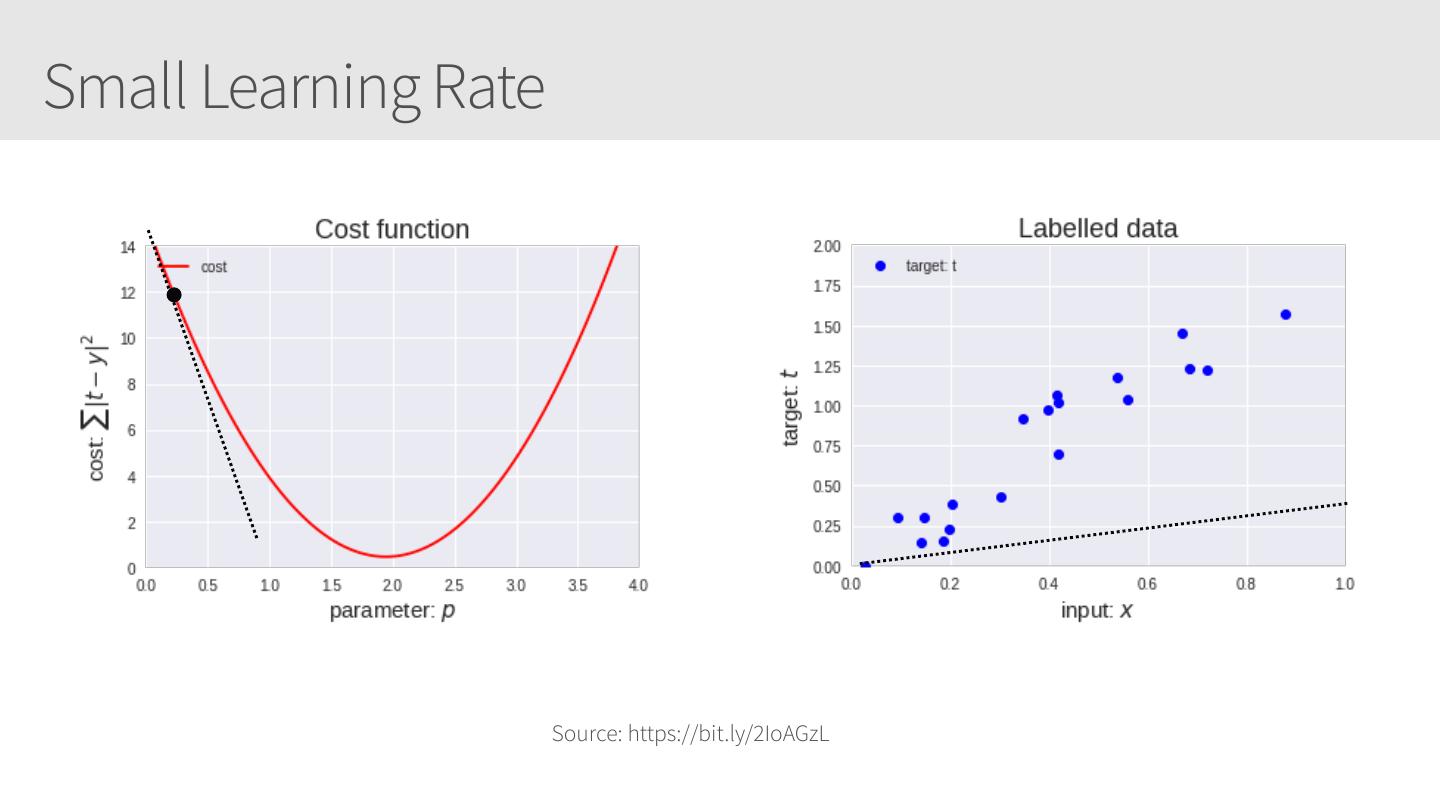
11 .Small Learning Rate Source: https://bit.ly/2IoAGzL
12 .Small Learning Rate Source: https://bit.ly/2IoAGzL
13 .Small Learning Rate Source: https://bit.ly/2IoAGzL
14 .Small Learning Rate Source: https://bit.ly/2IoAGzL
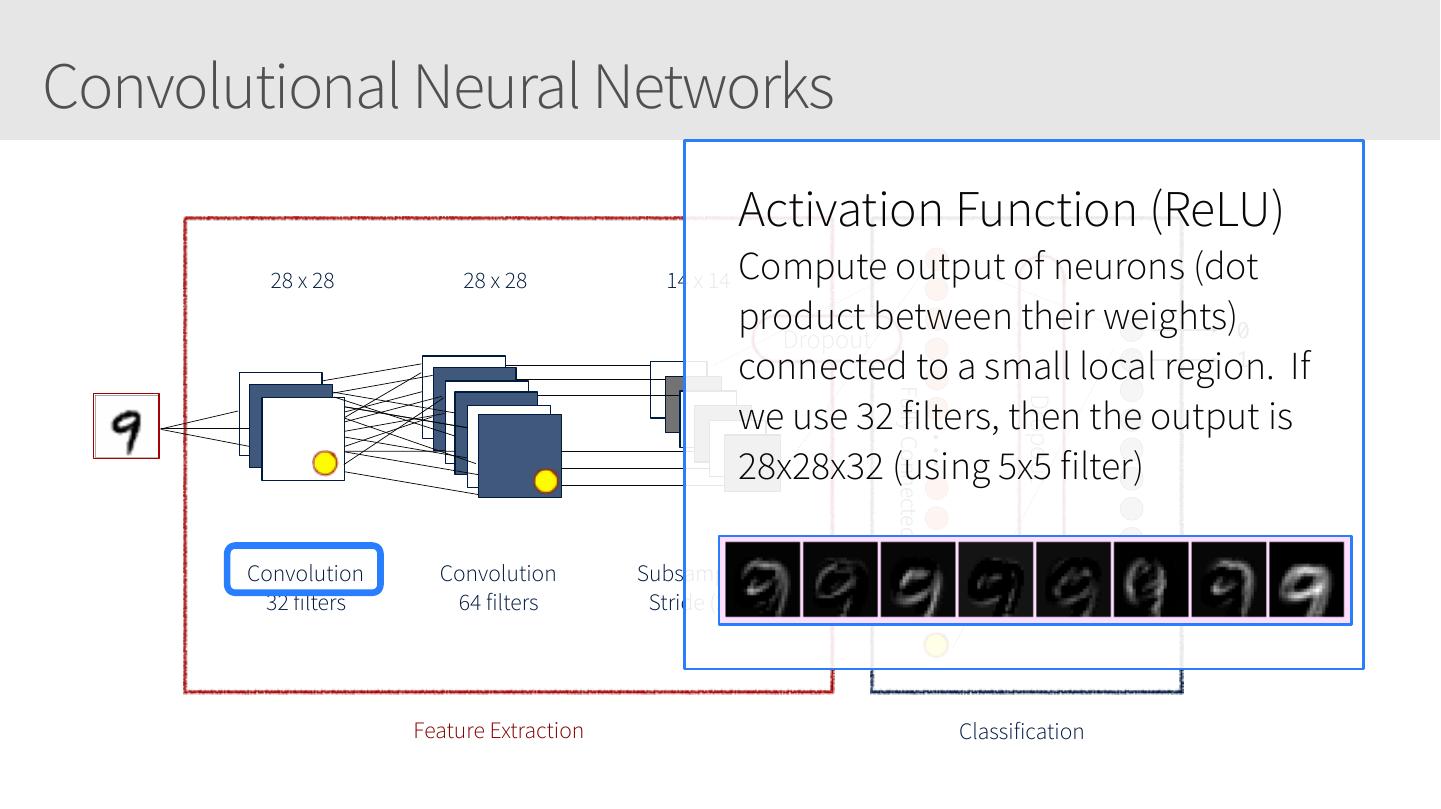
15 .Hyperparameters: Activation Functions? • Good starting point: ReLU • Note many neural networks samples: Keras MNIST, TensorFlow CIFAR10 Pruning, etc. • Note that each activation function has its own strengths and weaknesses. A good quote on activation functions from CS231N summarizes the choice well: “What neuron type should I use?” Use the ReLU non-linearity, be careful with your learning rates and possibly monitor the fraction of “dead” units in a network. If this concerns you, give Leaky ReLU or Maxout a try. Never use sigmoid. Try tanh, but expect it to work worse than ReLU/ Maxout.
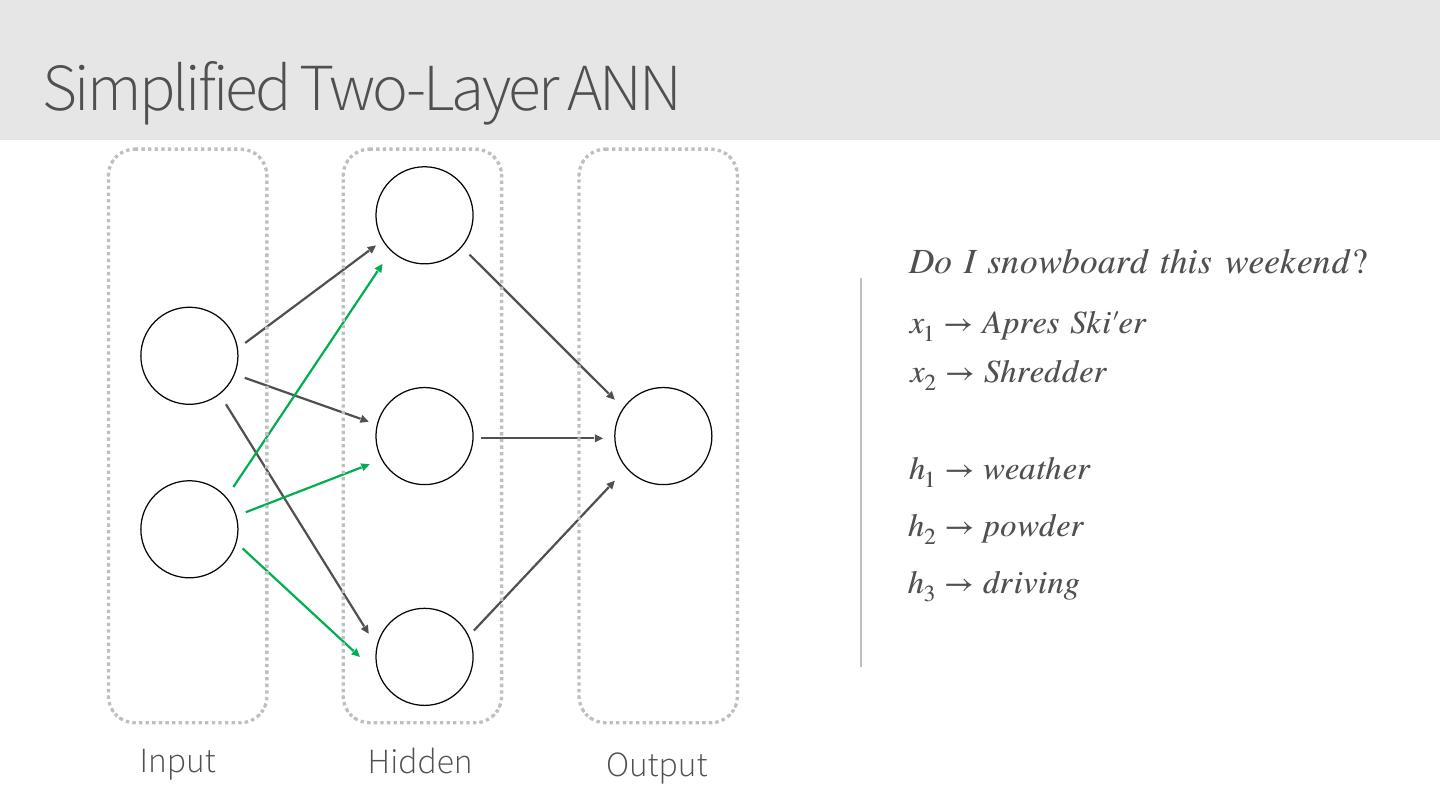
16 .Simplified Two-Layer ANN Do I snowboard this weekend? x1 → Apres Ski′er x2 → Shredder h1 → weather h2 → powder h3 → driving Input Hidden Output
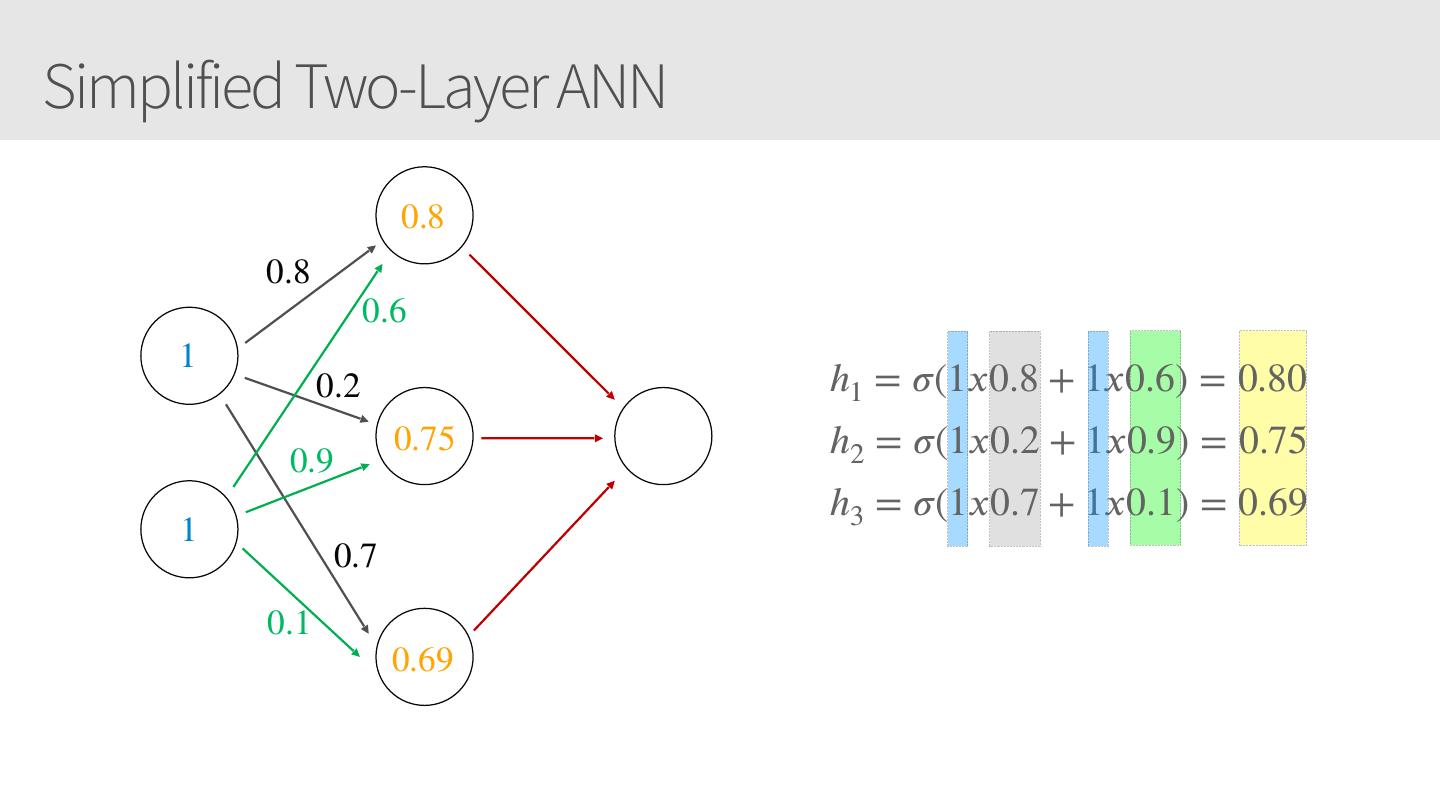
17 .Simplified Two-Layer ANN 0.8 0.8 0.6 1 0.2 h1 = 𝜎(1𝑥0.8 + 1𝑥0.6) = 0.80 0.9 0.75 h2 = 𝜎(1𝑥0.2 + 1𝑥0.9) = 0.75 h3 = 𝜎(1𝑥0.7 + 1𝑥0.1) = 0.69 1 0.7 0.1 0.69
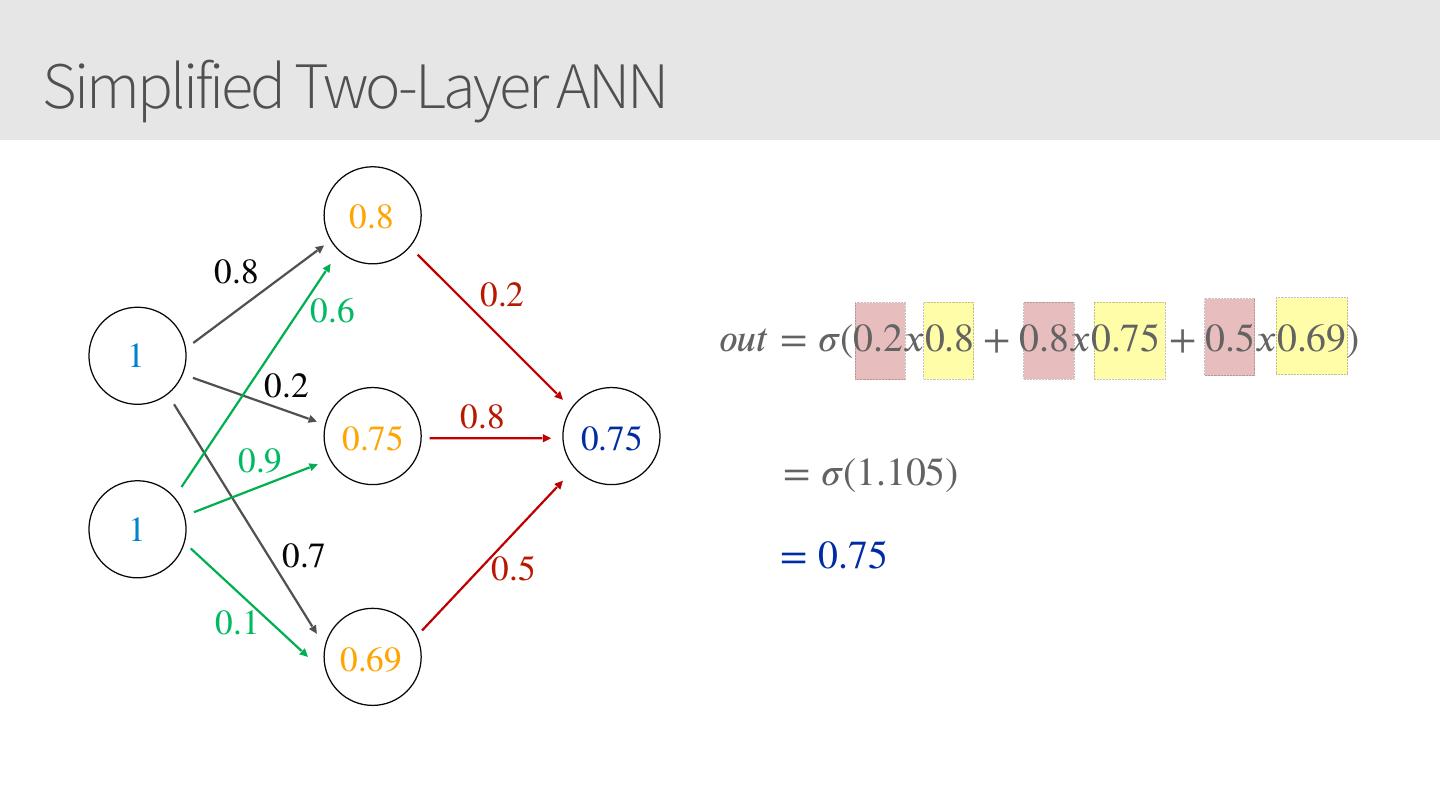
18 .Simplified Two-Layer ANN 0.8 0.8 0.6 0.2 1 𝑜𝑢𝑡 = 𝜎(0.2𝑥0.8 + 0.8𝑥0.75 + 0.5𝑥0.69) 0.2 0.8 0.75 0.75 0.9 = 𝜎(1.105) 1 0.7 0.5 = 0.75 0.1 0.69
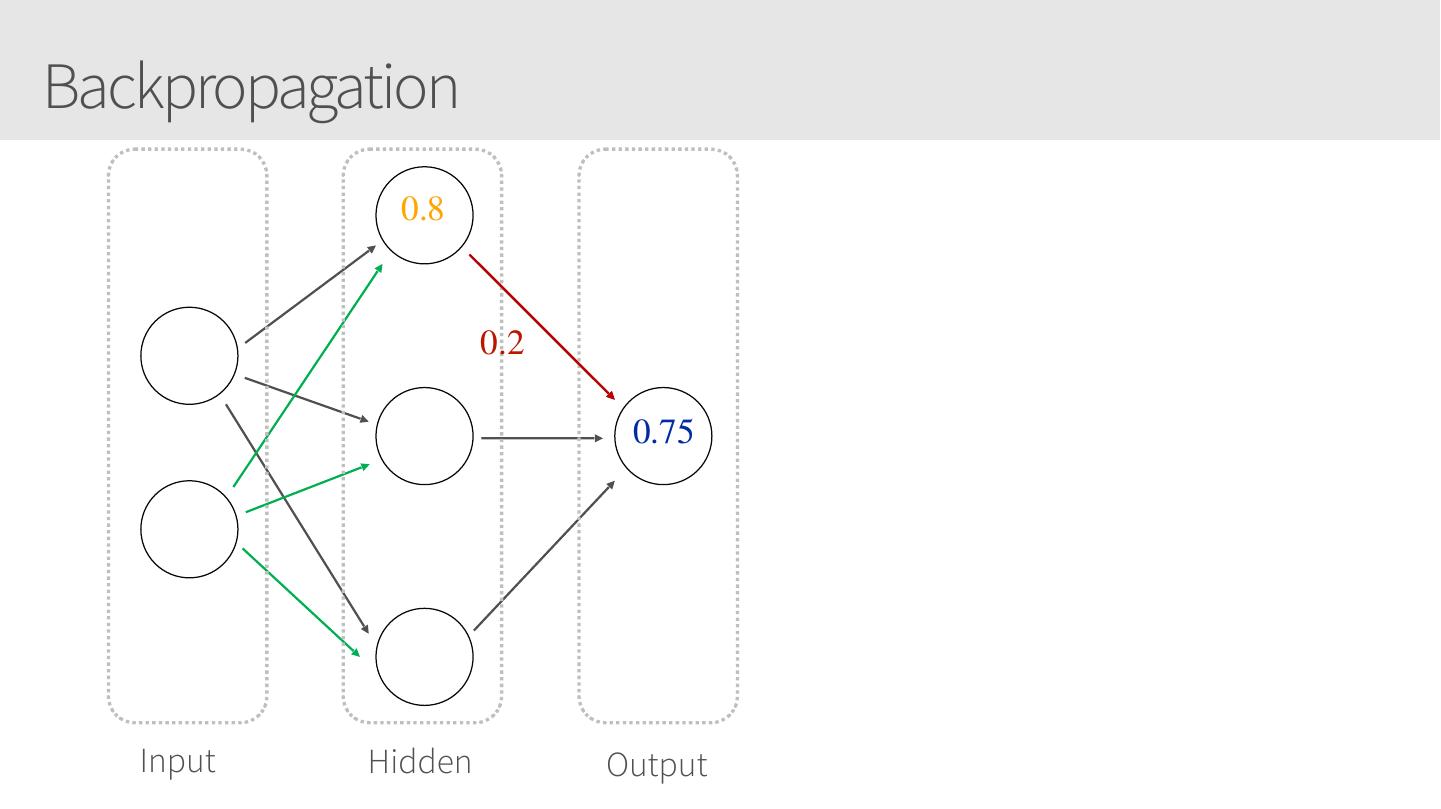
19 .Backpropagation 0.8 0.2 0.75 Input Hidden Output
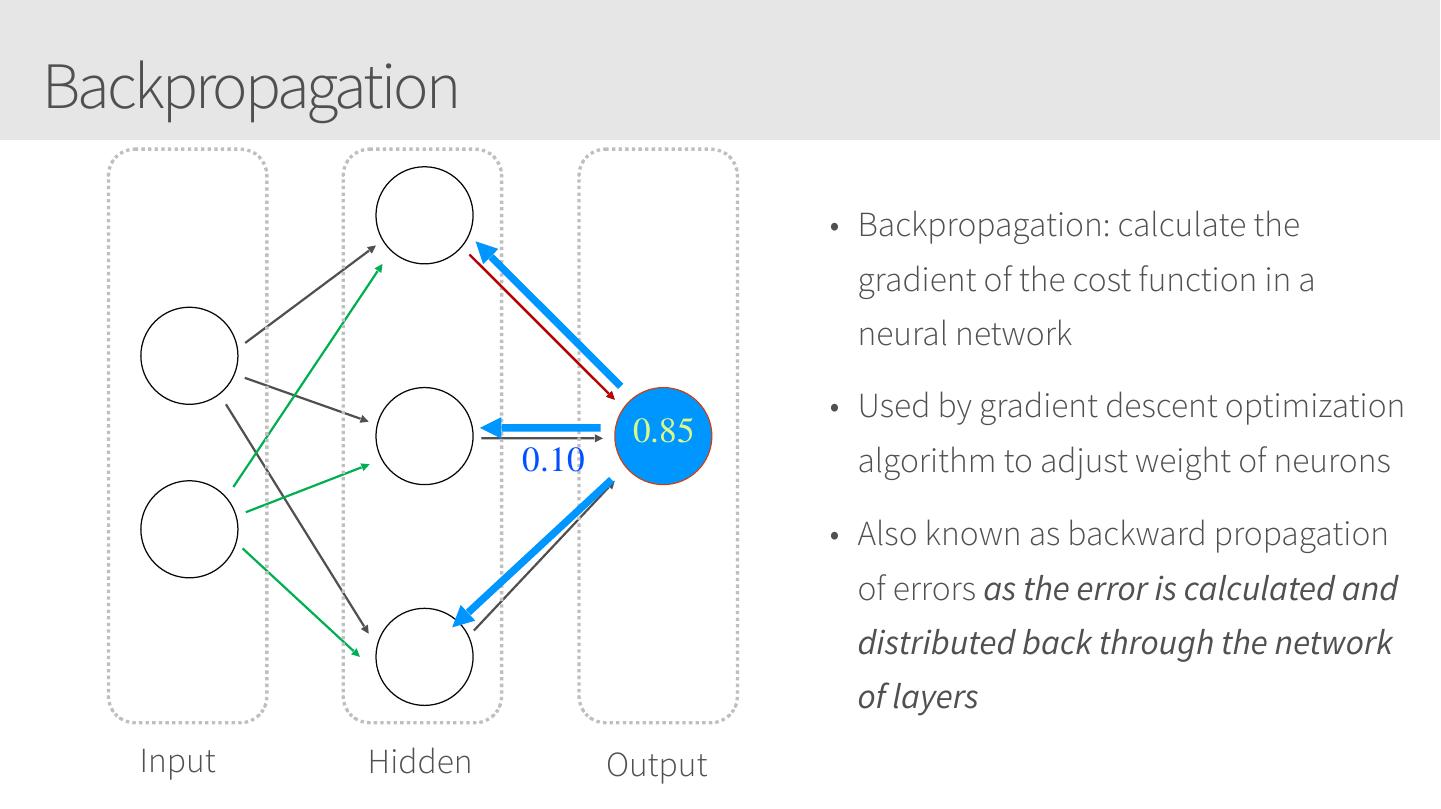
20 .Backpropagation • Backpropagation: calculate the gradient of the cost function in a neural network • Used by gradient descent optimization 0.85 0.10 algorithm to adjust weight of neurons • Also known as backward propagation of errors as the error is calculated and distributed back through the network of layers Input Hidden Output
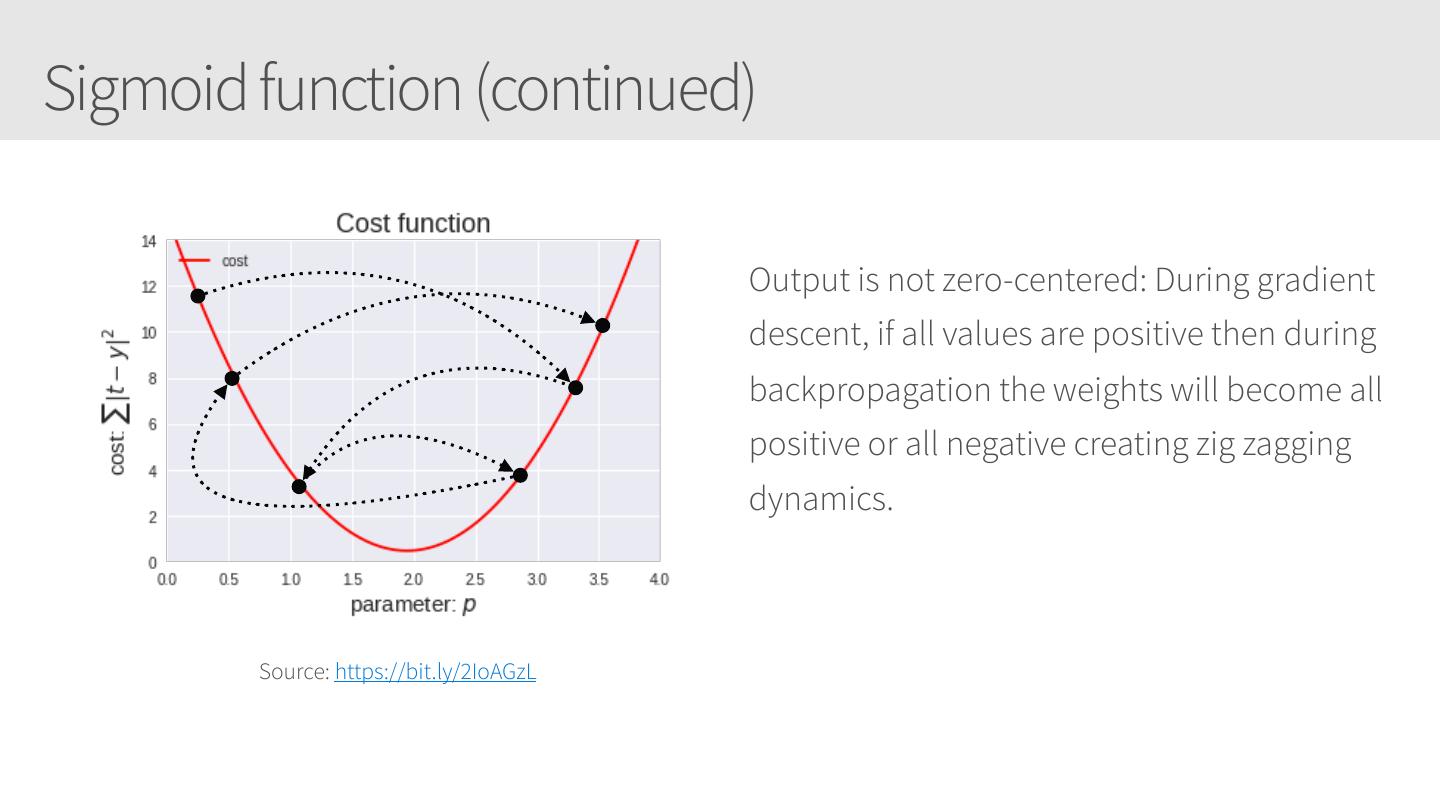
21 .Sigmoid function (continued) Output is not zero-centered: During gradient descent, if all values are positive then during backpropagation the weights will become all positive or all negative creating zig zagging dynamics. Source: https://bit.ly/2IoAGzL
22 .Learning Rate Callouts • Too small, it may take too long to get minima • Too large, it may skip the minima altogether
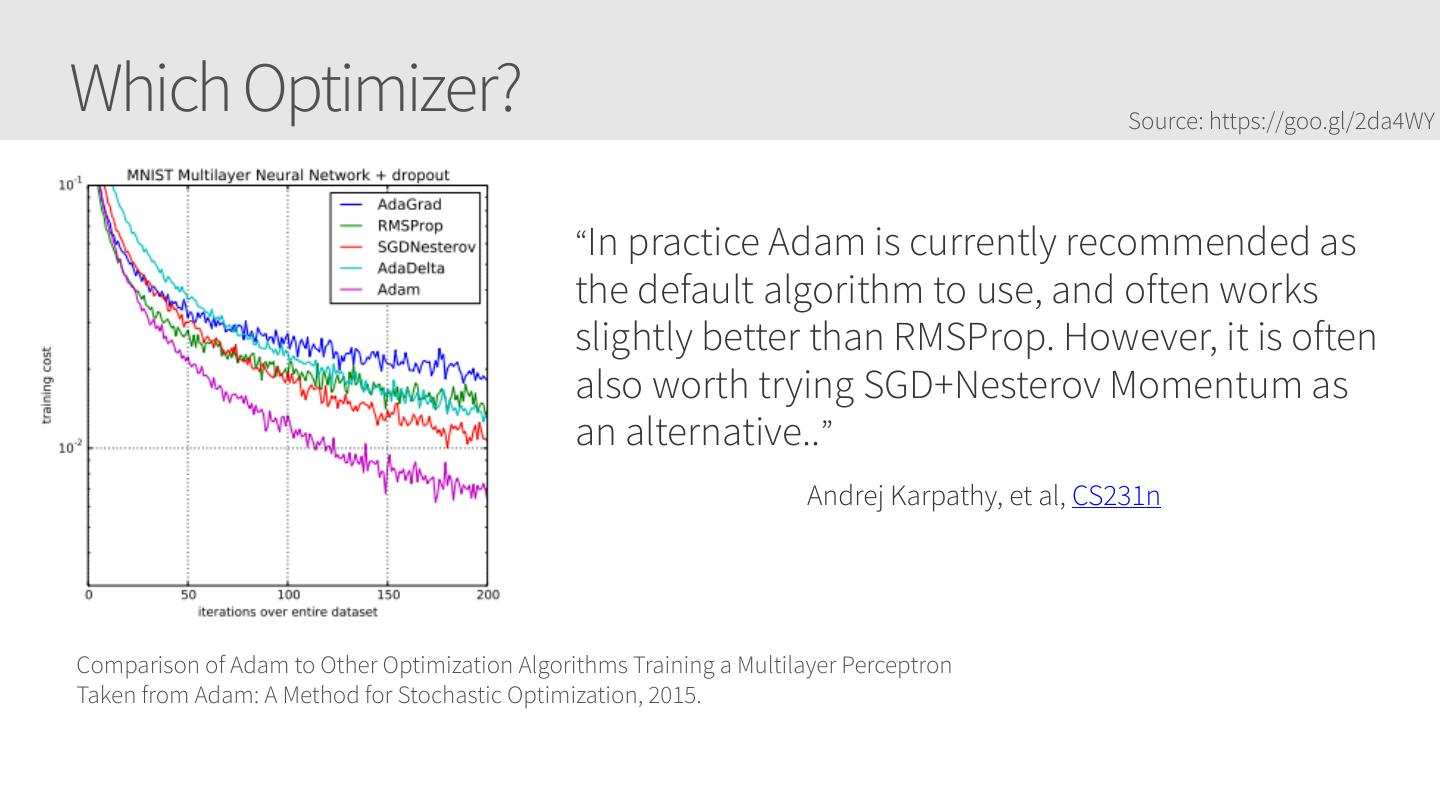
23 .Which Optimizer? Source: https://goo.gl/2da4WY “In practice Adam is currently recommended as the default algorithm to use, and often works slightly better than RMSProp. However, it is often also worth trying SGD+Nesterov Momentum as an alternative..” Andrej Karpathy, et al, CS231n Comparison of Adam to Other Optimization Algorithms Training a Multilayer Perceptron Taken from Adam: A Method for Stochastic Optimization, 2015.
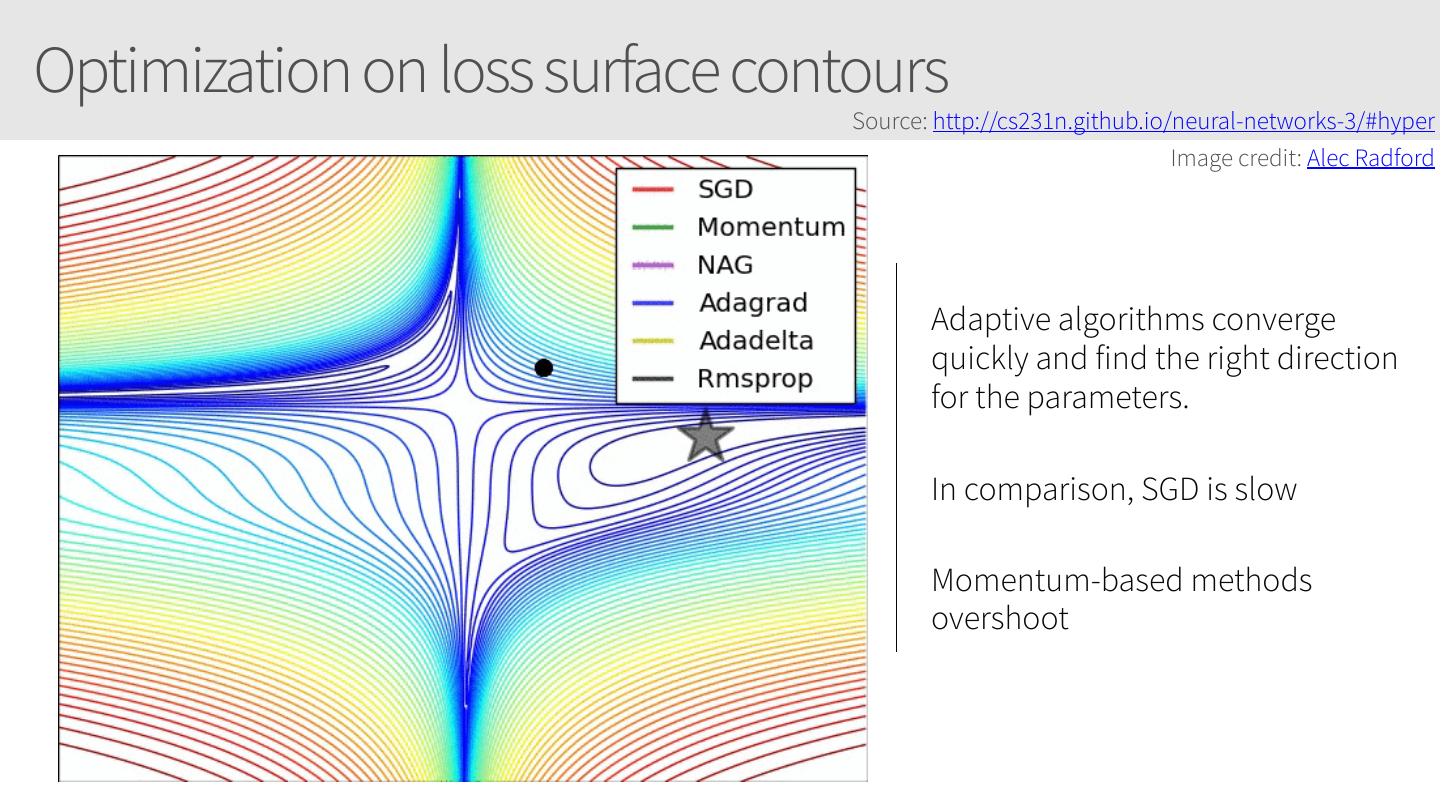
24 .Optimization on loss surface contours Source: http://cs231n.github.io/neural-networks-3/#hyper Image credit: Alec Radford Adaptive algorithms converge quickly and find the right direction for the parameters. In comparison, SGD is slow Momentum-based methods overshoot
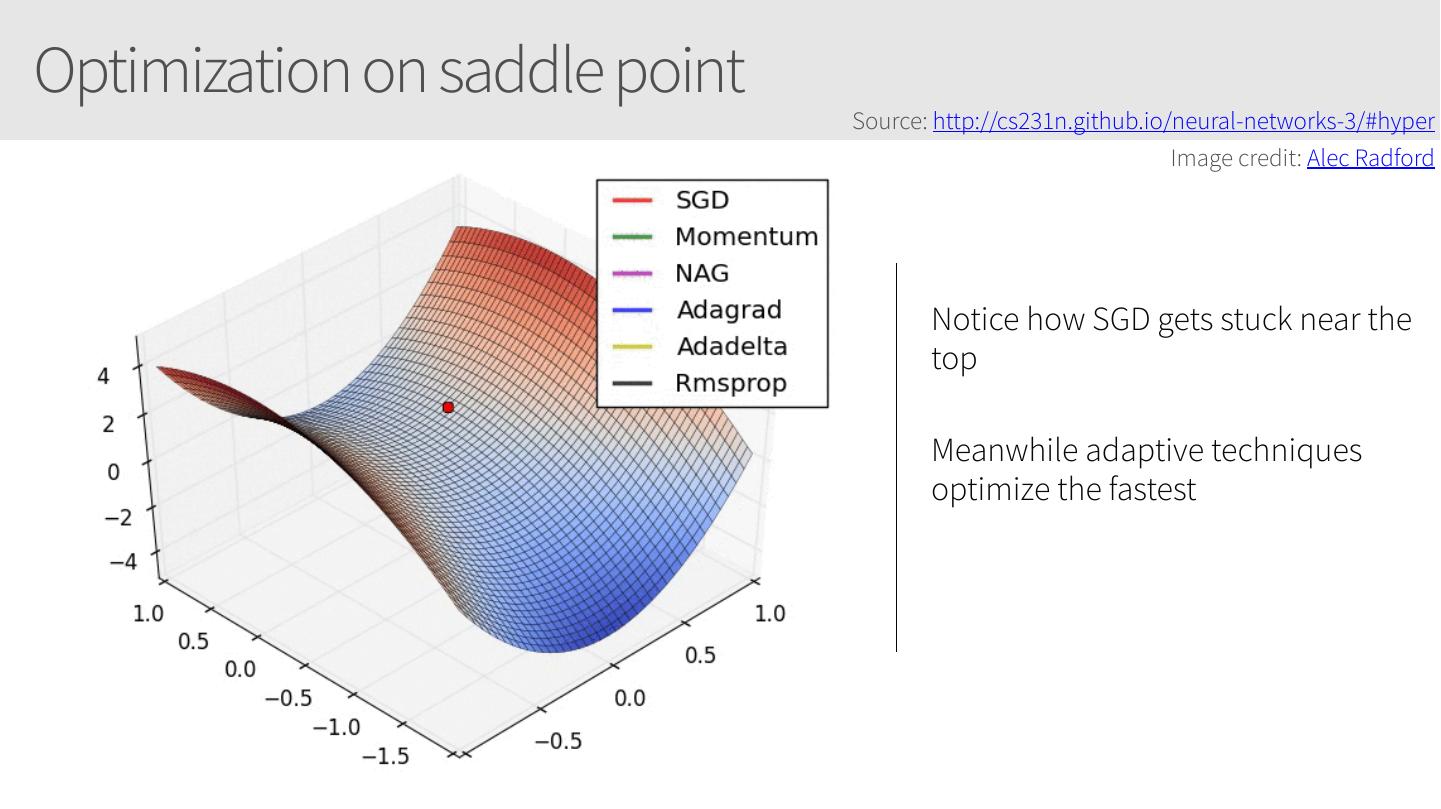
25 .Optimization on saddle point Source: http://cs231n.github.io/neural-networks-3/#hyper Image credit: Alec Radford Notice how SGD gets stuck near the top Meanwhile adaptive techniques optimize the fastest
26 .Good References • Suki Lau's Learning Rate Schedules and Adaptive Learning Rate Methods for Deep Learning • CS23n Convolutional Neural Networks for Visual Recognition • Fundamentals of Deep Learning • ADADELTA: An Adaptive Learning Rate Method • Gentle Introduction to the Adam Optimization Algorithm for Deep Learning
27 .Convolutional Networks
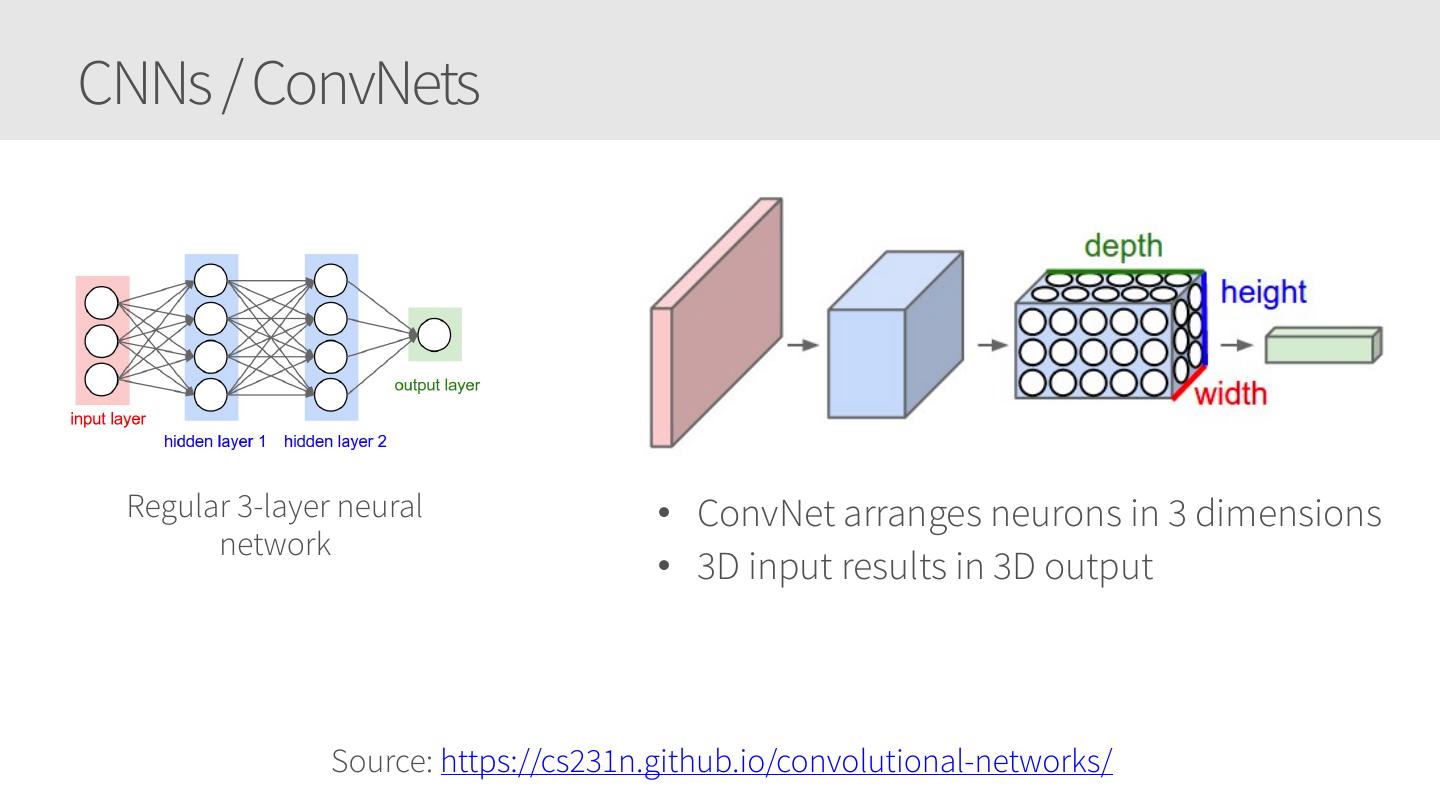
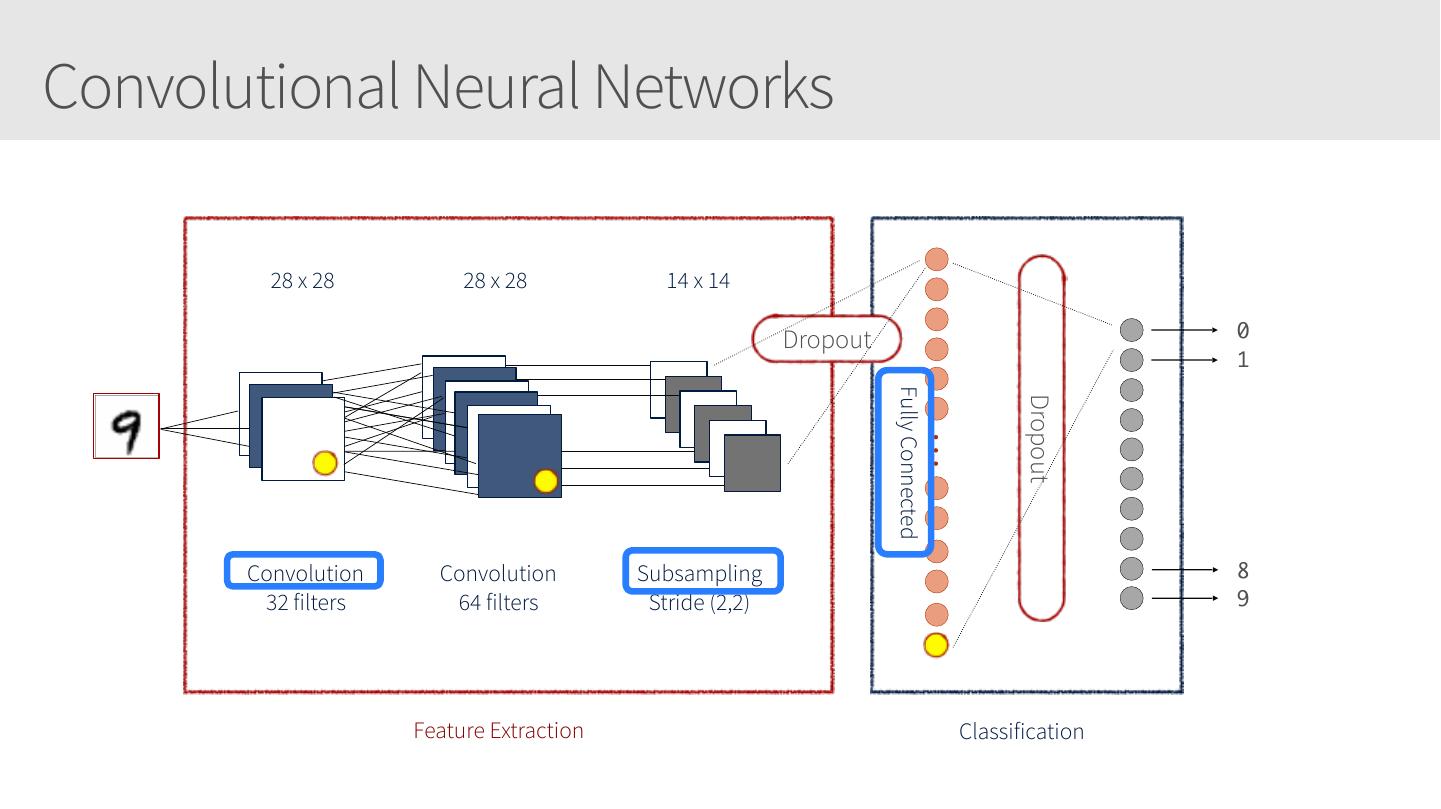
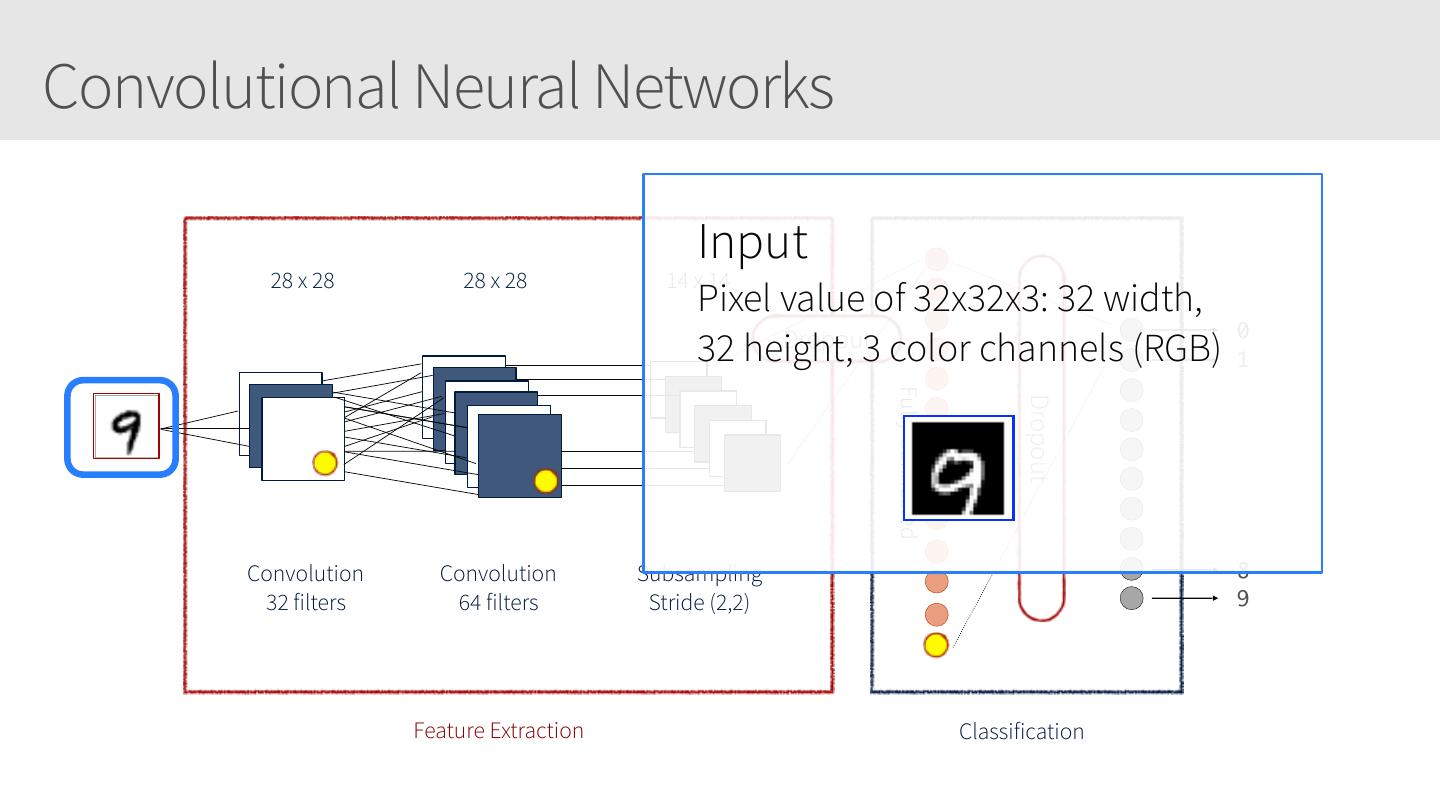
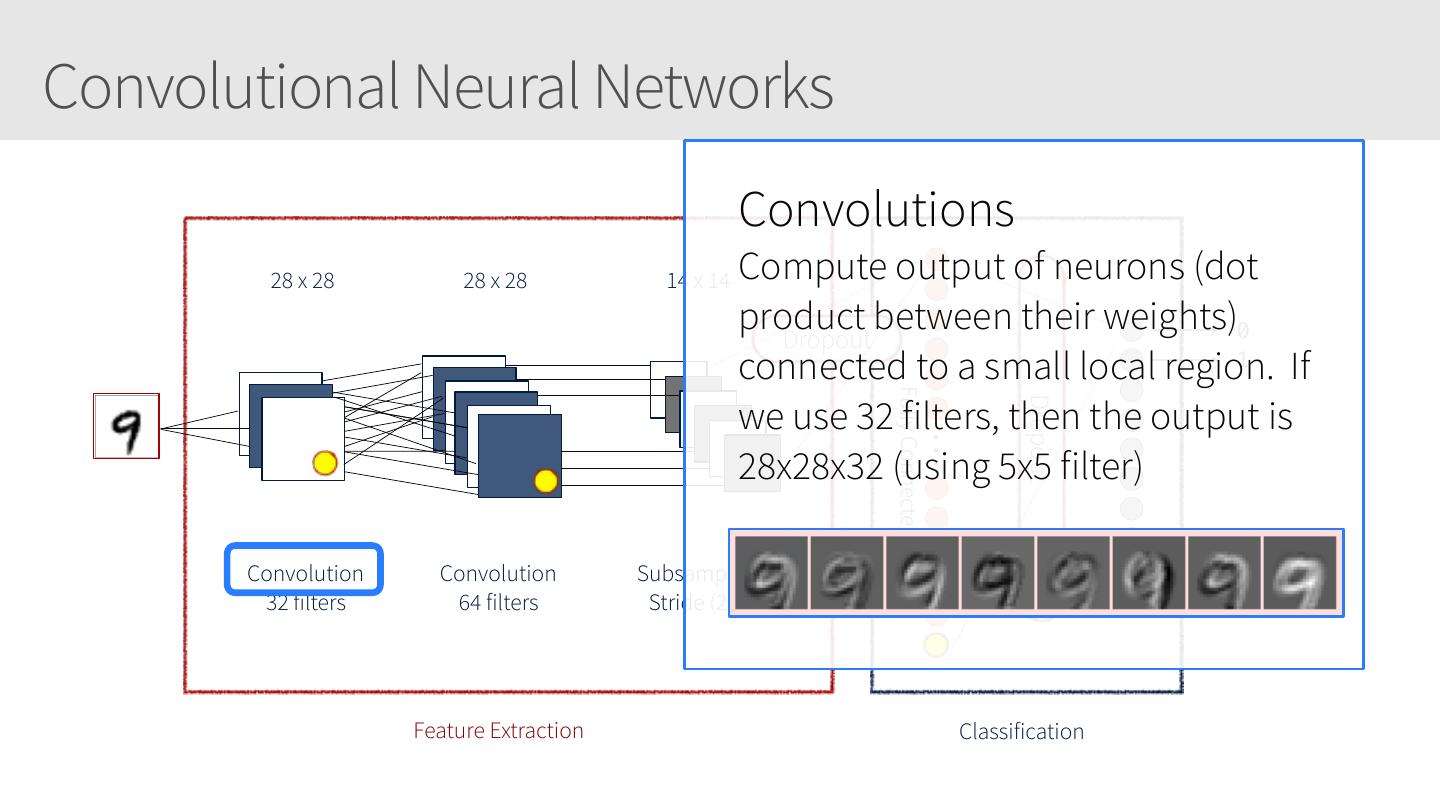
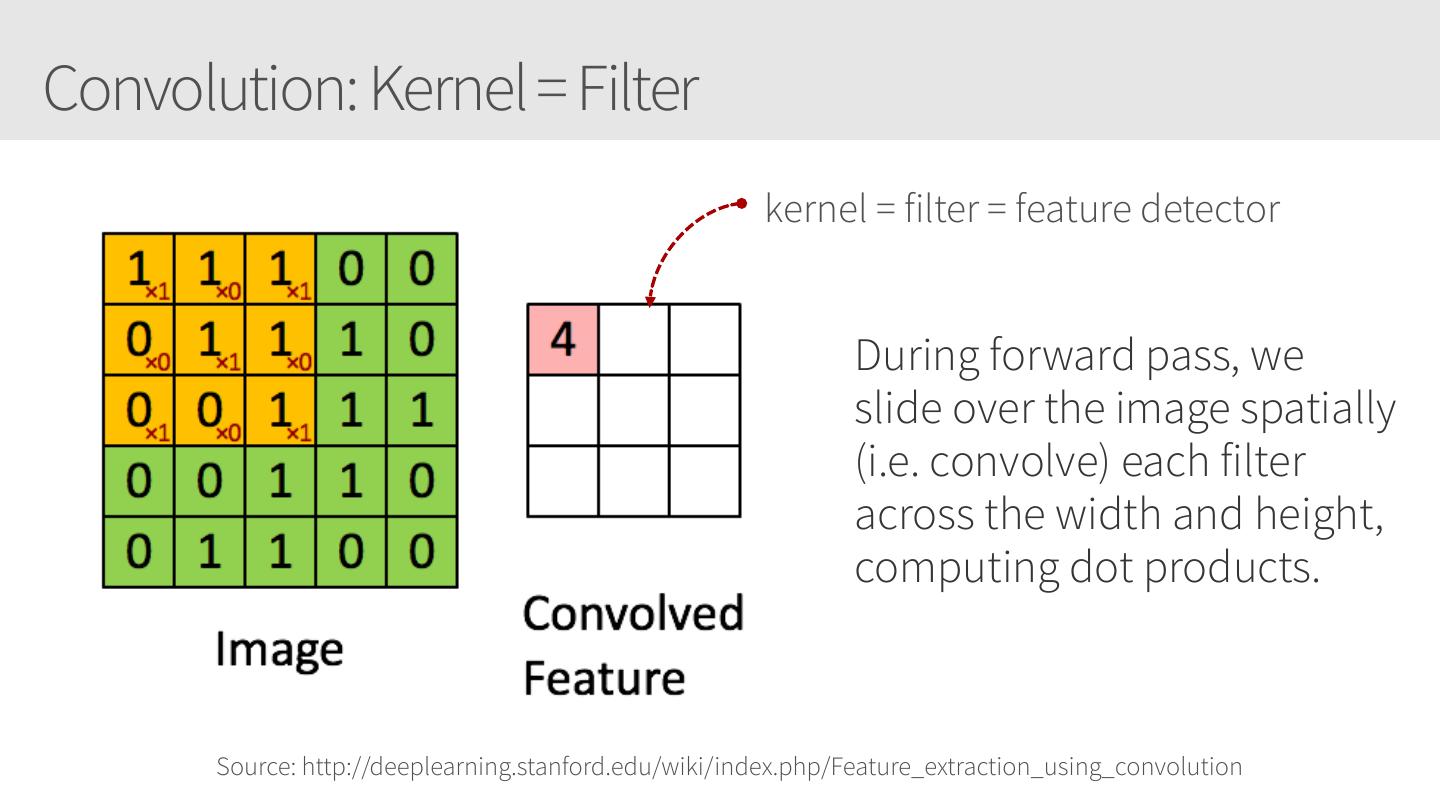
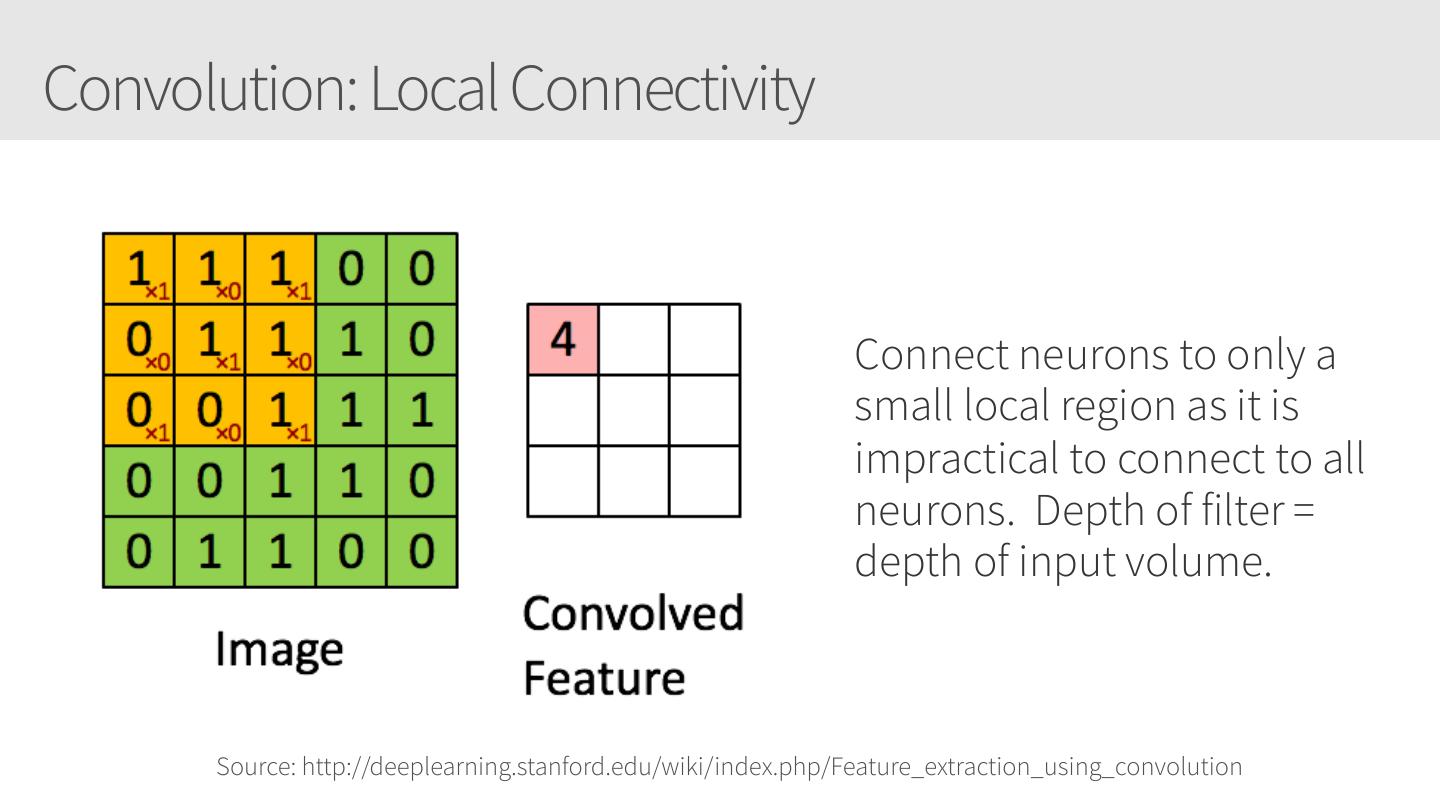
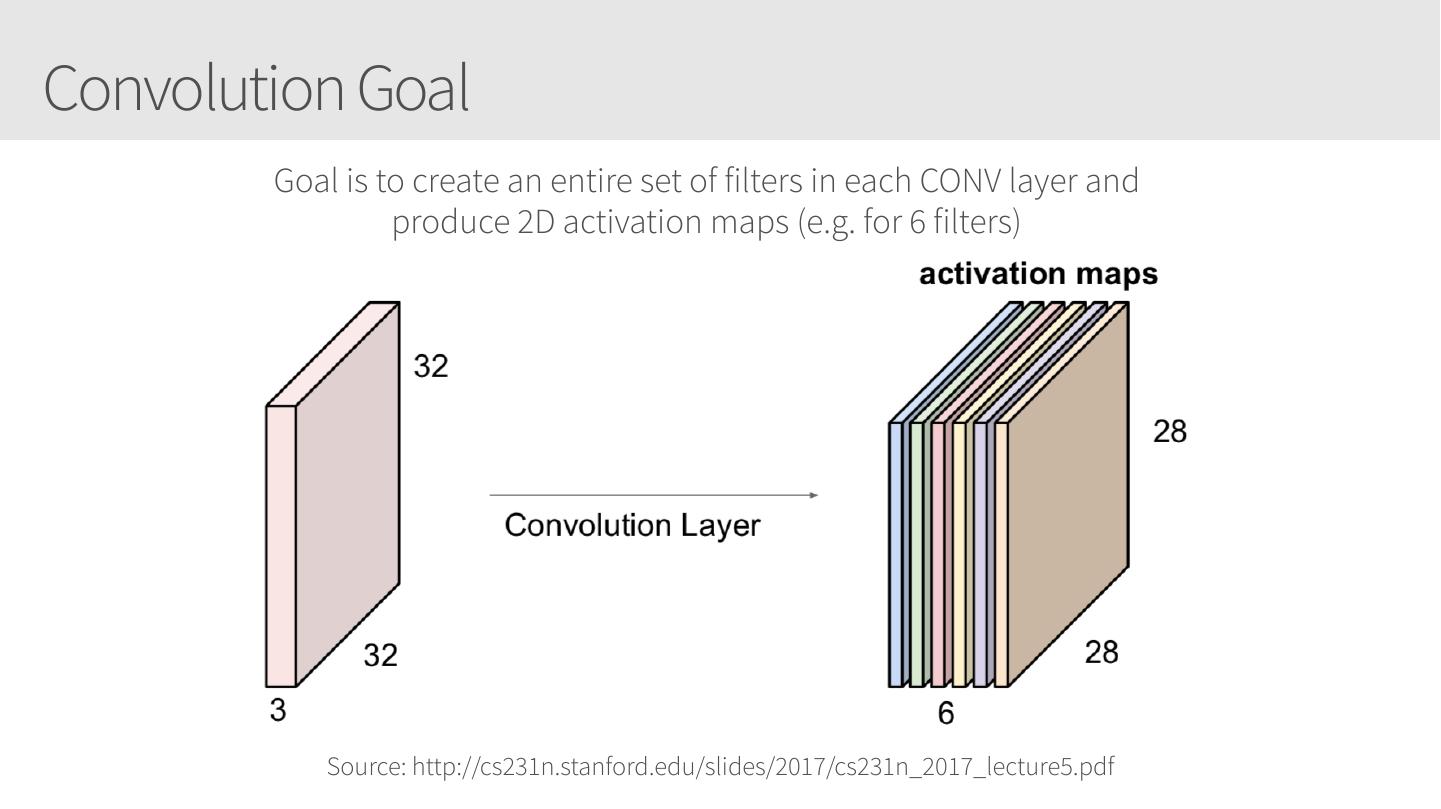
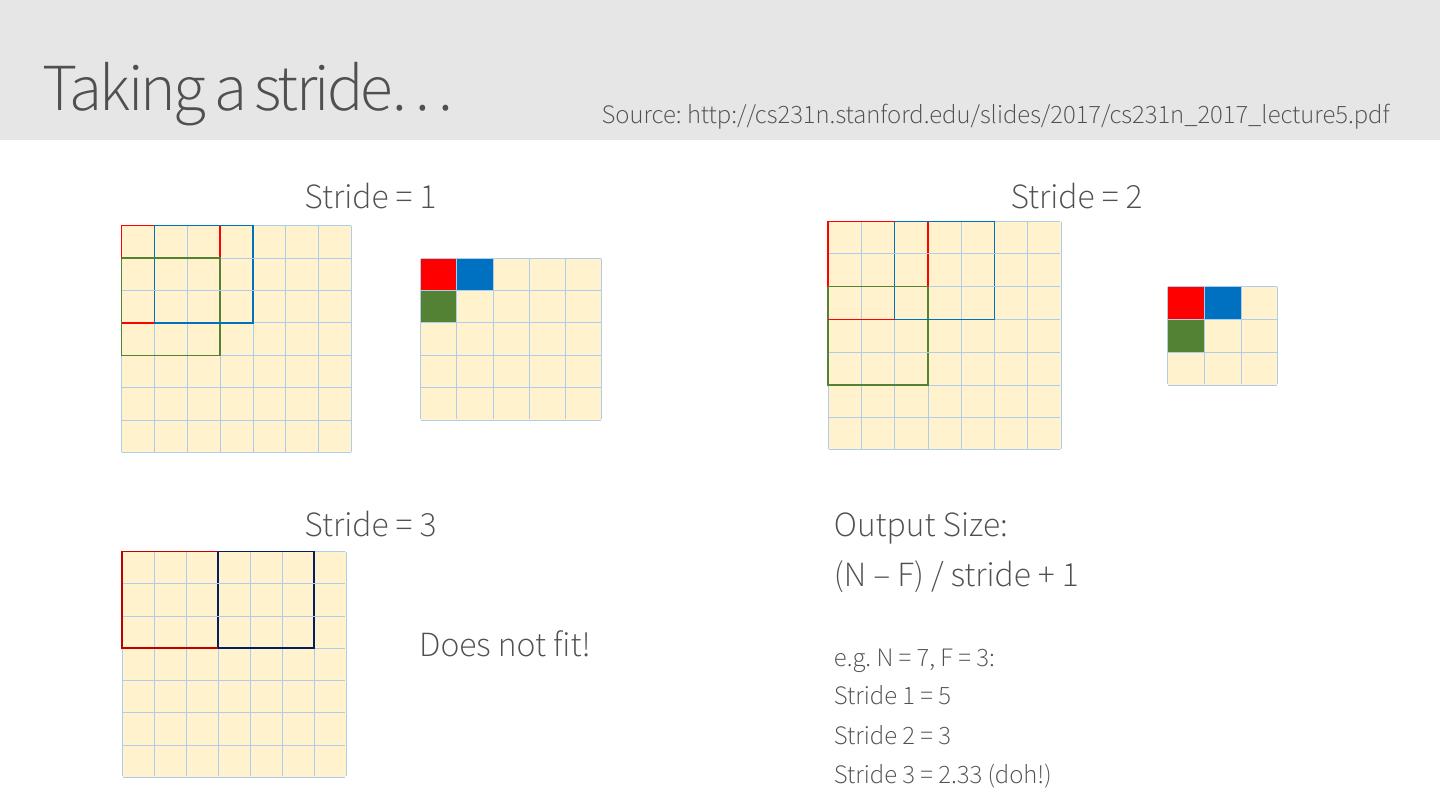
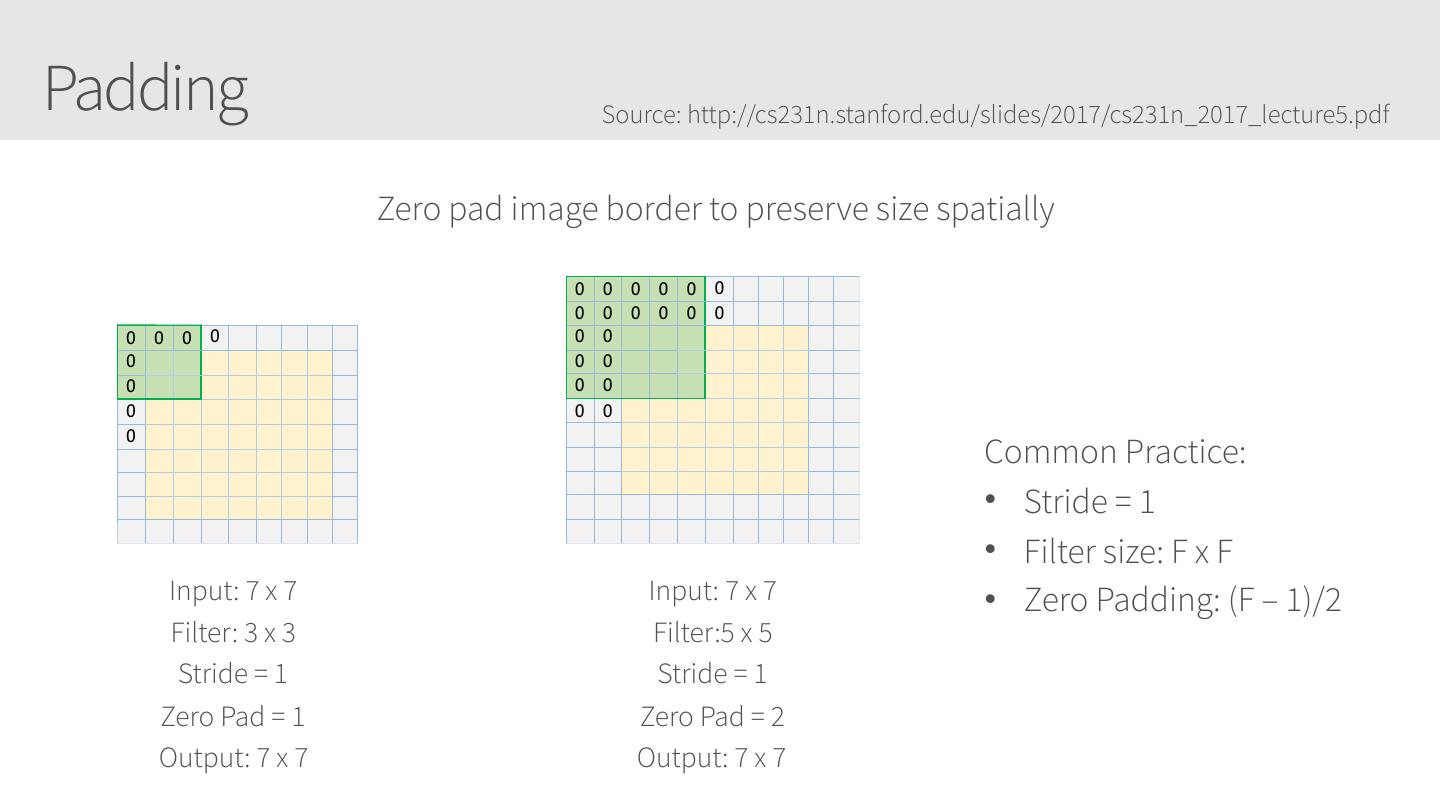
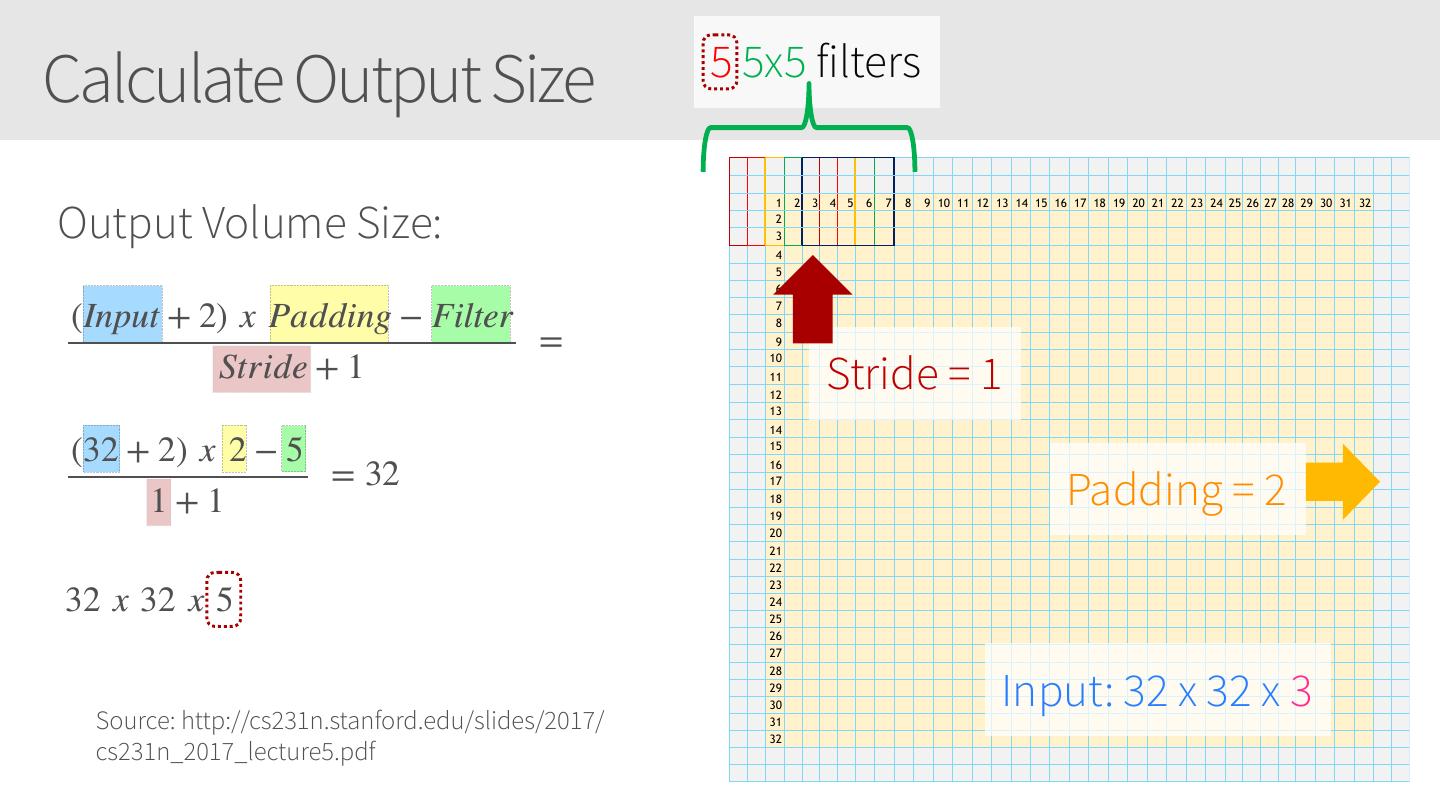
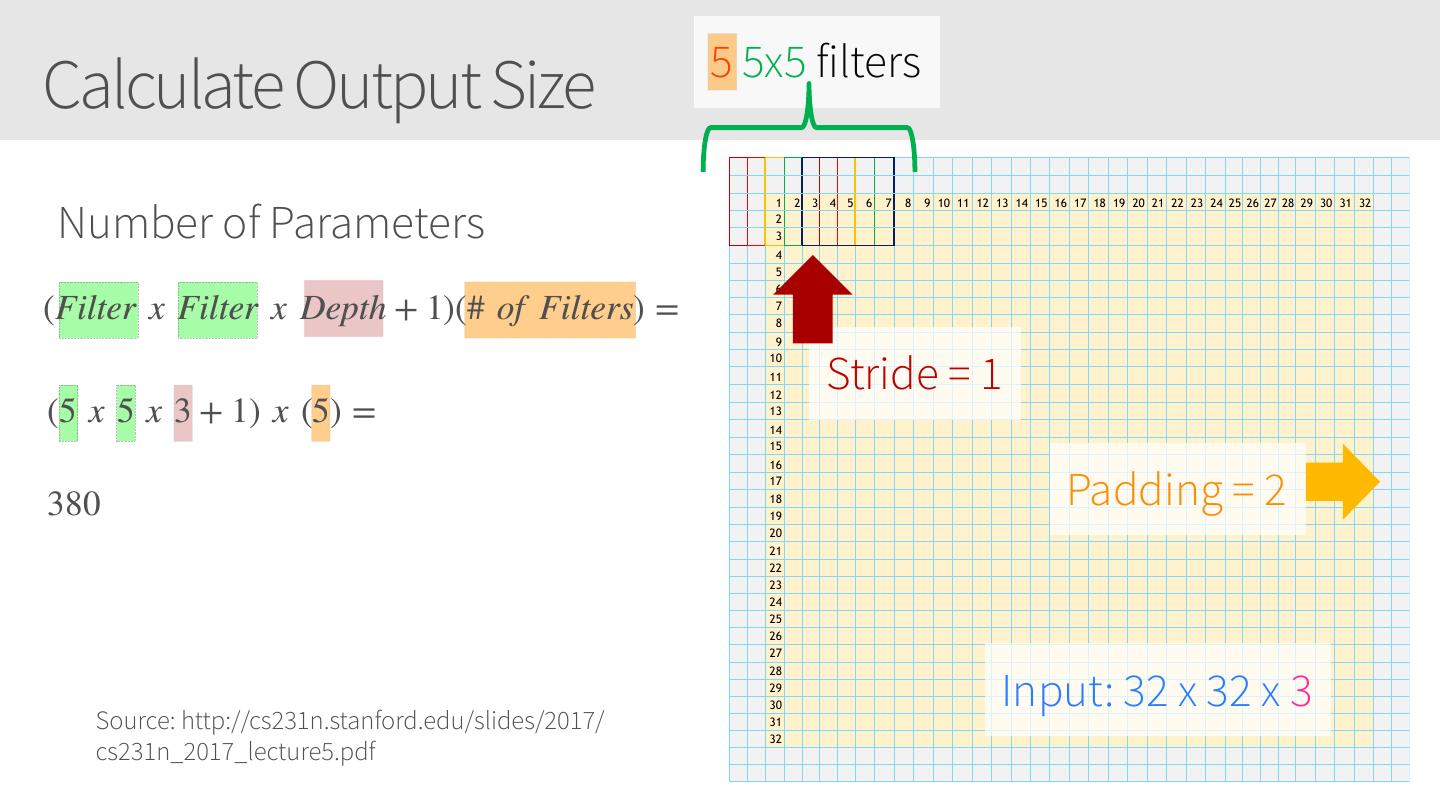
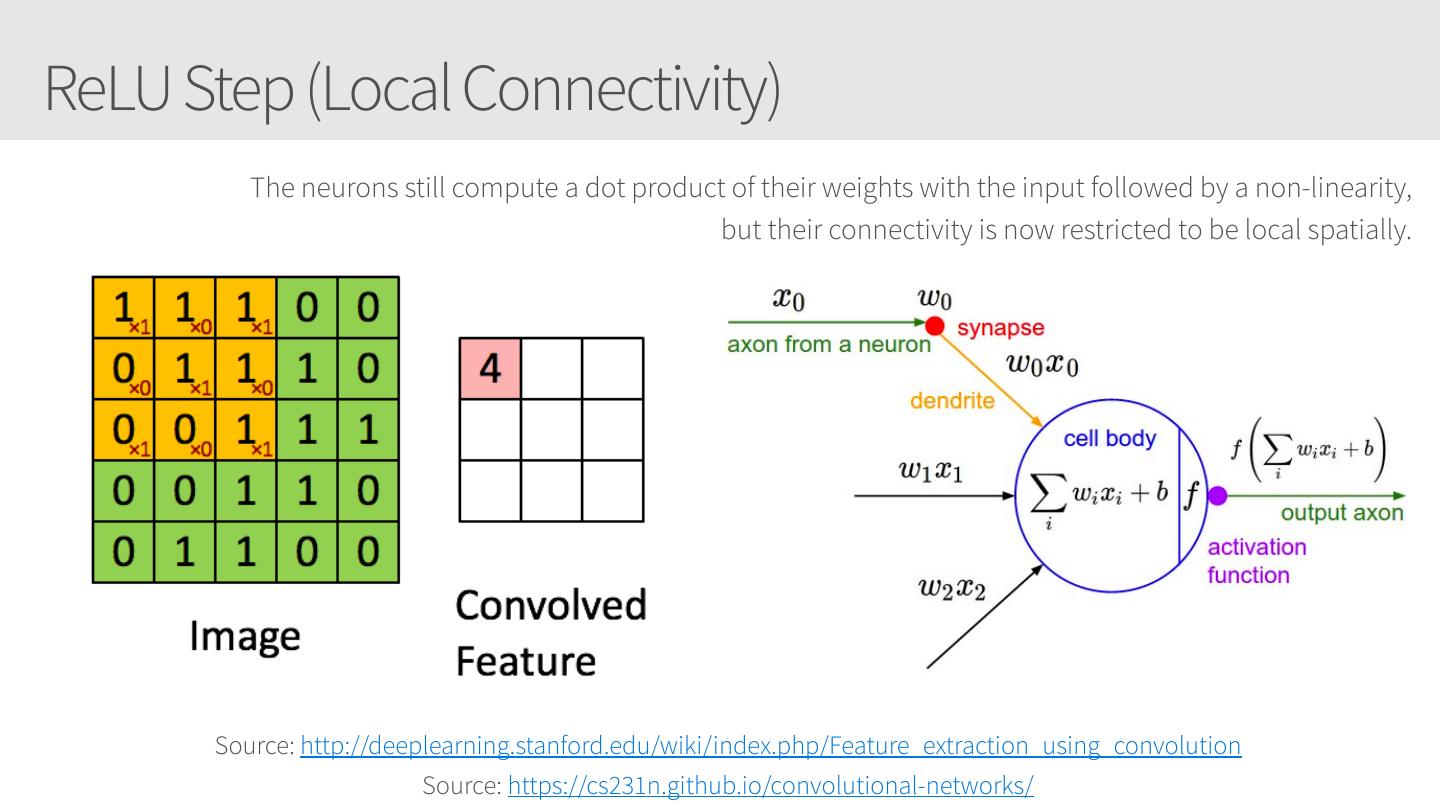
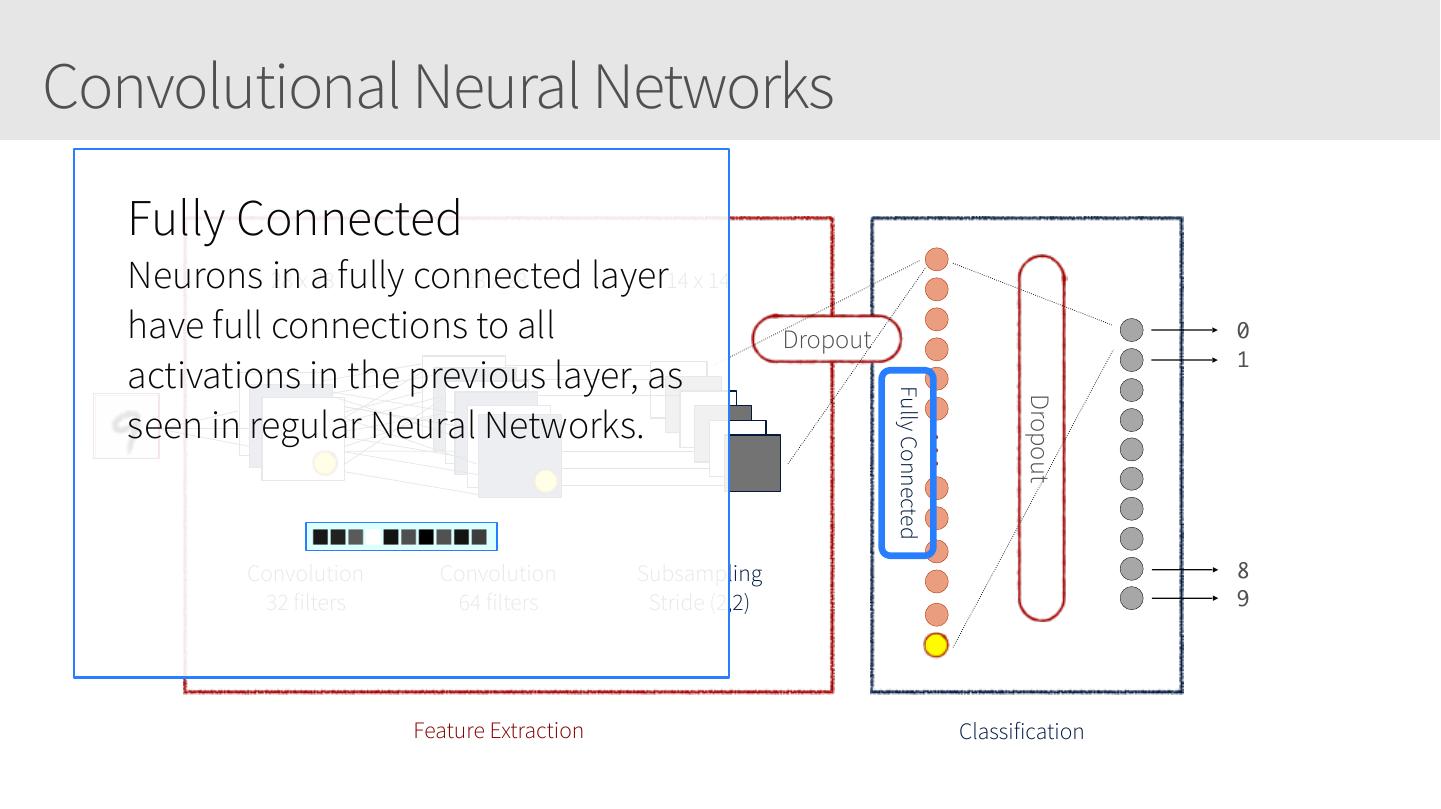
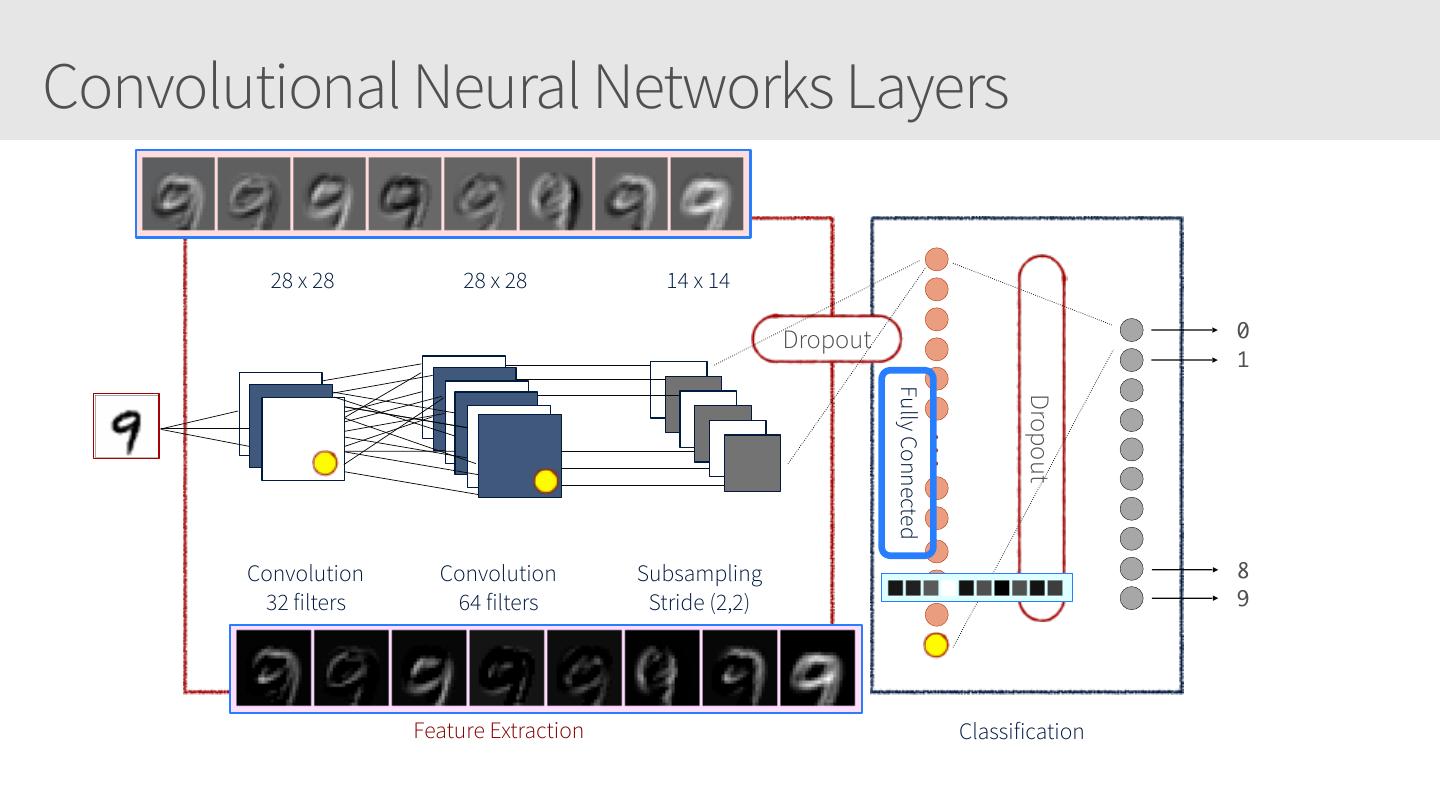
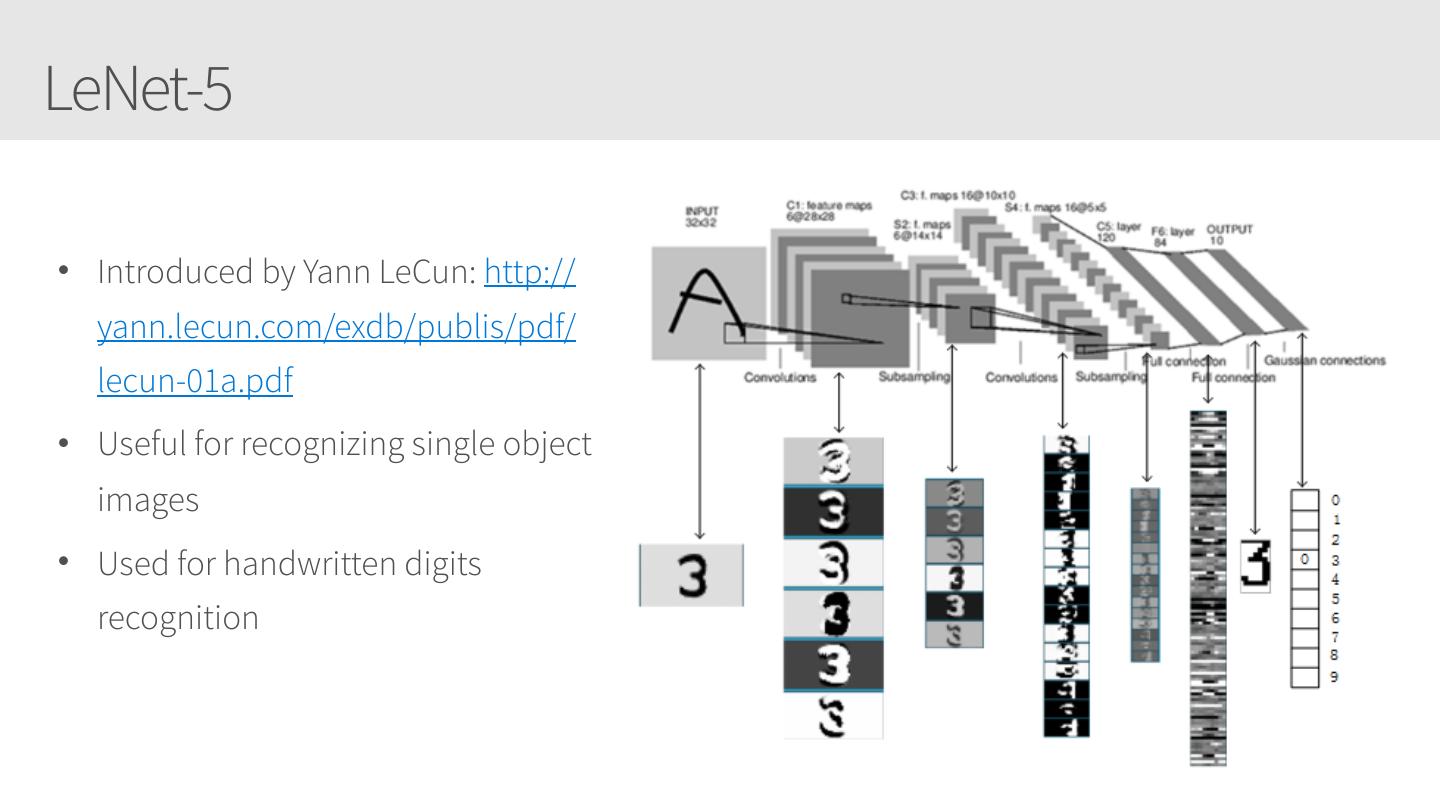
28 .Convolutional Neural Networks • Similar to Artificial Neural Networks but CNNs (or ConvNets) make explicit assumptions that the input are images • Regular neural networks do not scale well against images • E.g. CIFAR-10 images are 32x32x3 (32 width, 32 height, 3 color channels) = 3072 weights – somewhat manageable • A larger image of 200x200x3 = 120,000 weights • CNNs have neurons arranged in 3D: width, height, depth. • Neurons in a layer will only be connected to a small region of the layer before it, i.e. NOT all of the neurons in a fully-connected manner. • Final output layer for CIFAR-10 is 1x1x10 as we will reduce the full image into a single vector of class scores, arranged along the depth dimension
29 .CNNs / ConvNets Regular 3-layer neural • ConvNet arranges neurons in 3 dimensions network • 3D input results in 3D output Source: https://cs231n.github.io/convolutional-networks/
3秒后跳转登录页面
去登陆

