展开查看详情
1 .Apache HBase 2.x 架构演进
与社区最新进展
张铎
�
2 .关于HBase
Apache HBase™ is the Hadoop database, a
distributed, scalable, big data store.
https://hbase.apache.org/
�
3 .关于HBase
● Google Bigtable的开源实现
● 在HDFS之上构建
○ 数据文件也可以保存于对象存储,例如S3/OSS
○ WAL目前仍然必须依赖HDFS
● Wide column store
○ 单行百万列
○ 动态
○ 稀疏
● 支持万亿级别存储
○ 小米云服务已验证可行
�
5 .项目状态
● ...17,019 commits made by 440 contributors
● ...representing 868,768 lines of code
● ...mostly written in Java
● ...has a well established, mature codebase
● ...maintained by a very large development team
● ...with stable Y-O-Y commits
● ...took an estimated 242 years of effort (COCOMO model)
● ...starting with its first commit in April, 2007 (>10 years old!)
Source https://www.openhub.net/p/hbase
�
7 .兼容性
● Semantic Versioning
○ 从HBase-1.0.0开始使用
○ MAJOR.MINOR.PATCH[-IDENTIFIER]
○ 例如:2.0.0-alpha1
�
8 .兼容性
● 但是...
○ Semantic Versioning只规定了API
○ Spark/MapReduce使用的接口?
○ Coprocessor?
● 需要更细粒度的兼容性控制
�
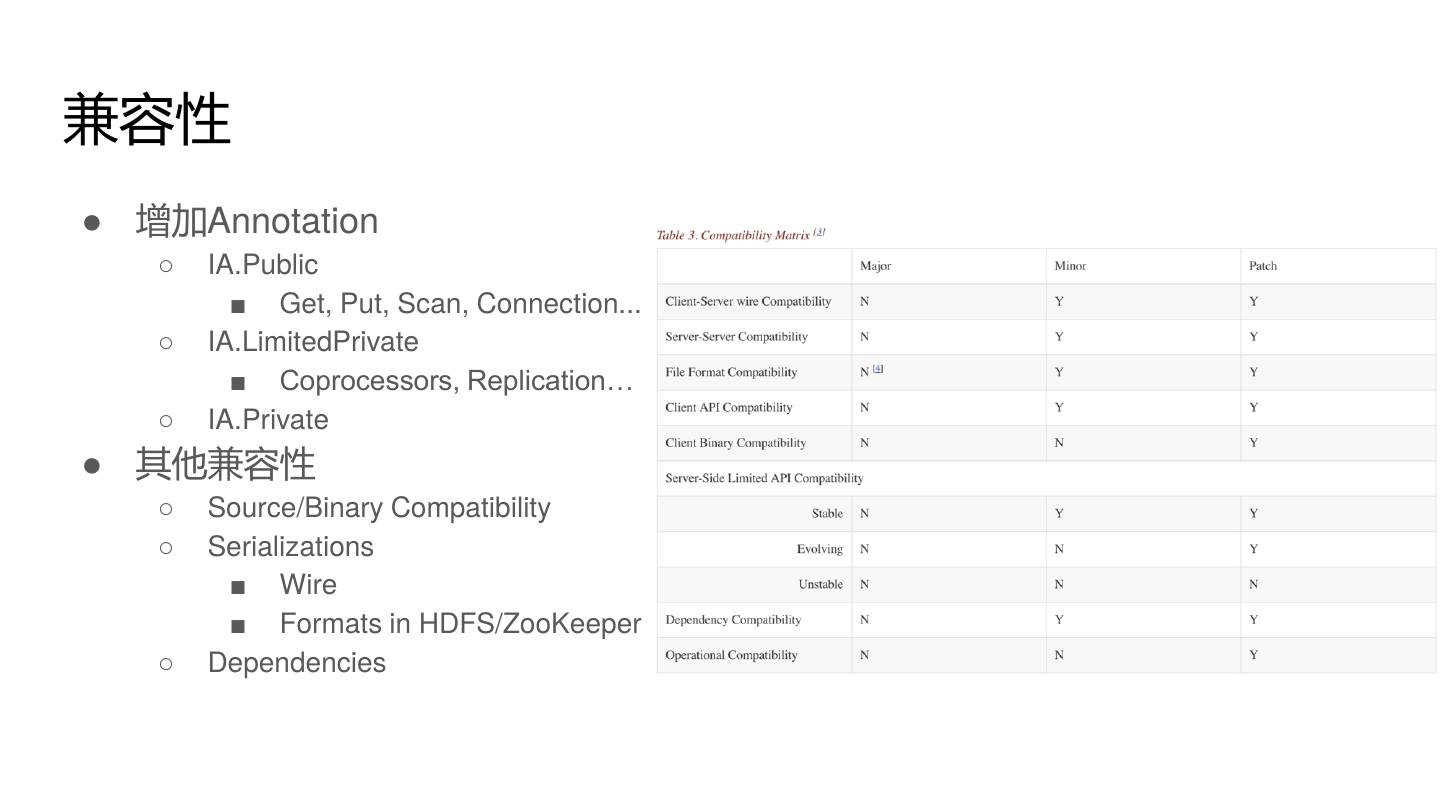
9 .兼容性
● 增加Annotation
○ IA.Public
■ Get, Put, Scan, Connection...
○ IA.LimitedPrivate
■ Coprocessors, Replication…
○ IA.Private
● 其他兼容性
○ Source/Binary Compatibility
○ Serializations
■ Wire
■ Formats in HDFS/ZooKeeper
○ Dependencies
�
10 .兼容性
● HBase-1.x客户端可以和HBase-2.x服务端交互
○ 不包括Admin操作,例如DDL操作
○ 支持Replication 1 ⇔ 2
● 不轻易使用IA.Public
● 在Public的接口中去除对Guava/Protobuf的依赖
● hbase-thirdparty
○ shaded/relocate部分容易产生冲突的依赖
● 滚动升级
○ 理论上支持
○ 需要特殊的操作方式
○ 禁止split/merge
�
11 .Assignment Manager
● Version1?
○ 状态散落在ZooKeeper/HDFS/hbase:meta中,非常容易不一致
○ HBase运维:又有Region无法online啦!
● Version2!
○ 基于Procedure V2框架
○ 状态机
○ Assignment/Split/Merge全部经过Master
○ 由Master将最终状态发布到hbase:meta/ZooKeeper
● 理论上可以比Version1更稳定
�
12 .现实?
● 重构一直持续到了HBase-2.2.x
○ 代码复杂度明显变高
● 确实更加稳定
● 完全可靠?
○ 代码总会有bug
● 修复问题更加繁琐
○ 代码复杂度高
○ HBCK2 vs. HBCK1
● Procedure V2的稳定性很重要
● 总体符合预期
�
13 .基于Procedure V2的更多操作
● 性能更好
○ 直接向RegionServer发送请求
● 状态机模型
● 降低对ZooKeeper的依赖
○ 仅用作外部存储
○ 很容易切换为ETCD,或者其他系统
○ 云端部署更简单
● 已改造的系统
○ Replication
○ Split WAL
○ ...
�
14 .串行复制
● 为什么会乱序
○ 每个regionserver负责推送自己的WAL
○ region会在regionserver之间挪动
● 问题?
○ 可能导致主备集群数据不一致
○ major compaction
● 解决
○ 记录region每次移动时的sequence id,划分出WAL的区间
○ 只有上一个区间完成了复制,当前区间才能开始推送
● 难点
○ split/merge
○ region移动时,sequence id必须连续不能跳跃
�
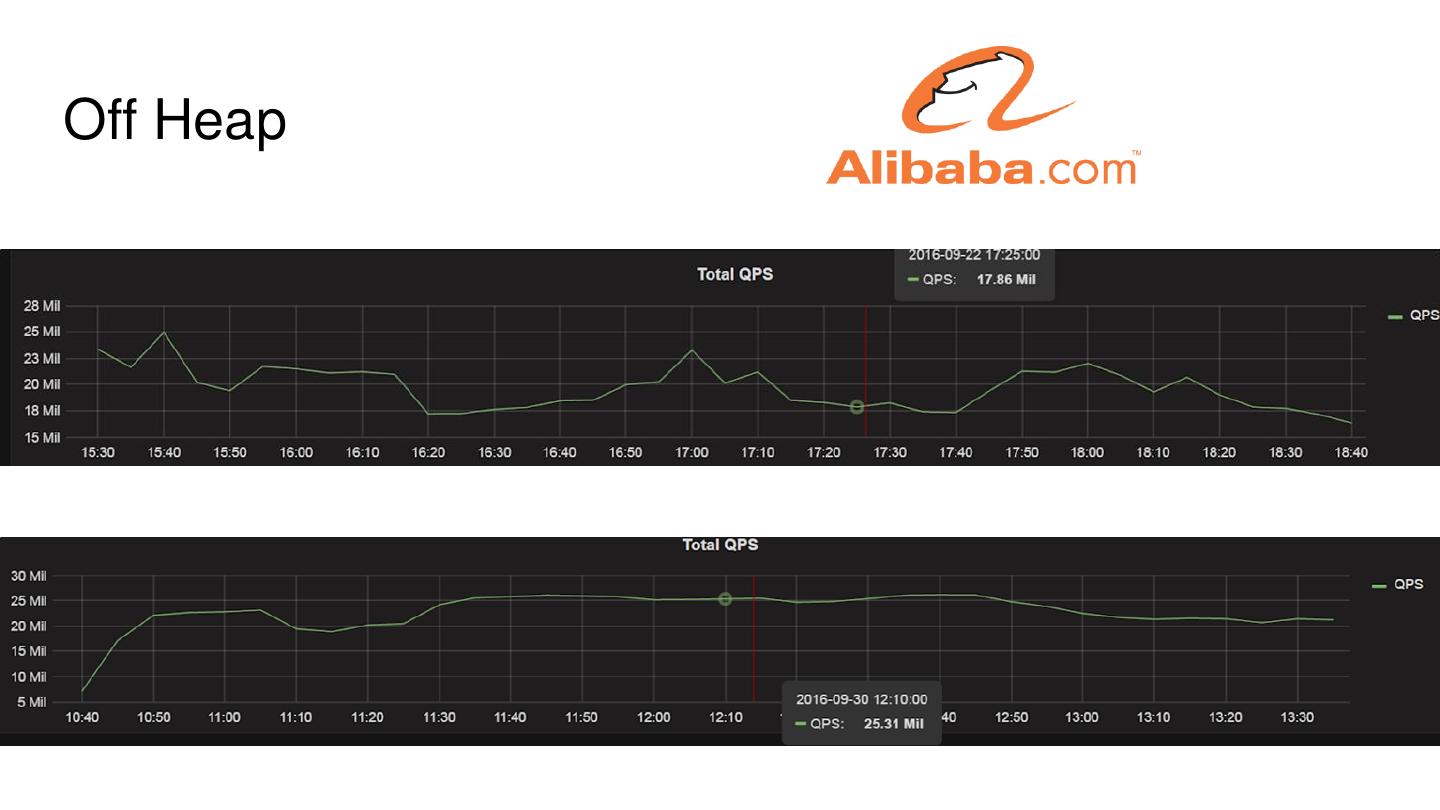
15 .Off Heap
● 更小的堆,减少GC时间
● 读路径
○ HDFS => BucketCache => RPC
○ 延迟
■ 缓存更多数据
■ GC更少,减少毛刺
● 写路径
○ RPC => HDFS
○ Async DFS WAL Client
● 问题
○ 需要复杂的引用计数
○ 内存泄漏
�
17 .Accordion
● In memory compaction
○ 在内存中将CSLM转换成只读的’Segments’
○ ‘Segments’也可以进行合并
○ 合并时可以清除不需要的版本,减小内存占用
● 提升性能
○ 减少对象,减轻GC压力
○ 减少flush次数,降低写放大
○ Off Heap
● WAL truncating?
○ 有时还是不得不flush
�
18 .异步化改造
● 异步的DFS Client
○ 仅用于写WAL
○ Fan out,fail-fast
● 异步的客户端
○ 官方实现,不是asynchbase
○ API基于Java8的CompletableFuture
○ 实现很完整,也支持Admin操作
�
19 .Medium Object Blobs(MOB)
● 大小在100KB ~ 10MB
○ 文档?
○ 图片?
● 并不能替代对象存储
○ 大对象仍然会写WAL,以及进入Memstore
○ 只能降低compaction压力
● 适用场景
○ 大部分小记录 + 偶尔的大对象
�
20 .云端部署
● 支持将HFile存储在对象存储上
○ HBase on Amazon S3
● HBoss
○ HBase Object Store Semantics
○ 方便接入更多对象存储
�
22 .同步复制
● 双集群强同步
● WAL同步写入到两个集群
● 主集群负责读写,备集群不接受外部请求
● 出现故障时进入降级状态,WAL变为只写入一个集群
○ 备集群故障,主集群直接断开
○ 主集群故障,备集群提升为主前,需要replay所有主集群写过来的WAL
● 需要异步复制配合,在备集群删除已经复制过的WAL
● 阿里在内部版本实现并介绍了大致思路,小米在开源版本中实现
�
23 .内部优化
● hbase:namespace合并入hbase:meta
○ 只保留一个必须的系统表
○ 简化bootstraping流程
● 更多的基于Procedure V2框架的操作
○ ACL
○ …
● 使用异步客户端重新实现同步客户端
○ 极大减少客户端代码量
○ 一个feature不需要加两次
�
24 .更多?
● SQL支持
○ Phoenix?Spark SQL?
○ 内建基本SQL支持?
● 二级索引
○ 局部/全局
○ 事务支持
● 可split的meta
○ 扩展性
○ 单集群超百万region
● 面向云端部署
○ 更好的对象存储支持
○ 去除WAL对HDFS的强依赖
�
26 .The Apache Way
● Independence
○ Only PMC of the project can control the direction of the project
○ Diversity
● Community Over Code
○ A healthy community is a higher priority than good code
○ 好社区烂代码 => 代码可以重写变好
○ 坏社区 => 项目死亡
�
27 .HBase 社区
● 86 Committers
○ 中国大陆有17位
● 51 PMC成员
○ 中国大陆有6位
● 来自中国的贡献越来越多
○ 活跃的贡献者中中国人很多
● 开放
○ 对中国人也很开放和友好
○ 主席是中国人
�