展开查看详情
1 .SeaTunnel在孩子王的应用实践
高性能OLAP数据同步方案
分享人:袁洪军
2022-04-16
�
2 . 01 背景介绍
02 主流工具对比分析
CONTENT 03 SeaTunnel的落地实践
04 常见问题列举
05 未来展望
�
3 .标题1、背景介绍
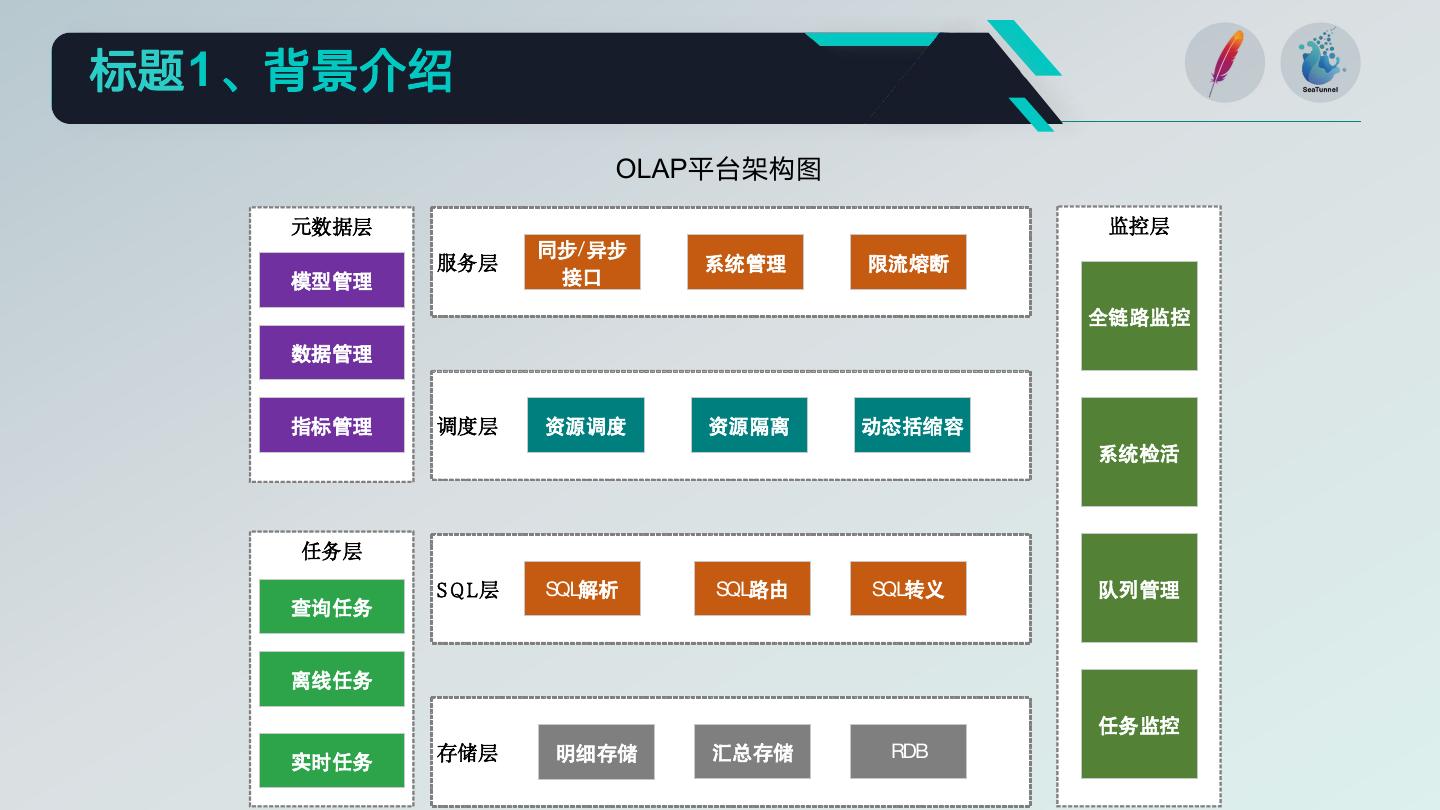
OLAP平台架构图
元数据层 监控层
同步/异步
服务层 系统管理 限流熔断
模型管理 接口
全链路监控
数据管理
指标管理 调度层 资源调度 资源隔离 动态括缩容
系统检活
任务层
S Q L层 SQL解析 SQL路由 SQL转义 队列管理
查询任务
离线任务
任务监控
实时任务 存储层 明细存储 汇总存储 RDB
�
4 . 标题1、背景介绍
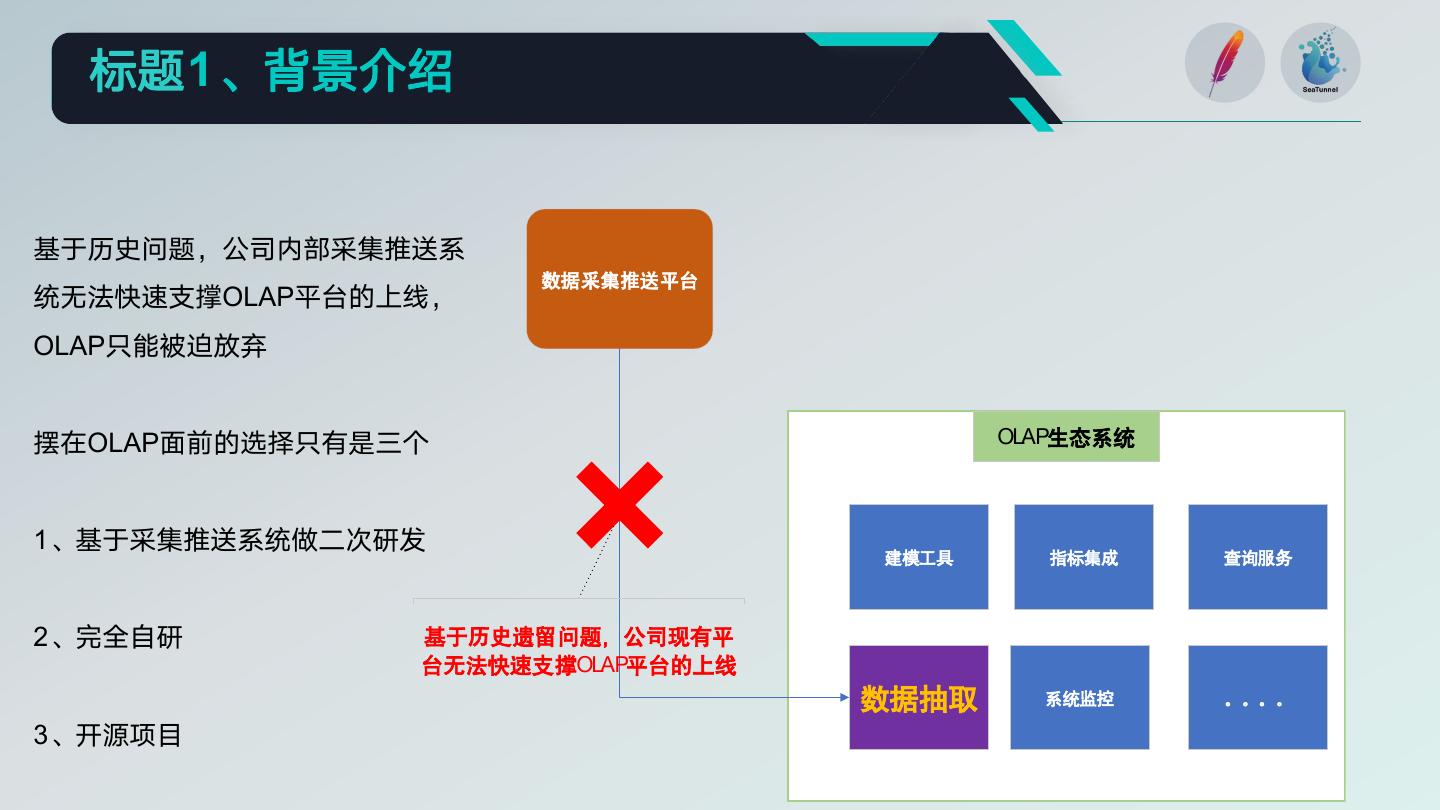
基于历史问题,公司内部采集推送系
数据采集推送平台
统无法快速支撑OLAP平台的上线,
OLAP只能被迫放弃
摆在OLAP面前的选择只有是三个 OLAP生态系统
1、基于采集推送系统做二次研发
建模工具 指标集成 查询服务
2、完全自研 基于历史遗留问题,公司现有平
台无法快速支撑OLAP平台的上线
数据抽取 系统监控 。。。。
3、开源项目
�
5 .标题2、主流工具对比分析
OLAP路线选择简单对比
对比 优点 缺点 补充说明
1、代码量大
基于采集推送 留有前人经验,避免重复踩坑 2、抽象较少
做二次研发 3、业务定制化功能多
1、自主可控
自研 2、分布式架构
未知问题 Spark技术栈普及率高,不占用单独的机器资源
1、抽象多
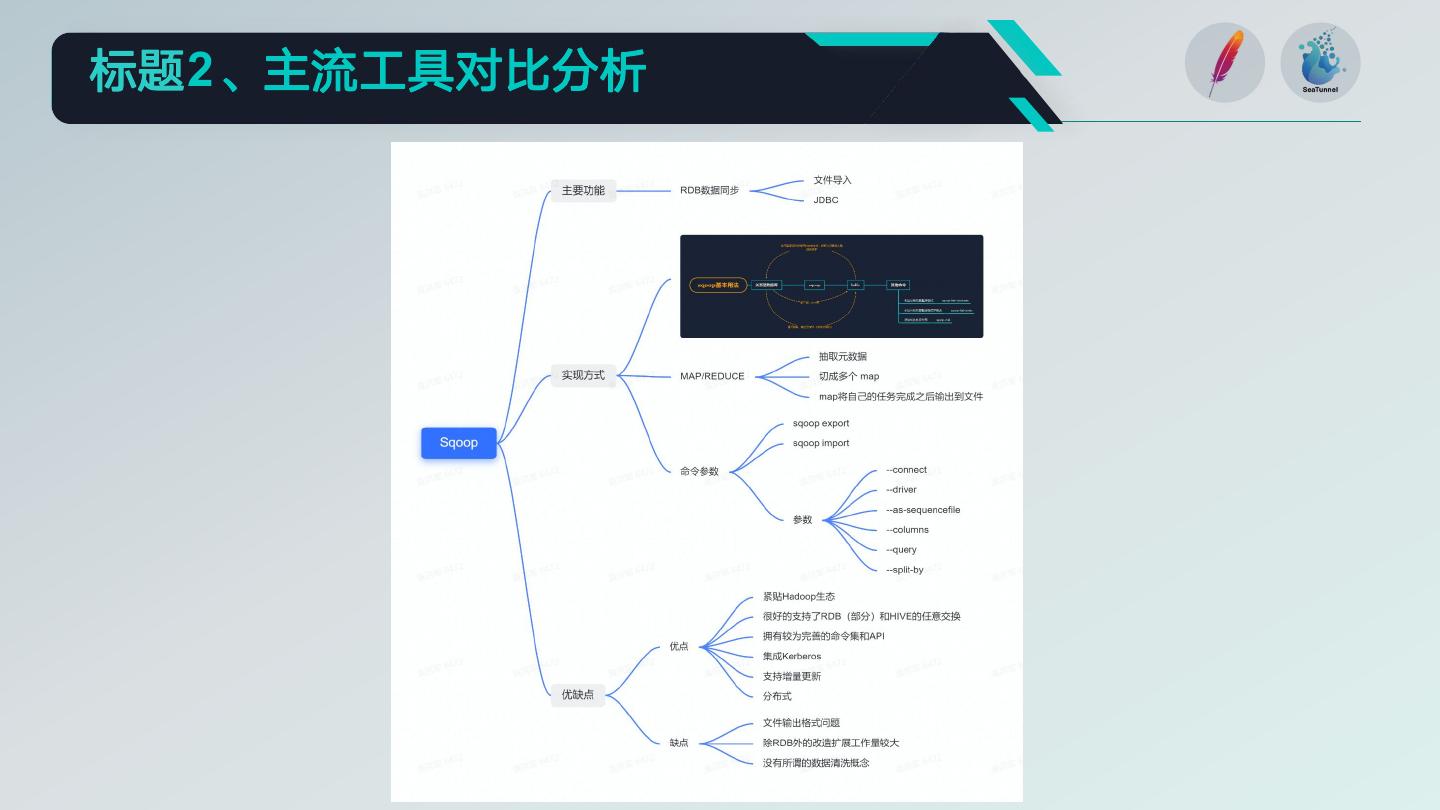
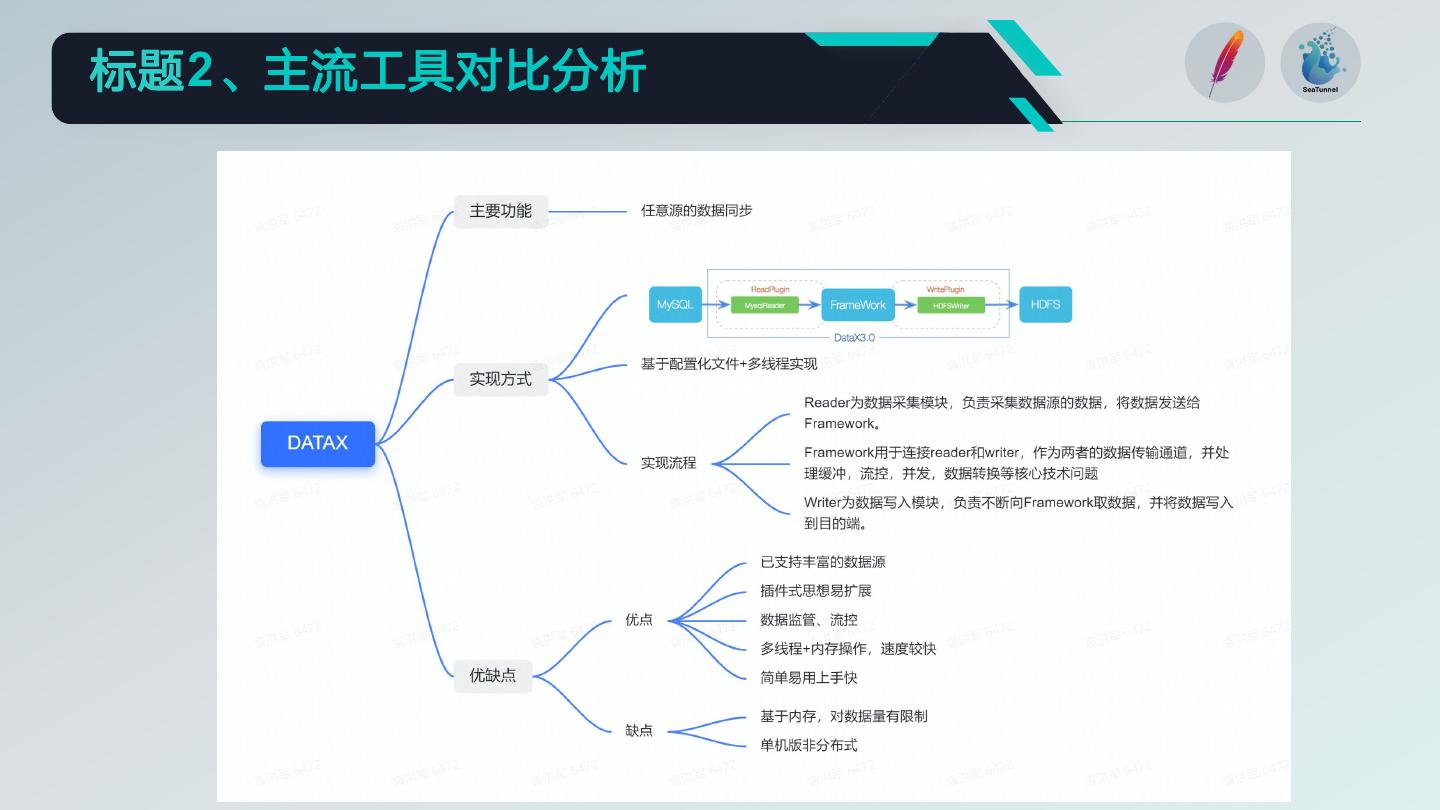
目前已知的有DATAX,Sqoop,SeaTunnel
开源框架 2、经过验证 需要先研究开源框架
3、分布式架构(?)
�
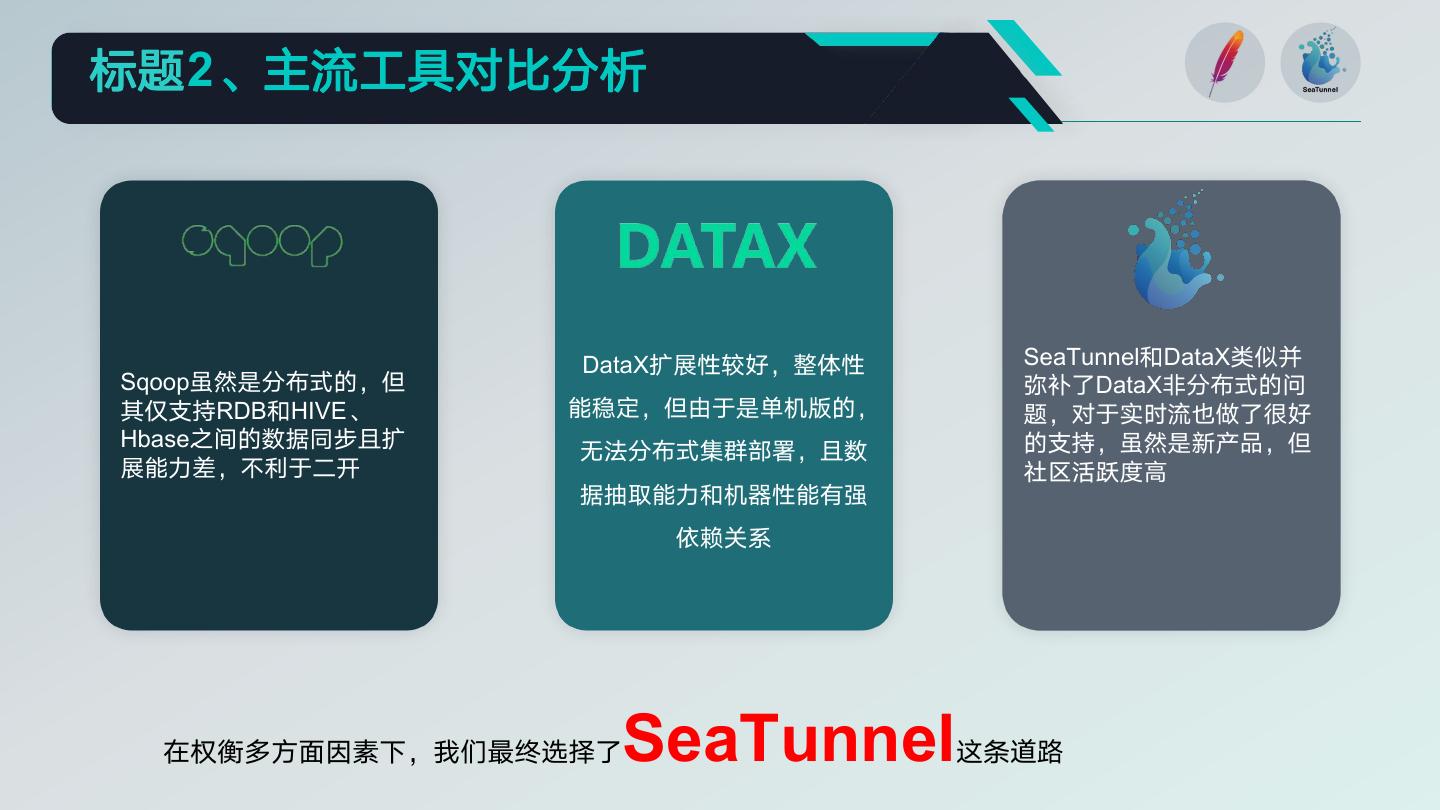
9 .标题2、主流工具对比分析
DataX扩展性较好,整体性 SeaTunnel和DataX类似并
Sqoop虽然是分布式的,但 弥补了DataX非分布式的问
其仅支持RDB和HIVE、 能稳定,但由于是单机版的, 题,对于实时流也做了很好
Hbase之间的数据同步且扩 的支持,虽然是新产品,但
无法分布式集群部署,且数
展能力差,不利于二开 社区活跃度高
据抽取能力和机器性能有强
依赖关系
在权衡多方面因素下,我们最终选择了SeaTunnel这条道路
�
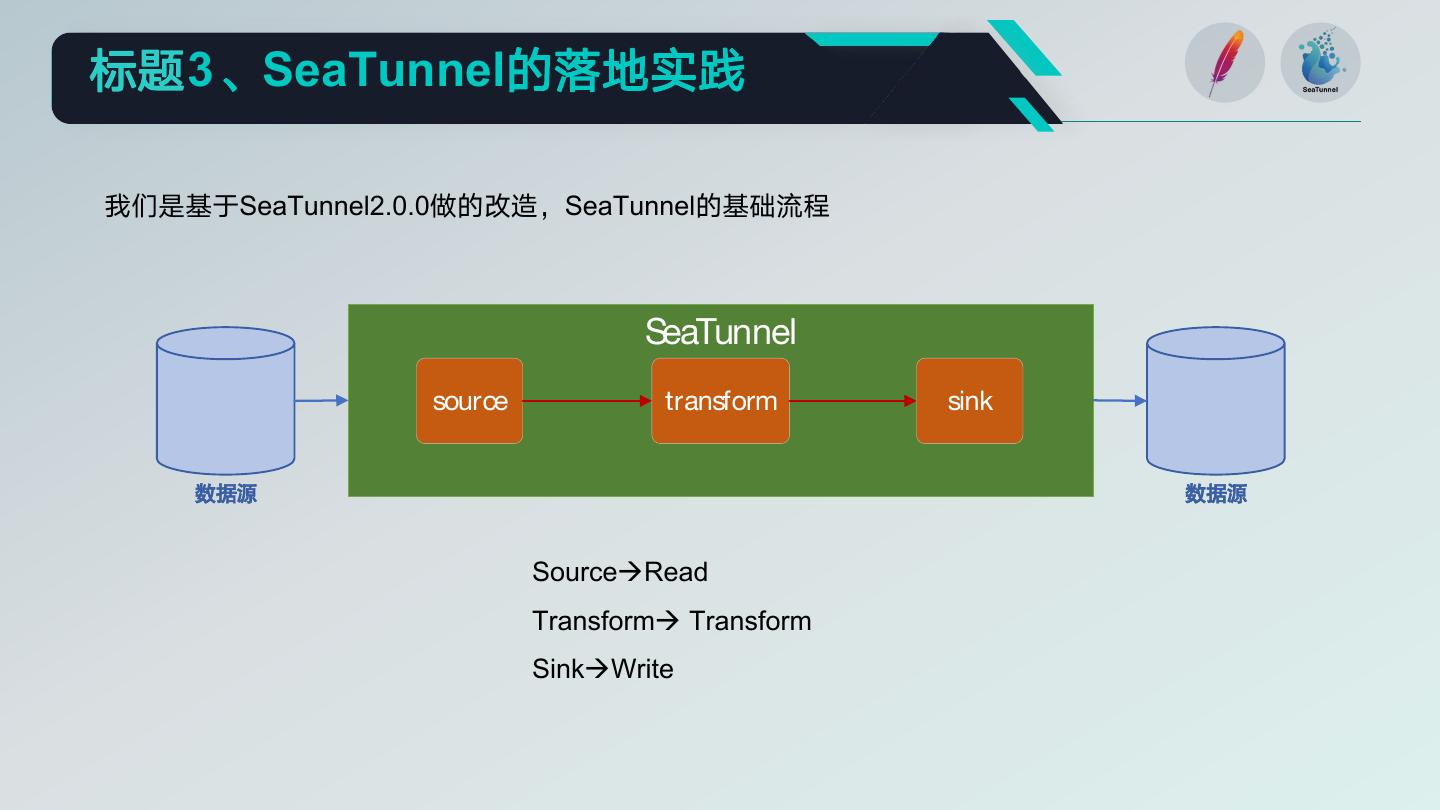
10 .标题3、SeaTunnel的落地实践
我们是基于SeaTunnel2.0.0做的改造,SeaTunnel的基础流程
SeaTunnel
source transform sink
数据源 数据源
SourceRead
Transform Transform
SinkWrite
�
11 . 标题3、SeaTunnel的落地实践
SeaTunnel的启动命令:
sh ./bin/start-waterdrop-spark.sh --master ${MASTER} --deploy-mode ${DEPLOY_MODE} --config ${config}
实际上真正执行的是
sh ${SPARK_HOME}/bin/spark-submit --class io.github.interestinglab.waterdrop.Waterdrop \
--name $(getAppName ${CONFIG_FILE}) \
--jars $(echo ${LIB_DIR}/*.jar | tr ' ' ',') \
--master ${MASTER} \
--deploy-mode ${DEPLOY_MODE} \
--driver-java-options "${clientModeDriverJavaOpts}" \
--conf spark.executor.extraJavaOptions="${executorJavaOpts}" \
--conf spark.driver.extraJavaOptions="${driverJavaOpts}" \
${sparkconf} \
${JarDepOpts} \
${FilesDepOpts} \
${assemblyJarName} ${CMD_ARGUMENTS}
�
12 .标题3、SeaTunnel的落地实践
从上面的命令可以分析得出
SeaTunnel的最终执行是依赖config 文件的spark-submit提交的一个Application应用
SeaTunnel自身config信息结构如下
env是SeaTunnel启动时需要申请的一些spark资源
这一块会在脚本中先做部分解析,并在初始化sparksession
的时候使用到
�
13 .标题3、SeaTunnel的落地实践
这种启动方式虽然简单,但却存在一个小问题:必须依赖config文件
这就要求每次任务都要生成config文件,然后再清除,虽然可以在调度脚本中动态生成,但
1、频繁的磁盘操作是否有意义?
2、是否存在更为高效的方式?
�
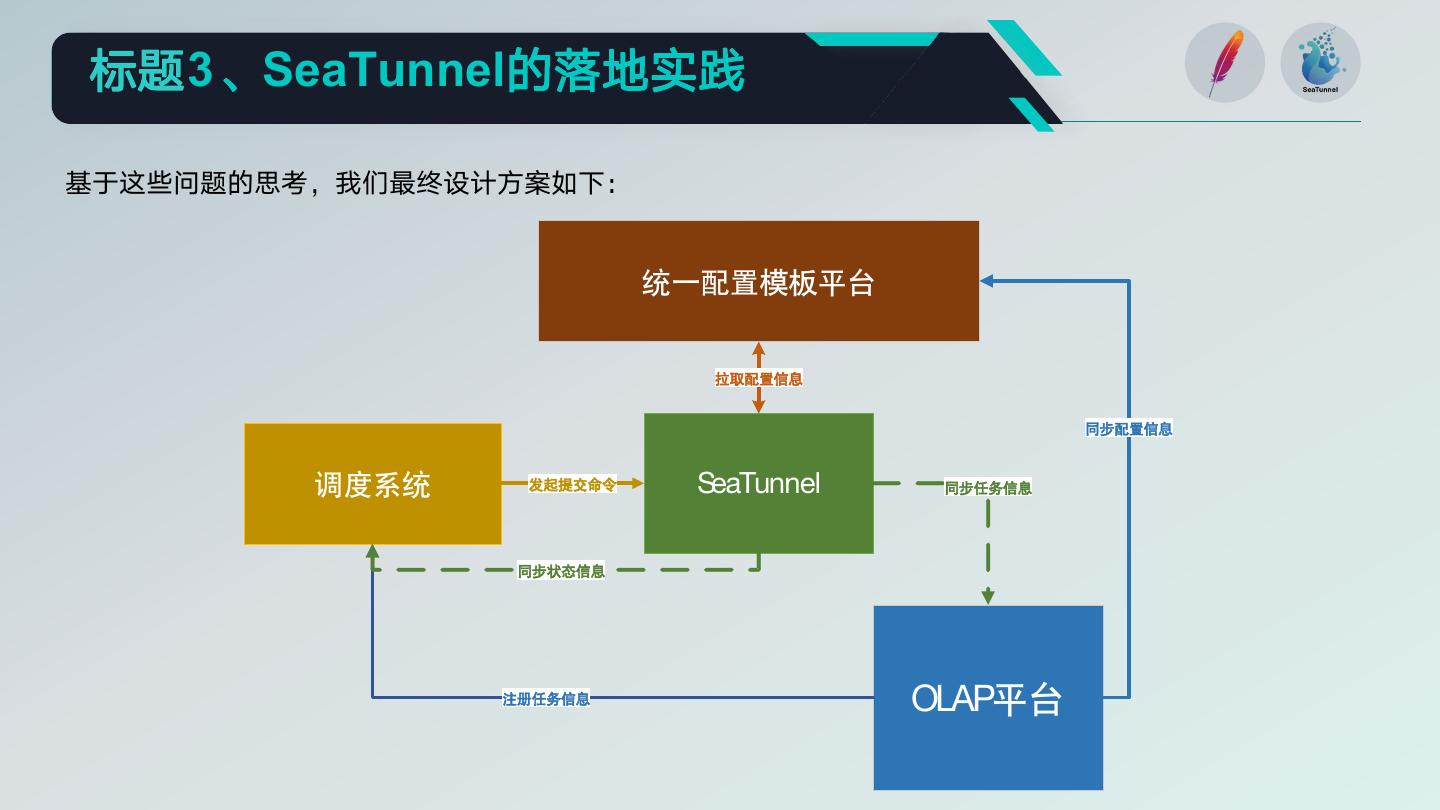
14 .标题3、SeaTunnel的落地实践
基于这些问题的思考,我们最终设计方案如下:
统一配置模板平台
拉取配置信息
同步配置信息
调度系统 发起提交命令 SeaTunnel 同步任务信息
同步状态信息
注册任务信息 OLAP平台
�
15 .标题3、SeaTunnel的落地实践
调度系统 Parquet任务
JOB 事实表
J
Hive- O Parquet
source I 表
N
维度表
KYLIN任务 CK任务
Kylin- KYLIN Clickhouse-
CK表
source cube source
�
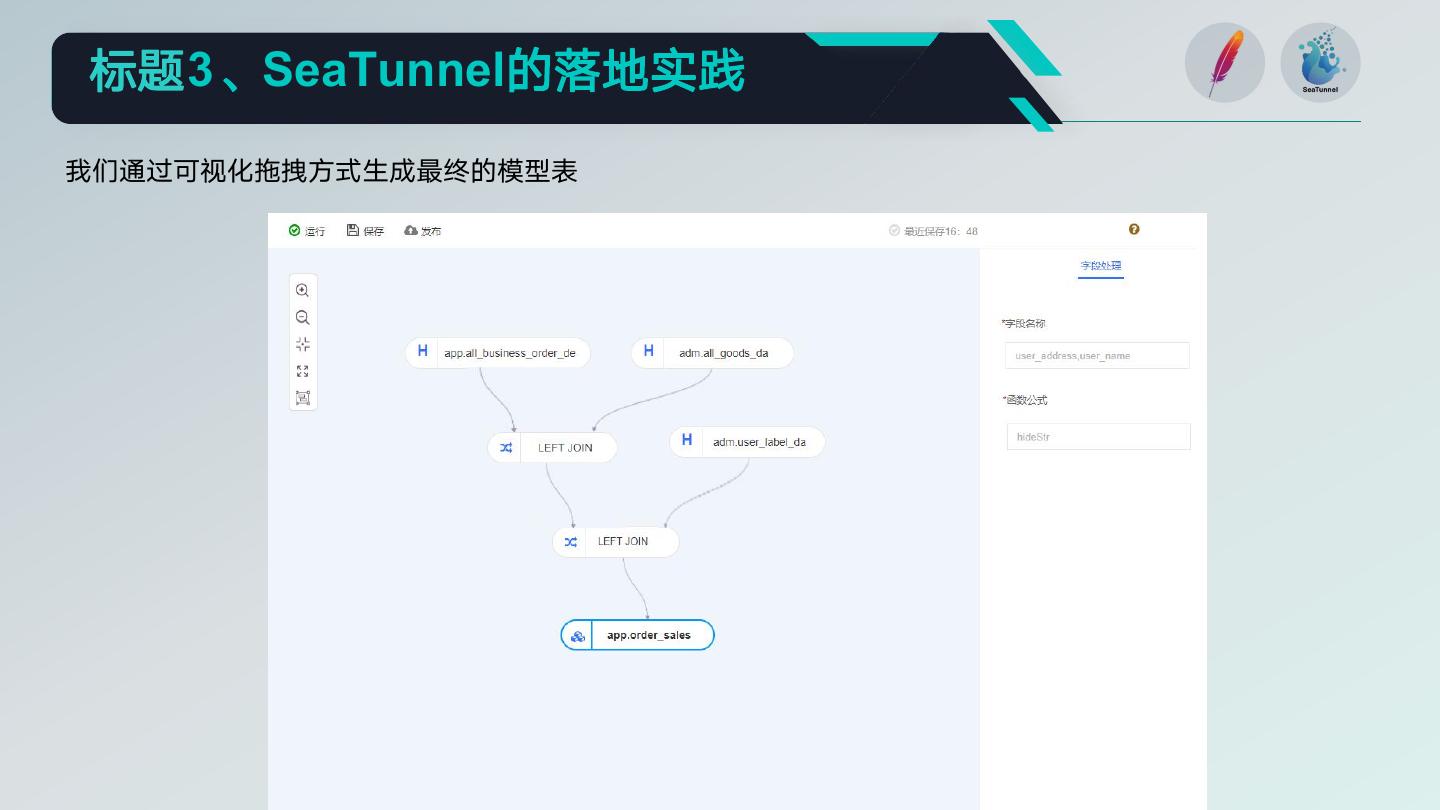
16 .标题3、SeaTunnel的落地实践
我们通过可视化拖拽方式生成最终的模型表
�
17 . 标题3、SeaTunnel的落地实践
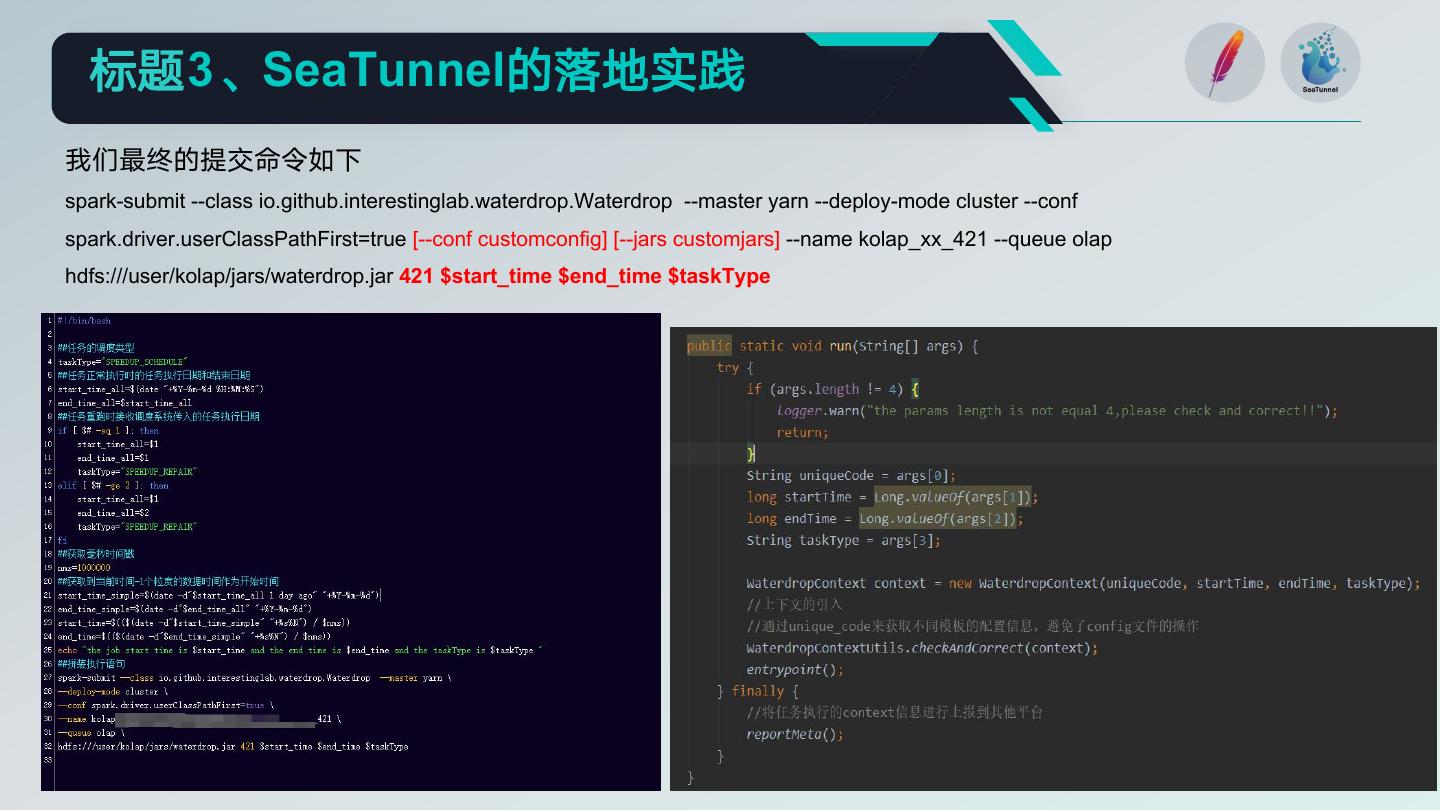
我们最终的提交命令如下
spark-submit --class io.github.interestinglab.waterdrop.Waterdrop --master yarn --deploy-mode cluster --conf
spark.driver.userClassPathFirst=true [--conf customconfig] [--jars customjars] --name kolap_xx_421 --queue olap
hdfs:///user/kolap/jars/waterdrop.jar 421 $start_time $end_time $taskType
�
18 . 标题3、SeaTunnel的落地实践
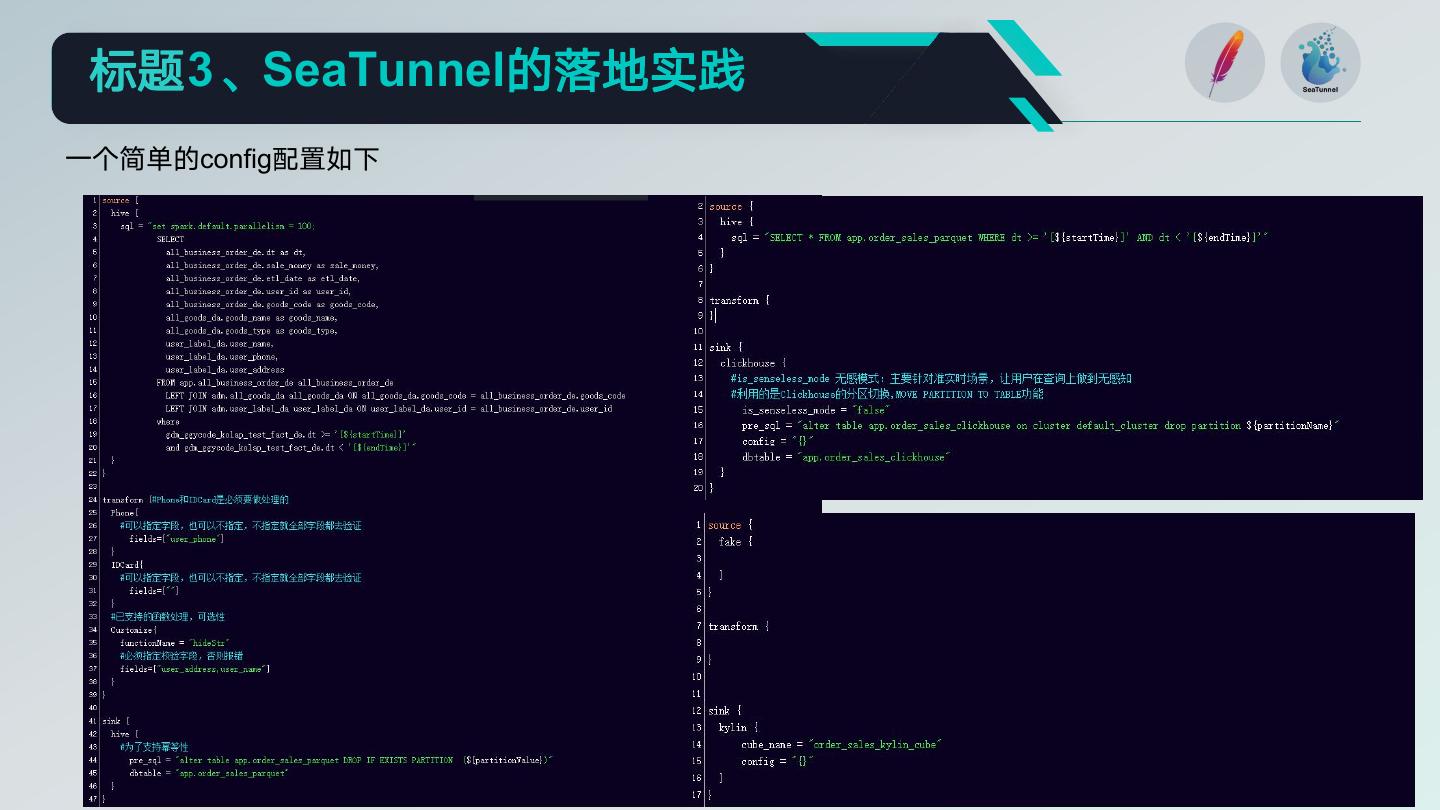
一个简单的config配置如下
�
19 . 标题3、SeaTunnel的落地实践
特别说明:Kylin的Sink端
由于kylin自身拥有一整套数据录入的逻辑,因此基于kylin的改造只是简单的调用其API操作
由于kylin只是简单的API调用和不断轮询状态,因此kylin这块的资源在统一模板配置平台就被限制的很小
注意:多segment和count distinct的锁问题
�
20 . 标题3、SeaTunnel的落地实践
任务幂等性
自定义SQL配置 设置pre_sql,使得任务多次执行都能保证数据的不重不丢
通过多SQL的输入,使得熟悉SparkSQL的用户可以自
.
己设置各种配置
. 安全管控
通过扩展transform的功能,对敏感字段进行脱
资源的动态伸缩 敏处理,增强数据的安全性
通过动态获取env配置和时间范围参数,对spark
的资源参数进行动态扩缩,实现资源利用的最大化
.
元信息上报
任务状态,数据情况等元数据信息自动上报到消息中间件
统一模板配置
通过统一模板配置平台+unique_code,避免了大量文
件的生成删除操作 无感模式
主要改造了Clickhouse的Sink端,保证了数据录入期间用户查
询的无感知和最终一致性
�
21 . 标题4、常见问题列举
Q:OOM&Too many Parts
A:可以通过配置Spark资源或者调整数据同步批量时间避免
Q:字段、类型不一致问题
A:依托血缘+快照逻辑,提前感知避免任务的失败
Q:自定义数据源&自定义分隔符
A:用户自己在统一配置模板平台指定加载额外jar信息以及分隔符信息
Q:数据倾斜问题
A:遇到,但还没做处理,思路是:在Source模块增加post处理
Q:KYLIN全局字典锁问题
A:分散任务调度时间+自定义分布式锁控制
�
22 .标题5、未来展望
1、多源数据同步
2、基于实时Flink的实现
3、接管已有采集调度平台(主要解决分库分表问题)
4、数据质量校验
�