





























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Milvus 2.0 背后的设计原理-云原生的向量数据库
展开查看详情
1 .2021.06 Milvus Shanghai Meetup Design principles behind Milvus 2.0 – build a cloud-native vector database
2 .Who we are Open-source company behind Milvus Mission: Reinvent data science Who I am 7 years working experience focused on building database/storage systems. After graduation from Cornell university, I worked for Oracle, HEDVIG and Alibaba cloud database. Now I work for ZILLIZ as the director of engineering on Milvus project.
3 . 01 Motivation of building Milvus 2.0 02 Quick Recap C O N T E N T S 03 Milvus 2.0 Architecture overview 04 Feature Highlights 05 Real-world cases 06 Future Works
4 . Motivation of Building Milvus 2.0
5 .What is Milvus Ø It’s a database with CRUD support, Milvus now rank 285 at DB-Ranking list. Ø Designed for efficient similarity search on dense vectors Ø Highly scalable and robust, performance on demand Ø Opensource, world’s most popular, maybe the world’s most advanced vector database Not a relational database -> No ACID, Approximate Not a search engine like elastic search -> Semantic Search
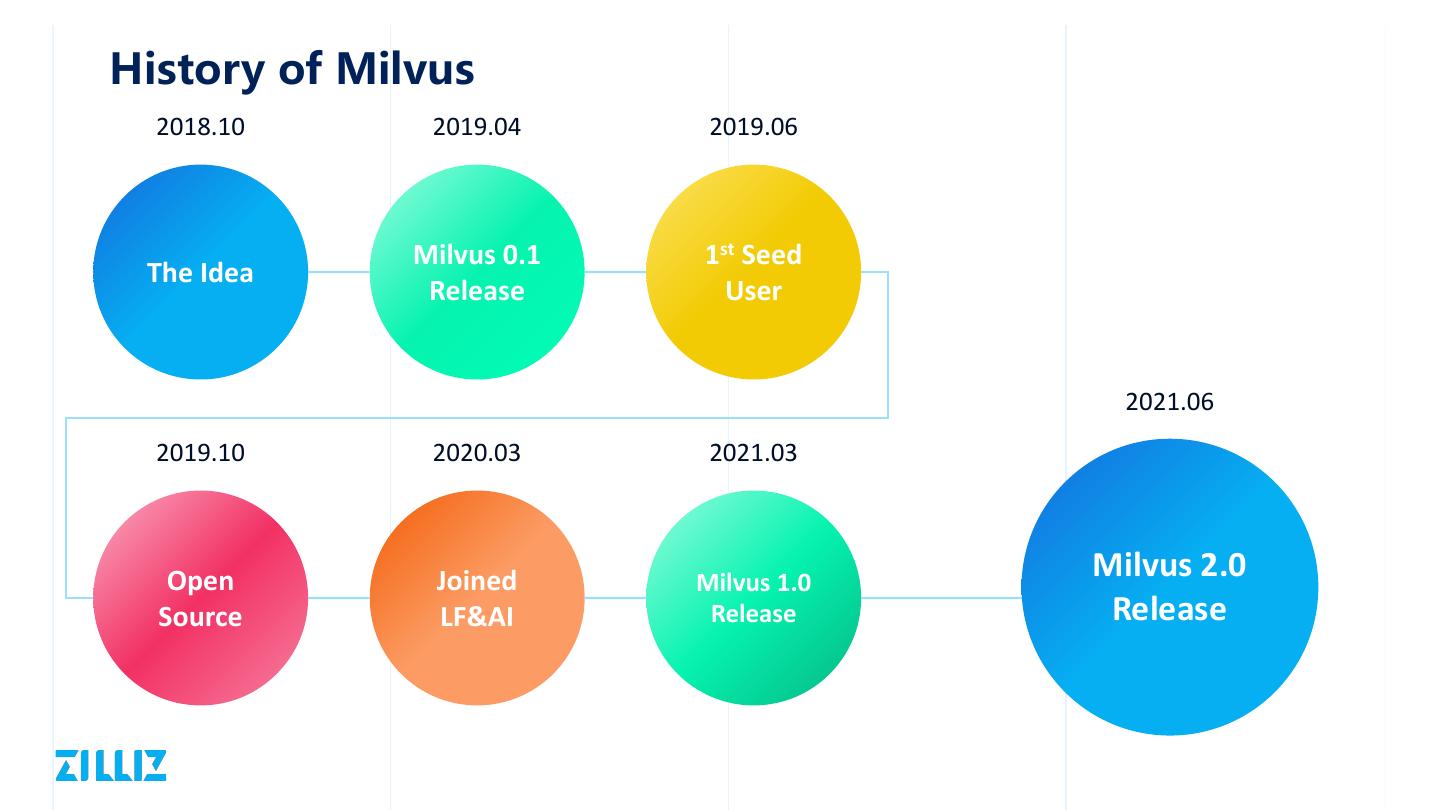
6 .History of Milvus 2018.10 2019.04 2019.06 Milvus 0.1 1st Seed The Idea Release User 2021.06 2019.10 2020.03 2021.03 Open Joined Milvus 1.0 Milvus 2.0 Source LF&AI Release Release
7 .Key issues for Milvus 1.x Ø Data silo Persistence Performance Ø Couples everything together Ø Lack of elasticity cost Functionality Ø Painful user experience Elasticity Availability Ø Slow iteration: cost effectiveness, enterprise class features, availability Why not solve the issue on 1.x? Ø History Ø It’s complex
8 .Quick Recap
9 .LSM Tree Ø Append Only Logs Ø Immutable files on disk Ø Merge in memory and on disk data when read Ø Log sequence number(LSN) as the order Ø Background task - Flush/Compaction
10 .Lambda structure Incremental + Historical ü Reduce latency for unanalyzable data ü Robustness ü Flexible scaling Achilles 'Heel: Complexity Kappa, Kappa+
11 . Milvus 2.0 Architecture overview
12 .Log As Data Log is all you need to restore system state t0 t1 t2 t3 t4 t5 now System State can be reconstructed by log snapshot + log sequence t1 - t4 t0 t1 t2 t3 t4 t5 t6 t7 now Durability: how to safely store logs?
13 .Log Sequence Pub-sub as System Backbone Distributed log on pub-sub systems Ø Disaggregate Log and database, make failure recovery easy and fast Ø Guarantee data durability Ø High Availability Ø Make System extendable Ø Reduce system complexity
14 .Key challenges and Milvus approach Problem 1 Relying only on log stream for reads is not practical (too slow) Solution Periodically backfill history data to segments, just like flush in LSMT, and handoff incremental files to historical. Merge on Read to maintain data completeness
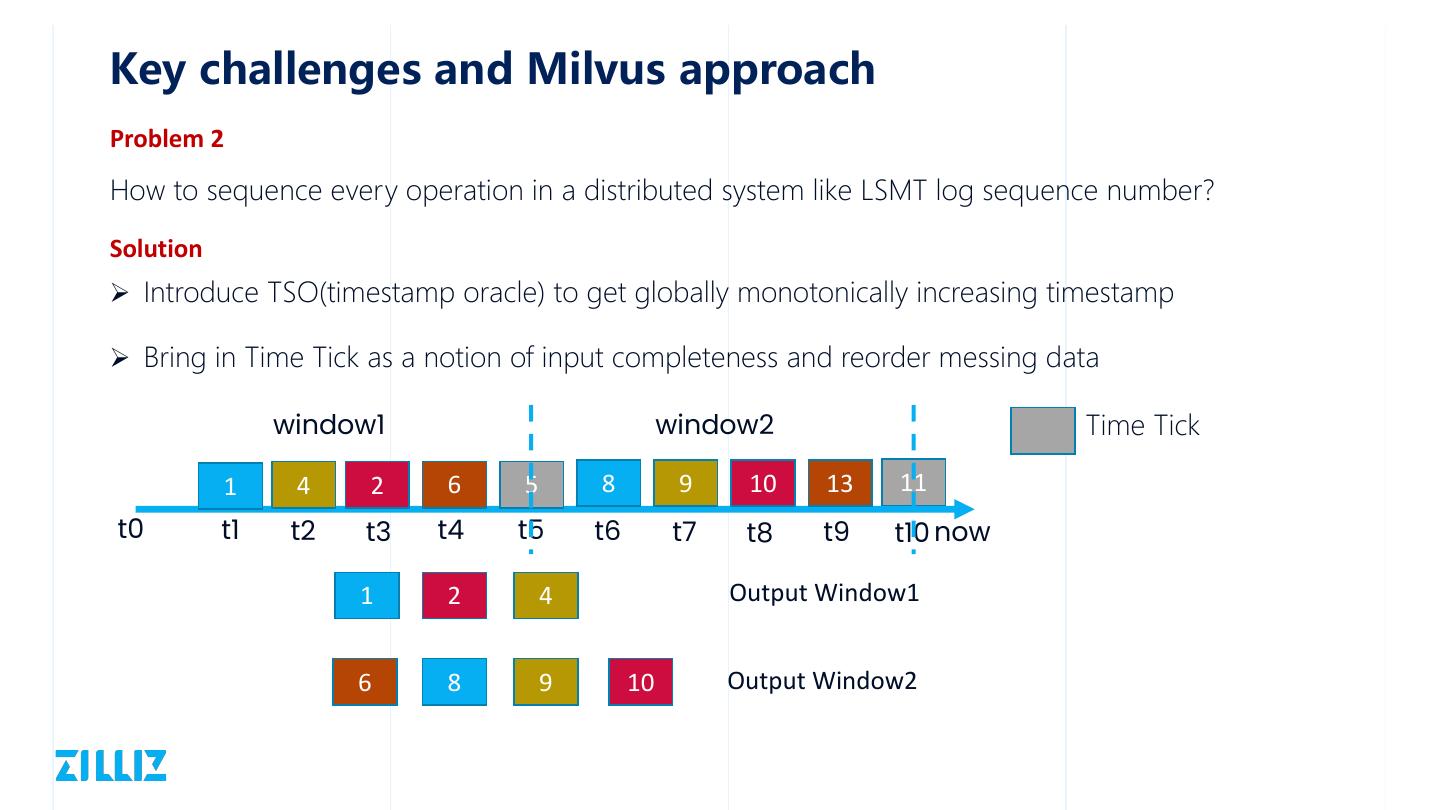
15 .Key challenges and Milvus approach Problem 2 How to sequence every operation in a distributed system like LSMT log sequence number? Solution Ø Introduce TSO(timestamp oracle) to get globally monotonically increasing timestamp Ø Bring in Time Tick as a notion of input completeness and reorder messing data window1 window2 Time Tick 1 4 2 6 5 8 9 10 13 11 t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 t10 now 1 2 4 Output Window1 6 8 9 10 Output Window2
16 . Key challenges and Milvus approach Problem 3 Near Real-Time is a good trade-off between accuracy and efficiency, any better? Solution Well-defined consistency levels: Strong, Bounded Staleness, Session, Consistent prefix Magic: wait until data ready We recommend Milvus users to use weaker consistency for better performance, but the choice is yours Strong Bounded Session Consistent now Staleness Last write Prefix now - window min Stronger Weaker Consistency Consistency Higher availability, lower latency, higher throughput Learn more: https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels
17 .Key challenges and Milvus approach Problem 4 LSMT is burdened by burst write traffic and background task like compaction/flush, same issue here? Solution Disaggregate different business into micro service, Separate control and data panel Ø Independently scalable Ø Reduce downtime through fault isolation Ø Easier to understand code and debugging Ø Ready for cross-cloud, cross-dc deployment
18 .Milvus Architecture Overview
19 . Milvus 2.0 Feature Highlights
20 .Hybrid search Milvus combines scalar and vector search, such as “Find top 10 drama films similar to Forrest Gump” Ø Support scalar datatypes columnar storage Ø Filter scalar data by arithmetic and bool expressions Ø Prune data by Partition Ø Cost-based on the way
21 .ORM Pymilvus SDK Mind the gap! Data scientists and data engineers maintain different Code, deploy on different environment, hard to put experiment into production Ø ORM API operate directly on Collection, Partition and Index, isolate business logic and data access details. Ø Running milvus everywhere, no matter on your laptop, local cluster, or cloud-service
22 .Time Travel Time Travel enables accessing historical data (i.e. data that has been changed or deleted) at any point within a defined period Milvus maintains a timeline of each DML and DDL Operation. Data is organized in time order thus we can offer Point-in-time data view. v1 v2 v3 v4 DDL v5 v6 t0 t1 t2 t3 t4 t5 t6 t7 now Search * from xxx where a = 1 and v = [1.0,1.0,1.0] and ts = t4 top 10
23 .Milvus Insight Ø Cluster state visualization Ø Meta Management Ø Data Query Ø Health Diagnosis Ø Open source, Please join us https://github.com/milvus-io/milvus-insight
24 .Real-world Cases
25 .Reverse Image Search
26 .
27 .Future works
28 .World’s Most advanced Vector Database ! Make it Correct Make it easy Make it fast Make it smart
29 .Resources https://milvus.io https://github.com/milvus-io/milvus https://twitter.com/milvusio https://medium.com/unstructured-data-service https://zhuanlan.zhihu.com/ai-search THANKS!
3秒后跳转登录页面
去登陆

