展开查看详情
1 .HDFS optimization for Hbase
At XiaoMi
�
4 .l Multiple replicas
l Namenode & Datanode
r
writeSLAAvailability =1 − ∑ C (i, k ) × C (r − i, N − k ) / C (N, r )
i= 1
readdSLAAvailability =1 − k / N
availability =Min(namenodeAvailability ,writeSLA,readSLA )
r=replication, factor k=fault datanodes, N=total datanodes
�
5 . Cluster Configs
Master Namenode
DataNode
Worker Worker DataNode
MonitorCluster Metrics
HDFS
Falcon
�
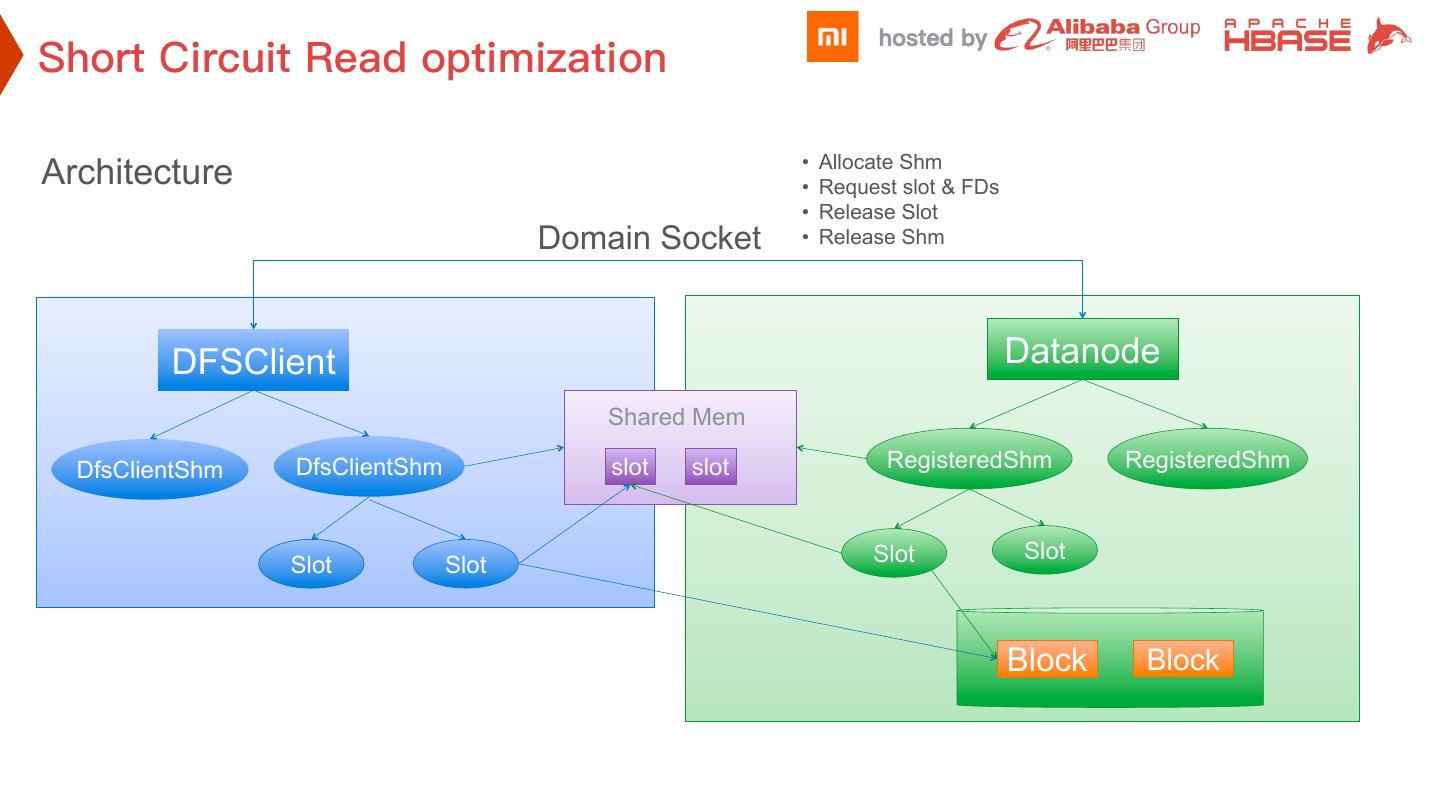
7 . • Allocate Shm
Architecture • Request slot & FDs
• Release Slot
Domain Socket • Release Shm
DFSClient Datanode
Shared Mem
DfsClientShm DfsClientShm slot slot RegisteredShm RegisteredShm
Slot Slot
Slot Slot
Block Block
�
8 .²
•
•
• Datanode Full GC caused by RegisteredShm
• 3000+ QPS alloction VS 1000+ QPS release
�
10 .²
YCSB get 20% QPS incensement
�
11 .²
Preallocate the Shm:
• 1000 files
• 60 threads
• seek read
�
13 .² Listen drop on SSD cluster causes 3s delay
15:56:14.506610 IP x.x.x.x.62393 > y.y.y.y.29402: Flags [S], seq 167786998, win 14600, options [mss 1460,sackOK,TS val
1590620938 ecr 0,nop,wscale 7], length 0<<<--------timeout on first try
15:56:17.506172 IP x.x.x.x.62393 > y.y.y.y.29402: Flags [S], seq 167786998, win 14600, options [mss 1460,sackOK,TS val
1590623938 ecr 0,nop,wscale 7], length 0<<<--------retry
15:56:17.506211 IP y.y.y.y.29402 > x.x.x.x.62393: Flags [S.], seq 4109047318, ack 167786999, win 14480, options [mss
1460,sackOK,TS val 1589839920 ecr 1590623938,nop,wscale 7], length 0
² HDFS-9669
² After change backlog 128, 3s delays reduced to ~1/10 on Hbase SSD cluster
Somaxconn=128 Default Datanode backlog=50
�
14 .² Peer cache bucket adjustment
�
15 .² Connection/Socket timeout of the DFSClient & Datanode
dfs.client.socket-timeout
dfs.datanode.socket.write.timeout
l Reduce the timeout to 15s
l Avoid pipeline timeout, upgrade the DFSClient first
�
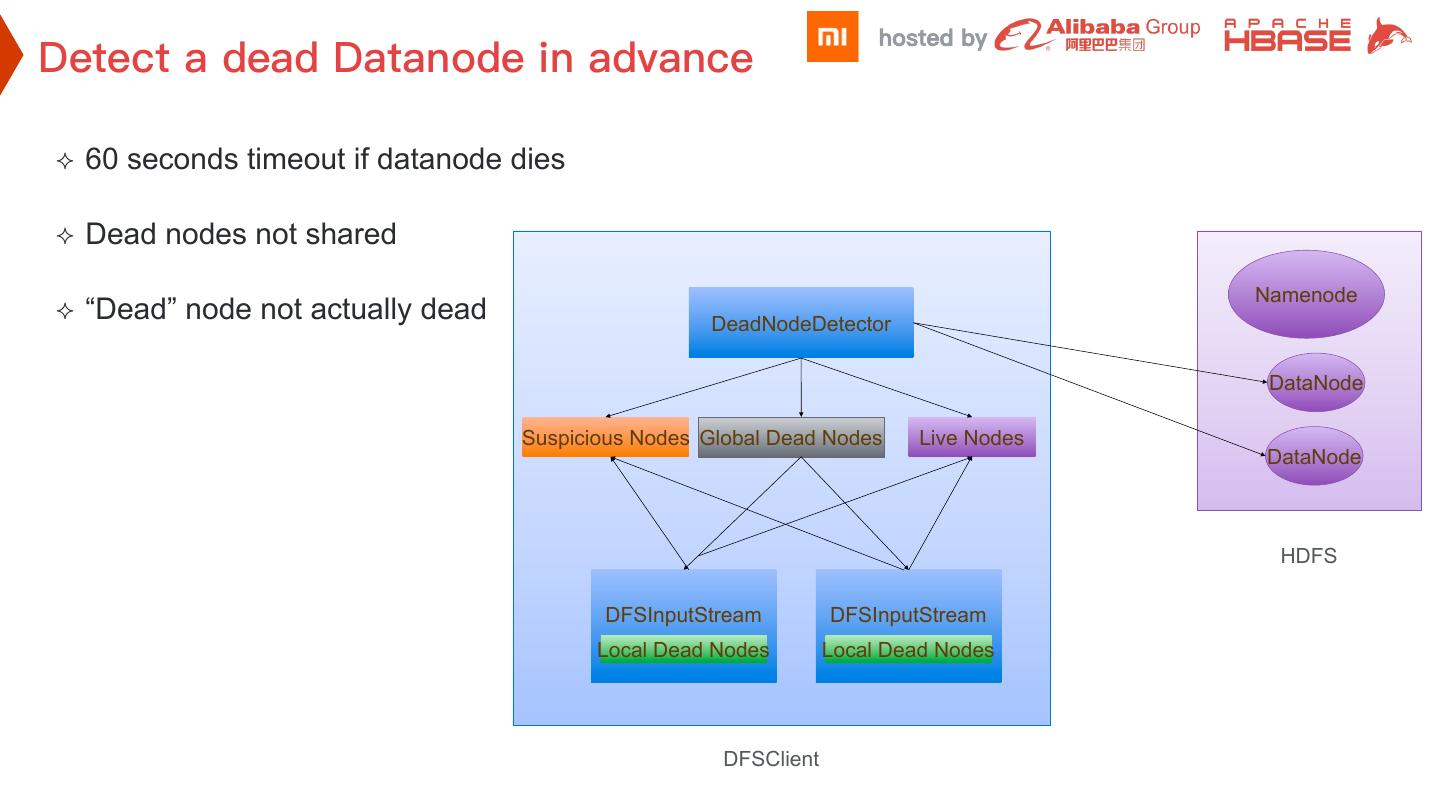
17 .² 60 seconds timeout if datanode dies
² Dead nodes not shared
Namenode
² “Dead” node not actually dead DeadNodeDetector
DataNode
Suspicious Nodes Global Dead Nodes Live Nodes
DataNode
HDFS
DFSInputStream DFSInputStream
Local Dead Nodes Local Dead Nodes
DFSClient
�
18 .² Node state machine
Init Open Live
RPC Failure
RPC Success
Close Dead
Read Failure Read Success
RPC Failure
Removed
Suspicious
�
19 .Subtitle Text
Maintain the data on local host as much as
possible and reduce the over head of the
local read
Make sure the response to Hbase is
returned as soon as possible even a failed
one
Minor GC from both Hbase and HDFS
affects the latency. Try to easy the one
from HDFS on client side.
�