展开查看详情
2 .Pharos as a Pluggable Secondary
Index Component
Lei Wang
China Everbright Bank Enterprise Architect
�
3 .Introduce
Lei Wang 王 磊
光大银行科技部领域架构师,曾任职于IBM全球咨询服务部从事技术咨询工作,具有十余年数据领域
研发及咨询经验。目前负责全行数据领域系统的日常架构设计、评审及内部研发等工作,对分布式数据库、
Hadoop等基础架构研究有浓厚兴趣。
�
4 .I Overall Introduction
II Architecture Design
III Future Development
�
5 . Part I
Overall Introduction
�
6 .Research Background
Existing Products or Solutions
1. Native Filter,Low performance
2. HBase +Solr(ES) , Complex architecture / Performance is not good enough / High maintenance cost
3. Phoenix,Heavy Solution / Community inactivity / Imperfect function
4. HBase On Cloud,Unable to use because of security requirements
Our requirements
1. Non-Invasive
2. High performance
3. Universal
4. Simple architecture
5. Support transaction consistency
�
7 .Pharos
1. Name
comes from English word ‘pharos’
2. Business Scenarios
• Read Only , T+1 Batch Load
• Read and Less Write ( Experimental )
3. Design Principle
Non-Invasive, Simple architecture
�
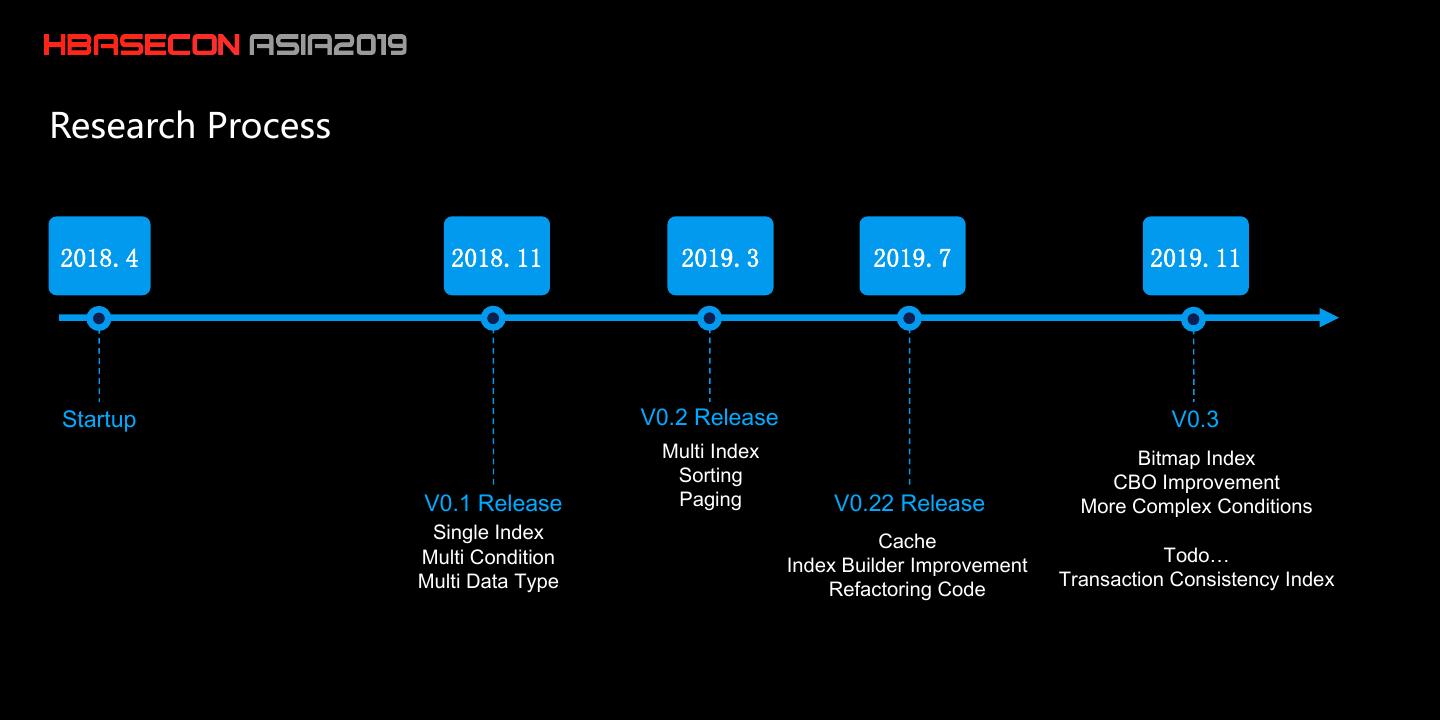
8 .Research Process
2018.4 2018.11 2019.3 2019.7 2019.11
Startup V0.2 Release V0.3
Multi Index Bitmap Index
Sorting CBO Improvement
V0.1 Release Paging V0.22 Release More Complex Conditions
Single Index Cache
Multi Condition Todo…
Index Builder Improvement
Multi Data Type Transaction Consistency Index
Refactoring Code
�
9 .Pharos V0.22 Features (on HBase 1.2.6 or CDH 5.8.3-HBase 1.2.0)
1. Single Index(single column、multi column),Multi Index.
2. Paging, Sorting.
3. Multi Condition Query,including equal, less (equal), greater (equal).
4. AND / OR logic operation.
5. Multiple Data Type, including Char, Date ,Double and so on.
6. Simple Function Compute, for example record count.
7. Batch Index Creation.
�
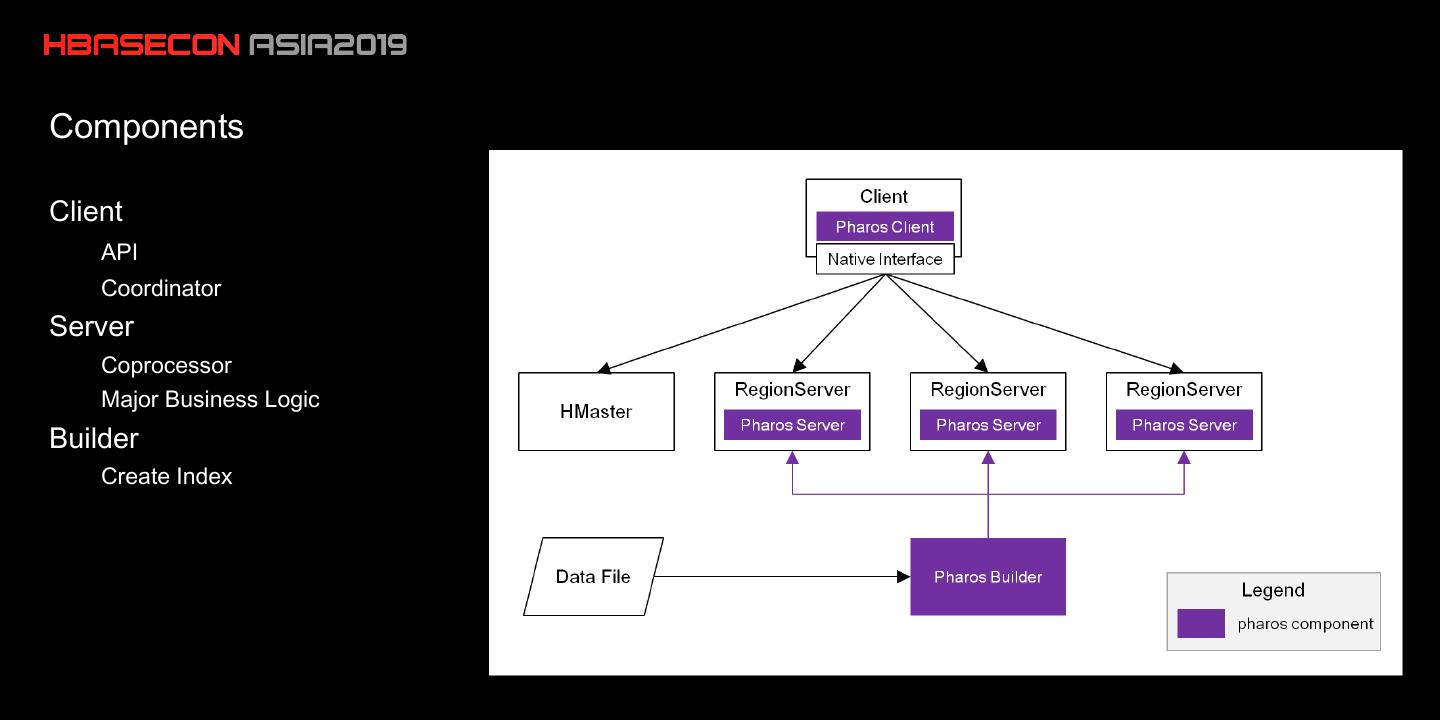
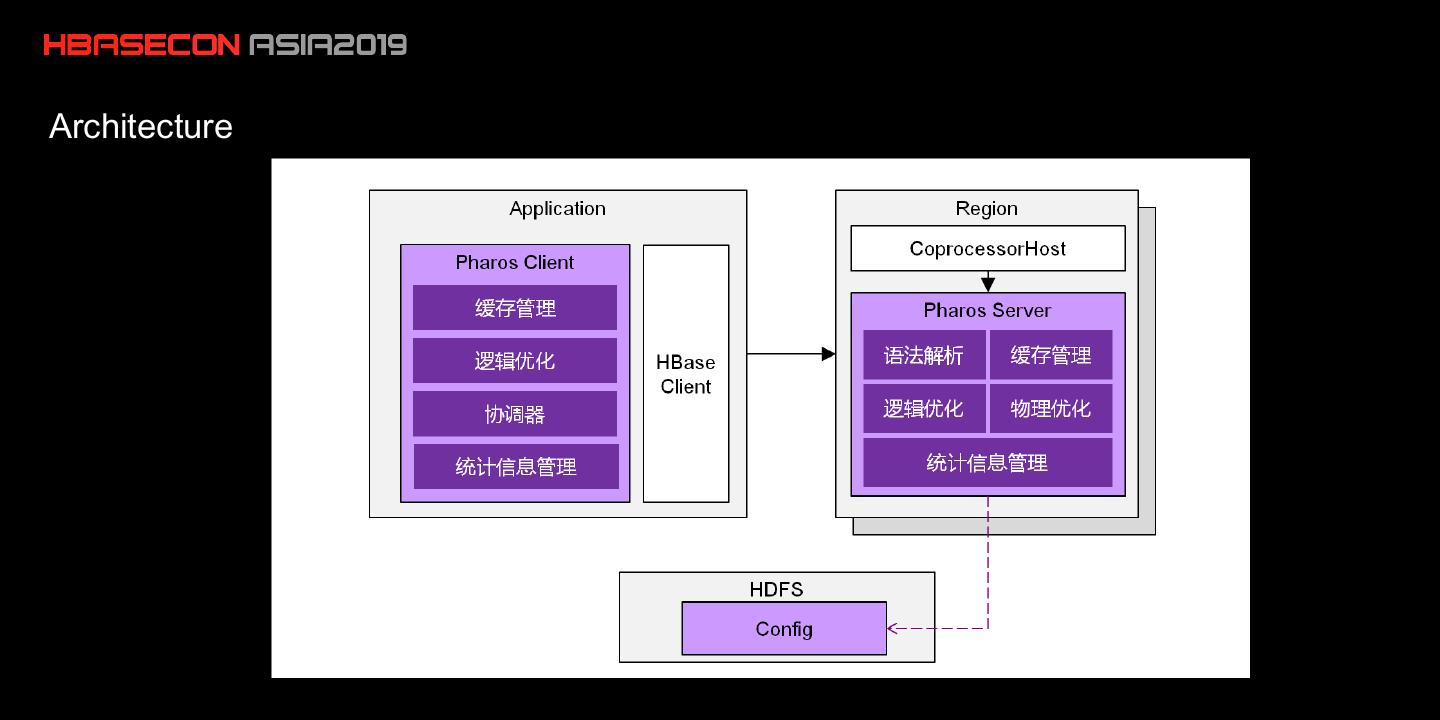
10 .Components
Client
API
Coordinator
Server
Coprocessor
Major Business Logic
Builder
Create Index
�
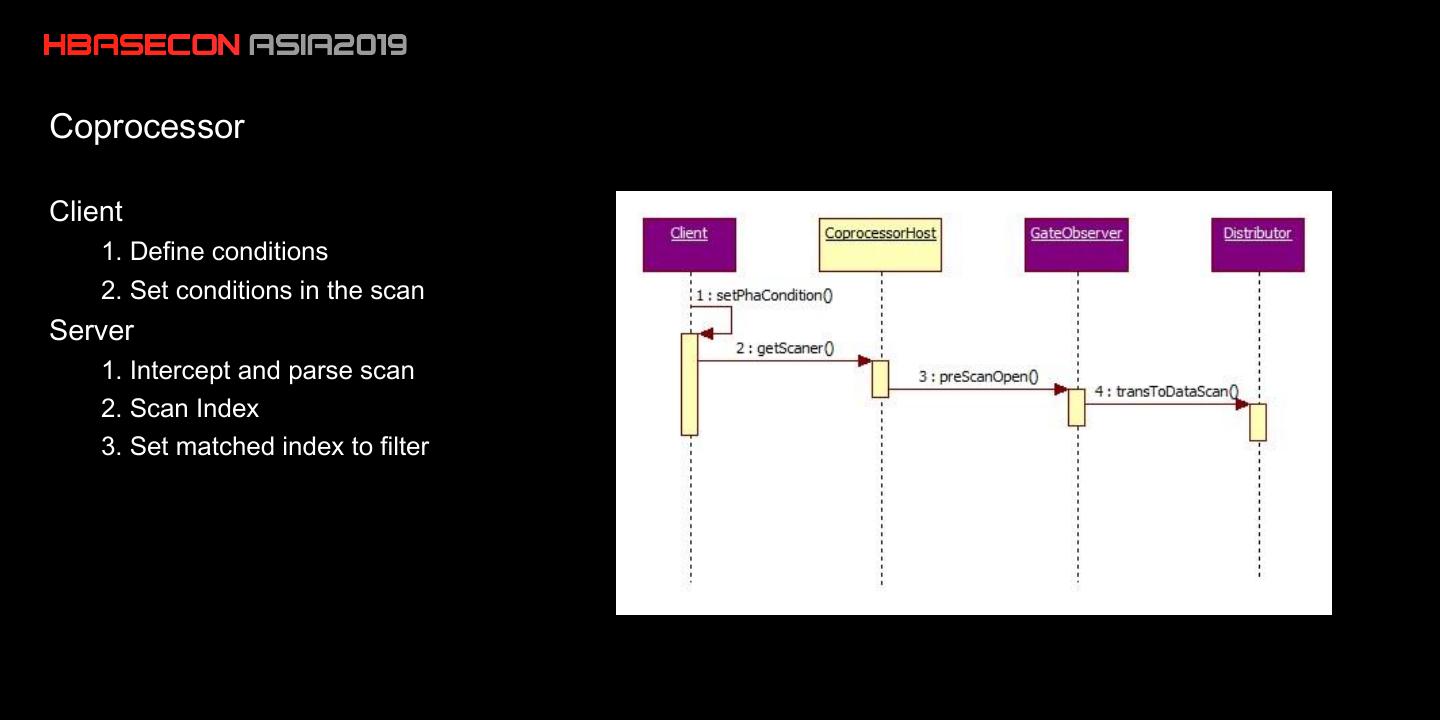
11 .Coprocessor
Client
1. Define conditions
2. Set conditions in the scan
Server
1. Intercept and parse scan
2. Scan Index
3. Set matched index to filter
�
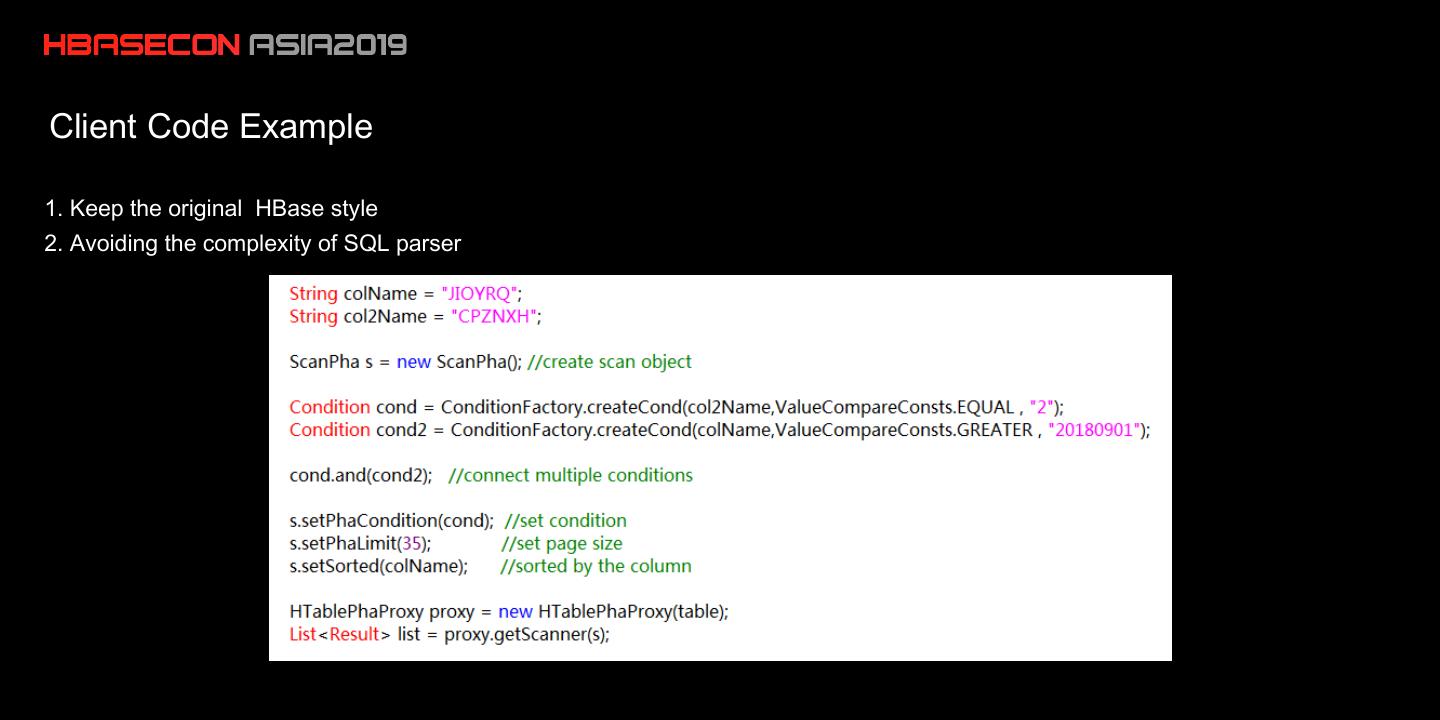
12 .Client Code Example
1. Keep the original HBase style
2. Avoiding the complexity of SQL parser
�
13 . Part II
Architecture Design
�
14 .Global Index VS Partition(Local)Index
Global Index Partition Index
• Support unique index • Index and data are co-distribution ,so queries can be pushed down to
each node. We can get good performance.
• Avoiding distributed transaction
• Index creating and updating will be part of distributed
transactions, performance is not good.
• Query will cross different nodes, so performance may not • Not support unique index or other global constraints.
be good
�
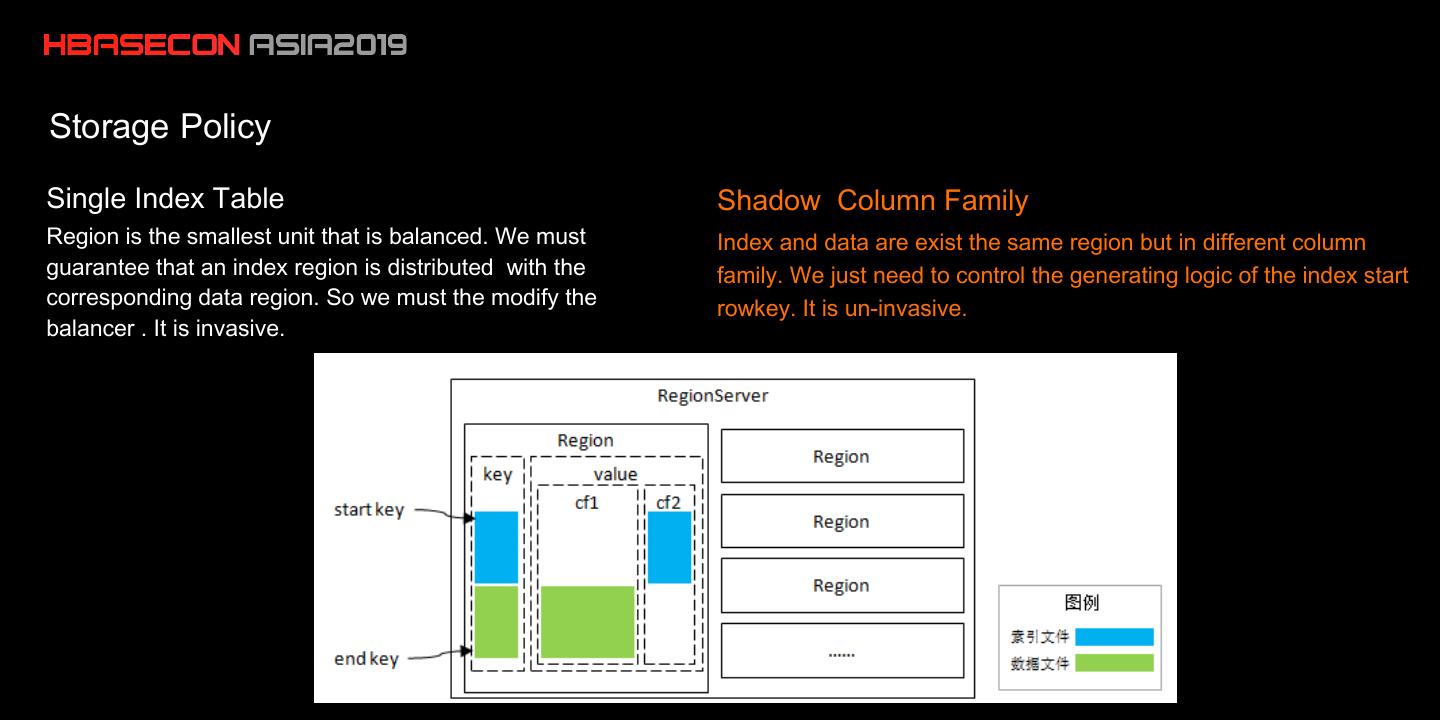
15 .Storage Policy
Single Index Table Shadow Column Family
Region is the smallest unit that is balanced. We must Index and data are exist the same region but in different column
guarantee that an index region is distributed with the family. We just need to control the generating logic of the index start
corresponding data region. So we must the modify the rowkey. It is un-invasive.
balancer . It is invasive.
�
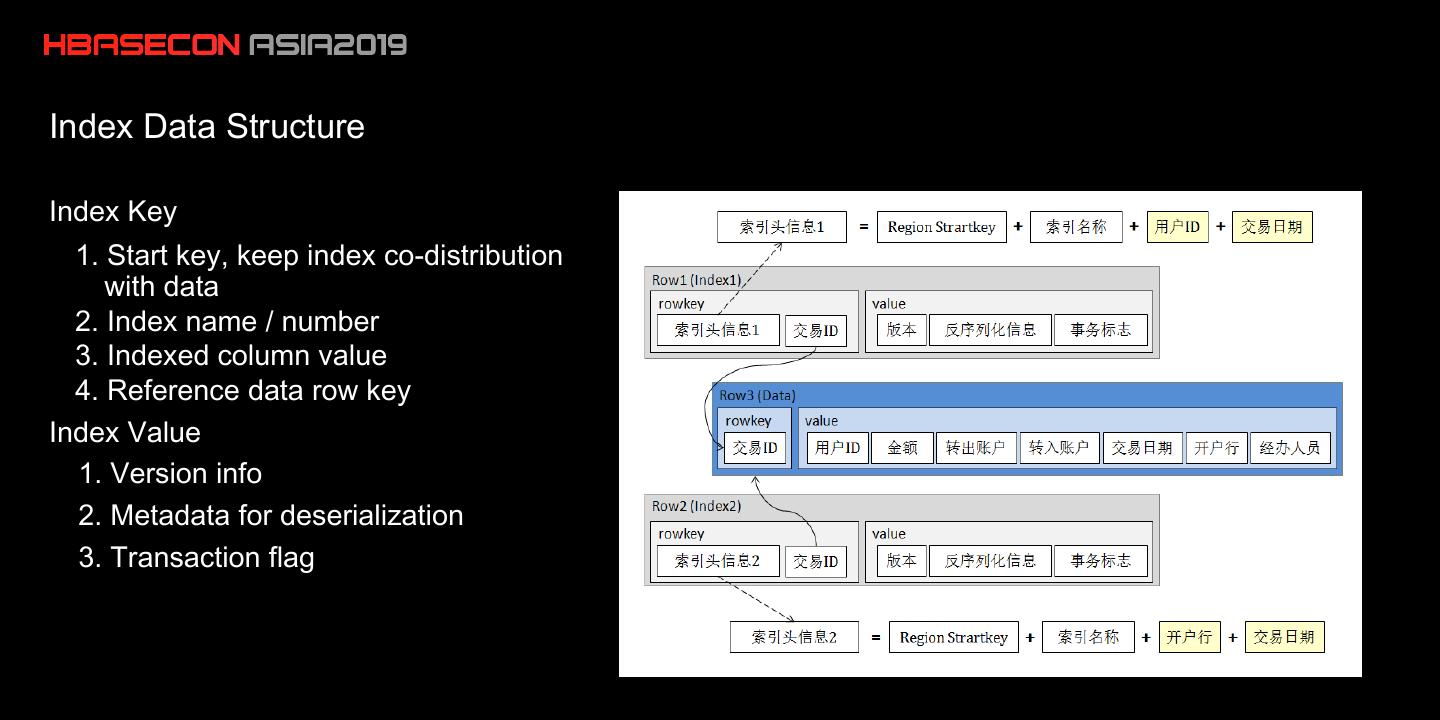
16 .Index Data Structure
Index Key
1. Start key, keep index co-distribution
with data
2. Index name / number
3. Indexed column value
4. Reference data row key
Index Value
1. Version info
2. Metadata for deserialization
3. Transaction flag
�
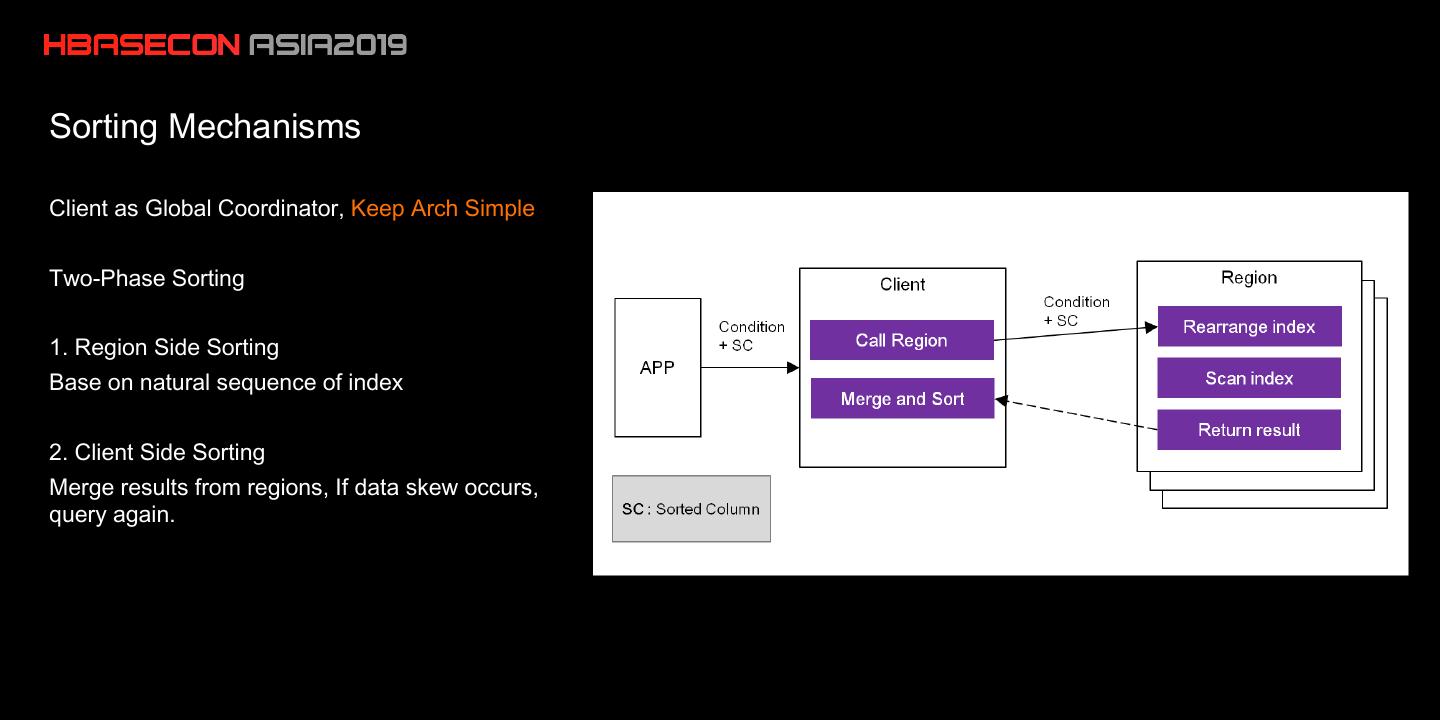
17 .Sorting Mechanisms
Client as Global Coordinator, Keep Arch Simple
Two-Phase Sorting
1. Region Side Sorting
Base on natural sequence of index
2. Client Side Sorting
Merge results from regions, If data skew occurs,
query again.
�
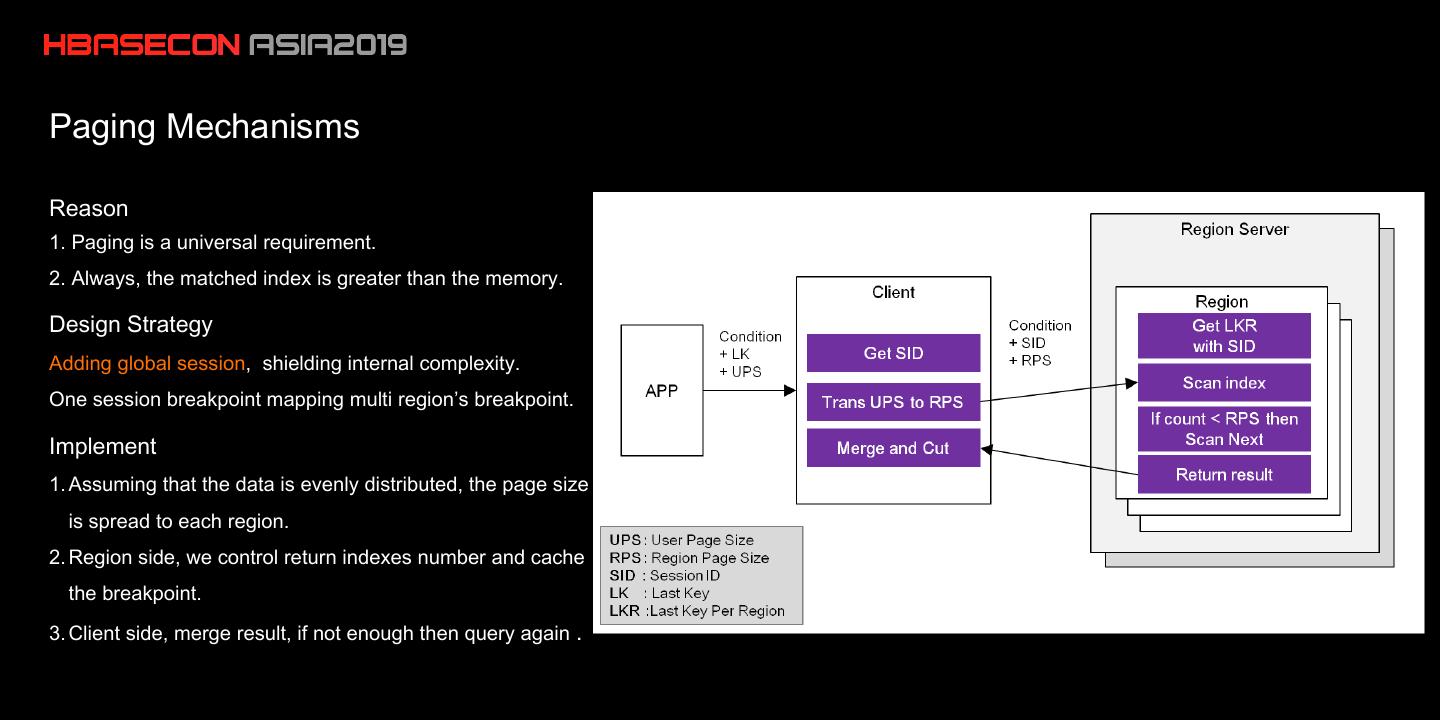
18 .Paging Mechanisms
Reason
1. Paging is a universal requirement.
2. Always, the matched index is greater than the memory.
Design Strategy
Adding global session, shielding internal complexity.
One session breakpoint mapping multi region’s breakpoint.
Implement
1. Assuming that the data is evenly distributed, the page size
is spread to each region.
2. Region side, we control return indexes number and cache
the breakpoint.
3. Client side, merge result, if not enough then query again .
�
19 .Cache Mechanisms
Choose local cache instead of distributed cache
Keep Arch Simple
Client side cache + Server side cache
�
20 .Index Builder
Avoid Rebuilding index due to Region Splitting.
For different rowkey design, Bulkload may lead to
region splitting.
After data loading, stable regions can be obtained.
So we can create indexes and keep co-distribution
with the reference data.
�
22 . Part III
Future Development
�
23 .Transaction Consistency
Inspire by Google’s Percolator
Bob -> Joe $7
Deformation of 2 Phase Commit
The state of the primary data is the state of the Step 4 -> Transaction complete
transaction.
In the write process, only modify the primary state.
In the subsequent query, the state of second data
can be modified asynchronously based on the
primary.
�
24 .Transaction Consistency
In the write process, we can
complete majority consistency, but
not all;
In the read process, we can confirm
transaction state by data row state,
then update index state.
�
25 .Other features
Bitmap Index
CBO Improvement
Integration with SQL Engine(Presto?)
�