展开查看详情
2 .Agenda
• 使用现状
• 架构实践
• 服务策略
• 问题瓶颈
�
4 .概况
• HBase版本
爱奇艺云
• 1.2.0-CDH5.14.4-qiyi-1
Babel计算平台
• 规模
• 物理机数量6000+,最大集群1500节点 Gear作业调度系统
云 中 数
• 数据总量约3PB(单备份),大表>100TB 计 间 据
算 件 库
• 离线QPS 50 Mil+,线上QPS 3 Mil+ 压测 元数据
…
Hadoop服务平台
• 服务使用架构
• 私有云环境
…
• 大数据平台化服务 Hadoop集群
• 大数据产品栈
�
5 .数据库@iQIYI 产品定位
• 按访问模式:NoSQL -> SQL
• schema
• 访问接口
• ACID
• 按应用场景:OLTP -> HTAP -> OLAP
• 目的:交易处理 vs 数据分析
• 延时:ms vs s/m
• 按分布式系统特点
• 可扩展性 CAP
• QPS量级:10K vs 10M
• 数据量:GB vs TB/PB
�
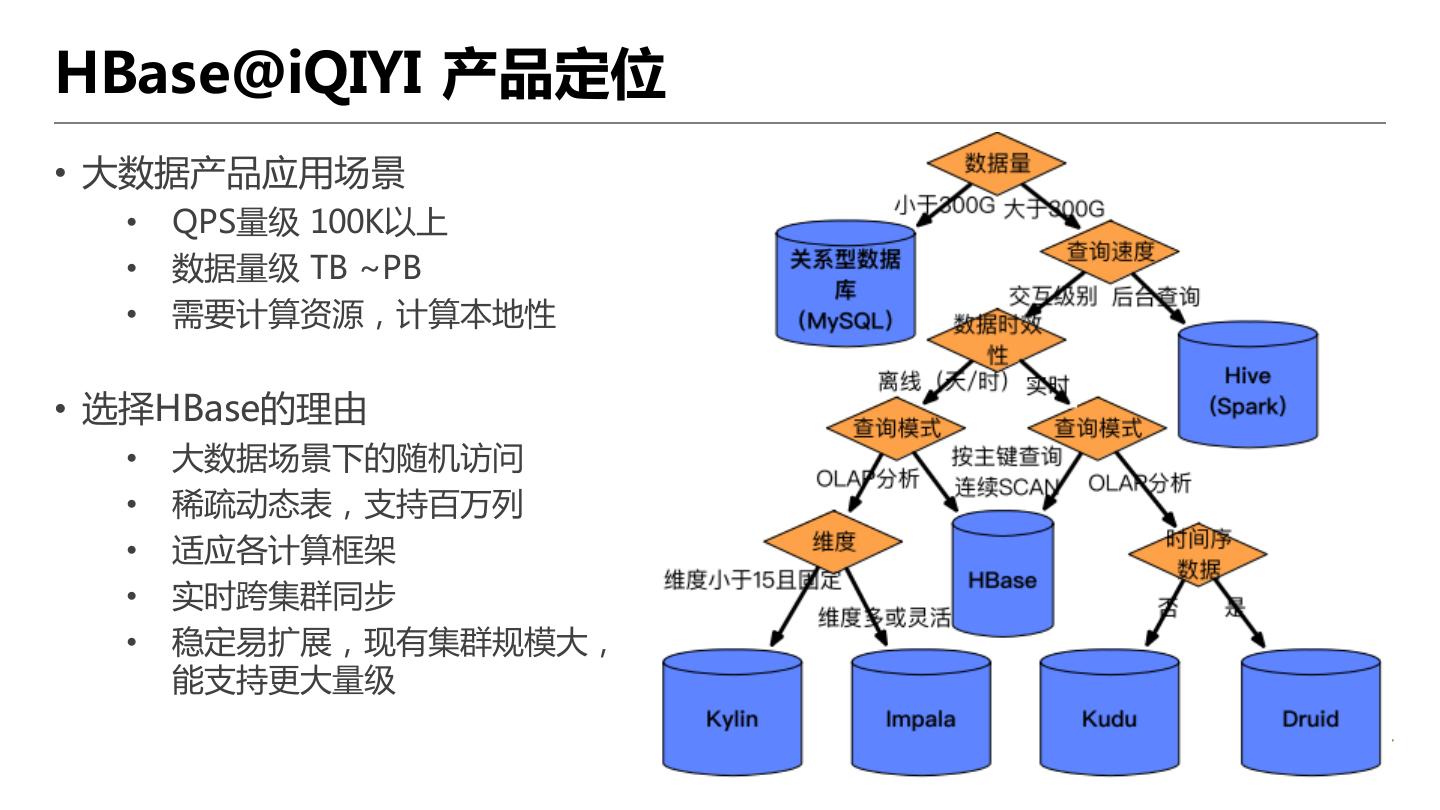
6 .HBase@iQIYI 产品定位
• 大数据产品应用场景
• QPS量级 100K以上
• 数据量级 TB ~PB
• 需要计算资源,计算本地性
• 选择HBase的理由
• 大数据场景下的随机访问
• 稀疏动态表,支持百万列
• 适应各计算框架
• 实时跨集群同步
• 稳定易扩展,现有集群规模大,
能支持更大量级
�
7 .应用场景
视频推荐 安全风控
视频元数据存储
广告推荐
搜索 Kylin Cube
Phoenix
调用链日志
泡泡Feeds流
封面图片
IM 聊天消息
物理机监控 评论
�
9 .架构概览
• 3-4个主力DC DC 1 数据 DC 2
• 业务分流 同步/迁移
公共集群 公共集群
• 运营商
• HA HBase专用集群 HA HBase专用集群
实时计算集群 实时计算集群
• HBase相关集群分类
OLAP专用集群 OLAP专用集群
• 公共集群
Druid专用集群 Druid专用集群
• Kylin HBase集群
• HBase专用集群 业务独立 Kylin 业务独立 Kylin
集群 HBase 集群 HBase
• 业务独立集群
DC 3
�
10 .公共集群
• 场景
Kylin
• 1000+节点 TSDB IMPALA Hive Kylin HBase
• 用于大规模数据计算 集群
• 亚秒延时、单表10M qps MR/Spark/Flink
YARN ZK
HBase 150G HBase
• 架构 BucketCache 20G + 12G 专用ZK
• 拆分ZooKeeper
其他服务
• 分离Kylin HDFS 4G SSD&SATA ZooKeeper
• 异构存储 WAL-on-SSD
• BucketCache 20G offheap
• 非实时访问禁用BlockCache
�
11 .HBase专用集群
• 场景 全文 Janus Graph
MR
• 100节点 索引 图数据库
Spark
• 线上实时访问,简单OLAP分析 Phoenix 控制
• 150ms以下延时,均值50ms ES/Solr 任务
HBase YARN
• 架构 50G + 50G 50G
• SSD
两备份(计算本地性要求低,HA) HDFS 4G SSD
• BucketCache 50G offheap
• 控制计算任务执行
• 分离 线上访问-计算分析
• Pheonix:SQL、二级索引、Salt
• 调研中:Solr+JanusGraph Atalas
�
12 .业务独立集群
• 场景
• 10-50节点 Flink
• 用于业务特定需求
• 案例-Flink流关联 YARN
• 全量消息,数据量大,需5ms以下延时 HBase 100G
LRU 60G
• 写入足够分散,无更新特性
• 91.52%读最近1小时写入的数据
HDFS 4G SSD
• 非重复读,每条数据只会访问一次
• 优化
• 7天TTL,2备份,压缩后150TB
• cache索引,cache_data_on_write 缓存最近数据
• 读不替换缓存,减少缓存置换开销
• compactionThreshold + compaction.max.size +BloomFilter
缩小随机访问范围,减少compaction压力
�
13 .数据同步
• 同步管理 HA、访问计算分离、数据依赖、数据冷备…G
• 表级别控制
• 定义同步链路 DC-1G A C D
HA
• 表同步设置 G
1. export snapshort DC-2G E F I
2. 目标表设置purge.deletes(24h)
3. 设置表同步
4. copyTable补数据 DC-3G G H
• 定期一致性检查 公共 专用 独立
• 基于ReplicationCompare改造
• 迭代多轮比较,验证最终一致性
�
14 .监控
关联服务DashBoard 未恢复报警 日志分析
• 统计型排查
• 整合关键指标
信息整合
• 集群整体->服务器、表
• 子维度排序、展开详情
服务总体指标
• 拨测
• 表分布到每个RS,put/get
• 表RowCounter检查
• 指标存储 子维度排序、展开详情
• OpenTSDB + InfluxDB
• 长时间、高基数聚合慢
转型使用Druid
�
15 .升级策略
• 需要持续关注社区release、patch GitHub
• 升级历程:5.2.0→5.11.0→5.14.2→5.14.4
• 5.11.0 HBase bugs:CDH-55446、HBase-17319、17069…
• 版本管理
QIYI GitLab
• CDH Major、Minor、Maintenance 升级
• QIYI Maintenance :5.14.4-qiyi-1
• 源码开发、发布、部署 Maven
• Gitlab管理源码,比较各release分支
• 维护QIYI内部版本,发布到maven
• 复用CDH rpm包 Ansible 集群
maven_artifact
ansible maven_artifact模块指定jar包版本
�
17 .向业务提供服务的策略
• HBase单集群多租户
• 硬件资源利用率高
• 部署管理方便
• 隔离性差
• 策略
• 定义资源:HBase表
• 集群容量:空间大小、region总数
• 提供方式:模板化建表
• 资源隔离性:尽可能确保各表健康
�
18 .资源与配额
• HBase表资源
• Default namespace
• 未使用RS group
• 通过平台工单申请,控制建表
• 线上统一控制DDL、权限操作
• 健康检查,确保表均匀无热点
• 配额定义
• 集群资源总容量
• 部门配额
• 资源分配配额
• 资源实际使用量
�
19 .压测与容量
• 确定Space容量
• /hbase目录的总Quota
• 确定Region容量
• 根据Memstore估算大概范围
• 单节点压测,HBase pe,估算最佳region数、
最佳并发数、读写峰值
300个region,64并发数
随机读 78K, 随机写 231K
顺序读 133K,顺序写 426K
• 300/RS,每个region容量:5~20GB
读qps 0.26K~0.6K, 写qps 0.77K~1.5K
�
20 .模板化建表
• 确定应用场景
• 选择集群类型
• 运行计算任务、实时访问、线上业务…
• 关键表属性设置
• 用户确定Version、TTL、同步链路
• 自动设置BlockCache、MOB、分裂策略、
压缩等
• 确定表预分区方法
• 16进制字符串、10进制字符串、采样
• 配额
• 数据量估算+峰值qps,推算Region数量
• 用户可以只给出数据量估算
�
21 .定期整理与健康度检查
• 表定期整理
• major compact
• 自定义normalize
• balance
• 表健康度检查
• 热点
• 数据倾斜
• 分区数不匹配
�
23 .问题瓶颈
• ZooKeeper重选,RegionServer重连超时
• HBase启动恢复慢
�
24 .ZooKeeper重选,RS重连超时
• 问题:
• ZooKeeper发生重选时,Session重连,RegionServer发生ZK sessionTimeout宕机
• ZooKeeper Zxid rollover,定期引发重选
�
25 .ZooKeeper重选,RS重连超时
• 连接数过多,单个ZK-server 5000个连接
Ø 限制maxClientCnxns,找出错误使用HBase Conn任务
• Znode过多,25w个
Ø 定期清理Replication残留Znode
• ZooKeeper关闭连接时的瓶颈
Ø ZOOKEEPER-1669,HashSet并发瓶颈
• ZooKeeper Leader session激活(revalidation)瓶颈
Ø ZOOKEEPER-3169,未解决,通过调高max session timeout应对
• 减少对ZooKeeper依赖
Ø 调研:ZK-less,AssignmentMananger v2
�
26 .HBase启动恢复慢
• 问题:
• 1500节点,25w region
• clean-startup 15min;主动关闭集群,经常无法正常进入clean-startup
• 恢复流程需要1 hour左右
�
27 .HBase启动恢复慢
• 错误判定为恢复流程
Ø HBASE-14223,清理残留的Meta WALs
Ø HBASE-15251,错误判断为failover
• SplitWAL ZK阻塞
Ø 参考HBASE-19290,调节RS遍历Znode停顿时间
• SplitWAL并发控制,易引起gc问题
Ø master.executor.serverops.threads x bulk.assignment.threadpool.size
• 启动过程中,部分节点阻塞影响恢复
Ø 及时处理启动过程中阻塞节点
Ø 启动恢复过程中,停止业务访问(需要一种安全模式)
�
28 .我们正在招聘大数据方面的运维开发工程师、资深架构师等人才
有意者请发邮箱到
zhenghaonan@qiyi.com
�