展开查看详情
1 .Project Hydrogen, HorovodRunner, and
Pandas UDF: Distributed Deep Learning
Training and Inference on Apache Spark
Lu WANG
2019-01-17 BASM Meetup @ Unravel Data
1
�
2 .About
• Lu Wang
• Software engineer @ Databricks
• Ph.D. from Penn State in Mathematics
• Contributor to Deep Learning Pipelines
2
�
3 .Table of contents
• Introduction
• Project Hydrogen: Spark + AI
• Barrier Execution Mode: HorovodRunner
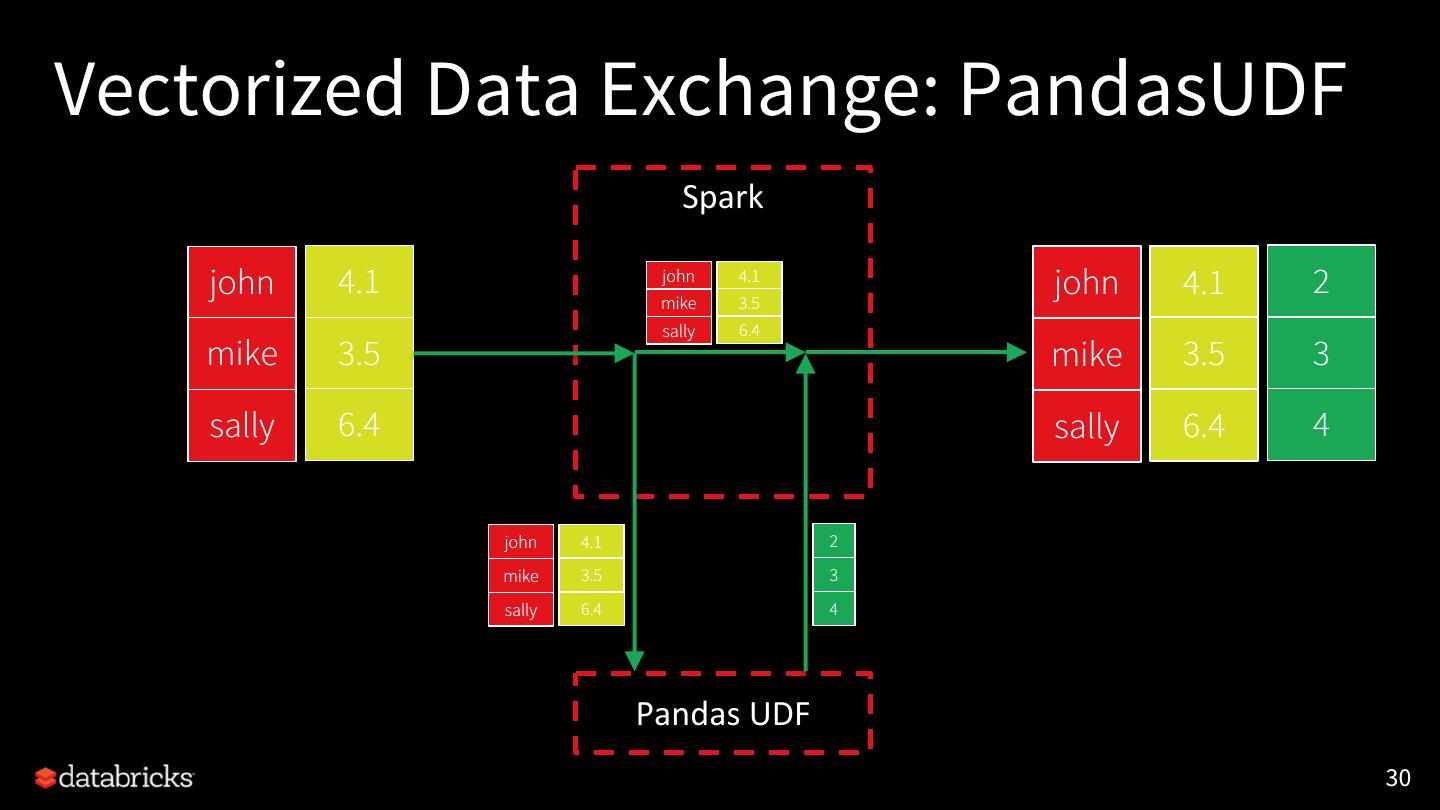
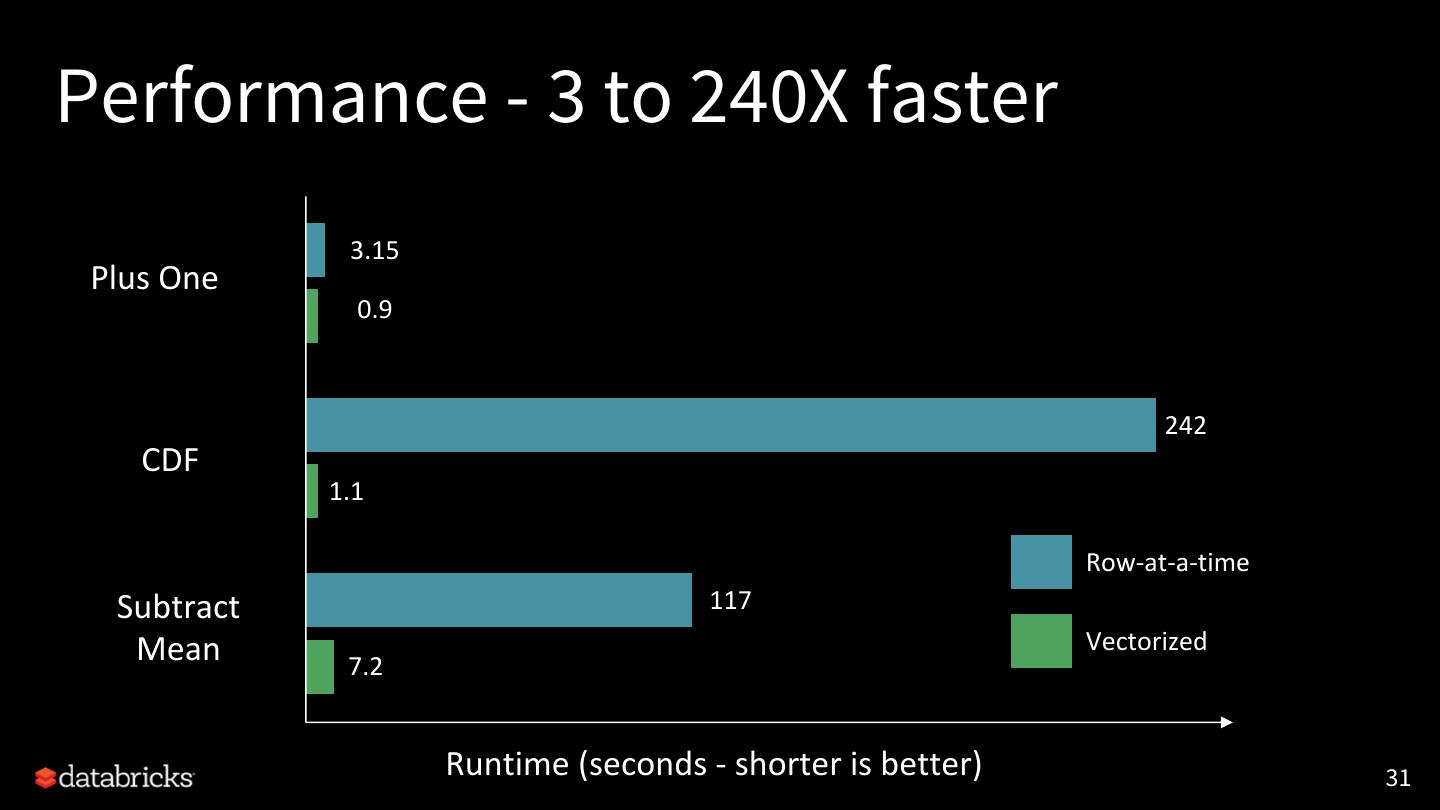
• Optimized Data Exchange: Model inference with PandasUDF
• Accelerator Aware Scheduling
• Conclusion
3
�
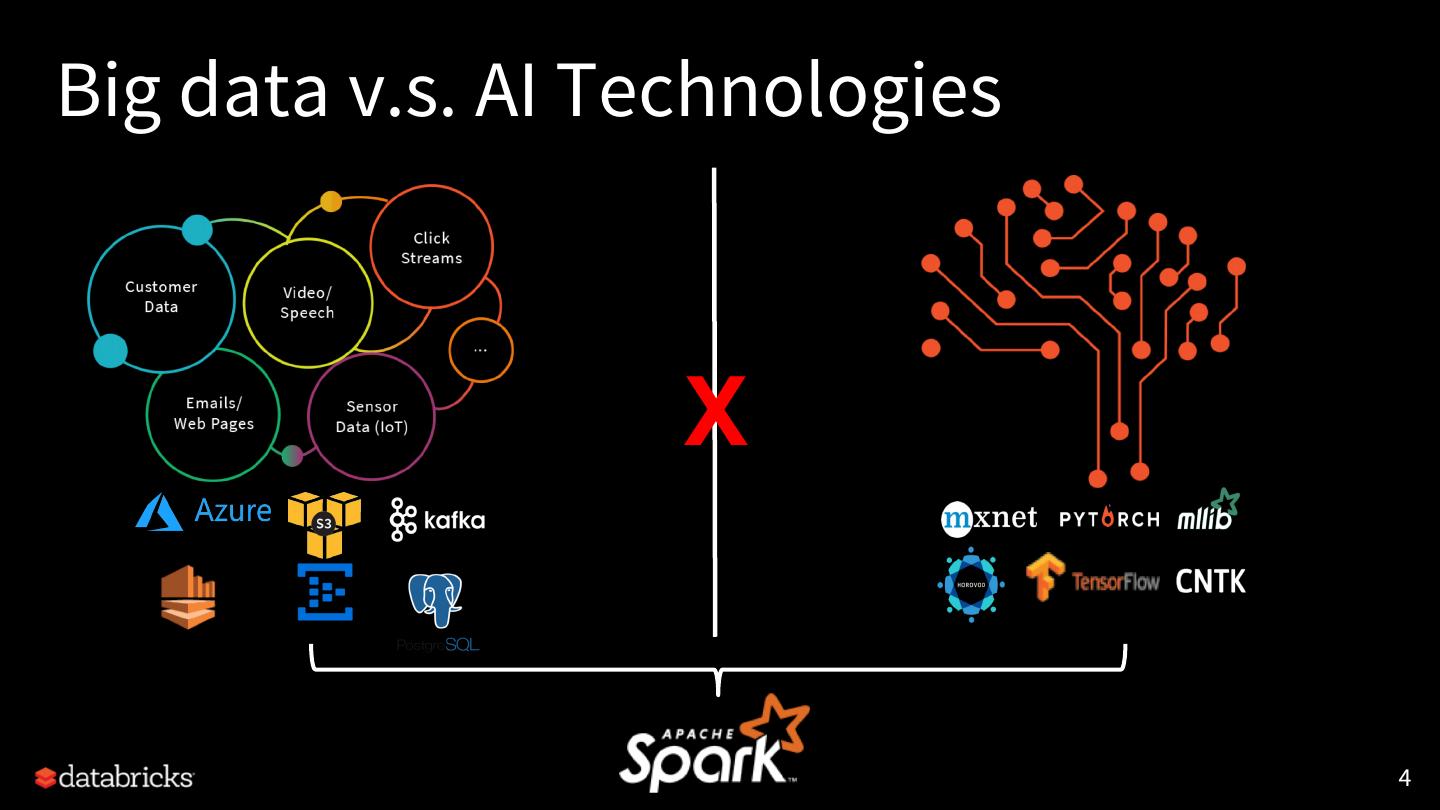
4 .Big data v.s. AI Technologies
X
4
�
5 .Big data for AI
There are many efforts from the Spark community to integrate
Spark with AI/ML frameworks:
● (Yahoo) CaffeOnSpark, TensorFlowOnSpark
● (John Snow Labs) Spark-NLP
● (Databricks) spark-sklearn, tensorframes, spark-deep-
learning
● … 80+ ML/AI packages on spark-packages.org
5
�
6 .AI needs big data
We have seen efforts from the DL libraries to handle different data
scenarios:
● tf.data, tf.estimator
● spark-tensorflow-connector
● torch.utils.data
● … ...
6
�
7 .The status quo: two simple stories
As a data scientist, I can:
● build a pipeline that fetches training events from a production
data warehouse and trains a DL model in parallel;
● apply a trained DL model to a distributed stream of events
and enrich it with predicted labels.
7
�
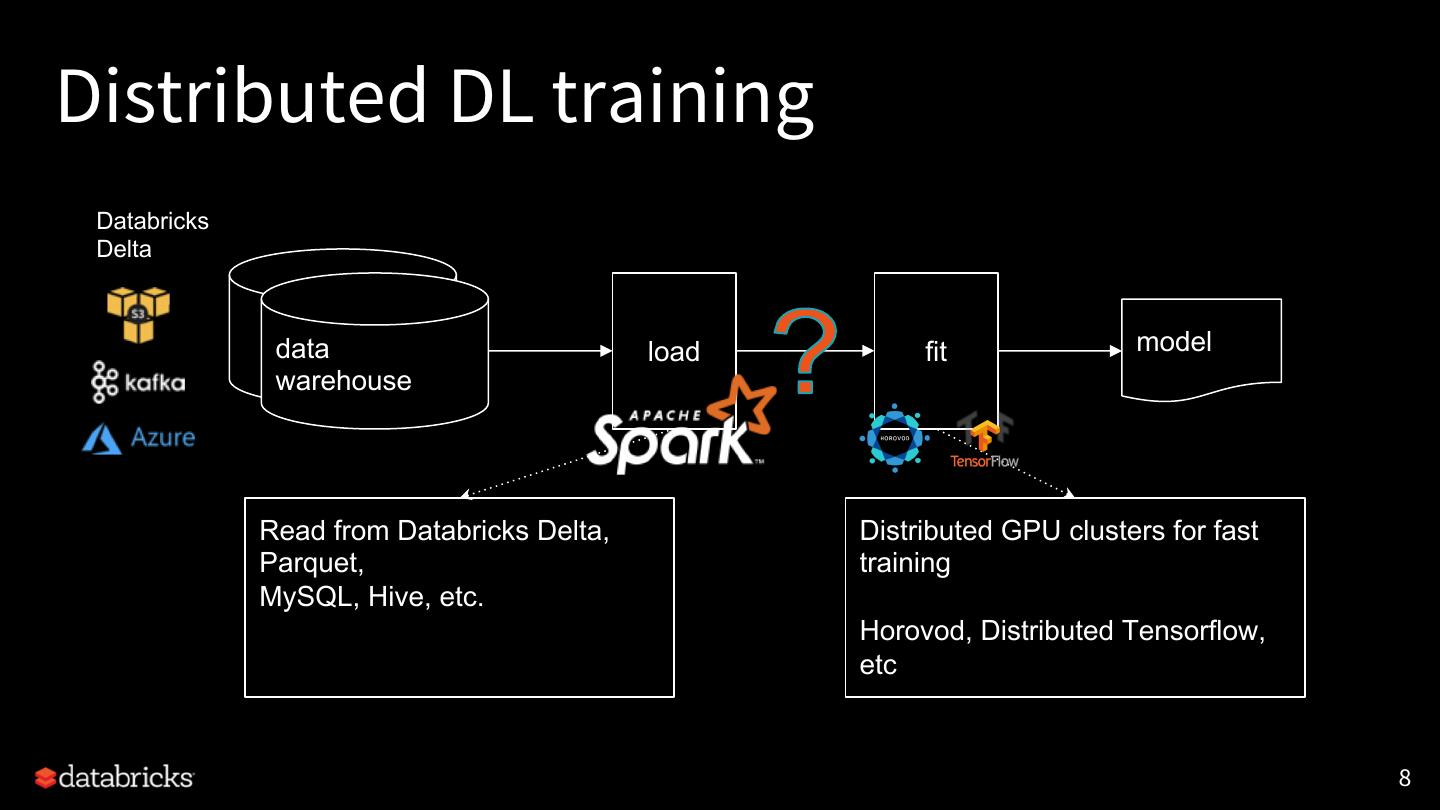
8 .Distributed DL training
Databricks
Delta
data load fit model
warehouse
Read from Databricks Delta, Distributed GPU clusters for fast
Parquet, training
MySQL, Hive, etc.
Horovod, Distributed Tensorflow,
etc
8
�
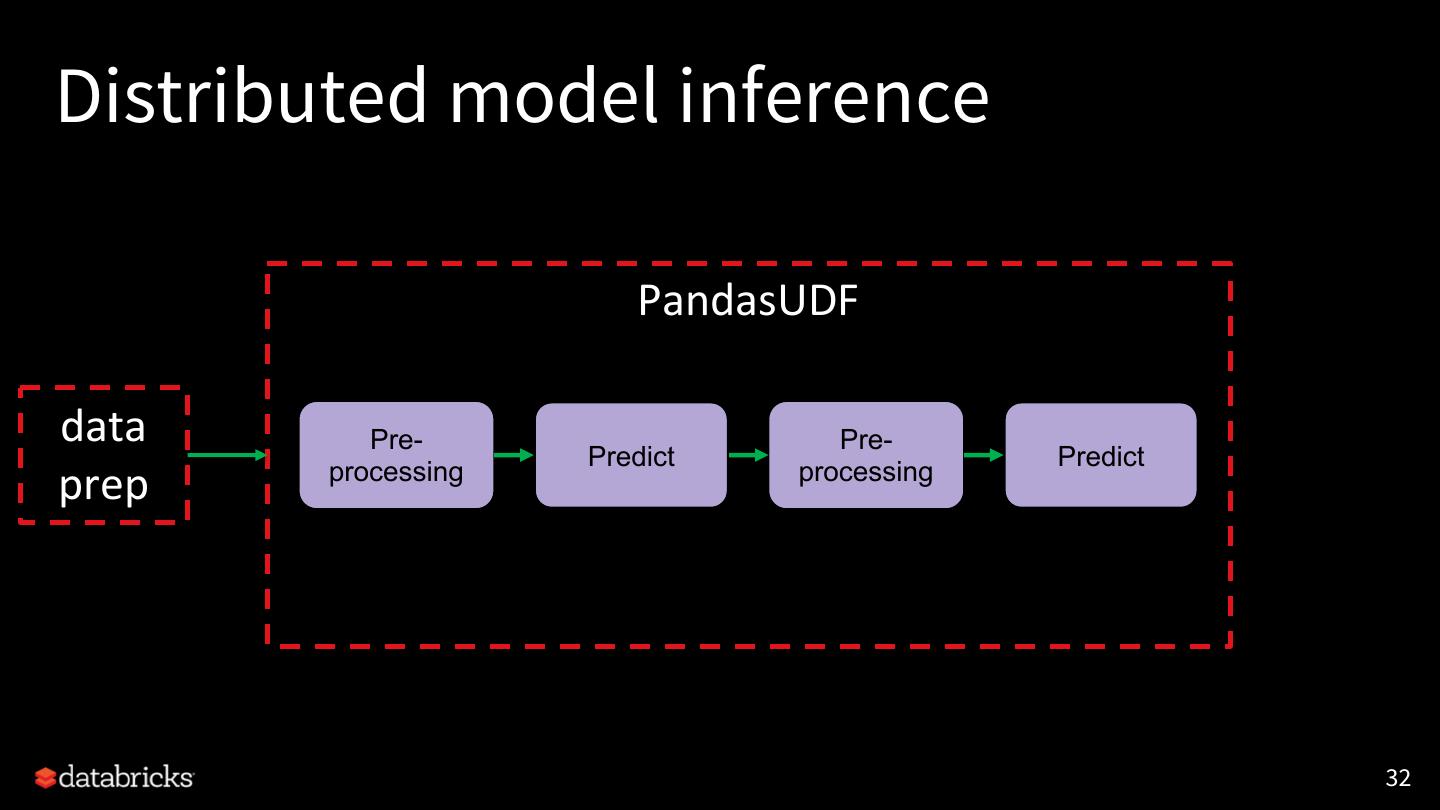
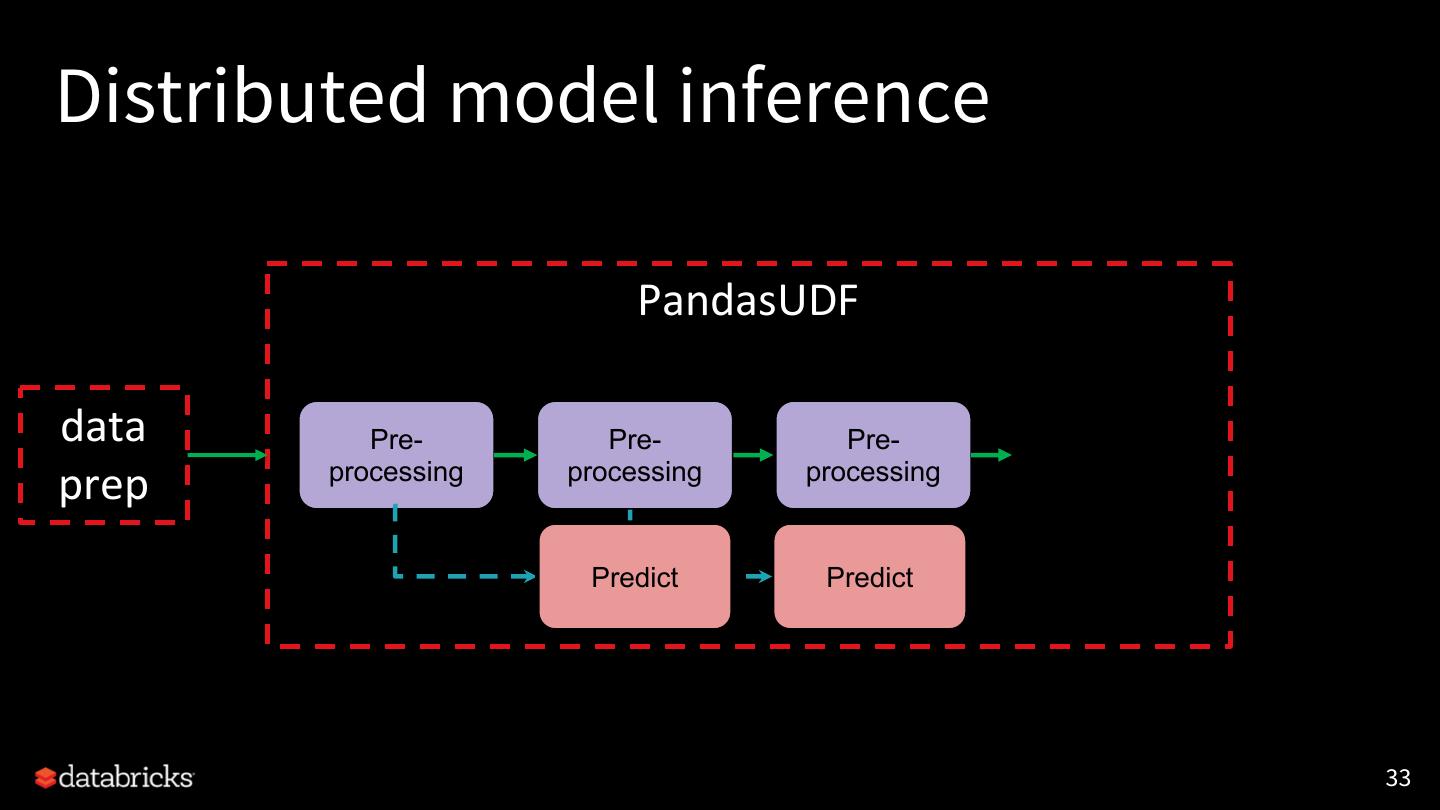
9 .Distributed model inference
data prep predict model
warehouse
● GPU for fast inference
9
�
10 .Two Challenges in Supporting AI
Frameworks in Spark
1 2
Execution mode: Data exchange:
fundamental incompatibility between need to push data in high
Spark (embarrassingly parallel) vs AI throughput between Spark and
frameworks (gang scheduled) Accelerated frameworks
10
�
11 .Project Hydrogen: Spark + AI
1 2
Execution mode: Data exchange:
Barrier Execution Mode Vectorized Data Exchange
Accelerator-aware
scheduling
11
�
12 .Project Hydrogen: Spark + AI
1 2
Execution mode: Data exchange:
Barrier Execution Mode Vectorized Data Exchange
Accelerator-aware
scheduling
12
�
13 .Different execution mode
Spark Task 1
Task 2
Tasks are independent of each other
Task 3
Embarrassingly parallel & massively scalable
Distributed Training
Complete coordination among tasks
Optimized for communication
13
�
14 .Different execution mode
Spark Task 1
Task 2
Tasks are independent of each other
Task 3
Embarrassingly parallel & massively scalable
If one crashes…
Distributed Training
Complete coordination among tasks
Optimized for communication
14
�
15 .Different execution mode
Spark Task 1
Task 2
Tasks are independent of each other
Task 3
Embarrassingly parallel & massively scalable
If one crashes, rerun that one
Distributed Training
Complete coordination among tasks
Optimized for communication
If one crashes, must rerun all tasks
15
�
16 .Barrier execution mode
We introduce gang scheduling to Spark on top of MapReduce
execution model. So a distributed DL job can run as a Spark job.
● It starts all tasks together.
● It provides sufficient info and tooling to run a hybrid distributed job.
● It cancels and restarts all tasks in case of failures.
16
�
17 .RDD.barrier()
RDD.barrier() tells Spark to launch the tasks together.
rdd.barrier().mapPartitions { iter =>
val context = BarrierTaskContext.get()
...
}
17
�
18 .context.barrier()
context.barrier() places a global barrier and waits until all tasks in
this stage hit this barrier.
val context = BarrierTaskContext.get()
… // write partition data out
context.barrier()
18
�
19 .context.getTaskInfos()
context.getTaskInfos() returns info about all tasks in this stage.
if (context.partitionId == 0) {
val addrs = context.getTaskInfos().map(_.address)
... // start a hybrid training job, e.g., via MPI
}
context.barrier() // wait until training finishes
19
�
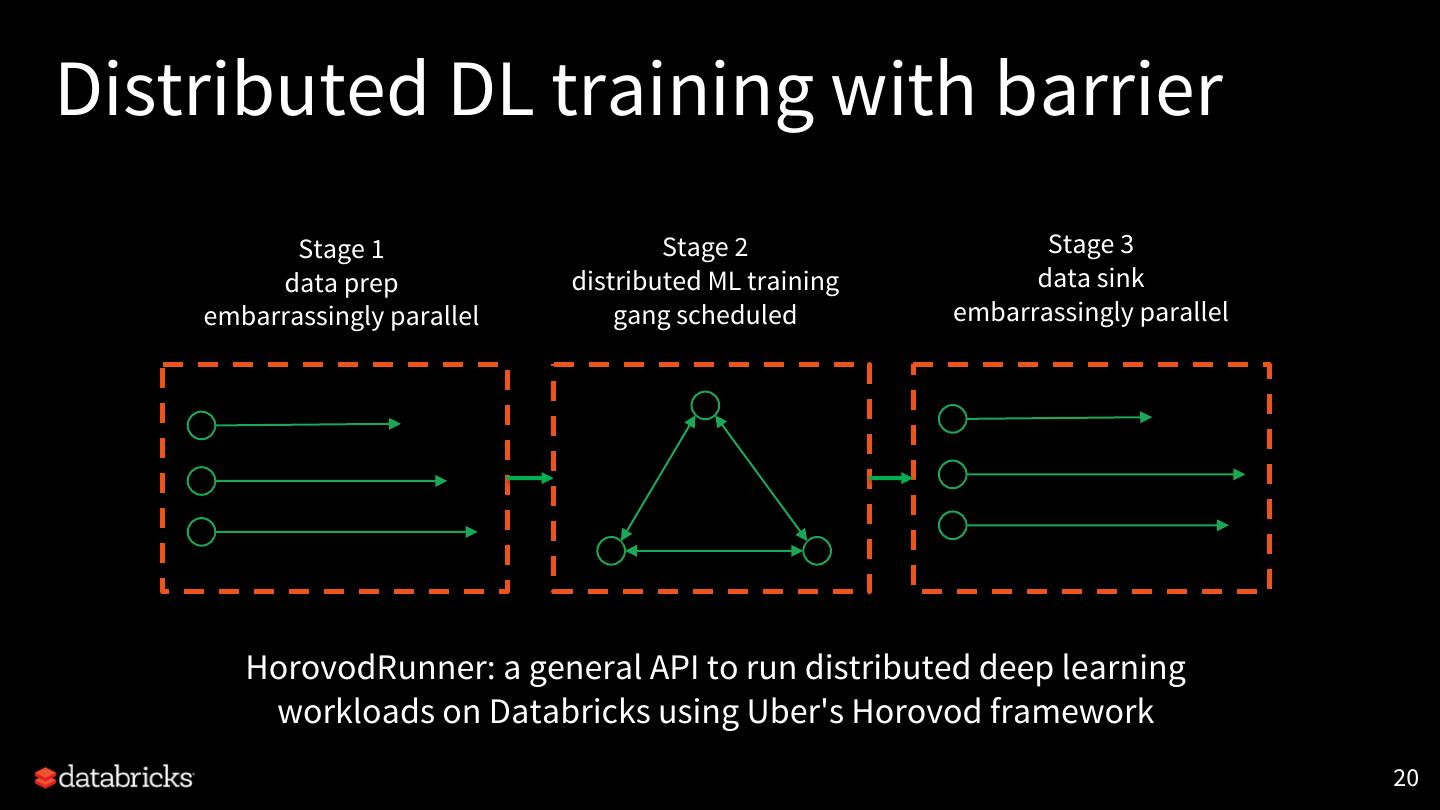
20 .Distributed DL training with barrier
Stage 1 Stage 2 Stage 3
data prep distributed ML training data sink
embarrassingly parallel gang scheduled embarrassingly parallel
HorovodRunner: a general API to run distributed deep learning
workloads on Databricks using Uber's Horovod framework
20
�
21 .Why start with Horovod?
Horovod is a distributed training framework developed at Uber
● Supports TensorFlow, Keras, and PyTorch
● Easy to use
■ Users only need to slightly modify single-node training code to use Horovod
● Horovod offers good scaling efficiency
21
�
22 .Why HorovodRunner?
HorovodRunner makes it easy to run Horovod on Databricks.
● Horovod runs an MPI job for distributed training, which is
hard to set up
● It is hard to schedule an MPI job on a Spark cluster
22
�
23 .HorovodRunner
The HorovodRunner API supports the following methods:
● init(self, np)
○ Create an instance of HorovodRunner.
● run(self, main, **kwargs)
○ Run a Horovod training job invoking main(**kwargs).
def train():
hvd.init()
hr = HorovodRunner(np=2)
hr.run(train)
23
�
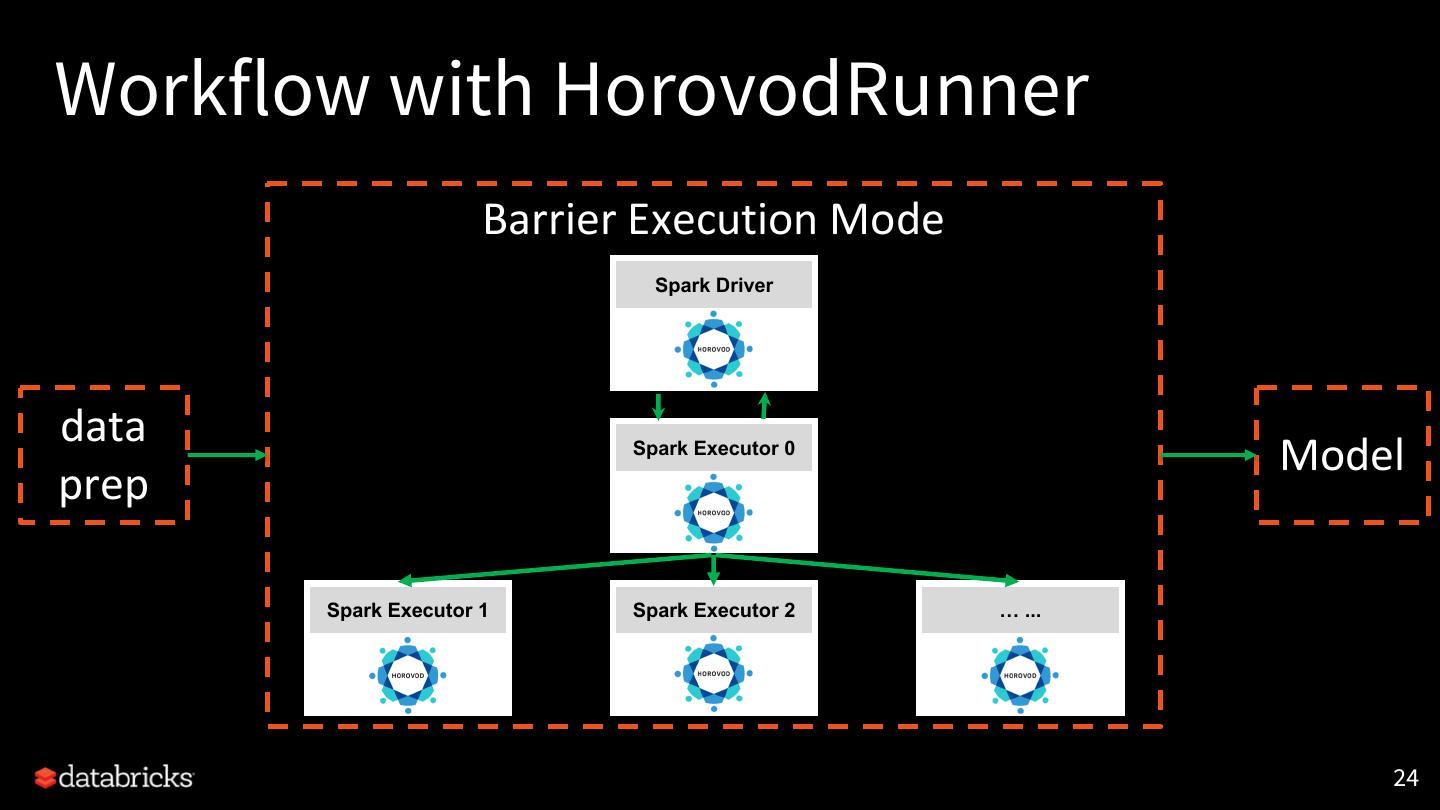
24 .Workflow with HorovodRunner
Barrier Execution Mode
Spark Driver
data Spark Executor 0
Model
prep
Spark Executor 1 Spark Executor 2 … ...
24
�
25 .Single-node to distributed
Development workflow for distributed DL training is as following
● Data preparation
● Prepare single node DL code
● Add Horovod hooks
● Run distributively with HorovodRunner
25
�
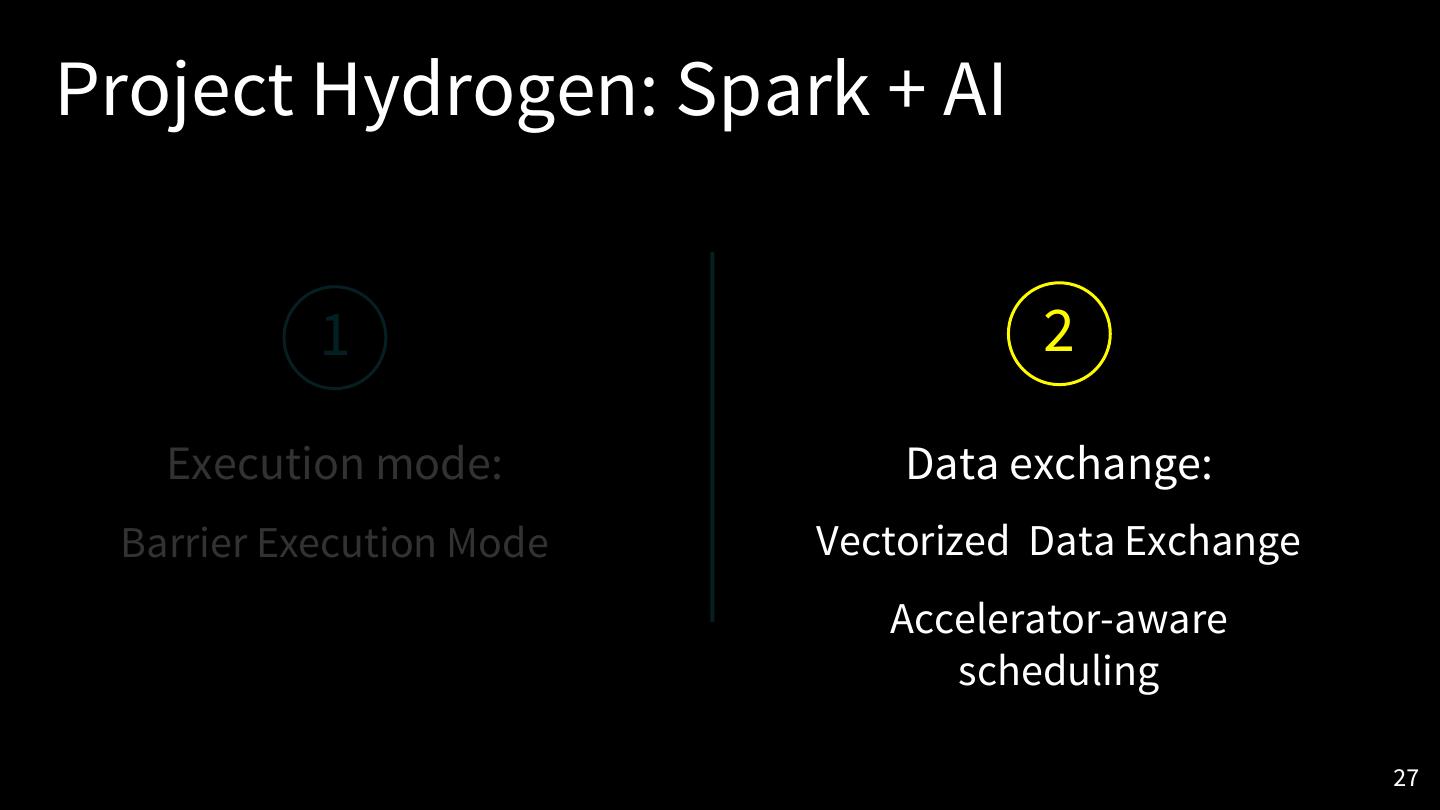
27 .Project Hydrogen: Spark + AI
1 2
Execution mode: Data exchange:
Barrier Execution Mode Vectorized Data Exchange
Accelerator-aware
scheduling
27
�
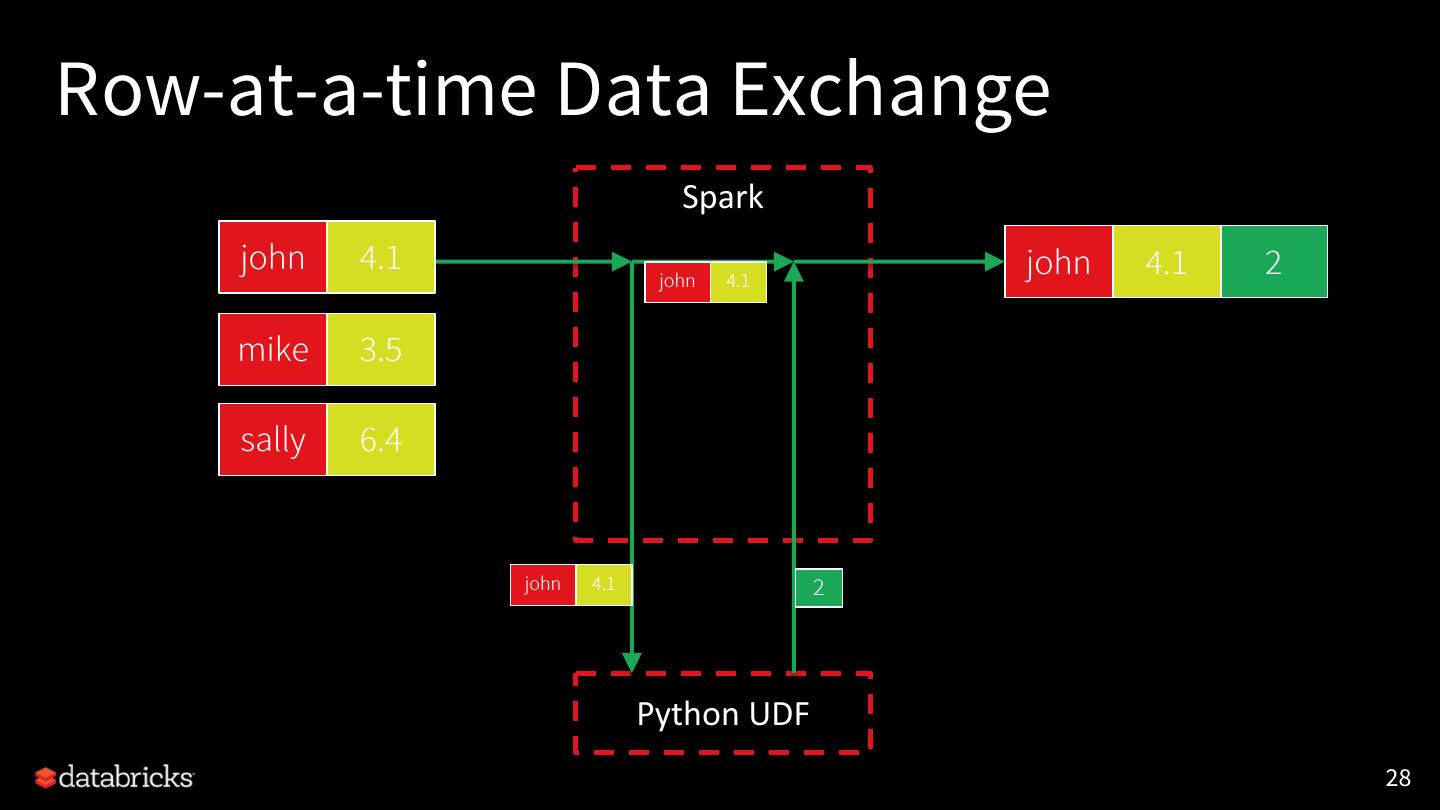
28 .Row-at-a-time Data Exchange
Spark
john 4.1 john 4.1 2
john 4.1
mike 3.5
sally 6.4
john 4.1 2
Python UDF
28
�
29 .Row-at-a-time Data Exchange
Spark
john 4.1
mike 3.5 mike 3.5
mike 3.5 3
sally 6.4
mike 3.5 3
Python UDF
29
�