




































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Doris+Flink+DolphinScheduler+Dinky构建开源数据平台
展开查看详情
1 .Doris + Flink + DolphinScheduler + Dinky 构建开源数据平台 亓文凯 2022/7/24
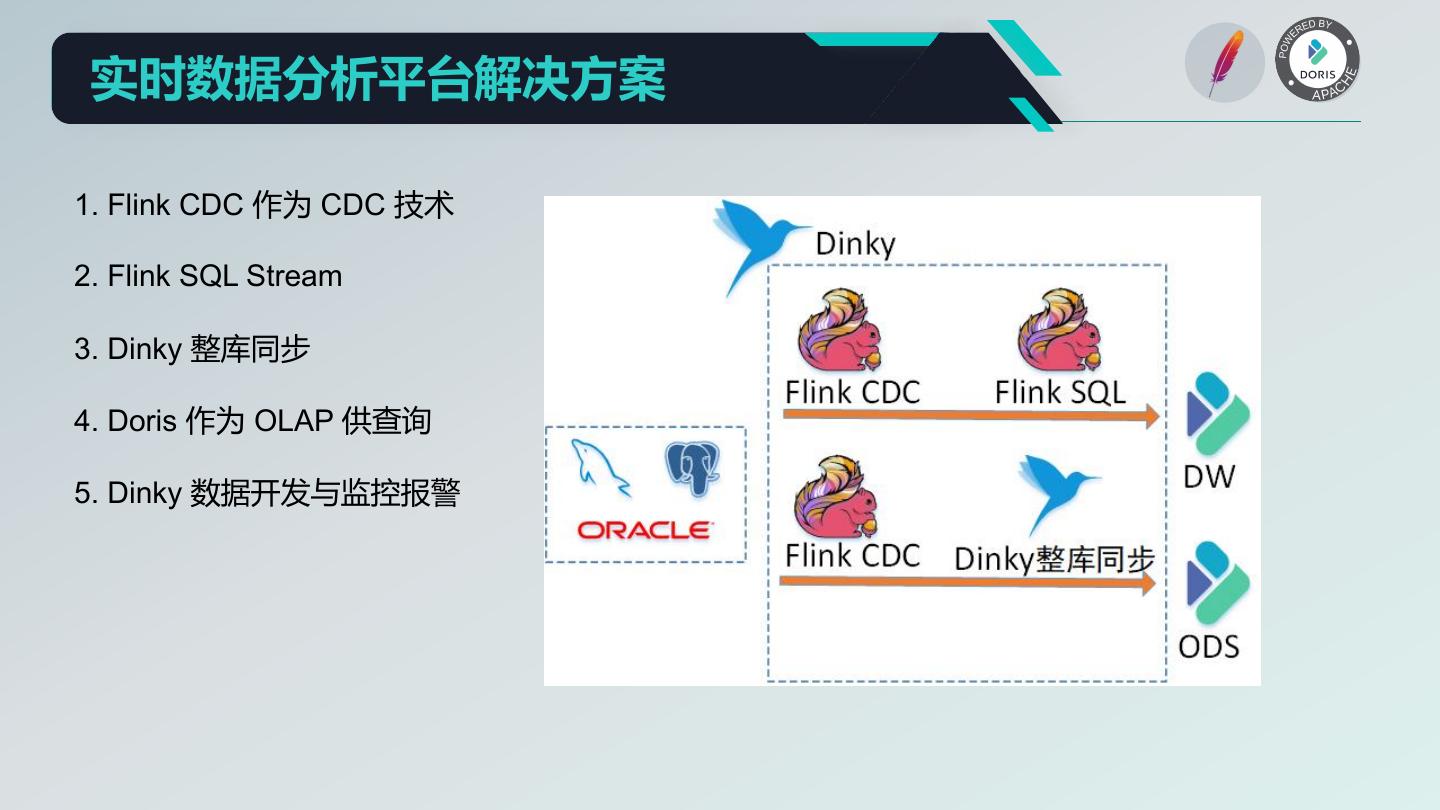
2 . 01 背景 02 平台思路 03 Dinky 实时计算平台 CONTENT 04 离线数据分析平台 05 实时数据分析平台 06 未来规划
3 .01 背景
4 .大数据时代的冲击 1. 如何应对日益骤增的业务数据? 2. 如何解决业务方大量的数据需求? 3. 如何高效快速地进行数据处理与分析? 4. 如何构建敏捷易扩展的数据平台? 5. 如何应用开源项目并推动其发展?
5 .开源数据平台实践分享 Doris Flink Dinky
6 .02 平台思路
7 .Apache Doris https://github.com/apache/doris
8 . Apache Doris 核心优势 1. 丰富的数据导入: 提供丰富的数据同步方式,支持快速加载来自本地、Hadoop、Flink、Spark、Kafka、SeaTunnel 等业务 系统及数据处理组件中的数据。 2. 强大的数据读取: Apache Doris可以直接访问MySQL、PostgreSQL、Oracle、S3、Hive、Iceberg、Elasticsearch等系统中 的数据而无需数据复制。同时存储在Doris中的数据也可以被 Spark、Flink 读取,并且可以输出给上游数据应 用进行展示分析。 3. 友好的数据应用: Apache Doris 支持通过JDBC标准协议将数据输出给下游应用,也支持各类BI/客户端工具通过MySQL协议 连接Doris。基于此,Apache Doris 在多维报表、用户画像、即席查询、实时大屏等诸多业务领域都能得到很 好应用。 4. 极致性能: 高效的列存储引擎和现代MPP架构,结合智能物化视图、向量化执行和各种索引加速,实现极致的查询性能。 5. 流批一体: 支持离线批量数据和实时流式数据高效导入,秒级实时性保证。多版本极机制结合导入事务支持,解决读写 冲突并实现Exactly-Once。 6. 极简运维: 高度一体,无任何外部组件依赖,集群规模在线弹性伸缩。系统高可用,节点故障自动副本切换,数据分片 自动负载均衡。
9 .Apache Flink https://github.com/apache/flink
10 . Apache Flink 核心优势 1. 高吞吐量、低延迟、高性能; 2. 支持 Event Time 和乱序事件; 3. 支持 exactly-once 语义; 4. 支持多种流式窗口; 5. 自身的内存模型与管理; 6. Batch 与 Stream 在 SQL 层实现一体; 7. 丰富的 Connector; 8. 社区火爆,用户规模大。
11 .Flink CDC https://github.com/ververica/flink-cdc-connectors
12 . Flink CDC 核心优势 1. 简化实时数据集成: 无须额外部署 Debezium、Canal、Kafka 等组件,运维成本大幅降低,链路稳定性提升。 2. 支持丰富的数据源: 目前支持 MongoDB、Mysql、OceanBase、Oracle、Postgres、SQLServer、TiDB 数据源的 CDC。 3. 支持全量、增量订阅及自动切换: 能进行全量与增量自动切换,支持 Exactly-once 语义,支持无锁并发读取,支持从检查点、保存点恢复, 断点续传,保证数据的准确性。 4. 无缝对接 Flink: 无缝对接 Flink 生态,复用 Flink 众多 Sink 能力,可使用 Flink 数据清理转换的能力。 5. 支持 FlinkSQL: 支持 FlinkSQL 定义 Flink CDC 任务,进一步降低使用门槛与运维成本。 6. 社区活跃: Github Stars 2800+,Fork 940 +,Contributors 56。
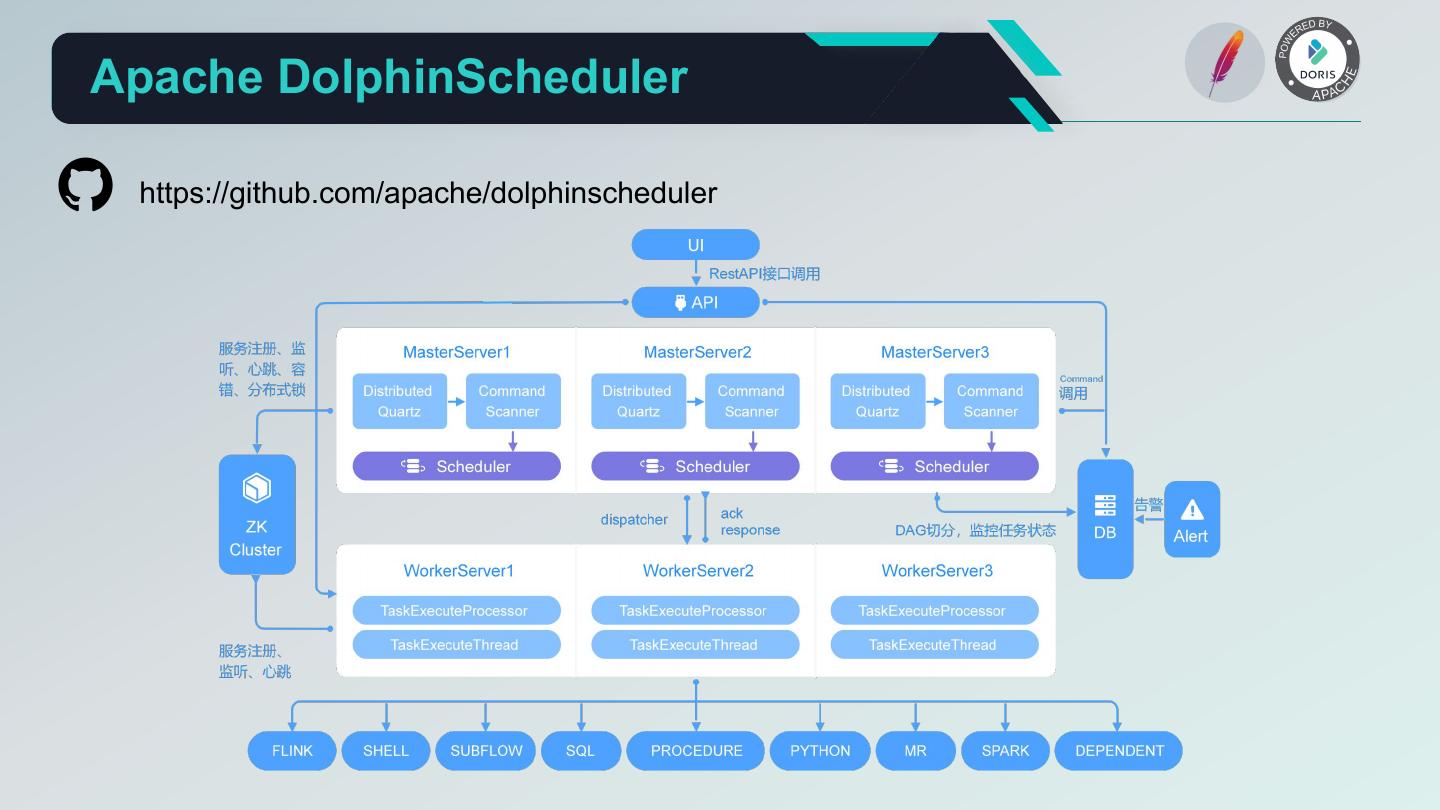
13 .Apache DolphinScheduler https://github.com/apache/dolphinscheduler
14 . Apache DolphinScheduler 核心优势 1. 高可靠性: 去中心化的多 Master 和多 Worker 服务对等架构, 避免单 Master 压力过大,另外采用任务缓冲队列来避 免过载。 2. 简单易用: DAG监控界面,所有流程定义都是可视化,通过拖拽任务完成定制DAG,通过API方式与第三方系统集成, 一键部署。 3. 丰富的使用场景: 支持多租户,支持暂停恢复操作。紧密贴合大数据生态,提供 Spark,Hive,M/R,Python,Sub_process, Shell 等近 20 种任务类型。 4. 高扩展性: 支持自定义任务类型,调度器使用分布式调度,调度能力随集群线性增长,Master 和Worker 支持动态上下线。 5. 社区活跃: 相比于其他调度平台社区更加活跃,版本功能及修复迭代快。 Github Stars 8300+,Fork 3200 +,Contributors 370。
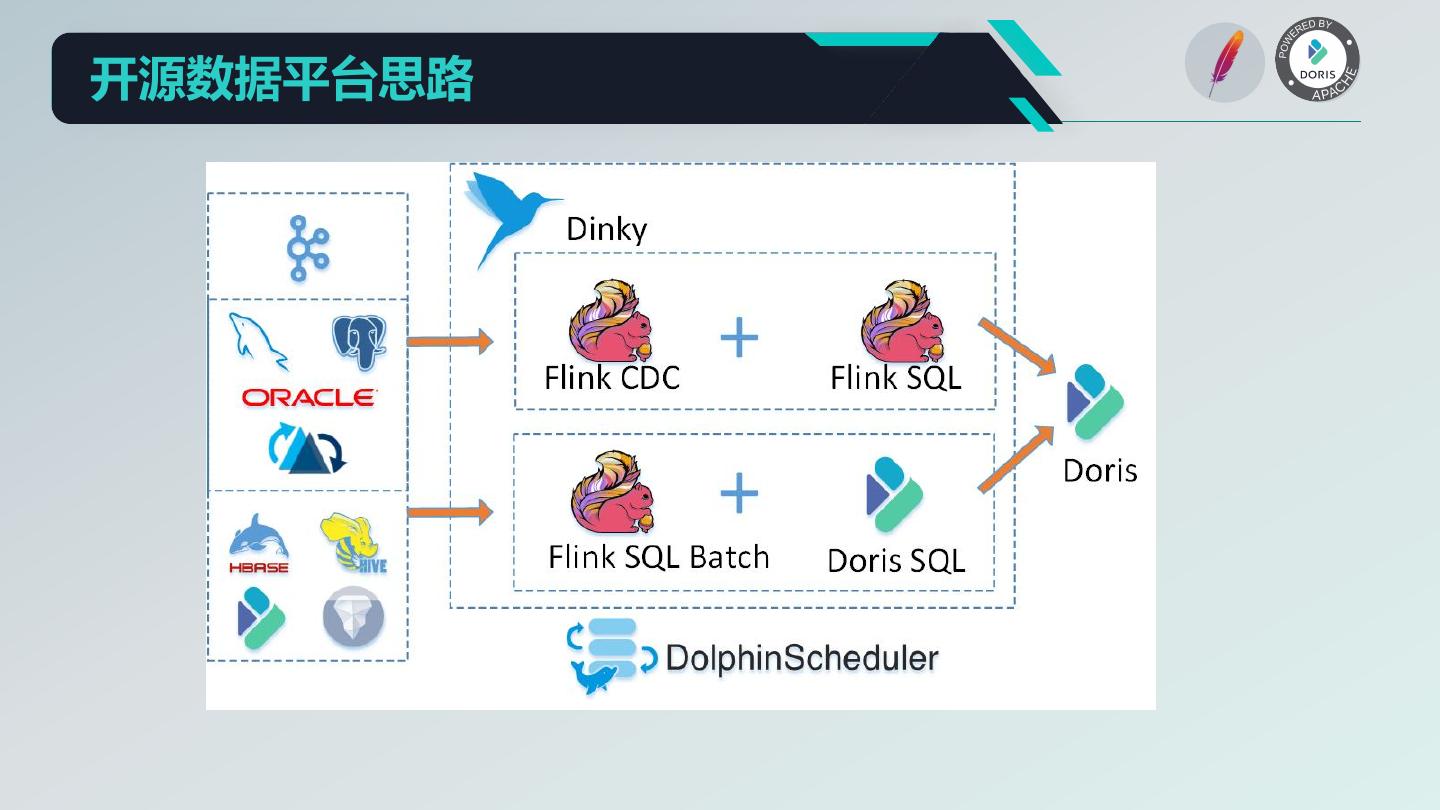
15 .开源数据平台思路
16 .03 Dinky 实时计算平台
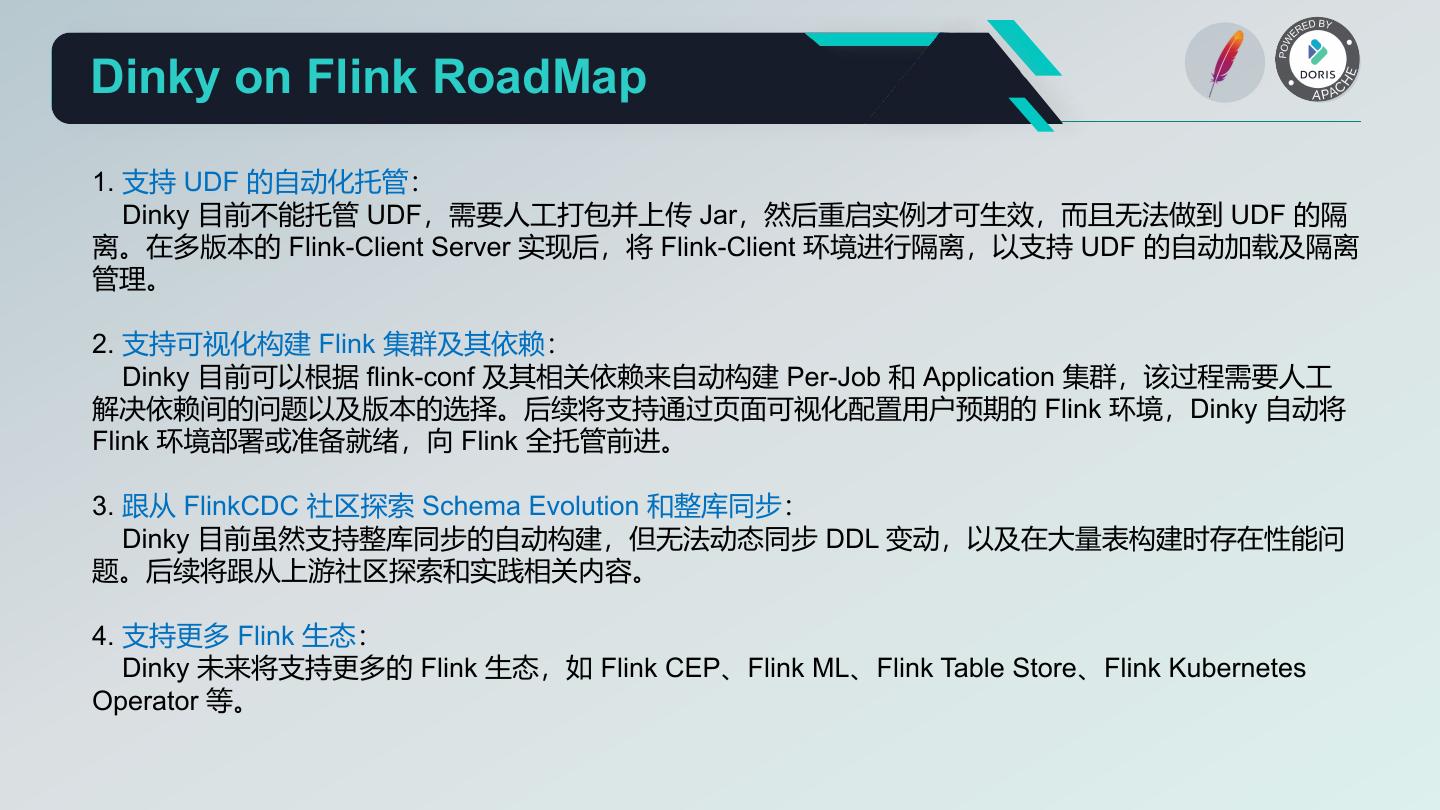
17 . Dinky 发展历程 1. 2021年6月6日,当时 Flink 社区正如火如荼的发展,但苦于没有一款适合 Flink SQL 界面化开发的工具, 于是增加了 Flink 的门槛与成本。虽然官方提供了 SQL Client,但仍有很多局限与不方便。于是 Dlink 以学习 项目的形式在个人仓库开源,版本号 0.1.0。 2. 2021年6月9日,由于项目引起了诸多用户的关注,为便于贡献及发展项目,创建了 DataLinkDC 组织来 管理 dlink 开源项目,标志着 dlink 正式开源共建。 3. 2022年1月17日,Dlink 更名为 Dinky,英译为 “ 小巧而精致的 ” ,最直观的表明了它的特征:轻量级但又 具备复杂的大数据开发能力,标志着 Dinky 从 FlinkSQL 开发平台转变为实时计算平台。 4. 2022年3月25日,Dinky 顺利入选 2022 年度 Gitee GVP 项目。 5. 2022年5月20日,Dinky 加入中国信通院可信开源社区共同体预备成员。 6. 2022年7月24日,Dinky 在 Doris & SeaTunnel 联合 Meetup 首次亮相。
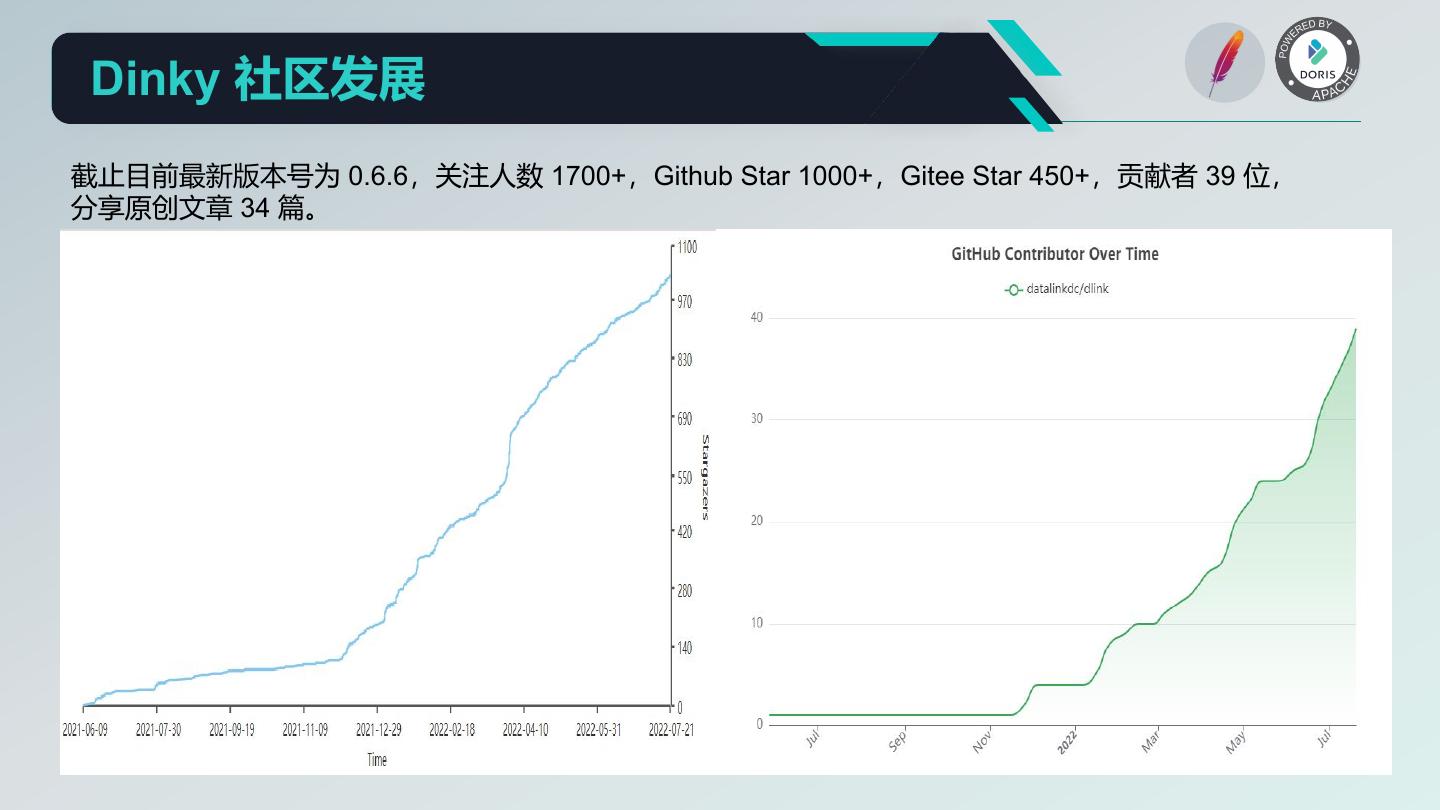
18 . Dinky 社区发展 截止目前最新版本号为 0.6.6,关注人数 1700+,Github Star 1000+,Gitee Star 450+,贡献者 39 位, 分享原创文章 34 篇。
19 .Dinky https://github.com/DataLinkDC/dlink
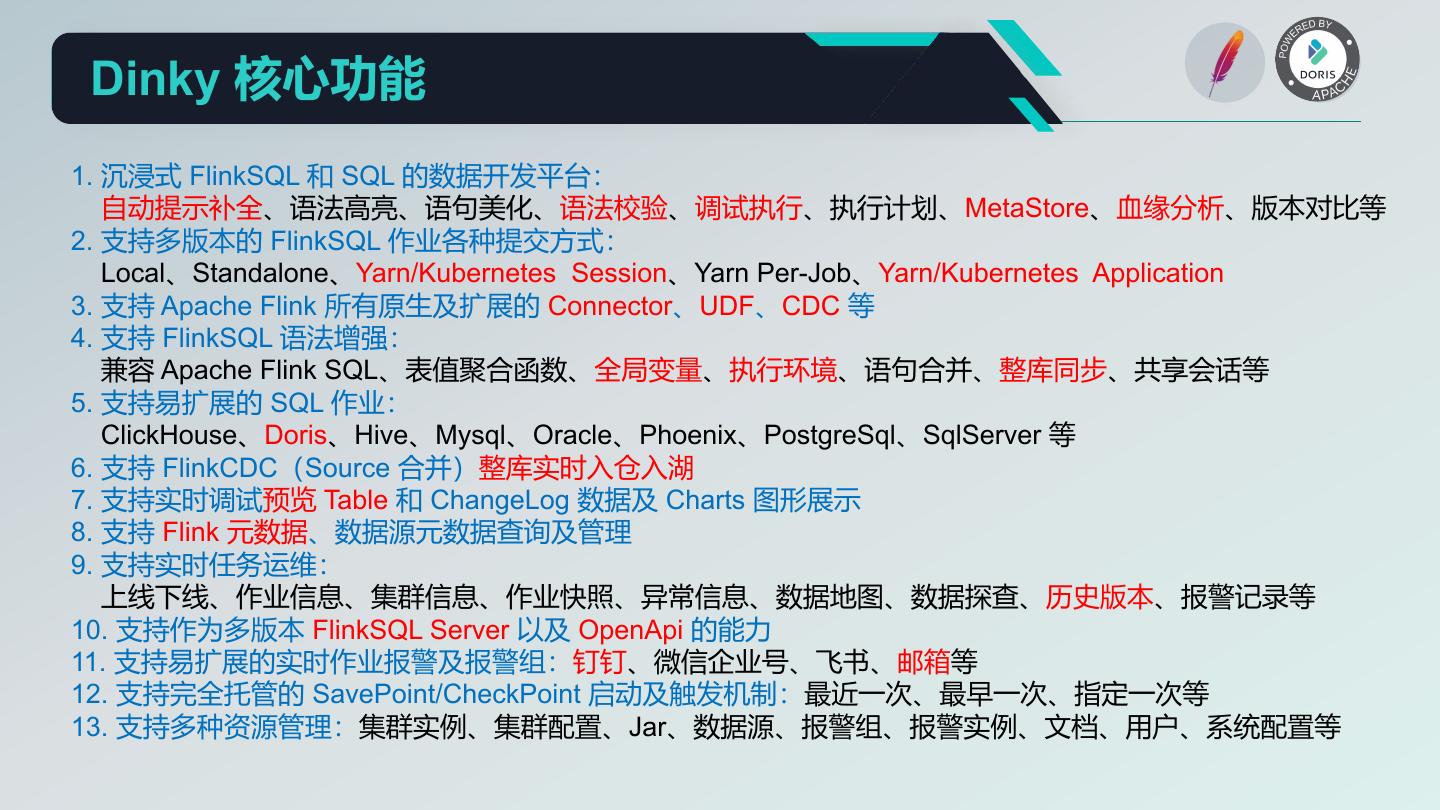
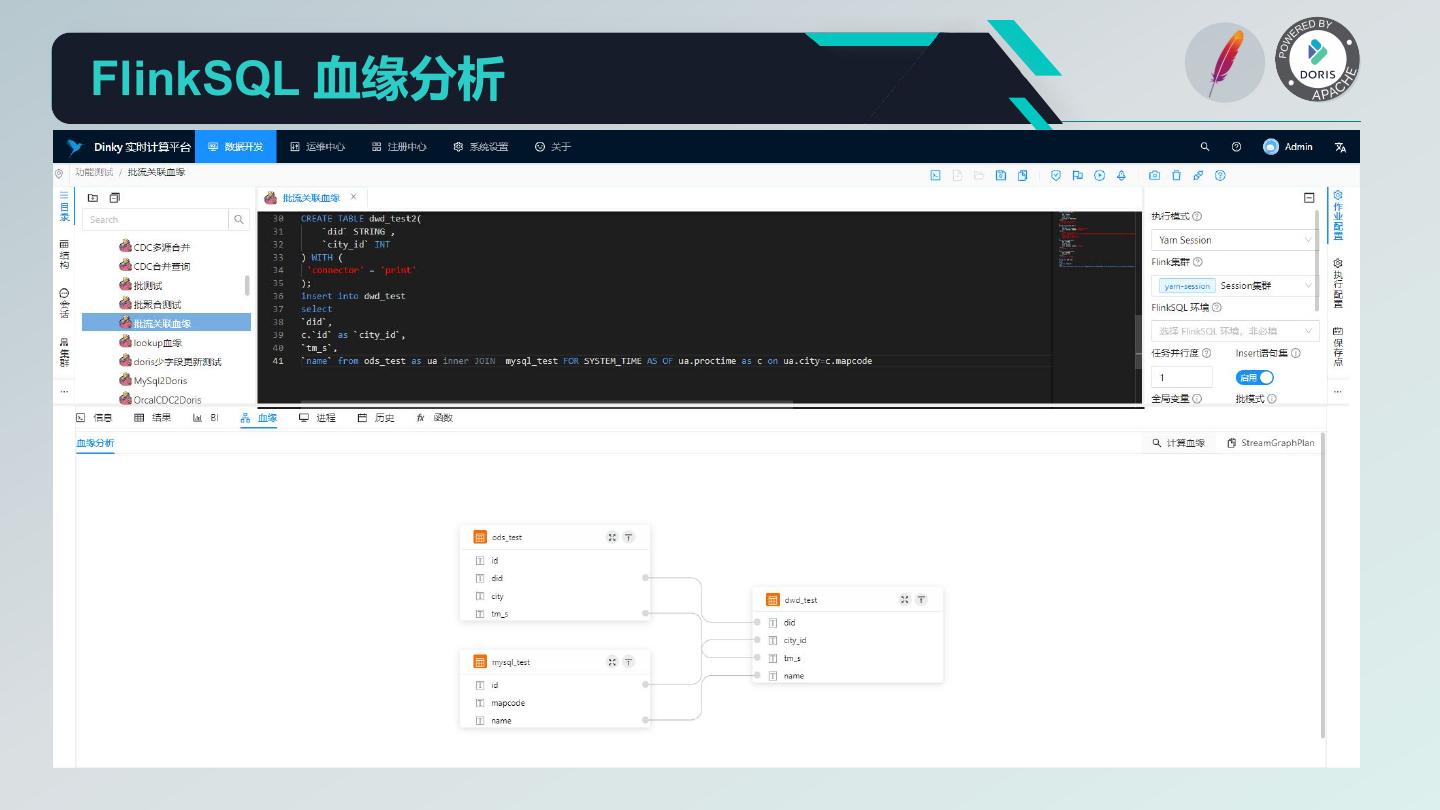
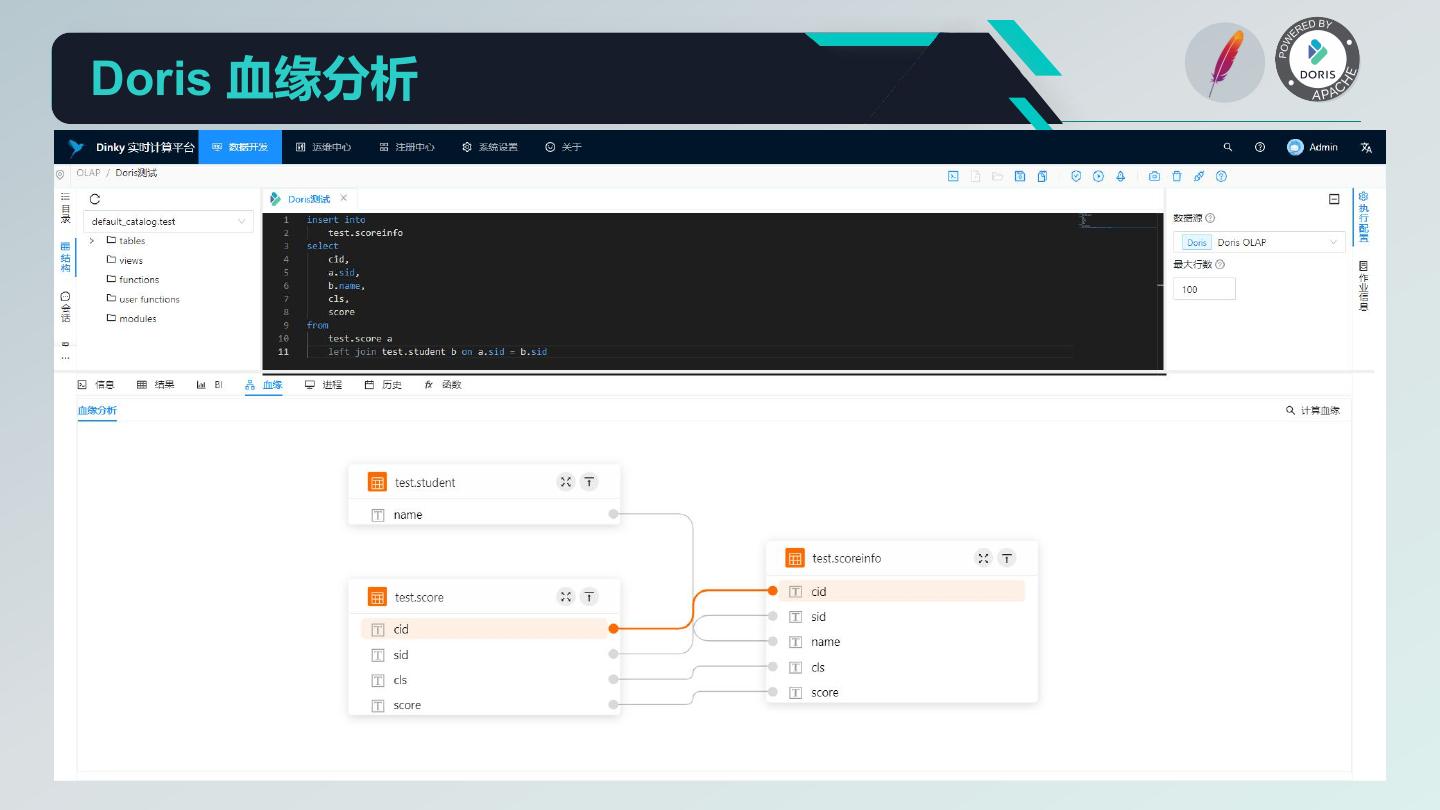
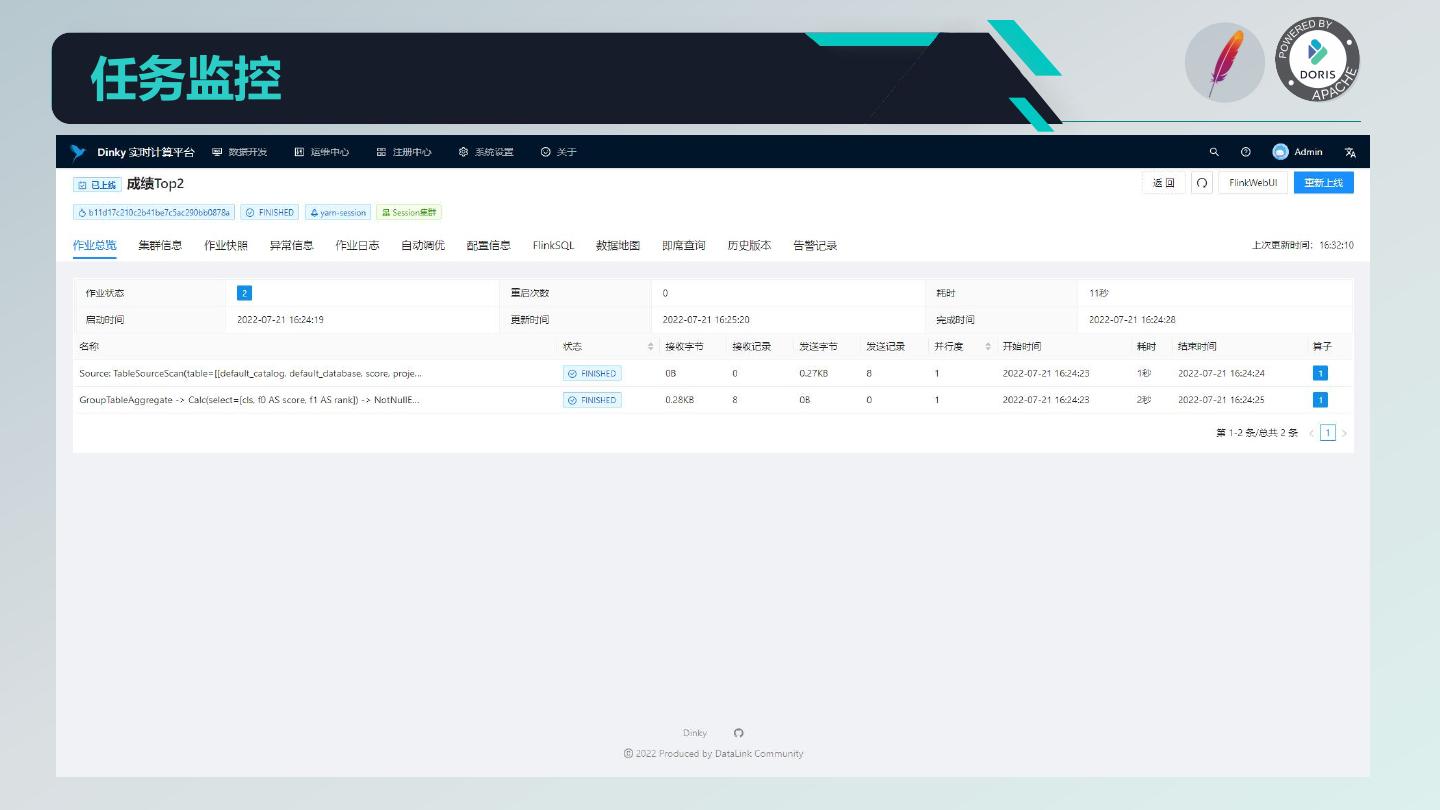
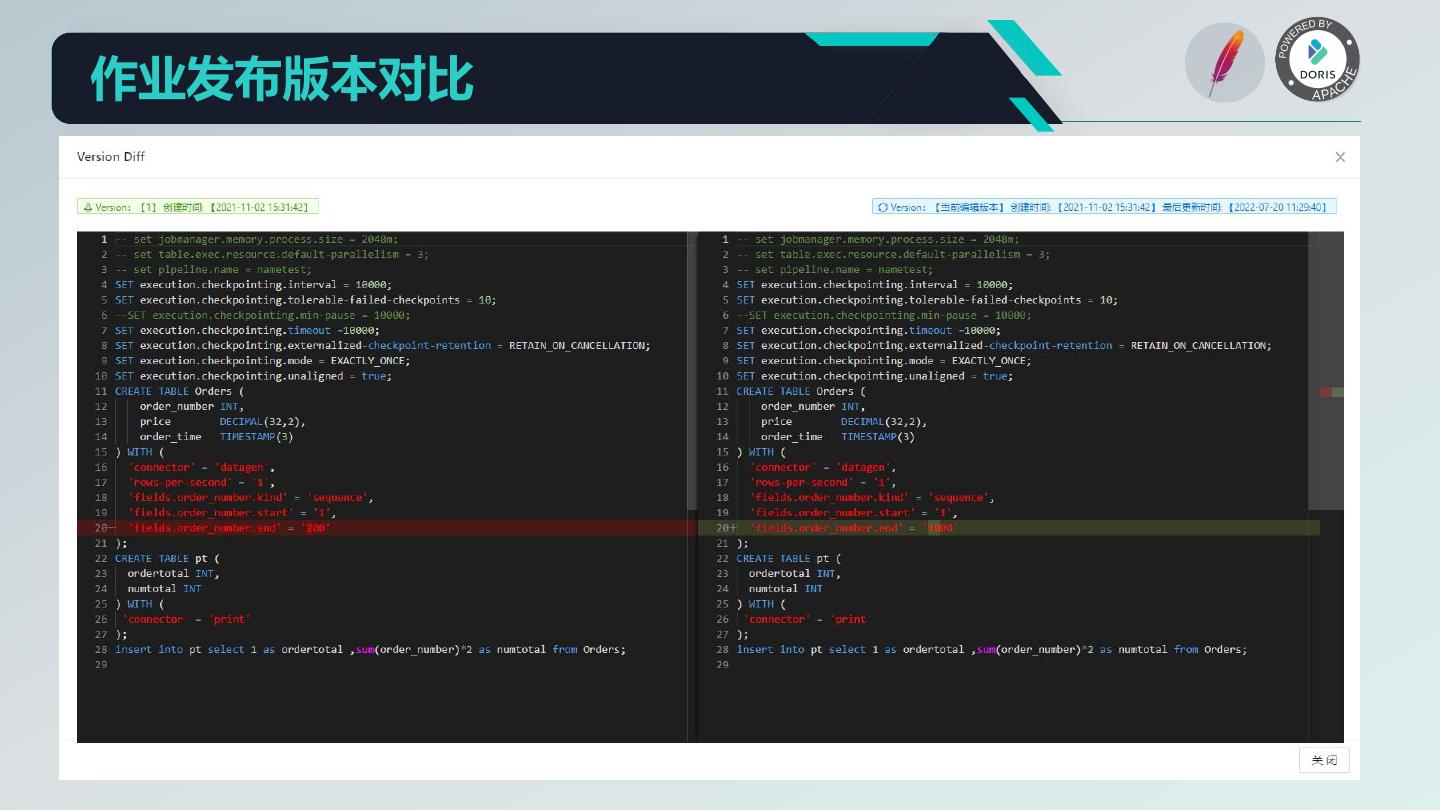
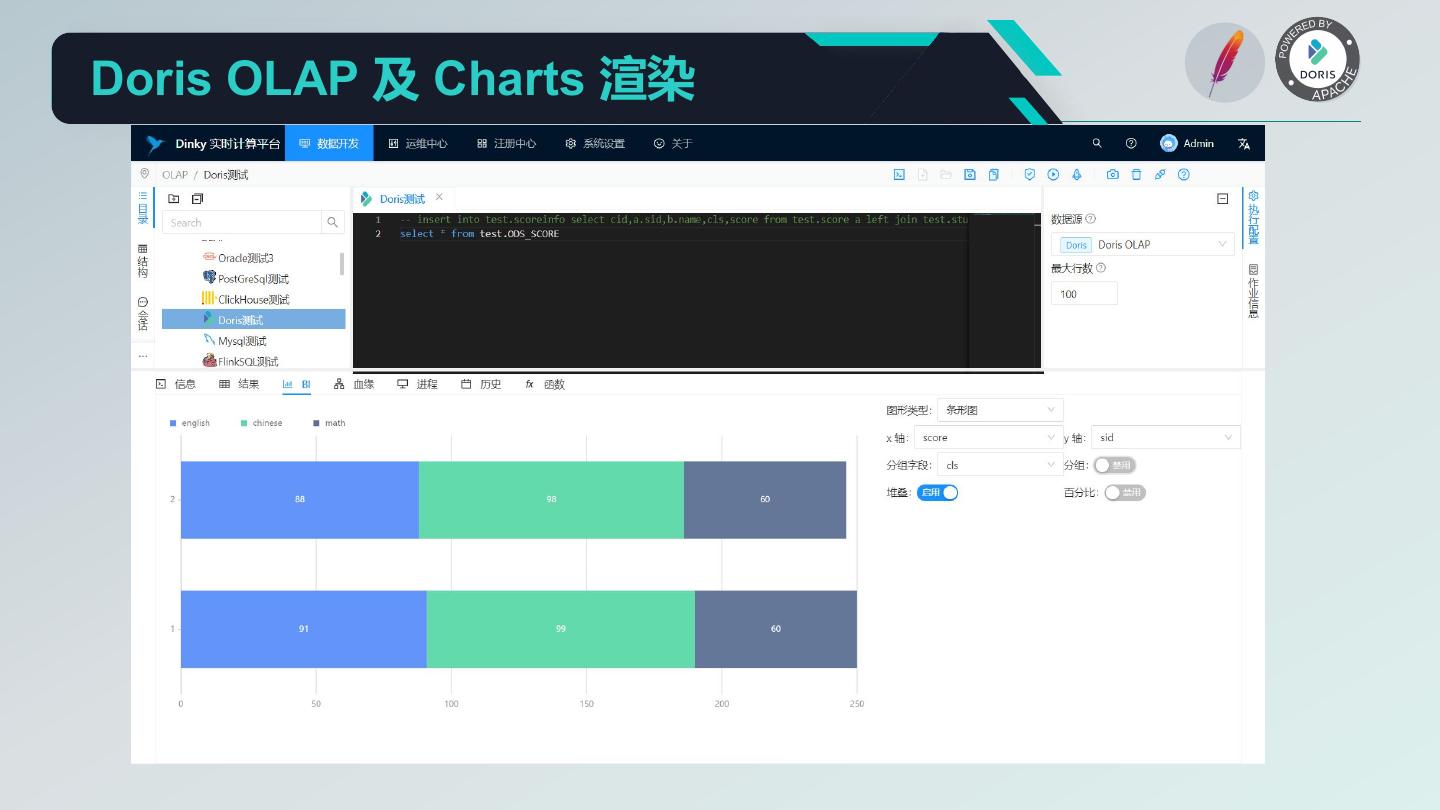
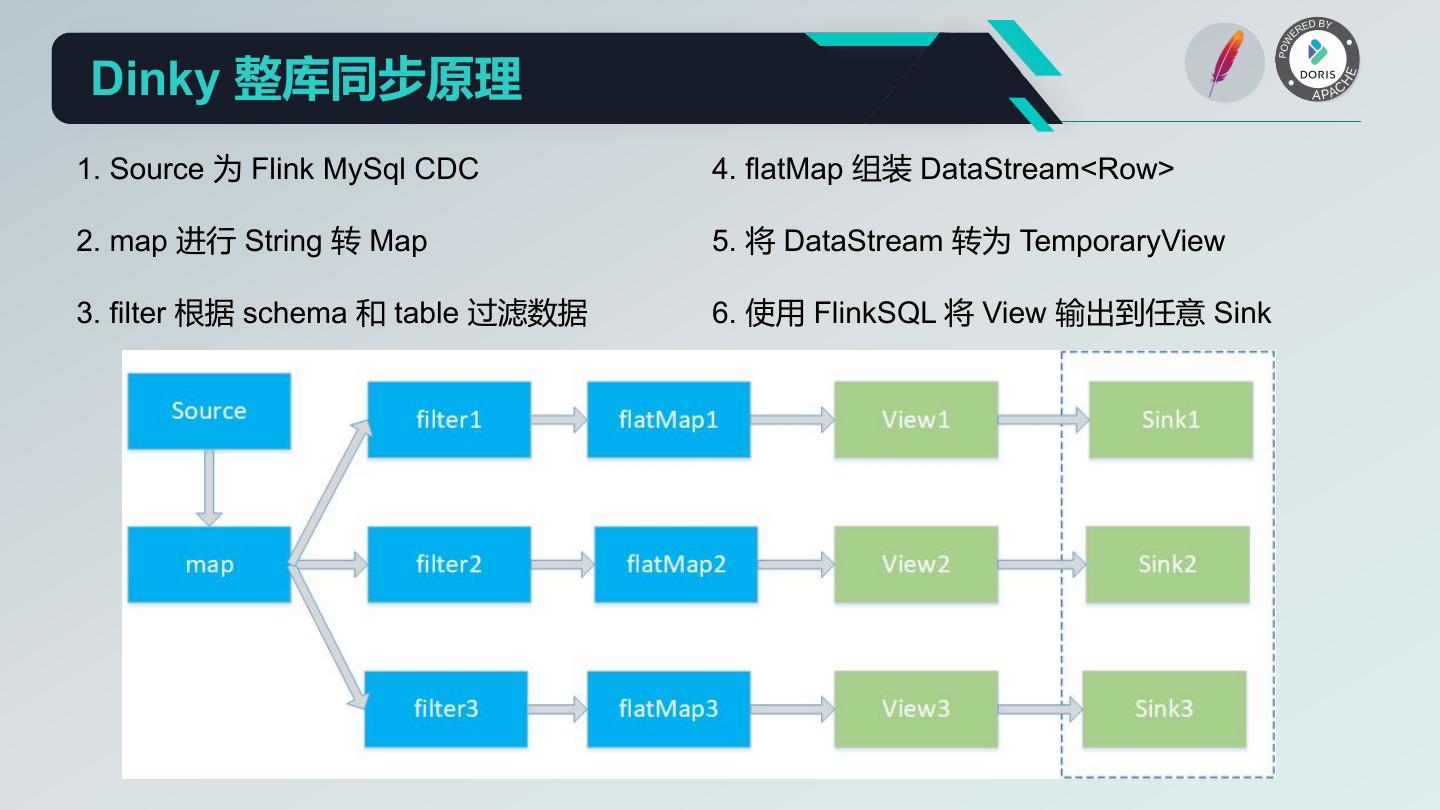
20 . Dinky 核心功能 1. 沉浸式 FlinkSQL 和 SQL 的数据开发平台: 自动提示补全、语法高亮、语句美化、语法校验、调试执行、执行计划、MetaStore、血缘分析、版本对比等 2. 支持多版本的 FlinkSQL 作业各种提交方式: Local、Standalone、Yarn/Kubernetes Session、Yarn Per-Job、Yarn/Kubernetes Application 3. 支持 Apache Flink 所有原生及扩展的 Connector、UDF、CDC 等 4. 支持 FlinkSQL 语法增强: 兼容 Apache Flink SQL、表值聚合函数、全局变量、执行环境、语句合并、整库同步、共享会话等 5. 支持易扩展的 SQL 作业: ClickHouse、Doris、Hive、Mysql、Oracle、Phoenix、PostgreSql、SqlServer 等 6. 支持 FlinkCDC(Source 合并)整库实时入仓入湖 7. 支持实时调试预览 Table 和 ChangeLog 数据及 Charts 图形展示 8. 支持 Flink 元数据、数据源元数据查询及管理 9. 支持实时任务运维: 上线下线、作业信息、集群信息、作业快照、异常信息、数据地图、数据探查、历史版本、报警记录等 10. 支持作为多版本 FlinkSQL Server 以及 OpenApi 的能力 11. 支持易扩展的实时作业报警及报警组:钉钉、微信企业号、飞书、邮箱等 12. 支持完全托管的 SavePoint/CheckPoint 启动及触发机制:最近一次、最早一次、指定一次等 13. 支持多种资源管理:集群实例、集群配置、Jar、数据源、报警组、报警实例、文档、用户、系统配置等
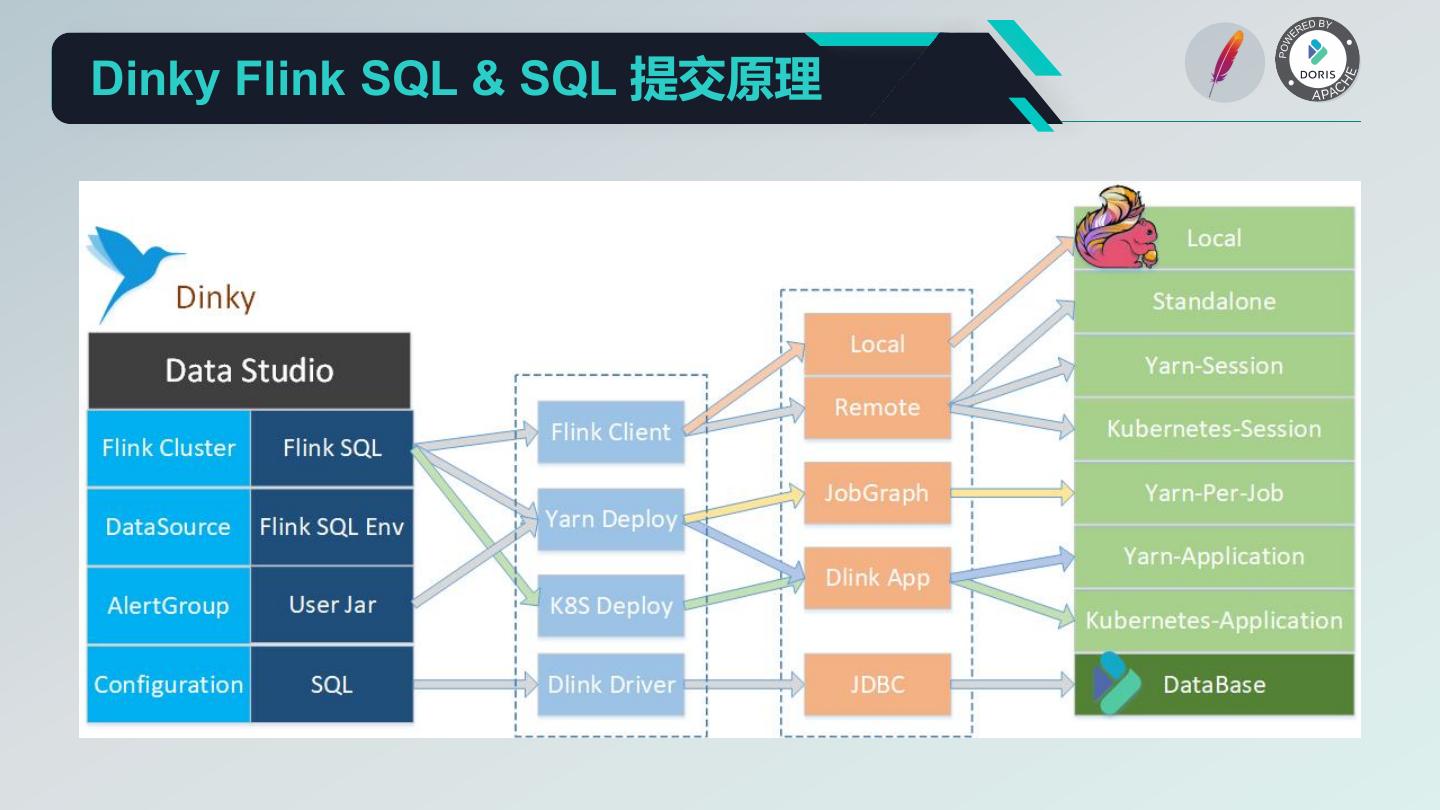
21 .Dinky Flink SQL & SQL 提交原理
22 . Dinky 核心优势 1. 多兼容:基于 Apache Flink 源码二次开发,兼容官方 1.11~1.15 版本源码,也兼容用户自己的分支改进版。 支持官方及其他扩展的 SQL Connector,如 ChunJun。支持 FlinkCDC 官方的 CDC SQL Connector。 2. 无侵入:Spring Boot 轻应用快速部署,不需要在任何 Flink 集群修改源码或添加额外插件,无感知连接和 监控 Flink 集群。如果要使用 Flink MetaStore、整库同步等功能,则需要在 Flink lib 中添加对应的依赖包。 3. 无依赖:只需要 Mysql 数据库与 JDK1.8 环境,不依赖任何其他中间件,如 zookeeper、hadoop 等。 4. 易用性:Flink 多种执行模式无感知切换,支持 Flink 多版本切换,自动化托管实时任务、恢复点、报警等, 自定义各种配置,持久化管理的 Flink Catalog (即 Flink MetaStore)。 5. 增强式:兼容且增强官方 FlinkSQL 语法,如 SQL 表值聚合函数、全局变量、CDC 整库同步、执行环境、 语句合并、共享会话等。 6. 易扩展:源码采用 SPI 插件化及各种设计模式支持用户快速扩展新功能,如连接器、数据源、报警方式、 Flink Catalog、CDC 整库同步、自定义 FlinkSQL 语法等。 7. 沉浸式:提供专业的 DataStudio 功能,支持全屏开发、自动提示与补全、语法高亮、语句美化、语法校验、 调试预览结果、全局变量、MetaStore、字段级血缘分析、元数据查询、FlinkSQL 生成等功能。 8. 一站式:提供从 FlinkSQL 开发调试到上线下线的运维监控及 SQL 的查询执行能力,使数仓建设及数据治理 一体化。 9. 易二开:源码后端基于 Spring Boot 框架开发,前端基于 React (Ant Design Pro) 开发,及其易扩展的设计, 易于企业进行定制化功能开发或集成到已有的开源或自建数据平台。
23 .04 离线数据分析平台
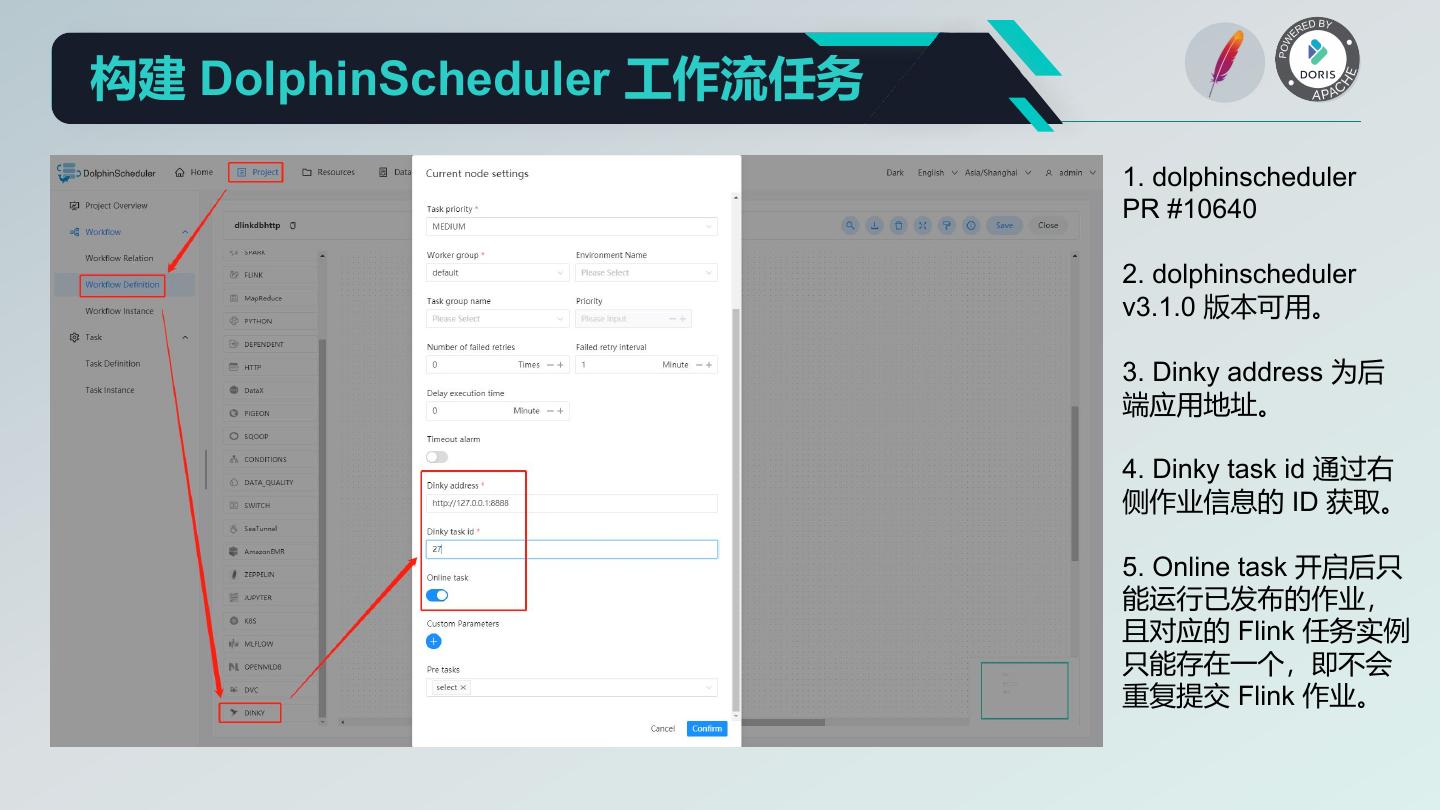
24 . 离线数据分析平台解决方案 1. Doris 作为数仓 2. Flink SQL Batch 3. Doris 外部表 4. Doris Insert SQL 5. Dinky 数据开发 6. DolphinScheduler 提供工作流调度 7. Doris OLAP
25 .Flink SQL 写入 Doris 1. Flink lib 及 Dinky plugins 下添加依赖: flink-doris-connector-1.13_2.11-1.0.0.jar (对应 flink、scala 和 doris 版本根据自己的环 境进行编译) 2. 支持写入更新: (1) ‘sink.enable-delete’ = ‘true’ (2) 只支持 Unique 模型 (3) FlinkDDL 指定主键信息 3. 解决换行符导致分隔错误: 'sink.properties.format' = 'json', 'sink.properties.strip_outer_array' = 'true',
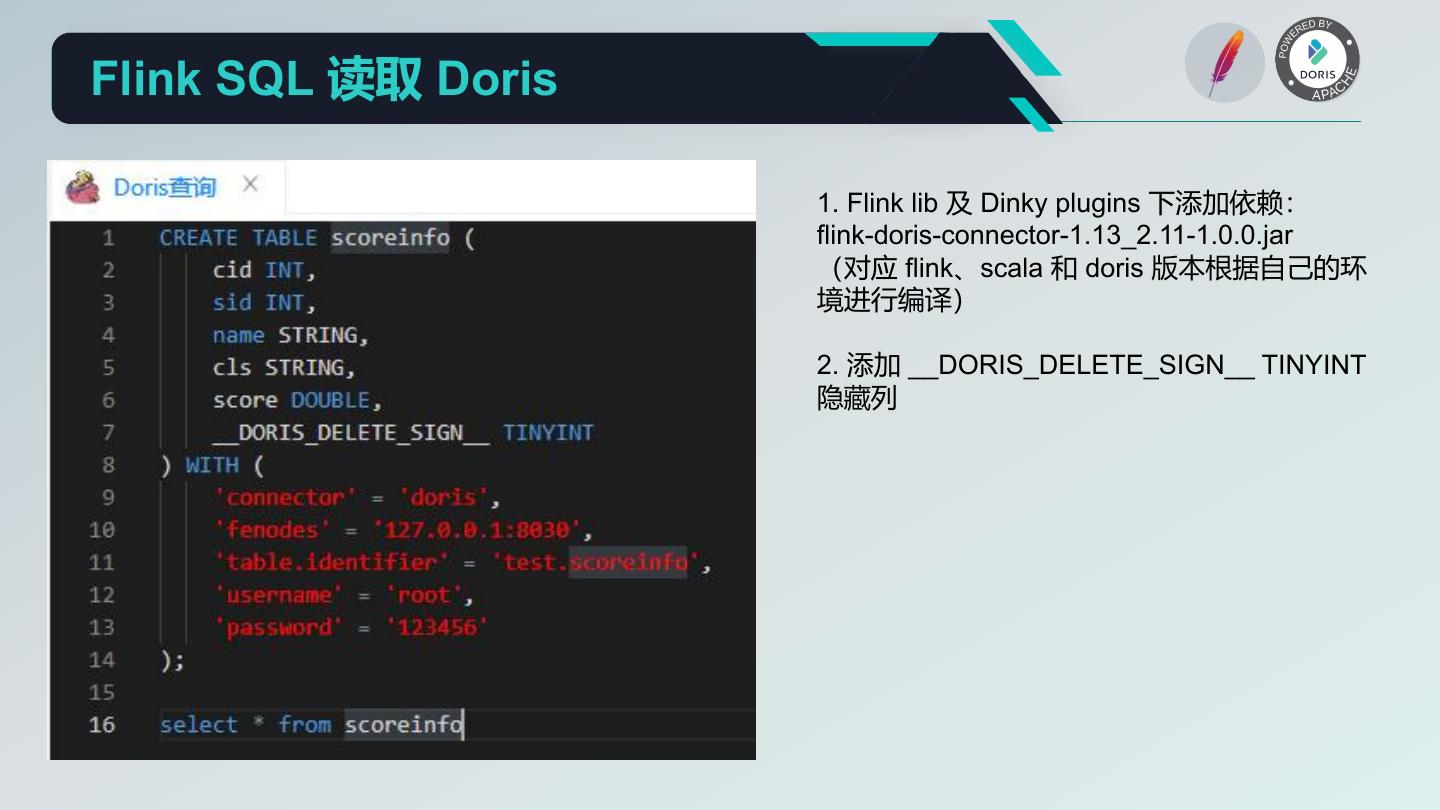
26 .Flink SQL 读取 Doris 1. Flink lib 及 Dinky plugins 下添加依赖: flink-doris-connector-1.13_2.11-1.0.0.jar (对应 flink、scala 和 doris 版本根据自己的环 境进行编译) 2. 添加 __DORIS_DELETE_SIGN__ TINYINT 隐藏列
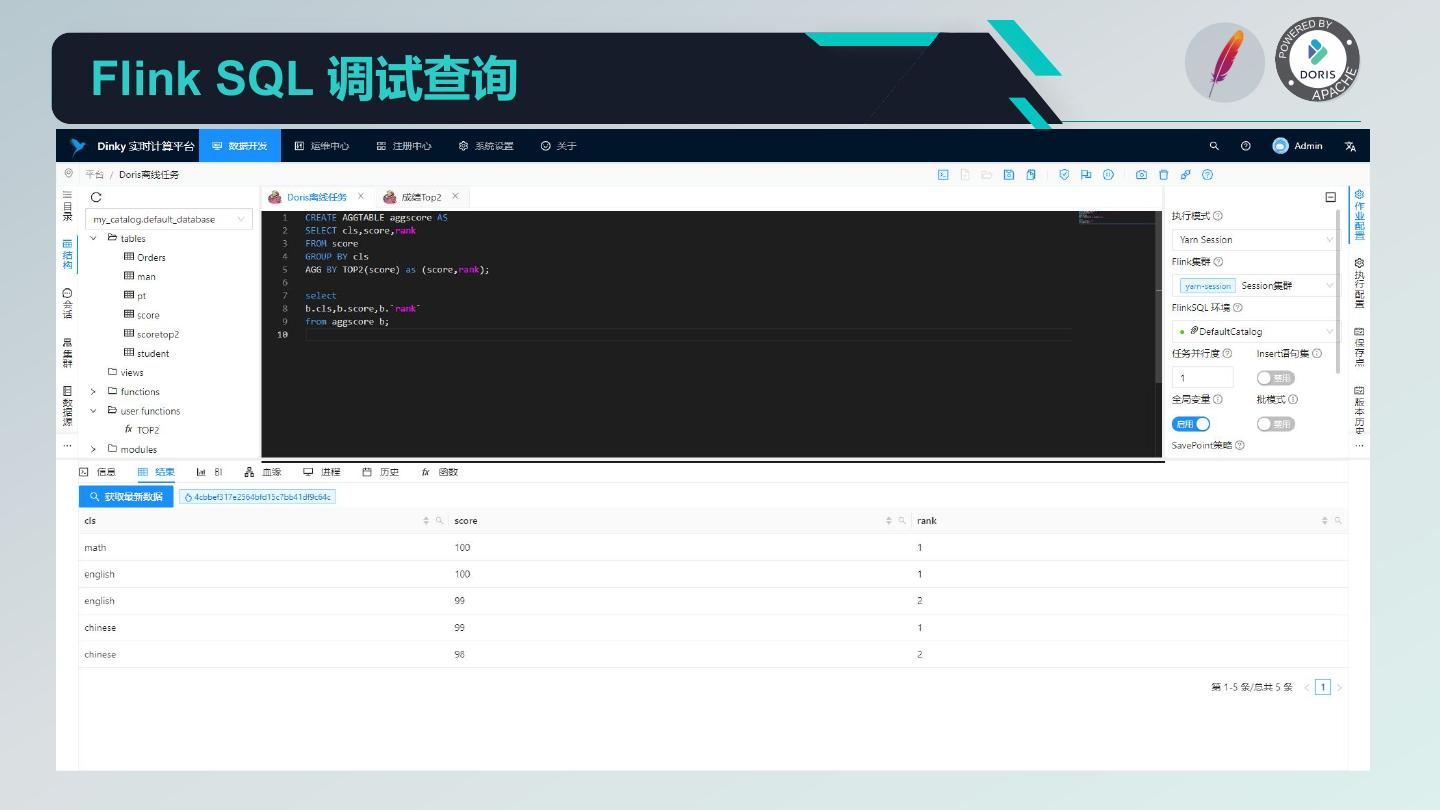
27 .Flink SQL 调试查询
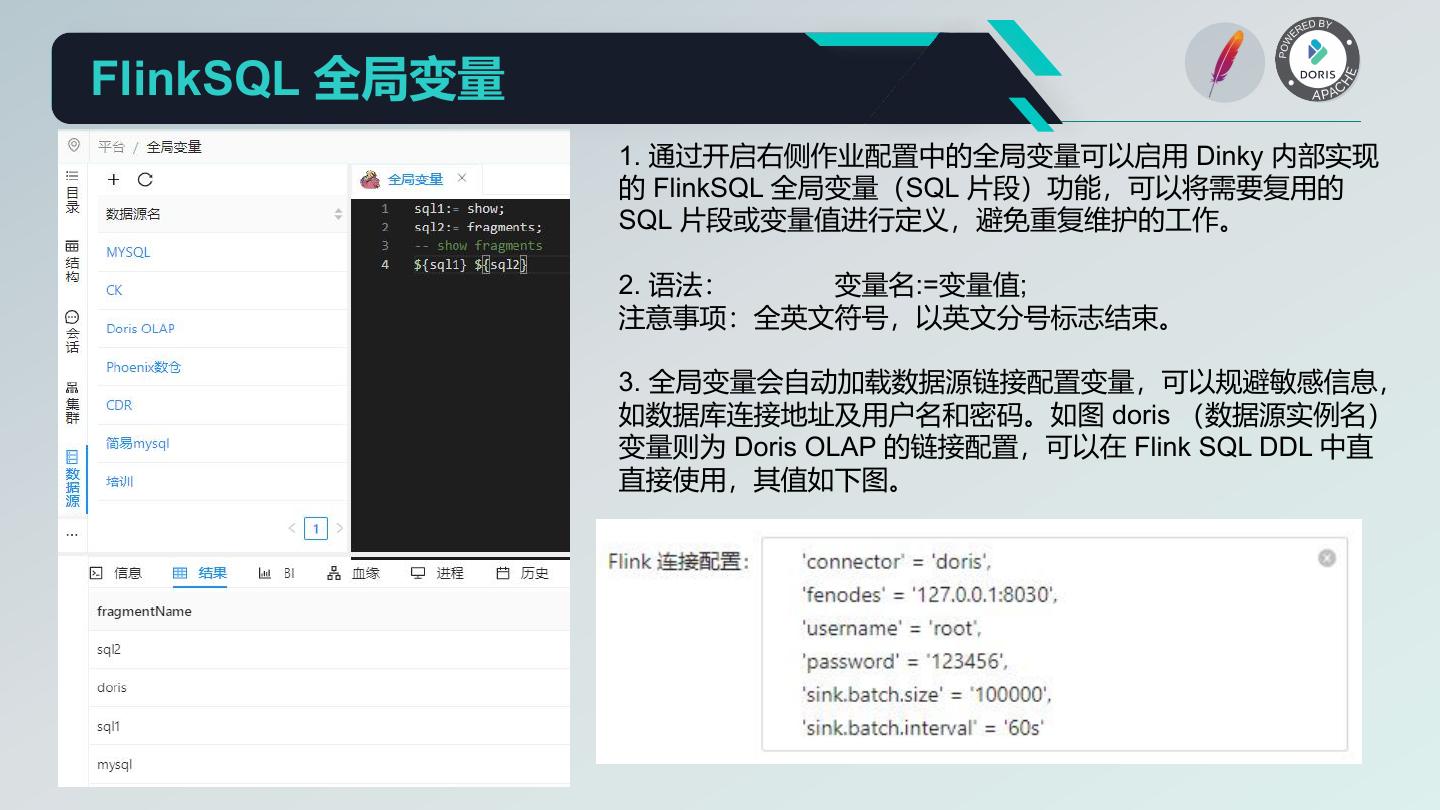
28 .Flink Catalog 管理 1. Dinky 实现了 MysqlCatalog 管理,为区分其他社 区及个人实现的 MysqlCatalog,其 type 为 dlink_mysql。 2.Dinky 的 MysqlCatalog 管理需要进行数据库表的 初始化,即执行根目录下 sql 文件夹里的 dlinkmysqlcatalog.sql 脚本。如果要使用 FlinkSQL 环境中默认的 default_catalog ,则需要在 dlink 的数 据库中执行该脚本。也可以在其他 Mysql 数据库中 执行该脚本,则需要自定义 FlinkSQLEnv 任务来提 供 Catalog 的环境。 3. FlinkSQLEnv 中可以定义多个 catalog 共同使用, 如 Flink 官方的 HiveCatalog。在 FlinkSQL 任务中 使用 catalog.database.table 来操作表,或者使用 use catalog 来切换不同的 catalog。
29 .FlinkSQL 表值聚合语法 AGGTABLE 1. Dinky 自定义了 CREATE AGGTABLE ... AS ... 语法, 该语法实现了 TableApi 层的表值聚合处理,使得 SQL 也 支持该操作(Flink 官方未实现)。 2. AGGTABLE 中 GROUP BY 为分组字段,AGG BY 为 聚合函数及其输出的字段信息。如 AGG BY TOP2(score) as (score,rank) 则为对 score 字段进行分组聚合操作,取 每组内最大值与次大值,然后返回多行结果。 3. 对于表值聚合函数的自定义,则需要按照 Flink 官网中 的 Table Aggregate Functions 文档进行扩展。扩展完成 后打包成 jar 文件,将其添加至 Dinky 的 plugins 和 Flink 的 lib 下,重启 Dinky 与 Flink 则生效。由于内存 Catalog 及 Dinky 的 default_catalog 中不包含该函数的定义,所以 使用时需要先通过 CREATE FUNCTION ... AS ... 进行自 定义函数的注册。
3秒后跳转登录页面
去登陆

