






















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
大规模数据近实时加载方法和体系结构
大规模数据近实时加载方法和体系结构
展开查看详情
1 .Large scale data near-line loading method and architecture FiberHome Telecommunication 2017-7-19
2 . /usr/bin/whoami Shuaifeng Zhou(周帅锋): • Big data research and development director ( Fiberhome 2013-) • Software engineer (Huawei 2007-2013) • Use and contribute to HBase since 2009 • sfzhou1791@fiberhome.com
3 . Contents 1 Motivation 2 Solution 3 Optimization 4 Tests 5 Summarize
4 .HBase Realtime Data Loading WAL/Flush/Compact Triple IO pressure Read/Write operations share resource: Cpu Network Disk IO Handler Read performance decrease too much when write load is heavy
5 .Why near-line data loading? Scale Delay Billions write ops per Usually, several minutes region server one day delay is acceptable for customers HBase Resource Reliable Resource occupied can Write op can be be limited under an repeated acceptable level Optimistic failure handling Large scale data loading reliably with acceptable time delay and resource occupation
6 . Contents 1 Motivation 2 Solution 3 Optimization 4 Tests 5 Summarize
7 .Read-Write split data loading Independent WriterServer to handle put request RegionServer only handle read request WriteServer write HFile on HDFS, send do-bulkload operation. Several minutes delay between put and data readable.
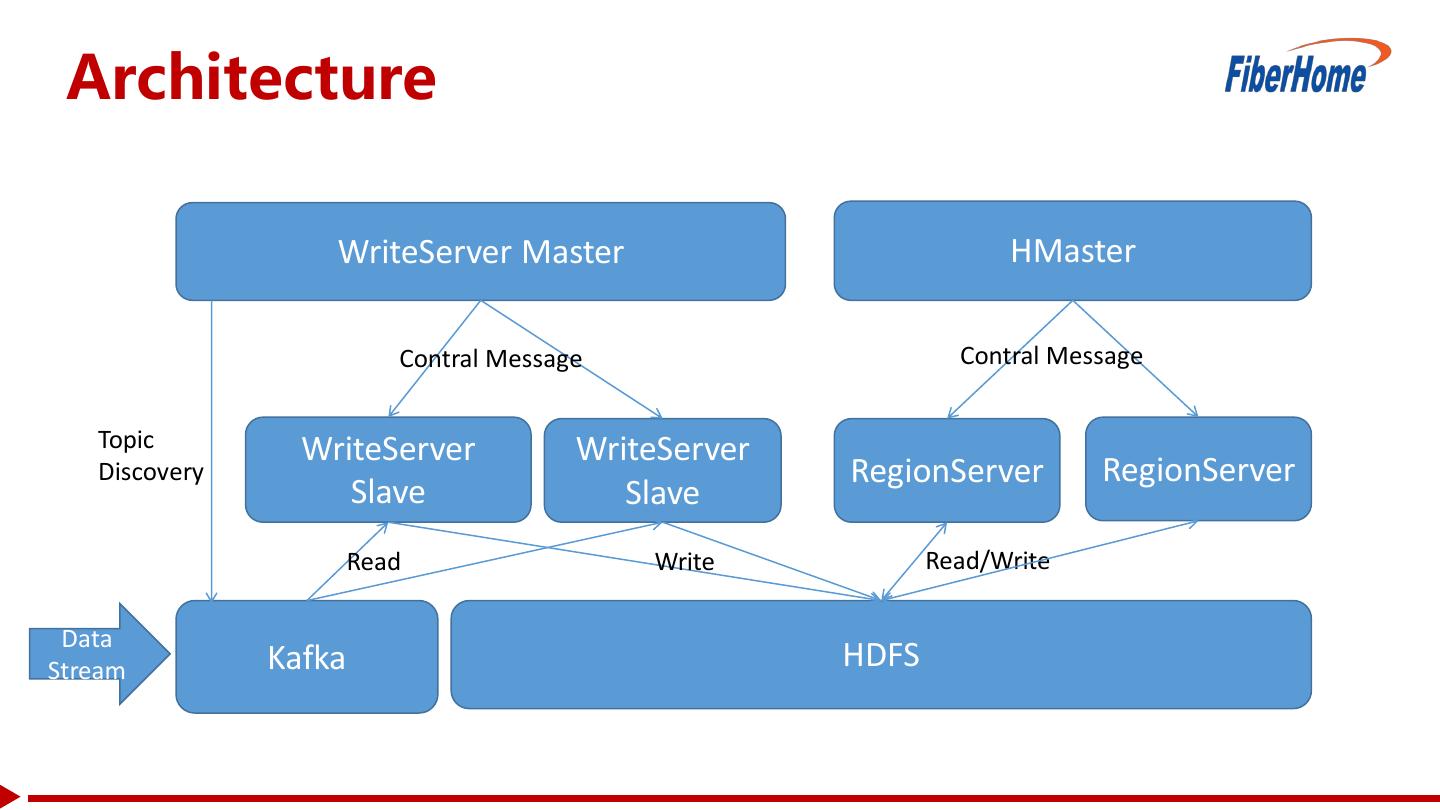
8 . Architecture WriteServer Master HMaster Contral Message Contral Message Topic WriteServer WriteServer Discovery RegionServer RegionServer Slave Slave Read Write Read/Write Data Stream Kafka HDFS
9 .WriteServer Master Topic Management Task Management Slaves Management • Discover new kafka topics • Create new loading tasks • Slave status report to every five minutes or every master • Receive loading request 10,000 records • Balance • Loading records statistic • Find a slave to load the task • failover • Task status control
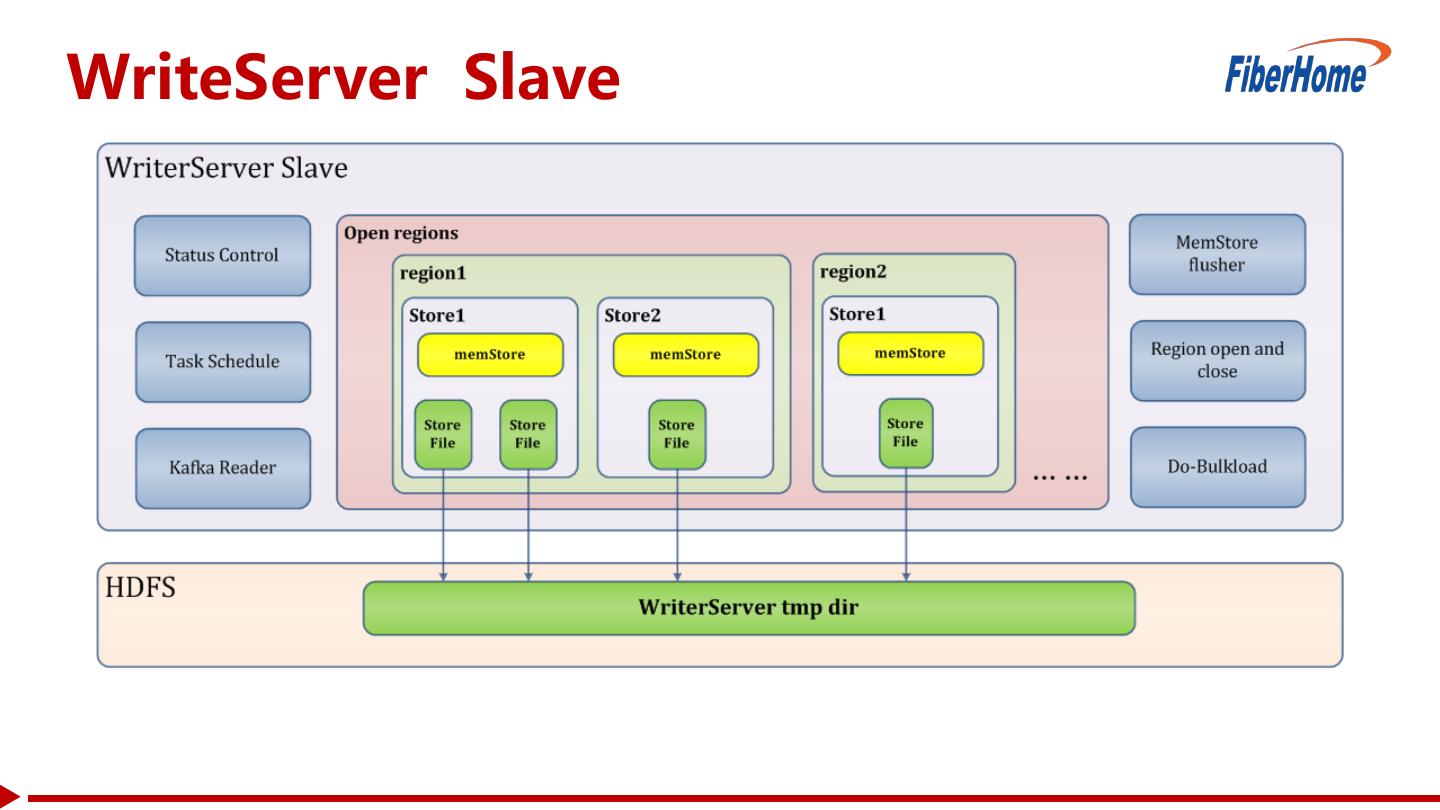
10 .WriteServer Slave
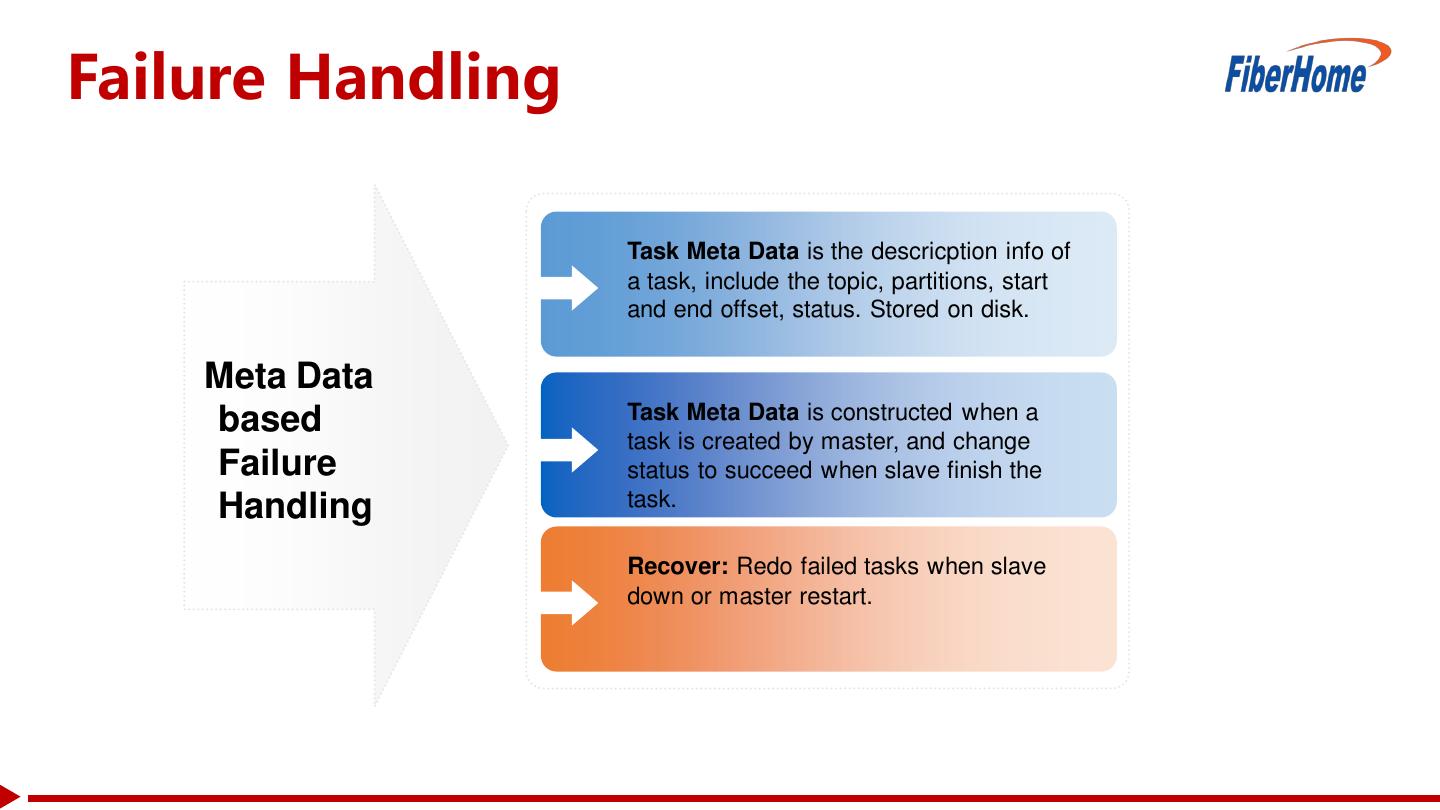
11 .Failure Handling Task Meta Data is the descricption info of a task, include the topic, partitions, start and end offset, status. Stored on disk. Meta Data based Task Meta Data is constructed when a task is created by master, and change Failure status to succeed when slave finish the Handling task. Recover: Redo failed tasks when slave down or master restart.
12 . Contents 1 Motivation 2 Solution 3 Optimization 4 Tests 5 Summarize
13 .Balance Load balance according tasks: • Send new tasks to slaves with less tasks on handling • Try to send tasks of one topic to a few fixed slaves −avoid one region open everywhere −Less region open, less small files • Keep region opened for a while, even there are no tasks − avoid region open/close too frequently
14 . Compact • Small files with higher priority • Avoid one large file together with many small files compact again and again compact compact 9 1 5 2 3 4 6 7 8
15 . StoreEngine Customized store engine: • organize store files in two queues −one can be read and compact −The other can only be compact −If there are too many files, new file will not be readable until they are compact • Some new files discovered later better than all files can not be read before time out − Occasionally data explosion can be handled − Region need split − “Hot key” should be handled
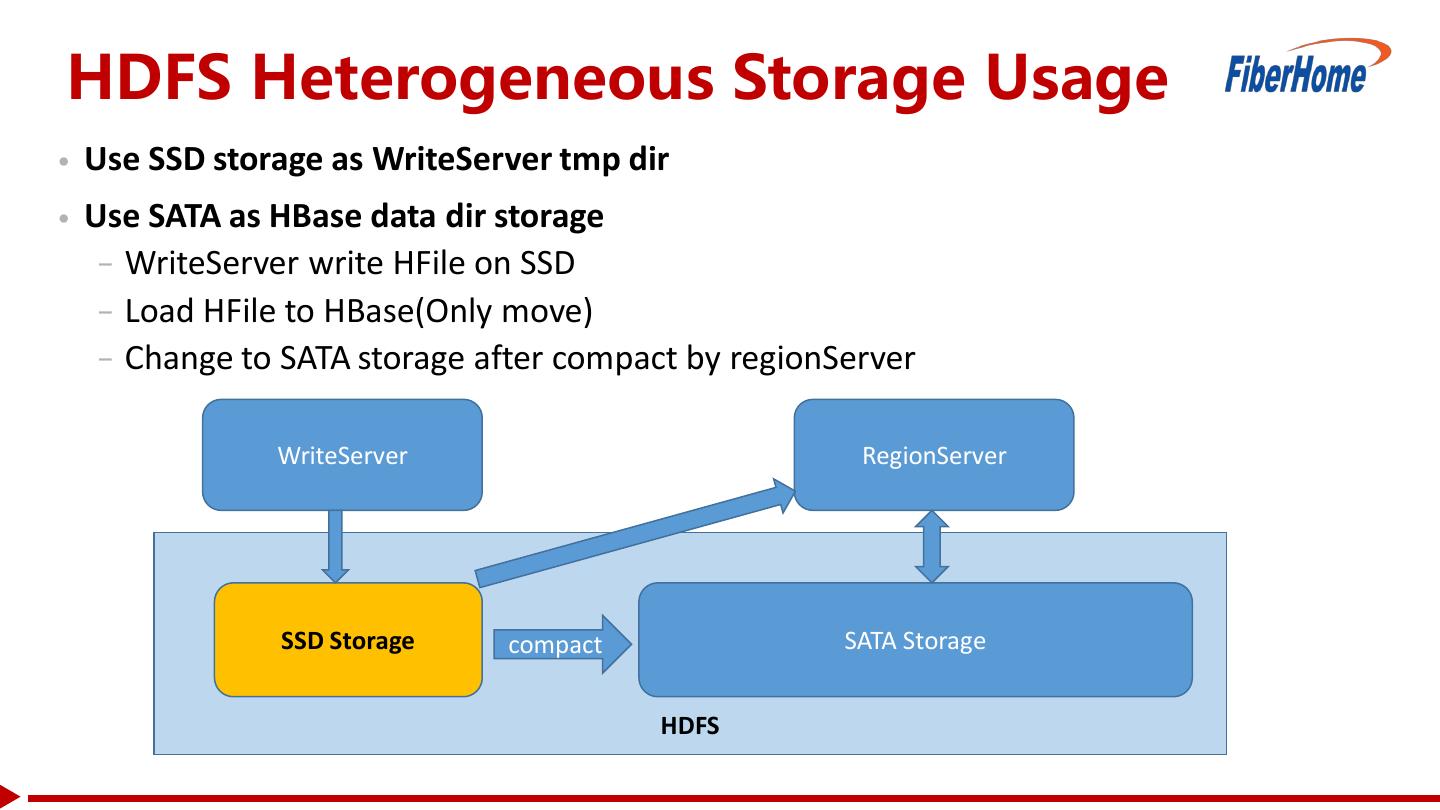
16 .HDFS Heterogeneous Storage Usage • Use SSD storage as WriteServer tmp dir • Use SATA as HBase data dir storage − WriteServer write HFile on SSD − Load HFile to HBase(Only move) − Change to SATA storage after compact by regionServer WriteServer RegionServer SSD Storage compact SATA Storage HDFS
17 .Resource Control Resource used by WriteServer should be controllable: • Memory: −JVM parameters 30~50GB memory −Large Memory Store will avoid small files −Too Large memory store will cause gc problems • CPU: − Slave can use 80% cpu cores at most − Compare to real-time data load, a big optimize is we can control the cpu occupation by write operations.
18 . Contents 1 Motivation 2 Solution 3 Optimization 4 Tests 5 Summarize
19 .Loading Performance WriterServer Slave CPU Intel(R) Xeon(R) CPU E5-2640 v2 @ 2.00GHz Memory 128G Disk 1TB SSD * 4 Network 10GE Record size 1KB Compress Snappy Performance 300,000 records/s One WriteServer slave can match 5 RegionServer’s loading requirements before RegionServer reach compact limitation.
20 . 100 20 40 60 80 0 MB/sec 13:16 13:22 100 200 300 400 0 13:19 13:29 13:27 13:36 13:34 13:42 13:42 13:49 13:50 13:55 13:57 14:02 14:05 14:08 14:13 14:15 14:20 14:21 14:28 14:28 Disk Read KB/s 14:36 14:34 User% 14:43 14:41 14:51 14:47 14:59 14:54 Sys% 15:06 15:00 15:14 15:07 15:22 15:13 Wait% 15:29 15:20 Disk Write KB/s 15:37 15:26 15:45 15:33 15:52 15:39 16:00 15:46 16:08 15:52 IO/sec 16:15 15:59 CPU Total WS-Slave5 – 2017/2/17 Disk total MB/s WS-Slave5- 2017/2/17 16:23 16:05 16:31 16:12 16:18 0 500 16:25 1000 1500 2000 IO/sec 16:31 Resource Performance 200 400 600 0 -400 -200 13:19 13:25 13:32 13:38 13:45 13:51 assigned 13:58 Memory 14:04 14:11 14:17 14:24 14:30 14:37 Total-Read 14:43 14:50 14:56 15:03 15:09 15:16 15:22 Total-Write (-ve) 15:29 15:35 15:42 GC: config gc policy to avoid full gc. 15:48 JVM: aways use memory as much as 15:55 16:01 16:08 Network I/O WS-Slave5 (MB/s) - 2017/2/17 16:14 16:21 16:27 16:34
21 . Contents 1 Motivation 2 Solution 3 Optimization 4 Tests 5 Summarize
22 .Summarize We proposed an read-write split near-line loading method and architecture: • Increase loading performance • Control resource used by write operation, make sure read operation can not be starved • Provide an architecture corresponding with kafka and hdfs • Provide some optimize method, eg: compact, balance, etc. • Provide test result
23 .FiberHome Questions ?
24 .Thanks
3秒后跳转登录页面
去登陆

