






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
使用HBase构建大数据生态
使用HBase构建大数据生态
展开查看详情
1 .Ecosystems built with HBase and CloudTable service at Huawei Jieshan Bi, Yanhui Zhong 1
2 .Agenda CTBase: A light weight HBase client for structured data Tagram: Distributed bitmap index implementation with HBase CloudTable service(HBase on Huawei Cloud) 2
3 .CTBase Design Motivation Most of our customer scenarios are structured data HBase secondary index is a basic requirement New application indicated new HBase secondary development Simple cross-table join queries are common Full text index is also required for some customer scenarios 3
4 .CTBase Features Schematized table Global secondary index Cluster table for simple cross-table join queries Online schema changes JSON based query DSL 4
5 .Schematized Table Column Qualifier UserTable contains User table column: mapping HBase column: Service conceptual user table for Each column indicates an Each column indicates a storing user data attribute of service data. KeyValue. contains Index Index RowKey Primary index: Rowkey of table that stored the user data, Column 1 Column 2 Column 3 indicating the search scenario with the highest probability Secondary index: Saves the information about the index to the primary index. Schematized Tables is better for structured user data storage. A lot of modern NewSQL databases likes MegaStore, Spanner, F1, Kudu are designed based on schematized tables. 5
6 .Schema Manager CTBase provide schema definition API. Schema definition includes: Table Creation A user table will be exist as simple or cluster table mode. Column Definition Column is a similar concept with RDBMS. A column has specific type and length limit. Qualifier Definition Column to ColumnFamily:Qualifier mapping. CTBase supports composite column, multiple column can be stored into one same ColumnFamily:Qualifier. Index Definition An index is either primary or secondary. The major part of index definition is the index rowkey definition. Some hot columns can also be stored in secondary row. 6
7 .Schema Manager Cont. Meta Cache Each client has a schema locally in memory for fast data conversion. Meta Backup/Recovery Tool Schema data can be exported as data file for fast recovery. Schema Changes • Column changes • Qualifier changes • Index changes Some changes are light-weight since they can take advantage of the scheme-less characteristics of HBase. But some changes may cause the existing data to rebuild. 7
8 .HBase Global Secondary Index NAME =‘Lina’ ID NAME PROVINCE GENDER PHONE AGE NAME ID I0000001 Lily Shandong MALE 13322221111 20 Region1 I0000002 Wang Guangdong FEMAIL 13222221111 15 Ariya I0000005 Bai I0000006 I0000003 Lina Shanxi FEMAIL 13522221111 13 IndexRegionA He I0000004 I0000004 He Henan MALE 13333331111 18 Lily I0000001 I0000005 Ariya Hebei FEMAIL 13344441111 28 Region2 I0000006 Bai Hunan MALE 15822221111 30 Lina I0000003 Lina I9999999 I0000007 Wang Hubei FEMAIL 15922221111 35 Lisa I0000008 I0000008 Lisa Heilongjiang MALE 15844448888 38 Wang I0000002 Region3 Wang I0000007 I0000009 Xiao Jilin MALE 13802514000 38 IndexRegionB ……. …………. …………. ……. …… ………. ………………….. …. Xiao I0000009 I9999999 Lina Liaoning MALE 13955225522 70 Region4 Secondary index is for non-key column based queries. Global secondary index is better for OLTP-like queries with small batch results. User Region Index Region 8
9 .HBase Global Secondary Index Cont. Section Section Section …………. Index RowKey Format Section is normally related to one user column, but can also be a constant or a random number. Primary Key Secondary Index Key Suppose table UserInfo includes below 5 columns: Secondary index key for NAME index: ID, NAME, ADDRESS, PHONE,DATE Primary key are composed with 3 sections: NAME ID truncate(DATE, 8) Section 1: ID H H H Section 2: NAME Section 3: truncate(DATE, 8) Secondary index key for PHONE index: So the primary rowkey is: PHONE ID NAME truncate(DATE, 8) ID NAME truncate(DATE, 8) H H H NOTE:Sections with H are also exist in primary key 9
10 . Cluster Table Example: select a.account_id, a.amount, b.account_name, b.account_balance from Transactions a left join AccountInfo b on a.account_id = b.account_id where a.account_id = “xxxxxxx” account_id amount time A0001 Andy $100232 A0001 $100 12/12/2014 18:00:02 Records from different A0001 $100 12/12/2014 18:00:02 business-level user A0001 $1020 10/12/2014 15:30:05 A0001 $1020 10/12/2014 15:30:05 table stored together A0001 $89 09/12/2014 13:00:07 A0001 $89 09/12/2014 13:00:07 A0002 $105 11/12/2014 20:15:00 A0002 Lily $902323 AccountInfo record A0002 $105 11/12/2014 20:15:00 account_id account_name account_balance A0002 $129 11/11/2014 18:15:00 Transaction record A0001 Andy $100232 A0002 Lily $902323 A0003 Selina $90000 Pre-Joining with Keys: A better solution for cross-table join in HBase. Records come from different tables but have some same A0004 Anna $102320 primary key columns can be stored adjacent to each other, so the cross-table join turns into a sequential scan. 10
11 . ClusterTable Write Vs. HBase Write Table table = null; ClusterTableInterface table = null; try { try { table = conn.getTable(TABLE_NAME); table = new ClusterTable(conf, CLUSTER_TABLE); // Generate RowKey. CTRow row = new CTRow(); String rowKey = record.getId() + SEPERATOR + record.getName(); // Add all columns. Put put = new Put(Bytes.toBytes(rowKey)); row.addColumn("ID", record.getId()); // Add name. row.addColumn("NAME", record.getName()); put.add(FAMILY, Bytes.toBytes("N"), Bytes.toBytes(record.getName())); row.addColumn("Address", record.getAddress()); // Add phone. row.addColumn("Phone", record.getPhone()); put.add(FAMILY, Bytes.toBytes("P"), Bytes.toBytes(record.getPhone())); row.addColumn("Age", record.getAge()); // Add composite columns. row.addColumn("Gender", record.getGender()); String compositeColumn = record.getAddress() + SEPERATOR table.put(USER_TABLE, row); + record.getAge() + SEPERATOR + record.getGender(); } catch (IOException e) { put.add(FAMILY, Bytes.toBytes("Z"), Bytes.toBytes(compositeColumn)); // Handle exception. } finally { table.put(put); // …………. } catch (IOException e) { } // Handle exception. } finally { // …….. RowKey/Put/KeyValue are not visible to application directly. } Secondary index row will be auto-generated by CTBase. 11
12 .JSON Based Query DSL { JSON table: “TableA", conditions: [“ID": “23470%", “CarNo": “A1?234", “Color”: “Yello || Black || White”], columns: ["ID", “Time", “CarNo", “Color”], Query Executor caching: 100 } JSON Analyzer Flexible and powerful query API. Support for below operators: Rule Based Optimizer Range Query Operator: >, >=, <, <= Logic Operator: &&, || Query Plan Fuzzy Query Operator: ?, *, % Result Scanner Index name can be specified, or just depend on imbedded RBO to choose the best index. Result Using exist or customized filters to push down queries for decreasing query latency. 12
13 .Bulk Load KeyValue HFile Structured Local (User data) Data Schema KeyValue HFile (Index data) Schema has been defined in advance, including columns, column to qualifier mappings, index row key format, etc. The only required configuration for bulk load task is the column orders of the data file. Secondary index related HFiles can be generated together in one bulk load task. 13
14 .Future Work For CTBase 1. Better Full-Text index support. 2. Active-Active Clusters Client. 3. Better HFile format for structured data. 14
15 .Agenda CTBase: A light weight HBase client for structured data Tagram: Distributed Bitmap index implementation with HBase CloudTable service(HBase on Huawei Cloud) 15
16 .Tagram Design Motivation Low-cardinality attributes are popularly used in Personas area, these attributes are used to describe user/entity typical characteristics, behavior patterns, motivations. E.g. Attributes for describing buyer personas can help identify where your best customers spend time on the internet. Ad-hoc queries must be supported. Likes: “How many male customers have age < 30?” “How many customers have these specific attributes?” “Which people appeared in Area-A, Area-B and Area-C between 9:00 and 12:00?” Solr/Elasticsearch based solutions are not fast enough for low-cardinality attributes based ad-hoc queries. 16
17 .Tagram Introduction Each attribute value Distributed bitmap index implementation uses Tagram Client relates to a Bitmap Condition 101111010010101... HBase as backend storage. GENDER:Male AND MARRIAGE:Married AND AGE:25-30 AND BLOOD_TYPE:A AND CAROWNER Each bit represent Milliseconds level latency for attribute based ad- whether an Entity have this attribute hoc queries. Each attribute value is called a Tag. Entity is called TagZone TagZone a TagHost. Each Tag relates to an independent Conditions 001111010010... Conditions 101111010010... bitmap. Hot tags related bitmaps are memory- & & 111001011110... 011001011110... AST Tree & AST Tree & 001101011010... & 101001011010... & resident. Query 101001011010... Query 101111011010... Optimization & Optimization & A Tag is either static or dynamic. Static tags must 000010011010... 101010011010... Query Plan Query Query Plan Query be defined in advance. Dynamic tags have no such Execution Execution restriction, likes Time-Space related tags. 17
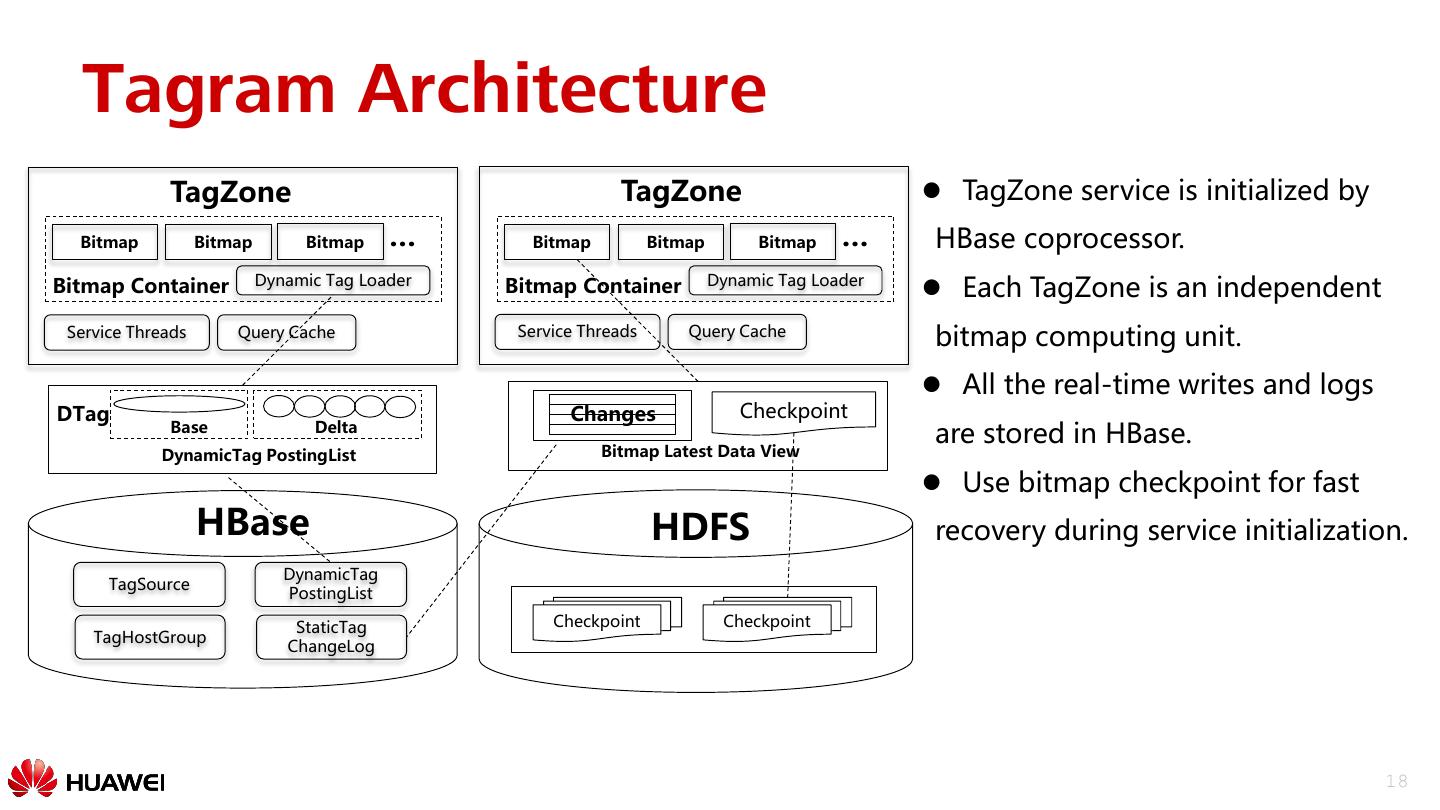
18 . Tagram Architecture TagZone TagZone TagZone service is initialized by Bitmap Bitmap Bitmap … Bitmap Bitmap Bitmap … HBase coprocessor. Bitmap Container Dynamic Tag Loader Bitmap Container Dynamic Tag Loader Each TagZone is an independent Service Threads Query Cache Service Threads Query Cache bitmap computing unit. All the real-time writes and logs DTag Changes Checkpoint Base Delta are stored in HBase. DynamicTag PostingList Bitmap Latest Data View Use bitmap checkpoint for fast HBase HDFS recovery during service initialization. DynamicTag TagSource PostingList StaticTag Checkpoint Checkpoint TagHostGroup ChangeLog 18
19 . Data Model TagSource: Meta data storage for static tags, includes Tags Meta data storage TagSource configurations per tag. 1 TagHostGroup: Uses TagHostID as key, and store all the M tags as columns. TagHost to Tags TagHostGroup TagZone: Inverted index from Tag to TagHost list. 1 Bitmap related data is also stored in this table. Partitions 1 are decided during table creation, and can not split in Inverted index of Tag to TagHosts TagHostGroup_TAGZONE future. TagHostID TID (Any Type) (Integer) Each table is an independent HBase table. 19
20 .Query Query grammar in BNF: Query ::= ( Clause )+ Clause ::= ["AND", "OR", "NOT"] ([TagName:]TagValue| "(" Query ")" ) A Query is a series of Clauses. Each Clause can also be a nested query. Supports AND/OR/NOT operators. AND indicates this clause is required, NOT indicates this clause is prohibited, OR indicates this clause should appear in the matching results. The default operator is OR is none operator specified. Parentheses “(” “)” can be used to improve the priority of a sub-query. 20
21 .Query Example Normal Query: GENDER:Male AND MARRIAGE:Married AND AGE:25-30 AND BLOOD_TYPE:A Use parentheses “(” “)” to improve the priority of sub-query: GENDER:Male AND MARRIAGE:Married AND (AGE:25-30 OR AGE:30-35) AND BLOOD_TYPE:A Minimum Number Should Match Query: At least 2 of below 4 groups of conditions should be satisfied: (A1 B1 C1 D1 E1 F1 G1 H1) (A2 B2 C2 D2 E2 F2 G2 H2) (A3 B3 C3 D3 E3 F3 G3 H3) (A4 B4 C4 D4 E4 F4 G4 H4) Complex query with static and dynamic tags: GENDER:Male AND MARRIAGE:Married AND AGE:25-30 AND CAROWNER AND $D:DTag1 AND $D:DTag2 21
22 .Evaluation Bitmap in-memory and on-disk size: Bitmap Cardinality In-memory Bytes On-Disk Size Bytes 5,000,000 15426632 10387402 10,000,000 29042504 20370176 50,000,000 140155632 99812920 100,000,000 226915200 198083304 NOTE: 1. Bitmap cardinality is the number of bit 1 from the bitmap in binary form. 2. The positions with bit 1 are random integers between 0 and Integer.Max. 3. The distribution of bit 1(In Bitmap binary form) and the range may affect the bitmap size. Test results on small cluster: 3 Huawei 2288 Servers(256GB Memory, Intel(R) Xeon(R) CPU E5-2618L v3 @2.30GHZ*2 SATA,4TB*14) 1.5 Billion TagHosts, ~60 static Tags per TagHost. Query with 10 random tags(Hundreds of thousands satisfied results), count and only return first screen results. Average query latency: 60ms。 22
23 .Future Work For Tagram 1. Multiple TagZone Replica. 2. Async Tagram/HBase Client. 3. Better Bitmap Memory Management. 4. Integration with Graph/Full-Text index. 23
24 .Agenda CTBase: A light weight HBase client for structured data Tagram: Distributed Bitmap index implementation with HBase CloudTable service(HBase on Huawei Cloud) 24
25 .CloudTable Service Features Easy Maintenance Security High Performance SLA High Availability Low Cost 25
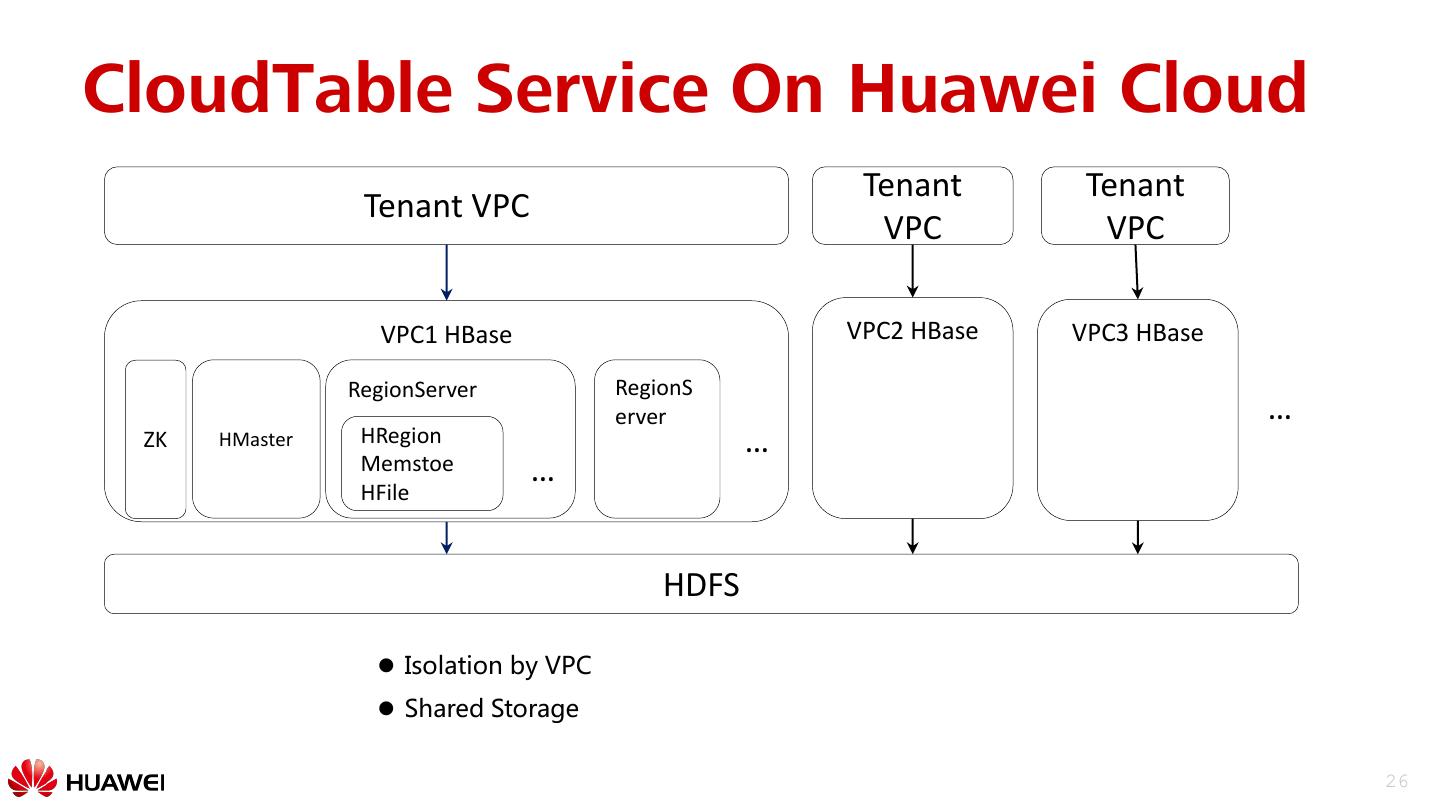
26 .CloudTable Service On Huawei Cloud Tenant Tenant Tenant VPC VPC VPC VPC1 HBase VPC2 HBase VPC3 HBase RegionServer RegionS erver … ZK HMaster HRegion … Memstoe … HFile HDFS Isolation by VPC Shared Storage 26
27 .CloudTable – IO Optimization HBase HBase HBase HBase HBase HBase HDFS HDFS Interface Distribute Pool(Append only) FileSystem FileSystem FileSystem Block Block Block Disk Disk Disk Disk Device Device Device CloudTable IO Stack Disk Disk Disk • A low-latency IO stack • Deep Optimization With hardware Native HBase IO Stack 27
28 . CloudTable – Offload Compaction Region Server Region Server Region RegionCompaction Region Region Read Write Offload compaction CMD:compaction HDFS Data Node Read Compaction HDFS Data Node Write HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile HFile 25000 20000 15000 TPS normal 10000 5000 offload 0 1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49 52 55 58 61 64 67 70 73 76 79 82 85 88 91 94 97 100 103 106 109 112 115 118 121 124 127 130 Smooth Performance 28
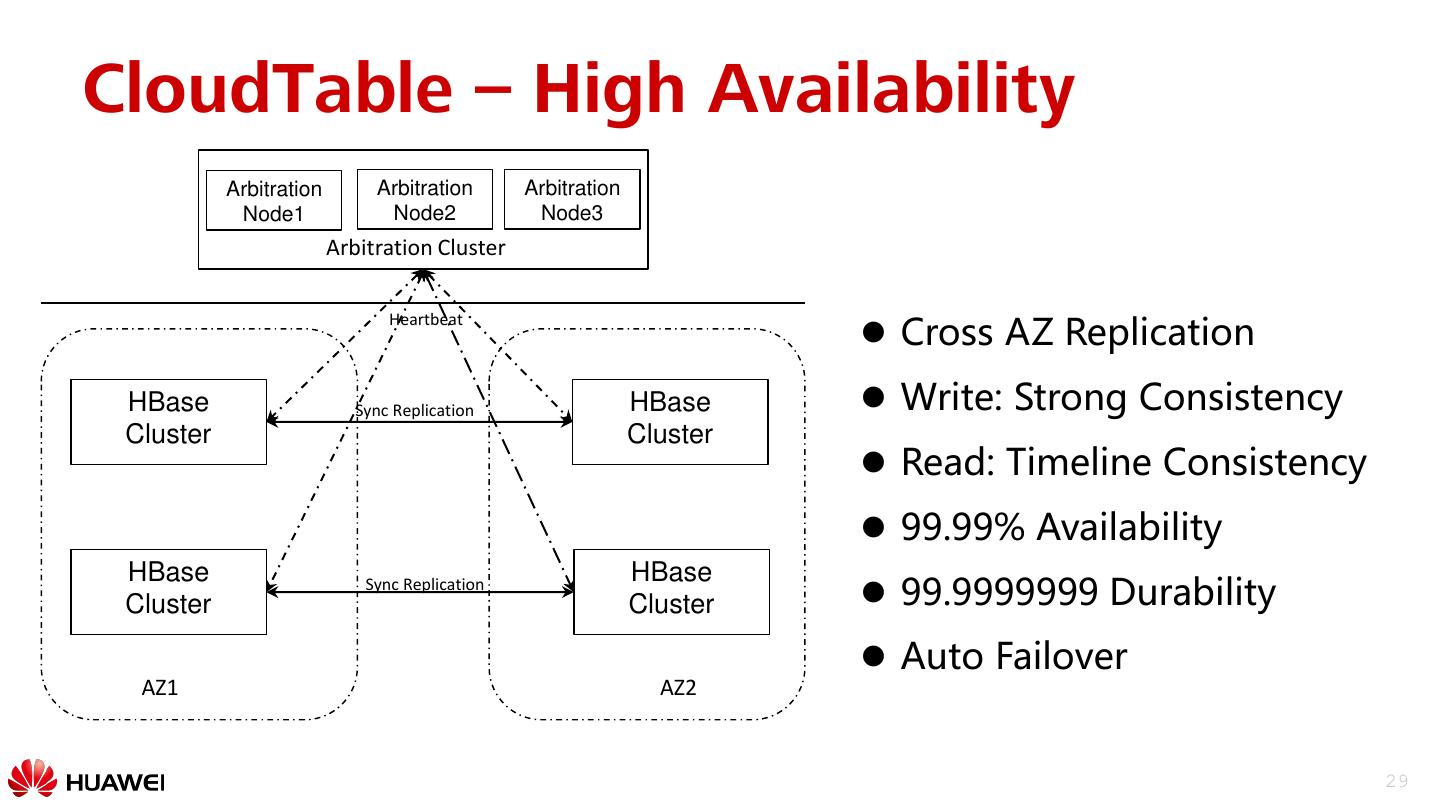
29 .CloudTable – High Availability Arbitration Arbitration Arbitration Node1 Node2 Node3 Arbitration Cluster Cross AZ Replication Heartbeat HBase Sync Replication HBase Write: Strong Consistency Cluster Cluster Read: Timeline Consistency 99.99% Availability HBase HBase Cluster Sync Replication Cluster 99.9999999 Durability Auto Failover AZ1 AZ2 29
3秒后跳转登录页面
去登陆

