


















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Distributed Bitmap Index Solution & Lightweight SQL Engine – Lemon SQL
这个议题由华为的工程师郝行军和刘志分享,其实是两个相对独立的议题,一个是基于 HBase 实现 Bitmap 索引,另外一个是基于 HBase 实现轻量级的 SQL 引擎。
首先华为提出在安全领域,会对用户打很多标签。然后业务层面通过指定各种标签组合(用AND,OR,NOT等)来点查用户集合。因此,华为设计了基于 HBase 的 bitmap索引,借助 Coproccessor 来同时更新主表和索引表。
第二部分,华为工程师刘志介绍他们基于 HBase 实现的一种轻量级 SQL 查询引擎,相比 Phoenix,他们的实现更加轻量级、性能更高、吞吐扩展也更强。感兴趣的朋友可以在PPT末尾扫描他们的微信,跟两位工程师直接交流。
展开查看详情
1 .
2 .Distributed Bitmap Index Solution Xingjun Hao Huawei
3 .Motivation •Motivation for designing software - HBase is suitable for storing massive tag data Gender:male Info:Gender Info:Age Car:Brand House:Address Entity1 Male 20_25 Audi Education: Bachelor Entity2 Male 25_30 Urban Car Entity3 Female 25_30 Audi Entity4 Male 20_25 Suburbs Age:20-25 Hbase Data Model is suitable for tag data storage House 1. Distributed LSM-based storage: PB-level storage and good write performance 1. Sorted RowKey -> Support Quick Point Query and Range Query Marriage: Married 2. Columns -> Support Each entity has a custom tag schema. 3. Cell -> Can have multi-value, can be empty. - Lack of efficient indices when processing ad hoc queries Scenrio Advantage Get(“RowKeyX”)/Scan(“RowKeyX” -> “RowKeyY”) Good Put Good Fexiable Good Ad-hoc Query(“TagA AND TagB AND (TagX OR TagY)”) Poor
4 . Search Example: Security project Profile JSON Communication Activities … Applications Production data rate XML Subject Store Import Tools Link/Graph • ~ 1 TB per day Persons Locations Travel CSV Objects • Storage data of a year ~ 400TB Events Properties Network Voice • each event ~1 KB in size … Image ML/DL Consume data rate • 1000 queries / second • Desire to get the 300 rows collection within 100ms in per query Engineer may query any of the 500 attributes • Each query may involve conditions on 5 ~ 8 attributes. Ad-hoc queries • Eg. select * from table WHERE (location = “area-A” ) • select * from table WHERE (location = “area-A” AND time = “20190705”) • select * from table WHERE (location = "area-A” OR location = "area-B” AND time = “20190705”) HBase can't satisfy this scene.
5 .Applications Involve Massive Tags AI:select * from pictures where theme =“monkey” Graph Computing : select * from graphs where edge = “obama” Time series: select * from timeseries where time = ‘20190705H22:00’ Spatial temporal: select * from spatialtemporal where location = ‘wx4g0e’and time = ‘20190705H22:00’
6 .Searching and Indexing Requirements •Some common features of the large tag datasets – Read-mostly – Large high-dimensional data: millions or billions of records, each record with tens or hundreds of attributes – Many queries are high-dimensional point queries or partial range queries – Most users desire to modify queries interactively •Existing database software not specialized for these tasks – Secondary index on HBase: slow, low storage efficiency – ES/lucene: cannot be updated frequently
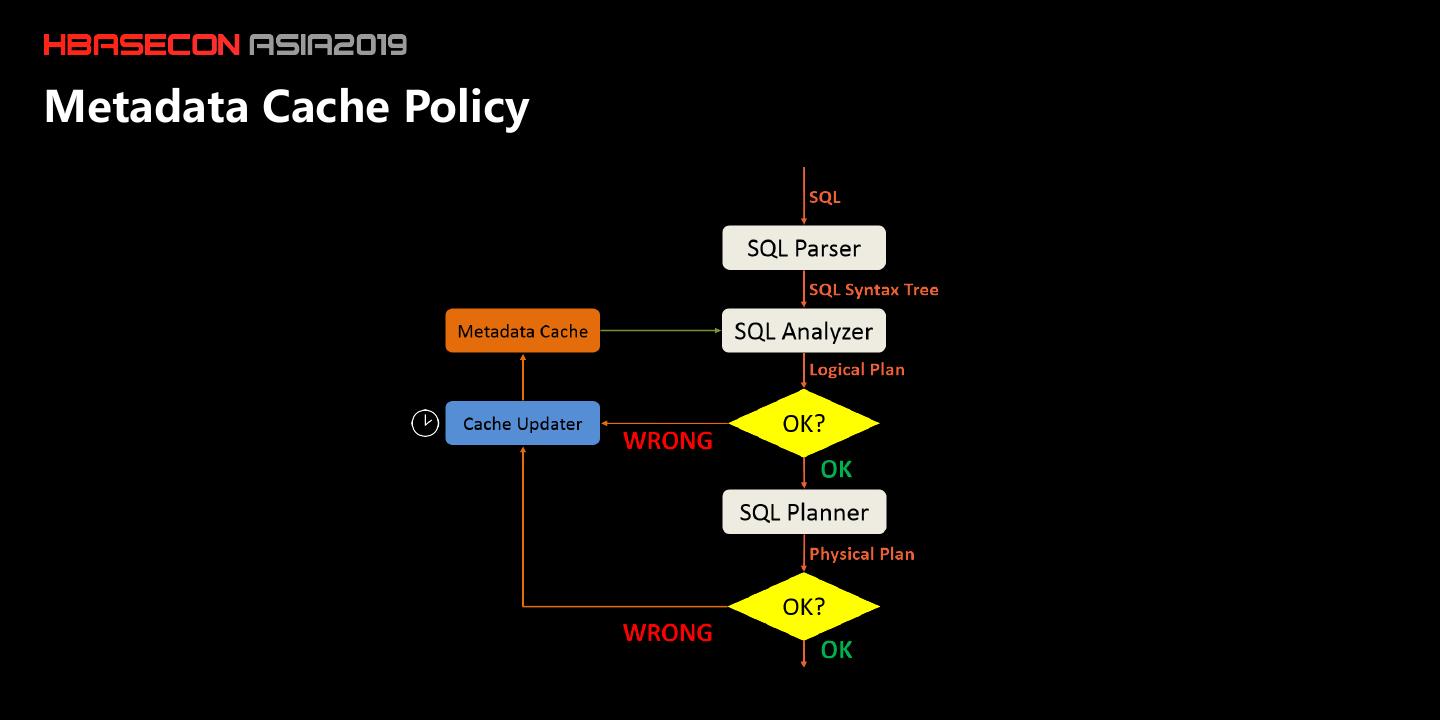
7 .Issues to Be Discussed •Framework : Organization of data on HBase – Data Organization: An entity table is used to store primary data, while an index table to to store bitmap index data. – Index Schema: The Bitmap index is actually an inverted index based bitmap index framework. •Implement : – Index implement: Coprocessor-based bitmap index building and querying. – Index Data partition. •API – Write Data with HBase API – Normal Query/ Paging Query/ Top-N Query/ Counting Query/ Sample Query
8 .Framework: Concept Gender:male Education: Bachelor Car Term Age:20-25 House Marriage: Married Entity
9 .Framework: Organization of data Overview Married Age:20_30 City:SZ Car ... Entity Table ... Married Age:30_40 City:GZ House ... Entity Key-> {TermX, TermY, TermZ, ...} Married Index Table Age:20_30 ... Term X -> {EntityKey1, EntityKey2, City:SZ EntityKey3, …}
10 .Framework: An Example of Organization of data value ColumnFamily:Column Entity Table Info:Gender Info:Age Car:Brand House:Address Entity0 Male 20_25 Audi Entity1 Male 25_30 Audi Entity Key-> {TermX, TermY, TermZ, ...} Rowkey Entity2 Female 25_30 Urban Entity3 Male 20_25 Suburbs Index: 1101 Index: 0110 Index: 1100 Index Table Gender:Male B Age:25_30 B Term X -> {EntityKey1, EntityKey2, Car:Brand B EntityKey3, …}
11 . GENDER:Male AND (Age:25_30 OR CarBrand:Audi) ❶ Recevie Query Conditions Framework: Index Schema Index: 1101 Index: 0110 Index: 1100 Gender:Male B Each attribute value relates to a Bitmap Lemon Client Age:25_30 B Condition 101111010010101... GENDER:Male AND (Age:25_30 OR CarBrand:Audi) CarBrand:Audi B Each bit represent whether an Entity Gender:Male 1 1 0 1 have this attribute Age:25_30 0 1 1 0 Coprocessor Conditions 101111010010... CarBrand:Audi 1 1 0 0 & 011001011110... AST Tree & 101001011010... e.g. 1 AND (0 OR 1) = 1 Bitmap Computing & Query 101111011010... Optimization & 1 1 0 0 101010011010... Query Plan Fetch Entities And Return Info:Gender Info:Age Car:Brand Entity0 Male 20_25 Audi Entity1 Male 25_30 Audi
12 .Issues to Be Discussed •Framework : Organization of data on HBase – Data Organization: An entity table is used to store primary data, while an index table to store bitmap index data. – Index Schema: The Bitmap index is actually an inverted index based bitmap index framework. •Implement : – Index implement: Coprocessor-based bitmap index building and querying. – Index Data partition. •API – Write Data with HBase API – Normal Query/ Paging Query/ Top-N Query/ Counting Query/ Sample Query
13 . Implement: Coprocessor-based bitmap index building RowKey U0100100 Column Family (I) Age City Term FieldName: Age, FieldValue: 20_30 20_30 SZ Term FieldName: City, FieldValue: SZ U0200111 Age30_40 City_GZ Index Region 30_40 GZ Entity Column Family (B) Column Family (I) Region U0100100 -> 1 Coprocessor Assign a ID to RPC Index RPC Handler U0200111 -> 2 Extract terms based on each Entity Client term extraction rules 1 -> U0100100 and write index data to index region 2 -> U0200111 Index Age20_30 -> {1} Region Age30_40 -> {2} Inverted index of Term City_GZ -> {2} 2.Only build the inverted index when write to Entity ID City_SZ -> {1} to MemStore. Married -> {1,2}
14 .Implement: Coprocessor-based bitmap index building (continued) Client HFile HFile {1, 3, 5, 6, 7, 10, 12, 14, 16,…} HFile MemStore ❹ HFile Compaction ❸ {1, 3, 7, 10, 12, 16,…} 3. Flush phase: build the bitmap index of the HFiles. 4. Compaction phase: rebuild bitmap index MemStore HFile when merge HFiles. Flush
15 .Implement: Data Partition if there are 10 billions entities contains the same term? The bitmap will be about 1GB. Harm read performance Idea: Each bitmap index is responsible for only a portion of the entity Index: 1101 Index: 0110 Index: 1100 Index: 11 Index: 01 Index: 11 Gender:Male B 1_Gender:Male B Age:25_30 B 1_Age:25_30 B Car:Brand B 1_Car:Brand B 1 1 0 1 Index: 01 Index: 10 Index: 00 2_Gender:Male B 1 1 0 1 2_Age:25_30 B 2_Car:Brand B
16 .Implement: Data Partition ID01 ID11 ID21 ID31 ID41 ID51 ID61 ID71 ID81 ID02 ID12 ID22 ID32 ID42 ID52 ID62 ID72 ID82 Entity Table ID03 ID13 ID23 ID33 ID43 ID53 ID63 ID73 ID83 Data Partition . ID04 ID05 ID06 ID14 ID15 ID16 ID17 ID24 ID25 ID26 . ID34 ID35 ID36 ID44 ID45 ID46 ID54 ID55 ID56 ID57 . ID64 ID65 ID66 ID67 ID74 ID75 ID76 ID77 ID84 ID85 ID86 ID87 ID07 ID27 ID37 ID47 Index Table ID01 ID11 ID21 ID31 ID41 ID51 ID61 ID71 ID81 Data Partition ID02 ID12 ID22 ID32 ID42 ID52 ID62 ID72 ID82 ID03 ID13 ID23 ID33 ID43 ID53 ID63 ID73 ID83 ID04 ID14 ID24 ID34 ID44 ID54 ID64 ID74 ID84 ID05 ID15 ID25 ID35 ID45 ID55 ID65 ID75 ID85 ID06 ID16 ID26 ID36 ID46 ID56 ID66 ID76 ID86 ID07 ID17 ID27 ID37 ID47 ID57 ID67 ID77 ID87 Index Index Index Partition1 Partition2 Partition3 1. The number of regions of entity table and number of shard of index table are specified by user 2. 1 shard is response for 1 or more regions of entity table.
17 .Implement: Coprocessor-based bitmap index query Lemon Client Condition GENDER:Male AND MARRIAGE:Married AND AGE:25-30 AND BLOOD_TYPE:A AND CAROWNER Entity coprocessor is response for distributing the requests to Index Coprocessors Entity Coprocessor Index Coprocessor Index Coprocessor Shard Shard 001111010010... 001111010010... Conditions Conditions & & 111001011110... 111001011110... & & AST Tree AST Tree 001101011010... 001101011010... & & 101001011010... 101001011010... Query Query Optimization & Optimization & 000010011010... 000010011010... Query Query Query Plan Query Plan Execution Execution
18 .Issues to Be Discussed •Framework : Organization of data on HBase – Data Organization: An entity table is used to store primary data, while an index table to store bitmap index data. – Index Schema: The Bitmap index is actually an inverted index based bitmap index framework. •Implement – Index implement: Coprocessor-based bitmap index building and querying. – Index Data partition. •API – Write Data with HBase API – Normal Query/ Paging Query/ Top-N Query/ Counting Query/ Sample Query
19 .API - Put: Write interfaces are the same as hbase. - Query: Query Grammar Query grammar in BNF: Query ::= ( Clause )+ Clause ::= ["AND", "OR", "NOT"] ([Field:]Value | "(" Query ")" ) • A Query is a series of clauses. Each Clause can also be a nested query • Supports AND/OR/NOT operators. AND indicates this clause is required, NOT indicates this clause is prohibited, OR indicates this clause should appear in the matching results. The default operator is OR is none operator specified. • Parenthese “(”“)”can be used to improve the priority of a sub-query
20 .Query(1): Normal Query/ Paging Query/ Top-N Query Query records that meet the combined label criteria for "City: Shenzhen AND Age:20_30", and request the first time to retrieve 10 records: LemonTable lemonTable = new LemonTable(table); LemonQuery query = LemonQuery.builder() .setQuery("City:Shenzhen AND Age:20_30") .setCaching(10) .build(); ResultSet resultSet = lemonTable.query(query); // Data records that are cached to the Client side can be accessed as follows: List<EntityEntry> entries = resultSet.listRows(); // Get 20 rows of records from index position 100 resultSet.listRows(100, 20); // Top 10 records can be obtained by: List<EntityEntry> entries = resultSet.listRows(10);
21 .Query(2): Count Query LemonTable lemonTable = new LemonTable(table); LemonQuery query = LemonQuery.builder() .setQuery("City:Shenzhen AND (Age:10_20 OR Age:20_30) AND Occupation:Engineer") //Counting .setCountOnly() .addFamily(TableTmpl.FAM_M) .build(); ResultSet resultSet = lemonTable.query(query); // Read count. int count = resultSet.getCount();
22 .Query(3): Sampling Query The result of a random query for a data shard (normal query sends requests to all data shards): LemonQuery query = LemonQuery.builder() .setQuery("City:Shenzhen AND (Age:10_20 OR Age:20_30)") … .setSampling() .addFamily(TableTmpl.FAM_M) Samping Query .setCaching(CACHING) .build(); ResultSet resultSet = lt.query(query); … // List all the caching rows. List<EntityEntry> entries = resultSet.listRows(); Normal Query
23 .Future 1. Better Bitmap Memory Management. 2. Range Query 3. ASync HBase client 4. Bitmap Calculation On FPGA
24 .Lightweight SQL Engine – Lemon SQL Zhi Liu Huawei
25 .Agenda • Why Lemon SQL • What to do, and what not to do • How to do • Lemon SQL current • Lemon SQL future
26 .Agenda • Why lemon SQL • What to do, and what not to do • How to do • Lemon SQL current • Lemon SQL future
27 .Why Lemon SQL? Why not phoenix?
28 .Why Lemon SQL? Problems of phoenix: 1. Too heavy Transaction, Join, View, Index, … Code lines: 30w+ 2. Low performance on OLTP scene 3. Poor functional scalability
29 .Agenda • Why Lemon SQL • What to do, and what not to do • How to do • Lemon SQL current • Lemon SQL future
3秒后跳转登录页面
去登陆

