展开查看详情
1 .基于⼤数据分布式存储系统
Alluxio的负载均衡优化
余英豪
⾹港科技⼤学博⼠研究⽣
阿⾥巴巴 Research Intern
Alluxio 官⽅中⽂公众号
�
2 .存储与计算分离
Ø 弹性部署
Ø 细粒度容量伸缩
Ø 快速扩容
2
�
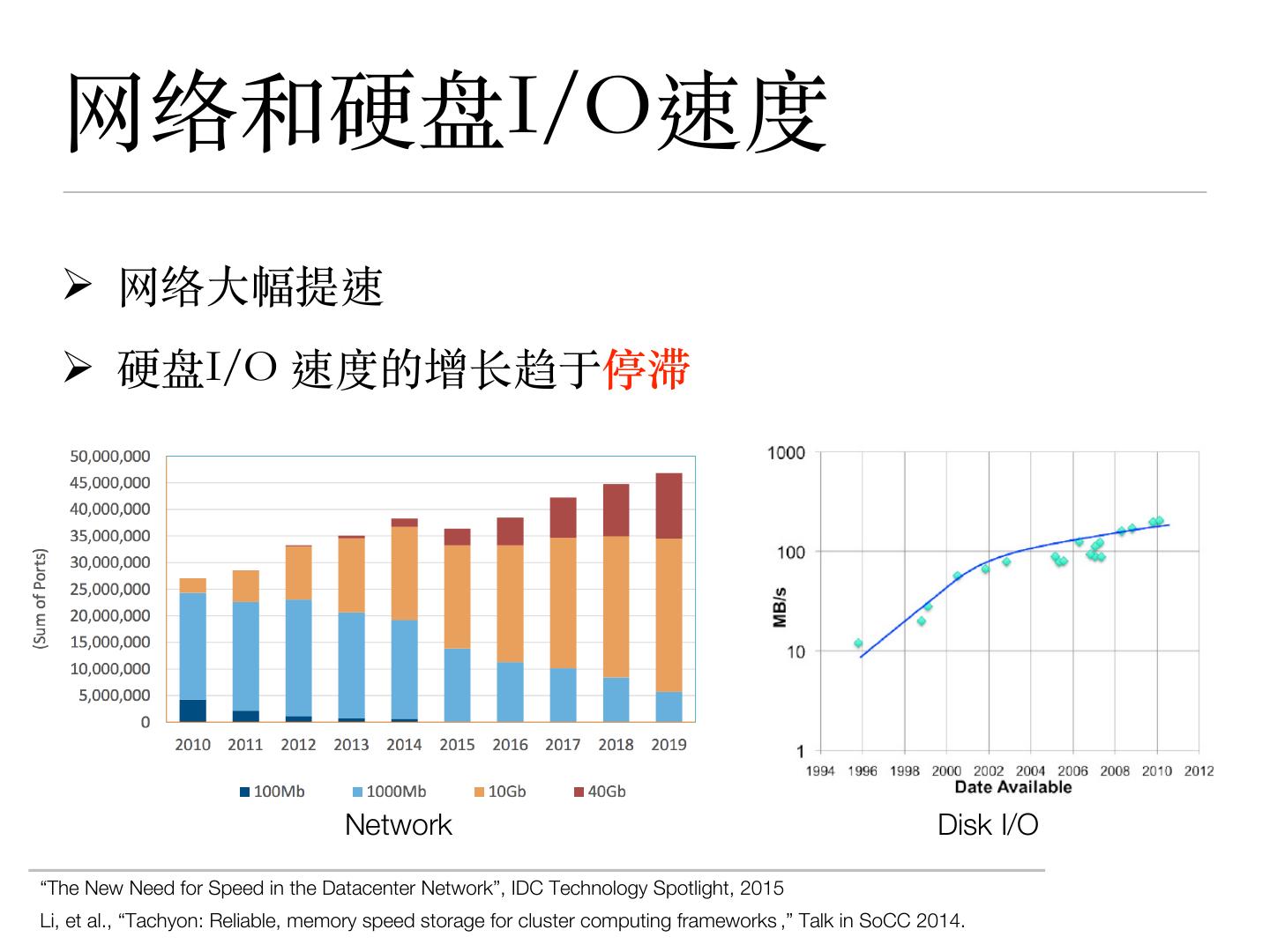
3 . ⽹络和硬盘I/O速度
Ø ⽹络⼤幅提速
Ø 硬盘I/O 速度的增长趋于停滞
Network Disk I/O
“The New Need for Speed in the Datacenter Network”, IDC Technology Spotlight, 2015
Li, et al., “Tachyon: Reliable, memory speed storage for cluster computing frameworks ,” Talk in SoCC 2014.
�
4 . 云对象存储
Ø 硬盘本地性不再重要 [AMPLab, 2011],得益于⾼速⽹络
Ø 硬盘I/O 仍然是瓶颈
Big data apps Spark TensorFlow Hadoop
Cluster storage
HDFS, Azure Storage, S3
“Disk-Locality in Datacenter Computing Considered Irrelevant”, AMPLab, 2011
4
�
5 .Data Ecosystem 1.0
Ø 多种计算平台、多种云存储
Ø 数据管理复杂度⾼、性能差、运维成本⾼
5
�
6 .Alluxio: 统⼀化分布式内存⽂件系统
Data Ecosystem 2.0
Java File API HDFS Interface FUSE Interface S3 Interface REST API
Alluxio: a Virtual Distributed File System (VDFS)
HDFS Driver S3 Driver Swift Driver NFS Driver
6
�
7 .Alluxio: 技术创新
Unified API Intelligent
Namespace Translation Cache
Bring all files into Interact with data Accelerate slow
a single interface using any API data transparently
7
�
8 .Alluxio: 100+ Known Production Deployments
Ø 中⽂公众号:更多案例分享和开源
社区动态
8
�
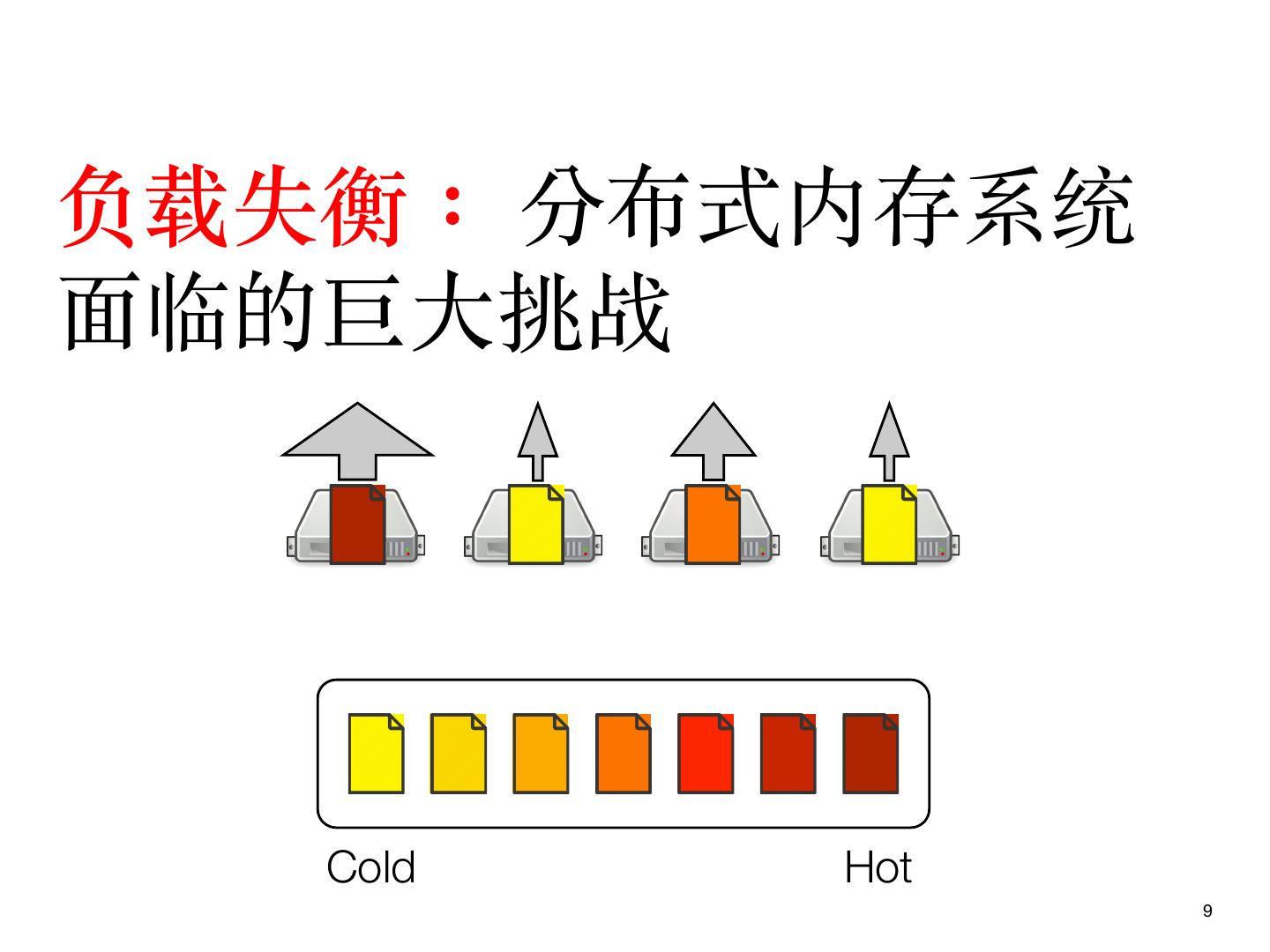
9 .负载失衡: 分布式内存系统
⾯临的巨⼤挑战
Cold Hot
9
�
10 .热度差异
Trace study in a Yahoo! cluster
少数⽂件被⾼频率访问 (Zipf-like 分布)
热点⽂件往往是⼤⽂件
10
�
11 .负载失衡抵消了内存优势!
AWS EC2上⼀个30节点的Alluxio 集群
⽂件热度服从Zipf分布
Benefits of caching diminishes!
11
�
12 .现有的负载均衡算法
Selective replication
[选择性复制]
Scarlett [Eurosys’11]
[Hong et al. SoCC’13]
State-of-the-art
Erasure coding
[纠删码]
EC-Cache [OSDI’16]
12
�
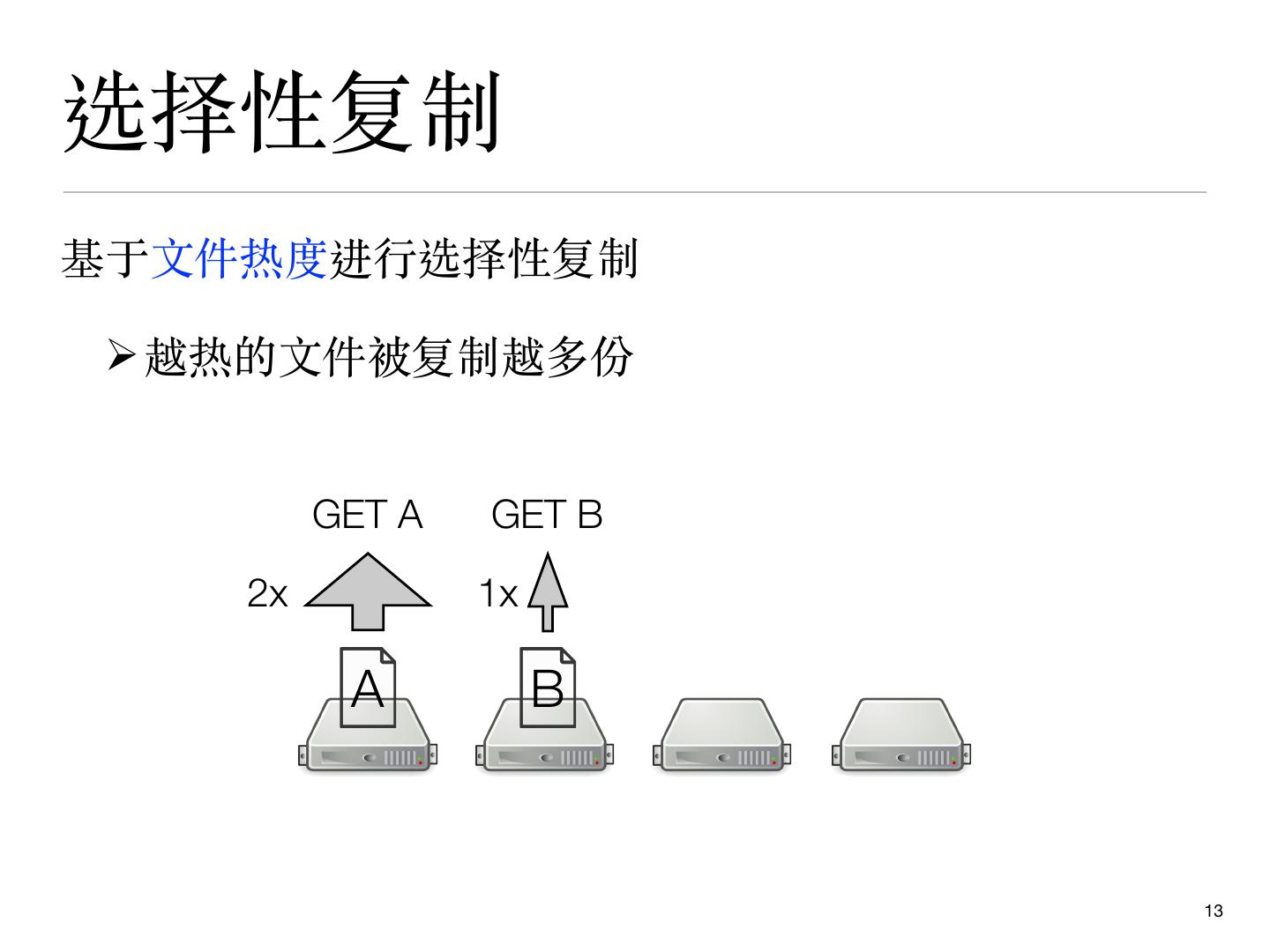
13 .选择性复制
基于⽂件热度进⾏选择性复制
Ø越热的⽂件被复制越多份
GET A GET B
2x 1x
A B
13
�
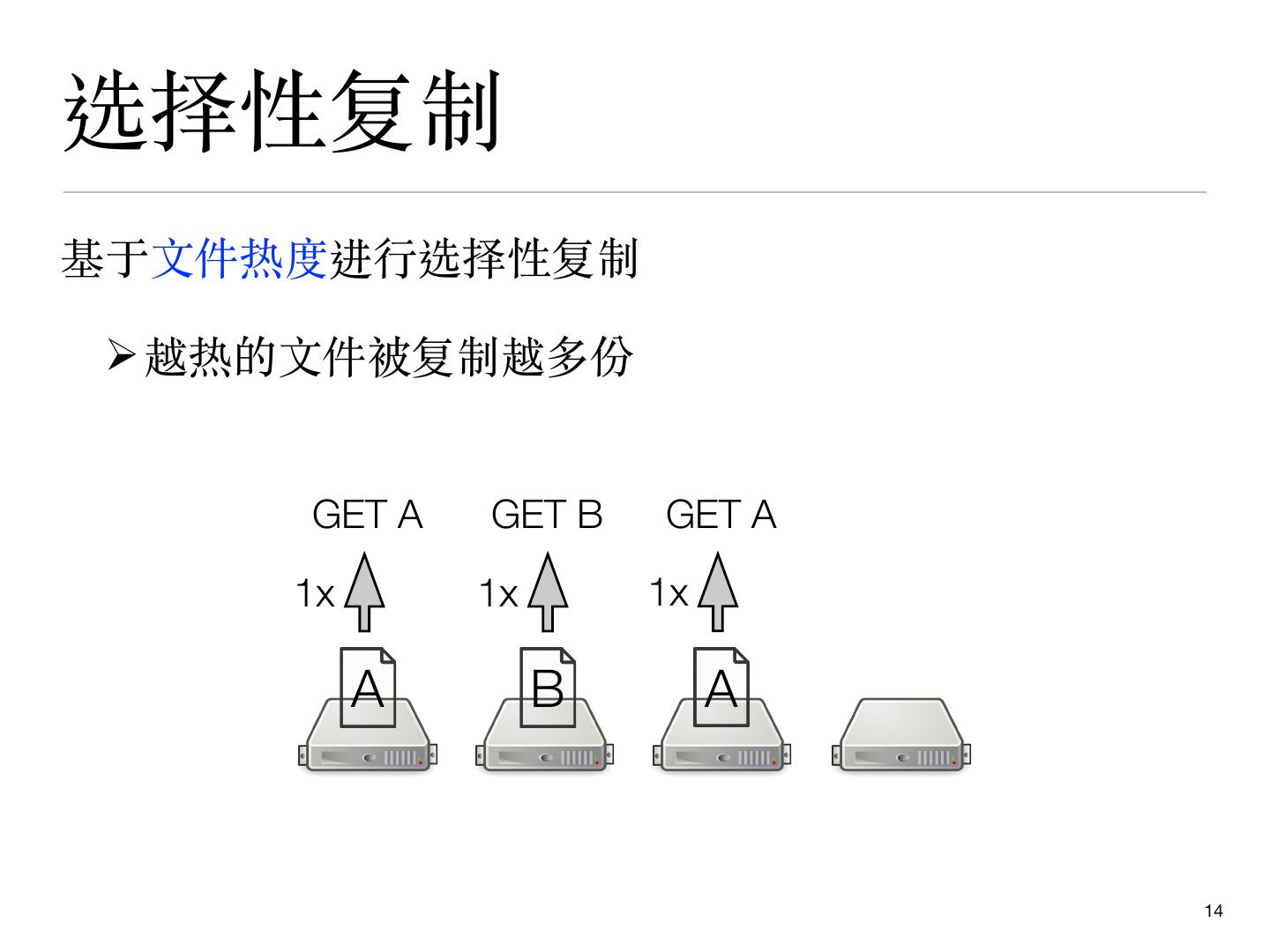
14 .选择性复制
基于⽂件热度进⾏选择性复制
Ø越热的⽂件被复制越多份
GET A GET B GET A
1x 1x 1x
A B A
14
�
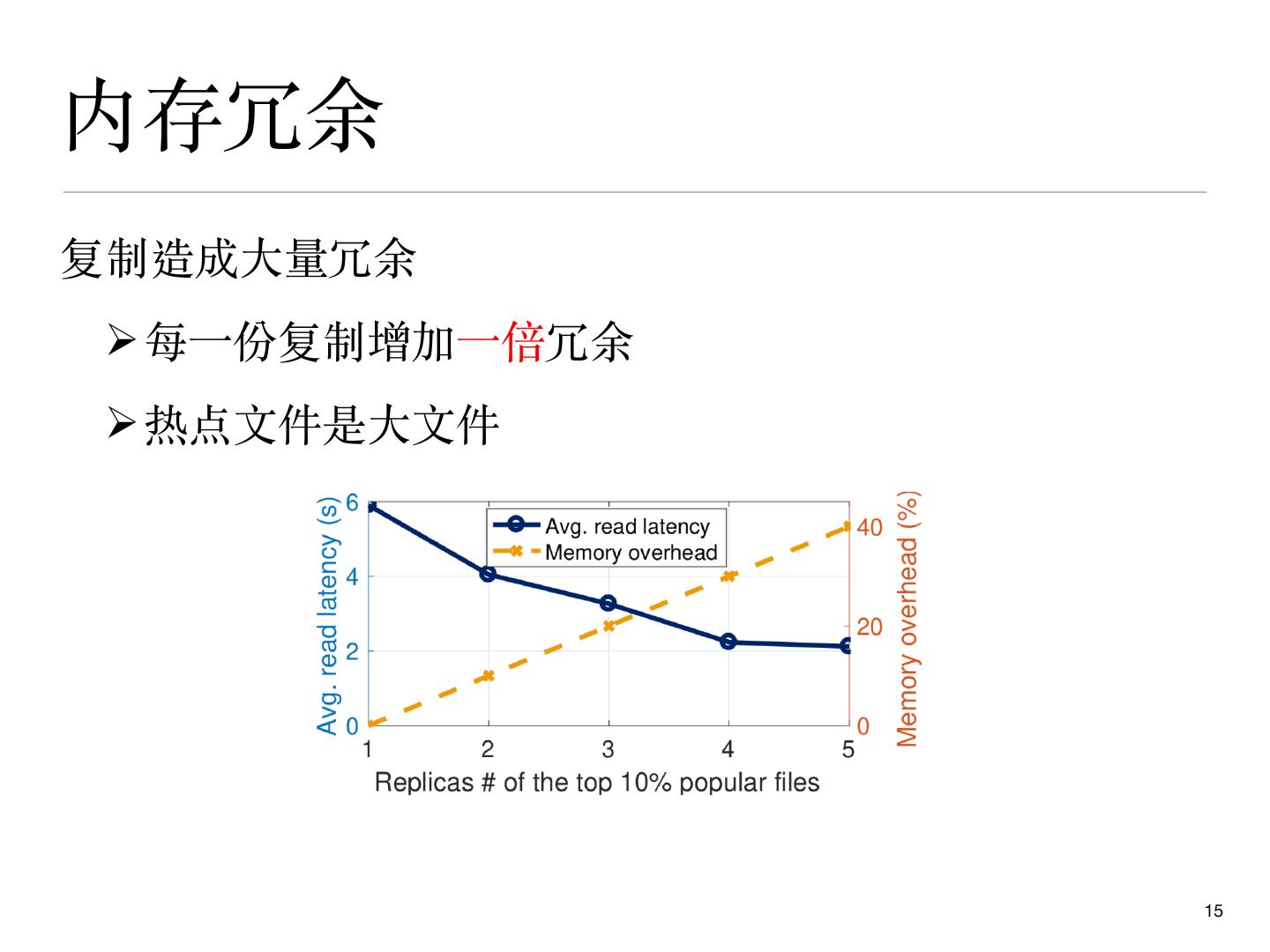
15 .内存冗余
复制造成⼤量冗余
Ø每⼀份复制增加⼀倍冗余
Ø热点⽂件是⼤⽂件
15
�
16 .纠删码
(k, n) 纠删码: 先将⽂件分为 k 个⼩块(信息块),基于此
编码⽣成另外 n-k 个校验块
任意 k 个⼩块可以解码出原⽂件
Ø更⼩的冗余度:(n-k)/k <1
16
�
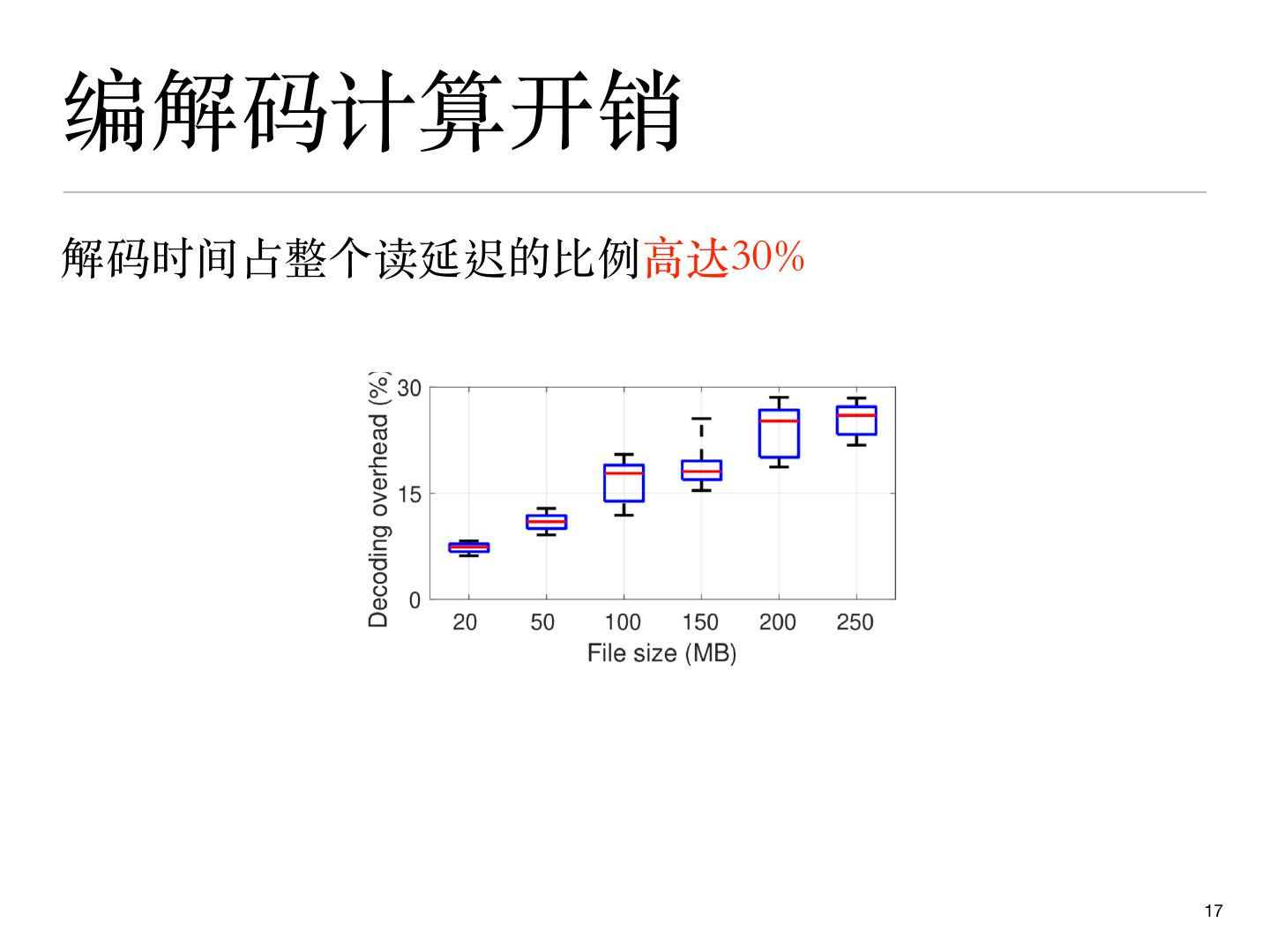
17 .编解码计算开销
解码时间占整个读延迟的比例⾼达30%
17
�
19 .⽂件分割
将⽂件分割为多个⼩块,随机分散在内存系统中
400 Mbps 50 Mbps
A B
19
�
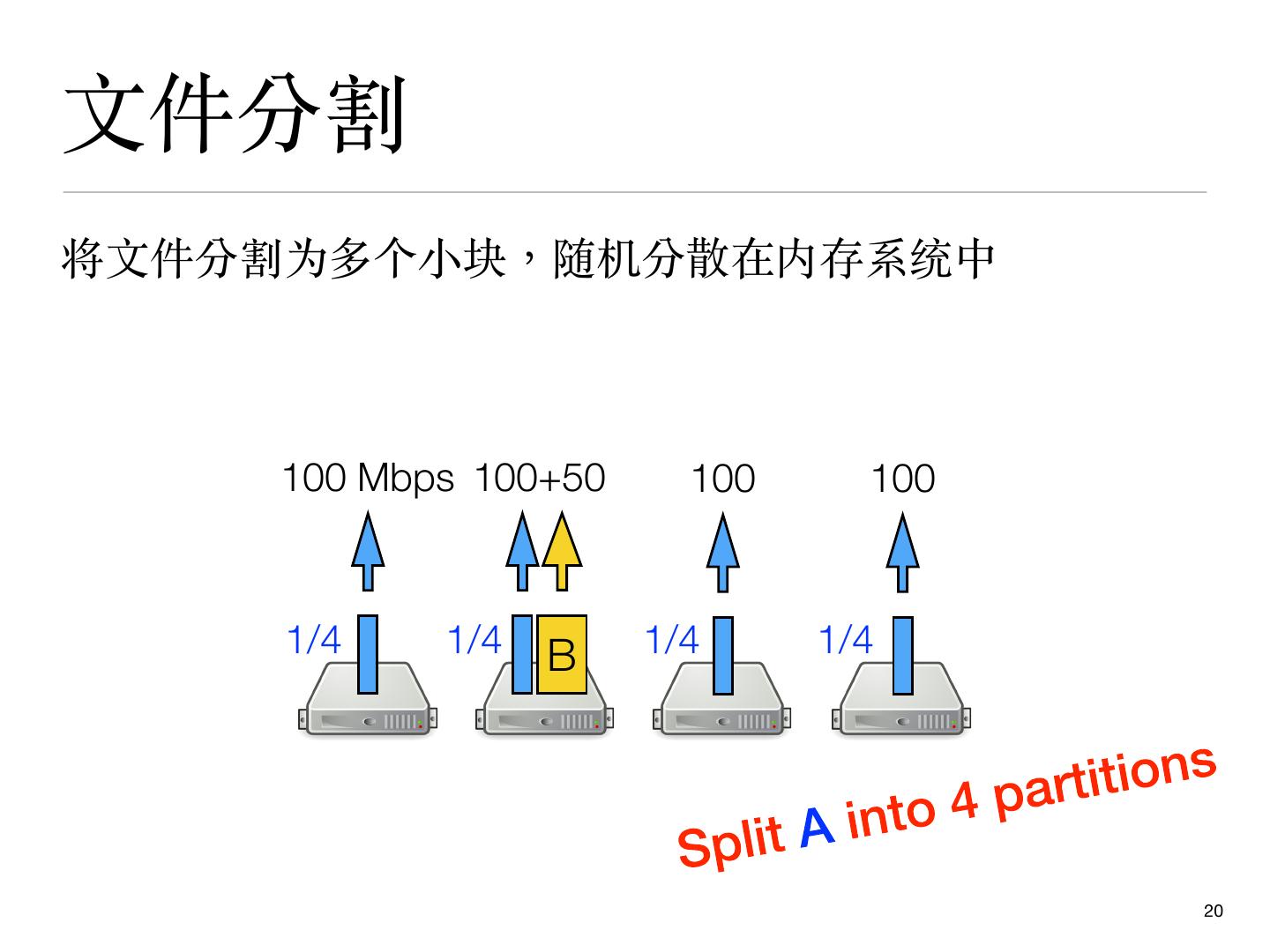
20 .⽂件分割
将⽂件分割为多个⼩块,随机分散在内存系统中
100 Mbps 100+50 100 100
1/4 1/4 B 1/4 1/4
20
�
21 .⽂件分割的好处
ü 将热点⽂件的负载分散在多台机器上
ü 零冗余
ü 无需编解码计算
ü 并⾏I/O减少读延迟
21
�
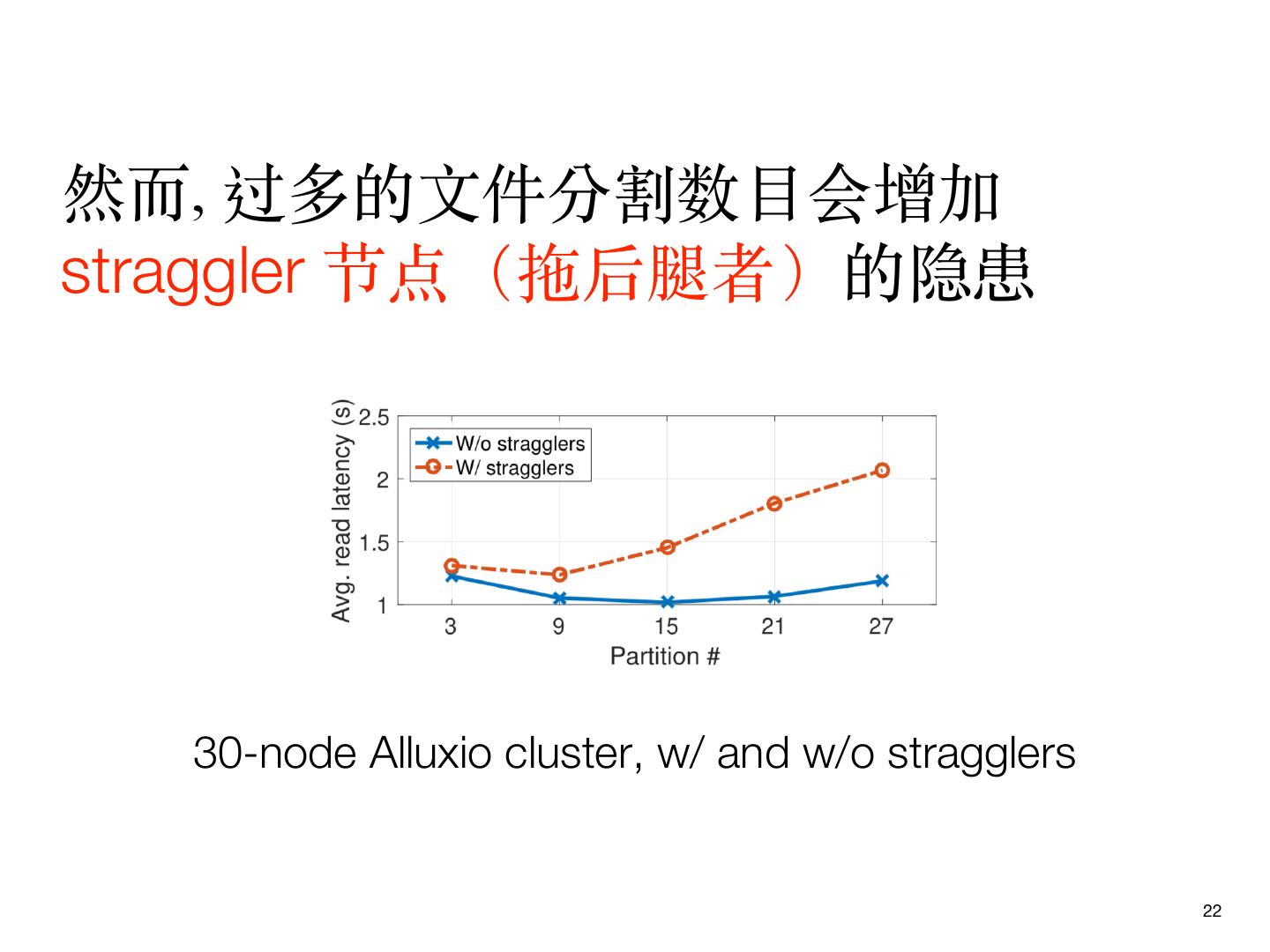
22 .然⽽, 过多的⽂件分割数⽬会增加
straggler 节点(拖后腿者)的隐患
30-node Alluxio cluster, w/ and w/o stragglers
22
�
23 .如何决定⽂件的分割数⽬︖
Ø太少了不⾜以均衡负载
Ø太多了受straggler的影响
23
�
24 .选择性分割
SP-Cache: Selective Partition
popularity
# partitions
size
scale factor
load
24
�
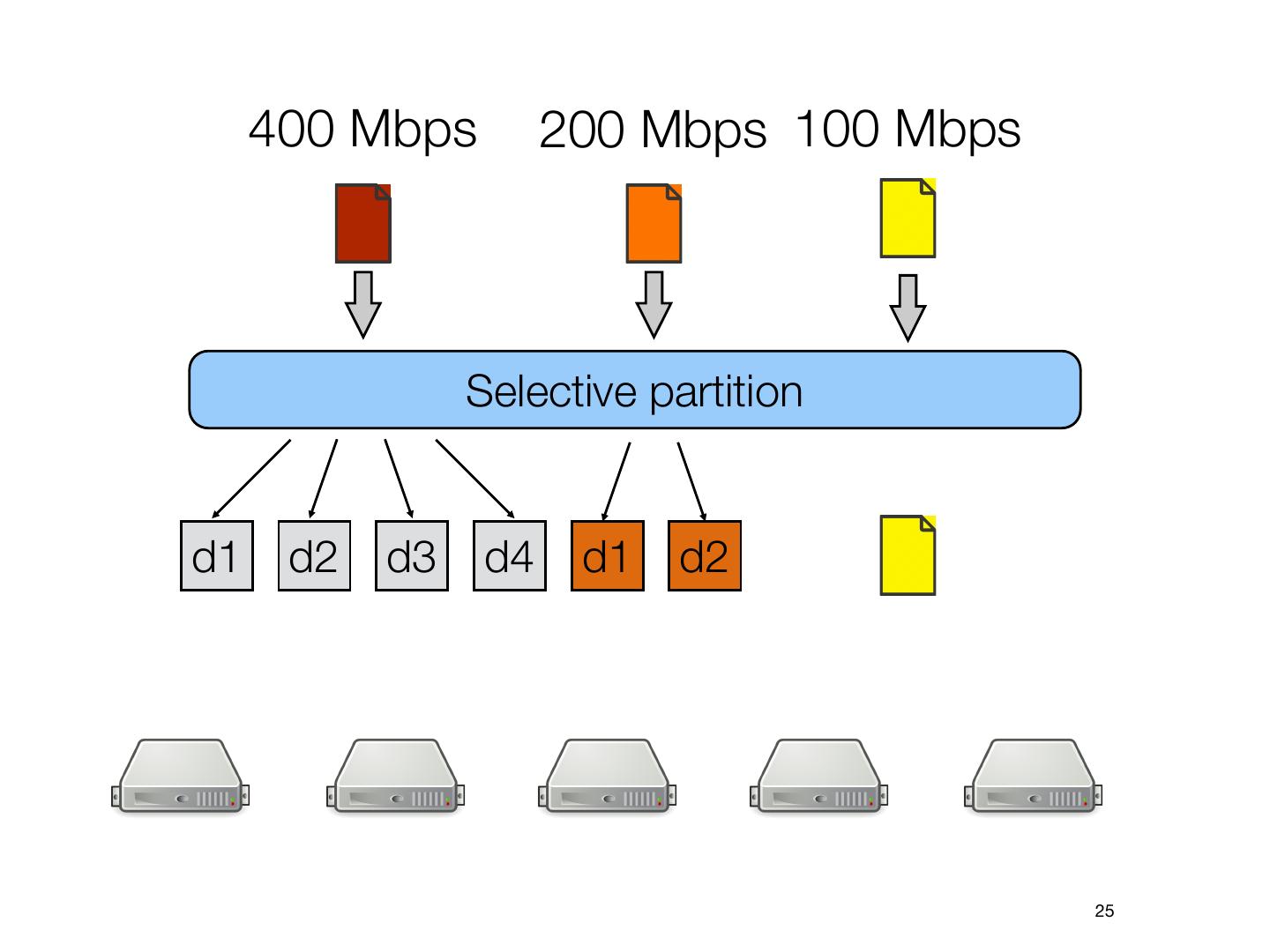
25 . 400 Mbps 200 Mbps 100 Mbps
Selective partition
d1 d2 d3 d4 d1 d2
25
�
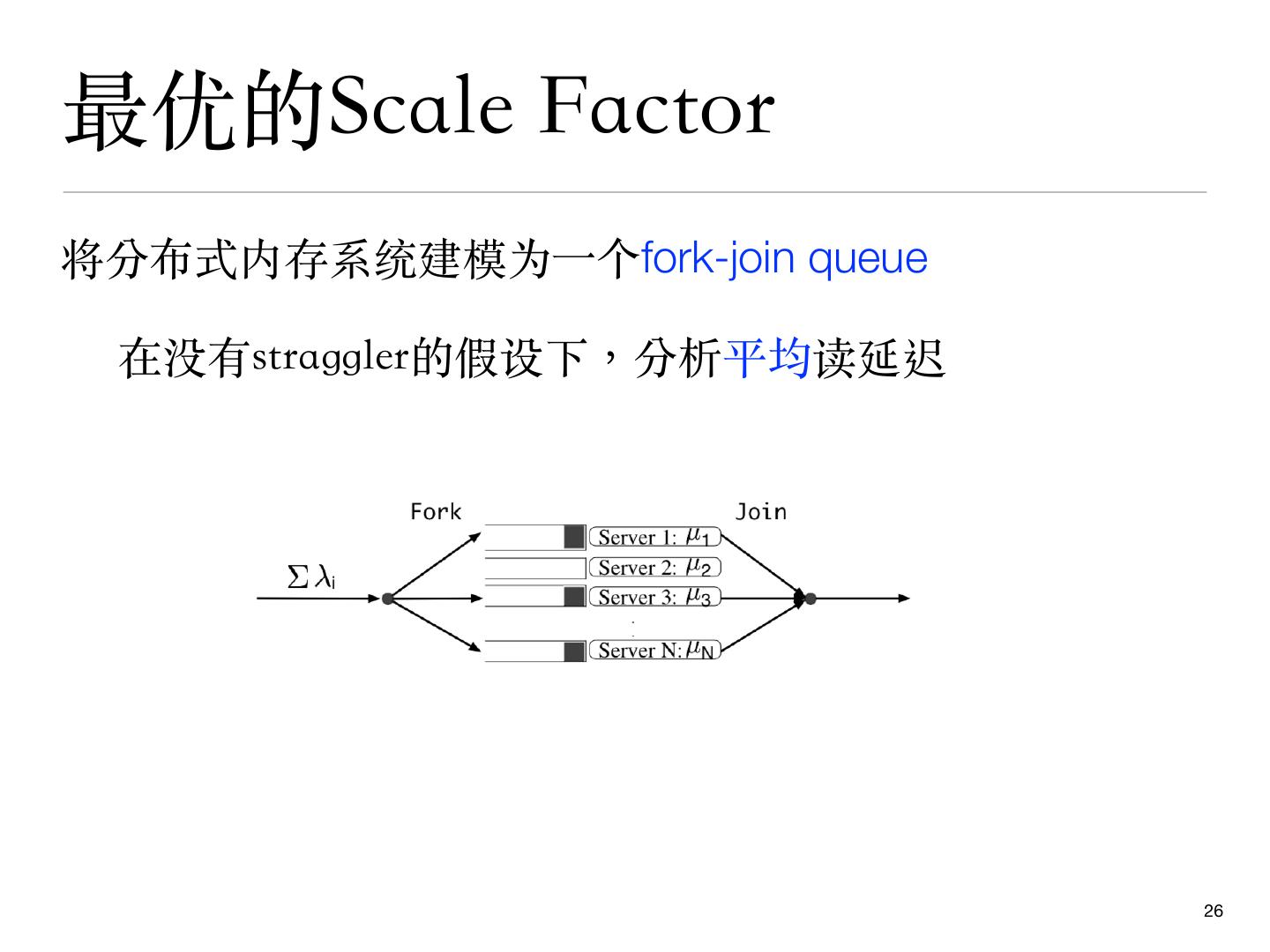
26 .最优的Scale Factor
将分布式内存系统建模为⼀个fork-join queue
在没有straggler的假设下,分析平均读延迟
26
�
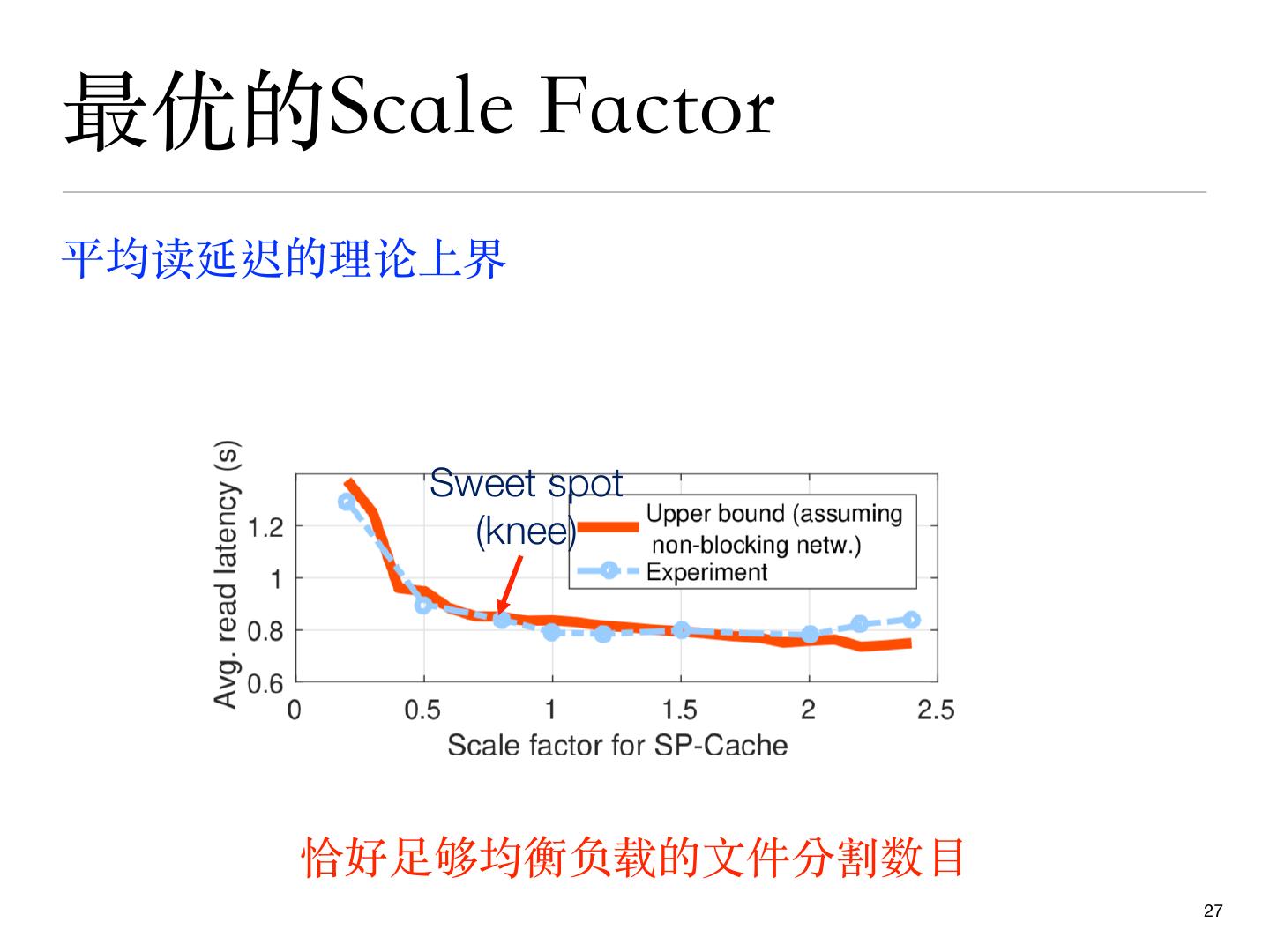
27 .最优的Scale Factor
平均读延迟的理论上界
Sweet spot
(knee)
恰好⾜够均衡负载的⽂件分割数⽬
27
�
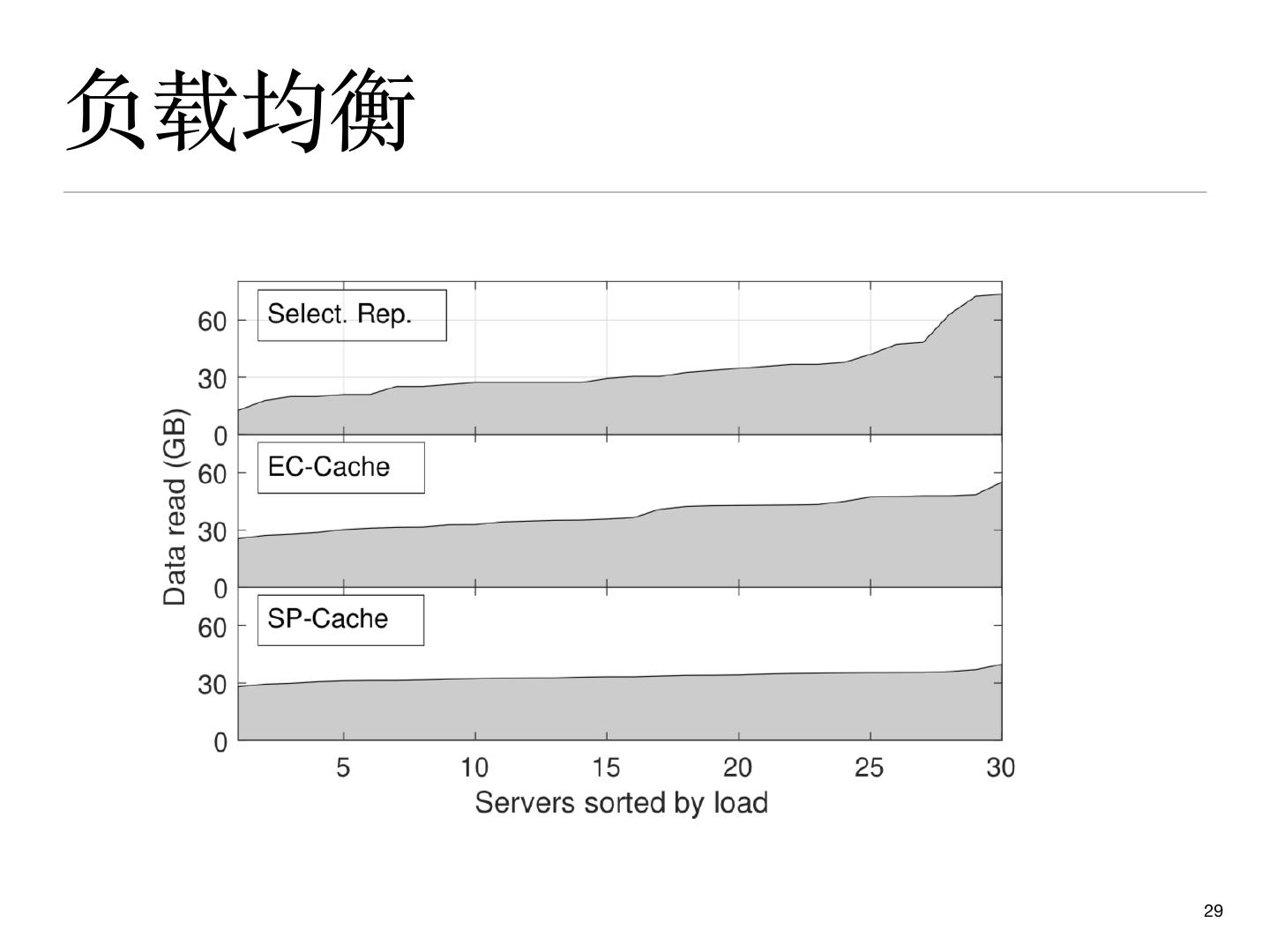
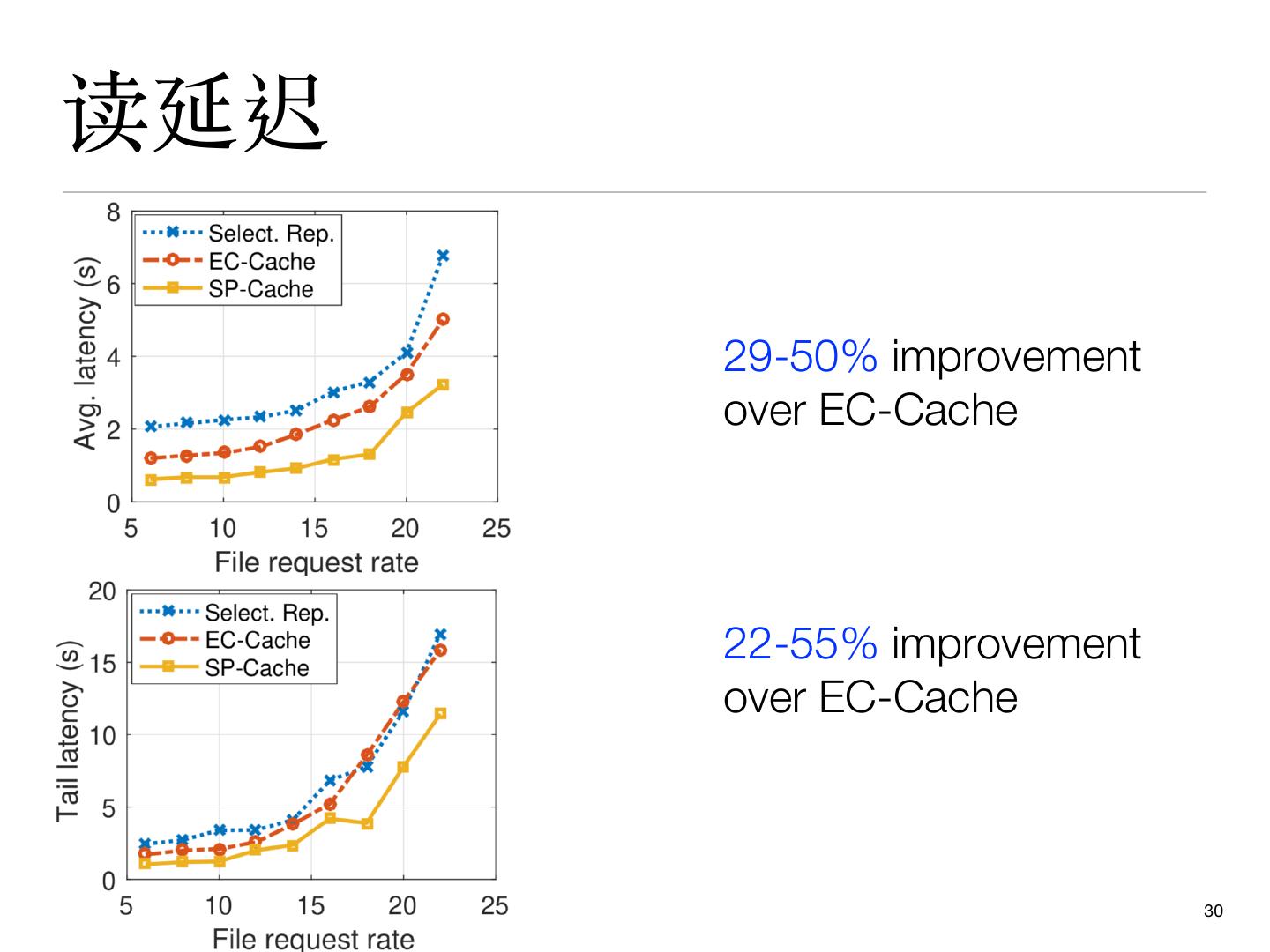
28 .性能评价
51个 r3.2xlarge 节点: 1 master, 30 servers 和 20 clients
⽂件热度服从Zipf分布
两个的现有策略
Ø EC-Cache: (10, 14) 纠删码 [Rashmi et al. OSDI’16]
Ø Selective replication: 将top 10% 的热点⽂件各复制四份
28
�