


















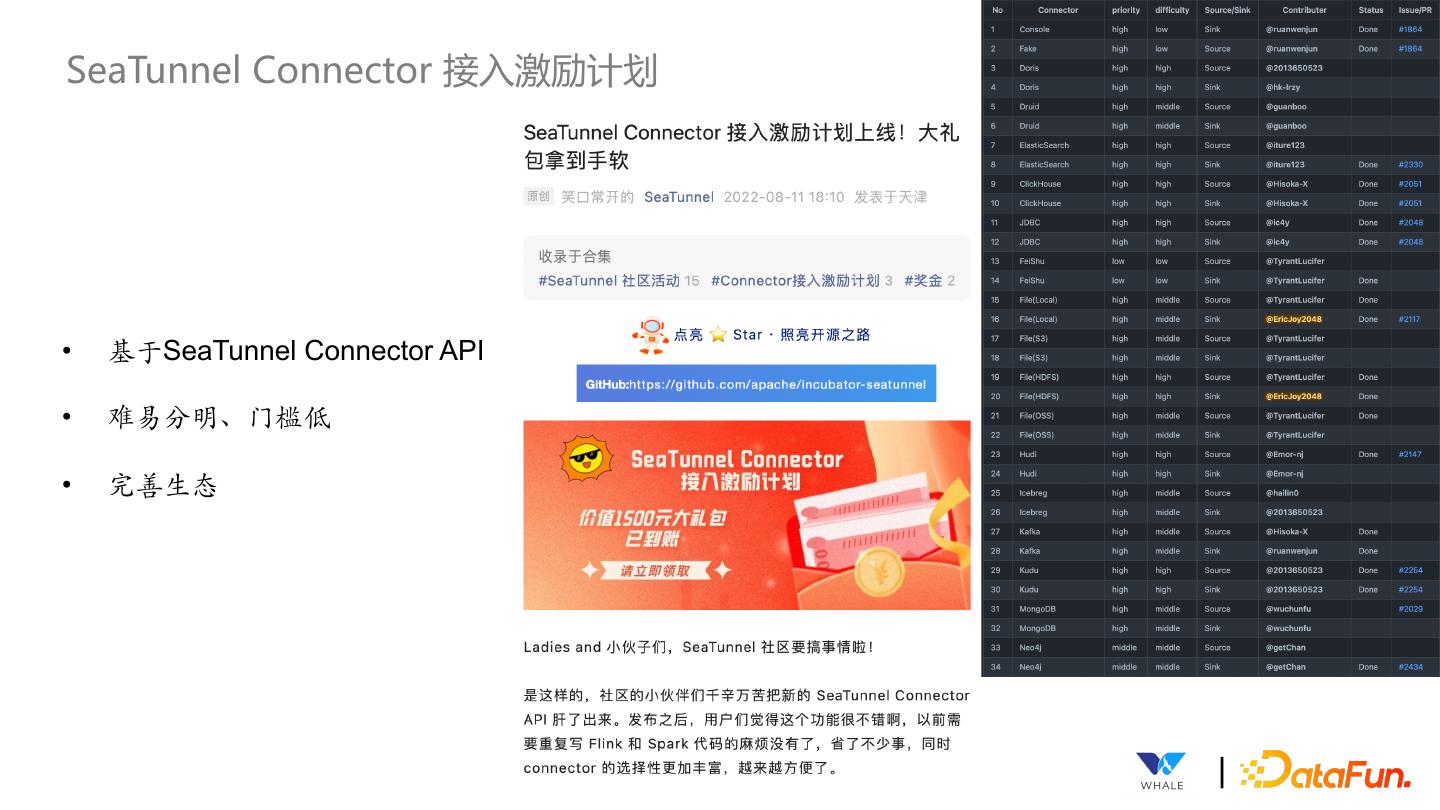
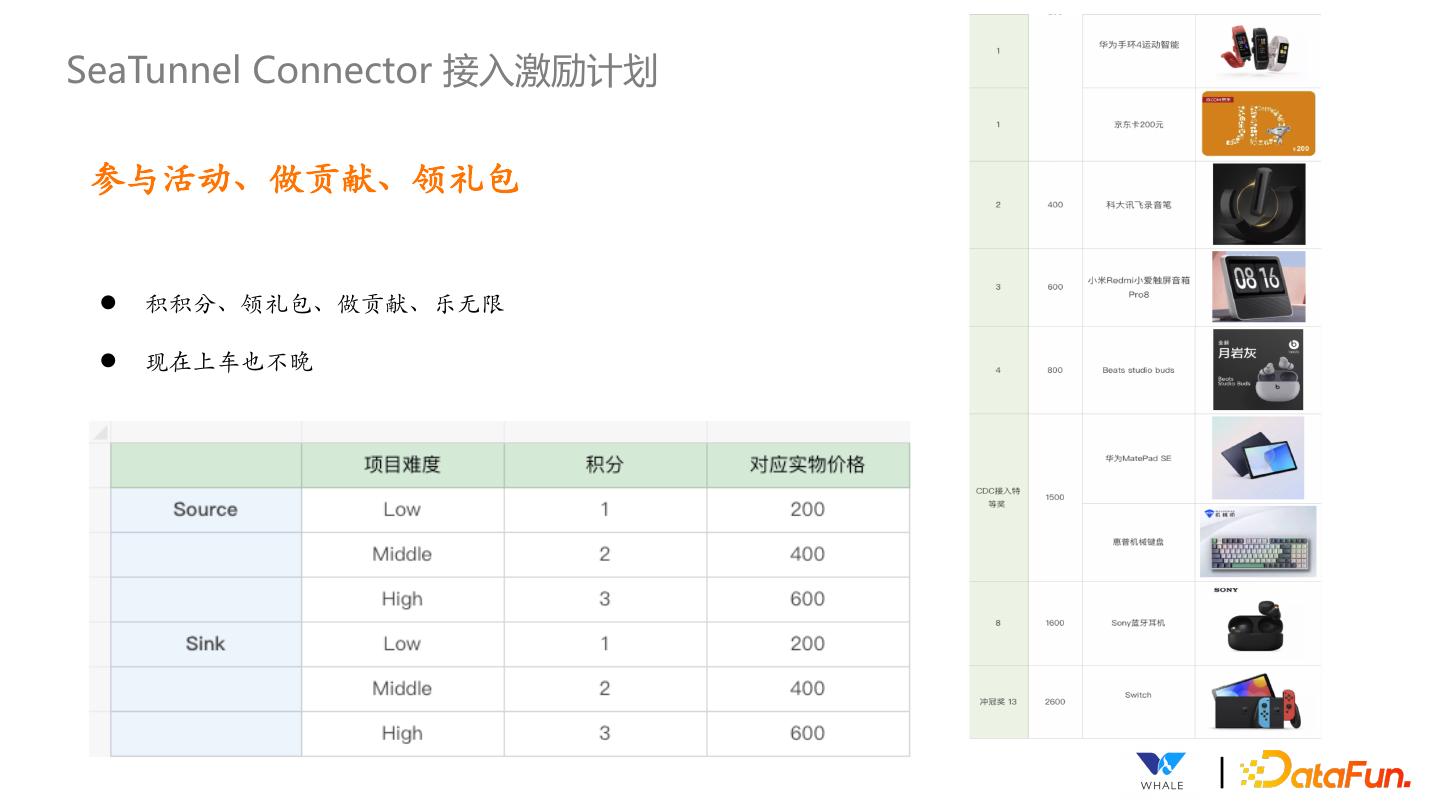



- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Seatunnel (incubator) 数 据 集成平台-高俊
展开查看详情
1 . | Apache Seatunnel ( incubator) 数 据 集 成 平 台 高俊 白鲸开源 架构师 |
2 .关于我 开源爱好者 10年大数据相关工作,主要从事大数据平台建设、OLAP引擎设 计研发工作。 开源爱好者,参与多个开源项目的贡献。 Apache DolphinScheduler PMC Apache SeaTunnel (incubator) Contributor Trino Contributor Apache Arrow-Datafusion Contributor 2
3 . 目录 CONTENT 01 SeaTunnel的设计目标 03 SeaTunnel整体设计 02 SeaTunnel现状 04 近期规划 05 Connector接入激励计划 |
4 . | 01 SeaTunnel设计目标 |
5 .SeaTunnel的设计目标 简单易用的,分布式可扩展的支持超⼤数据级的 ⾼吞吐低延时的数据集成平台。 数据源多,版本间不兼容,⽽ 离线同步和实时同步常被分开 且不断有新的出现 管理,维护困难 企业技术栈差异⼤,导致选择 同步组件时需要更多的学习成 数据同步需要⾼吞吐低时延, 本。 数据⼀致性要求⾼。 |
6 . | 02 SeaTunnel现状 |
7 .SeaTunnel现状——连接器数量 支持的连接器有50+ 支持数据源Source 支持目标端Sink 20+ 支持Transform 10+ 20+ |
8 .SeaTunnel现状——流批一体 • 流批⼀体 • 只需要实现 ⼀个连接器 • 适配纯流和 微批 支持离线同步和实时同步两种⽅式 同⼀个连接器,只需要在env配置中指定job.mode为BATCH或STREAMING即可轻 松切换离线和实时同步两种模式。 |
9 .SeaTunnel现状——多引擎支持 多引擎支持 SeaTunnel多引擎支持为了更好的兼容企业已有的技术⽣态,降低使用 SeaTunnel的技术成本. 已经支持的引擎 Flink Spark SeaTunnel Engine 支持多个版本的Flink引擎,完美支 支持Spark微批处理模式,支持聚 专为数据同步场景设计的引擎,还在开发中。 SeaTunnel内部引擎,为那些没有⼤数据⽣态的 持Flink的Checkpoint流程 合提交特性 企业或追求数据同步最佳体验的用户提供可选⽅ 案 …… …… …… |
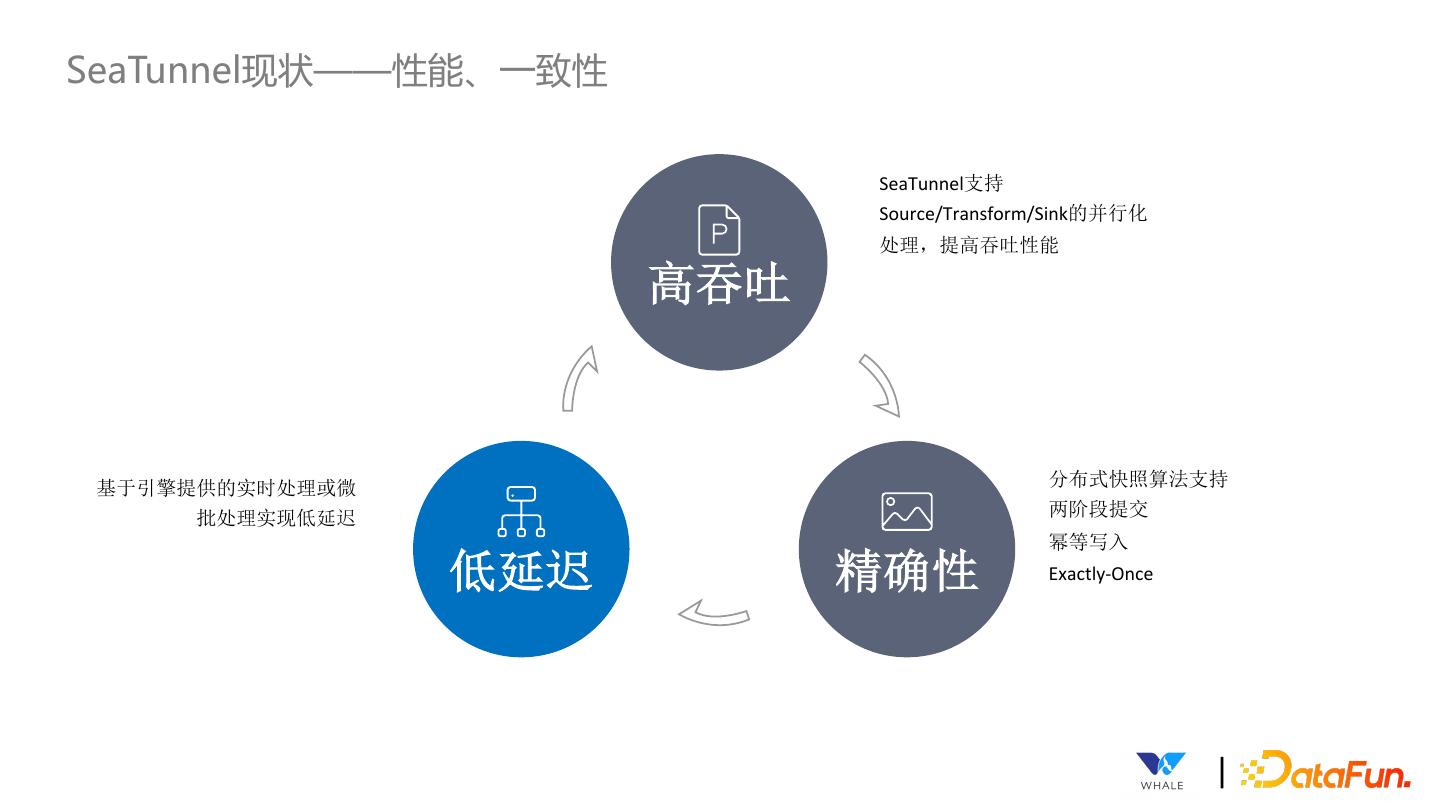
10 .SeaTunnel现状——性能、一致性 SeaTunnel支持 Source/Transform/Sink的并行化 处理,提高吞吐性能 高吞吐 基于引擎提供的实时处理或微 分布式快照算法支持 批处理实现低延迟 两阶段提交 幂等写入 低延迟 精确性 Exactly-Once |
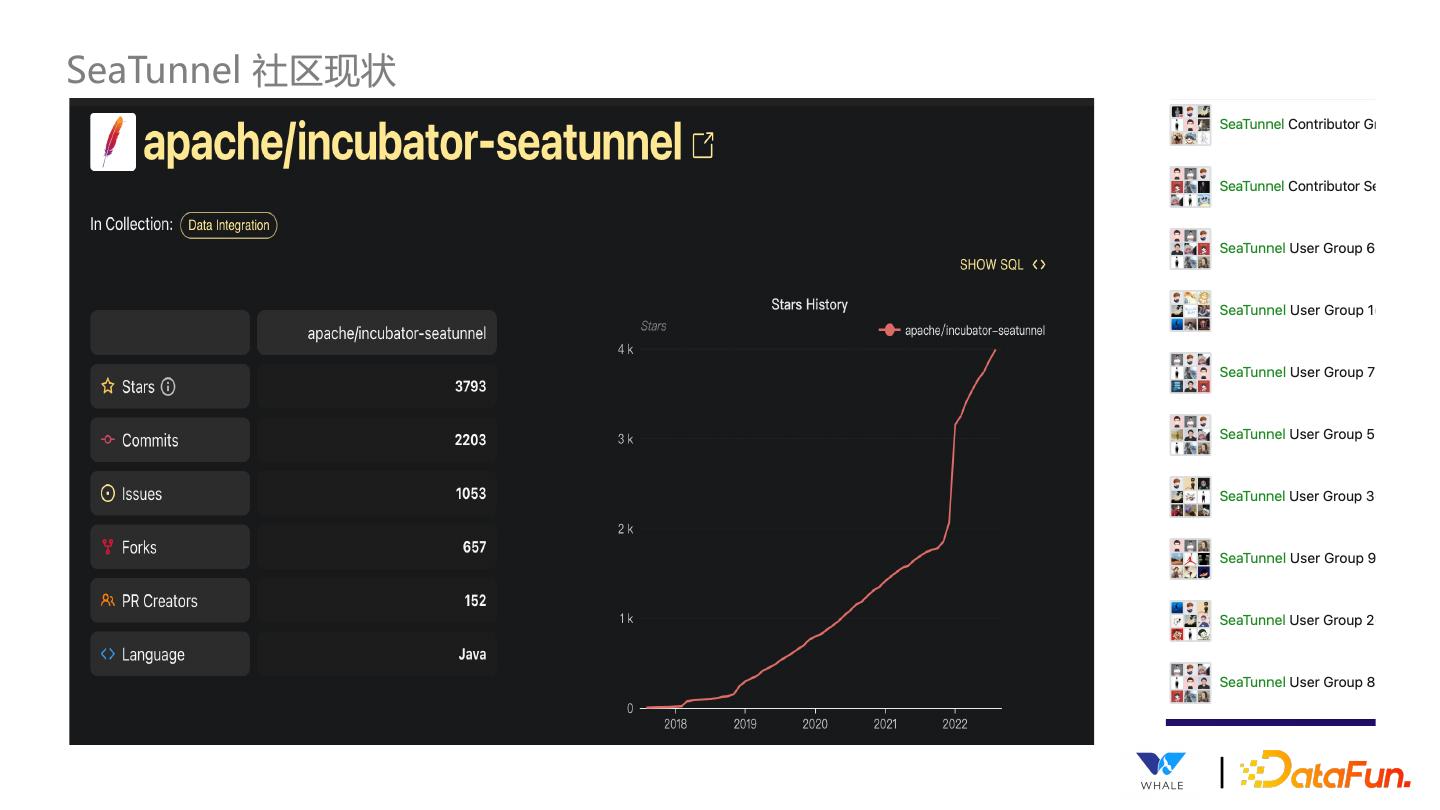
11 .SeaTunnel 社区现状 |
12 .SeaTunnel 用户 |
13 . | 03 SeaTunnel整体设计 |
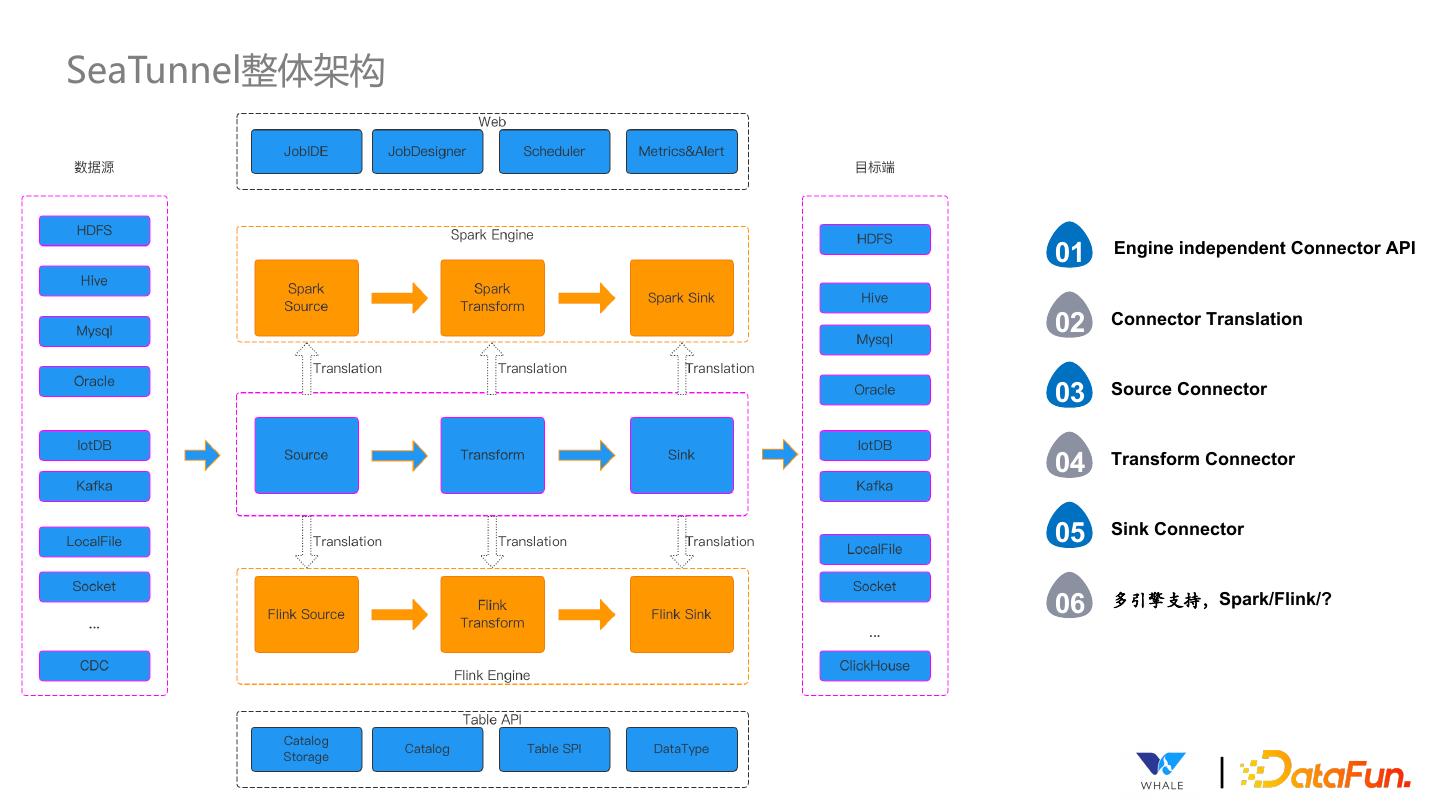
14 .SeaTunnel整体架构 01 Engine independent Connector API 02 Connector Translation 03 Source Connector 04 Transform Connector 05 Sink Connector 06 多引擎支持,Spark/Flink/? |
15 .SeaTunnel 使用方式 |
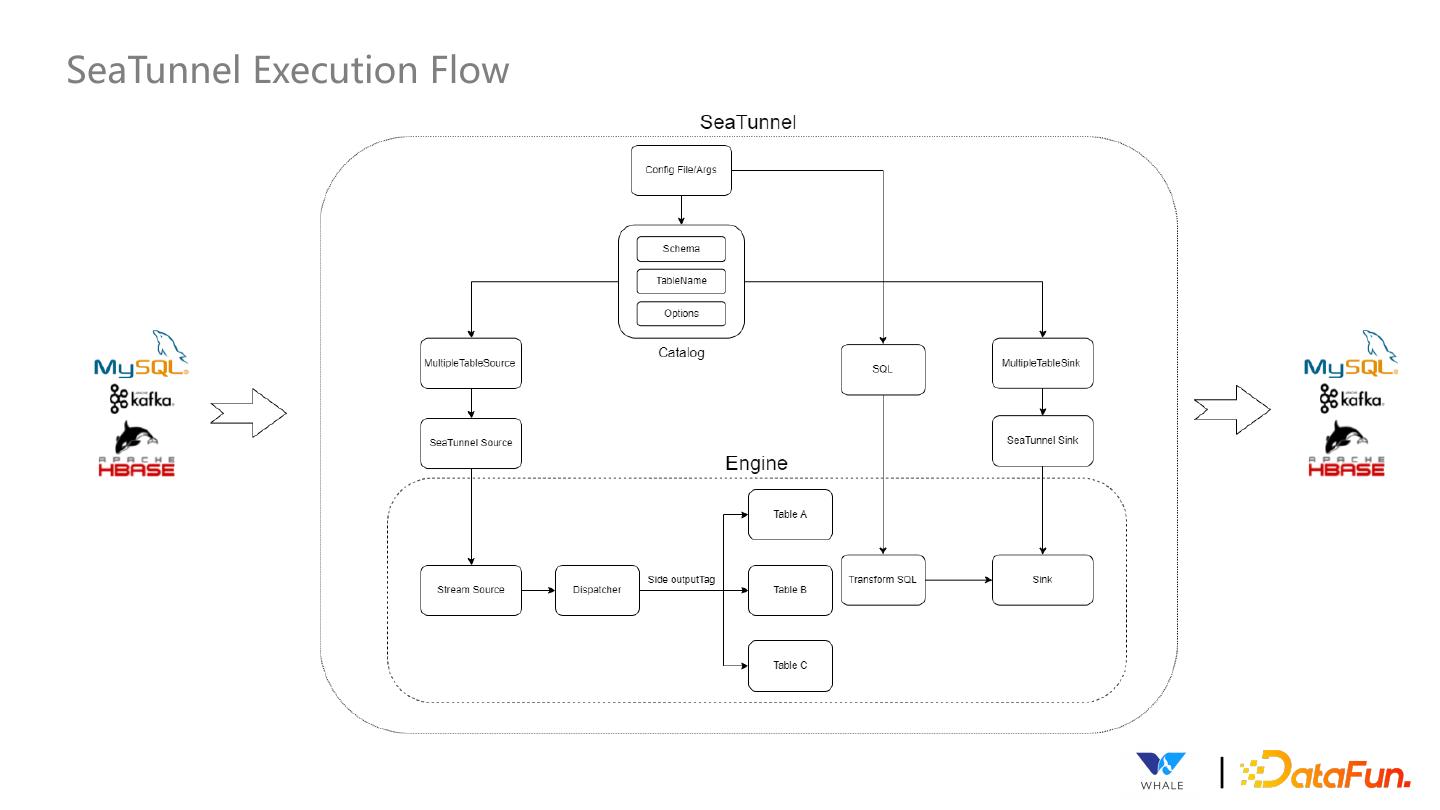
16 .SeaTunnel Execution Flow |
17 .SeaTunnel Connector Flow |
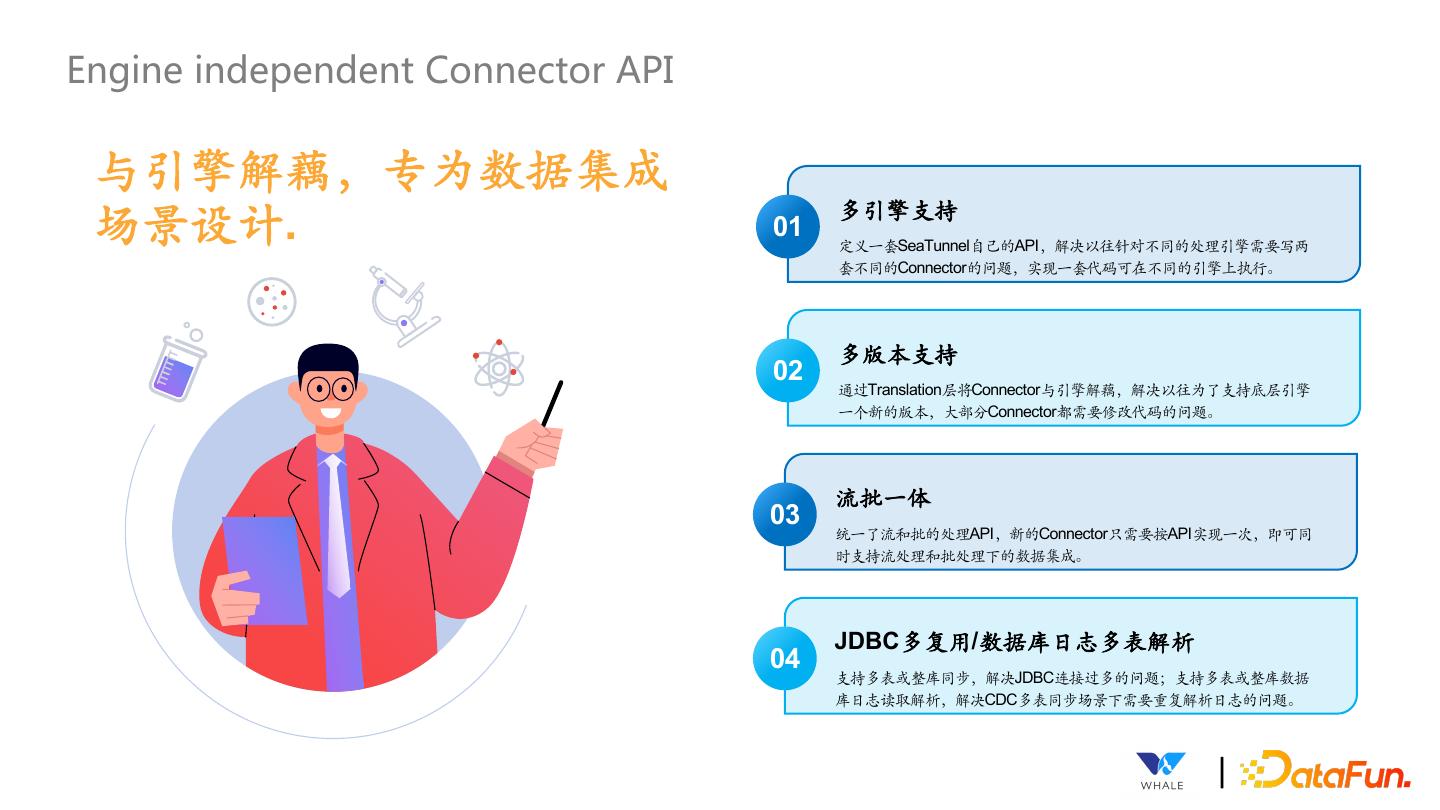
18 .Engine independent Connector API 与引擎解藕,专为数据集成 场景设计. 01 多引擎支持 定义⼀套SeaTunnel自⼰的API,解决以往针对不同的处理引擎需要写两 套不同的Connector的问题,实现⼀套代码可在不同的引擎上执⾏。 多版本支持 02 通过Translation层将Connector与引擎解藕,解决以往为了支持底层引擎 ⼀个新的版本,⼤部分Connector都需要修改代码的问题。 流批⼀体 03 统⼀了流和批的处理API,新的Connector只需要按API实现⼀次,即可同 时支持流处理和批处理下的数据集成。 JDBC多复用/数据库日志多表解析 04 支持多表或整库同步,解决JDBC连接过多的问题;支持多表或整库数据 库日志读取解析,解决CDC多表同步场景下需要重复解析日志的问题。 |
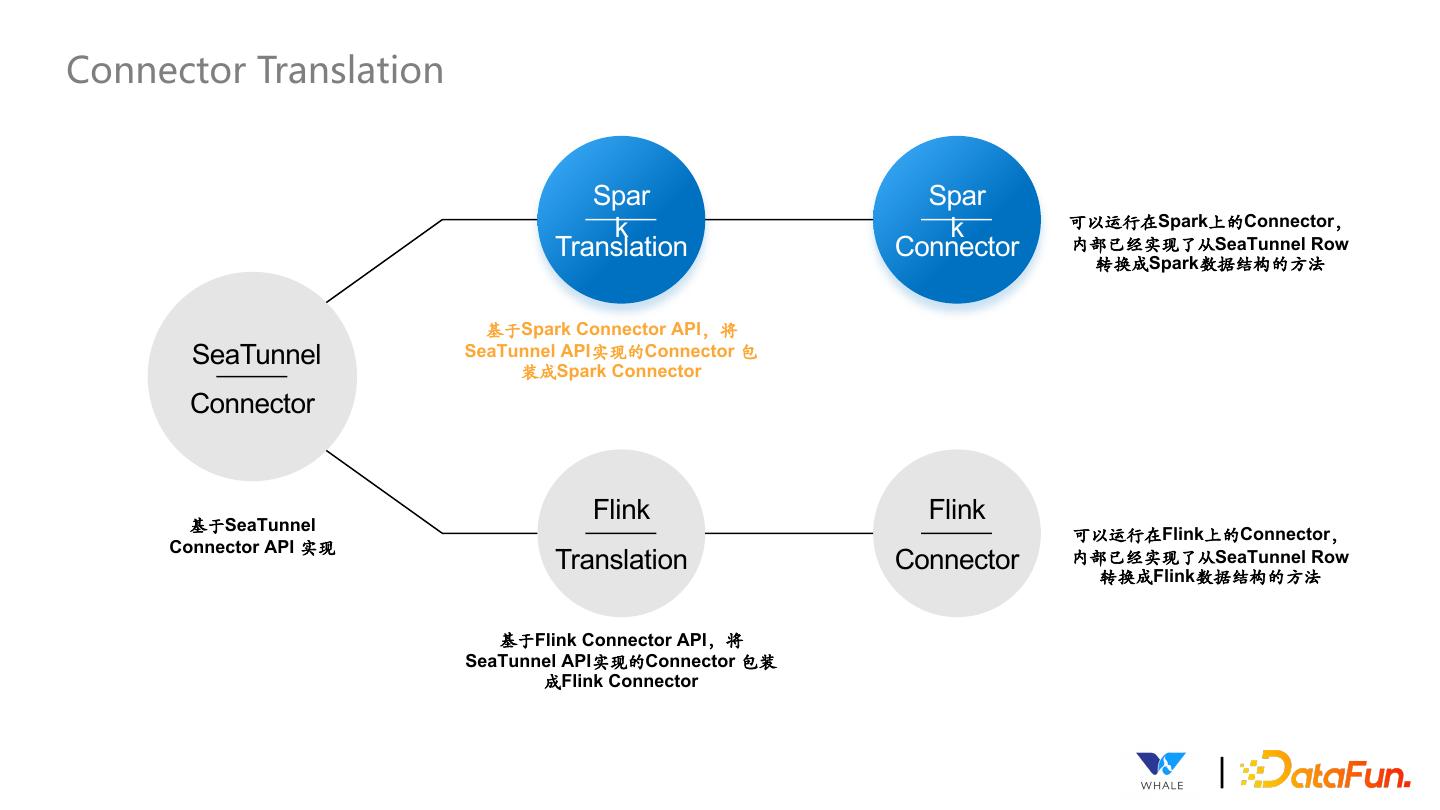
19 .Connector Translation Spar Spar 可以运⾏在Spark上的Connector, k k Translation Connector 内部已经实现了从SeaTunnel Row 转换成Spark数据结构的⽅法 基于Spark Connector API,将 SeaTunnel SeaTunnel API实现的Connector 包 装成Spark Connector Connector 基于SeaTunnel Flink Flink 可以运⾏在Flink上的Connector, Connector API 实现 Translation Connector 内部已经实现了从SeaTunnel Row 转换成Flink数据结构的⽅法 基于Flink Connector API,将 SeaTunnel API实现的Connector 包装 成Flink Connector |
20 .Source API 统一离线与实时API Boundedness 支持并行读取 SourceReader & Source Split Keyword Keyword 支持动态发现分片 Source Split & Enumerator Source特性 Source API 支持协调读取 SupportCoordinate &SourceEvent 支持状态存储、恢复 snapshotState |
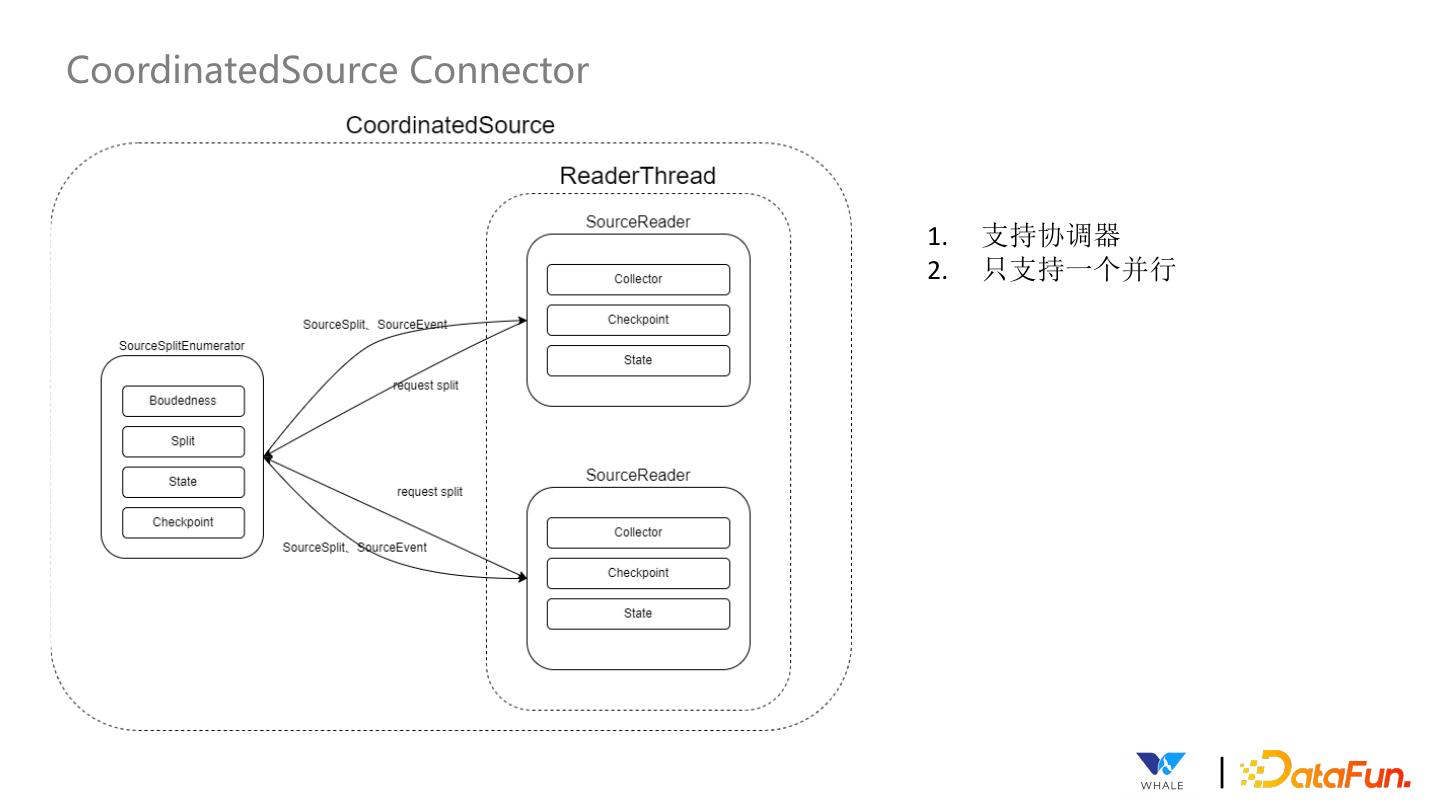
21 .CoordinatedSource Connector 1. 支持协调器 2. 只支持一个并行 |
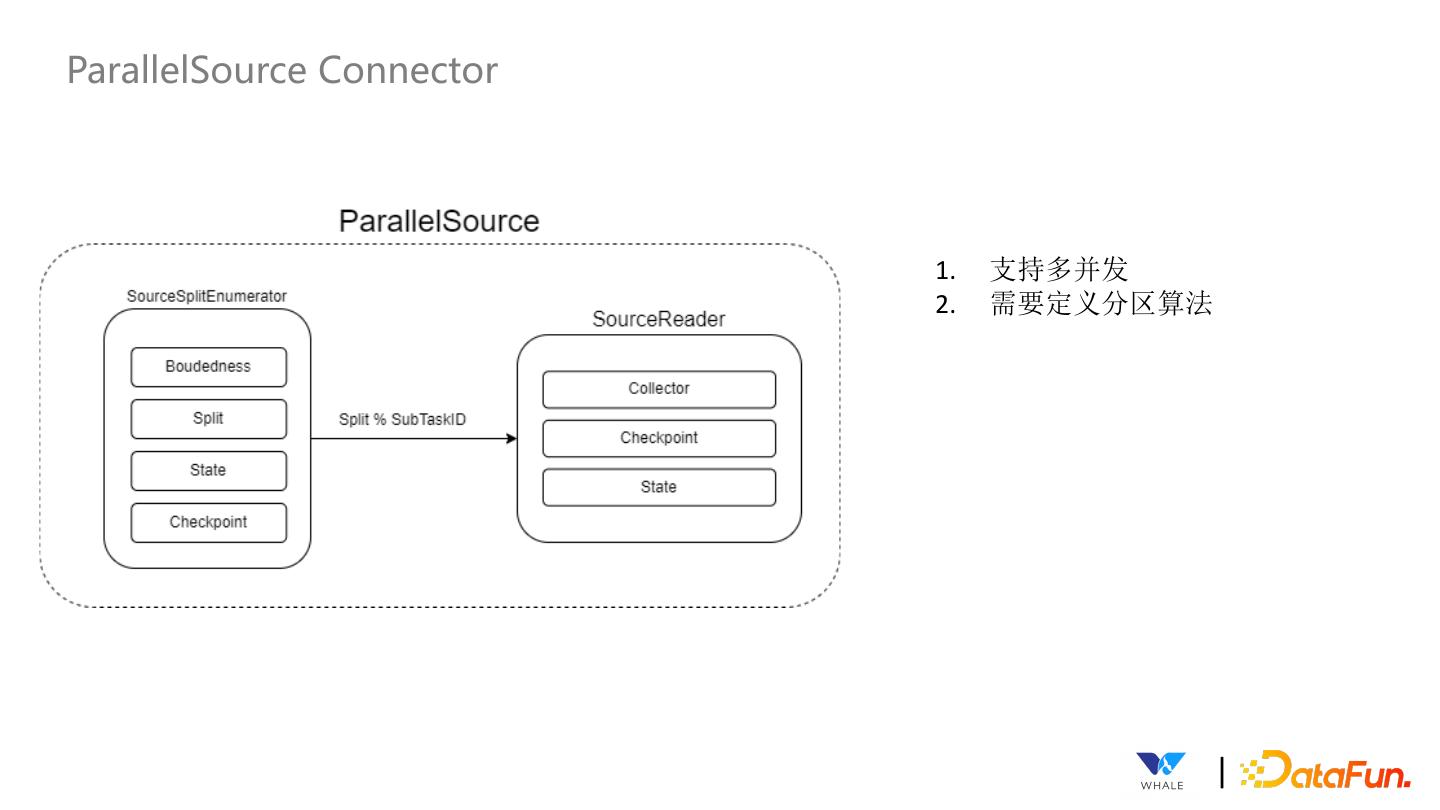
22 .ParallelSource Connector 1. 支持多并发 2. 需要定义分区算法 |
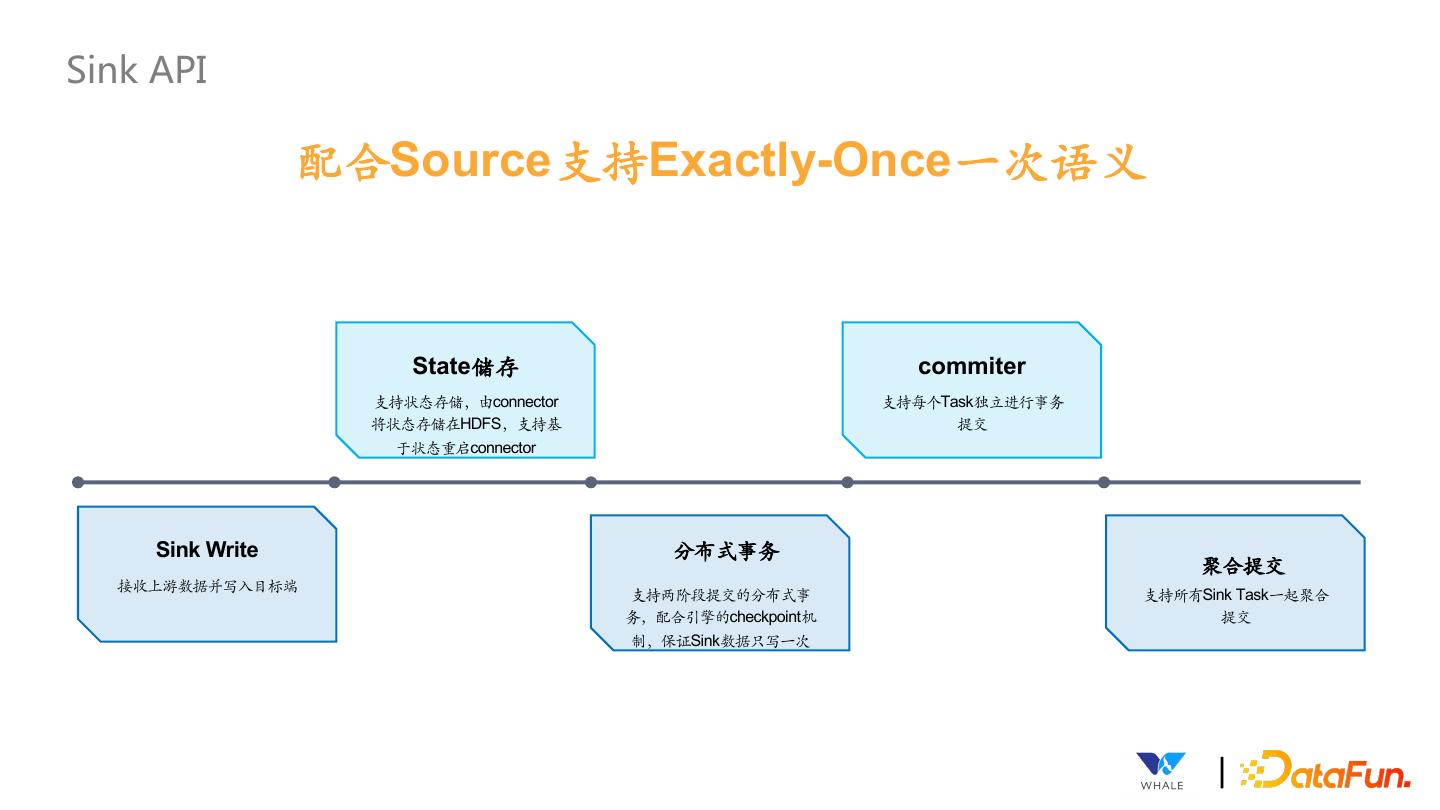
23 .Sink API 配合Source支持Exactly-Once⼀次语义 State储存 commiter 支持状态存储,由connector 支持每个Task独立进⾏事务 将状态存储在HDFS,支持基 提交 于状态重启connector Sink Write 分布式事务 聚合提交 接收上游数据并写⼊目标端 支持两阶段提交的分布式事 支持所有Sink Task⼀起聚合 务,配合引擎的checkpoint机 提交 制,保证Sink数据只写⼀次 |
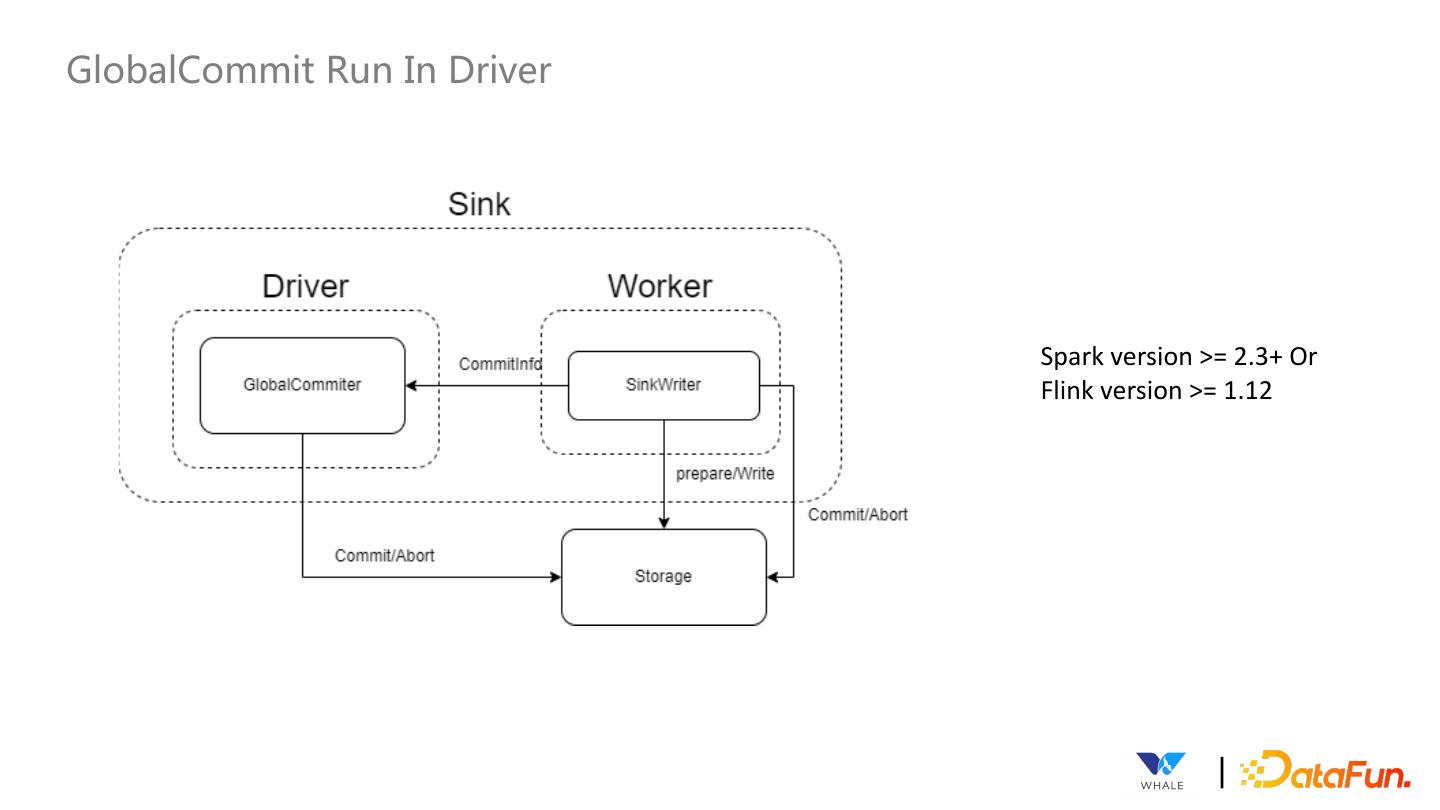
24 .GlobalCommit Run In Driver Spark version >= 2.3+ Or Flink version >= 1.12 |
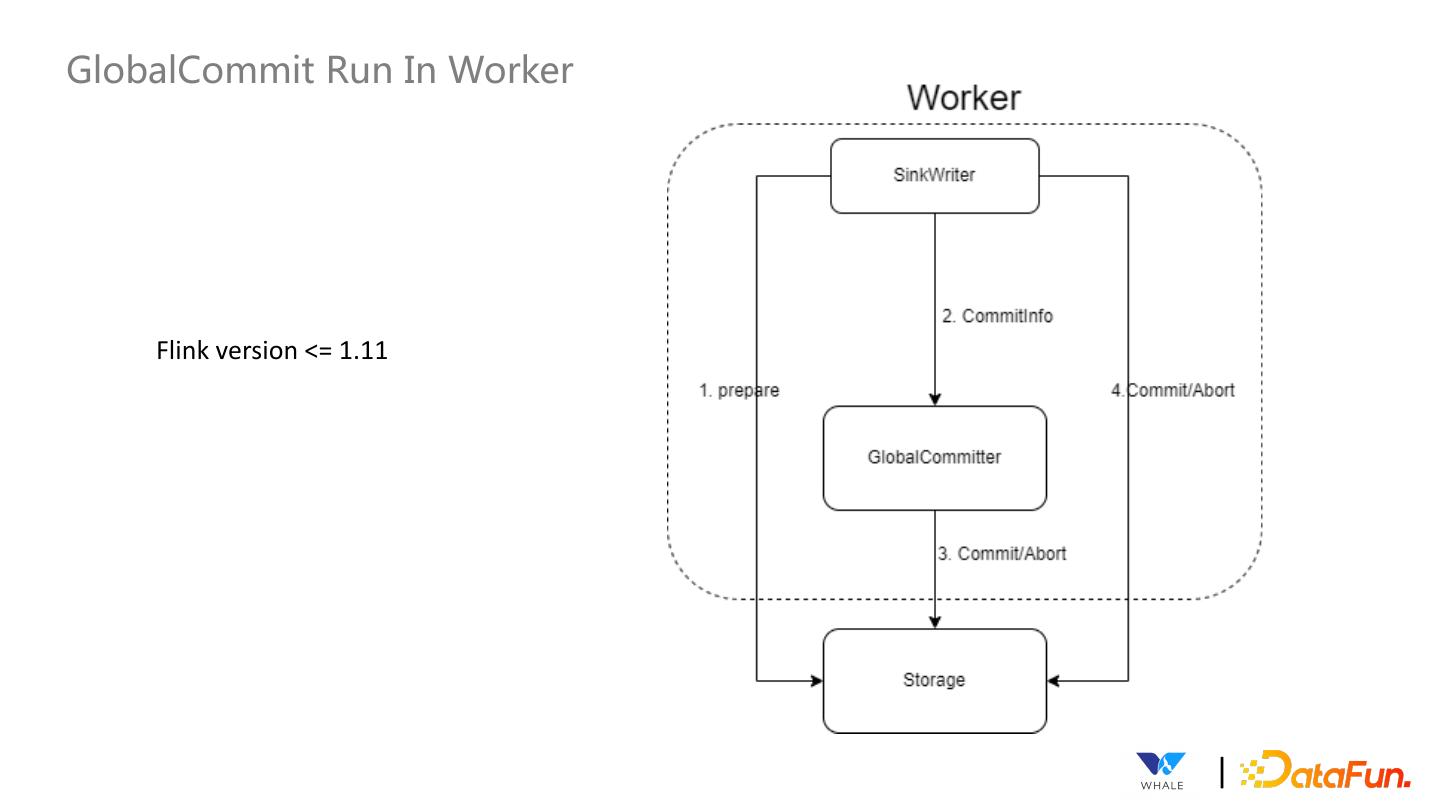
25 .GlobalCommit Run In Worker Flink version <= 1.11 |
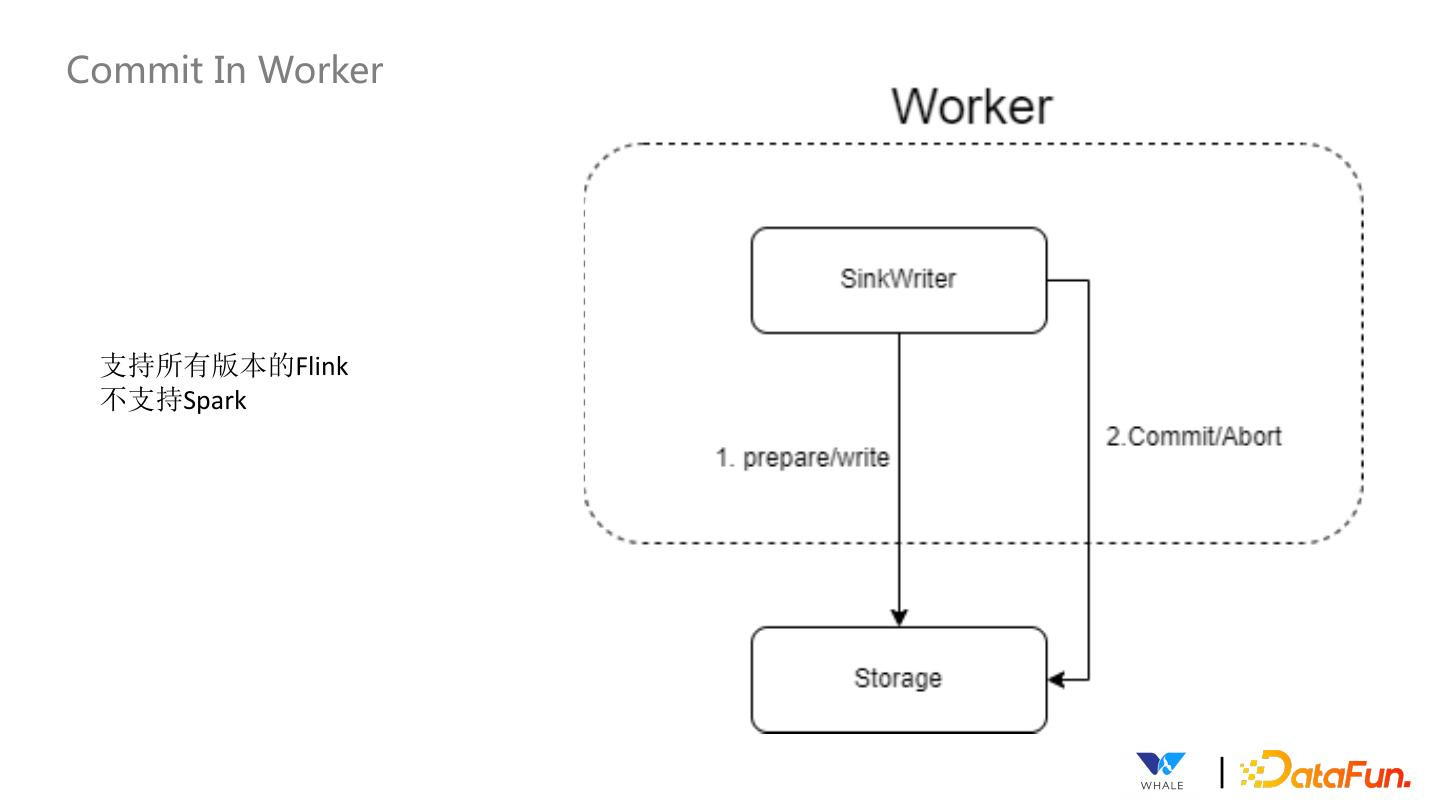
26 .Commit In Worker 支持所有版本的Flink 不支持Spark |
27 .SeaTunnel Table & Catalog API 面向应用的API,简化同步作业配置, 提供可视化作业配置的基础 数据源管 元数据获 数据类型定 连接器创 理 取 义 建 SeaTunnel定义了⼀套API来 支持获取数据源的表结构 由于需要支持多引擎,所有 SeaTunnel提供了⼀套API用 支持创建数据源插件,基于 (库名、表名、字段名、字 连接器中都使用SeaTunnel 于创建自动获取信息创建 SPI实现后即可集成该数据 段类型等),⽅便可视化的 的格式,在Connector Source,Sink等实例。 源的配置、连接测试⼯作。 配置同步作业的源和目标端 Translation会转换为对应引 的表名映射,字段映射等。 擎的格式。 |
28 . | 04 SeaTunnel近期规划 |
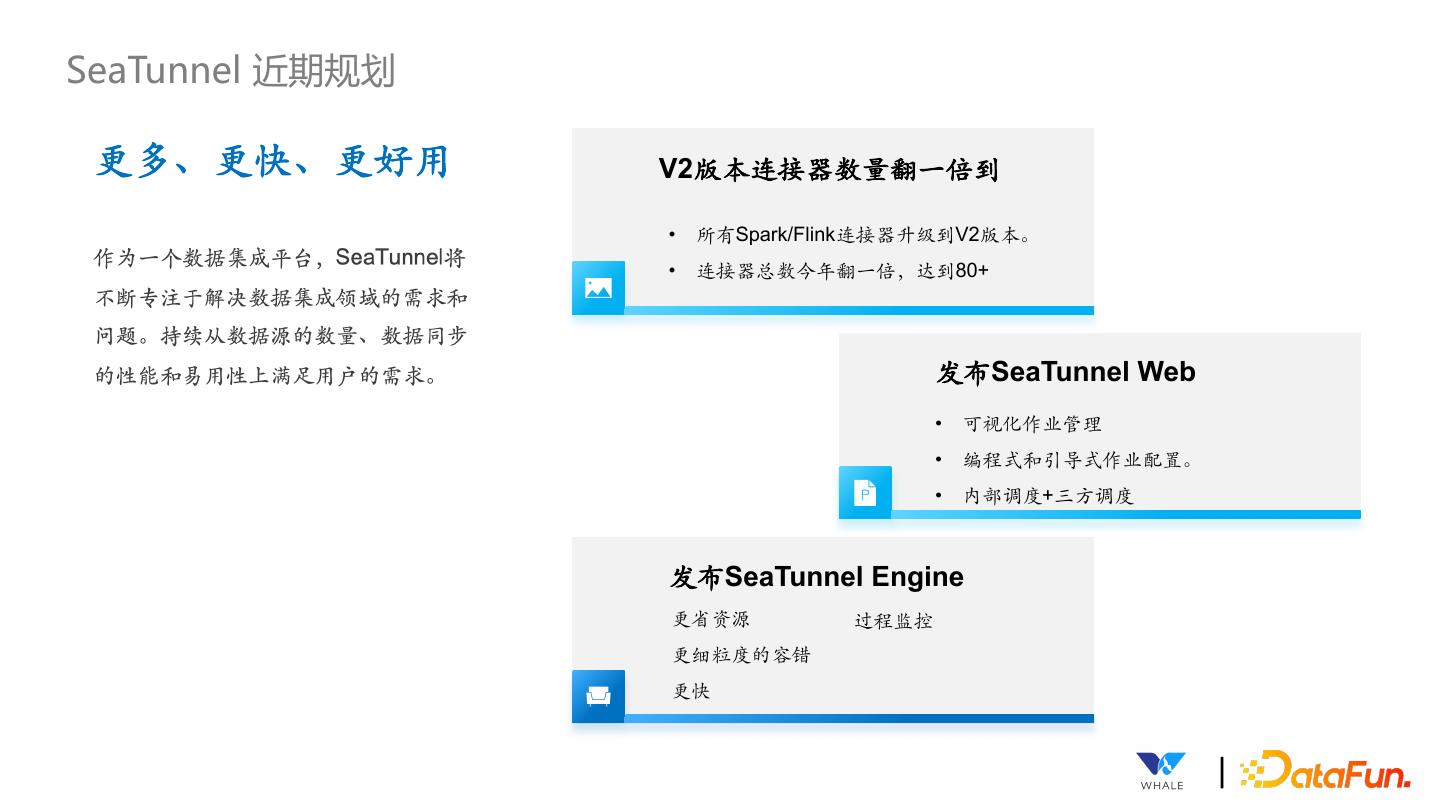
29 .SeaTunnel 近期规划 更多、更快、更好用 V2版本连接器数量翻⼀倍到 • 所有Spark/Flink连接器升级到V2版本。 • 连接器总数今年翻⼀倍,达到80+ 发布SeaTunnel Web • 可视化作业管理 • 编程式和引导式作业配置。 • 内部调度+三⽅调度 发布SeaTunnel Engine 更省资源 过程监控 更细粒度的容错 更快 |
3秒后跳转登录页面
去登陆

