
































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
HBase Practice in China Mobile
来自中国移动苏州研发中心 HBase 负责人陈叶超介绍了 HBase 在中国移动的实践
中国移动目前大概有6000个物理节点,100多个集群,几十PB数据,单集群最大600多个节点,单表最大1.6PB,最大3000万并发访问,存储的数据采用较高压缩比进行压缩,减少存储空间。
HBase 在中国移动的几个应用场景:
(1)北京移动的流量清单,比如手机使用流量,这个在掌上营业厅是可以查到的。
(2)DPI数据,主要是信令相关的,有一些网络优化的设计。
(3)监控和日志,包括小图片、用户标签、爬虫和市场营销等。
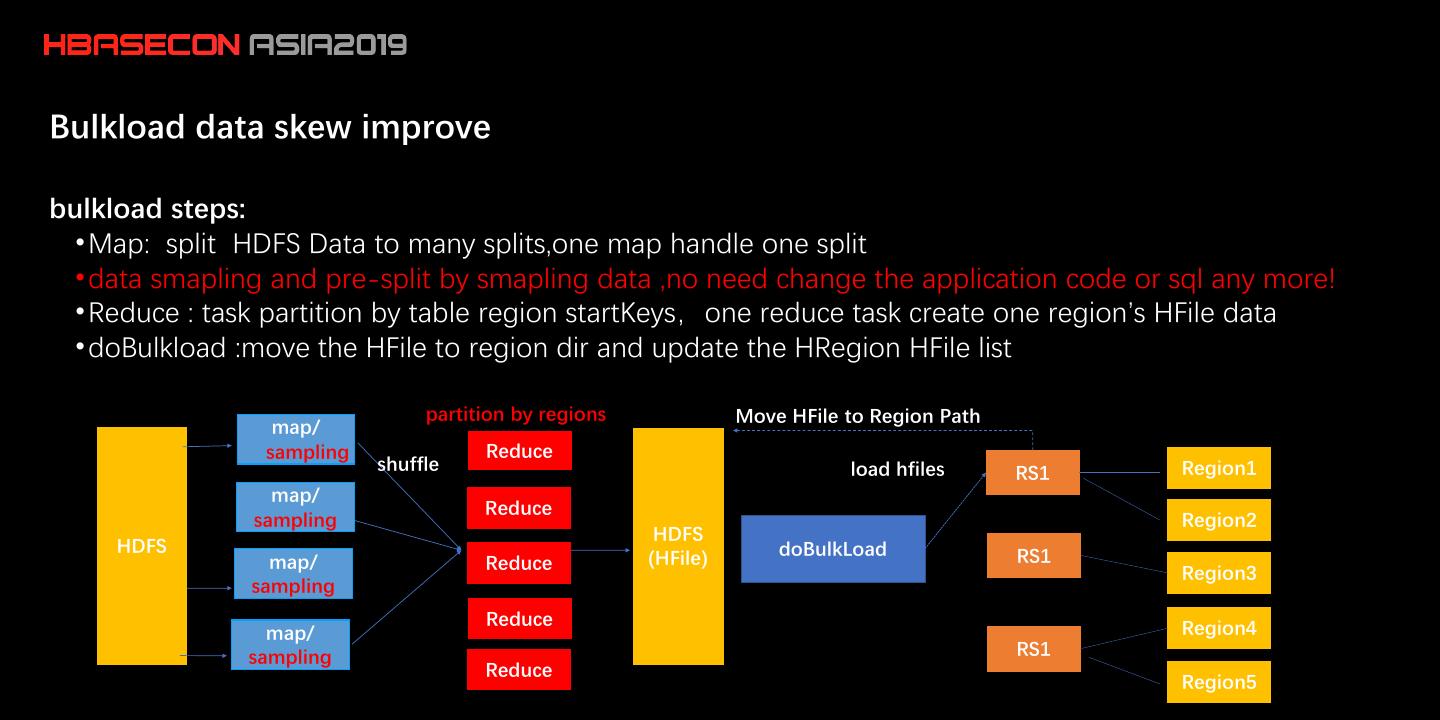
中国移动在实践中通过数据抽样解决 BulkLoad 中数据倾斜问题。数据压缩在Flush 和 BulkLoad 阶段都不开启,只在 compaction 阶段使用,提高读写性能。混合使用 SSD/HDD 磁盘,compaction 后数据存储在 HDD 磁盘。对于更好的使用 SSD,中国移动做了如下工作:
backport HSM To HBase 1.2.6版本。
所有用户过来的写入路径都是SSD的,写性能提高50%。
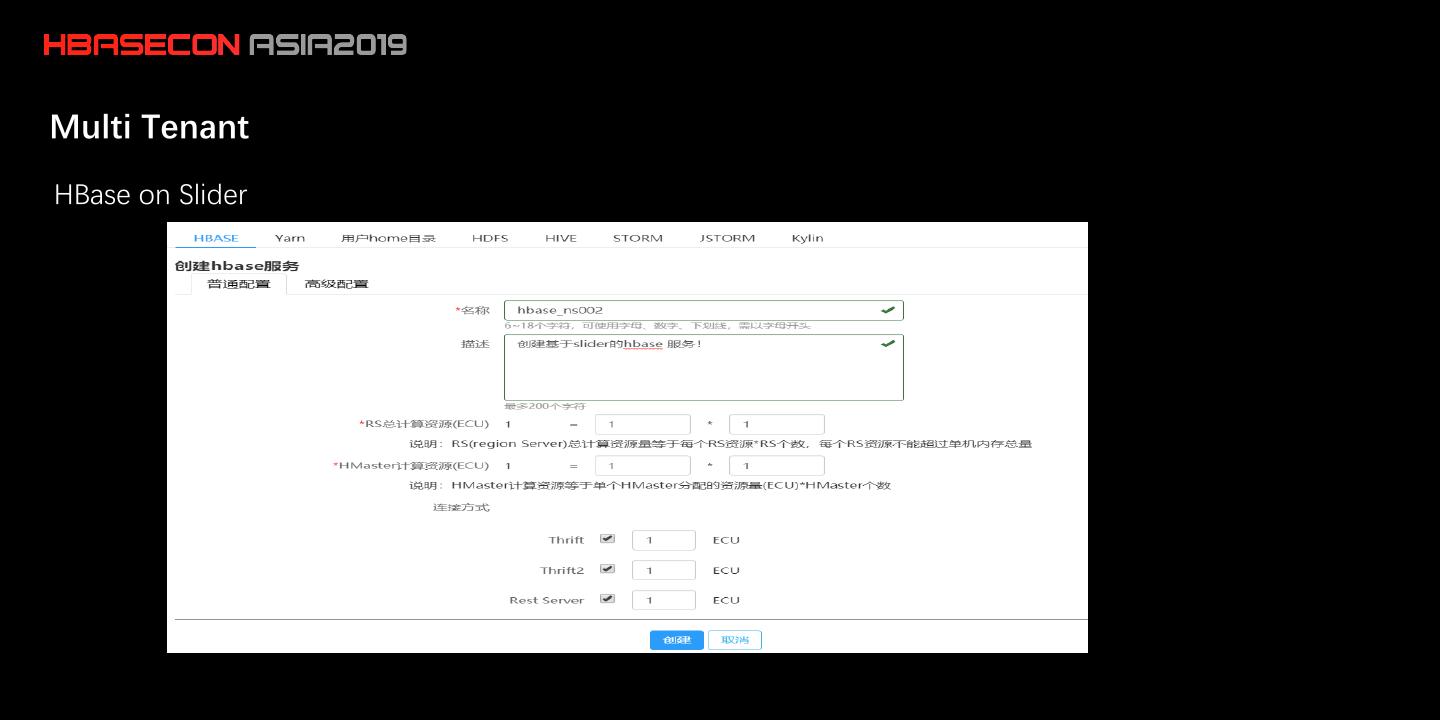
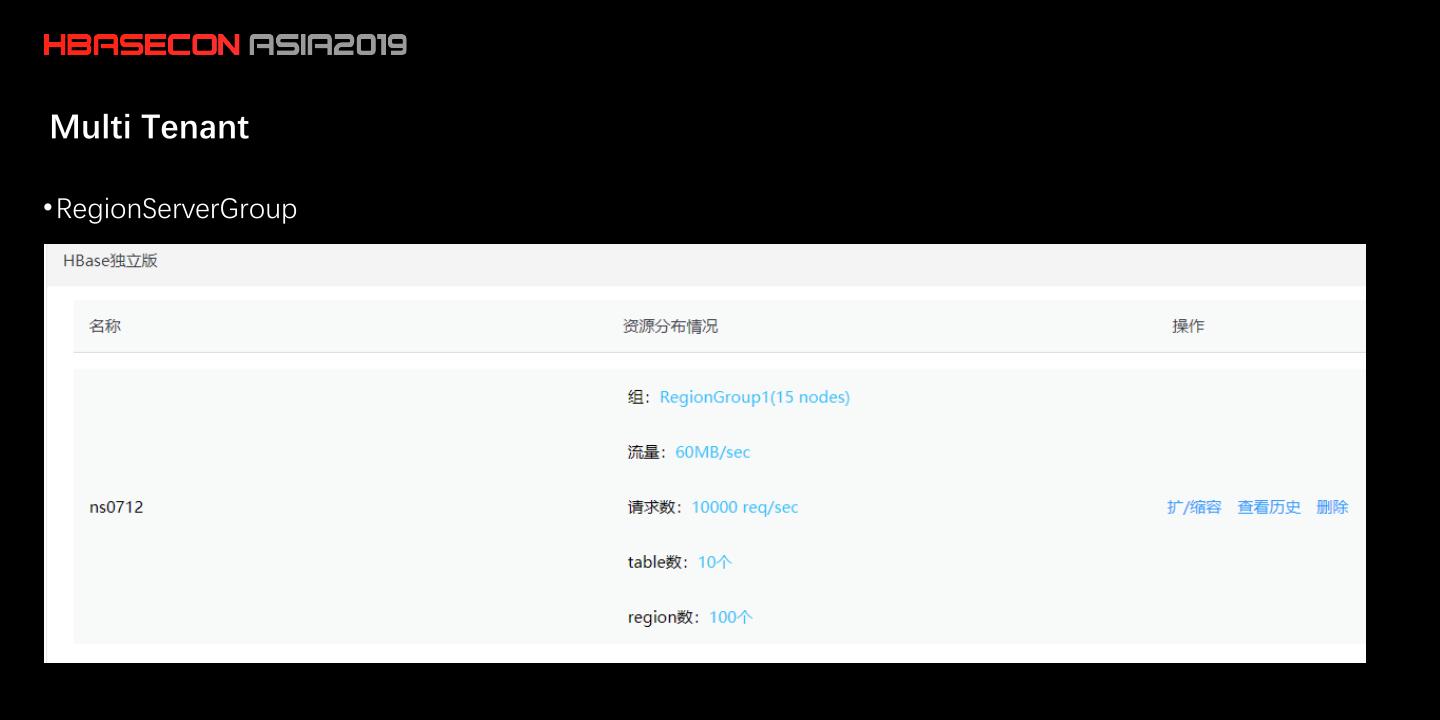
此外,中国移动还开发了 HBase 集群智能运维工具:Slider 和RegionServerGroup,可以控制资源的分配,并基于 Region 做了一套权限认证体系。
展开查看详情
1 .
2 .HBase Practice In China Mobile Yechao Chen China Mobile (Suzhou) Software Technology Co., Ltd. China Mobile Suzhou Research Center
3 .About China Mobile 1. China Mobile is the world’s biggest telecom companies in the world 2. 932 million customers 3. 727 million 4G customers 4. 172 million wireline broadband customers 5. Over 100 PB data generated per day About CMSoft China Mobile Suzhou Software Technology Co., Ltd /China Mobile Suzhou Research Center. Specialized subsidiary of China Mobile. CMSoft focus on cloud computing ,big data and IT support related software services.
4 .01 HBase on China Mobile
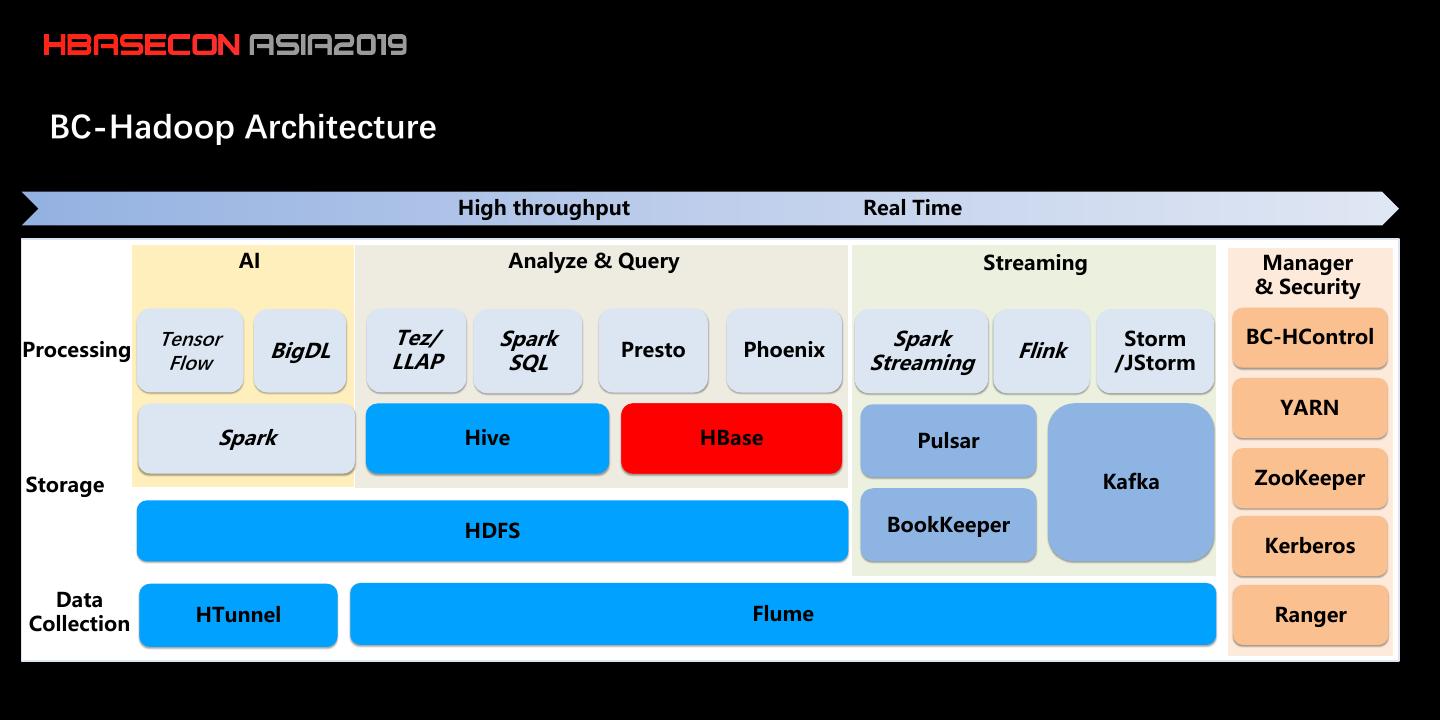
5 . BC-Hadoop Architecture High throughput Real Time AI Analyze & Query Streaming Manager & Security Tensor Tez/ Spark Spark Storm BC-HControl Processing BigDL Presto Phoenix Flink Flow LLAP SQL Streaming /JStorm YARN Spark Hive HBase Pulsar Storage Kafka ZooKeeper HDFS BookKeeper Kerberos Data HTunnel Flume Ranger Collection
6 .HBase Scales 1. Nodes:6000+ nodes 2. Clusters:100+ clusters,largest cluster with 600+ nodes 3. Data:tens of PBs,max table with 1.6 PB & 20000+Regions 4. Peak QPS: 30 millions rows/second with about 300 nodes
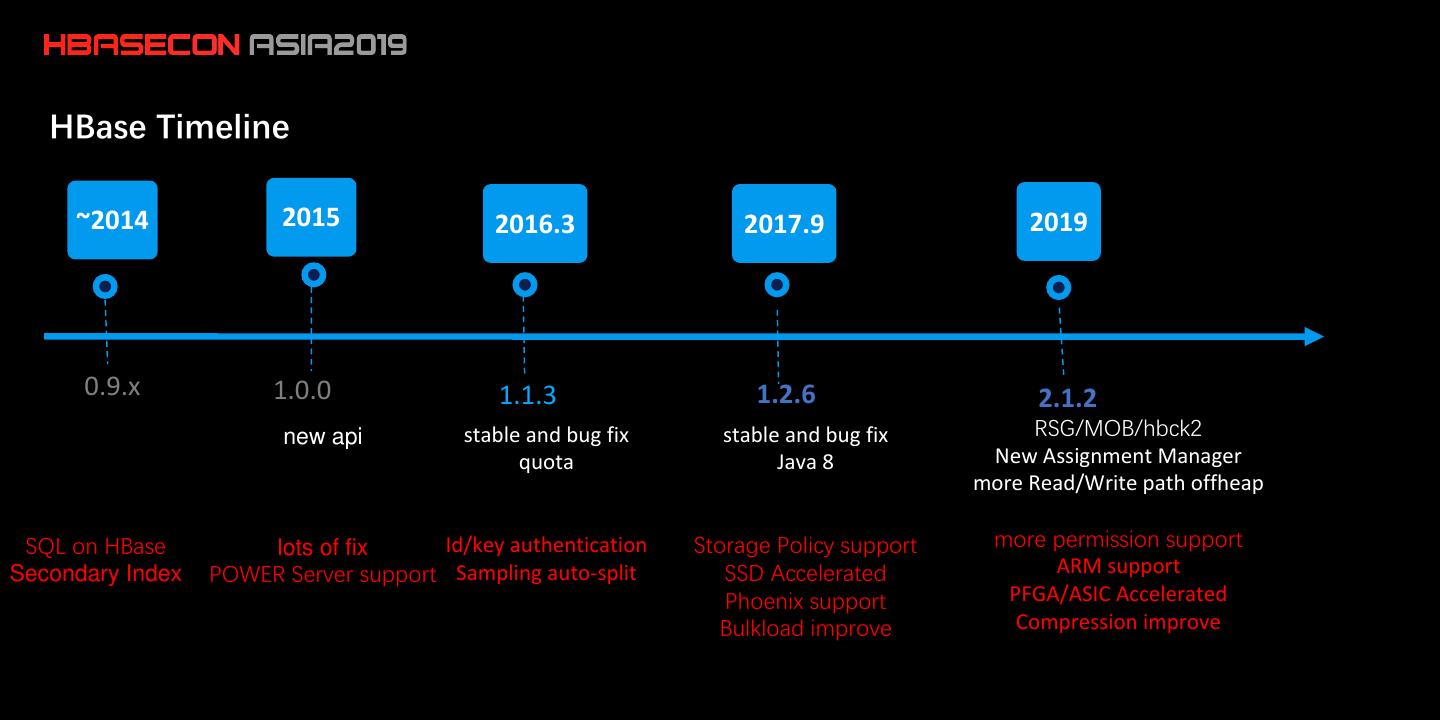
7 . HBase Timeline ~2014 2015 2016.3 2017.9 2019 0.9.x 1.0.0 1.1.3 1.2.6 2.1.2 new api stable and bug fix stable and bug fix RSG/MOB/hbck2 quota Java 8 New Assignment Manager more Read/Write path offheap SQL on HBase lots of fix Id/key authentication Storage Policy support more permission support Secondary Index POWER Server support Sampling auto-split SSD Accelerated ARM support Phoenix support PFGA/ASIC Accelerated Bulkload improve Compression improve
8 .Application Scenarios Consumption DPI Log/Monitor Location Small User Profile Web Pages Marketing .. Details Data Data Data Pictures HBase Phoenix Spark Hive Flink Storm MR/Bulkload Kylin .. API BC-HBase
9 .02 Write Path Improve
10 .Write path improve 1. Bulkload with pre-split table by sampling 2. Bulkload HFile Data locality 3. Compression data write path improve 4. SSD Accelerated
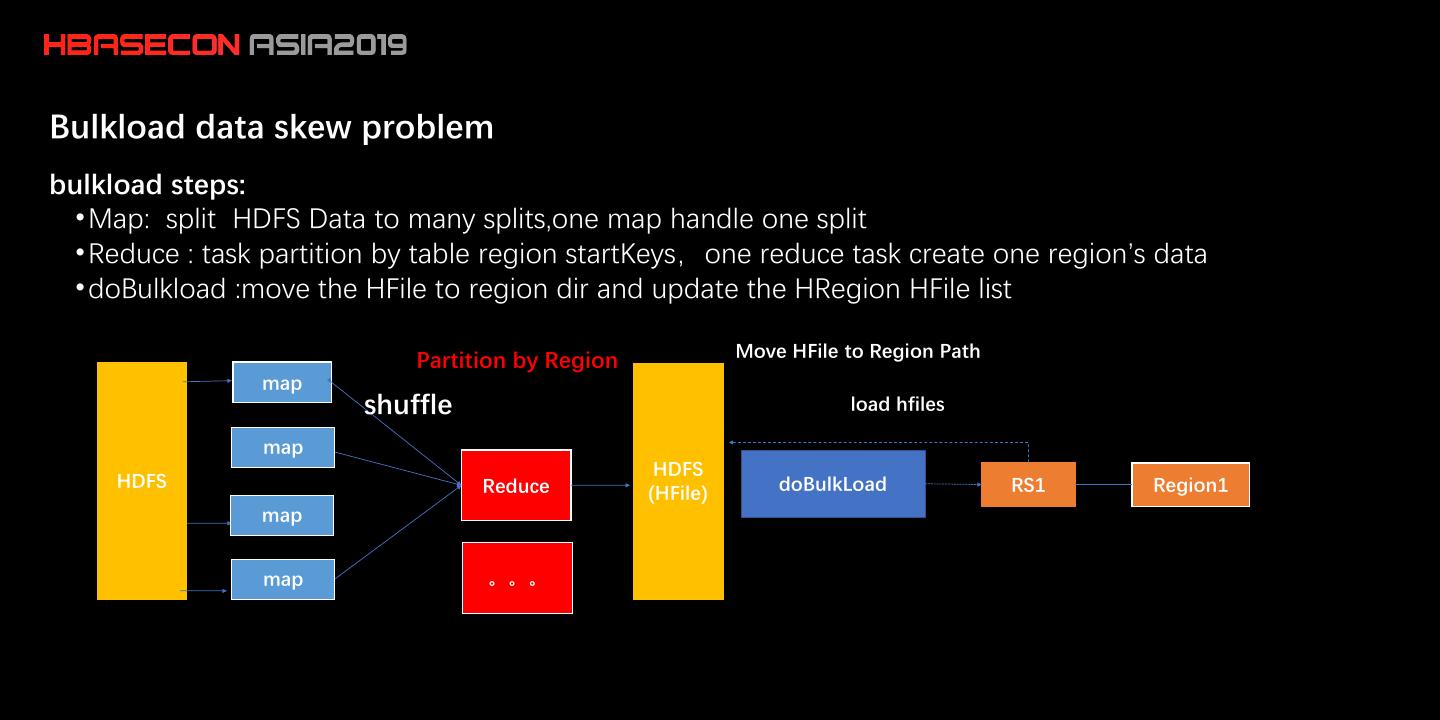
11 .Bulkload data skew problem bulkload steps: • Map: split HDFS Data to many splits,one map handle one split • Reduce : task partition by table region startKeys,one reduce task create one region’s data • doBulkload :move the HFile to region dir and update the HRegion HFile list Partition by Region Move HFile to Region Path map shuffle load hfiles map HDFS HDFS Reduce doBulkLoad RS1 Region1 (HFile) map map 。。。
12 .Bulkload data problem • table only one region by default • data skew case poor performance • hard to pre-split table or need to change the key to rowkey • application need to change the code to match the new key(rowkey) • why we need change the application sql or code ? ID IN OTHERS ROWKEY IN HBase BEFORE AFTER 139****1234 4321****931 USERID=139****1234 USERID=4321****931
13 .Bulkload data skew improve bulkload steps: • Map: split HDFS Data to many splits,one map handle one split • data smapling and pre-split by smapling data ,no need change the application code or sql any more! • Reduce : task partition by table region startKeys,one reduce task create one region’s HFile data • doBulkload :move the HFile to region dir and update the HRegion HFile list partition by regions Move HFile to Region Path map/ sampling Reduce shuffle load hfiles RS1 Region1 map/ Reduce sampling Region2 HDFS HDFS doBulkLoad RS1 map/ Reduce (HFile) Region3 sampling Reduce Region4 map/ sampling RS1 Reduce Region5
14 .Bulkload HFile data locality bulkload HFile Data locality Problem: • Bulkload HFile data locality is by reduce task ,not by the RegionServer of the Region • Bulkload HFile data locality too low,more network traffic with read/compaction Improve: • Bulkload Reduce task create one replica of the HFile on the RegionServer of the Region
15 .Compress table problem • Money is good : compression is a good choice to save the storage cost • But flush MemStore to HFile with compression can reduce performance and cost more cpu • bulkload to compression table slow than none-compression table also • Life is short : the small HFiles by flush or bulkload will be merged by compaction LSM Tree really always need compression??? Compcation flush bulkload HFile HFile HFile HFile Compression Compreesion
16 .Compress table improve HOW • Flush and bulkload HFile use none compression type : write path with no compression cost at all • Compreesion just happened in compaction Improve: • Access first small hfiles before compaction is fast same as none compression • Compcation will merge small hfiles to big hfiles with compression finally • First Compaction the small HFiles more faster with no decompression cost • also works for DATA_BLOCK_ENCODING
17 .SSD Accelerated with write path backgroup: • Node :12*6TB HDD + 1*1.6TB PCIe SSD • HDD:SSD =45:1 • How to use ssd more effective ? Improve: • Backport HSM to our 1.2.6 Version • WAL on ALL_SSD First : hbase.wal.storage.policy=ALL_SSD • HFile first created by bulkload or flush on ALL_SSD but table storage type is HOT(HDD) • ALL user write path happened in SSD,more faster than HDD • Small HFiles before compaction in SSD is good for reading and compaction
18 .Storage Policy • hot or import table data in ALL_SSD or ONE_SSD • SSD table region should keep more HFiles than HDD before minor compaction • too much compaction can reduce the ssd life • SSD random read is far faster than hdd • ONE_SSD bug found: HDFS-14512
19 .SSD and Compression SSD Compcation put bulkload HDD wal HFile HFile HFile HFile HFile HFile NONE Compression SNAPPY/GZ/ZSTD
20 .Jira and Config Jira ⚫HBASE-12596(bulkload needs to follow locality) ⚫HBASE-21810(bulkload support set hfile compression on client) ⚫HBASE-6572(Tiered HFile storage ) ⚫HBASE-20105(Allow flushes to target SSD storage) ⚫HDFS-14512(ONE_SSD policy will be violated while write data with DistributedFileSystem.create(....favoredNodes) Config hbase.wal.storage.policy=ALL_SSD create ‘test’, {NAME => ‘f', CONFIGURATION => {‘hbase.hstore.flush.storagepolicy' => 'ALL_SSD’}, COMPRESSION => 'NONE', METADATA => {'COMPRESSION_COMPACT' => 'GZ'}} Bulkload : -Dhbase.hstore.block.storage.policy=ALL_SSD - Dhbase.mapreduce.hfileoutputformat.compression=none
21 .03 Others
22 .Replication Backgroup • replication will happened in two different data center • user use bulkload not put api • bandwidth limit • RegionServer failed restart when add peer config cluster key error Improve: • Support HFile Bulkload Replication • support set bulkload HFile compression ,reduce the HFile transmission bandwidth from two data center • bug fix
23 .Replication Related Jira ⚫HBASE-13153(Bulk Loaded HFile Replication) ⚫HBASE-21810(bulkload support set hfile compression on client) ⚫HBASE-15769(Perform validation on cluster key for add_peer)
24 .Multi Tenant • Isolation: Slider vs RegionServerGroup RegionServerGroup Slider Isolation Physical isolation Base on YARN (vcores and memory) Use Case online service/import service offline or less import service Manager less clusters many clusters easy to manager hard to manager TIPS: create a group to hanlder meta table
25 .Multi Tenant HBase on Slider
26 .Multi Tenant • RegionServerGroup
27 .Multi Tenant • qps and bandwith quota set_quota TYPE => THROTTLE, USER => 'u1', LIMIT => '10M/sec’ set_quota TYPE => THROTTLE, USER => 'u1', LIMIT => ‘10000req/sec’ set_quota TYPE => THROTTLE, NAMESPACE => 'ns1', LIMIT => '10000req/sec'
28 .Authorization & Authentication 1. Authorization 1. auth base on Ranger 2. orginal just support: admin/create/read/write 3. more permission support :alter,drop,delete,modify,deletecolumn... 2. Authentication 1. White List base on Zookeeper 2. Use Kerberos or id/key authorization support 3. BCID : id/key authorization ,simple and effective
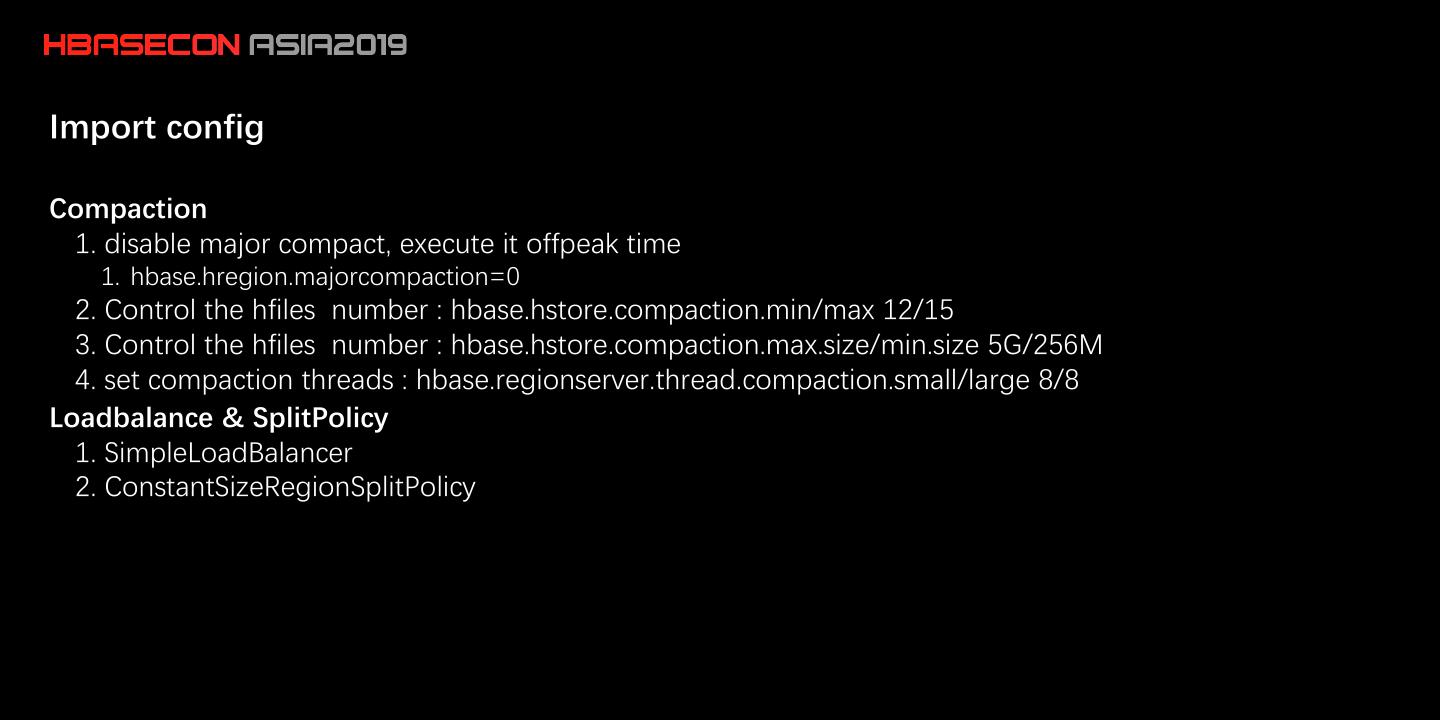
29 .Import config RPC handler : hbase.regionserver.handler.count queue : separation of read/write Read 1. BucketCache offheap 2. HDFS Short-Circuit Read 3. Hedged Read enable Write 1. Bulkload 2. Multi wal 3. MSLAB ENABLE 4. blockingStoreFiles
3秒后跳转登录页面
去登陆

