展开查看详情
1 .SeaTunnel 连接器V1到V2
的架构演进与探究
从底层API角度探究SeaTunnel运行原理
田超 tyrantlucifer SeaTunnel Contributor
2022.08.27
�
2 . 01 连接器V1架构探究
02 连接器V1运行原理解析
03 连接器V2架构探究
CONTENT 04 连接器V2运行原理解析
05 连接器V1和V2架构对比
06 SeaTunnel未来展望
07 如何快速参与贡献
�
4 .SeaTunnel核心理念
整个Seatunnel设计的核心是利用设计模式中的“控制翻转”或者叫“依赖注入”,主要概括为以下两点:
1. 上层不依赖底层,两者都依赖抽象
2. 流程代码与业务逻辑应该分离
对于整个数据处理过程,大致可以分为以下几个流程:输入 -> 转换 -> 输出,对于更复杂的数据处理,实
质上也是这几种行为的组合:
input transform output
input
transform output
input
�
5 .SeaTunnel内核原理
SeaTunnel将数据处理的各种行为抽象成Plugin,并使用Java SPI技术进行动态注册,设计思路保证了框
架的灵活扩展,在以上理论基础上,数据的转换与处理还需要做统一的抽象,譬如比较有名异构数据源同
步工具DataX,也同样对数据单条记录做了统一抽象。
在SeaTunnel V1架构体系中,由于背靠Spark和Flink两大分布式计算框架,框架已经为我们做好了数据源
抽象的工作,Flink的DataStream、Spark的DataStream已经是对接入数据源的高度抽象,在此基础上我
们只需要在插件中处理这些数据抽象即可,同时借助于Flink和Spark提供的SQL接口,还可以将每一次处
理完的数据注册成表,方便用SQL进行处理,减少代码的开发量。
实际上SeaTunnel最后的目的是自动生成一个Spark或者一个Flink作业,并提交到集群中运行。
�
6 .SeaTunnel连接器V1 API解析
目前在项目dev分支下,SeaTunnel连接器V1 API所在的模块如图所示:
seatunnel-api-base 基础API抽象
seatunnel-api-flink Flink 插件API抽象
seatunnel-api-spark Spark 插件API抽象
�
11 .SeaTunnel连接器V1 相关模块
seatunnel-core-base V1 基础启动模块
seatunnel-core-flink V1 flink启动模块
seatunnel-core-flink-sql V1 flink-sql启动模块
seatunnel-core-spark V1 spark启动模块
�
12 .SeaTunnel连接器V1 Spark 执行流程
�
13 .SeaTunnel连接器V1 执行原理
Source插件接入数据源为DataFrame
Transform插件转换DataFrame
Sink插件将DataFrame写入数据源
�
15 .SeaTunnel连接器V2 API相关模块
目前在项目dev分支下,SeaTunnel连接器V2 API所在的模块如图所示:
seatunnel-api connector v2 all apis
�
16 .SeaTunnel连接器V2 API数据抽象
SeaTunnel 连接器V2对数据做了统一的抽象,在所
有的Source连接器和Sink连接器中,处理的都是
SeaTunnelRow类型数据,同时SeaTunnel也对内设
置了数据类型规范,所有通过Source接入进来的数据
会被对应的连接器转化为SeaTunnelRow送到下游
�
17 .SeaTunnel连接器V2 API Common
PluginIdentifierInterface 插件唯一标识
SeaTunnelContext SeaTunnel应用上下文
SeaTunnelPluginLifeCycle SeaTunnel插件生命周期
�
18 .SeaTunnel连接器V2 API Source
类名 作用
Boundedness 标注数据有界无界
Collector 数据收集器
SeaTunnelSource Source插件基类
SourceReader Source插件真正接入数据的类
SourceSplit Source分片
SourceSplitEnumerator Source分片器
�
19 .SeaTunnel连接器V2 API Sink
类名 作用
SeaTunnelSink Sink插件基类
SinkAggregatedCommitter 用于处理SinkWriter#prepareCommit返回的数据
信息,包含需要提交的事务信息等,但是会在单
个节点一起处理,这样可以避免阶段二部分失败
导致状态不一致的问题。
SinkCommitter 用于处理SinkWriter#prepareCommit返回的数据
信息,包含需要提交的事务信息
SinkWriter Sink插件真正写入数据的类
�
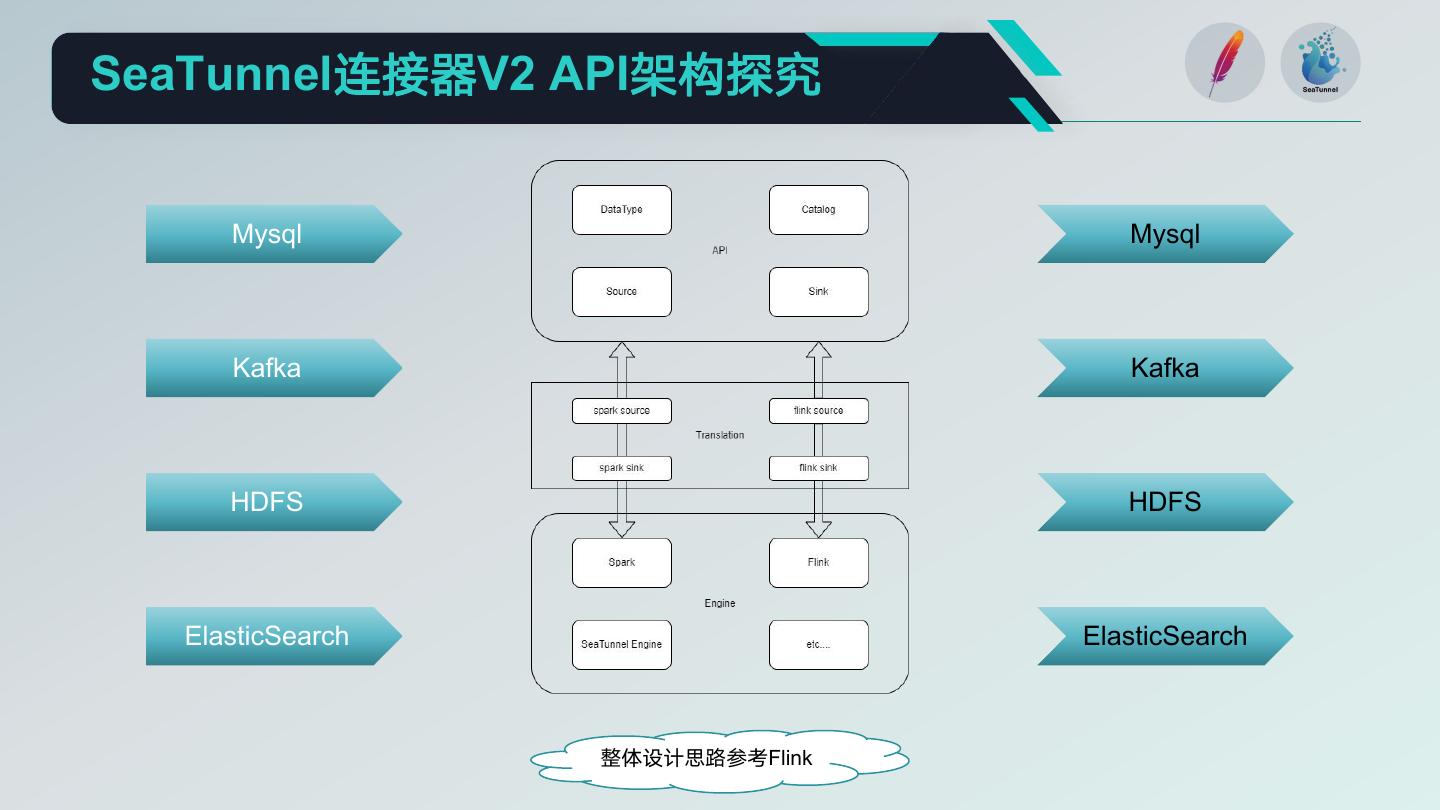
20 .SeaTunnel连接器V2 API架构探究
Mysql Mysql
Kafka Kafka
HDFS HDFS
ElasticSearch ElasticSearch
整体设计思路参考Flink
�
22 .SeaTunnel连接器V2 API Spark
Spark DataSource API V2
https://www.databricks.com/session/apache-spark-data-source-v2
�
23 .SeaTunnel连接器V2 API Flink
Flink Source API Flink Sink API
https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/datastream/sources/#the-data-source-api
�
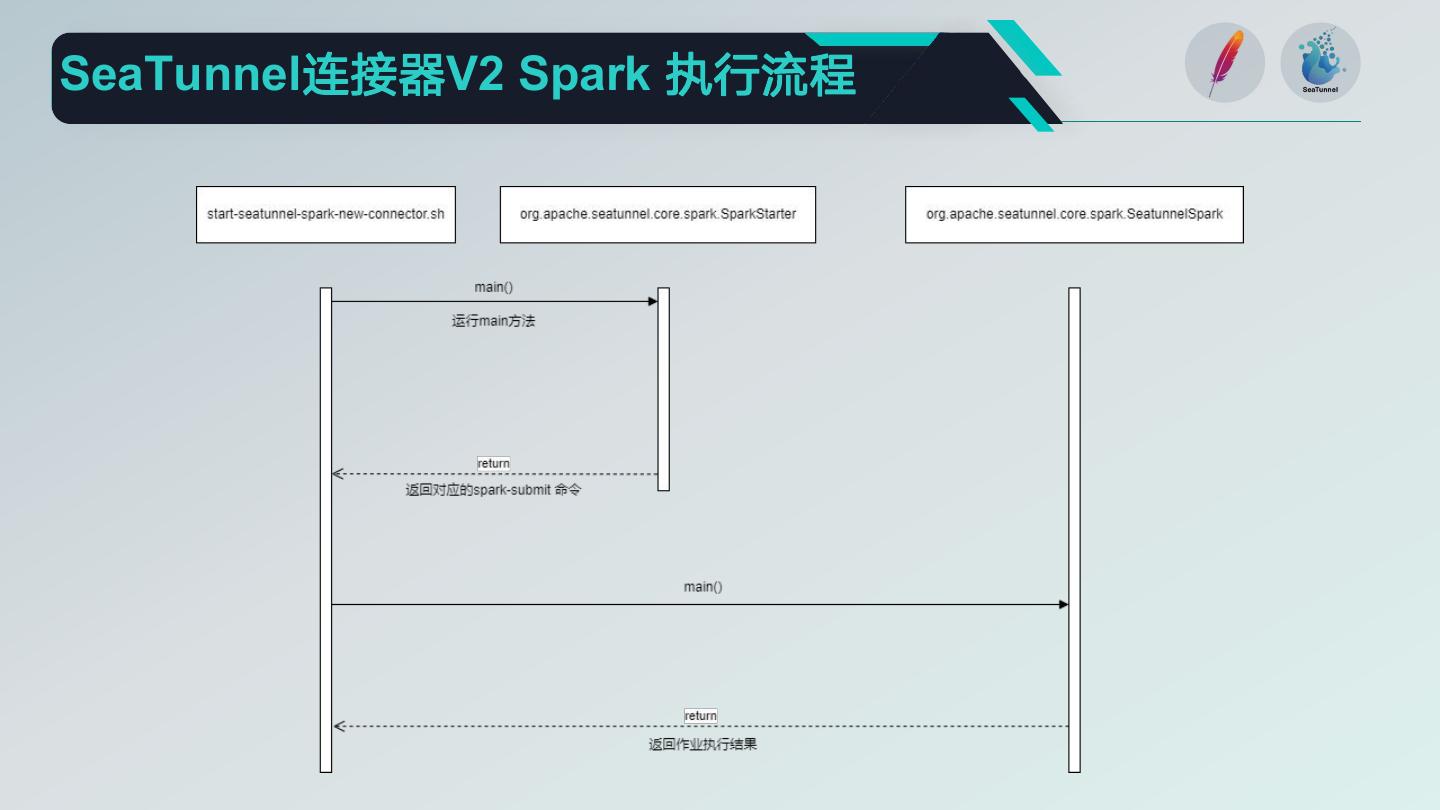
24 .SeaTunnel连接器V2 Spark 执行流程
�
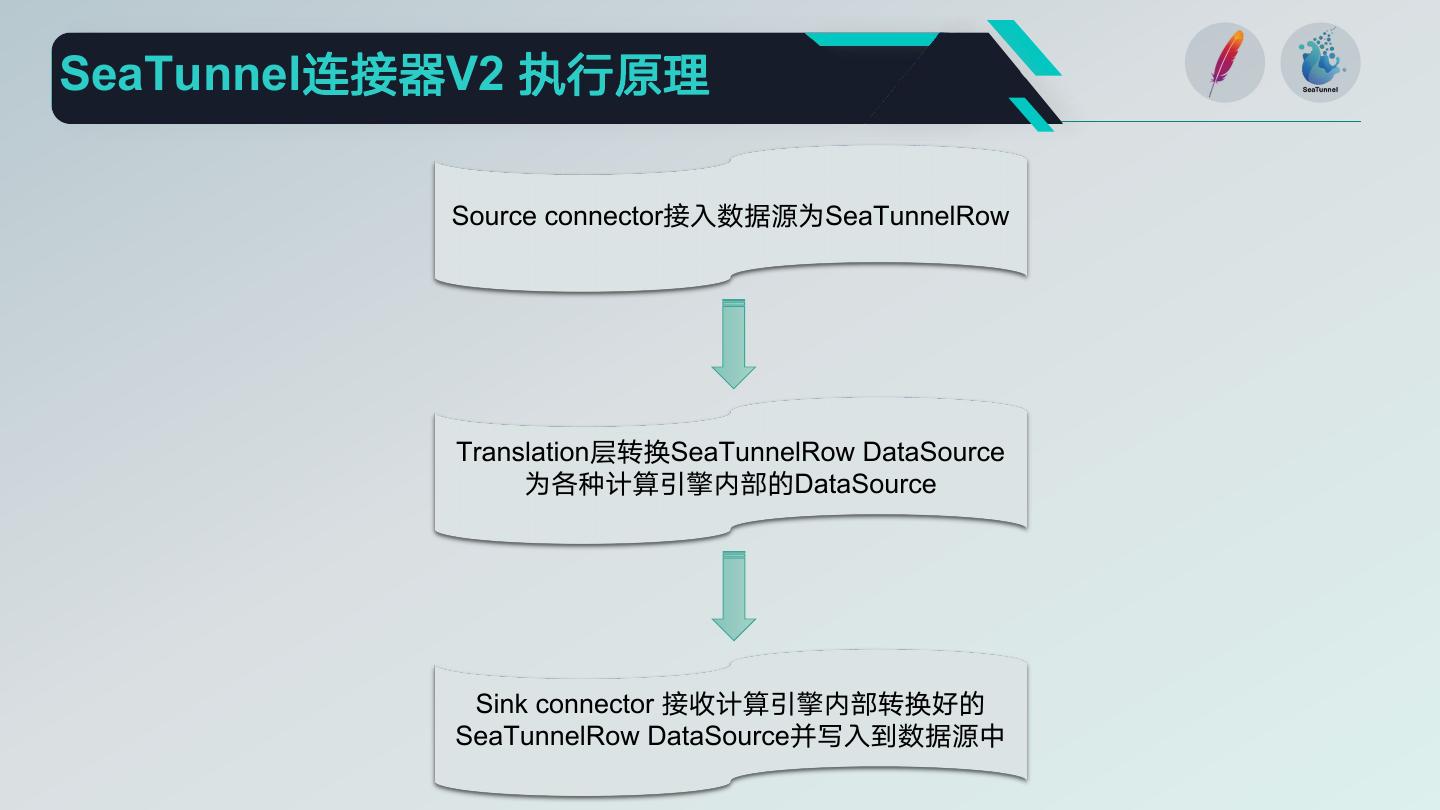
25 .SeaTunnel连接器V2 执行原理
Source connector接入数据源为SeaTunnelRow
Translation层转换SeaTunnelRow DataSource
为各种计算引擎内部的DataSource
Sink connector 接收计算引擎内部转换好的
SeaTunnelRow DataSource并写入到数据源中
�
27 .SeaTunnel连接器V1 V2细节对比
特征 连接器V1 连接器V2
引擎依赖 强依赖Spark、Flink 无依赖
连接器实现 针对不同引擎要实现多次 只实现一遍
较易,针对不同版本开
引擎版本升级难易程度 较难,连接器与引擎高度耦合
发不同翻译层即可
连接器参数是否统一 针对不同引擎可能会有不同参数 参数统一
依赖Spark、Flink已经实现好的数据
自定义分片逻辑 分片逻辑可自定义
Connector,分片逻辑不可控
�
29 . 当前工作
Connectors开发
SeaTunnel服务化
SeaTunnel计算引擎
World-Class open-source
data integration platform
from China
未来目标
性能优化,多维度指标监控,流速控制,
可视化大屏监控
可视化拖拉拽快速生成数据集成任务
更多调度平台无缝接入
�