展开查看详情
1 .2021.08 Hangzhou
Milvus2.0 主要进展及 RoadMap
Cao Zhenshan
zhenshan.cao@zilliz.com
�
2 . 01 What is Milvus
02 Milvus2.0 Architecture Review
C O N T E N T S
03 RoadMap
04 Work in progress
�
4 .80% data growth is unstructured, over 40,000 Exabytes per year
�
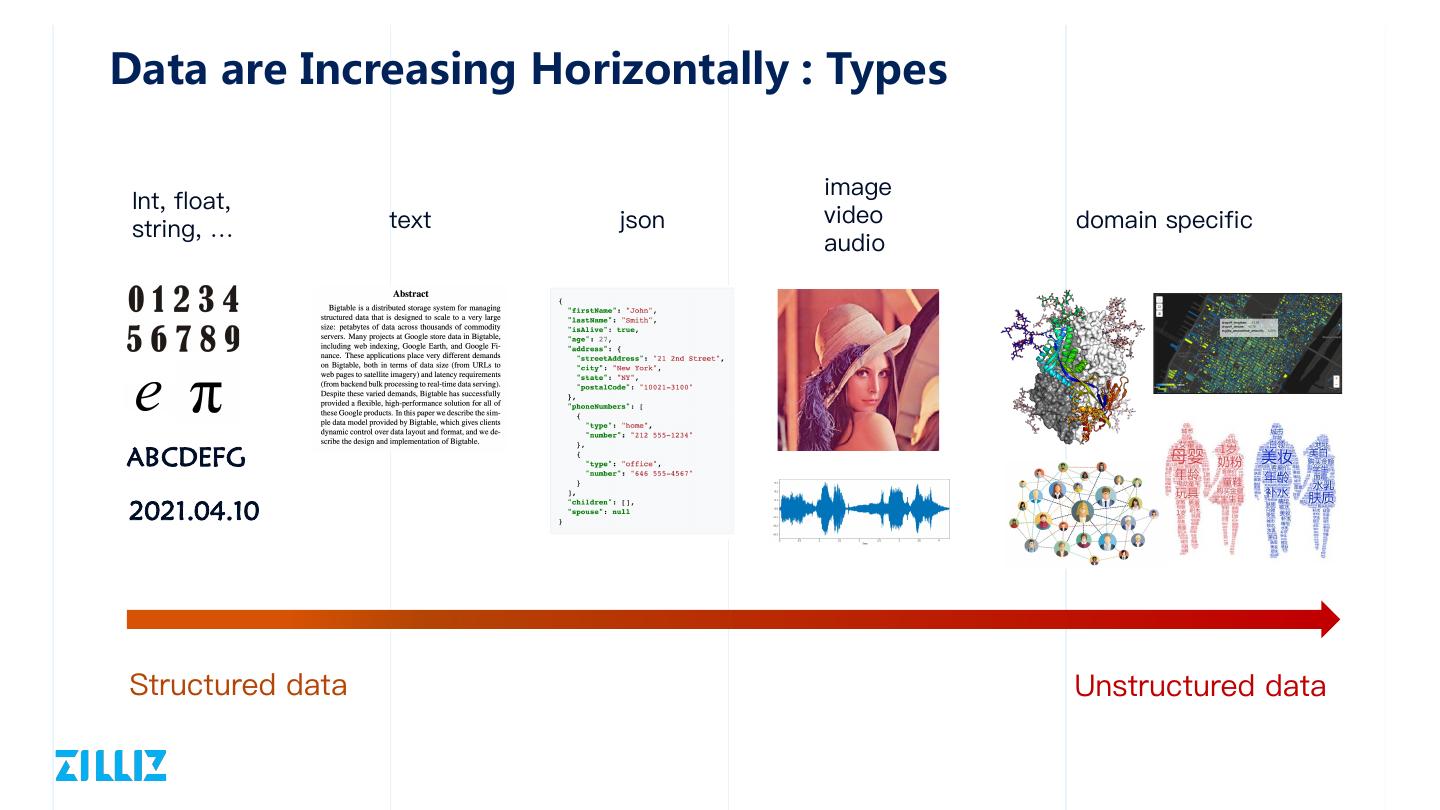
5 .Data are Increasing Horizontally : Types
image
Int, float,
text json video domain specific
string, …
audio
ABCDEFG
2021.04.10
Structured data Unstructured data
�
6 .Data are Increasing Vertically : Semantics
Richer semantics embeddings
embeddings embeddings
�
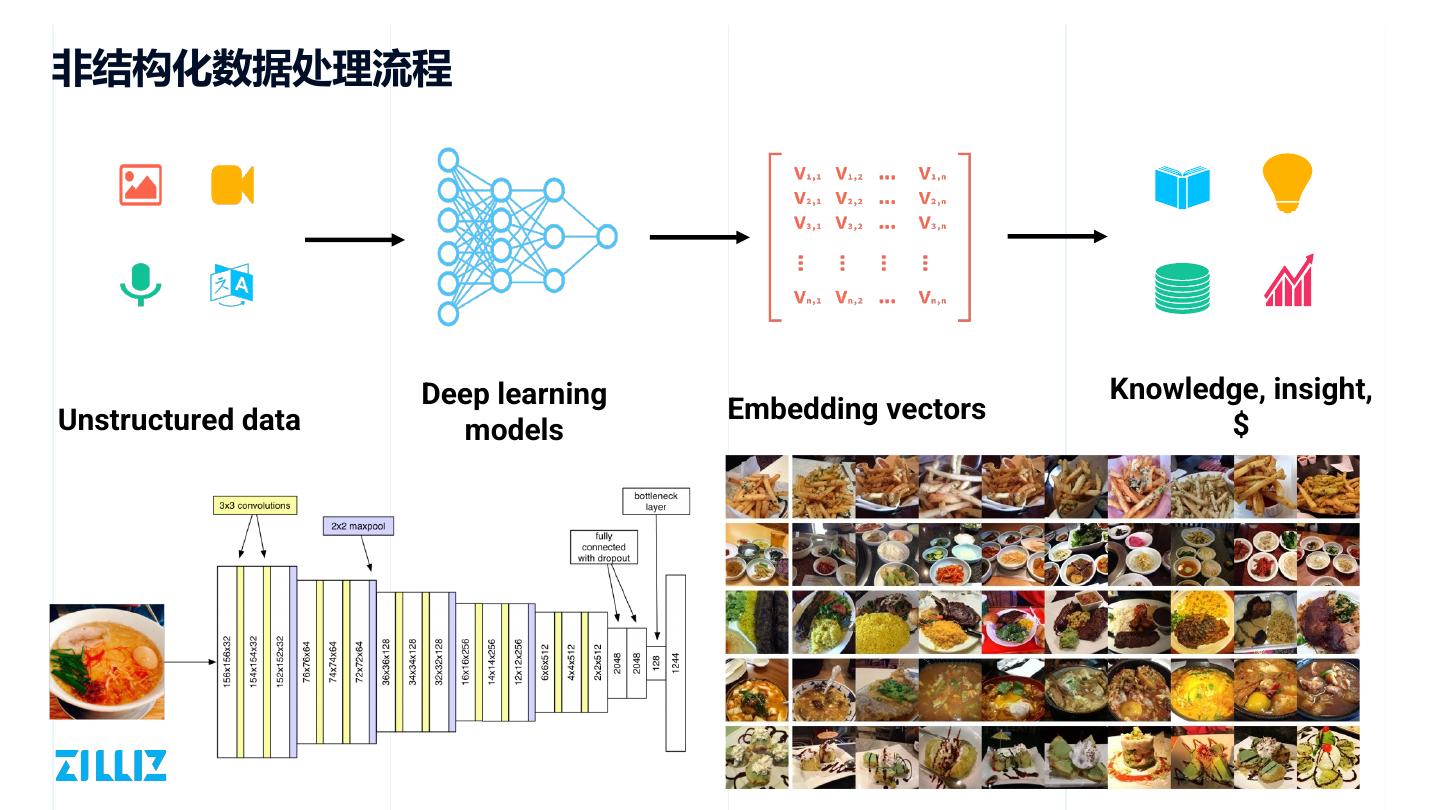
7 .非结构化数据处理流程
Deep learning Knowledge, insight,
Unstructured data Embedding vectors
models $
�
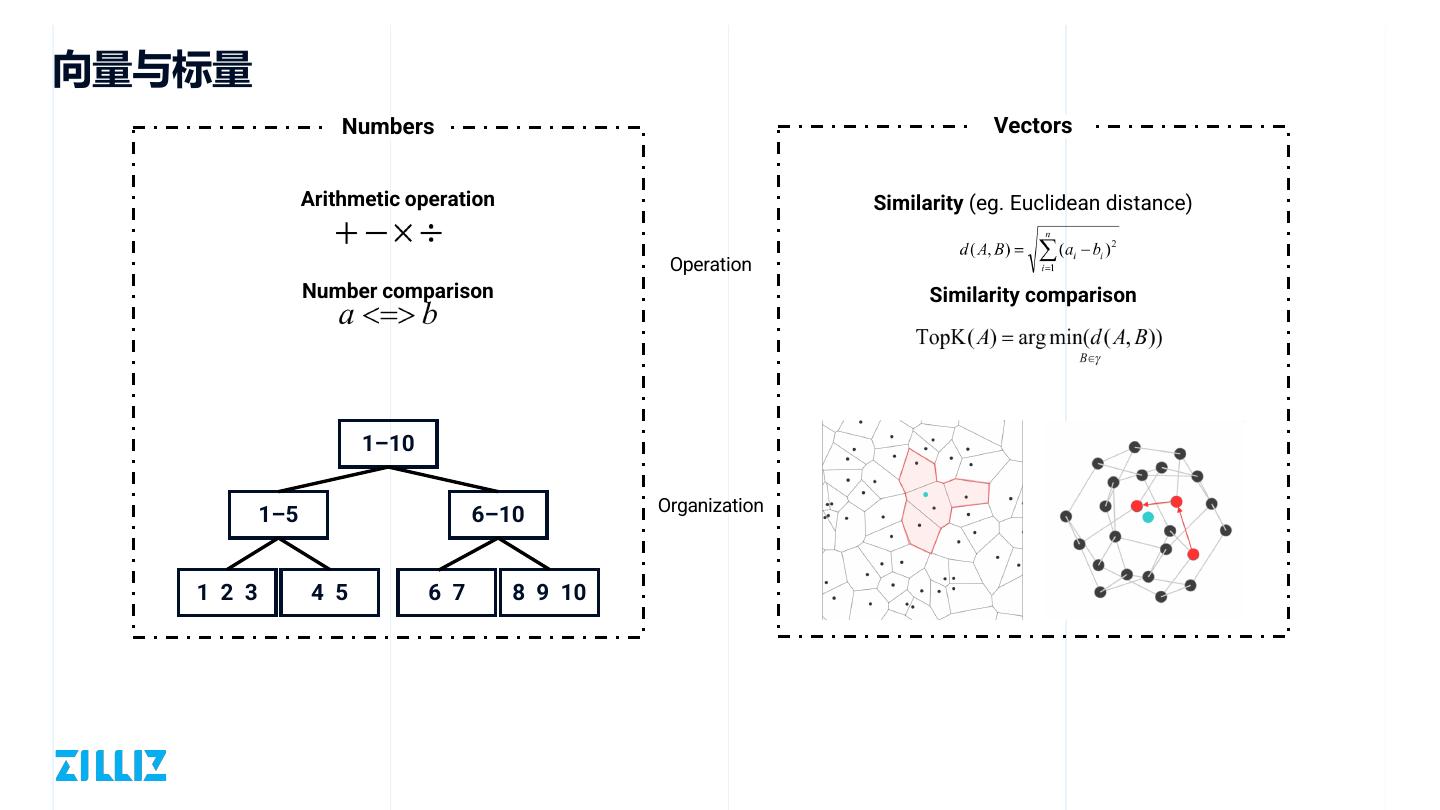
8 .向量与标量
Numbers Vectors
Arithmetic operation Similarity (eg. Euclidean distance)
Operation
Number comparison Similarity comparison
1–10
1–5 6–10 Organization
1 2 3 4 5 6 7 8 9 10
�
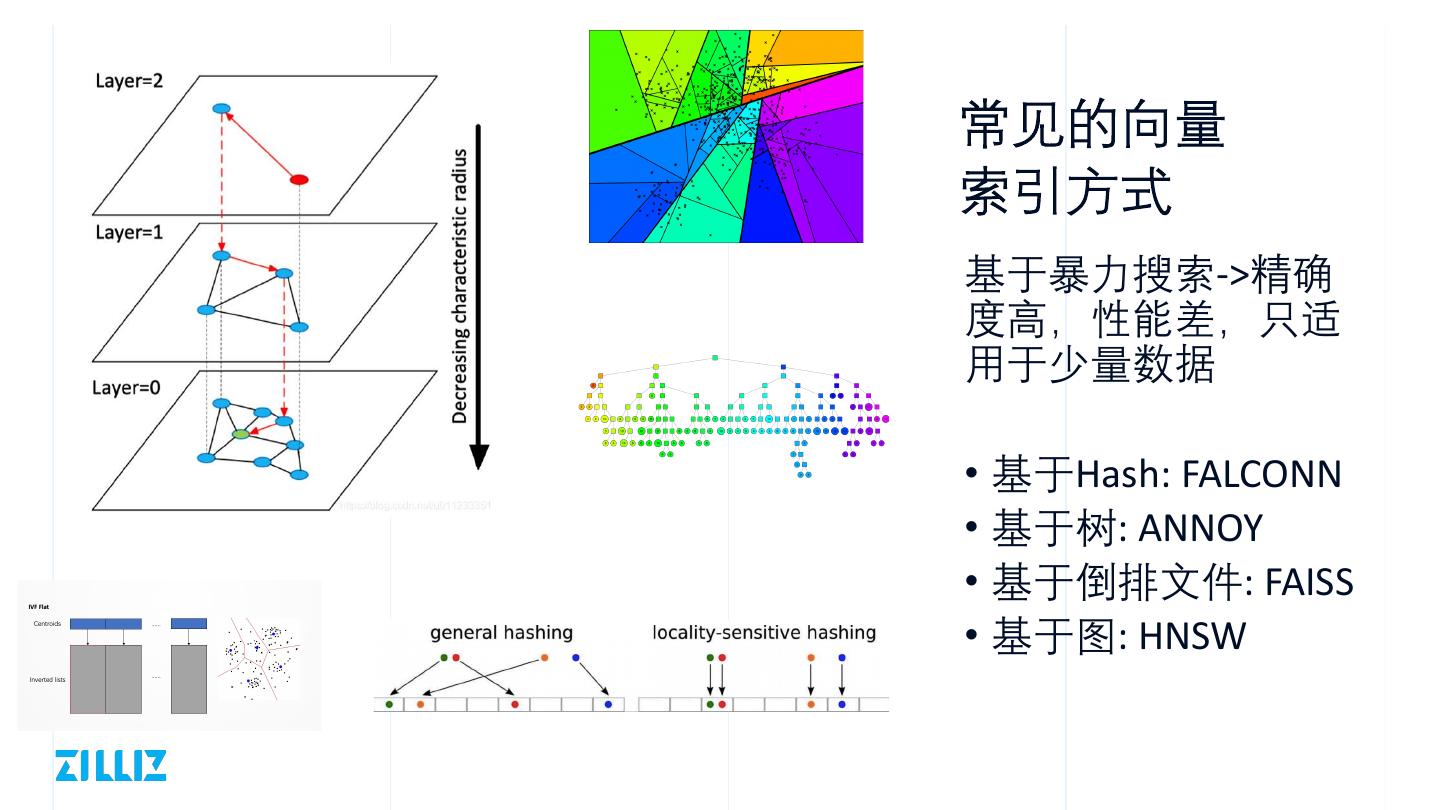
9 .常见的向量
索引方式
基于暴力搜索->精确
度高,性能差,只适
用于少量数据
• 基于Hash: FALCONN
• 基于树: ANNOY
• 基于倒排文件: FAISS
• 基于图: HNSW
�
10 .Milvus -> 为AI而生、面向云原生的向量数据库
从用户的角度出发,需要一个更易用,功能更强大
的数据库,而不仅仅是一个更快的库。
Ø 支持数据库的增删改查操作,并计划支持
snapshot,备份,多租户等数据库常见能力
Ø 支持基于标量和向量数据的混合查询
Ø 高可用,高扩展性,基于云实现弹性
Ø 开源,全世界最流行的向量数据库
不是一个关系型数据库-> 不支持ACID事务, 近似查询
不是一个搜索引擎> 语义检索而不仅是关键词检索。
�
11 .Milvus2.0 Architecture
Review
�
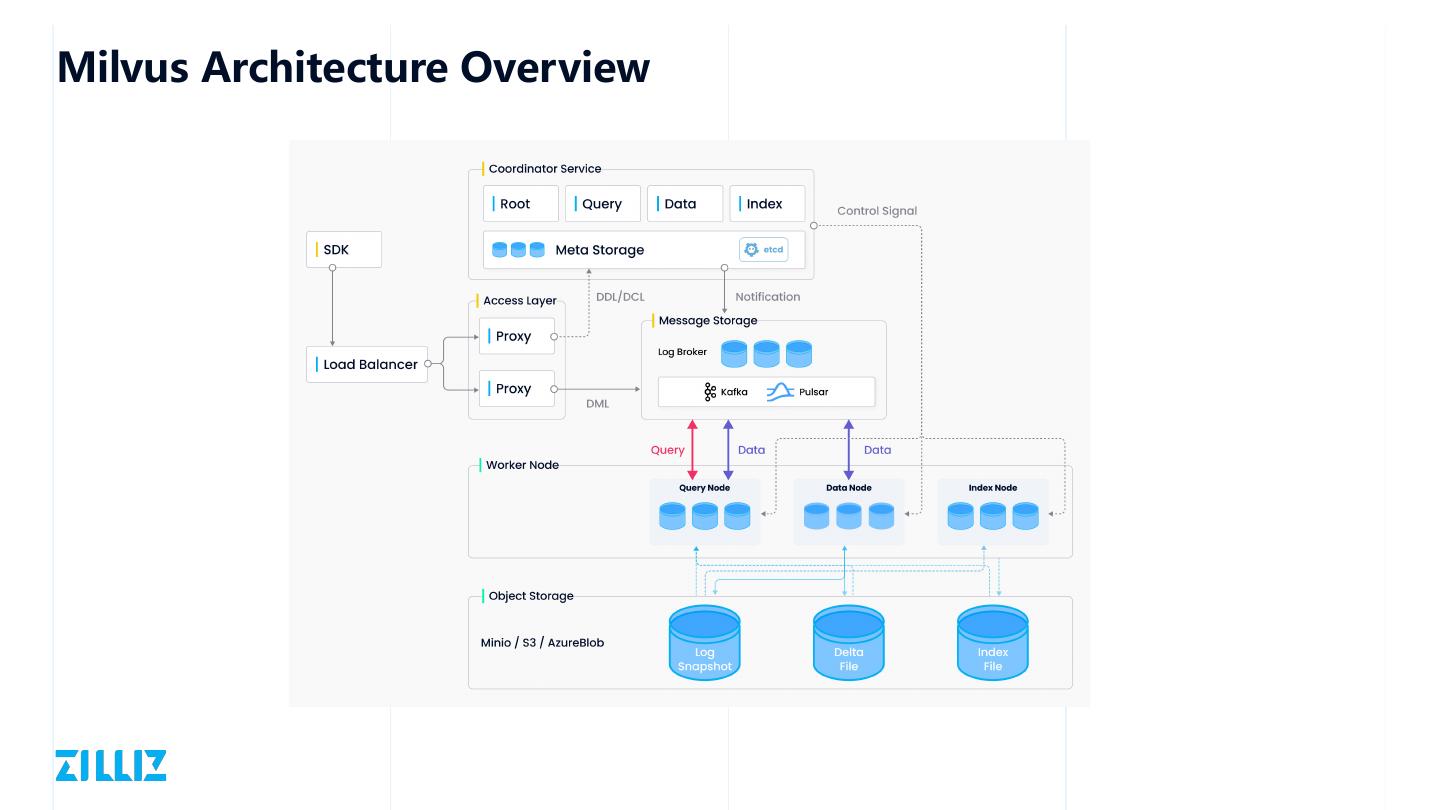
12 .Milvus Architecture Overview
�
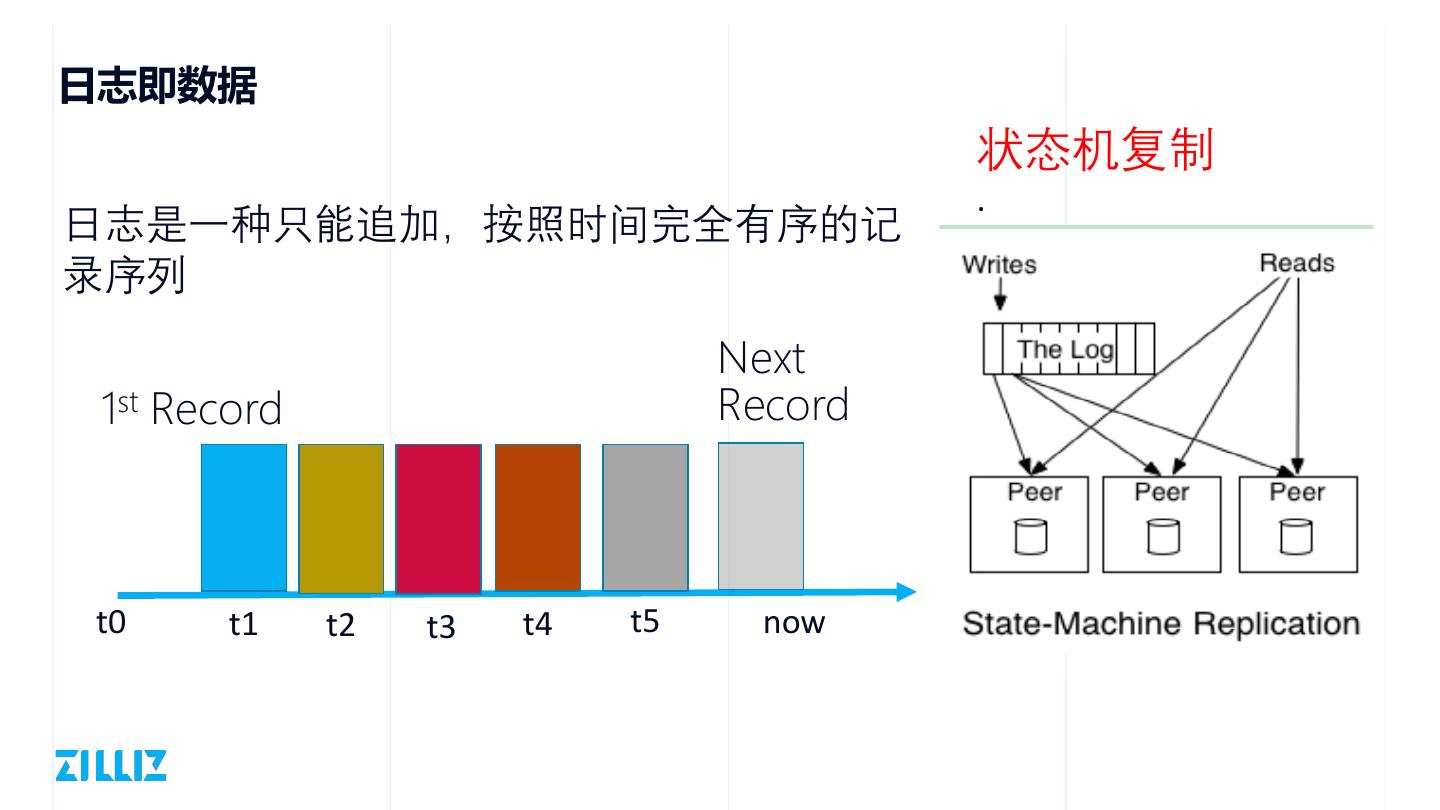
13 .日志即数据
状态机复制
.
日志是一种只能追加,按照时间完全有序的记
录序列
Next
1st Record Record
t0 t1 t2 t3 t4 t5 now
�
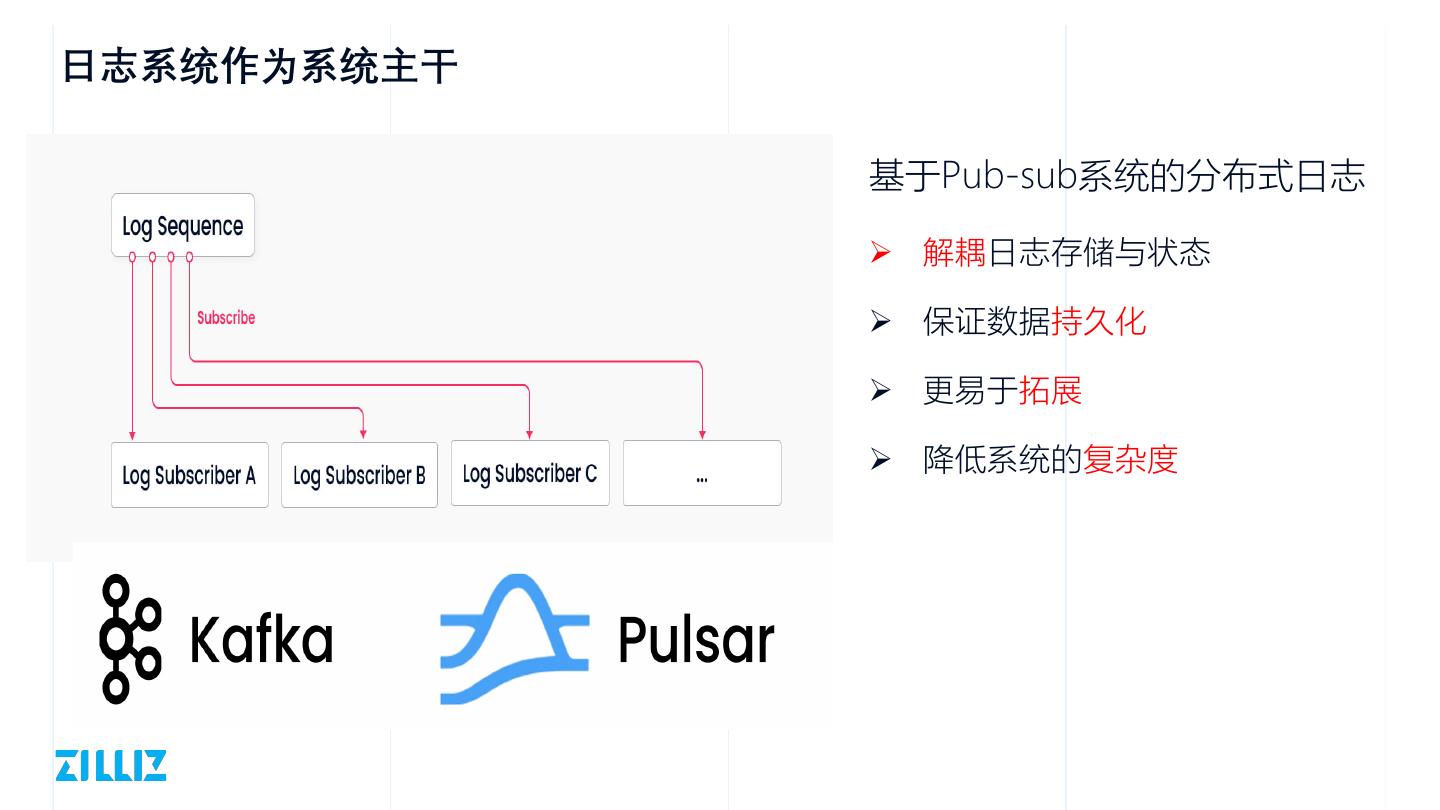
14 .日志系统作为系统主干
基于Pub-sub系统的分布式日志
Ø 解耦日志存储与状态
Ø 保证数据持久化
Ø 更易于拓展
Ø 降低系统的复杂度
�
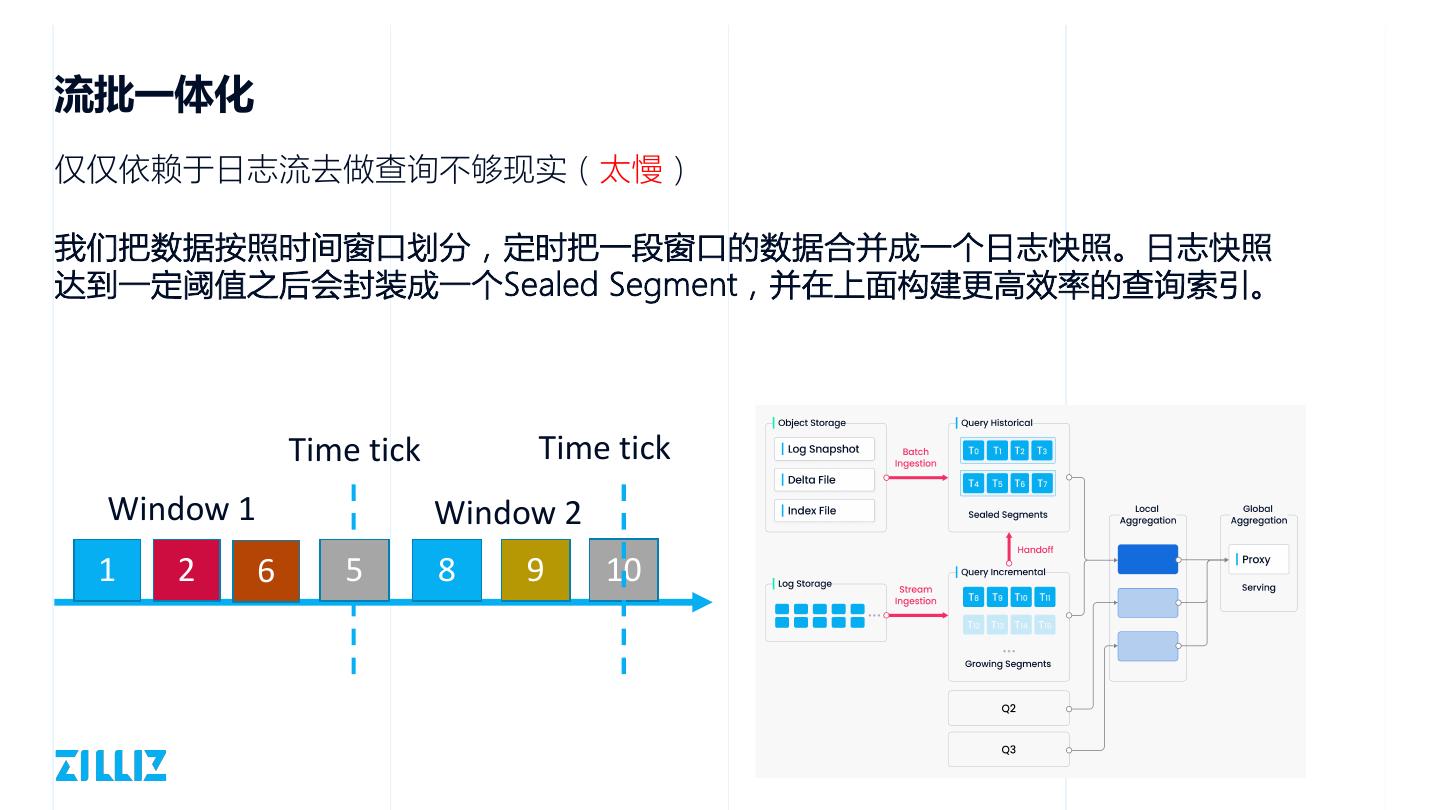
15 .流批一体化
仅仅依赖于日志流去做查询不够现实(太慢)
我们把数据按照时间窗口划分,定时把一段窗口的数据合并成一个日志快照。日志快照
达到一定阈值之后会封装成一个Sealed Segment,并在上面构建更高效率的查询索引。
Time tick Time tick
Window 1 Window 2
1 2 6 5 8 9 10
�
17 .Timeline
Milvus2.0 Milvus2.0 Milvus2.0 Milvus2.0 Milvus2.0 Milvus2.0
Begin RC1 RC2 RC3 RC4 RC5
2020.09 2021.06.28 2021.07.13 2021.07.29 2021.08.13 2021.08.24
Milvus2.0 Milvus2.0 Milvus2.0.0 Milvus2.1 Milvus2.2
rc6 GA
2021.09.07 2021.09.14 2021.09.30 TBD TBD
�
18 .Features in Milvus 2.0
String data type Python SDK enhancement Performance Tunning
Delete by primary key NodeJS SDK k8s operator
Search/Query with expression Go SDK Improve system stability
Milvus-Cli
�
19 .Features in Milvus 2.1
Supports Scalar Index for string, float, int Restful APIs
Support ScaNN index Adapt Kafka
Supports GPU Index building Adapt JuiceFS
and embedding retrieval
Data stored over local/distributed filesystems
Search by primary key
Improve hybrid search efficiency
Data bulkload
Segment replicas
Flow control and back pressure
Multi tenant support and access control
Java SDK
�
20 .Features in Milvus 2.2 Long Term
search/query result pagination static data encryption
Primary key deduplication FPGA and other Heterogeneous
hardware
On-disk vector indexing
Automatic index optimization
Embedded Milvus that runs on laptops
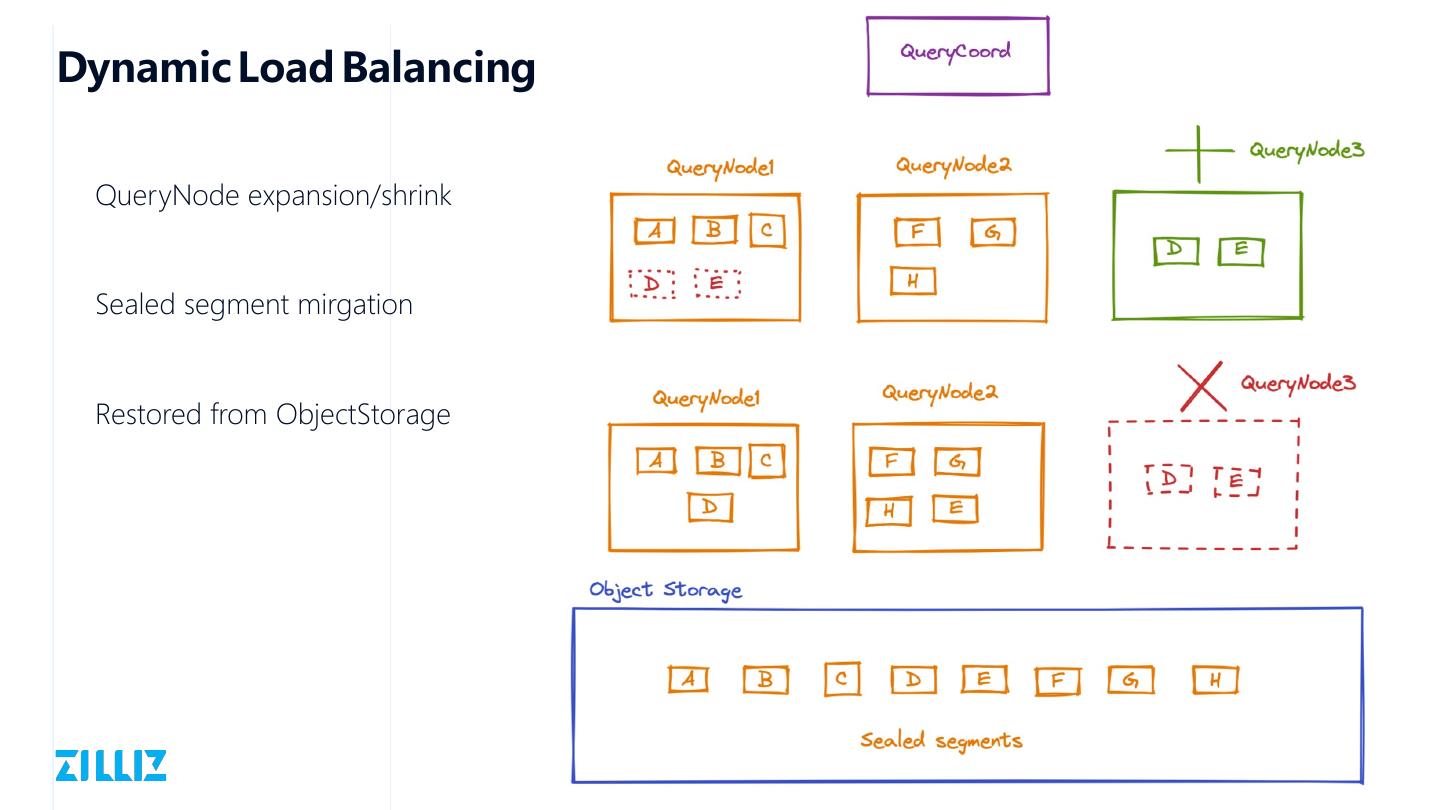
Dynamic cluster expansion/shrink
Integrates distributed KV stores
(HBase/TiKV/FoundationDB) SQL-like Query Language
�
25 .Search/Query With Expression Milvus combines scalar and vector search, such as
“Find top 10 drama films similar to Forrest Gump”
Search
Ø Support scalar datatypes columnar storage
A set of criteria that results in a
relevancy-ordered list that match the query. Ø Filter scalar data by arithmetic and bool
expressions
Ø Retrieve field data on query/search
Query GetEntityByID
A set of criteria that results in a list of records
that match the query exactly, returned in
Query(“ID in [PK1,PK2,…]”,
order of particular field values
output_fields = [F1,F2..])
�
26 .Support String Data Type
Urgent needs from users 3 million unicode russian words
Scalar filtering on string field
DataStructure MemoryUsage
Python-Dict 600MB
Retrieve origin string
Python-List 300MB
Memory consumption matters
�
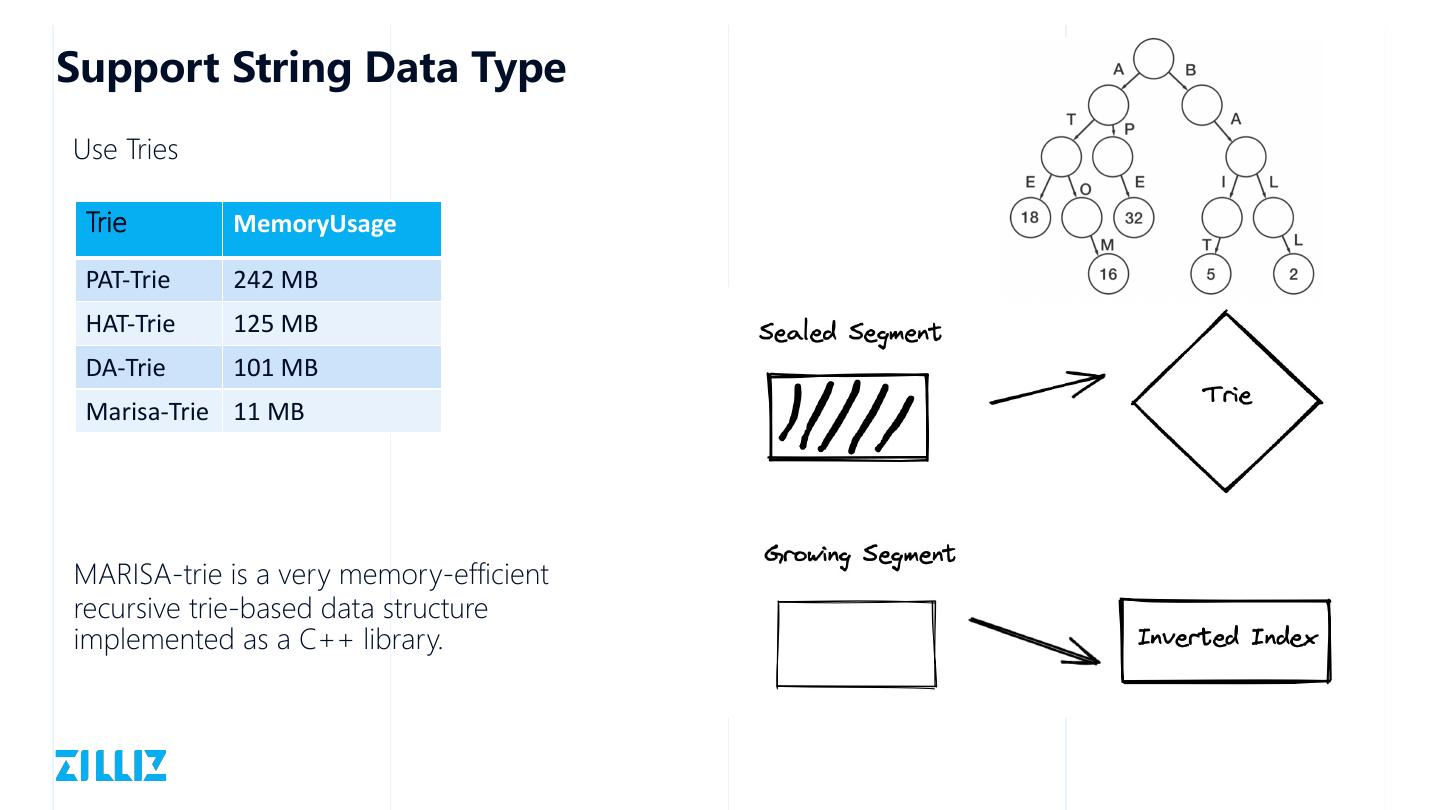
27 .Support String Data Type
Use Tries
Trie MemoryUsage
PAT-Trie 242 MB
HAT-Trie 125 MB
DA-Trie 101 MB
Marisa-Trie 11 MB
MARISA-trie is a very memory-efficient
recursive trie-based data structure
implemented as a C++ library.
�
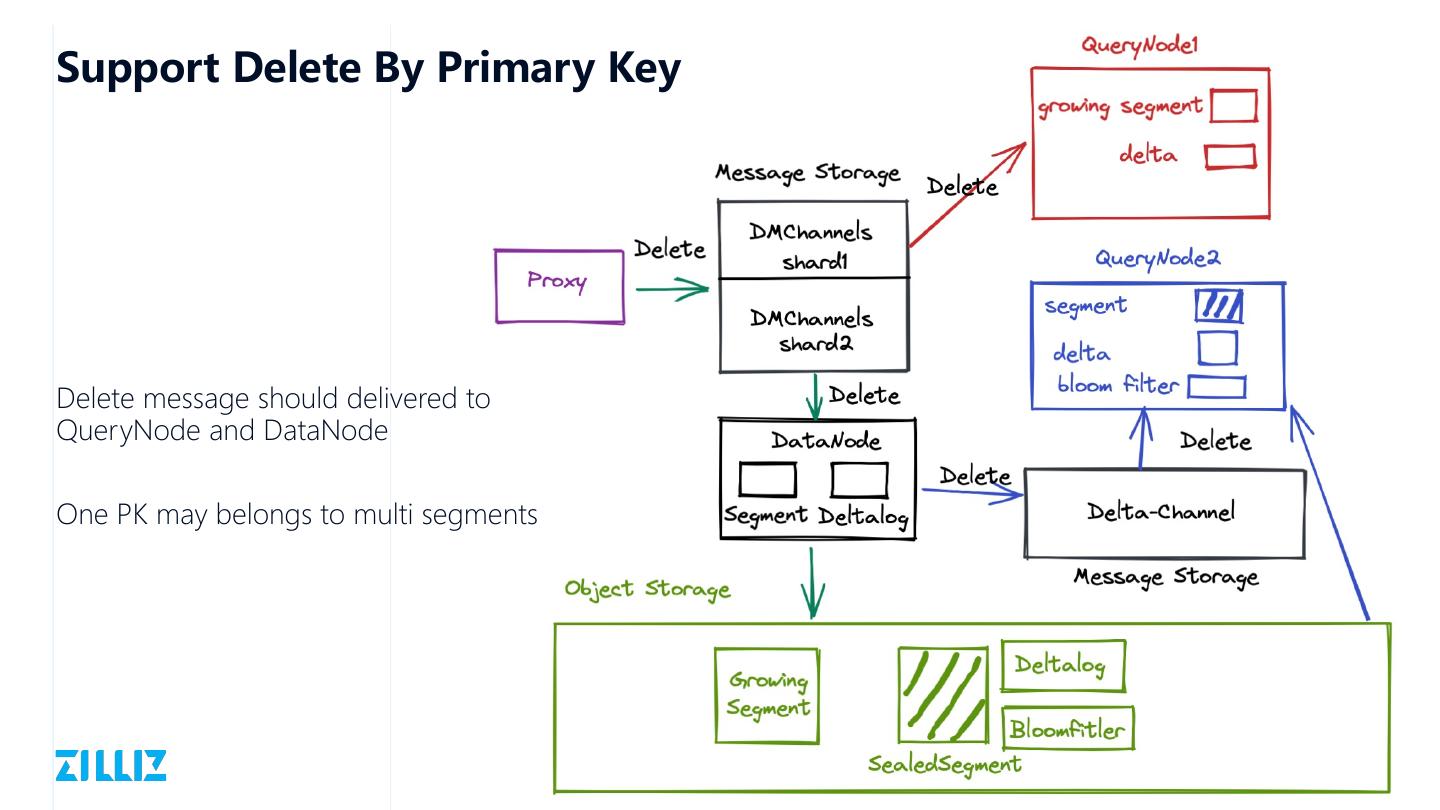
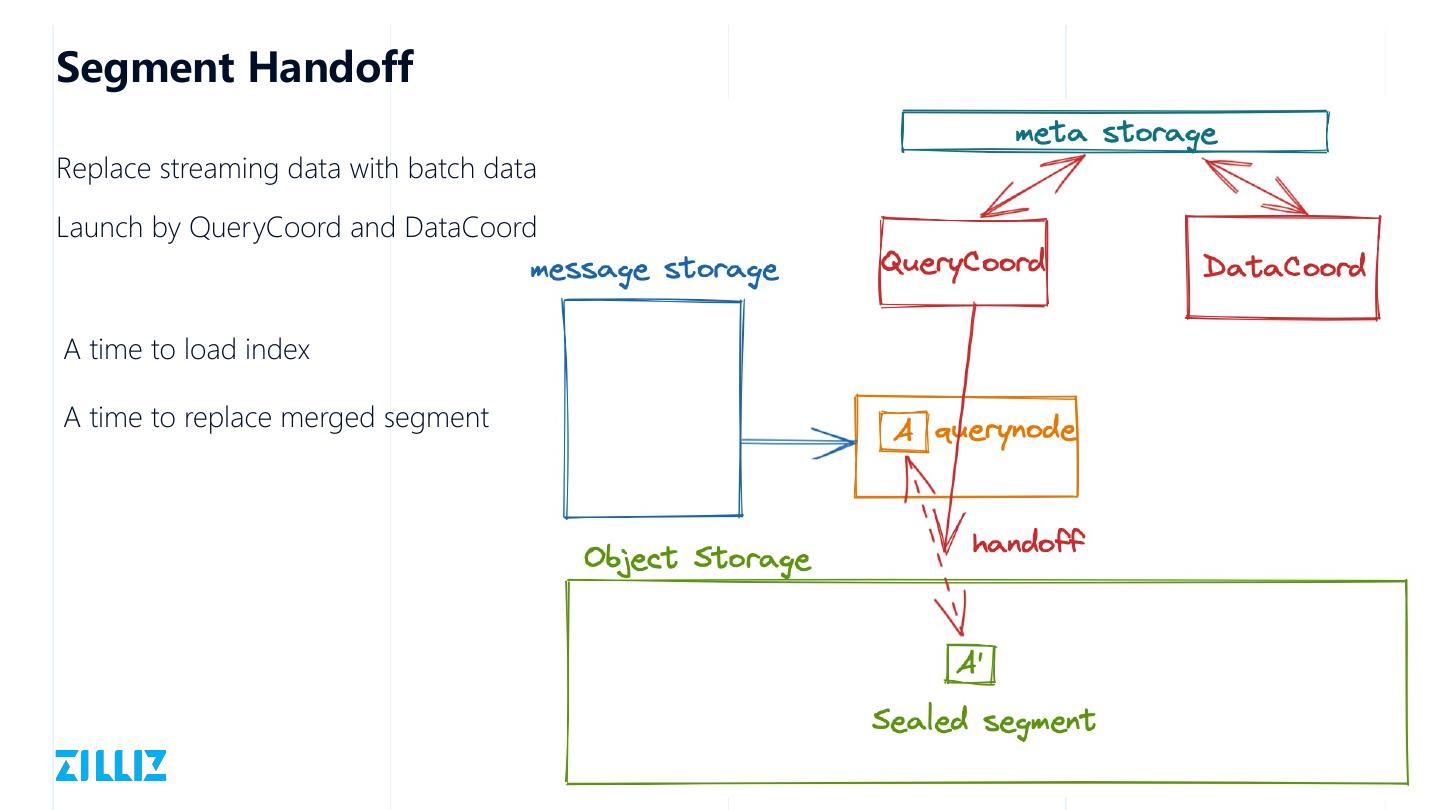
28 .Support Delete By Primary Key
Delete message should delivered to
QueryNode and DataNode
One PK may belongs to multi segments
�
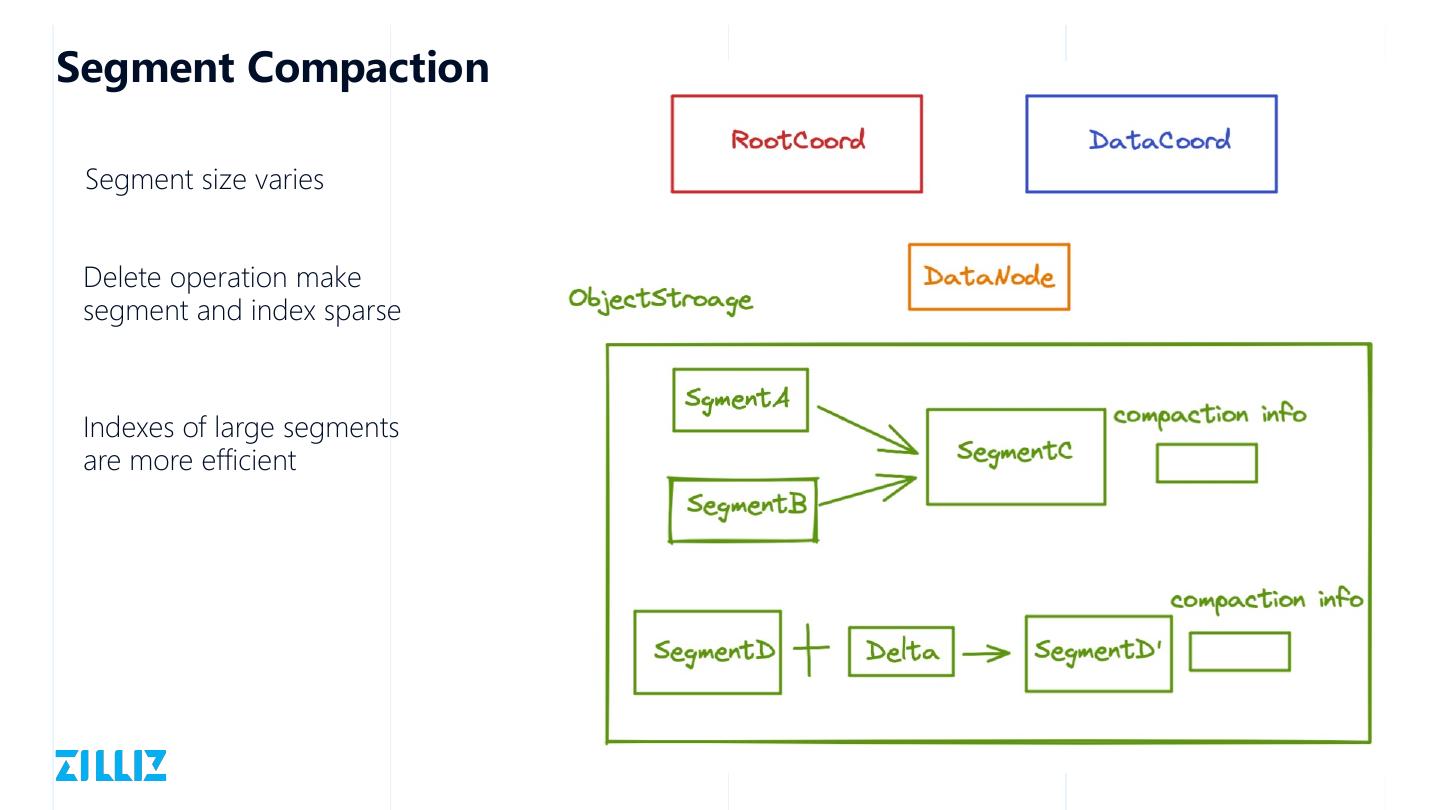
29 .Segment Compaction
Segment size varies
Delete operation make
segment and index sparse
Indexes of large segments
are more efficient
�