























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
易小萌 - NeurIPS 向量检索比赛介绍 及Track 2: Out-of-core indices with DiskANN as the baseline 获奖方案展示

展开查看详情
1 .NeurIPS向量检索比赛方案发布会 向量数据库研讨会
2 . Agenda • 特邀报告: 嘉宾: • Approximate Nearest Neighbor 王炜教授,香港科技大学广州分校 Queries for High Dimensional Data • 比赛获奖方案介绍: • 比赛简介 易小萌,Zillz 高级研究员 • Track 1 获奖方案展示 乔禹, 快手多模态检索工程师 • Track 2 获奖方案展示 许维芷,Zilliz 技术研究工程师 • Milvus 向量数据库介绍 栾小凡, Zilliz 合伙人 & Milvus 工程总监 刘炼, 亿贝技术负责人 • Milvus 在亿贝智能营销的实践 高林华, 亿贝资深软件开发工程师 王炜教授,香港科技大学广州分校 • 圆桌讨论:向量检索技术近期发展与未来方向 郑渤龙副教授, 华中科技大学 易小萌,Zilliz 高级研究员 王洪亚教授,东华大学 晏潇,南方科技大学副研究员
3 .
4 . 向量数据库研讨会 NeurIPS向量检索比赛介绍 易小萌 Zilliz 高级研究员 Billion-Scale Approximate Nearest Neighbor Search Challenge https://big-ann-benchmarks.com/ http://big-ann-benchmarks.com/templates/slides/comp-overview.pptx http://big-ann-benchmarks.com/templates/slides/T1_T2_results.pptx
5 .Competition: What and why? • ANNS increasingly used in scenarios with 109 – 1012 or more objects to index, e.g. • Web search, Recommend Ads, Enterprise/email search, Search large image databases • Most algorithms are evaluated on million-scale datasets; Competition focuses on indexing 1 billion points per machine. • Embeddings for a billion points can be 100GB (100 dim x int8) – 1TB (256dim x float) • Storing embeddings + index in memory can be expensive. Need to find alternative.
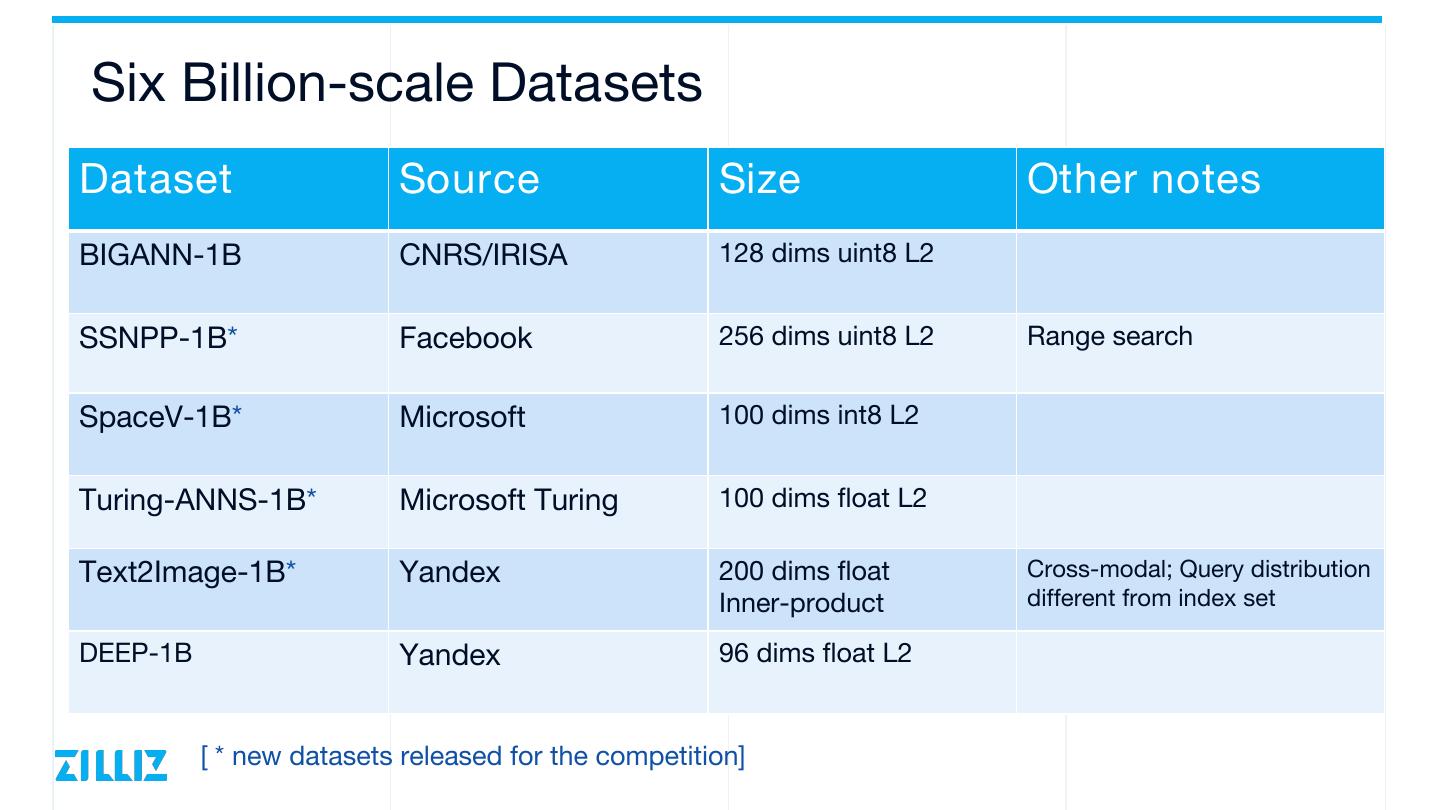
6 .Six Billion-scale Datasets Dataset Source Size Other notes BIGANN-1B CNRS/IRISA 128 dims uint8 L2 SSNPP-1B* Facebook 256 dims uint8 L2 Range search SpaceV-1B* Microsoft 100 dims int8 L2 Turing-ANNS-1B* Microsoft Turing 100 dims float L2 Text2Image-1B* Yandex 200 dims float Cross-modal; Query distribution Inner-product different from index set DEEP-1B Yandex 96 dims float L2 [ * new datasets released for the competition]
7 .Track 1: Standard hardware w/limited DRAM • Limit DRAM available for the data + index to 64GB • Smaller than the dataset (100GB-1TB). • Machine: Azure F32sv2 with 32 vCPUs, 64GB RAM • Index construction limited to 128GB DRAM and 4 days • Machine: Azure F64sv2 with 64 vCPUs, 128GB RAM • Considerations: • How well can we compress the points without perturbing the distances between them? • Extremely low over-head indices • Metrics: Recall@10 for the setting with >10K Queries/sec throughput
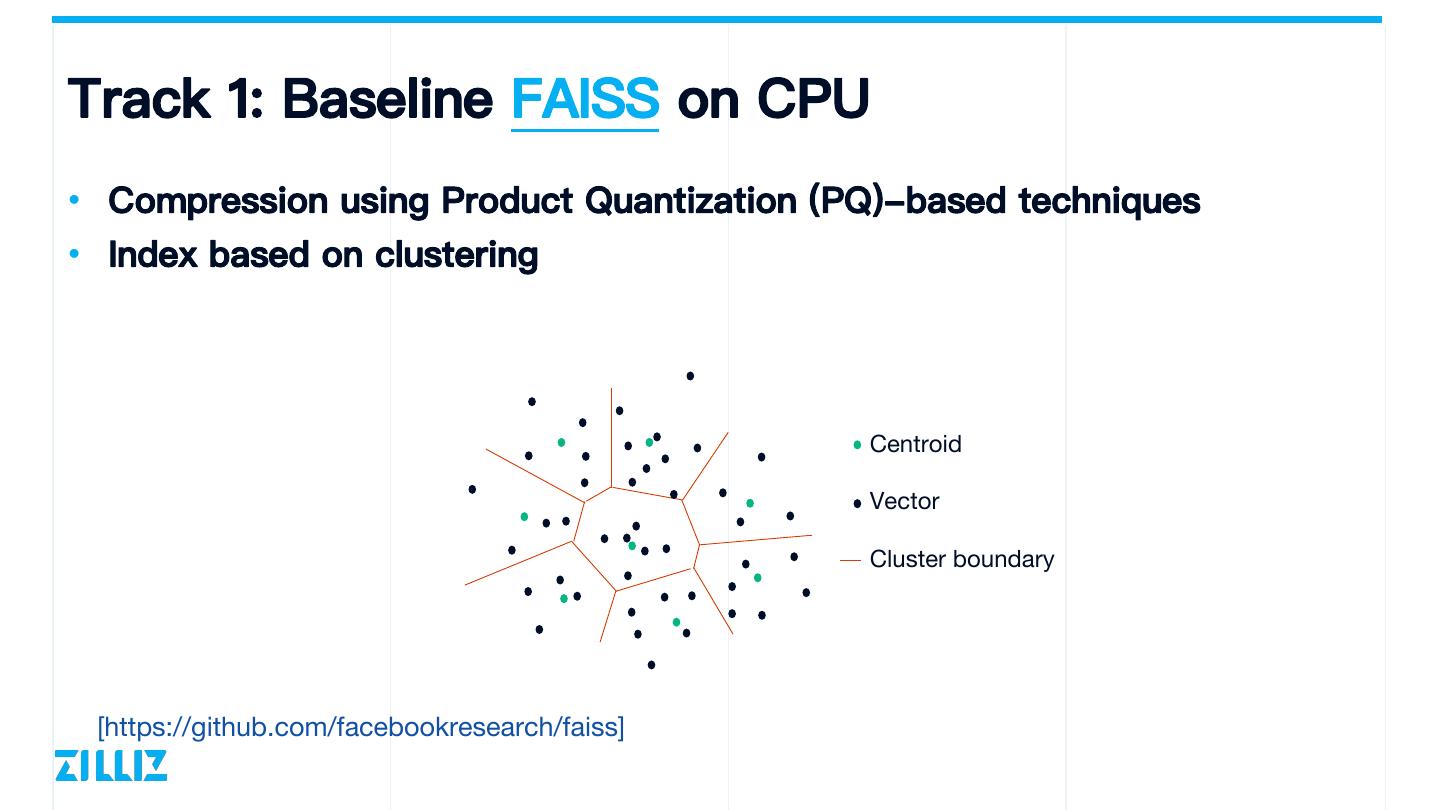
8 .Track 1: Baseline FAISS on CPU • Compression using Product Quantization (PQ)-based techniques • Index based on clustering Centroid Vector Cluster boundary [https://github.com/facebookresearch/faiss]
9 .Track 1 Results Dataset -> bigann deep msspac msturin ssnpp text2ima • F32v2 VM: 32 vCPU, 64GB DRAM -1B -1B ev-1B g-1B -1B ge-1B Team11 0.649 0.712 UESTC • Measure recall@10/AP for the best setting (among 10 submitted) that puck-t1 0.714 0.722 achieved at least 10,000 QPS CTAD, Baidu ngt-t1 Yahoo! Japan • Must submit an entry that works 0.75 kst_ann_t1 0.712 0.765 0.756 on at least 3 datasets Kuaishou Tech. 2 Tsinghua Univ. buddy-t1 0.627 • Winner: kst_ann_t1, Authors: Li Liu, Silo.AI OpenSource connections Jin Yu, Guohao Dai, Wei Wu, Yu Baseline 0.634 0.650 0.729 0.704 0.754 0.069 Qiao, Yu Wang, Lingzhi Facebook Liu; Kuaishou Technology and Research Tsinghua University Recall@10 at >10K QPS
10 .Track 2: Limited memory + inexpensive SSD • Limit DRAM to 64GB + 1TB Solid State-Drive • Azure L8sv2 with 8 vCPUs, 64GB RAM, local NVMe SSD • Considerations: • Can store small amount of data in-memory • Can store index and full-precision data on SSD, but index should be searchable with small number of I/Os per query. • Index construction limited to 128GB DRAM and 4 days • Machine: Azure F64sv2 with 64 vCPUs, 128GB RAM + 4TB disk space. • Metrics: recall@10 for the setting with >1500 Queries/sec
11 .Track 2: Baseline: DiskANN [https://github.com/microsoft/DiskANN/] DiskANN Design Compressed vectors DRAM SSD (50-60GB/billion vectors) Low-diameter graph s +full-precision vectors GreedySearch(q) • Let p = start node r • Fetch neighbors of p from SSD • Use compressed representation of points to q decide which neighbor to move to!
12 .Track 2 Results • Ls8v2 VM: 8 vCPU, 64GB DRAM Dataset -> bigann deep msspac msturin ssnpp text2ima • + 1TB SSD -1B -1B ev-1B g-1B -1B ge-1B kota-t2 0.951 0.904 0.940 0.182 Kwai Tech, • Measure recall@10/AP for the best Tsinghua Univ setting (among 10 submitted) that ngt-t2 achieved at least 1500 QPS Yahoo! Japan bbann 0.760 0.8857 0.495 Zilliz 3 • Must submit an entry that works on at SUSTech least 3 datasets Baseline 0.949 0.937 0.901 0.935 0.163 0.488 Microsoft Research India • Winner: bbann, Xiaomeng Yi, Xiaofan Recall@10/AP at >1500 QPS Luan, Weizhi Xu, Qianya Cheng, Jigao Luo, Xiangyu Wang, Jiquan Long, Xiao Yan, Zheng Bian, Jiarui Luo, Shengjun Li, Chengming Li, Zilliz and Southern University of Science and Technology
13 .Thank you
14 .
15 .Billion-scale Similarity Search Track 2: SSD Solution Xiaomeng Yi, Xiaofan Luan, Weizhi Xu, Qianya Cheng, Jigao Luo, Xiangyu Wang, Jiquan Long, Xiao Yan, Zheng Bian, Jiarui Luo, Shengjun Li, Ming Cheng https://github.com/zilliztech/BBAnn
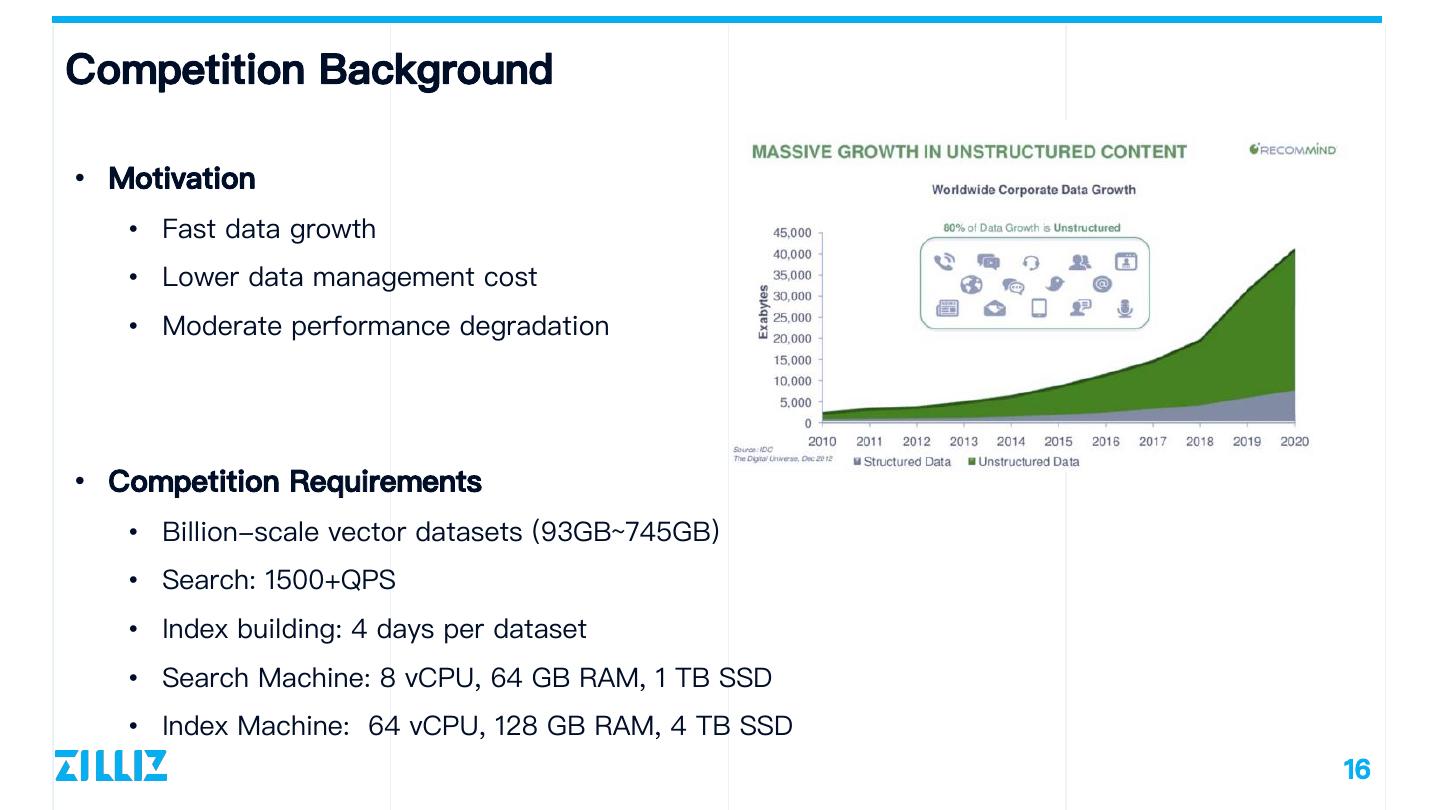
16 .Competition Background • Motivation • Fast data growth • Lower data management cost • Moderate performance degradation • Competition Requirements • Billion-scale vector datasets (93GB~745GB) • Search: 1500+QPS • Index building: 4 days per dataset • Search Machine: 8 vCPU, 64 GB RAM, 1 TB SSD • Index Machine: 64 vCPU, 128 GB RAM, 4 TB SSD 16
17 . Solution Overview • Data storage in SSD • Assign vectors to buckets • Buckets are page-aligned for read efficiency • Maintain bucket graph in memroy • Represent each bucket with its centroid • Organize centroids in a graph index • Vector search • Find related buckets through graph search • Fetch these buckets from SSD for scan 17
18 .Assign vectors to buckets • Target • Assign similar vectors into the same bucket • Key consideration • Efficient read for SSD • Fast processing • Our choice: • Hierachical KMeans • Page-aligned bucket size (4KB-8KB) 18
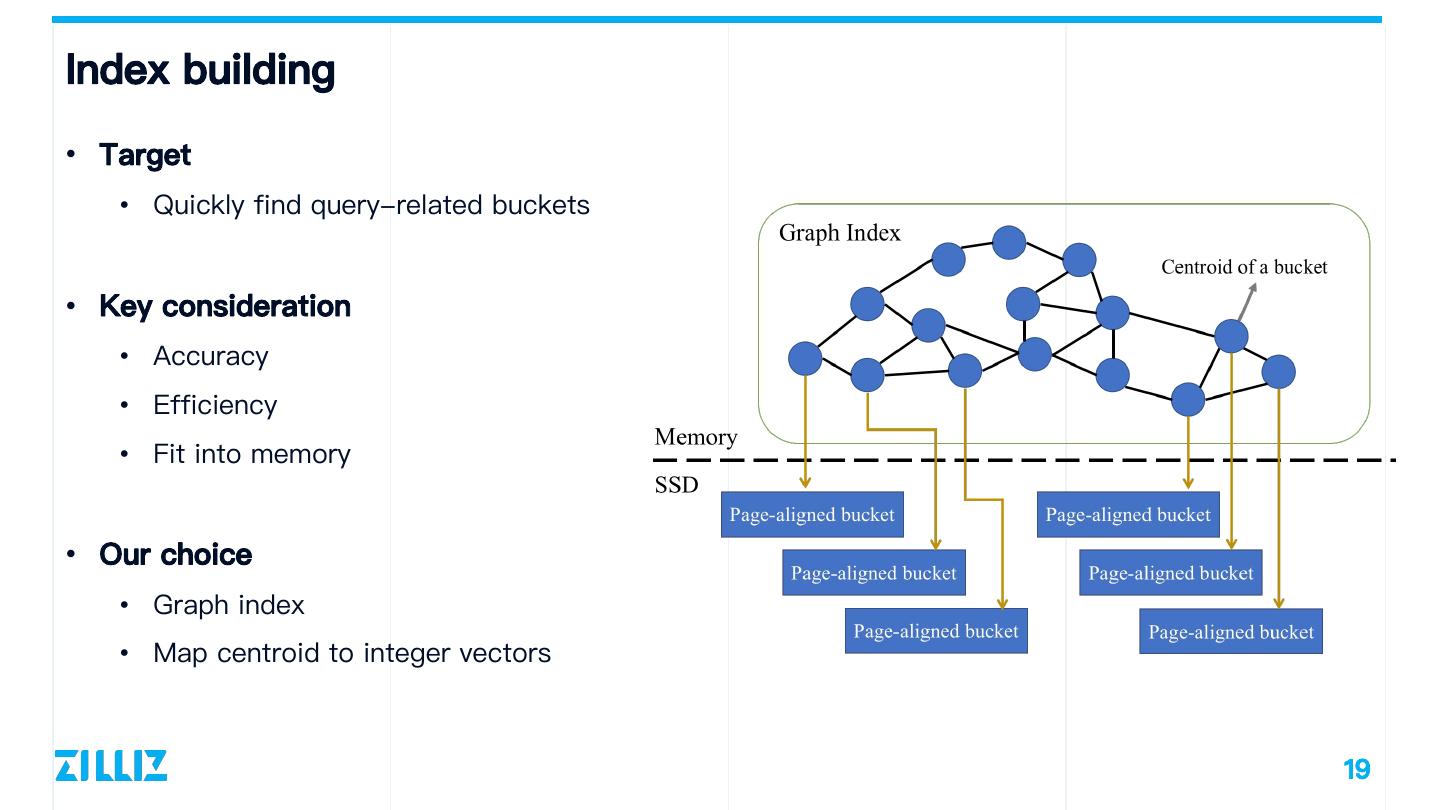
19 .Index building • Target • Quickly find query-related buckets • Key consideration • Accuracy • Efficiency • Fit into memory • Our choice • Graph index • Map centroid to integer vectors 19
20 .Vector Search • Range Search 1. Search graph index to find a small set of seed buckets 2. Find other related buckets from seed buckets with BFS until reaching range radius 3. Brute-force scan related buckets • KNN Search • Optimization choices 1. Search graph index to find related • Pruning buckets • Data reuse across queries 2. Brute-force scan related buckets • Pipeline compute and I/O 20
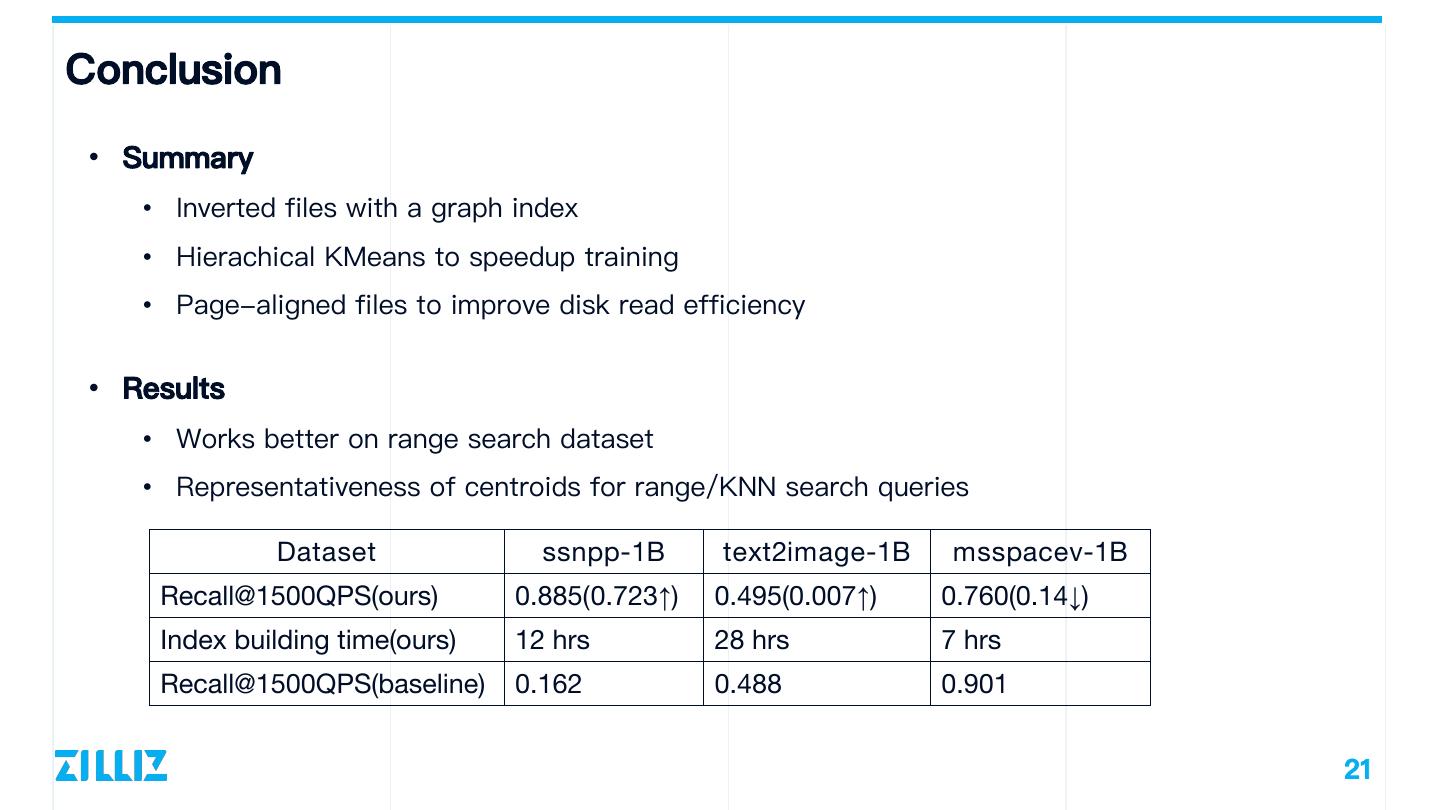
21 .Conclusion • Summary • Inverted files with a graph index • Hierachical KMeans to speedup training • Page-aligned files to improve disk read efficiency • Results • Works better on range search dataset • Representativeness of centroids for range/KNN search queries Dataset ssnpp-1B text2image-1B msspacev-1B Recall@1500QPS(ours) 0.885(0.723↑) 0.495(0.007↑) 0.760(0.14↓) Index building time(ours) 12 hrs 28 hrs 7 hrs Recall@1500QPS(baseline) 0.162 0.488 0.901 21
22 .Future directions • Uniformed index to handle both range search and KNN search • Analyze and exploit data hotness in queries • Vector search with heterogeneous device/storage(NVM/SSD/GPU/FPGA) • Distributed search algorithms • Better understand datasets and indexes • Automated index type/parameter recommendation • Learned index for vectors • Efficient vector search with attribute filtering • Multi-modal information retrieval 22
23 .About Zilliz Vision Build a data infrastructure that could help people accelerate AI adoptions in their organizations Open-source Projects • Milvus • Towhee Cloud native vector database for unstructured X2Vec: encode unstructured data into data embeddings https://milvus.io https://hub.towhee.io/ https://github.com/milvus-io/milvus https://github.com/towhee-io/towhee @milvusio @towheeio 23
24 .Thank You https://github.com/zilliztech/BBAnn
25 .
26 .圆桌讨论:向量检索技术近期发展与未来方向
3秒后跳转登录页面
去登陆

