展开查看详情
1 .Real-time OLAP Architecture in Apache Kylin v3.0 Shaofeng Shi | 史少锋 Apache Kylin committer & PMC Yanghong Zhong | 钟阳红 Apache Kylin committer & PMC
2 .Agenda New Apache Kylin Architecture for Real-time Real-time Data (cubing) Flow Real-time Query Flow Low Latency High Availability Performance
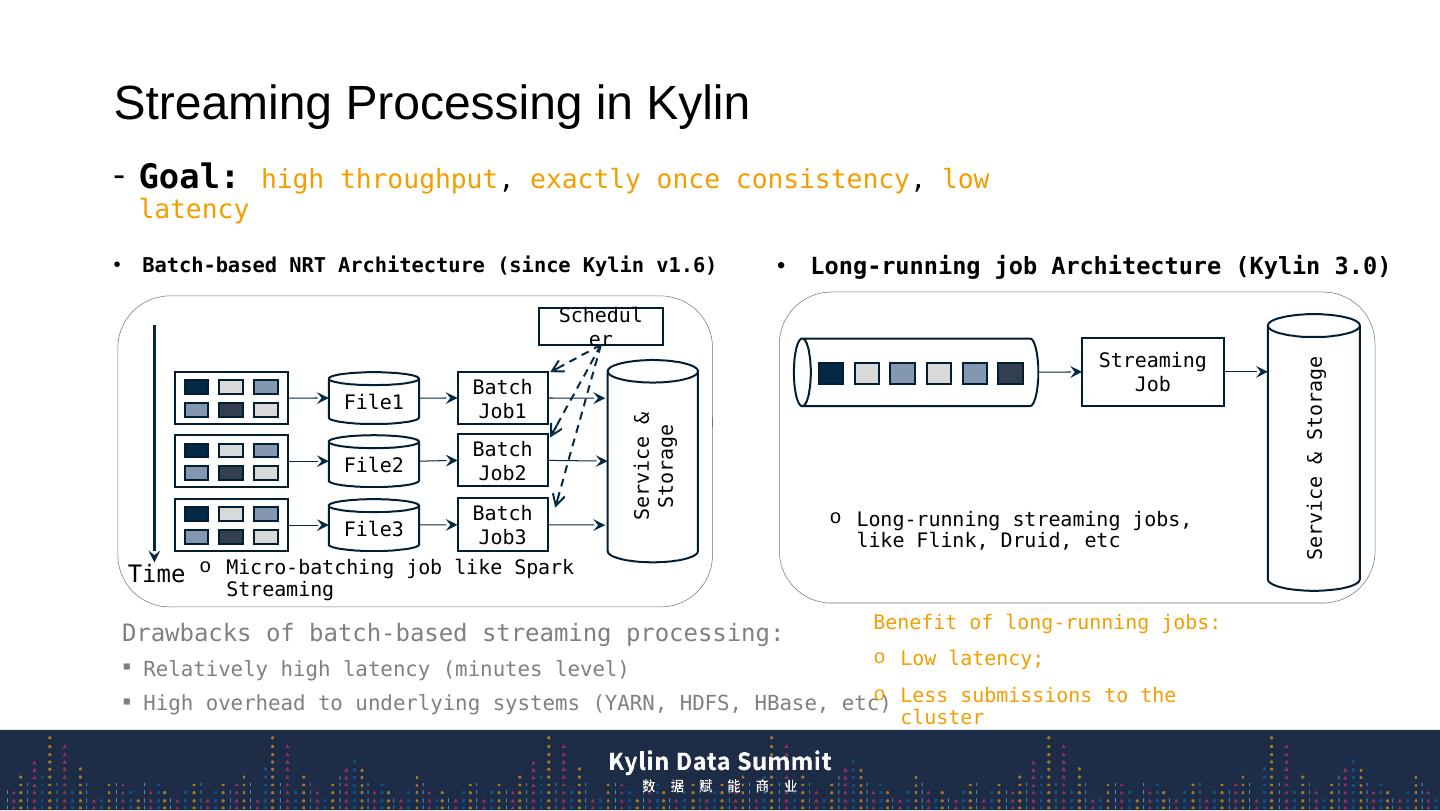
3 .Streaming Processing in Kylin Batch-based NRT Architecture (since Kylin v1.6) Long-running job Architecture (Kylin 3.0) Service & Storage File1 Batch Job1 File2 Batch Job2 File3 Batch Job3 Scheduler Time Streaming Job Service & Storage Goal: high throughput , exactly once consistency , low latency Drawbacks of batch-based streaming processing: Relatively high latency (minutes level) High overhead to underlying systems (YARN, HDFS, HBase, etc) Long-ru nning streaming jobs, like Flink , Druid, etc Micro-batching job like Spark Streaming Benefit of long-running jobs: Low latency; Less submissions to the cluster
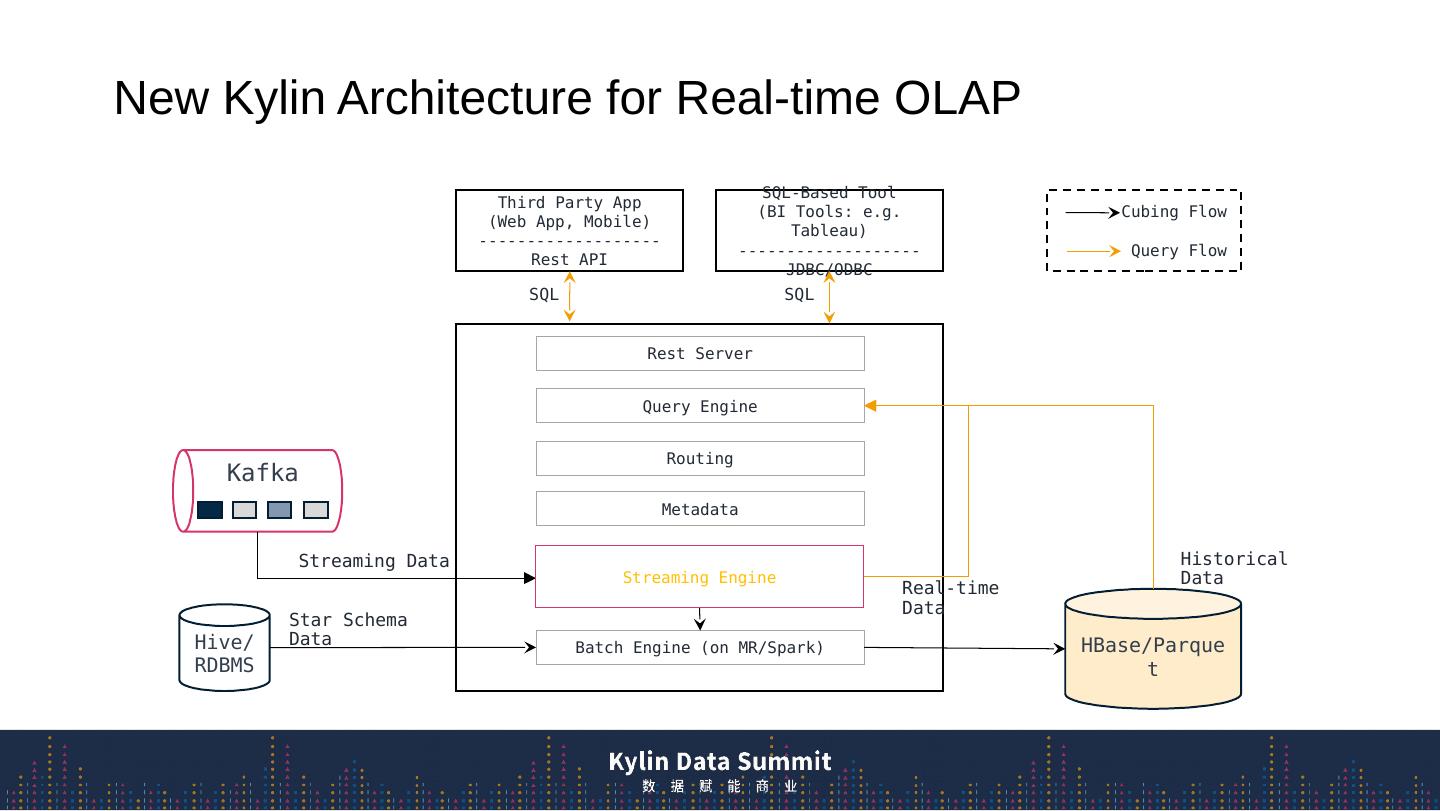
4 .New Kylin Architecture for Real-time OLAP Rest Server Query Engine Routing Metadata Batch Engine (on MR/Spark) Third Party App (Web App, Mobile) ------------------- Rest API SQL-Based Tool (BI Tools: e.g. Tableau) ------------------- JDBC/ODBC Kafka Hive/RDBMS HBase/Parquet Cubing Flow Query Flow SQL SQL Real-time Data Historical Data Streaming Data Star Schema Data Streaming Engine
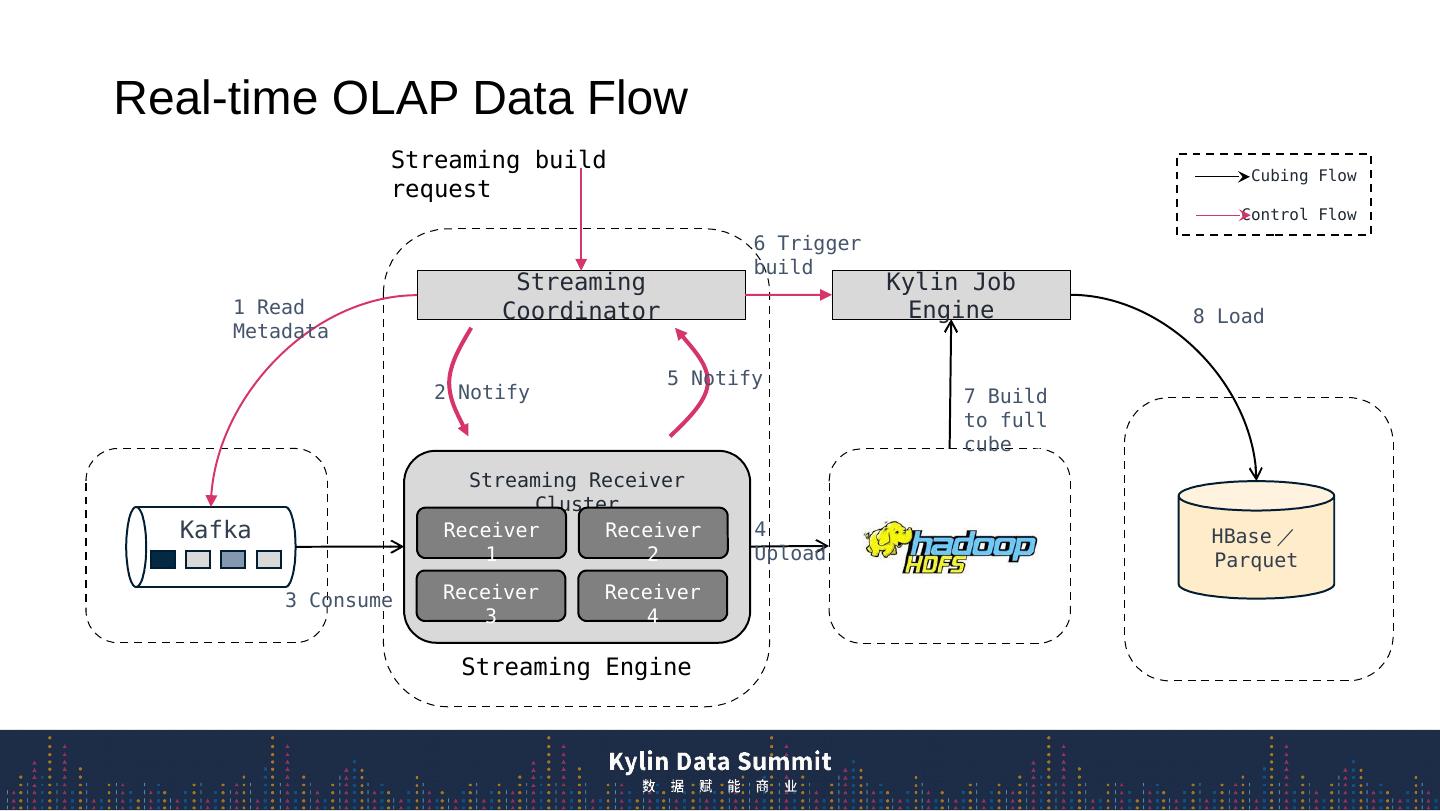
5 .Real-time OLAP Data Flow Streaming Engine Streaming Receiver Cluster Streaming Coordinator Receiver 2 Receiver 3 Receiver 1 Receiver 4 S treaming build request Kafka 1 Read Metadata 3 Consume 2 Notify HBase / Parquet 4 Upload 5 Notify Kylin Job Engine 6 Trigger build 7 Build to full cube 8 Load Cubing Flow Control Flow
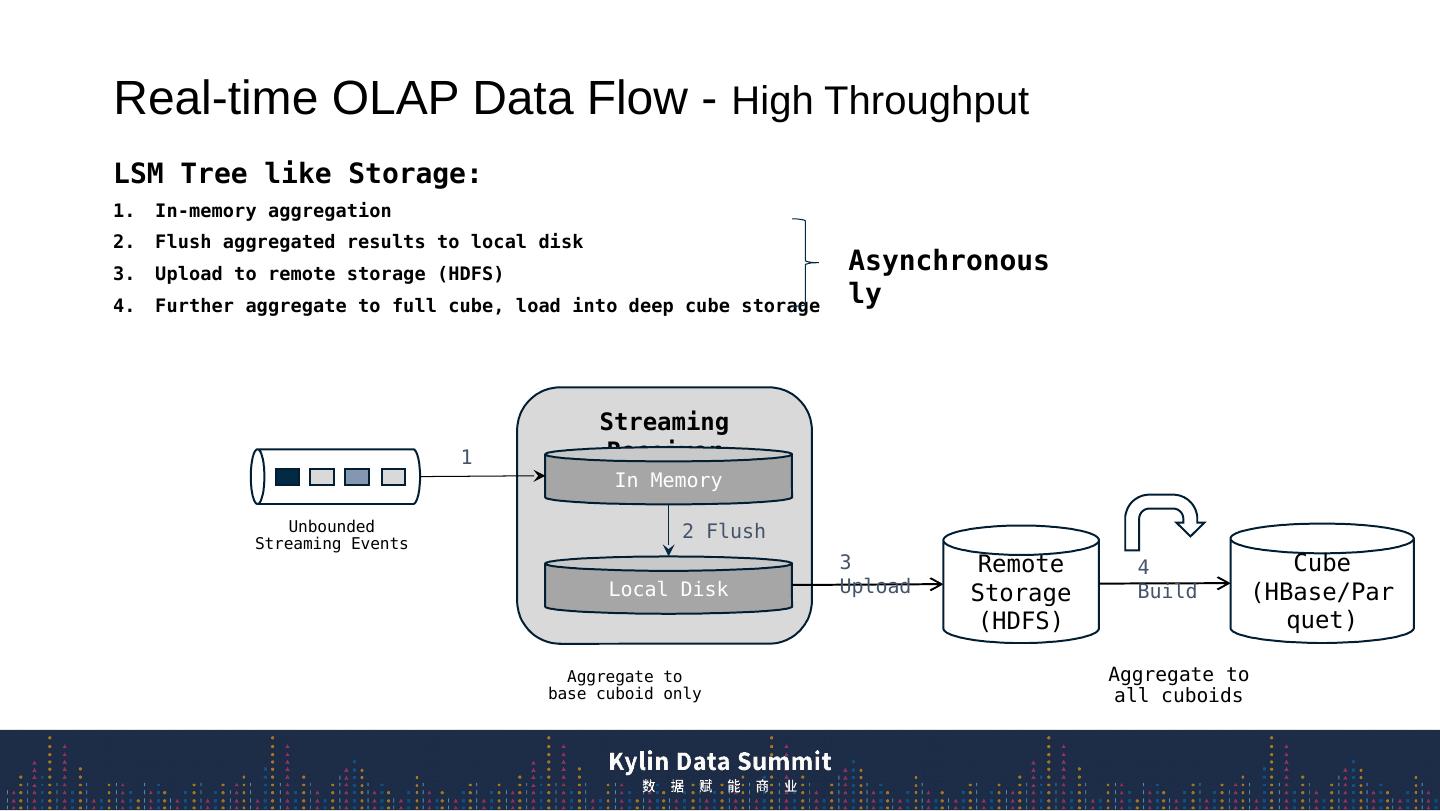
6 .Real-time OLAP Data F low - High Throughput Streaming Receiver In Memory Local Disk Unbounded Streaming Events LSM Tree like Storage: In-memory aggregation F lush aggregated results to local disk Upload to remote storage (HDFS) Further aggregate to full cube, load into deep cube storage Remote Storage (HDFS) 1 2 Flush 3 Upload Cube (HBase/Parquet) 4 Build Asynchronously Aggregate to all cuboids Aggregate to base cuboid only
7 .Fragment s Real-time OLAP Data F low – State Transition Segment: Defined by event time rather than processing time, [start time, end time) Auto generated by tumbling window with fixed time range (default 1 seg per hour) State change from active to immutable by session window (no message arrives for certain time) Seg_4 1 … J Active Segments Seg _3 Seg_2 Seg_1 1 … L 1 … M 1 … N Immutable Segments Open to Write Close to Process In Memory Store Remote Storage Unbounded Streaming Events
8 .Structure of Local State on Disk
9 .Real-time OLAP Data F low – Exactly Once Consistency Local Checkpoint Date Time Data Source State( Partition Offsets ) Local State( SeqID of Active Segments ) 2016/10/01 12:00:00 1,x 2,y 3,z Seg_5, I Seg_4, J Seg_3, K Kafka Seg_ 5 Seg_4 Seg_3 Topic_1 Part_1 1 … I 1 … J 1 … K Active Segments ... x x+1 … Topic_1 Part_2 ... y x+1 … Topic_1 Part_3 ... z z+1 … Local Checkpoint
10 .Real-time OLAP Data F low – Exactly Once Consistency Remote Checkpoint Checkpoint is saved to Cube Segment metadata after HBase segment be built “segments”:[{ …, " stream_source_checkpoint ": {"0":8946898241, “1”: 8193859535, ...} }, ] The checkpoint info is the smallest/earliest partition offsets on the streaming receiver when real-time segment is sent to full build.
11 .Streaming Engine Real-time OLAP Query Flow Streaming Coordinator Historical (HBase/Parquet) 3. Scan real-time Query Engine 1 2. Scan history SQL Query SQL Response Query Flow Control Flow Streaming Receiver Cluster Receiver 2 Receiver 3 Receiver 1 Receiver 4
12 .Real-time OLAP Query Flow – Low Latency In three a spects : Fast data ingestion by LSM tree like storage; Local states (memory or disk) in streaming receiver are all query-able; Accelerate query on local states as much as possible; Streaming Receiver Local State in Memory Local State on Disk Unbounded Streaming Events Remote Storage 1 2 3
13 .Real-time OLAP Query Flow – Low Latency Streaming Receiver Local State in Memory Local State on Disk Query Engine Streaming Coordinator SQL Query SQL Response 1 3 2 Fast data ingestion by three-level LSM tree Local states (memory or disk) in streaming receiver are all query-able; Accelerate query on local states as much as possible; Off Heap 3 In-Memory ConcurrentSkipList Local Disk Columnar Storage Inverted Index Off Heap Multi-thread Compression 3 HBase/ Parquet
14 .Low Latency - Columnar Storage File Format
15 .Low Latency - Inverted Index Format Using Roaring Bitmap as inverted index Two storage layout for 1) dictionary encoded values and 2) fixed-length encoded values
16 .Low Latency - Compression Run Length Encoding Time-related dimension First dimension LZ4 Compression Other dimensions by default Simple typed measures(long , double) No compression Complex measures (count distinct, top-n , etc.)
17 .High Availability Replica Set Re ceiver 1 Re ceiver2 Zookeeper Concept of “Replica Set” All receivers in the replica set share the same assignment. The lead in the Replica Set is responsible to upload local state to the remote storage Use Zookeeper to do leader election Remote Storage Leader
18 .Performance Streaming receiver with specification( RAM: 86GB, VCPUs: 16 VCPU, 2095 MHZ ) Query scan performance: 45M rows/s Query throughput: 110 QPS Detail Performance Doc: https://drive.google.com/file/d/1GSBMpRuVQRmr8Ev2BWvssfMd-Rck9vsH/view?ths=true
19 .Kylin Real-time OLAP In eBay Streaming receivers cluster: 20 instances Site Speed, 400 events/s, 16 dim, 50 metrics
20 .Next Step Star Schema Support On Kubernetes/Yarn Enhance Monitoring/Alerting for Streaming Receiver Parquet storage integration
21 .Key Takeaway Real-time OLAP is ready in Apache Kylin 3.0 Milliseconds data preparation (cubing) Automatic state change Less overhead HA for every component Download and try Kylin from https://kylin.apache.org Thank you !