展开查看详情
1 .Apache Spark at Apple
•
Spark + AI Summit 2018
Sam Maclennan and Vishwanath Lakkundi
© 2018 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission from Apple.
�
2 .Traditional Apache Hadoop at Apple
We schedule with YARN on HDFS
A lot of batch processing including ingest
�
3 .Along Comes Apache Spark
Users started testing pre 1.0
New set of users vs. MapReduce
Largely adhoc
�
4 .Spark Growth
September 2016 May 2018
25%
46%
54%
75%
Spark Spark
MapReduce MapReduce
�
5 .Challenges Scaling to Production
• Listenerbus
• Fault tolerance
• History Server
• Streaming jobs
�
6 .More Challenges Optimizing Resource Use
• Estimating Spark resource usage is harder than MapReduce
• Visualizing it is harder too
�
7 .Visualizing Resource Use
30
Used
22.5 Allocated
Memory (TB)
15
7.5
0
16:00 16:30 17:00 17:30 18:00 18:30 19:00 19:30 20:00 20:30
Time
�
8 .Hadoop/Spark Footprint
Over an exabyte of storage
Half a million cores
Over 5PB of RAM
�
9 .Hadoop Growth
In 18 months
• Storage—Up 2x
• Cores—Up 2x
• Memory—Up 4x
• Network—Now non-blocking
�
10 .Future Challenges for Spark on YARN
Tougher time with streaming jobs and having less reliance on data locality
Dimensions of hardware changing for Spark
�
11 .Elastic Self Service Spark
�
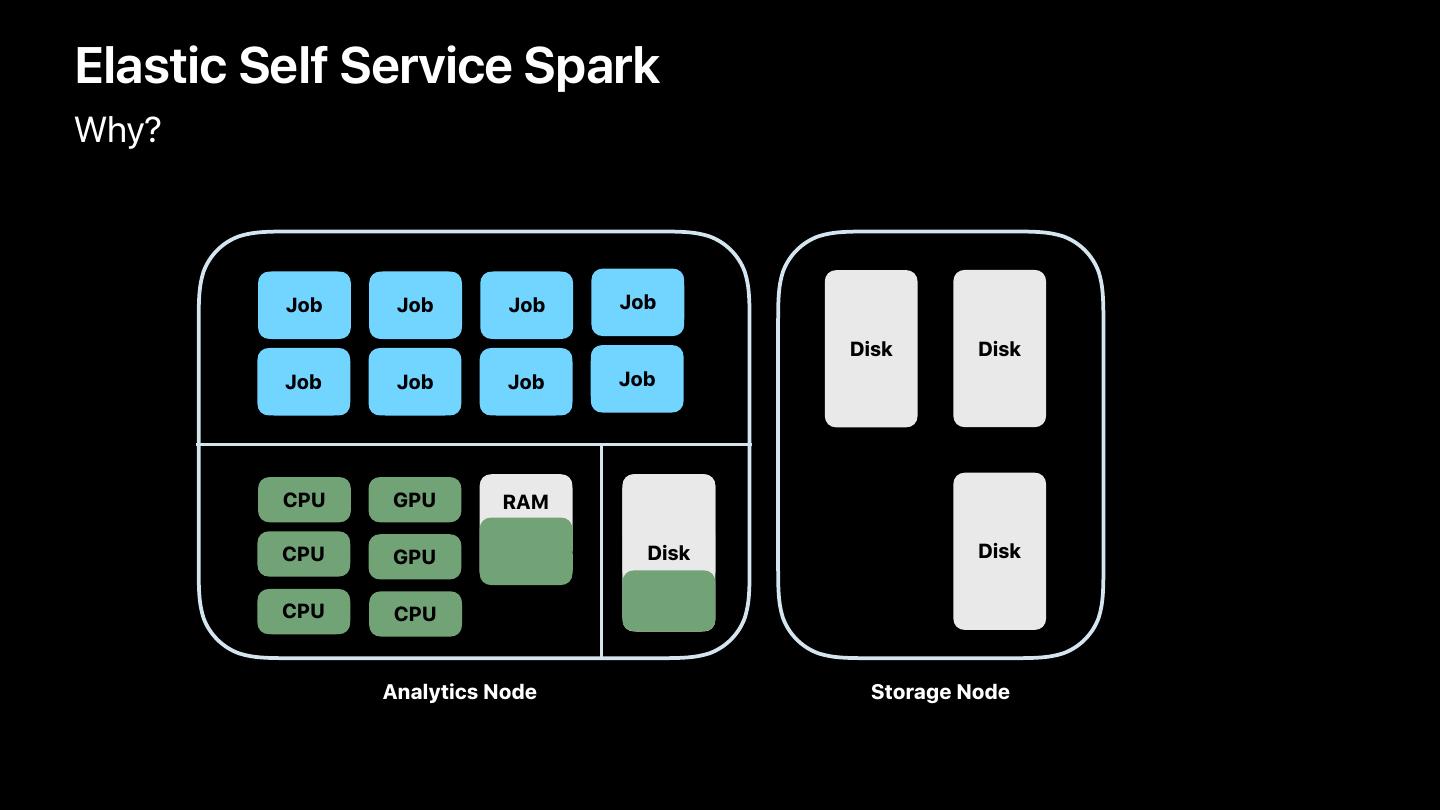
12 .Elastic Self Service Spark
Why?
Job Job Job Job
CPU GPU
RAM
CPU GPU Disk
CPU CPU
Analytics Node
�
13 .Elastic Self Service Spark
Why?
Job Job Job Job
Disk Disk
Job Job Job Job
CPU GPU RAM Disk
CPU GPU Disk Disk
CPU CPU
Analytics Node Storage Node
�
14 .Elastic Self Service Spark
Why?
Scale compute and storage independently
Maximize utilization of resources
�
15 .Elastic Self Service Spark
Goals
• Scalable, Multi-tenant, and on-demand Spark
• Security-first design
• Developer and Data Scientist productivity
• Cost efficiency
• Uptime
• Connectivity and Metrics
�
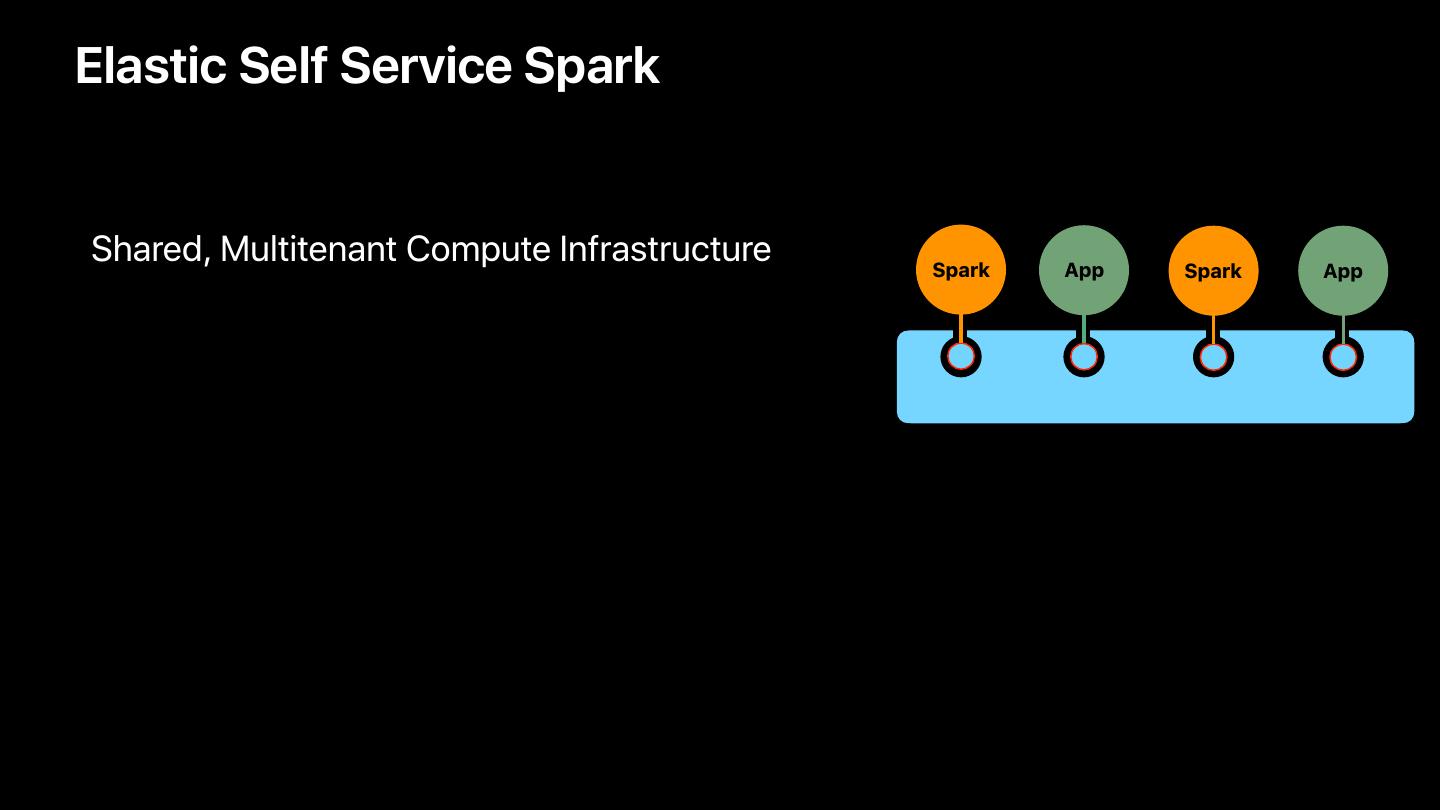
16 .Elastic Self Service Spark
• Shared, Multitenant Compute Infrastructure
Spark App Spark App
•
�
17 .Elastic Self Service Spark
• Shared, Multitenant Compute Infrastructure
Spark App Spark App
• Built on Apache Mesos and a custom scheduler
• Spark 1.6.2, 2.1.1, 2.2.1 and 2.3
Scheduler
Mesos
�
18 . Concepts
• Logical Environment
• • For network isolation
• For Automatic scale up/down boundaries
• For CI/CD
Spark
• One place to see them all
Spark
Notebook
Environment
�
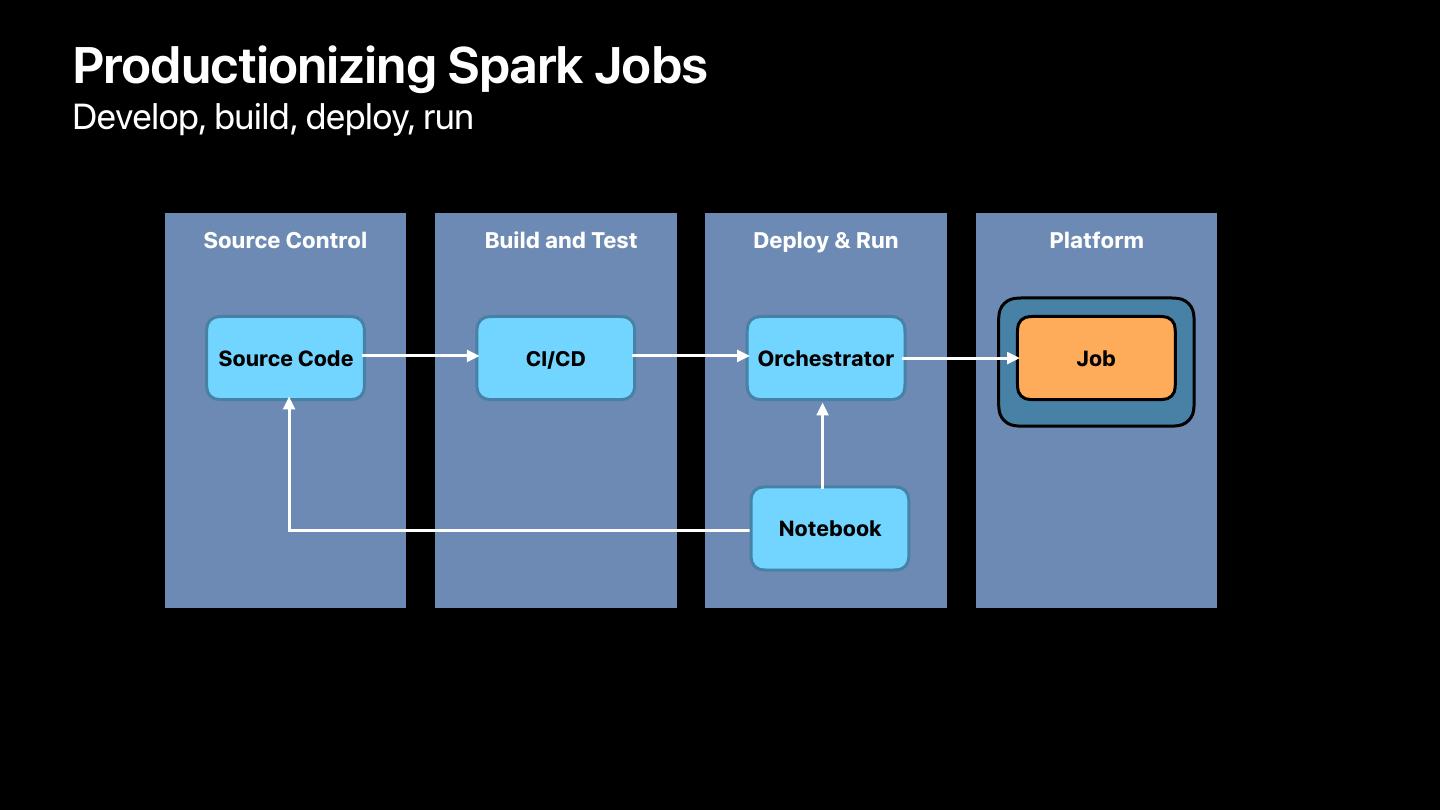
19 .Productionizing Spark Jobs
Develop, build, deploy, run
Source Control Build and Test Deploy & Run Platform
Source Code CI/CD Orchestrator Job
Notebook
�
20 .How Does it Work?
Driver Executor
APIs
Portal Orchestrator Scheduler
Workflow
Engines
Executor
�
21 .Configuring Your Job
Yaml based Job spec
Define jobs and properties
jobs:
# Name of the job
- name: word-search
jobClass: 'spark.examples.WordSearch'
sparkVersion: 2.2.0
# The properties for the spark job.
properties:
spark.executor.instances: 1000
spark.executor.cores: 8
�
22 .Security
• Application certificates for each driver and executor
• Predefined network policy for connectivity
App
• Authorized allocation of ports 011001
• Encryption on wire for all data ID Cert
• Secrets
�
23 .Telemetry and Forensics
• Driver and Executor Logs available through log management system
• Automatic integration with Telemetry system
• User defined metrics
• Ability to alert on Key metrics
• Driver/Executor Memory
• Task Metrics (Failed Tasks, Input Records, etc)
• BlockManager, Scheduler
• System, Load Avg
�
24 .History Server
• Multi-tenant history server
• History server based off of Spark 2.3
�
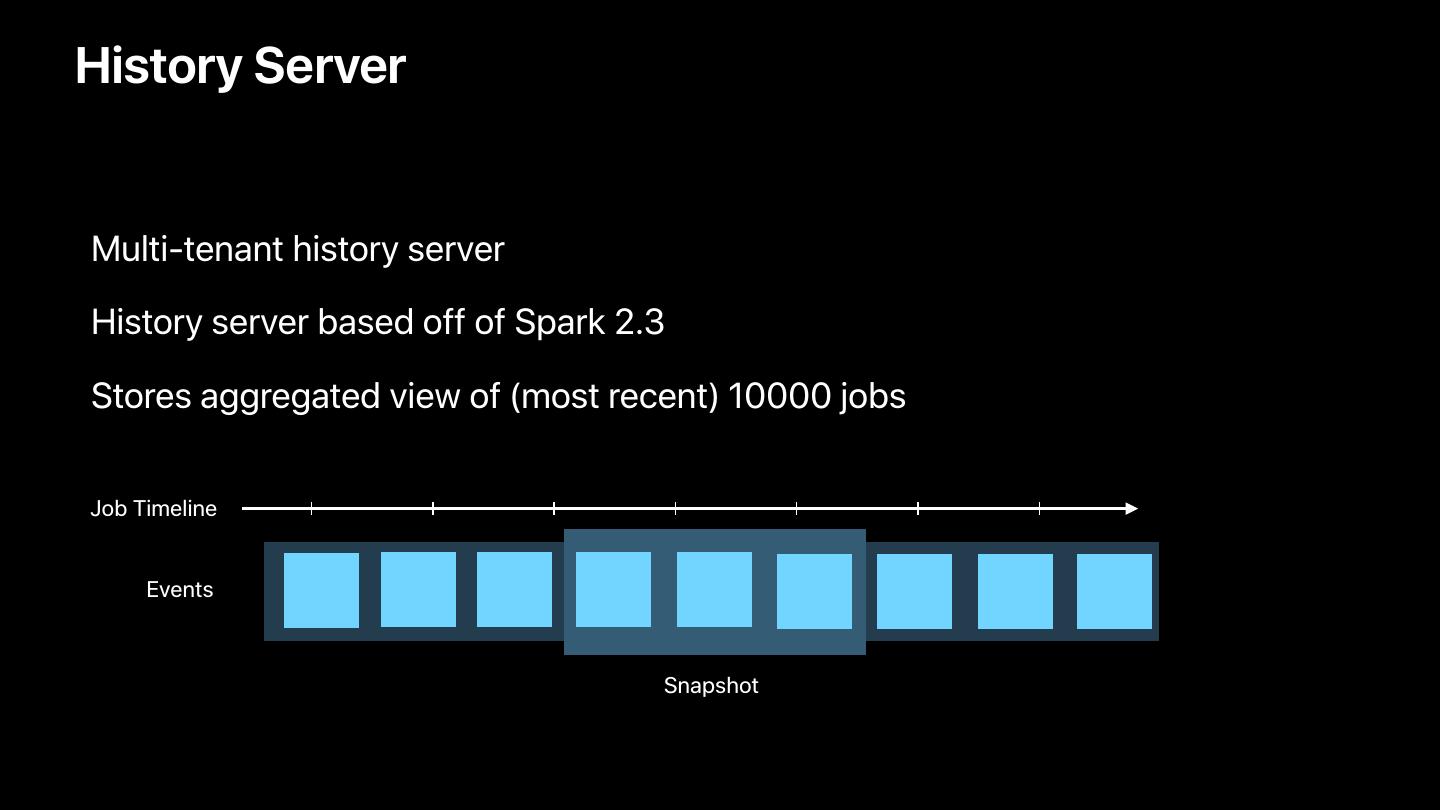
25 .History Server
• Multi-tenant history server
• History server based off of Spark 2.3
• Stores aggregated view of (most recent) 10000 jobs
Job Timeline
Events
Snapshot
�
26 .Elastic Self Service Spark
900 900,000
675 675,000
No of Executors
RAM in TB
450 450,000
225 225,000
0 0
Feb Mar Apr May
Ram (TB) Executors
�
27 .Open Source Is In Our Culture
�
28 .Open Source Is in Our Culture
�