展开查看详情
1 .WIFI SSID: SparkAISummit | Password: UnifiedAnalytics
�
2 .Apache Spark Data
Validation
Patrick Pisciuneri & Doug Balog, Target
#UnifiedAnalytics #SparkAISummit
�
3 .Outline
• Introductions
• Motivation
• Data Validator
• Open Source
• Future Work
• Conclusions
#UnifiedAnalytics #SparkAISummit 3
�
4 .Introduction
Patrick Pisciuneri Doug Balog
Patrick is a Data Scientist for Target. He received his PhD in Doug is a Data Engineer for Target. He develops Machine
Mechanical Engineering from the University of Pittsburgh in Learning infrastructure for Target in Pittsburgh, PA. He joined
2013. His research involved the intersection of high- Target in 2014 and is currently a Principal Data Engineer. He
performance computing and the simulation of turbulent has a BS in Computer Science from University of Pittsburgh.
reacting flows. In 2015 he joined Target as a data scientist
where he has worked on product and ad recommendations.
#UnifiedAnalytics #SparkAISummit 4
�
5 .Introduction
Target
• 1,845 stores in the United States
• 39 distribution centers in the United
States
• 350,000+ team members worldwide
• Online business at target.com
• Global offices in China, Hong Kong
and India
corporate.target.com/
#UnifiedAnalytics #SparkAISummit 5
�
6 .Motivation
• Understand data
• Catch errors/anomalies early in pipelines
• Promote best practices for data management
• Easy to adopt – language agnostic interface
• Efficient on large datasets and distributed
systems
#UnifiedAnalytics #SparkAISummit 6
�
7 .Motivation
References
1. TFX: A TensorFlow-Based Production-Scale Machine
Learning Platform, KDD 2017
2. Hidden Technical Debt in Machine Learning, NIPS 2015
3. Methodology for Data Validation 1.0, Eurostat – CROS,
2016
4. Extending Apache Spark APIs Without Going Near
Spark Source or a Compiler, Spark + AI Summit, 2018
#UnifiedAnalytics #SparkAISummit 7
�
8 .introducing
Data Validator
#UnifiedAnalytics #SparkAISummit 8
�
9 .Features
• Configuration
• Validators
• Reporting & Notification
• Profiling
#UnifiedAnalytics #SparkAISummit 9
�
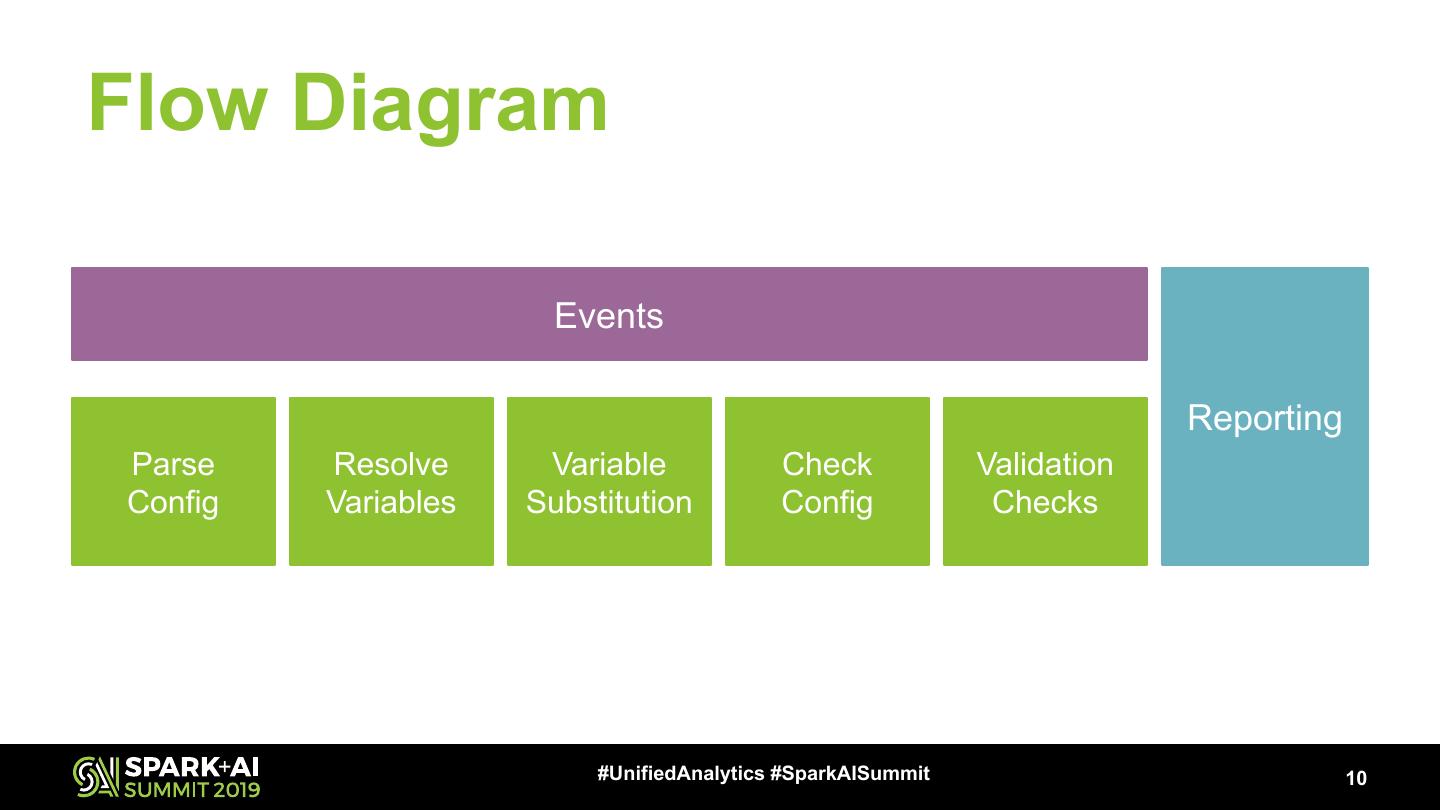
10 .Flow Diagram
Events
Reporting
Parse Resolve Variable Check Validation
Config Variables Substitution Config Checks
#UnifiedAnalytics #SparkAISummit 10
�
11 .Configuration
• User creates a configuration file (yaml)
1. Variables
2. Reporting settings
3. Notification settings
4. Validation checks
#UnifiedAnalytics #SparkAISummit 11
�
12 .Configuration - Variables
• Set the value of a
variable specified by the
name value
1. Simple substitution
2. Environment variable
substitution
3. Shell substitution
• First line of stdout
4. SQL substitution
• First column of first row
#UnifiedAnalytics #SparkAISummit 12
�
13 .Configuration – Report Settings
• Event report
– Specify path and filename
• local://
• hdfs://
• append – will overwrite
existing file if false
– Pipe event report to
another program
• ignoreError – mark data
validator as failed if pipe
command fails
#UnifiedAnalytics #SparkAISummit 13
�
14 .Configuration – Notification Settings
• Send email with
status of validation
checks
#UnifiedAnalytics #SparkAISummit 14
�
15 .Configuration – Validation Checks
• Specify the checks we want to
run on a data asset
• Support:
– Hive tables
– Orc files
– Parquet files
• Any number of checks on any
number of columns
• Specify condition to filter
asset
– Useful when applied to partition
column
#UnifiedAnalytics #SparkAISummit 15
�
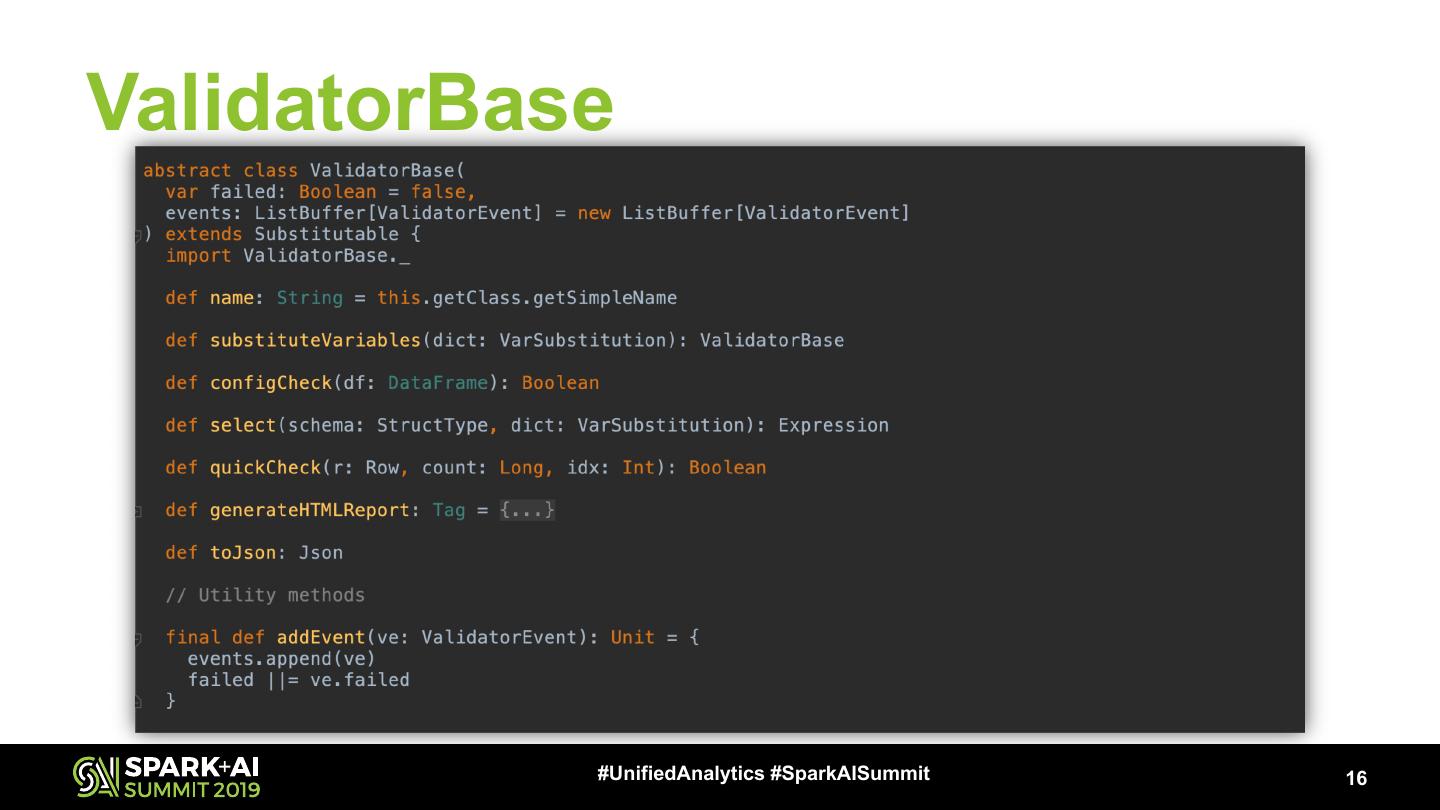
16 .ValidatorBase
#UnifiedAnalytics #SparkAISummit 16
�
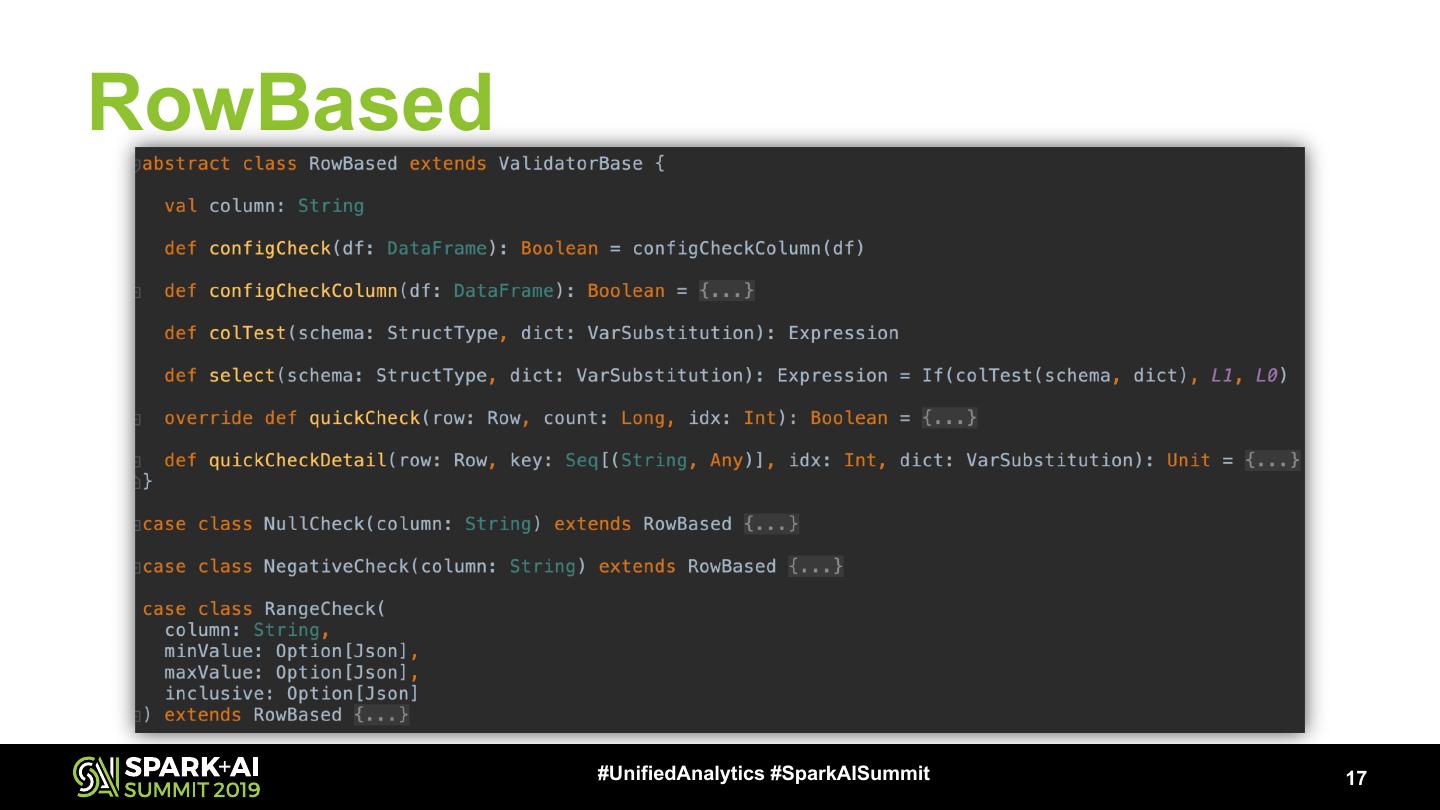
17 .RowBased
#UnifiedAnalytics #SparkAISummit 17
�
18 .ColumnBased
#UnifiedAnalytics #SparkAISummit 18
�
19 .Example
• Census (1994) Income Data Set
• Learning task: predict whether income exceeds 50k
http://archive.ics.uci.edu/ml/datasets/Census+Income
#UnifiedAnalytics #SparkAISummit 19
�
20 .Example
Config Schema
#UnifiedAnalytics #SparkAISummit 20
�
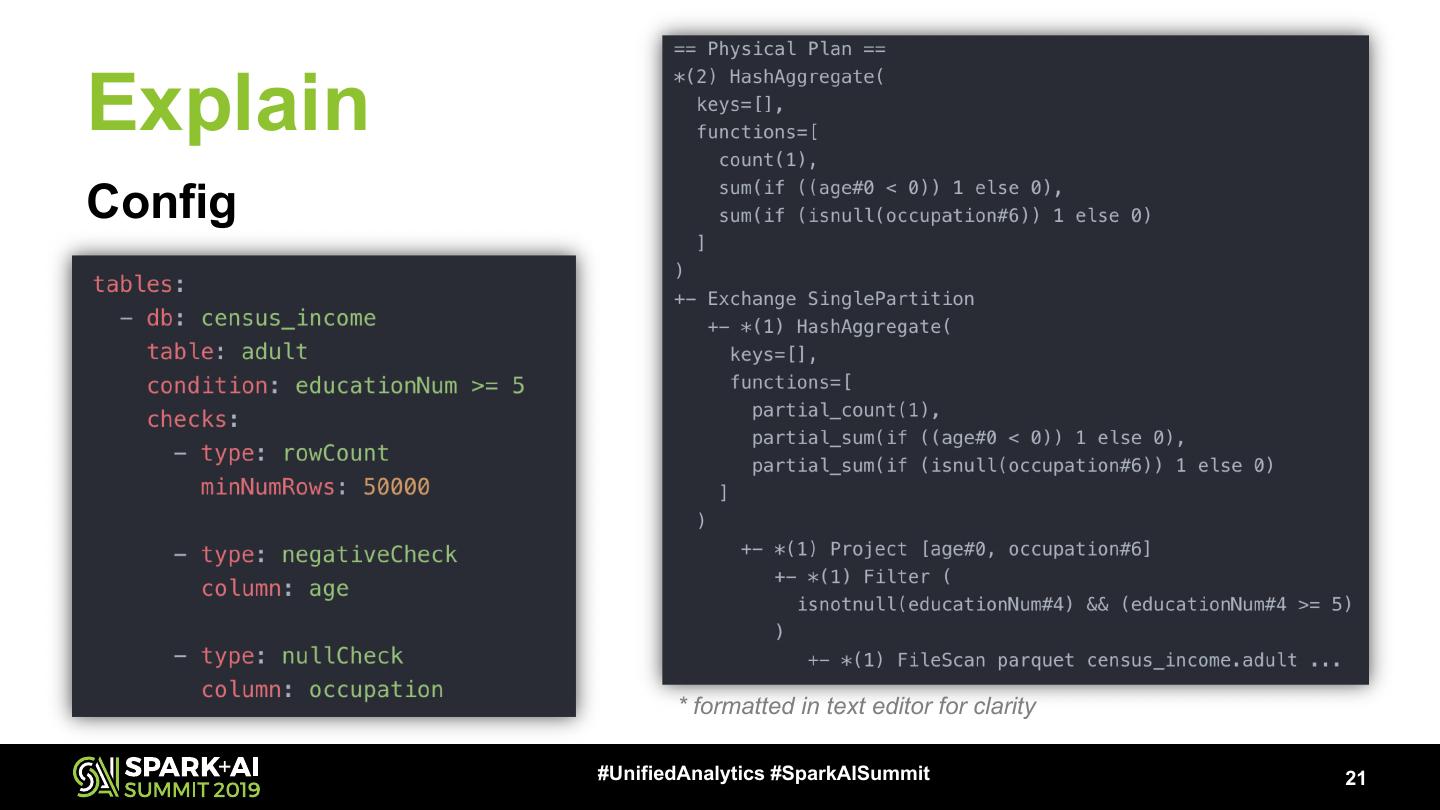
21 .Explain
Config
* formatted in text editor for clarity
#UnifiedAnalytics #SparkAISummit 21
�
22 .Reporting
• Event log
– Logs configuration settings
– Logs variable substitutions
– Logs runtime environment
and statistics
– Logs checks run and
status
– It’s extensive!
#UnifiedAnalytics #SparkAISummit 22
�
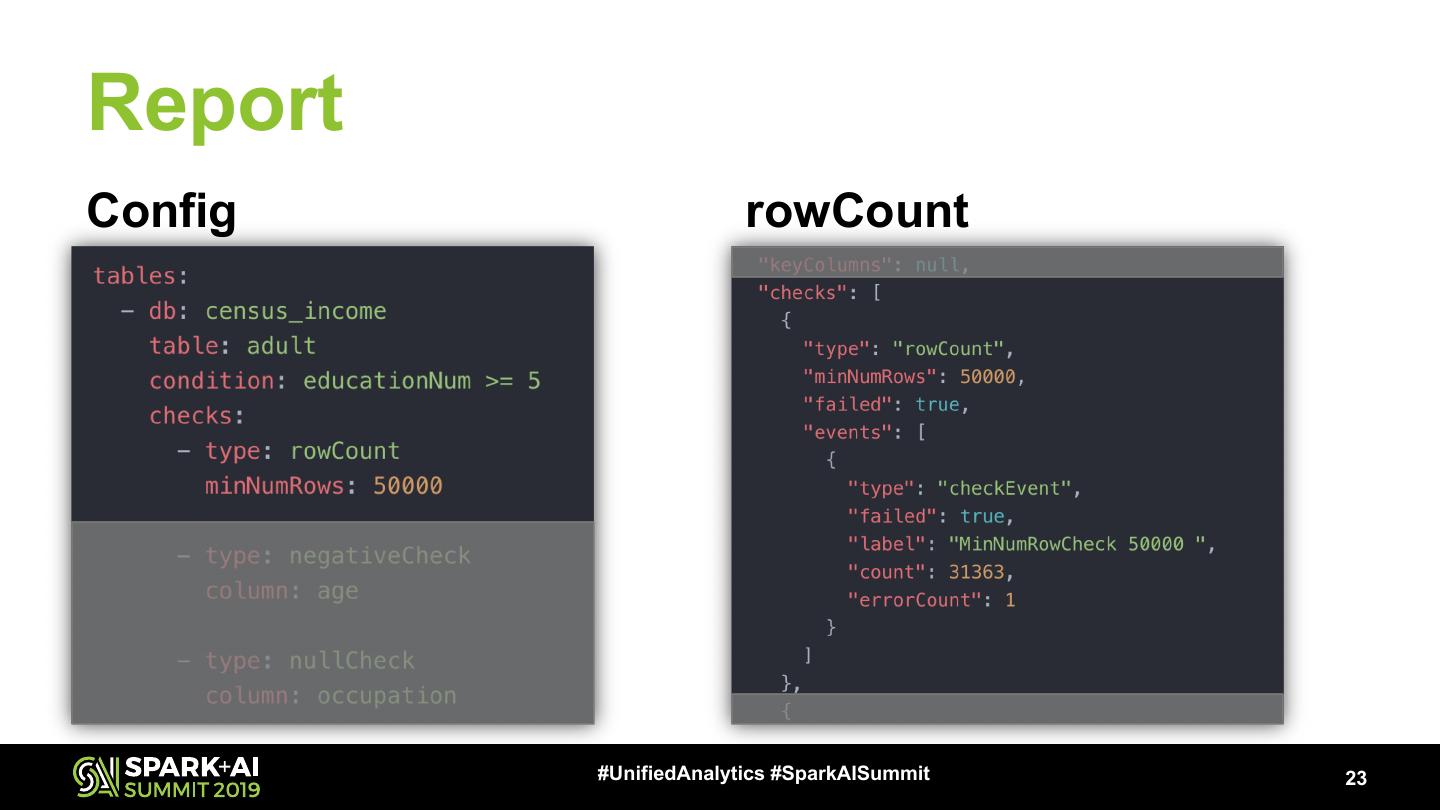
23 .Report
Config rowCount
#UnifiedAnalytics #SparkAISummit 23
�
24 .Report
Config negativeCheck
#UnifiedAnalytics #SparkAISummit 24
�
25 .Report
Config nullCheck
#UnifiedAnalytics #SparkAISummit 25
�
26 .Profiling
Config
#UnifiedAnalytics #SparkAISummit 26
�
27 .Profiling
Config
#UnifiedAnalytics #SparkAISummit 27
�
28 .Profiling Implementation
• Catalyst
aggregate
expressions
• Min
• Max
• Average
• Count
• Stddev
• UDAF
• histogram
#UnifiedAnalytics #SparkAISummit 28
�
29 .Profiling
• Parse / pipe output from report to tool for visualization
• Facets Overview
#UnifiedAnalytics #SparkAISummit 29
�