


























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
高性能Tars开发框架的实践之路
Tars整体介绍
• Tars开发框架在性能方面的技术实践
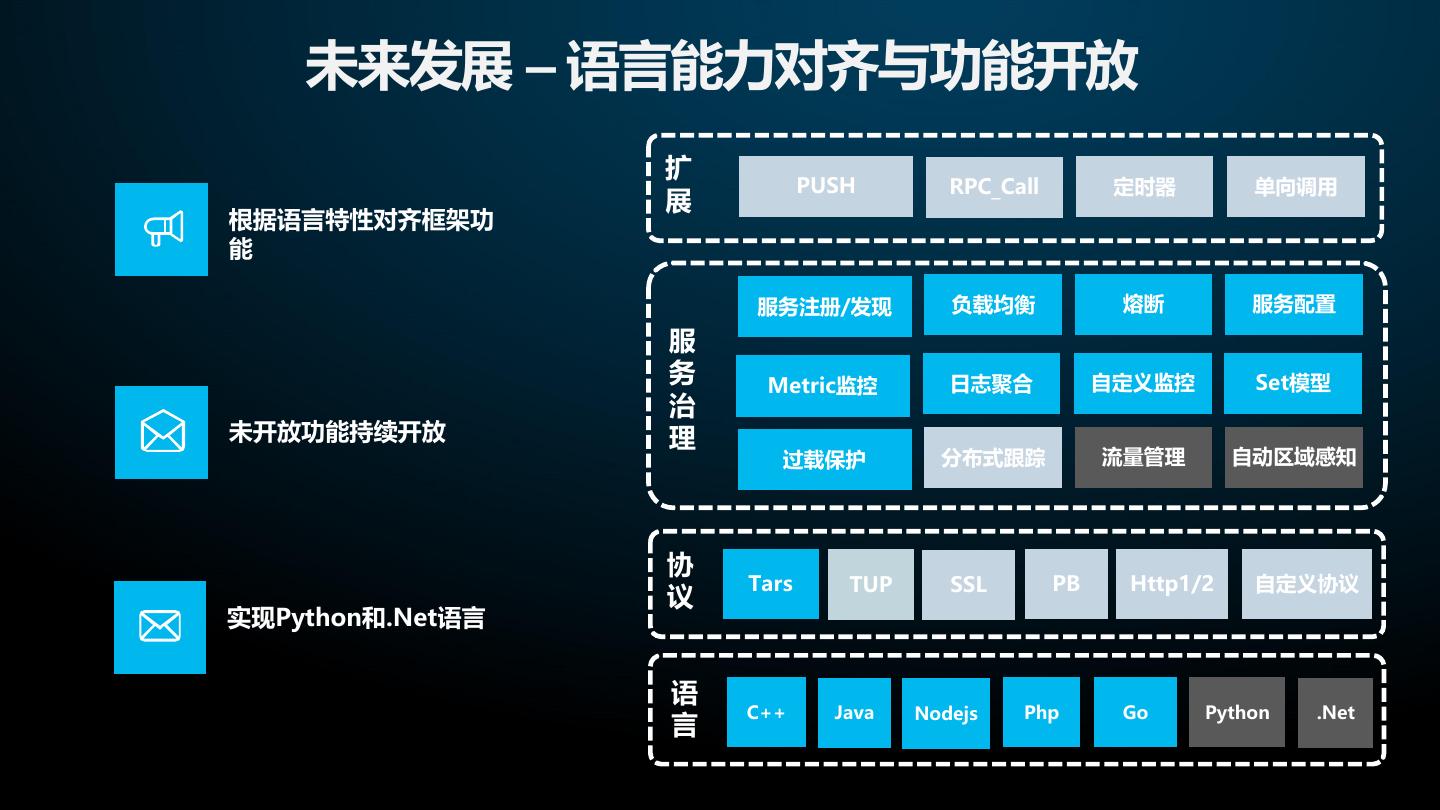
• Tars未来发展规划
展开查看详情
1 .高性能Tars开发框架 的实践之路 分享人:suziliu(刘豪) 时间:2018年12月22日 START
2 . 主要内容 • Tars整体介绍 • Tars开发框架在性能方面的技术实践 • Tars未来发展规划
3 .1. TARS整体介绍
4 . Tars微服务框架产生的背景 • 从2006年开始,腾讯接连推出了多个手机应用:手机QQ、超级QQ、手机腾讯 网、手机QQ游戏大厅、手机QQ浏览器等,随着产品、用户规模的增长,后台服 务开始面对各种各样的问题与挑战。 业务逻辑 基础组件 业务逻辑集中,耦合性强,开 代码重复率高,性能、高可用 发维护成本高,服务模型多样 性、可扩展性等方面能力参差 化,业务协议不统一 业务的多样性、复杂度 不齐,难以适应业务海量访问 、爆发性增长 发展趋势 运营管理 监控体系 运维工具各异,部署管理混乱 运营数据缺失,监控维度不立 ,规范性差,管理能力薄弱 体,故障时分析和查找问题困 难
5 . Tars发展历程 • 面对业务海量访问,我们采用微服务的思想,设计和实现了一个通用的统一应用 框架,给业务提供涉及到开发、运维的一整套解决方案,让开发和运维越来越简 单高效。 TARS产生 TARS容器化 (服务化的分布式架构) (服务混合+弹性调度) 2008 2015 2013 2017 TARS优化重构 TARS开源 (兼顾性能、易用性、扩展性) (开放共赢,合力共建)
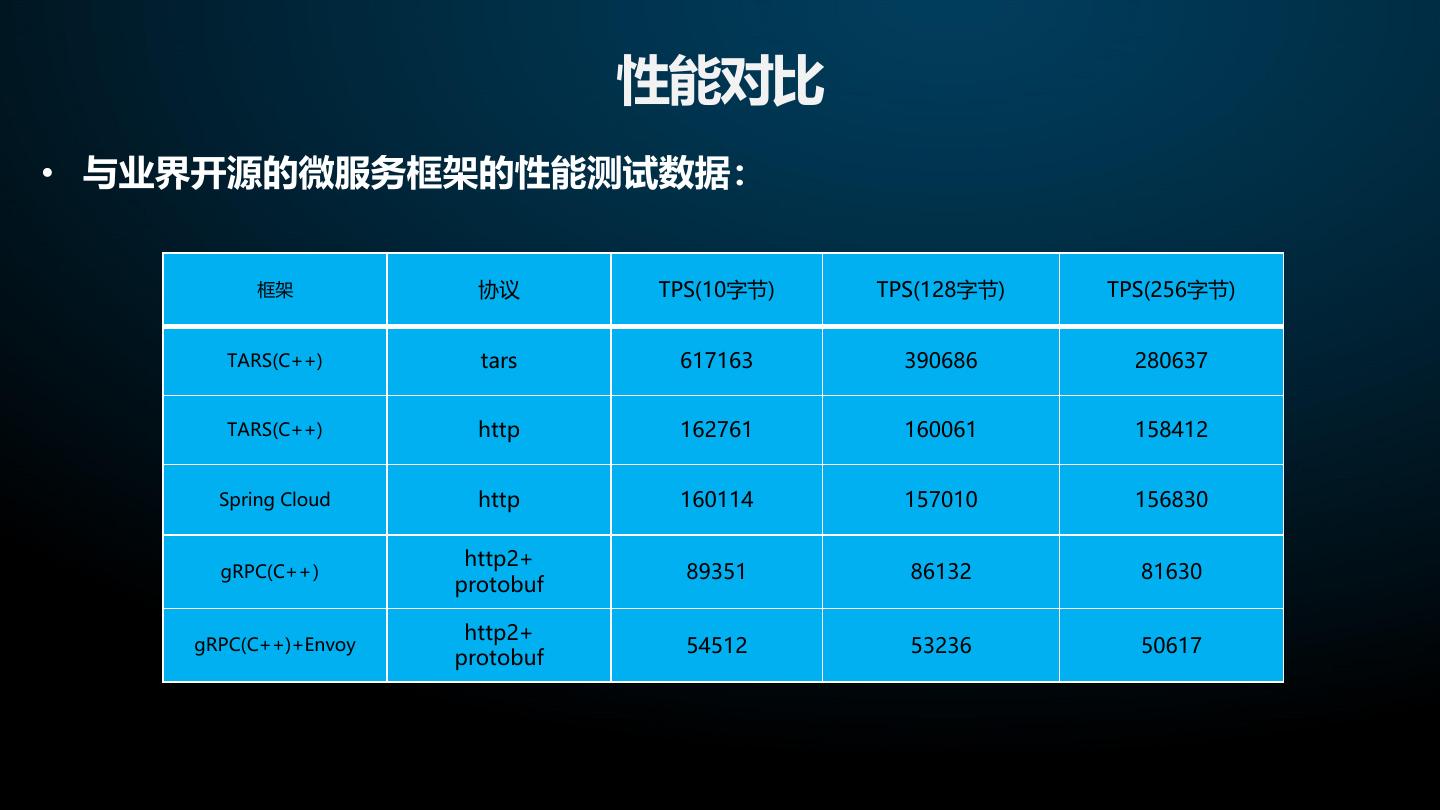
6 . Tars有什么优势 • 业界开源优秀的微服务框架现状 无服务治理类 ServiceMesh 专注于网络通信,RPC或消息队列模式,部 ServiceMesh体系,通过SideCar模式解决多 分框架支持多语言开发 技术栈问题,目前处于发展成熟期 单语言带服务治理类 多语言带服务治理类 在通信框架的基础上支持服务治理能力,单 在通信框架的基础上支持服务治理能力,多种 一编程语言实现,JAVA语言为主流 编程语言实现 Tars最大优势是在于提供服务治理和解决多技术栈的同时,可以获得更好的性能
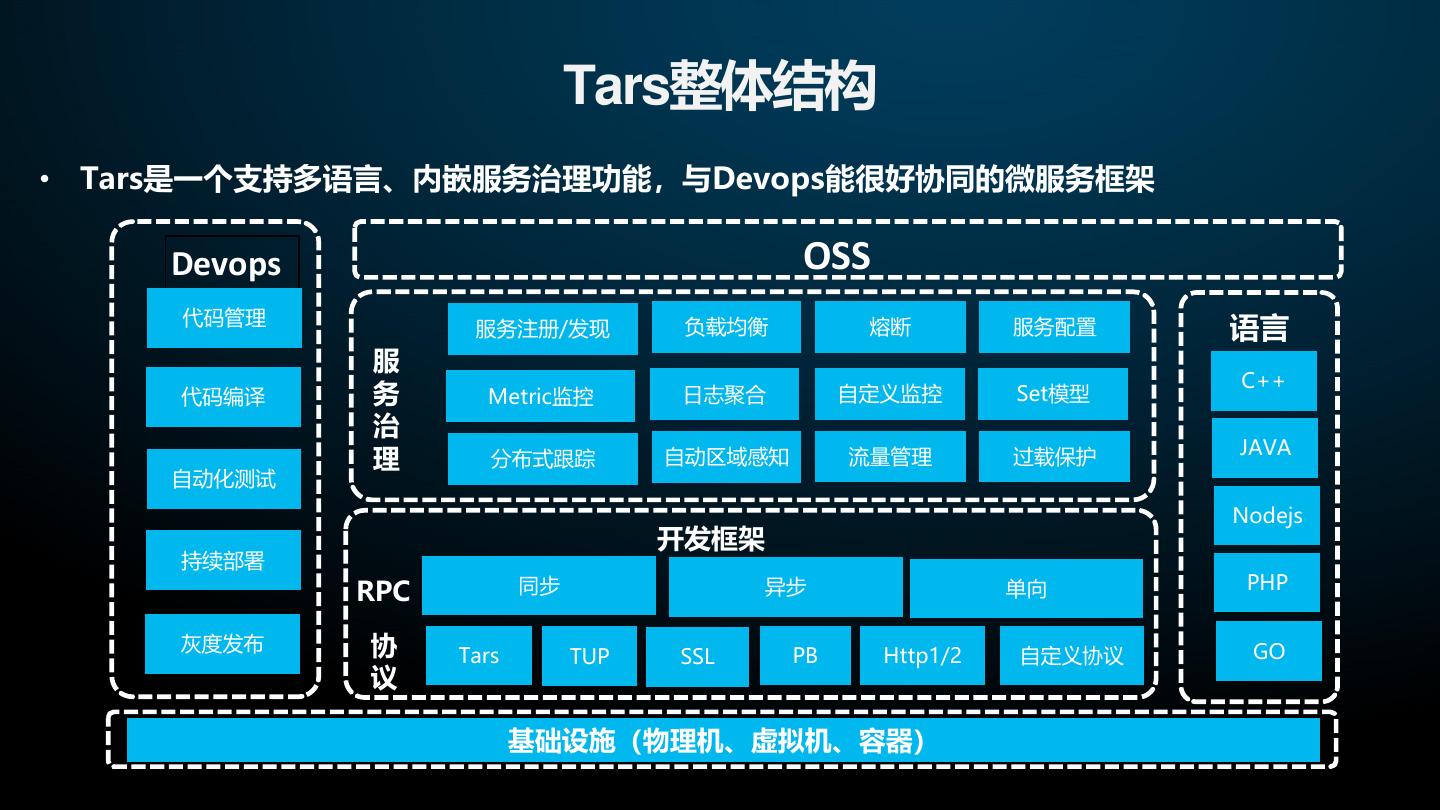
7 . Tars整体结构 • Tars是一个支持多语言、内嵌服务治理功能,与Devops能很好协同的微服务框架 Devops OSS 代码管理 服务注册/发现 负载均衡 熔断 服务配置 语言 服 C++ 代码编译 务 Metric监控 日志聚合 自定义监控 Set模型 治 JAVA 理 分布式跟踪 自动区域感知 流量管理 过载保护 自动化测试 Nodejs 开发框架 持续部署 同步 异步 PHP RPC 单向 灰度发布 协 Tars TUP SSL PB Http1/2 自定义协议 GO 议 基础设施(物理机、虚拟机、容器)
8 .2. Tars开发框架在性能方面的技术实践
9 . 影响服务框架性能的主要因素有哪些 01 02 03 04 协议 IO模型 线程模型 编程模型
10 . 最初TARS开发框架的架构设计 • 基于IDL的通信协议 • 基于RPC的调用方式 class UserServant 服务端 { virtual int32 getUserInfo(int32 uid, UserInfo &info, taf::TarsCurrentPtr current) = struct UserInfo Tars 文件 0; { }; 1 require int age; 2 require char sex; 3 optional string company; 4 optional vector<string> hobby; }; class UserProxy 客户端 interface User { { int getUserInfo( int uid, out UserInfo info); int getUserInfo(int uid,UserInfo &info, …); }; void async_getUserInfo(UserCallbackPtr cb, int uid, …); }; ✓ 高性能 ✓ 兼容性好 ✓ 代码自动生成 ✓ 多语言支持便利
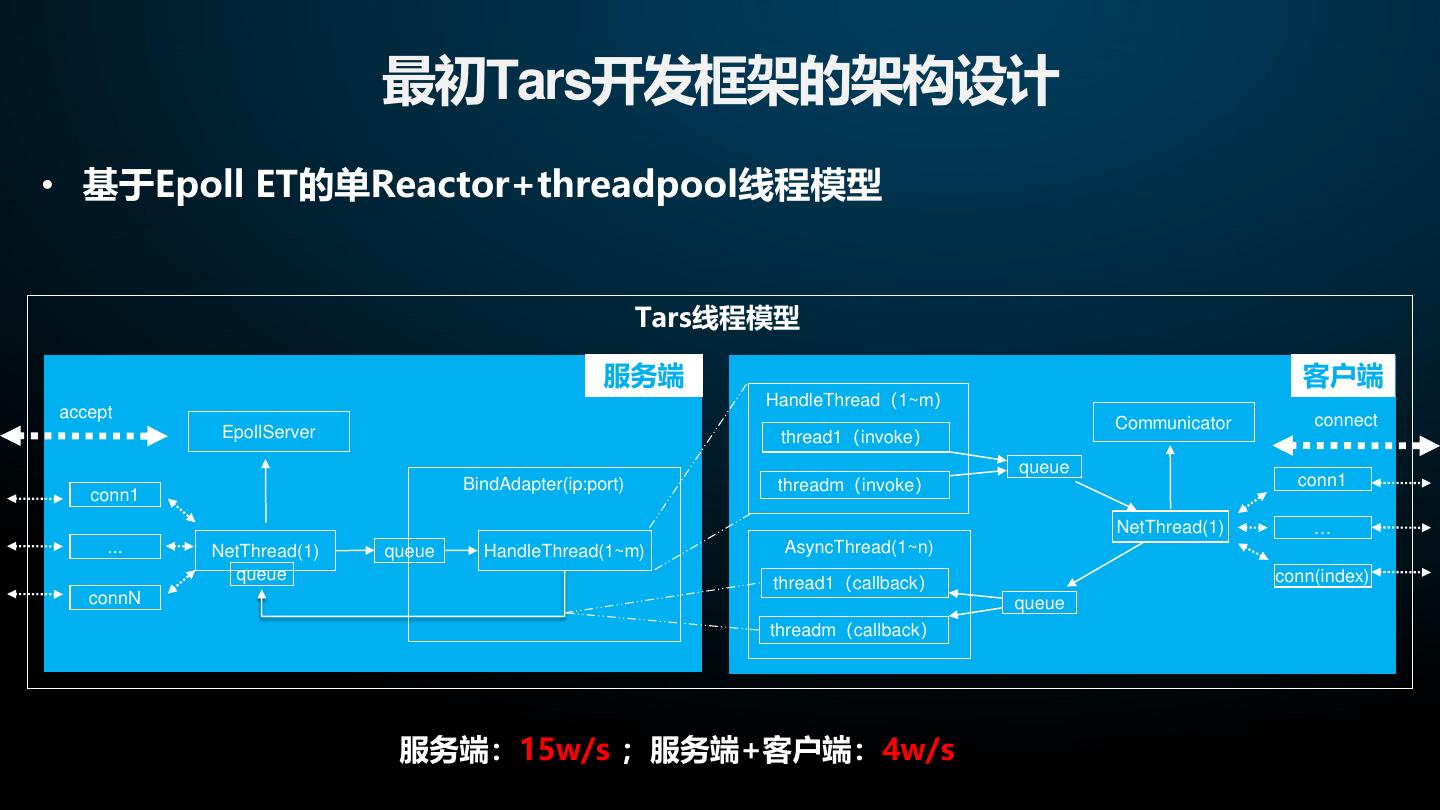
11 . 最初Tars开发框架的架构设计 • 基于Epoll ET的单Reactor+threadpool线程模型 Tars线程模型 服务端 客户端 HandleThread(1~m) accept connect Communicator EpollServer thread1(invoke) queue BindAdapter(ip:port) threadm(invoke) conn1 conn1 NetThread(1) … ... NetThread(1) queue HandleThread(1~m) AsyncThread(1~n) queue thread1(callback) conn(index) connN queue threadm(callback) 服务端:15w/s ;服务端+客户端:4w/s
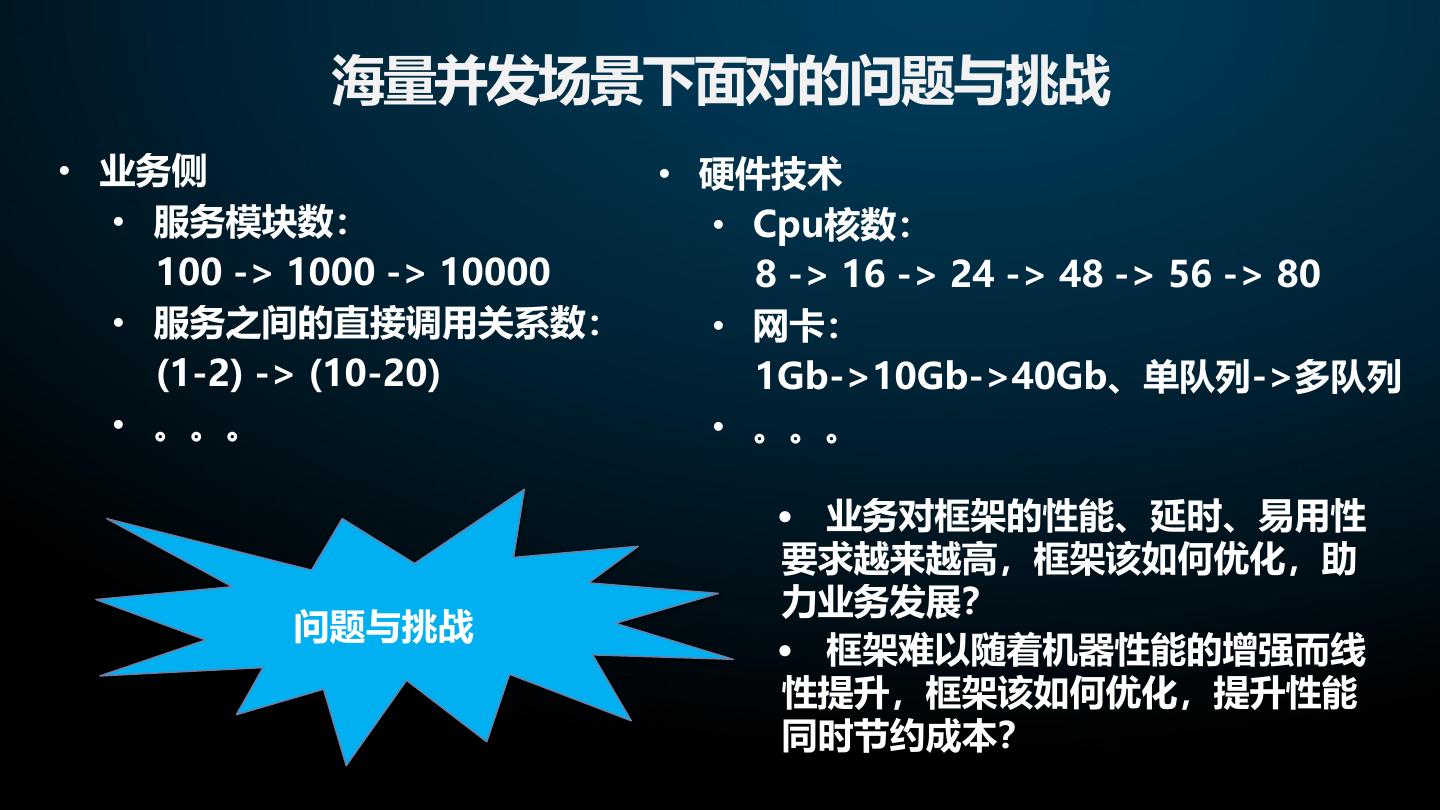
12 . 海量并发场景下面对的问题与挑战 • 业务侧 • 硬件技术 • 服务模块数: • Cpu核数: 100 -> 1000 -> 10000 8 -> 16 -> 24 -> 48 -> 56 -> 80 • 服务之间的直接调用关系数: • 网卡: (1-2) -> (10-20) 1Gb->10Gb->40Gb、单队列->多队列 • 。。。 • 。。。 • 业务对框架的性能、延时、易用性 要求越来越高,框架该如何优化,助 力业务发展? 问题与挑战 • 框架难以随着机器性能的增强而线 性提升,框架该如何优化,提升性能 同时节约成本?
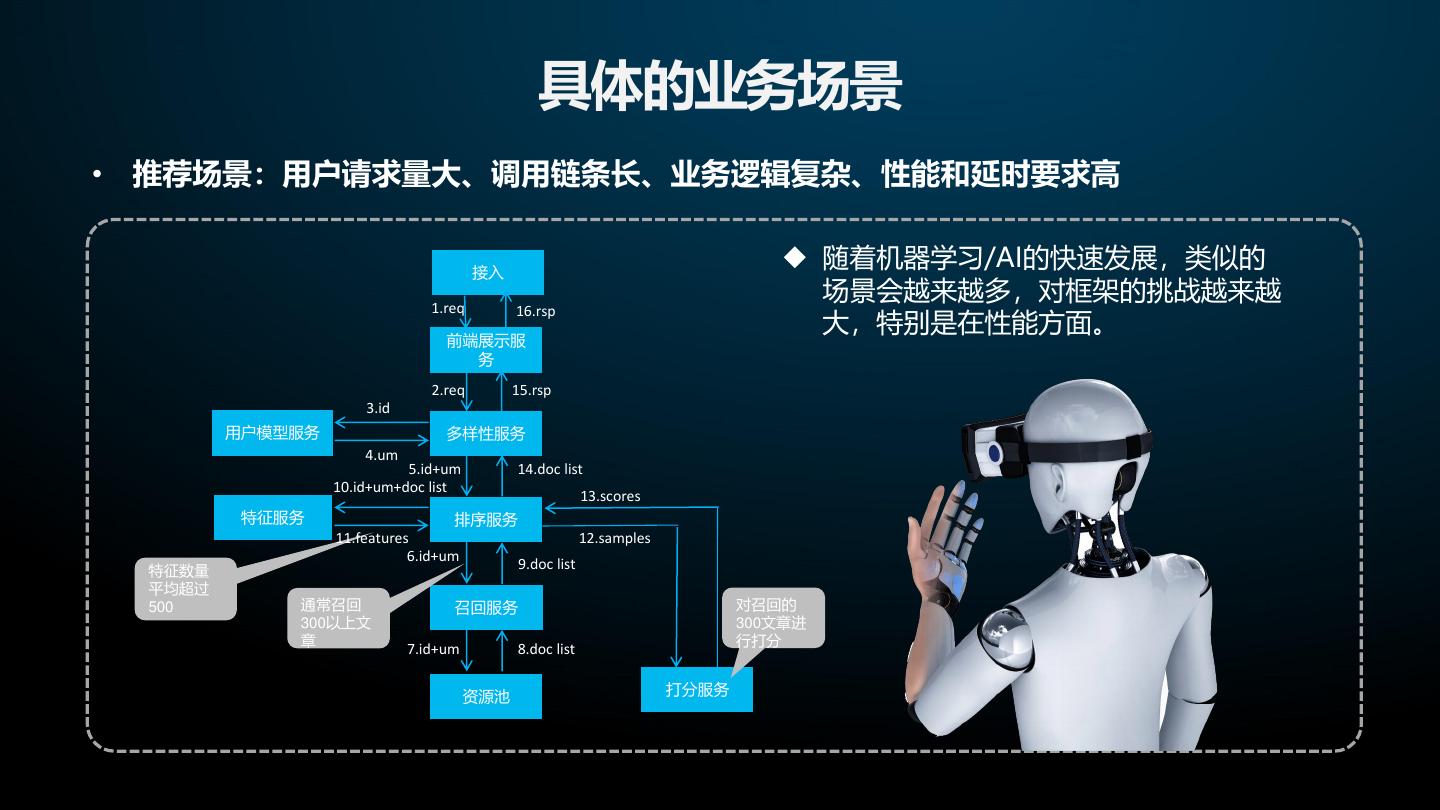
13 . 具体的业务场景 • 推荐场景:用户请求量大、调用链条长、业务逻辑复杂、性能和延时要求高 接入 随着机器学习/AI的快速发展,类似的 1.req 场景会越来越多,对框架的挑战越来越 大,特别是在性能方面。 16.rsp 前端展示服 务 2.req 15.rsp 3.id 用户模型服务 多样性服务 4.um 5.id+um 14.doc list 10.id+um+doc list 13.scores 特征服务 排序服务 11.features 12.samples 6.id+um 9.doc list 特征数量 平均超过 500 通常召回 召回服务 对召回的 300以上文 300文章进 章 行打分 7.id+um 8.doc list 资源池 打分服务
14 . 性能在理论上分析 • Tars开发框架的性能该如何提升,理论上性能能到多少? 以太网frame Preamble(8B) MAC(12B) type(2B) payload(46B-1500B) CRC(4B) gap(12B) 千兆网卡,最小的以太网frame为84B,理论上每秒能发送148wframe。 业务层 Data Packet 10B左右 应用层 Tars Packet 40B左右 传输层 TCP Packet 20B 网络层 IP Packet 20B 包含一个10B业务数据包的以太网frame大小为128B左右, 链路层 Frame 34B 理论上Tars服务端的处理性能上限为97w/s(125MB/128)。 物理层 Bits
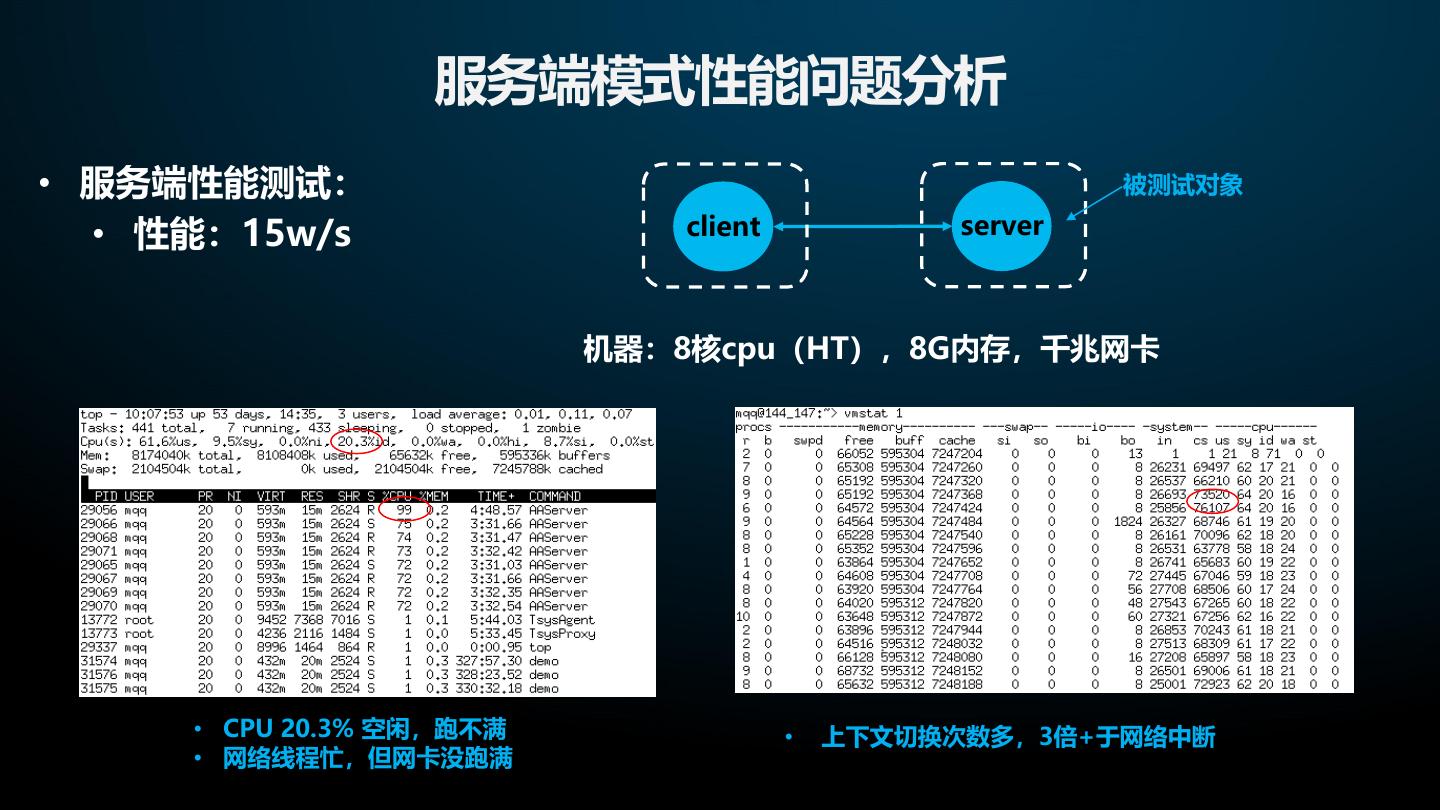
15 . 服务端模式性能问题分析 • 服务端性能测试: 被测试对象 • 性能:15w/s client server 机器:8核cpu(HT),8G内存,千兆网卡 • CPU 20.3% 空闲,跑不满 • 上下文切换次数多,3倍+于网络中断 • 网络线程忙,但网卡没跑满
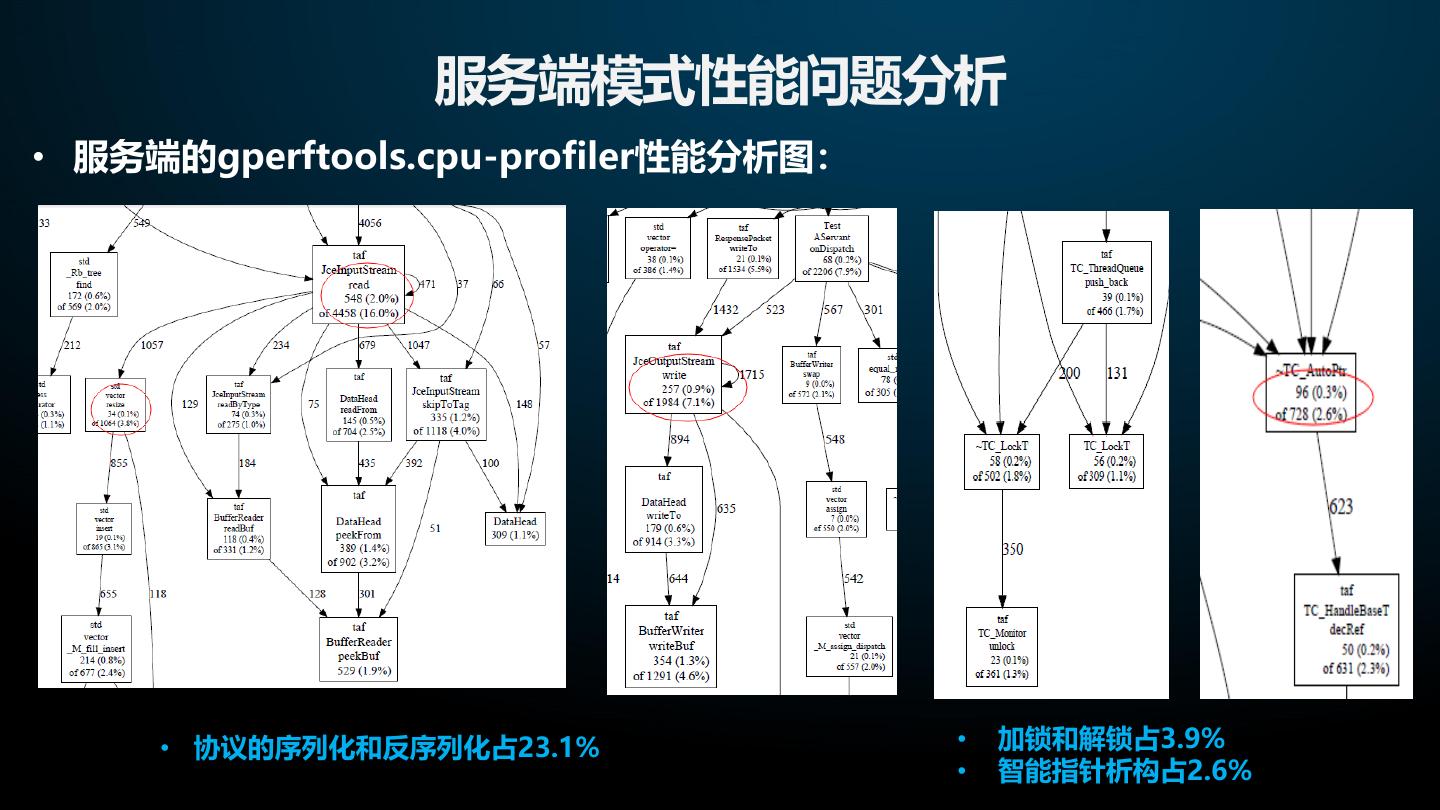
16 . 服务端模式性能问题分析 • 服务端的gperftools.cpu-profiler性能分析图: • 协议的序列化和反序列化占23.1% • 加锁和解锁占3.9% • 智能指针析构占2.6%
17 . 服务端+客户端模式性能问题分析 被测试对象 • 服务端+客户端性能测试: • 性能:4w/s client proxy server 机器:8核cpu(HT),8G内存,千兆网卡 • CPU 39.8% 空闲,跑不满 • 上下文切换次数多,8倍+于网络中断 • 网络线程忙,但网卡没跑满
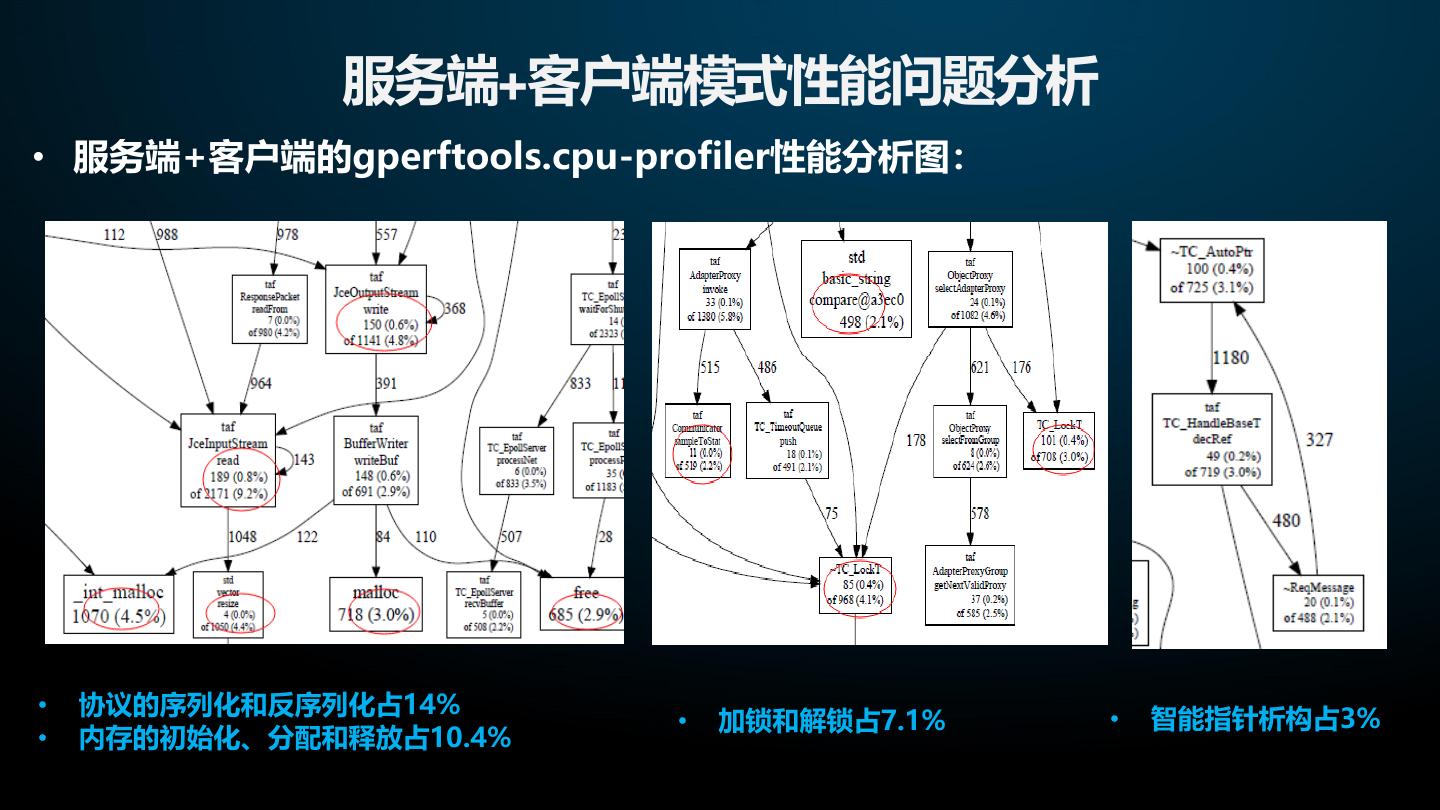
18 . 服务端+客户端模式性能问题分析 • 服务端+客户端的gperftools.cpu-profiler性能分析图: • 协议的序列化和反序列化占14% • 加锁和解锁占7.1% • 智能指针析构占3% • 内存的初始化、分配和释放占10.4%
19 . 性能问题分析总结 网络线程很忙 CPU:idle 太多的上下文切换 Network:idle 序列化和反序列化CPU消耗大 + 加锁和解锁操作频繁 Disk I/O:idle 内存的分配和释放频繁 Memory:enough 。。。
20 . 优化思路 • 协议 01 02 • 网络IO 整体思路 • 编程模型 04 03 • 线程交互
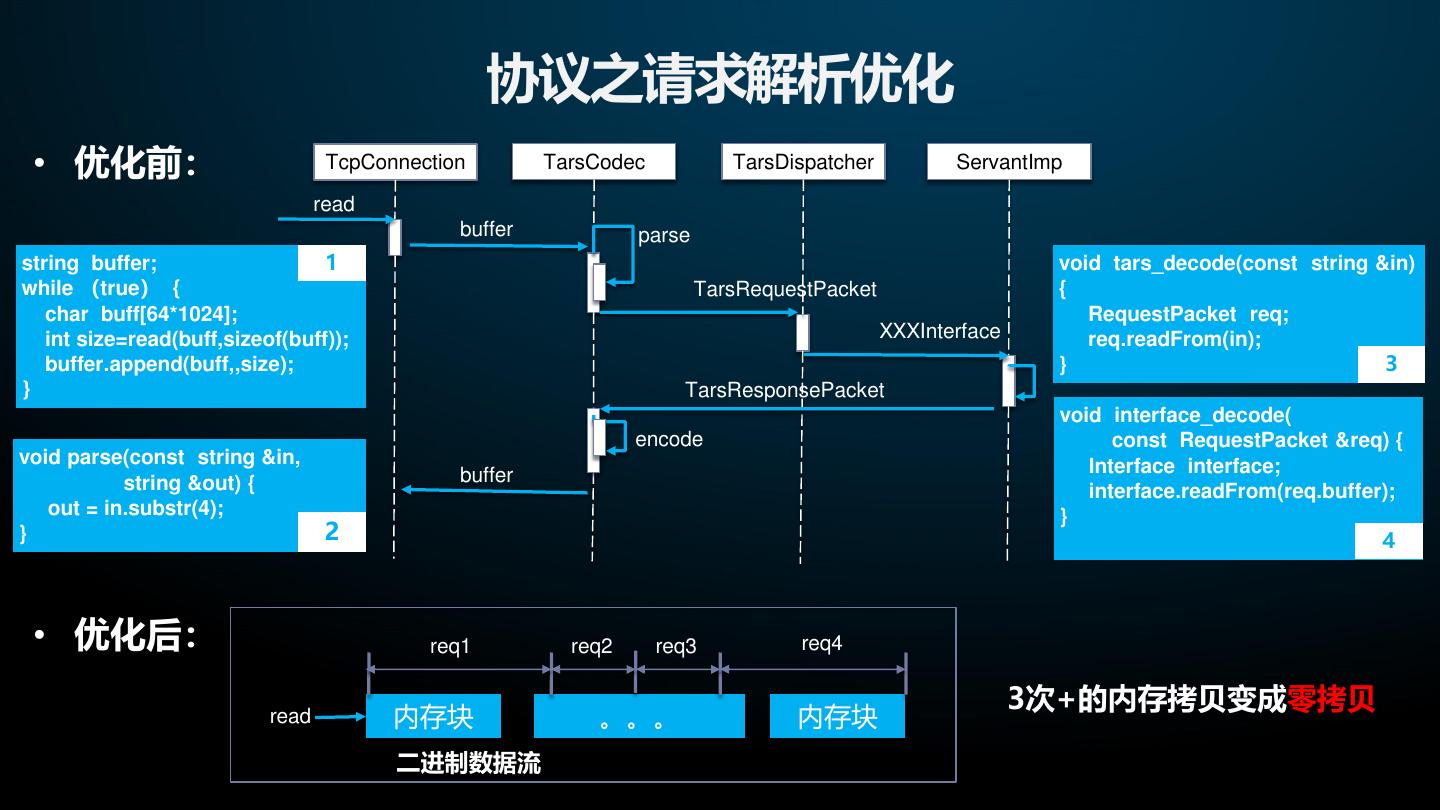
21 . 协议之请求解析优化 • 优化前: TcpConnection TarsCodec TarsDispatcher ServantImp read buffer parse string buffer; 1 void tars_decode(const string &in) while (true){ TarsRequestPacket { char buff[64*1024]; RequestPacket req; int size=read(buff,sizeof(buff)); XXXInterface req.readFrom(in); buffer.append(buff,,size); } 3 } TarsResponsePacket void interface_decode( encode const RequestPacket &req) { void parse(const string &in, Interface interface; string &out) { buffer interface.readFrom(req.buffer); out = in.substr(4); } } 2 4 • 优化后: req1 req2 req3 req4 3次+的内存拷贝变成零拷贝 read 内存块 。。。 内存块 二进制数据流
22 . 协议之编解码优化 结构体 Tars协议编码: 头信息 实际数据 tag 必选字段 Type Tag 1 Tag 2 (4 bits) (4 bits) (1 byte) 字段类型 • 问题: 接口 • 编码时,会不断申请释放内存 • 解码时,元数据的读取和定位存在重复读 TarsOutputStream<BufferWriter> os; ti.writeTo(os); • 解决方案: 编码 • 减少函数调用的开销 TarsInputStream<BufferReader> is; • 减少临时对象的定义,直接类型转换 is.setBuffer(os.getBuffer(), os.getLength()); • 编码时,预先计算出所需要的内存空间 ti.readFrom(is); 解码 • 解码时,只遍历数据一遍
23 . 网络IO优化 • 问题: • 解决方案: • 网络线程忙 • 使用多网络线程收发包(可配) • 减少内存拷贝(使用writev发送了多 个不连续的内存数据块) • 减少系统调用(buff为空时,先 write,再epoll;read或者write数 据时,如果返回长度小于缓存大小, 就可以退出循环了)
24 . 线程交互之队列优化 deque • 问题: iothread1 handle1 … … • 上下文切换频繁 iothreadN lock lock handleN • 出入队列请求信息存在内存拷贝 struct Item { Item *p = new Item(); … p->data.swap(input); string data; //p->data = std::move(input); … } enqueue(p); • 解决方案: iothread1 cas cas handle1 • 无锁队列 … … • 使用swap或者move iothreadN 定长数组 handleN
25 . 编程模型优化之异步编程 • Callback异步编程: Svr1 xxsvr … SvrN
26 . 编程模型优化之异步编程 • future/promise编程: Svr1 xxsvr … SvrN
27 . 编程模型优化之异步编程 • 协程编程: Svr1 xxsvr … SvrN
28 . 其它细节优化 • 日志打印,先判断等级,再确定输出 • 日志异步批量落盘 • 编译时使用O2 • vector预先分配好空间 • 使用c++11后的转移语义 • 监控统计数据按接口名合并 • 使用snprintf替换Ostringstream • strncasecmp替换strcmp(upper(a), upper(b)) • …
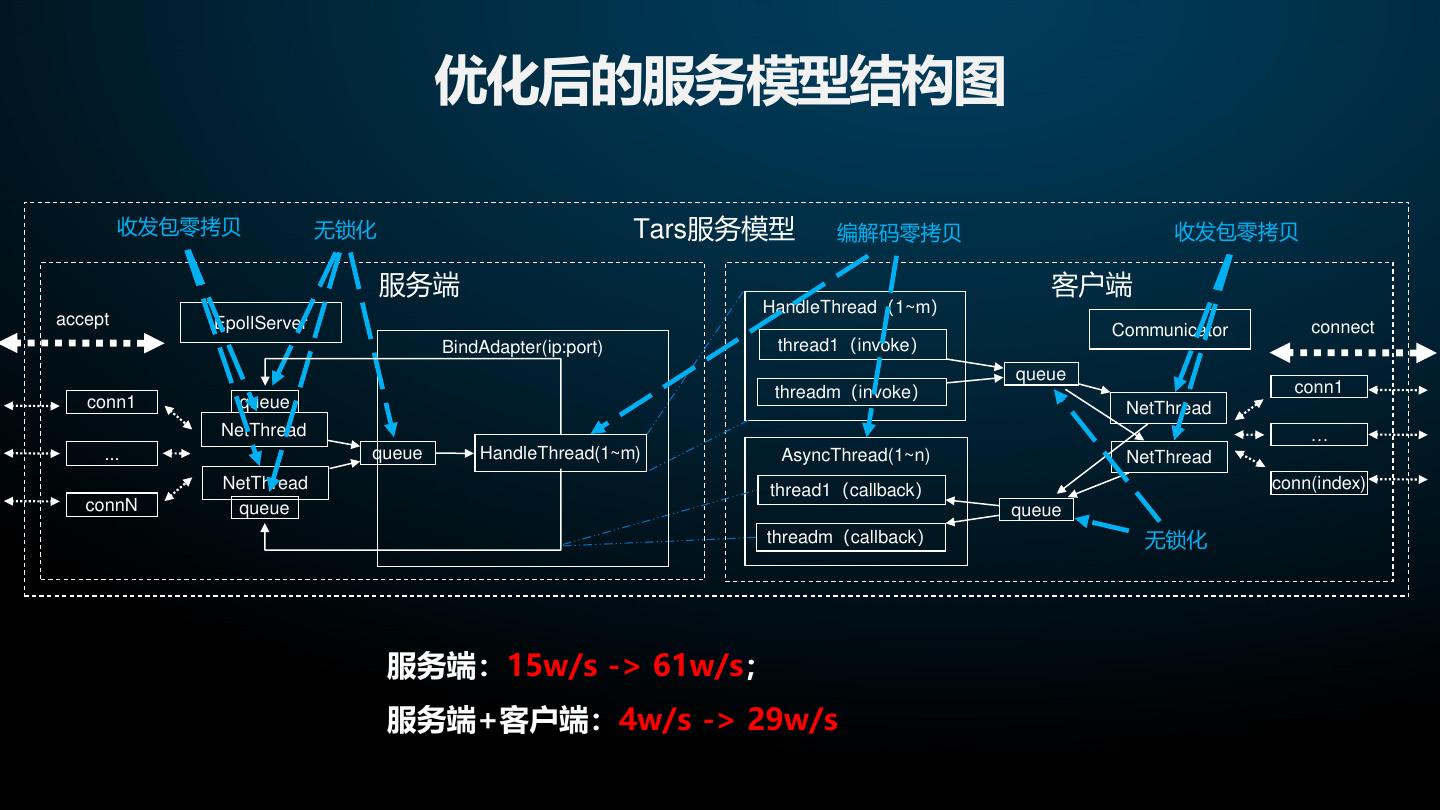
29 . 优化后的服务模型结构图 收发包零拷贝 无锁化 Tars服务模型 编解码零拷贝 收发包零拷贝 服务端 客户端 HandleThread(1~m) accept EpollServer connect Communicator BindAdapter(ip:port) thread1(invoke) queue threadm(invoke) conn1 conn1 queue NetThread NetThread … ... queue HandleThread(1~m) AsyncThread(1~n) NetThread NetThread thread1(callback) conn(index) connN queue queue threadm(callback) 无锁化 服务端:15w/s -> 61w/s; 服务端+客户端:4w/s -> 29w/s
3秒后跳转登录页面
去登陆

