展开查看详情
2 .Further GC optimization for HBase 2.x:
Reading HFileBlock into offheap directly
Anoop Sam John / Zheng Hu
�
3 .Abstract
❏ Background: Why offheap HDFS block reading
❏ Idea & Implementation
❏ Performance Evaluation
❏ Best Practice
�
4 .Abstract
❏ Background: Why offheap HDFS block reading
❏ Idea & Implementation
❏ Performance Evaluation
❏ Best Practice
�
5 .Background: current offheap read/write path
�
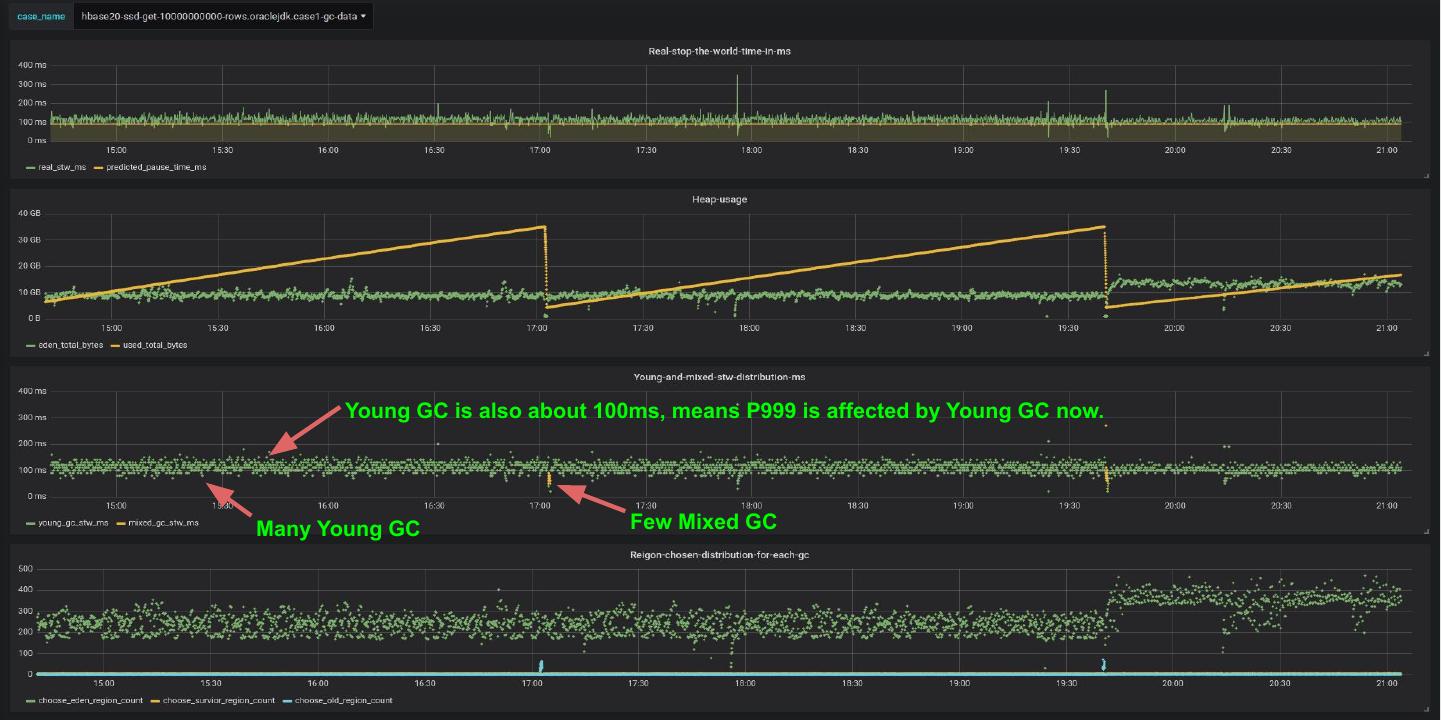
7 . Young GC is also about 100ms, means P999 is affected by Young GC now.
Many Young GC Few Mixed GC
�
8 . Background: still GC issue in some case ?
➢ High young GC pressure if cachHitRatio is not 100%
○ Reading the Block from HFile is still copied to the heap firstly
○ The heap block won’t be garbage collected unless:
■ Read is complete and the results been created (CellBlock) in the RPC responder area.
■ the WriterThread of BucketCache flushes the Block to offheap IOEngine successfully
○ A large number of young generation objects, which leads to the raising young GC pressure.
�
9 .Abstract
❏ Background: Why offheap HDFS block reading
❏ Idea & Implementation
❏ Performance Evaluation
❏ Best Practice
�
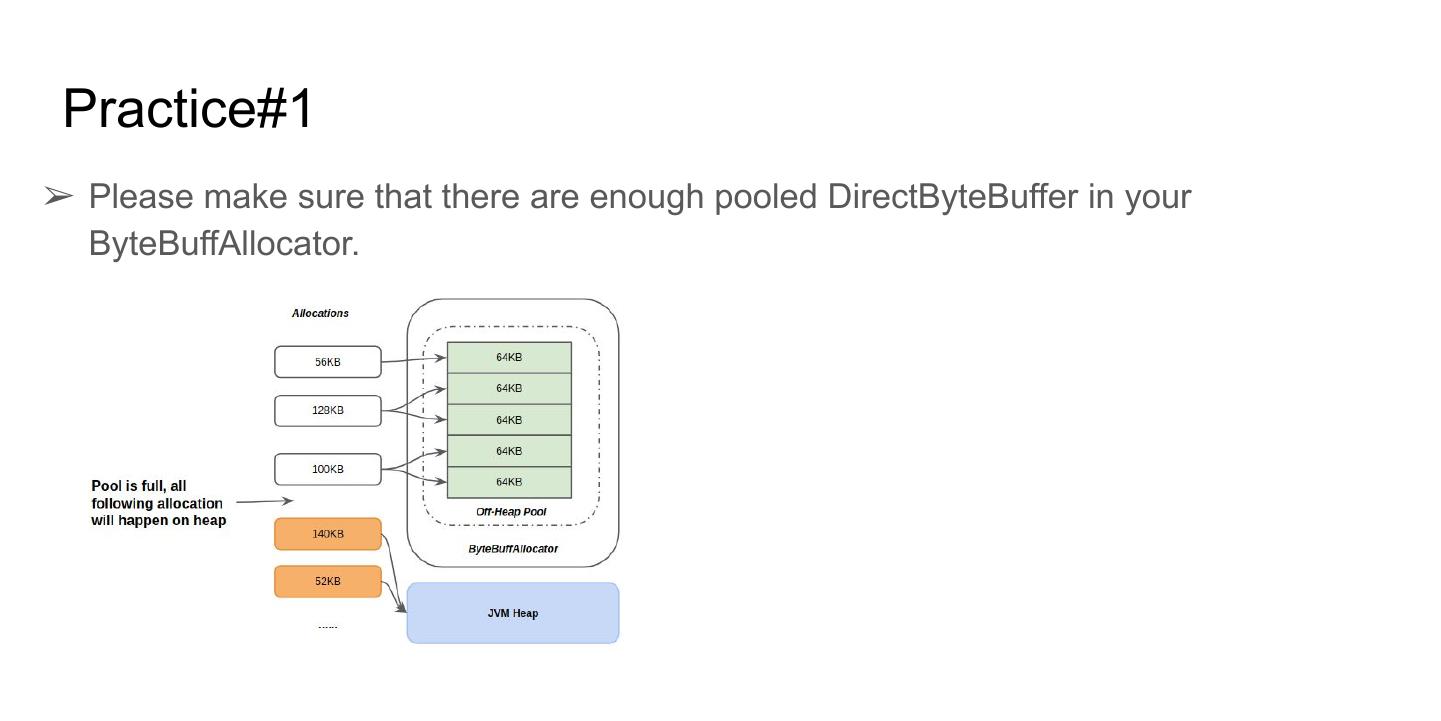
10 .Basic Idea: Just read the block from HFile to pooled ByteBuffers
�
11 .Review: how did we cache a block in BucketCache ?
RpcHandler
RPC layer
RAMCache
Block Block
heap
Bucket Bucket
BucketCache offheap
Cache layer
HDFS layer
Block HFile
HFile
�
12 .Review: how did we cache a block in BucketCache ?
RpcHandler
<3> RPC layer <1> Read block from HFile to pooled ByteBuffers;
<2> Cache the block in a temporary map named RAMCache for
RAMCache
avoiding the unstable latency if flushing to offheap bucket cache
Block Block synchronously.
heap
<1> The WriterThreads of BucketCache flush the block to offheap array
asynchronously once #2 finished.
Bucket Bucket
BucketCache offheap <3> Encoded the cells from block and shipped to RPC client.
<2> Cache layer
HDFS layer
Block HFile
HFile
�
13 .Problem: Block may be accessed by other RPC Handlers ?
RpcHandler RpcHandler
<3> RPC layer
<2.5> Once #2 load the block into RAMCache, then other RpcHandler
RAMCache may hit the block and reference to it.
Block Block
offheap
<1>
Bucket Bucket
BucketCache offheap
<2> Cache layer
HDFS layer
Block HFile
HFile
�
14 .Problem: Block may be accessed by other RPC Handlers ?
RpcHandler RpcHandler
<3> RPC layer
<2.5> Once #2 load the block into RAMCache, then other RpcHandler
RAMCache may hit the block and reference to it.
Block Block
offheap
<1>
Then how should we release the offheap block back to the
pool without causing any memory leak issues?
Bucket Bucket
BucketCache offheap
<2> Cache layer
HDFS layer
Block HFile
HFile
�
15 .Problem: Block may be accessed by other RPC Handlers ?
RpcHandler RpcHandler
<3> RPC layer
<2.5> Once #2 load the block into RAMCache, then other RpcHandler
RAMCache may hit the block and reference to it.
Block Block
offheap
<1>
Then how should we release the offheap block back to the
pool without causing any memory leak issues?
Bucket Bucket
BucketCache offheap Reference count:
<2> Cache layer 1. Consider the RAMCache as a separate reference path;
2. RPC handlers are another separate reference paths.
HDFS layer
Block HFile
HFile
�
16 .Core Idea
1. Maintain a refCount in block’s ByteBuff, once allocated, its refCount will be initialized to 1;
2. If put it into RAMCache, then refCount ++;
3. If removed from RAMCache, then refCount --;
4. If some RPC hit the ByteBuff in RAMCache, then refCount ++;
5. Once RPC finished, then ByteBuff’s refCount --;
6. If its refCount decrease to zero, we MUST deallocate the ByteBuff which means putting its NIO
ByteBuffers back to ByteBuffAllocator. Besides, nobody can access the ByteBuff with refCount = 0.
�
17 .Implementation
➢ General ByteBuffer Allocator
➢ Reference Count
➢ DownStream API Support
➢ Other issues:
○ Unify the refCnt of BucketEntry and HFileBlock into one
○ Combined the BucketEntry sub-classes into one
�
19 .General Allocator
SingleByteBuff
MultiByteBuff
Performance issues between SingleByteBuff and MultiByteBuff
�
20 . Reference Count
➢ Use Netty’s AbstractReferenceCounted
○ Use unsafe/safe method to maintain the reference count value.
○ Once the reference count value decreasing to zero, will trigger the registered Recycler to deallocate.
○ The duplicate or slice ByteBuff will share the same RefCnt with the original one.
■ if want to retain the buffer even if original one did a release, can do as the following:
Retain the duplicated one before release the original one
�
21 . Downstream API Support
➢ ByteBuffer positional read interface (HBASE-21946)
○ Need support from Apache Hadoop (Hadoop >=2.9.3)
➢ Checksum validation methods (HBASE-21917)
○ SingleByteBuff will use the hadoop native lib
○ MultiByteBuff will copy to heap and validate the checksum.
➢ Block decompression methods (HBASE-21937)
○ Copy to an temporary small heap buffer and decompression
�
22 .Unify the refCnt of BucketEntry and HFileBlock into one
�
23 .Unify the refCnt of BucketEntry and HFileBlock into one
RefCnt for HFileBlock
RefCnt for BucketEntry
Just pass the BucketEntry’s refCnt to HFileBlock. Then
BucketEntry and HFileBlock will share an single RefCnt.
�
24 . Combined the BucketEntry sub-classes into one
➢ BucketEntry
○ Exclusive heap block
○ No reference count.
➢ SharedMemoryBucketEntry
○ Shared offheap block BucketEntry
○ Use a AtomicInteger to maintain the reference count. With netty’s RefCnt inside, which will use
safe/unsafe way to update the refCnt.
➢ UnsafeSharedMemoryBucketEntry
○ Shared offheap block
○ Use integer and unsafe CAS to maintain the reference count.
Before HBASE-21879 After HBASE-21879
�
25 .Abstract
❏ Background: Why offheap HDFS block reading
❏ Idea & Implementation
❏ Performance Evaluation
❏ Best Practice
�
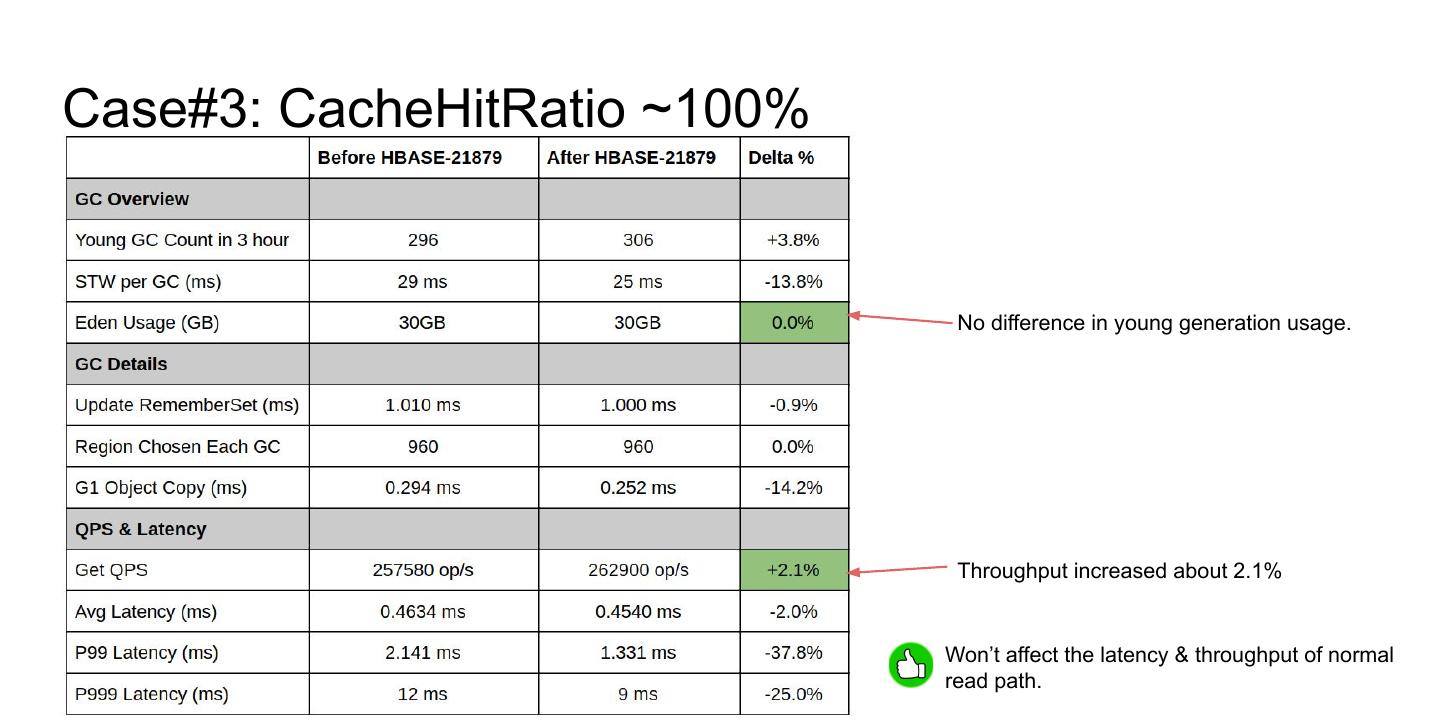
26 .Test Cases
Three test cases to prove the performance improvement after HBASE-21879
➢ Disabled BlockCache cache: CacheHitRatio ~ 0%
➢ CacheHitRatio~65%
➢ CacheHitRatio~100%
�
27 .Environment & Workload
Load 10 billion rows , each row with size=100 byte.
(about total 700GB in the clusters)
Major compaction to ensure the locality is 1.0
�
28 .Case#1: Disabled BlockCache, CacheHitRatio~0%
�
29 .Case#1: Disabled BlockCache, CacheHitRatio~0%
Decreased almost 81.7% young usage.
Heap occupation after GC decreased a bit.
Throughtput increased 17.2%, latency decreased
about 14.7%
�