展开查看详情
1 .Milvus在电商场景中的
千万级素材搜索实践
James Zhang
飞书深诺集团 算法工程师
�
2 .● 飞书深诺集团(https://www.meetsocial.com/)是专注海外数字营销解决方案的综合服务集团,
为中国出海企业提供可定制组合的全链路服务产品,满足游戏、APP、电商、品牌等典型出海场
景需求,陪伴品牌应对海外市场的种种挑战。
�
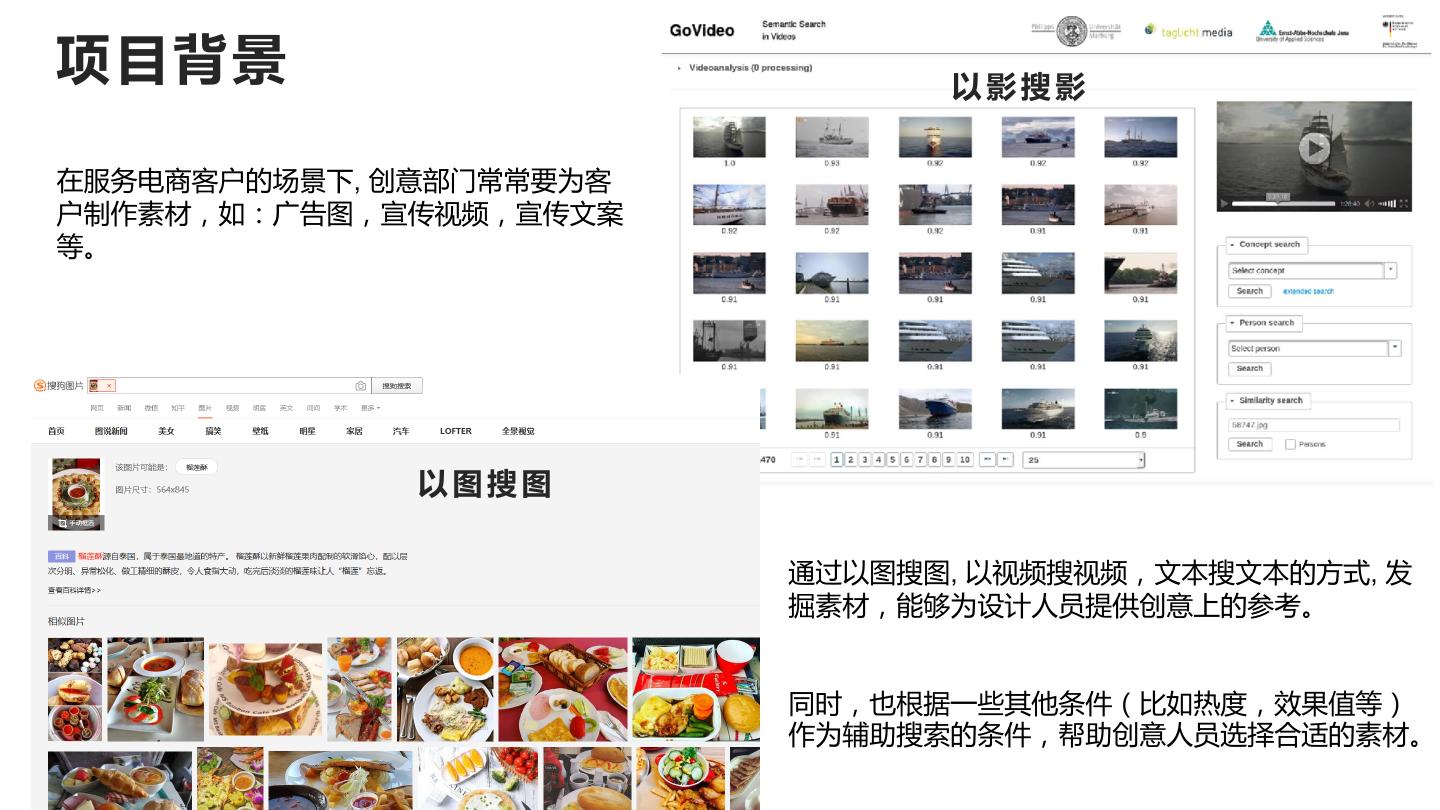
3 .项目背景 以影搜影
在服务电商客户的场景下, 创意部门常常要为客
户制作素材,如:广告图,宣传视频,宣传文案
等。
以图搜图
通过以图搜图, 以视频搜视频,文本搜文本的方式, 发
掘素材,能够为设计人员提供创意上的参考。
同时,也根据一些其他条件(比如热度,效果值等)
作为辅助搜索的条件,帮助创意人员选择合适的素材。
�
4 .技术要求
● 实时返回 ---- 高 (上层调用者还要做一些业务操作, 要求做到1s内返回)
● 并发负载 ---- 中
● 向量检索的准确性 ---- 低
● 内存资源占用 ---- 中 (部署的机器内存有一定的限制)
�
5 .架构示意
Milvus: 向量相似检索
Redis: 业务缓存
Nginx: 负载均衡
Flask+Gunicorn: Web服务
Supervisor: 进程启动与异
常重启
Docker: 容器隔离部署
�
6 .选择合适的索引
● Milvus索引类型
暴力, 无索引
Kmeans聚类 à 倒排文件索引 (占用空间比原向量大一些)
ScalarQuantifier: 浮点数 à 无符号整形 à 聚类 (大
小可压缩至 1/3~1/4)
ProductQuantifier: 压缩成低维向量 à 聚类 à 倒排索引
(根据分段参数, 可以压缩到很小)
为向量构建节点邻接图, 并分层搜索, 速度快, 准
确率高, 占用空间大 (约原向量120%)
● https://milvus.io/docs/v1.1.1/index.md#CPU
�
7 .选择合适的索引
● 图片/视频/文本向量在检索出来之后, 上层调用还要做一些业务操作, 留给
我们的接口的时间就不能太多。
● 由于对速度的要求高, 同时机器内存又有一定的限制, 我们选用了 IVF_PQ
作为向量索引,这是一种有损压缩的向量索引。
�
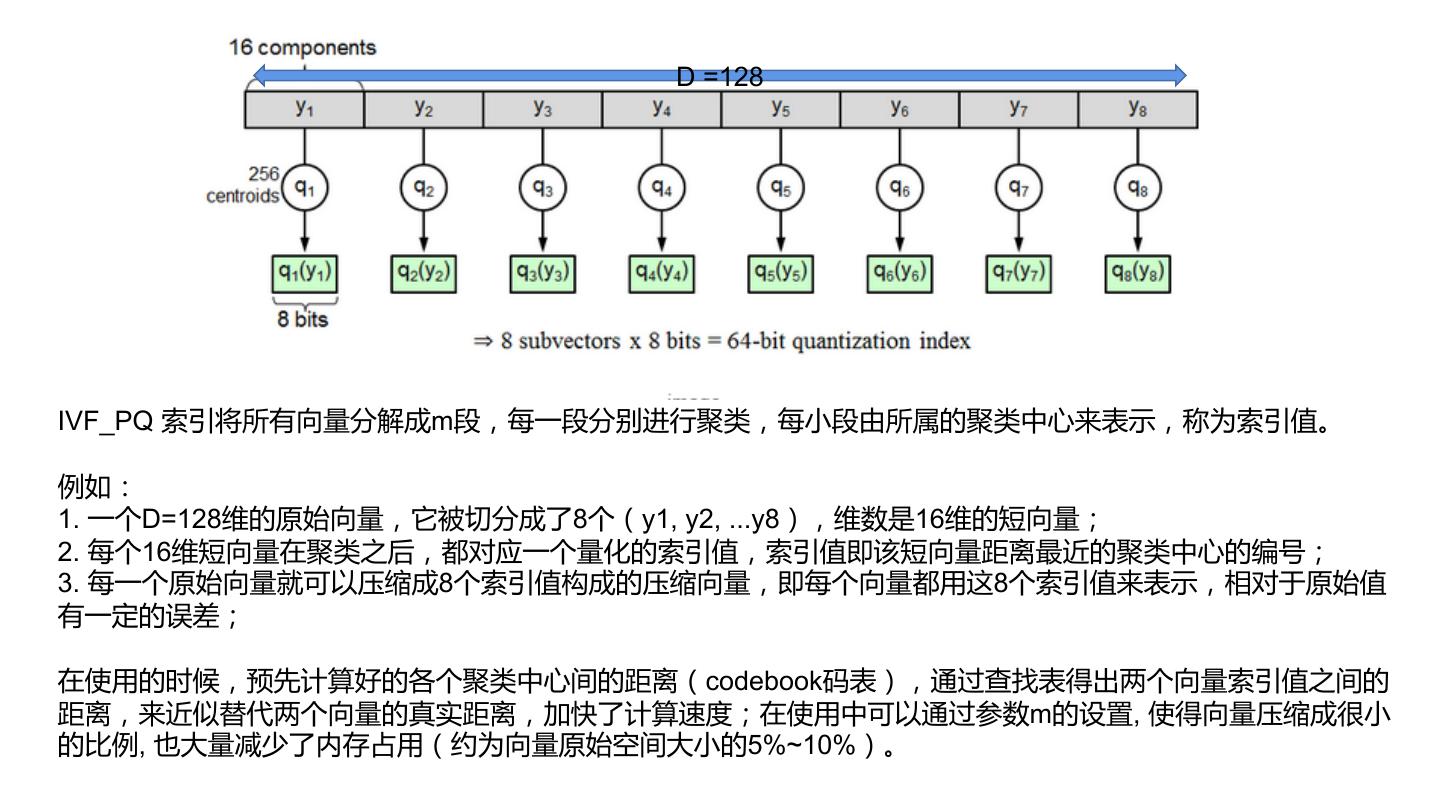
8 . D =128
IVF_PQ 索引将所有向量分解成m段,每一段分别进行聚类,每小段由所属的聚类中心来表示,称为索引值。
例如:
1. 一个D=128维的原始向量,它被切分成了8个(y1, y2, ...y8),维数是16维的短向量;
2. 每个16维短向量在聚类之后,都对应一个量化的索引值,索引值即该短向量距离最近的聚类中心的编号;
3. 每一个原始向量就可以压缩成8个索引值构成的压缩向量,即每个向量都用这8个索引值来表示,相对于原始值
有一定的误差;
在使用的时候,预先计算好的各个聚类中心间的距离(codebook码表),通过查找表得出两个向量索引值之间的
距离,来近似替代两个向量的真实距离,加快了计算速度;在使用中可以通过参数m的设置, 使得向量压缩成很小
的比例, 也大量减少了内存占用(约为向量原始空间大小的5%~10%)。
�
9 .设置索引参数
我们设置的 index_file_size=2048
根据milvus官方提供的公式,我们计算得出合适的
索引参数:
nlist=1024, m=8
�
10 .还想再快一些? 使用分区提高速度
● 目前数据中,图片、视频、文本都已经上千万,未来预计将扩充到一亿左右, 为了提高检索速度,
分区变得十分必要。
集合中的每个数据段依次建立索引,并将索引
单独存为一个文件;
假如检索n个相似向量, segment有3个, 在搜
索时先在每个segment的index文件中找出n个,
再合并在一起(共3*n个)互相比较找出最终的n
个;
https://milvus.io/docs/v1.1.1/storage_con
cept.md
�
11 .● 目前数据,图片4kw, 视频1kw,文本3kw+, 预计继续增加中...为了提高检索速度, 分区变得十分
必要。我们通过一些业务属性, 根据属性值做笛卡尔积操作来建立分区:
● 例如,我们向量对应的Item有两个属性: X 1
● 属性A,取值 X,Y,Z
Y 2
● 属性B,取值 1, 2, 3, 4
Z ...... 3
4
● 那么建立分区: X1,X2,X3,X4,Y1,Y2,......Z4, 一共12个。
● 通过分区操作,我们将每个分区的向量规模控制在600w以下, 进一步提高了检索速度。
�
12 .● 需要注意的是, 用来建立分区的属性应该是不会变动的基本属性, 因为如果
发生变动, 重新建立分区, 导入数据, 建立索引是非常漫长的过程。
● 另外分区及属性值不能太多, 否则各个属性值相乘(笛卡儿积)会让数量变得
非常庞大, 使程序变得过于复杂。更多的属性检索或筛选,我们在milvus
向量搜索的结果上另外封装一层业务接口来实现。
�
13 . 系统效果
服务以REST接口的形
式对外提供,前端团
队调用接口,将结果
展示在界面上。
�
14 .性能指标
● 图片数量:4kw,向量维数:2048,单条检索耗时:200~300 ms
● 视频数量:1kw,向量维数:2048,单条检索耗时:约100 ms
● 文本数量:3kw+,向量维数:768维,单条检索耗时:约100 ms
● 并发数大时(>50),时延会增加,有可能超过1s
● 参考资料:如何轻松玩转十亿向量检索(SIFT1B)
● https://milvus.io/cn/blogs/2019-08-29-vector-search-billion.md
�
15 .一些经验与总结
● milvus集成各种常见向量索引, 能满足工程中大部分的需求,操作方便程
度和检索速度都达到了工业级的水准, 基本上做到了开箱即用;
● 其他类型(字符型,整型)的属性筛选,目前还不支持;
● 总体来说,对于需要快速构建向量检索服务,又不想花太大成本(没时间/
人力去搞ES,SOLR)的轻量级项目来说,Milvus是一个很好的选择。
�
16 .Reference
● Product quantization for nearest neighbor search -- Hervé Jégou, Matthijs Douze, Cordelia
Schmid (乘积量化)
● https://zhou-
yuxin.github.io/articles/2020/IVFPQ%E7%AE%97%E6%B3%95%E5%8E%9F%E7%90%86/index.ht
ml (IVFPQ检索算法)
● https://blog.csdn.net/u011622208/article/details/107936456 (IVFFlat检索算法)
● Deep learning for content-based video retrieval in film and television production -- M. Mühling,
Nikolaus Korfhage, Eric Müller
�