





















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Spark 2.4 and Beyond
It offers an overview of the major features and enhancements in Apache Spark 2.4 and give insight into upcoming releases [Apache Spark 3.0].
展开查看详情
1 .Apache Spark 2.4 and Beyond Xiao Li, Wenchen Fan Mar 2019 @ Strata Data Conf
2 .About US • Software Engineers at • Apache Spark Committers and PMC Members Xiao Li (Github: gatorsmile) Wenchen Fan (Github: cloud-fan)
3 . Databricks Customers Across Industries Financial Services Healthcare & Pharma Media & Entertainment Data & Analytics Services Technology Public Sector Retail & CPG Consumer Services Marketing & AdTech Energy & Industrial IoT
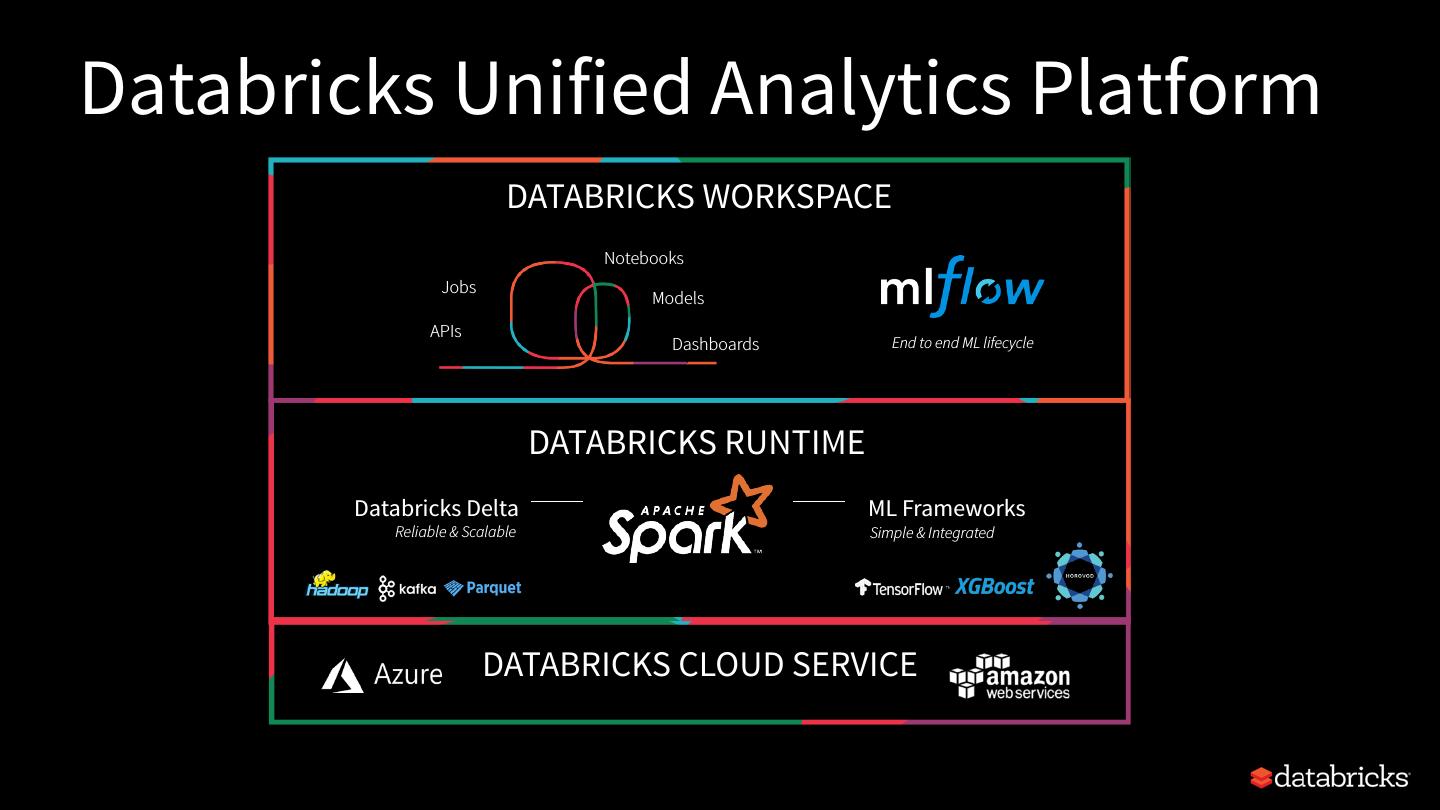
4 .Databricks Unified Analytics Platform DATABRICKS WORKSPACE Notebooks Jobs Models APIs Dashboards End to end ML lifecycle DATABRICKS RUNTIME Databricks Delta ML Frameworks Reliable & Scalable Simple & Integrated DATABRICKS CLOUD SERVICE
5 .
6 .https://insights.stackoverflow.com/survey/2018
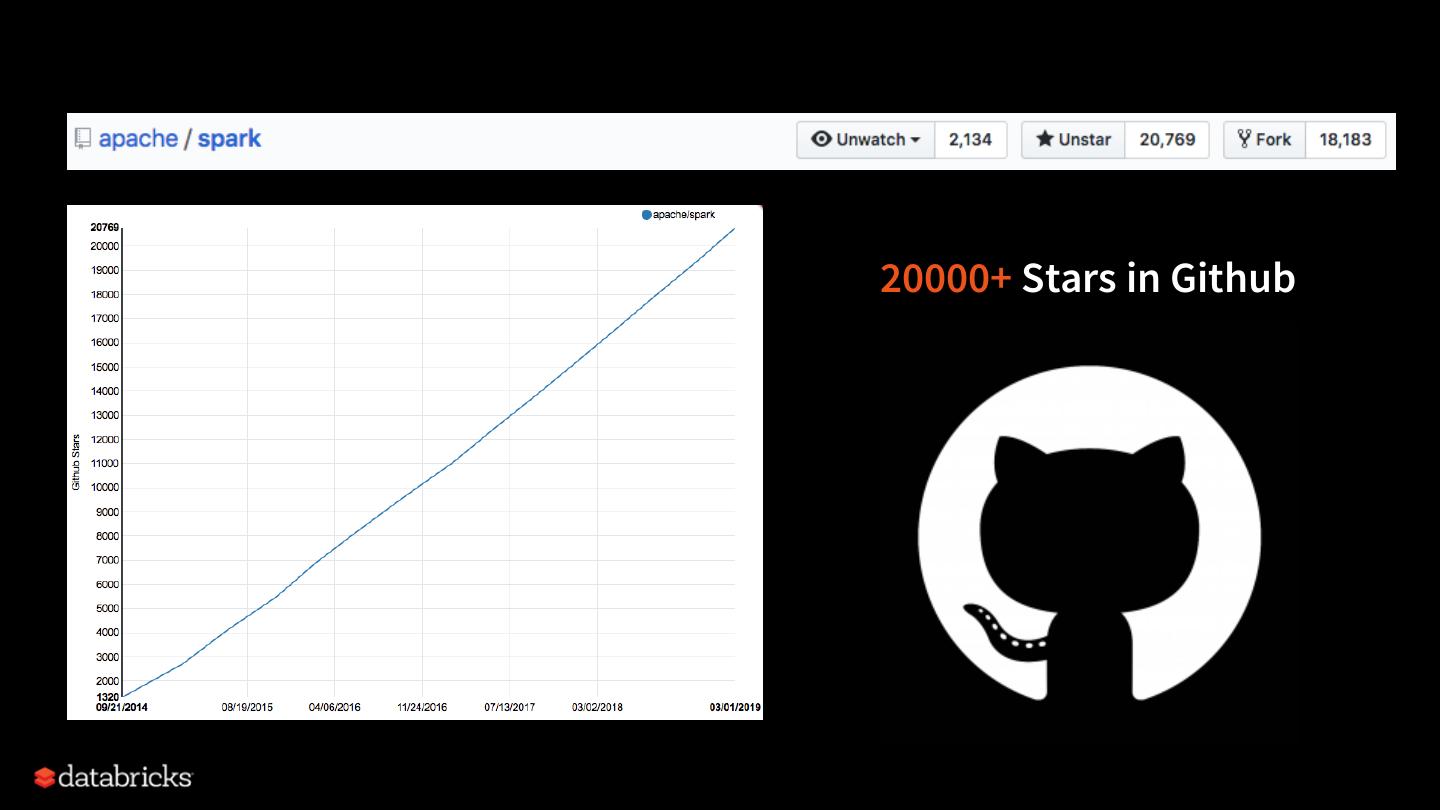
7 .20000+ Stars in Github
8 . Top Skill in 2018: Apache Spark https://economicgraph.linkedin.com/research/linkedin-2018-emerging-jobs-report
9 .
10 .Release: Nov 8, 2018 Blog: https://t.co/k7kEHrNZXp Above 1100 tickets. 10
11 .Major Features on Spark 2.4 Barrier Spark on Beta support PySpark Structured Execution Kubernetes Scala 2.12 Improvement Streaming Image Native Avro Built-in source Higher-order Various SQL Source Support Improvement Functions Features 11
12 .Survey Key Findings: The AI Dilemma Investment in AI is Growing Quickly However, very few are succeeding Major contributing factors to this AI dilemma 7 Different machine learning frameworks and tools https://databricks.com/CIO-survey-report
13 .CIO Survey Key Findings: Unified Analytics Enables AI Success Benefits Expected from a Unified Approach to Data & AI Increased operational efficiency More effective decision making Accelerated time to market Improved security Increased innovation Improved customer experience Increased competitive advantage Increased employee satisfaction Increased customer engagement Product/service transformation Topline growth Unifying data science & engineering Other (specify)
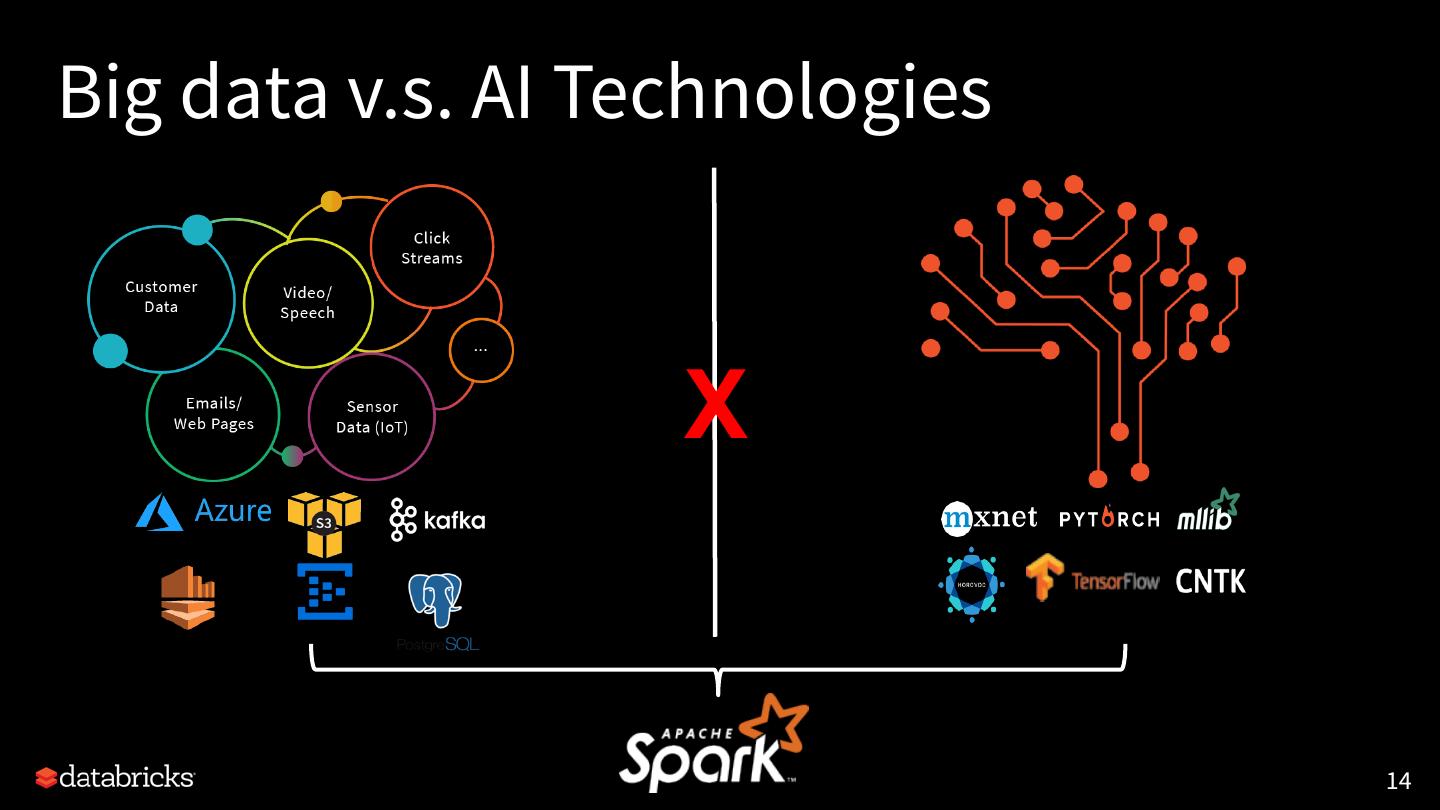
14 .Big data v.s. AI Technologies X 14
15 .Project Hydrogen: Spark + AI A gang scheduling to Apache Spark that embeds a distributed DL job as a Spark stage to simplify the distributed training workflow. [SPARK-24374] Task 1 Task 2 Task 3 15
16 .Major Features on Spark 2.4 Barrier Spark on Native Avro Image Built-in source Execution Kubernetes Support Source Improvement PySpark Higher-order Scala Structured Various SQL Improvement Functions 2.12 Streaming Features 16
17 .Flexible Streaming Sink [SPARK-24565] Exposing output rows of each microbatch as a DataFrame foreachBatch(f: Dataset[T] => Unit) • Scala/Java/Python APIs in DataStreamWriter. • Reuse existing batch data sources • Write to multiple locations • Apply additional DataFrame operations 17
18 .Reuse existing batch data sources 18
19 .Write to multiple location 19
20 .Major Features on Spark 2.4 Barrier Spark on Native Avro Image Built-in source Execution Kubernetes Support Source Improvement PySpark Higher-order Scala Structured Various SQL Improvement Functions 2.12 Streaming Features 20
21 .Parquet Update from 1.8.2 to 1.10.0 [SPARK-23972]. • PARQUET-1025 - Support new min-max statistics in parquet-mr • PARQUET-225 - INT64 support for delta encoding • PARQUET-1142 Enable parquet.filter.dictionary.enabled by default. Predicate pushdown • STRING [SPARK-23972] [20x faster] • Byte/Short [SPARK-24706] • Decimal [SPARK-24549] • StringStartsWith [SPARK-24638] • Timestamp [SPARK-24718] • IN [SPARK-17091] • Date [SPARK-23727] 21
22 .ORC Native vectorized ORC reader is GAed! • Native ORC reader is on by default [SPARK-23456] • Update ORC from 1.4.1 to 1.5.2 [SPARK-24576] • Turn on ORC filter push-down by default [SPARK-21783] • Use native ORC reader to read Hive serde tables by default [SPARK-22279] • Avoid creating reader for all ORC files [SPARK-25126] 22
23 .Major Features on Upcoming Spark 2.4 Barrier Spark on Native Avro Image Built-in source Execution Kubernetes Support Source Improvement PySpark Higher-order Scala Structured Various SQL Improvement Functions 2.12 Streaming Features 23
24 .Higher-order Functions Transformation on complex objects like arrays, maps and structures inside of columns. tbl_nested |-- key: long (nullable = false) |-- values: array (nullable = false) | |-- element: long (containsNull = false) UDF ? Expensive data serialization 24
25 .Higher-order Functions 1) Check for element existence tbl_nested |-- key: long (nullable = false) SELECT EXISTS(values, e -> e > 30) AS v FROM tbl_nested; |-- values: array (nullable = false) 2) Transform an array | |-- element: long (containsNull = false) SELECT TRANSFORM(values, e -> e * e) AS v FROM tbl_nested;
26 .Higher-order Functions 3) Filter an array tbl_nested |-- key: long (nullable = false) SELECT FILTER(values, e -> e > 30) AS v |-- values: array (nullable = false) FROM tbl_nested; | |-- element: long (containsNull = false) 4) Aggregate an array SELECT REDUCE(values, 0, (value, acc) -> value + acc) AS sum FROM tbl_nested; Ref Databricks Blog: http://dbricks.co/2rUKQ1A
27 .Built-in Functions [SPARK-23899] New or extended built-in functions for ArrayTypes and MapTypes • 26 functions for ArrayTypes transform, filter, reduce, array_distinct, array_intersect, array_union, array_except, array_join, array_max, array_min, ... • 3 functions for MapTypes map_from_arrays, map_from_entries, map_concat Blog: Introducing New Built-in and Higher-Order Functions for Complex Data Types in Apache Spark 2.4. https://t.co/p1TRRtabJJ 27
28 .Major Features on Spark 2.4 Barrier Spark on Native Avro Image Built-in source Execution Kubernetes Support Source Improvement PySpark Higher-order Scala Structured Various SQL Improvement Functions 2.12 Streaming Features 28
29 .Native Spark App in K8S New Spark scheduler backend • PySpark support [SPARK-23984] • SparkR support [SPARK-24433] • Client-mode support [SPARK-23146] on • Support for mounting K8S volumes [SPARK-23529] Blog: What’s New for Apache Spark on Kubernetes in the Upcoming Apache Spark 2.4 Release https://t.co/uUpdUj2Z4B 29
3秒后跳转登录页面
去登陆

