






















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Spark's Built-in File Sources in Depth
In Spark 3.0 releases, all the built-in file source connectors [including Parquet, ORC, JSON, Avro, CSV, Text] are re-implemented using the new data source API V2. We will give a technical overview of how Spark reads and writes these file formats based on the user-specified data layouts. The talk will also explain the differences between Hive Serde and native connectors, and share the experiences of how to tune the connectors and choose the best data layouts for achieving the best performance.
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
2 .Apache Spark’s Built-in File Sources in Depth Gengliang Wang, Databricks #UnifiedDataAnalytics #SparkAISummit
3 .About me • Gengliang Wang(Github:gengliangwang) • Software Engineer at • Apache Spark committer #UnifiedDataAnalytics #SparkAISummit 3
4 .Agenda • File formats • Data layout • File reader internals • File writer internals 4
5 .5
6 .Built-in File formats • Column-oriented • Row-oriented – Parquet – Avro – ORC – JSON – CSV – Text – Binary 6
7 .Column vs. Row Example table “music” artist genre year album Elvis Presley Country 1965 Love Me Tender The Beatles Rock 1966 Revolver Nirvana Rock 1991 Nevermind 7
8 .Column vs. Row Column Row Elvis Presley, The Beatles, Nirvana Elvis Presley, Country, 1965, Love Me Tender Country, Rock, Rock The Beatles, Rock, 1966, Revolver 1965, 1966, 1991 Nirvana, Rock, 1991, Nevermind Love Me Tender, Revolver, Nevermind artist genre year album 8
9 .Column-oriented formats Column Elvis Presley, The Beatles, Nirvana SELECT album Country, Rock, Rock FROM music 1965, 1966, 1991 WHERE artist = 'The Beatles'; Love Me Tender, Revolver, Nevermind Artist Genre Year Album 9
10 .Row-oriented formats Row SELECT * FROM music; Elvis Presley, Country, 1965, Love Me Tender The Beatles, Rock, 1966, Revolver Nirvana, Rock, 1991, Nevermind INSERT INTO music ... artist genre year album 10
11 .Column vs. Row Column Row • Read heavy workloads • Write heavy workloads • Queries that require only – event level data a subset of the table • Queries that require columns most or all of the table columns 11
12 .Built-in File formats • Column-oriented • Row-oriented – Parquet – Avro – ORC – JSON – CSV – Text – Binary 12
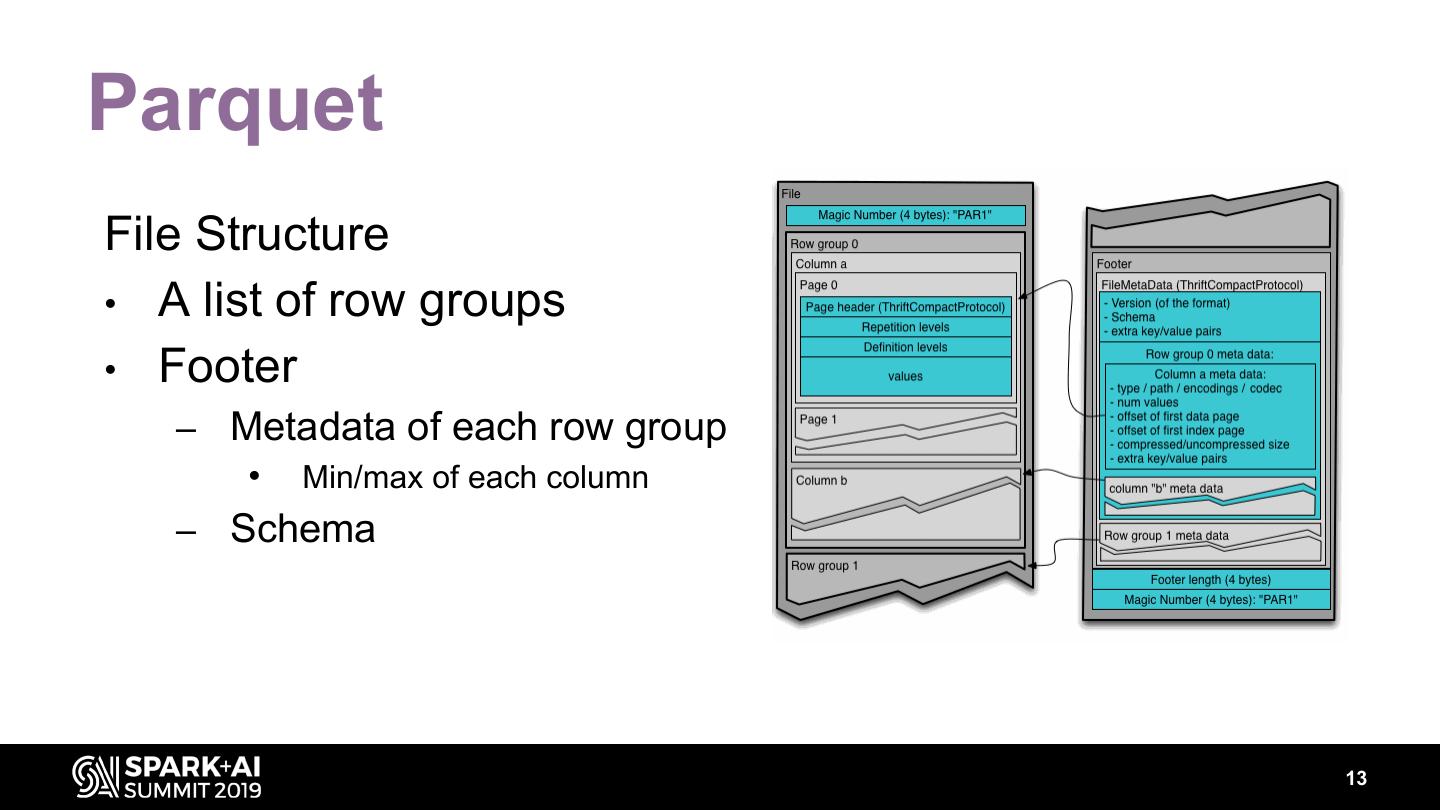
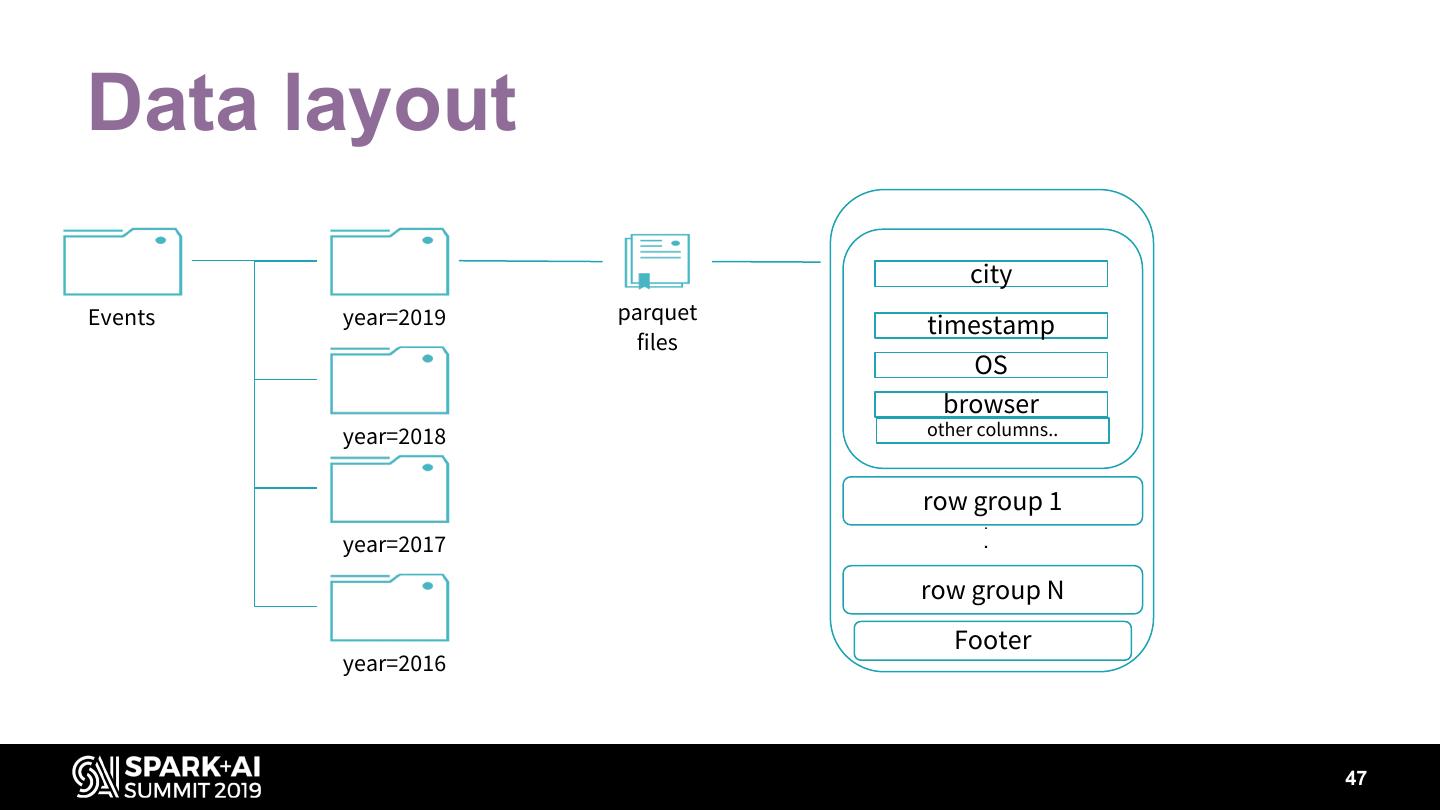
13 .Parquet File Structure • A list of row groups • Footer – Metadata of each row group • Min/max of each column – Schema 13
14 .Parquet Row group • A list of column trunks – One column chunk per column Column chunk • A list of data pages • An optional dictionary page 14
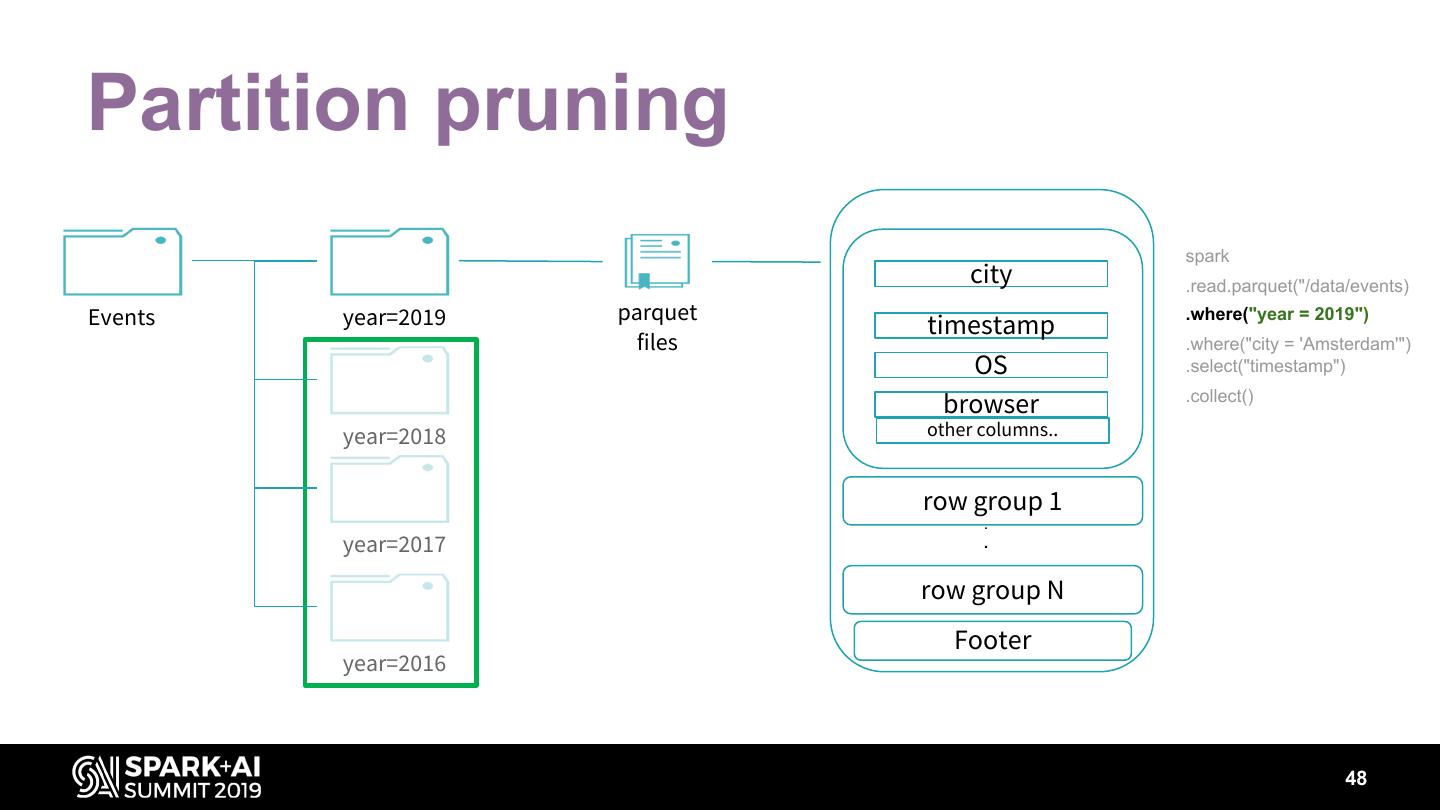
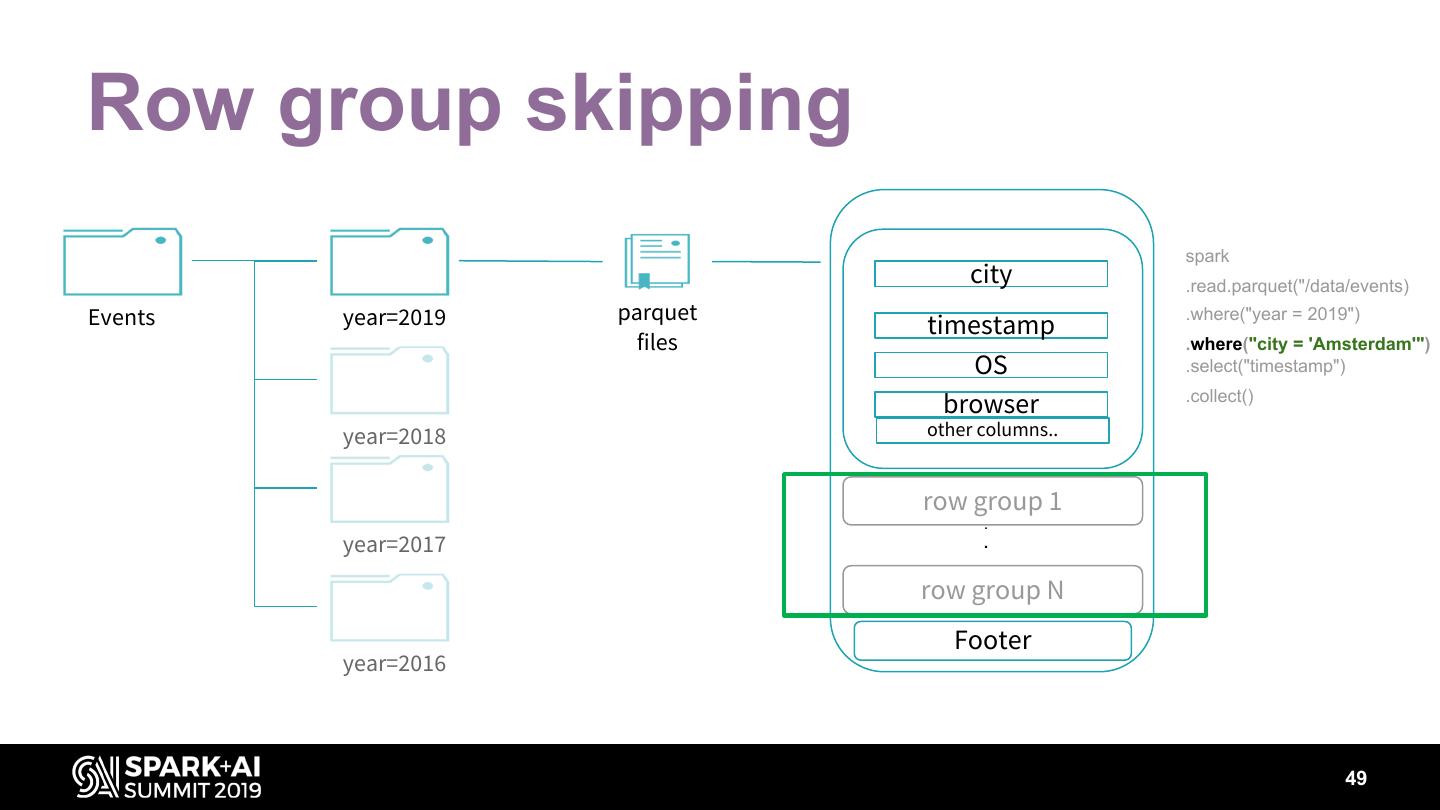
15 .Parquet Predicates pushed down • a=1 • a<1 • a>1 • … Row group skipping • Footer stats (min/max) • Dictionary pages of column chunks 15
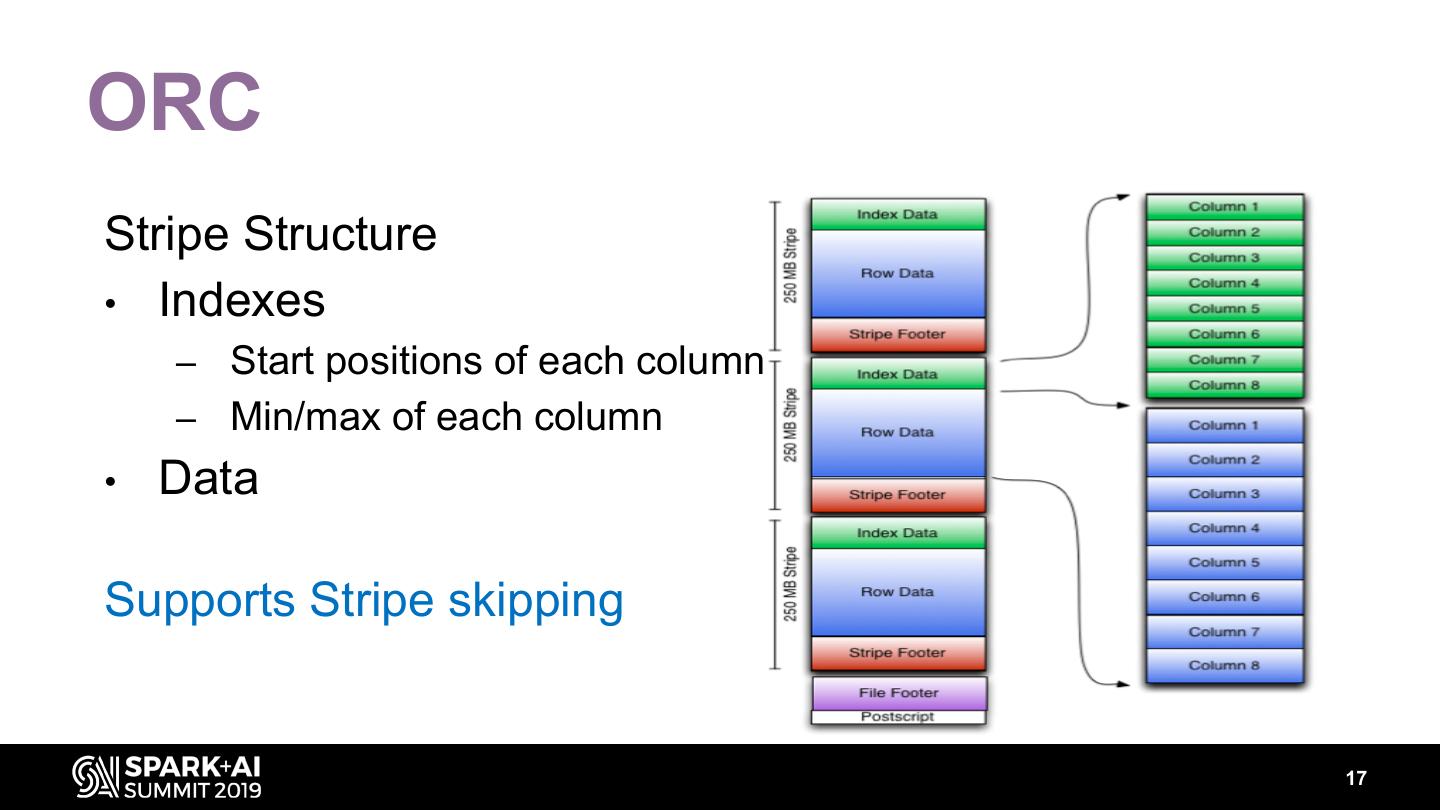
16 .ORC File Structure • A list of stripes • Footer – column-level aggregates count, min, max, and sum – The number of rows per stripe 16
17 .ORC Stripe Structure • Indexes – Start positions of each column – Min/max of each column • Data Supports Stripe skipping 17
18 .Built-in File formats • Column-oriented • Row-oriented – Parquet – Avro – ORC – JSON – CSV – Text – Binary 18
19 .Avro • Compact • Fast • Robust support for schema evolution – Adding fields – Removing fields – Renaming fields(with aliases) – Change default values – Change docs of fields 19
20 .Semi-structured text formats: JSON & CSV • Excellent write path performance but slow on the read path – Good candidates for collecting raw data (e.g., logs) • Subject to inconsistent and/or malformed records • Schema inference provided by Spark – Sampling-based – Handy for exploratory scenario but can be inaccurate 20
21 .JSON • JSON object: map or struct? – Spark schema inference always treats JSON objects as structs – Watch out for arbitrary number of keys (may OOM executors) – Specify an accurate schema if you decide to stick with maps 21
22 .Avro vs. JSON Avro JSON • Compact and Fast • Repeating every field name • Accurate schema inference with every single record • High data quality and robust • Schema inference can schema revolution support, inaccurate good choice for organizational • Light weight, easy scale development development and debug – Event data from Web/iOS/Android clients 22
23 .CSV • Often used for handling legacy data providers & consumers – Lacks of a standard file specification • Separator, escaping, quoting, and etc. – Lacks of support for nested data types 23
24 .Raw text files Arbitrary line-based text files • Splitting files into lines using spark.read.text() – Keep your lines a reasonable size • Limited schema with only one field – value: (StringType) 24
25 .Binary • New file data source in Spark 3.0 • Reads binary files and converts each file into a single record that contains the raw content and metadata of the file 25
26 .Binary Schema • path (StringType) • modificationTime (TimestampType) • length (LongType) • content (BinaryType) 26
27 .Binary To reads all JPG files recursively from the input directory and ignores partition discovery spark.read.format("binaryFile") .option("pathGlobFilter", "*.jpg") .option("recursiveFileLookup", "true") .load("/path/to/dir") 27
28 .Agenda • File formats • Data layout • File reader internals • File writer internals 28
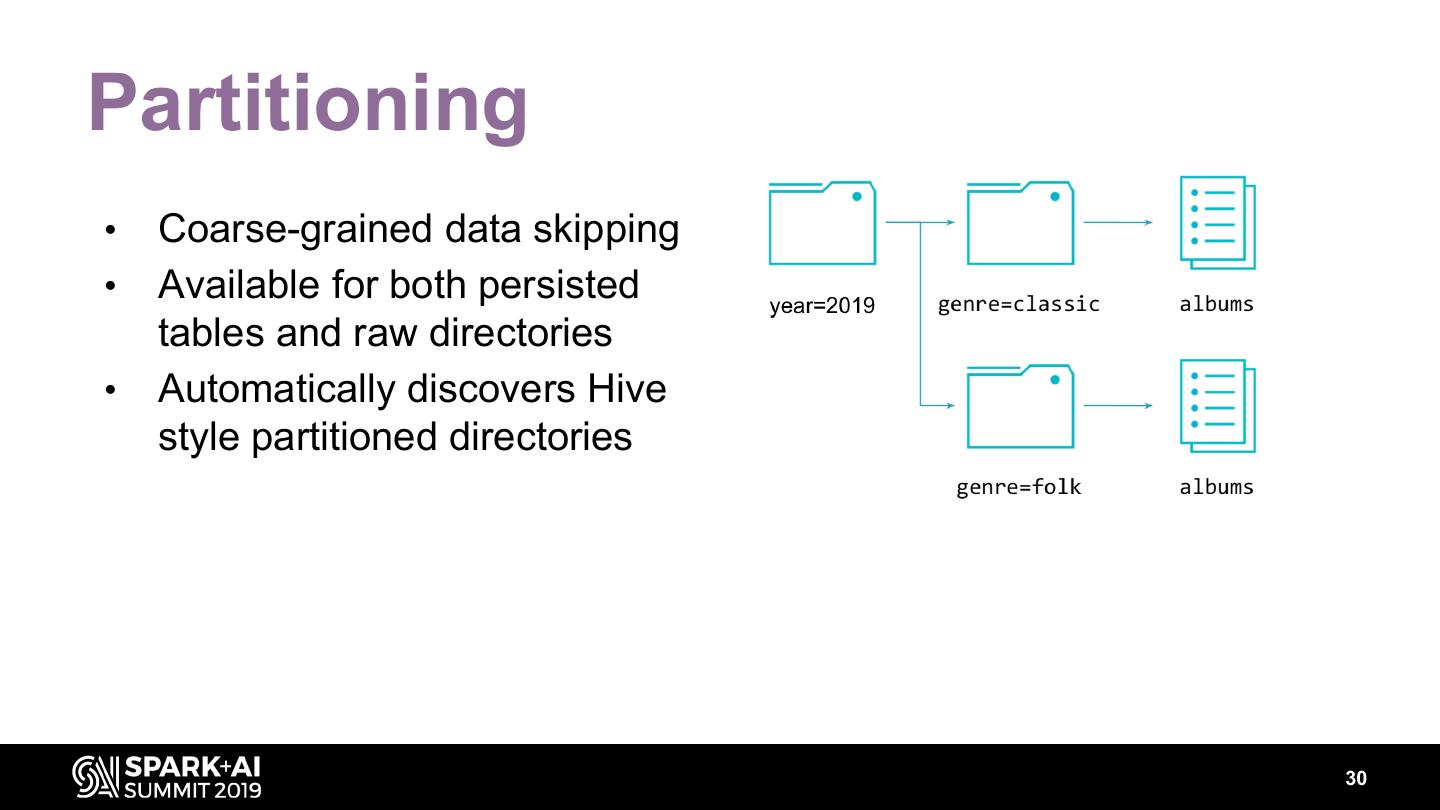
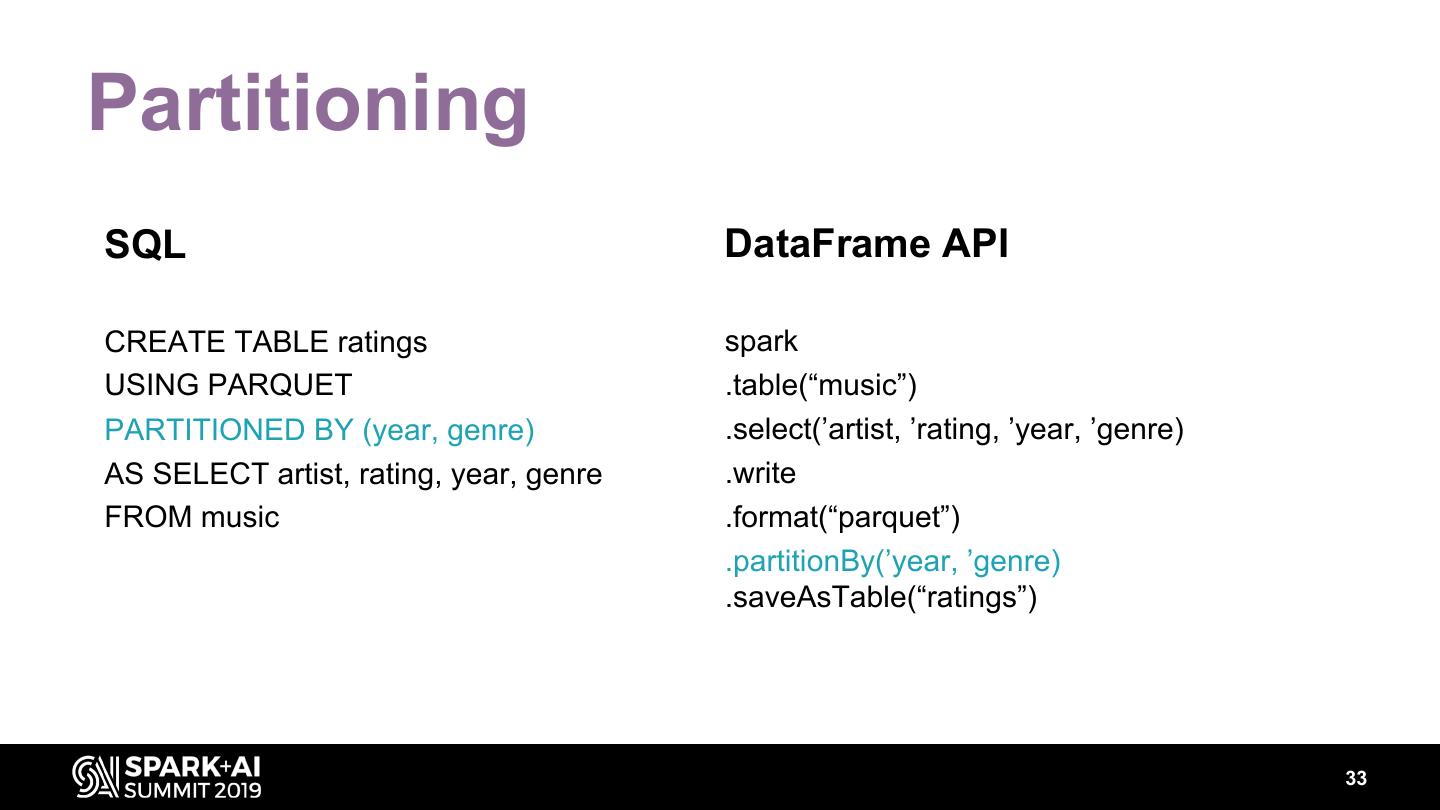
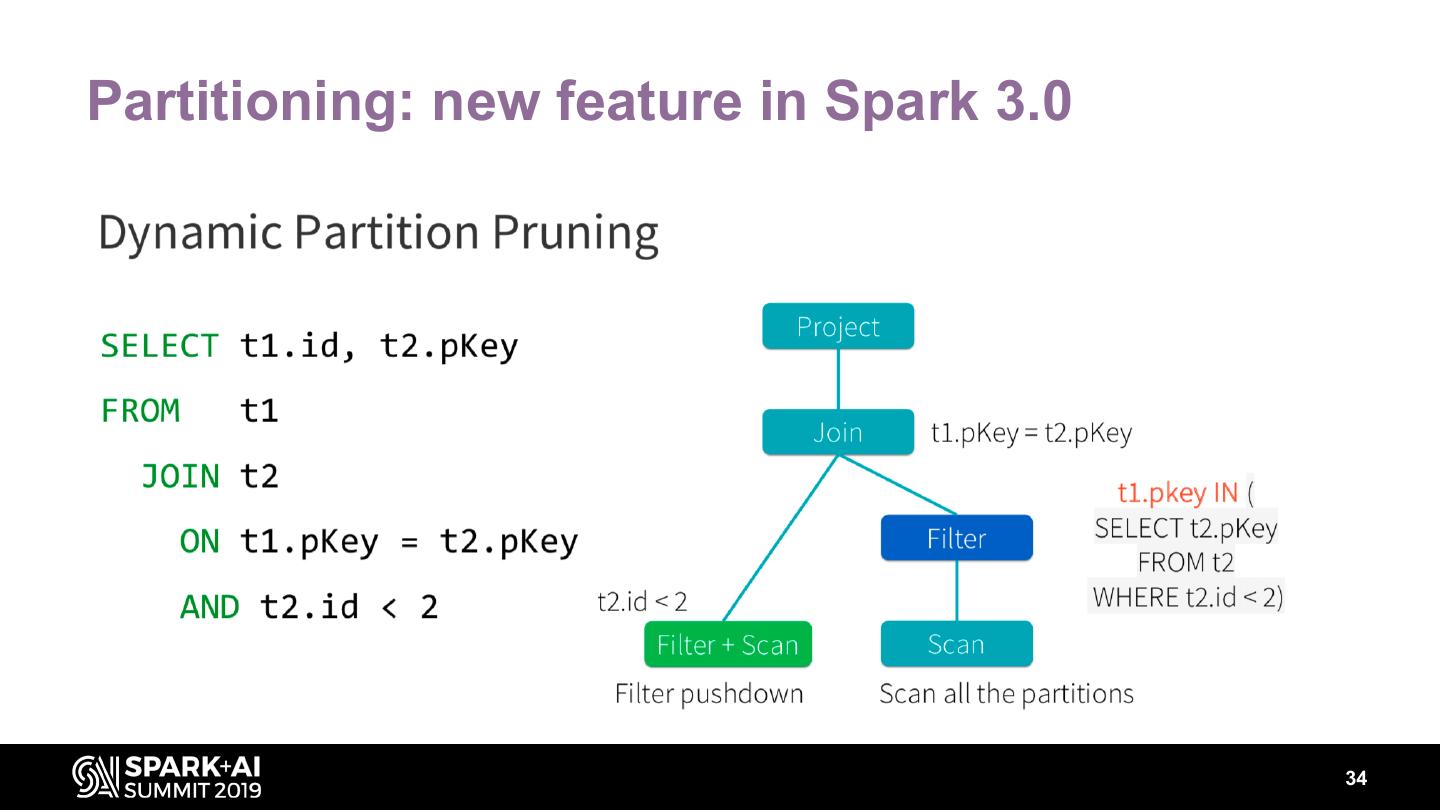
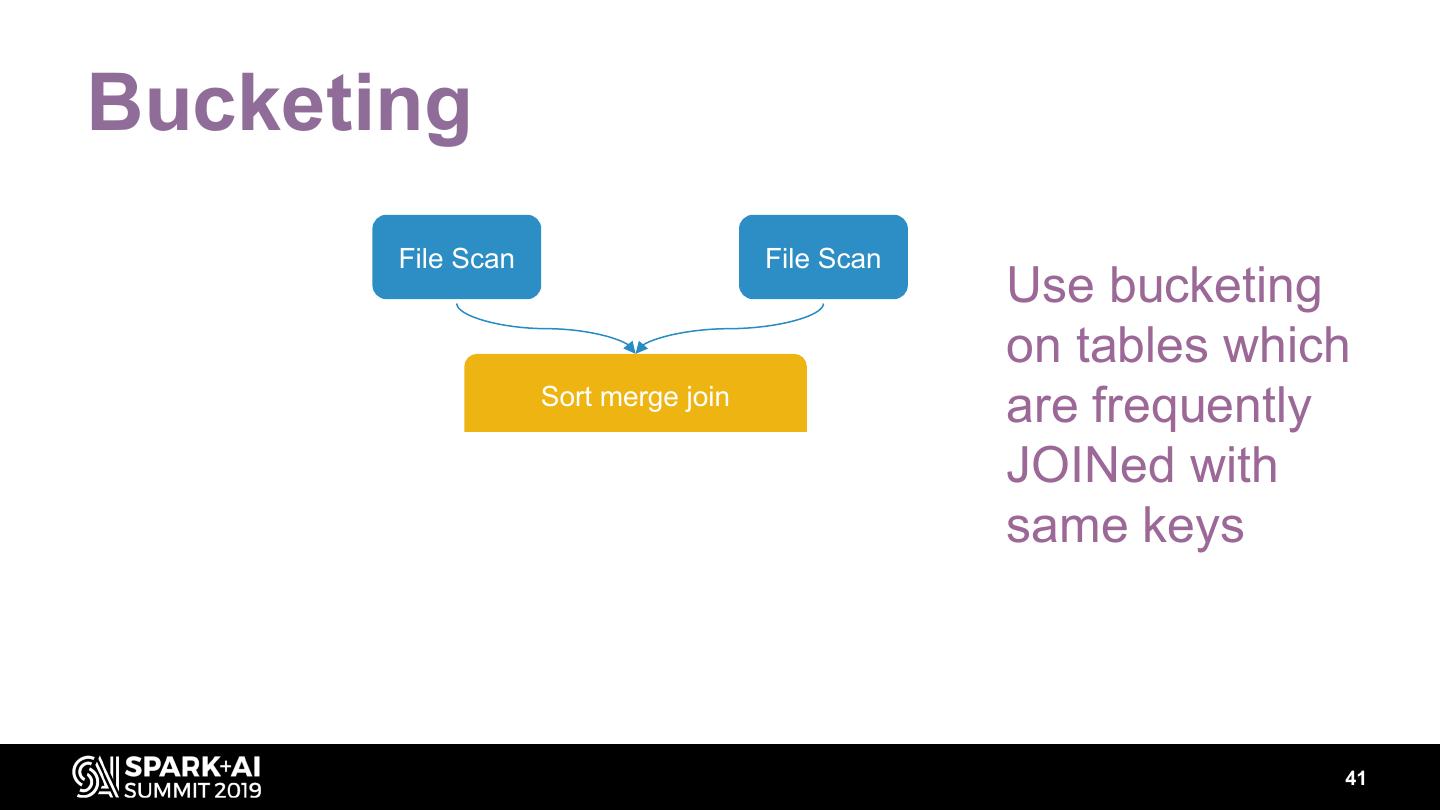
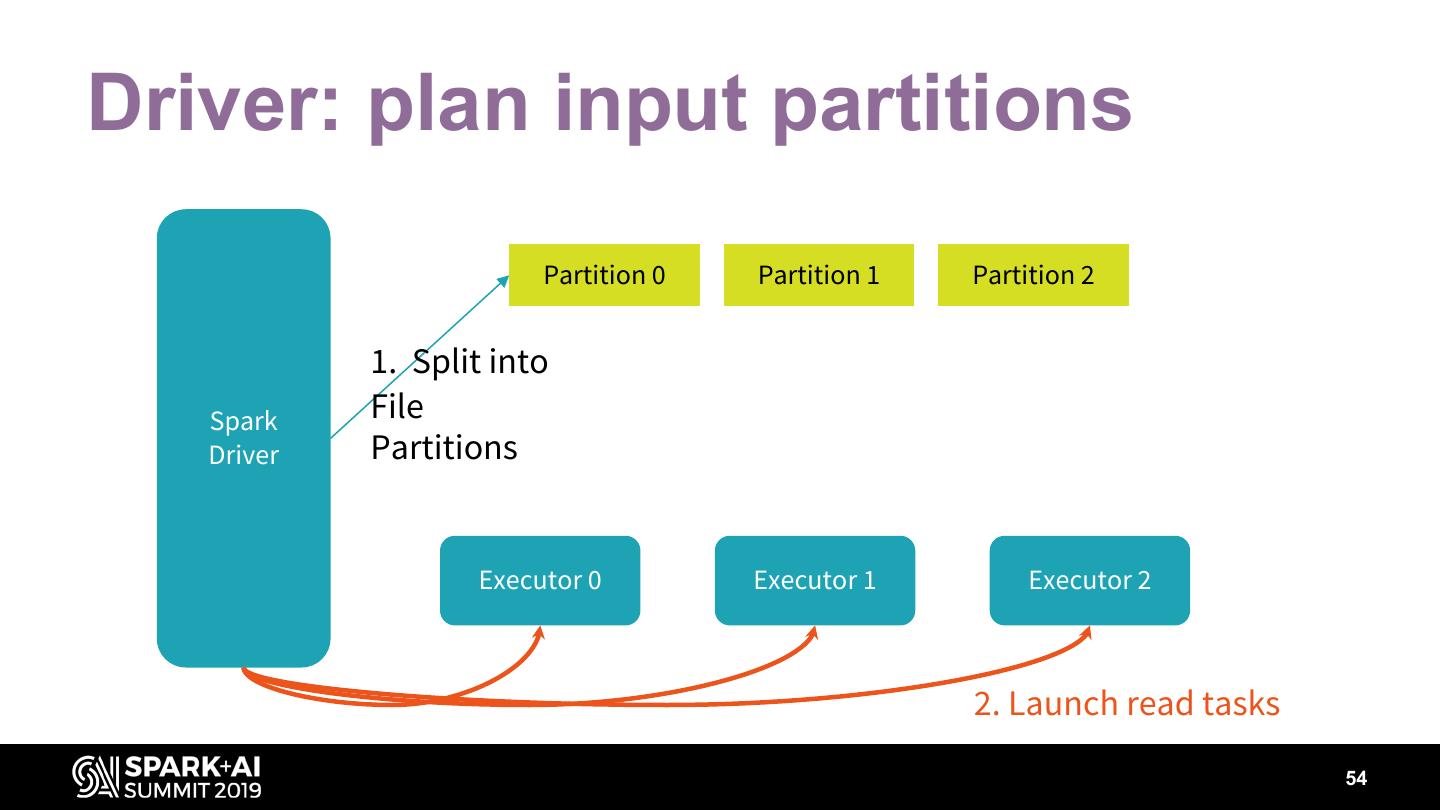
29 .Data layout • Partitioning • Bucketing 29
3秒后跳转登录页面
去登陆

