
























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
HBase 高可用HA
HBase 高可用HA
展开查看详情
1 .Highly Available HBase Micah Wylde @mwylde HBaseCon ‘17
2 .What is Sift Science Sift Science protects online businesses from fraud using real-time machine learning. We work with hundreds of customers across a range of verticals, countries, and fraud types.
3 . What is Sift Science? Customer bob added backend credit card Web Page Title http://domain.com Google bob loaded cart page fraud score bob sift 27 Carrier 12:00 PM bob opened app
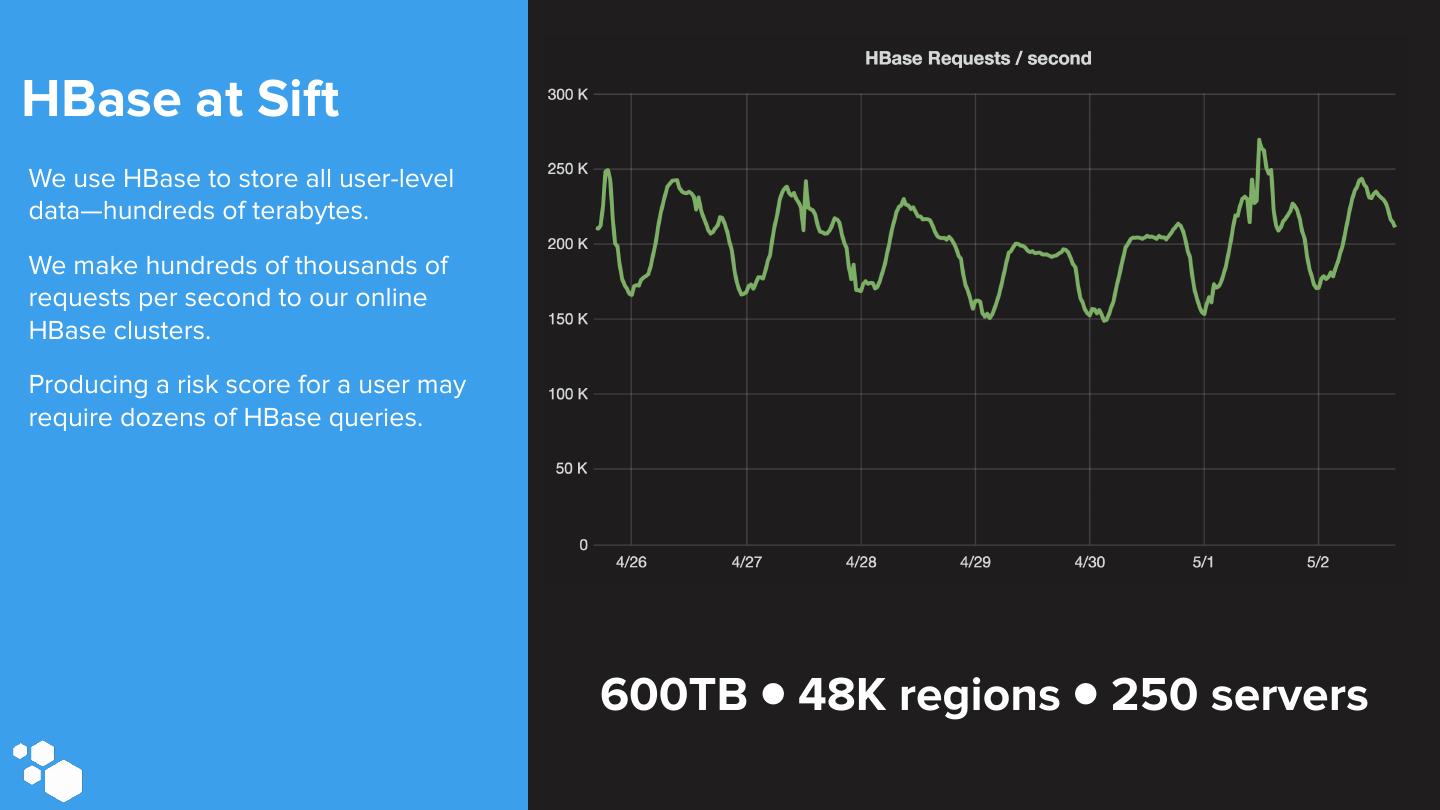
4 .HBase at Sift We use HBase to store all user-level data—hundreds of terabytes. We make hundreds of thousands of requests per second to our online HBase clusters. Producing a risk score for a user may require dozens of HBase queries. 600TB ● 48K regions ● 250 servers
5 . Why HBase • Scalable to millions of requests per second and petabytes of data • Strictly consistent writes and reads • Supports write-heavy workloads • Highly available …in theory
6 . When we’re down, our customers can’t make money
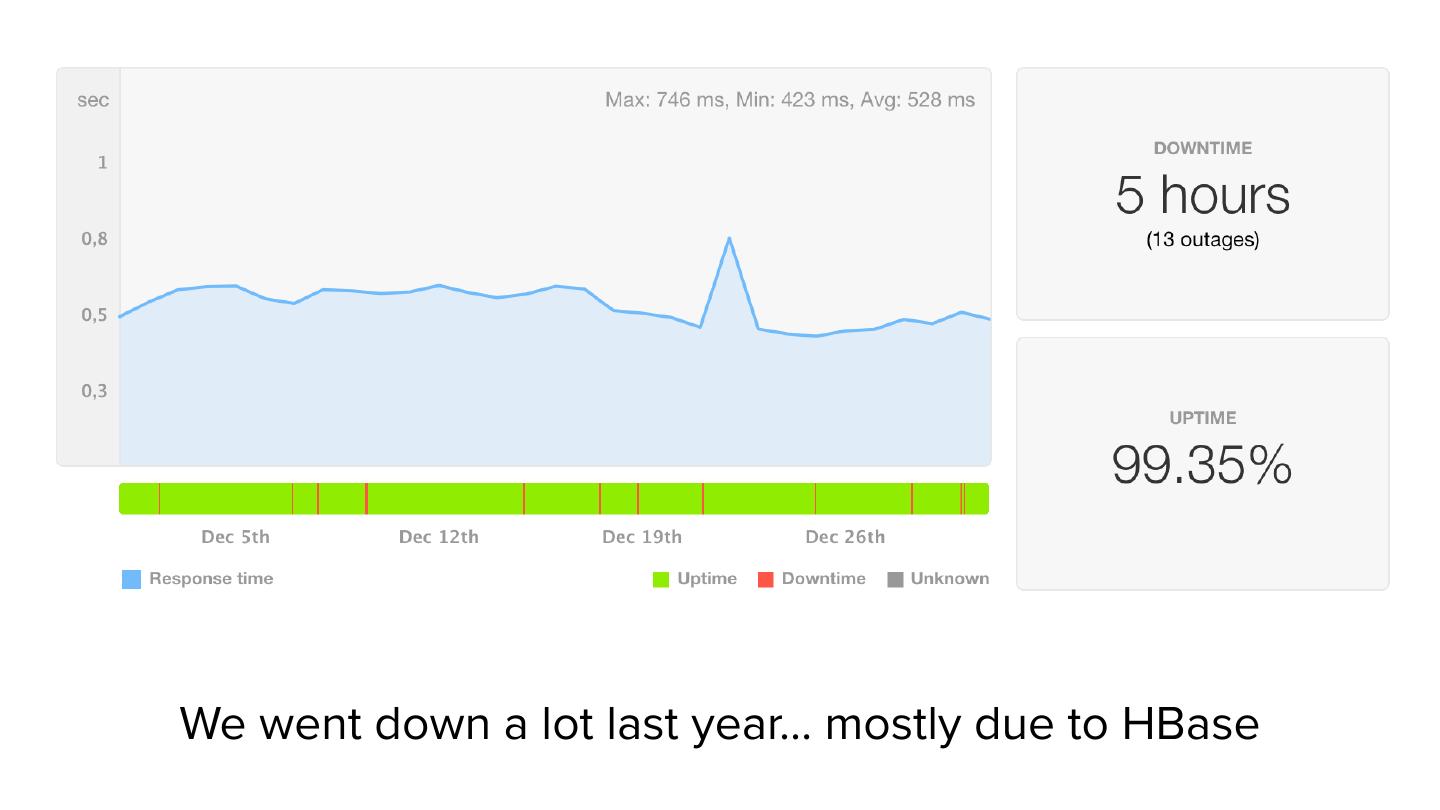
7 .We went down a lot last year… mostly due to HBase
8 .Since then we’ve mostly eliminated HBase downtime
9 .How?
10 .Step 0: Prioritize reliability (this means deferring new features)
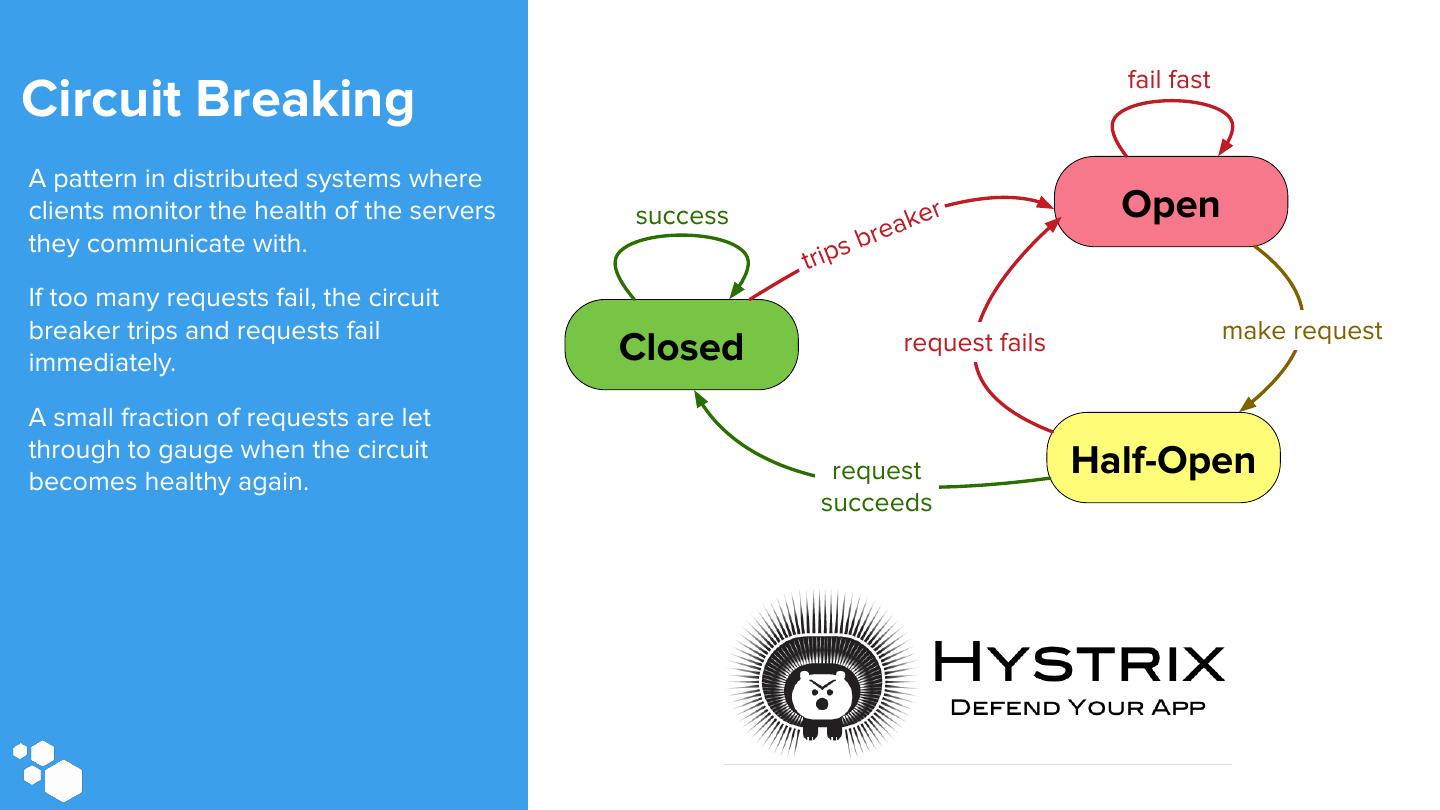
11 .Circuit Breaking
12 . Symptom: When a single region server became unavailable or slow, our application would stop doing work.
13 . Replicating the issue with Chaos Engineering • Killing processes • Killing servers • Partitioning the network • Throttling network on HBase port
14 . Replicating the issue with Chaos Engineering $ tc qdisc add dev eth0 handle ffff: ingress $ tc filter add dev eth0 parent ffff: protocol ip prio 50 u32 match ip protocol 6 0xff match ip dport 60020 0xffff police rate 50kbit burst 10k drop flowid :1 Sets the bandwidth available for HBase to 50 kb/s (don’t try this on your production cluster)
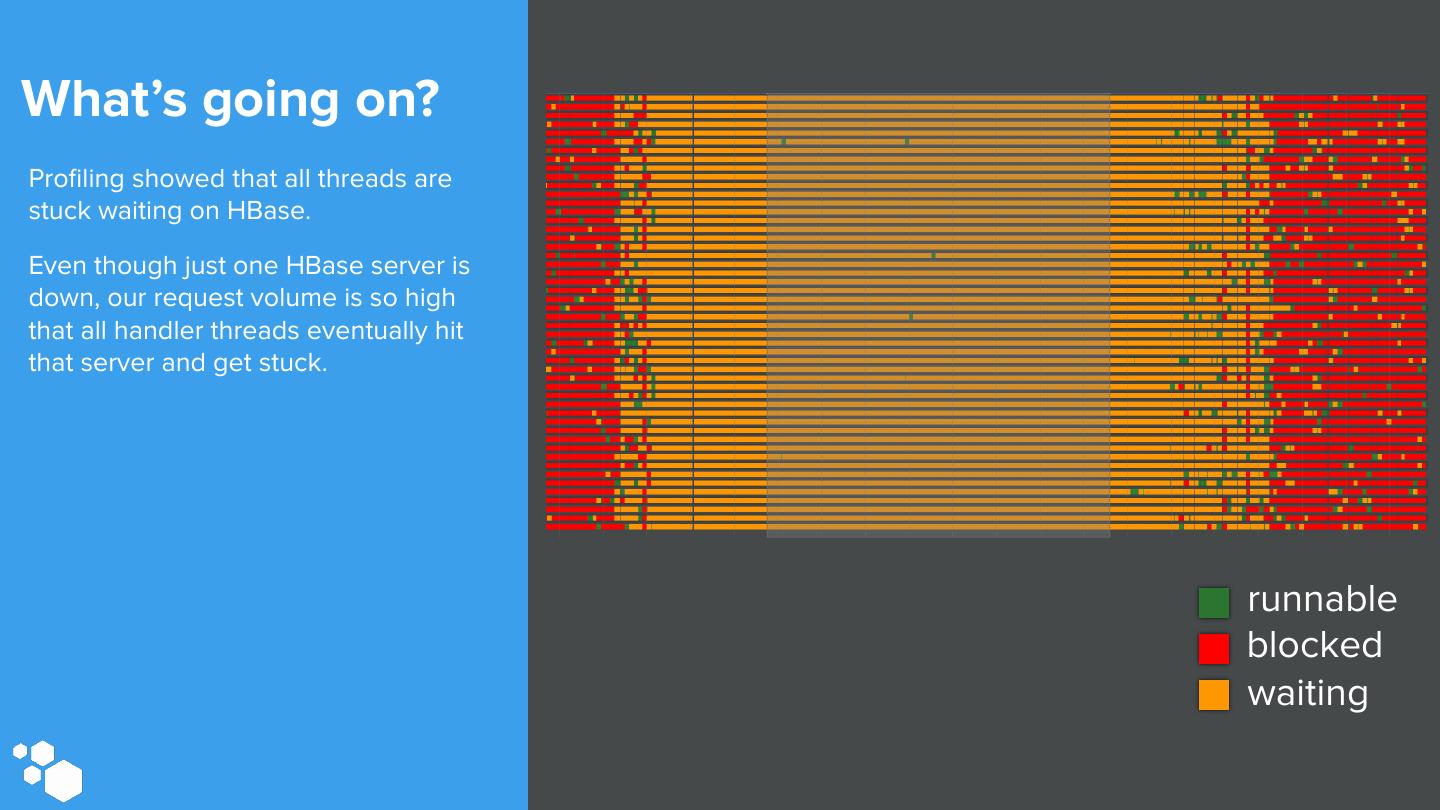
15 .What’s going on? Profiling showed that all threads are stuck waiting on HBase. Even though just one HBase server is down, our request volume is so high that all handler threads eventually hit that server and get stuck. runnable blocked waiting
16 . fail fast Circuit Breaking A pattern in distributed systems where clients monitor the health of the servers success a ke r Open they communicate with. br e i p s tr If too many requests fail, the circuit breaker trips and requests fail make request immediately. Closed request fails A small fraction of requests are let through to gauge when the circuit becomes healthy again. request Half-Open succeeds
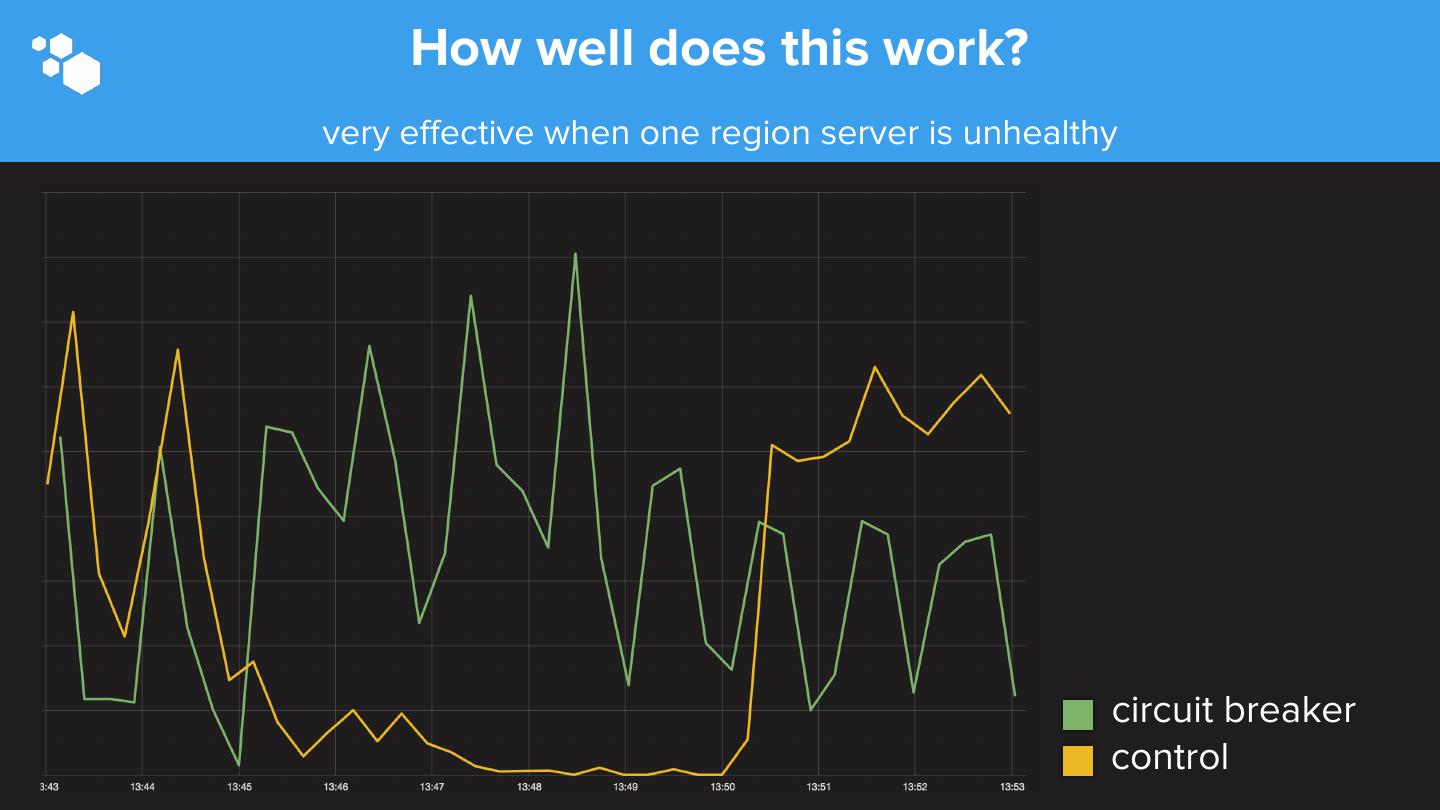
17 . How well does this work? very effective when one region server is unhealthy circuit breaker control
18 . Circuit Breaking in hbase-client Subclass RpcRetryingCaller / DelegatingRetryingCallable private static class HystrixRegionServerCallable<R> extends DelegatingRetryingCallable<R, RegionServerCallable<R>> { @Override public void prepare(boolean reload) throws IOException { delegate.prepare(reload); if (delegate instanceof MultiServerCallable) { server = ((MultiServerCallable) delegate).getServerName(); } else { HRegionLocation location = delegate.getLocation(); server = location.getServerName(); } setter = HystrixCommand.Setter .withGroupKey(HystrixCommandGroupKey.Factory.asKey(REGIONSERVER_KEY)) .andCommandKey(HystrixCommandKey.Factory.asKey( server.getHostAndPort())); } }
19 . Circuit Breaking in hbase-client Subclass RpcRetryingCaller / DelegatingRetryingCallable private static class HystrixRegionServerCallable<R> extends DelegatingRetryingCallable<R, RegionServerCallable<R>> { @Override public R call(final int timeout) throws Exception { if (setter != null) { try { return new HystrixCommand<R>(setter) { @Override public R run() throws Exception { return delegate.call(timeout); } }.execute(); } catch (HystrixRuntimeException e) { log.debug("Failed", e); if (e.getFailureType() == HystrixRuntimeException.FailureType.SHORTCIRCUIT) { throw new DoNotRetryRegionException(e.getMessage()); } else if (e.getCause() instanceof Exception) { throw (Exception) e.getCause(); } throw e; } } else { return delegate.call(timeout);
20 . Circuit Breaking in hbase-client Subclass RpcRetryingCaller public static class HystrixRpcCaller<T> extends RpcRetryingCaller<T> { @Override public synchronized T callWithRetries(RetryingCallable<T> callable, int callTimeout) throws IOException, RuntimeException { return super.callWithRetries(wrap(callable), callTimeout); } @Override public T callWithoutRetries(RetryingCallable<T> callable, int callTimeout) throws IOException { return super.callWithoutRetries(wrap(callable), callTimeout); } private RetryingCallable<T> wrap(RetryingCallable<T> callable) { if (callable instanceof RegionServerCallable) { return new HystrixRegionServerCallable<>( (RegionServerCallable<T>) callable, maxConcurrentReqs, timeout); } return callable; } }
21 . Circuit Breaking in hbase-client Subclass RpcRetryingCallerFactory public class HystrixRpcCallerFactory extends RpcRetryingCallerFactory { public HystrixRpcCallerFactory(Configuration conf) { super(conf); } @Override public <T> RpcRetryingCaller<T> newCaller() { return new HystrixRpcCaller<>(conf); } } // override the caller factory in HBase config conf.set(RpcRetryingCallerFactory.CUSTOM_CALLER_CONF_KEY, HystrixRpcCallerFactory.class.getCanonicalName());
22 .Replication
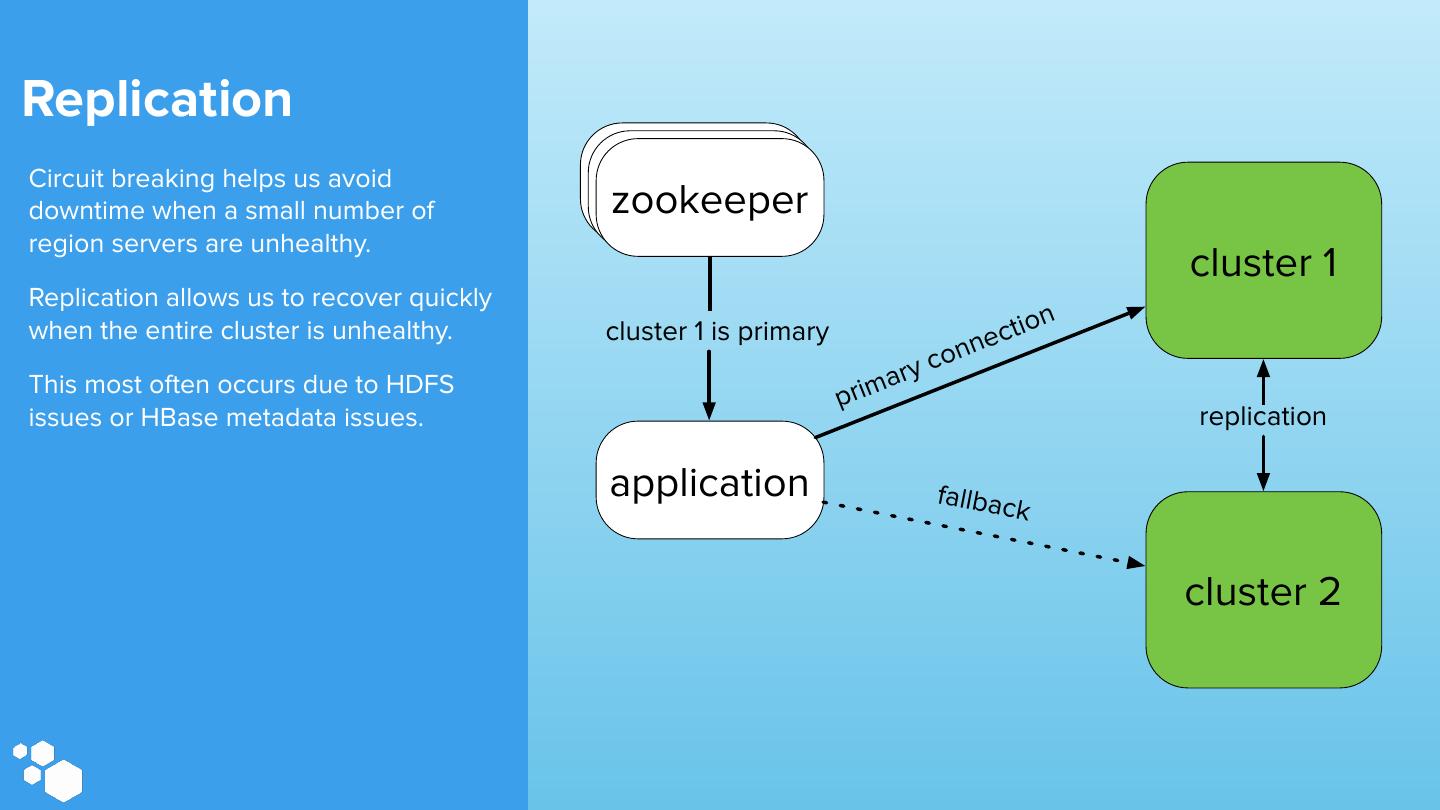
23 .Replication Circuit breaking helps us avoid zookeeper zookeeper zookeeper downtime when a small number of region servers are unhealthy. cluster 1 Replication allows us to recover quickly i o n when the entire cluster is unhealthy. cluster 1 is primary n ect co n This most often occurs due to HDFS ary prim issues or HBase metadata issues. replication application fallbac k cluster 2
24 .Replication We keep active connections to all zookeeper zookeeper zookeeper clusters to enable fast switching. A zookeeper-backed connection provider is responsible for handing out cluster 1 connections to the current cluster. cluster 2 is primary k a c If we see a high error rate from a fallb cluster, we can quickly switch to the other while we investigate and fix. replication This also allows us to do a full cluster application primar y conn without downtime, speeding up our ection ability to roll out new configurations and HBase code. cluster 2
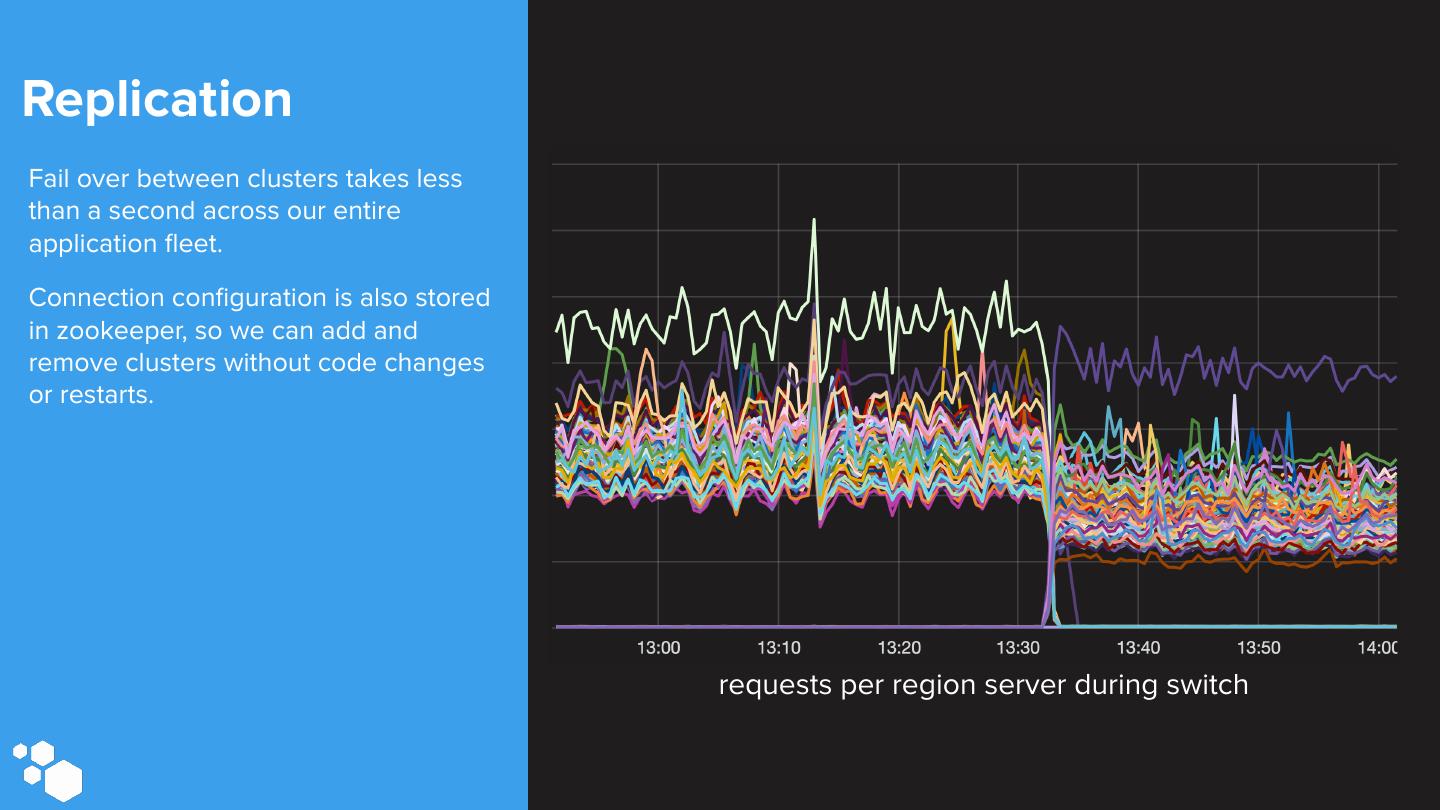
25 .Replication Fail over between clusters takes less than a second across our entire application fleet. Connection configuration is also stored in zookeeper, so we can add and remove clusters without code changes or restarts. requests per region server during switch
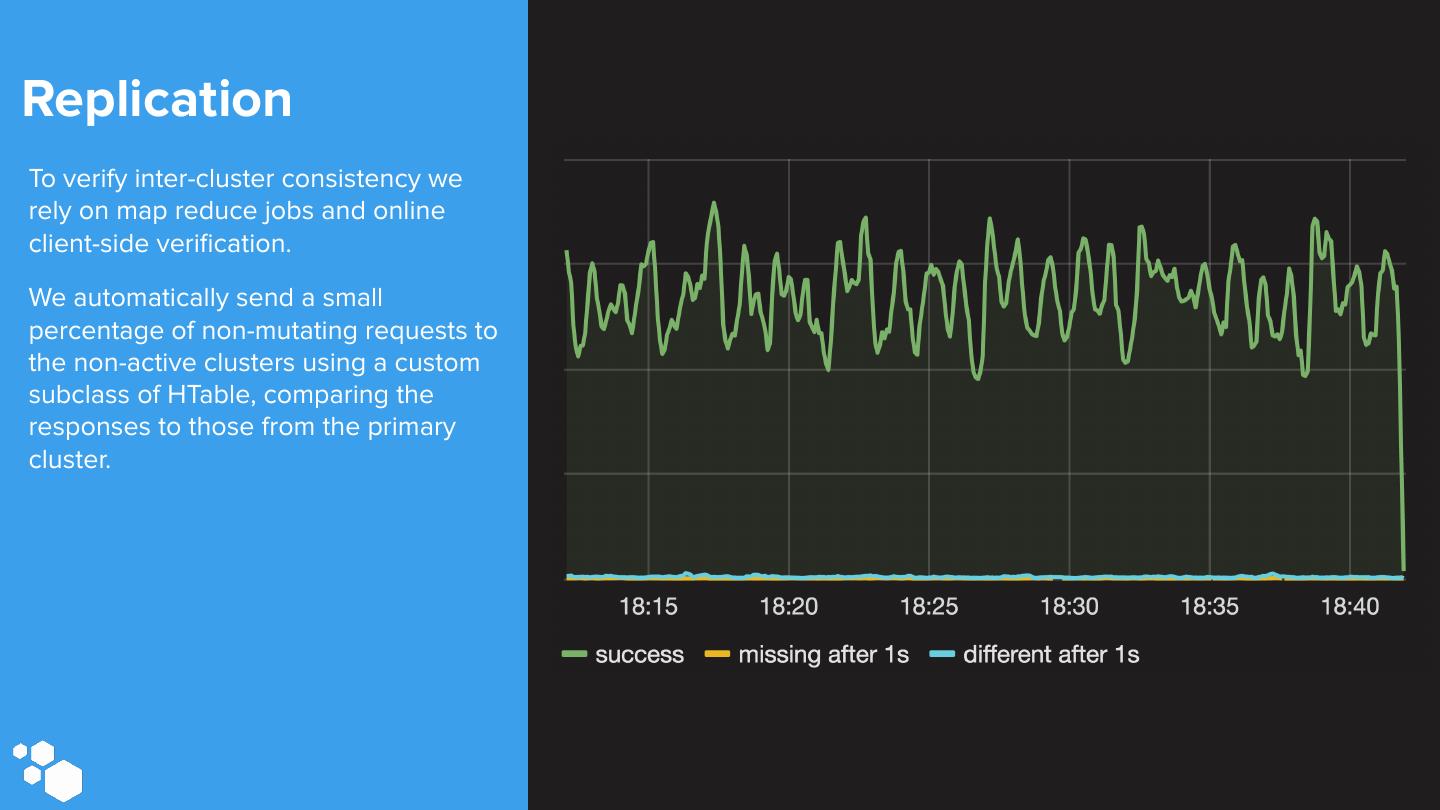
26 .Replication To verify inter-cluster consistency we rely on map reduce jobs and online client-side verification. We automatically send a small percentage of non-mutating requests to the non-active clusters using a custom subclass of HTable, comparing the responses to those from the primary cluster.
27 .Monitoring
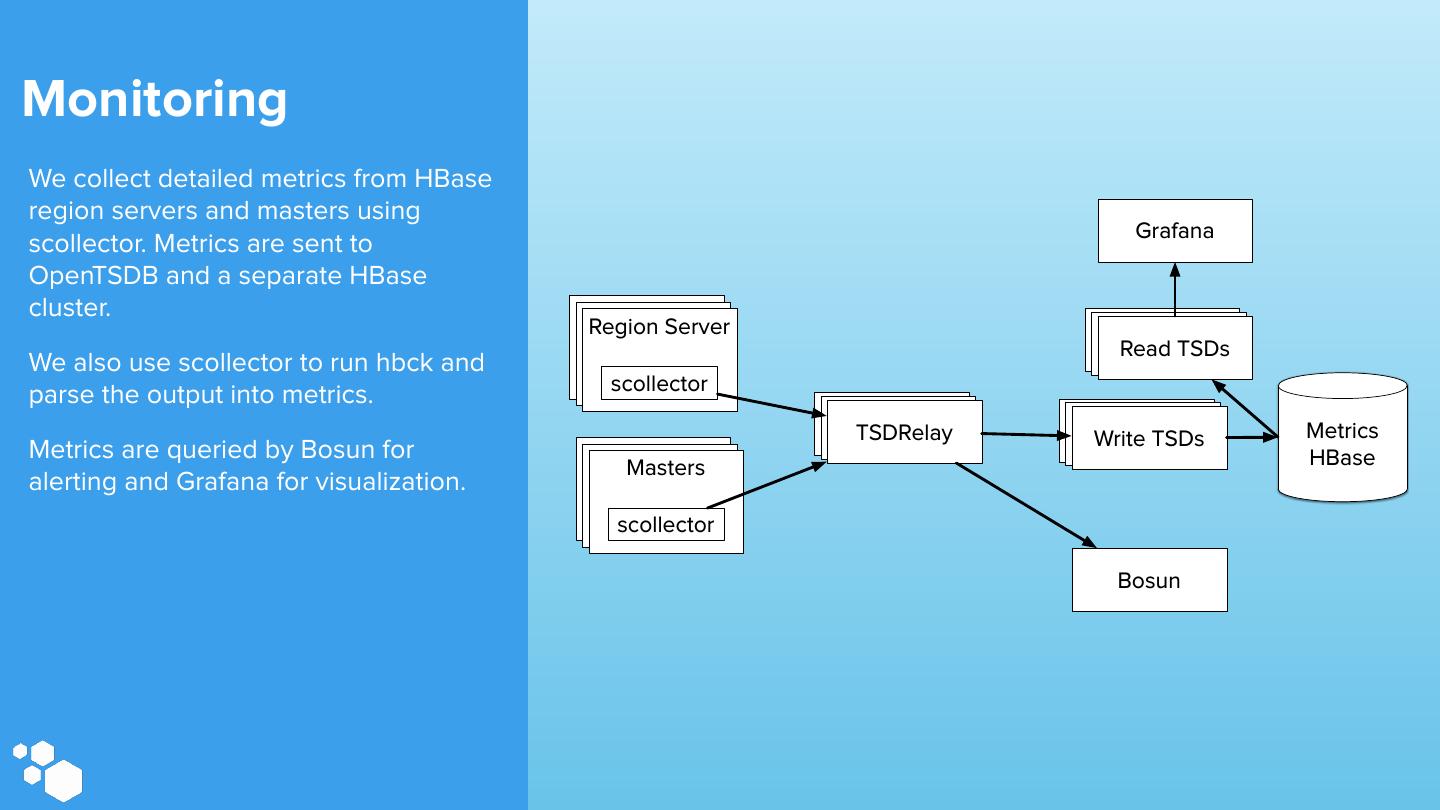
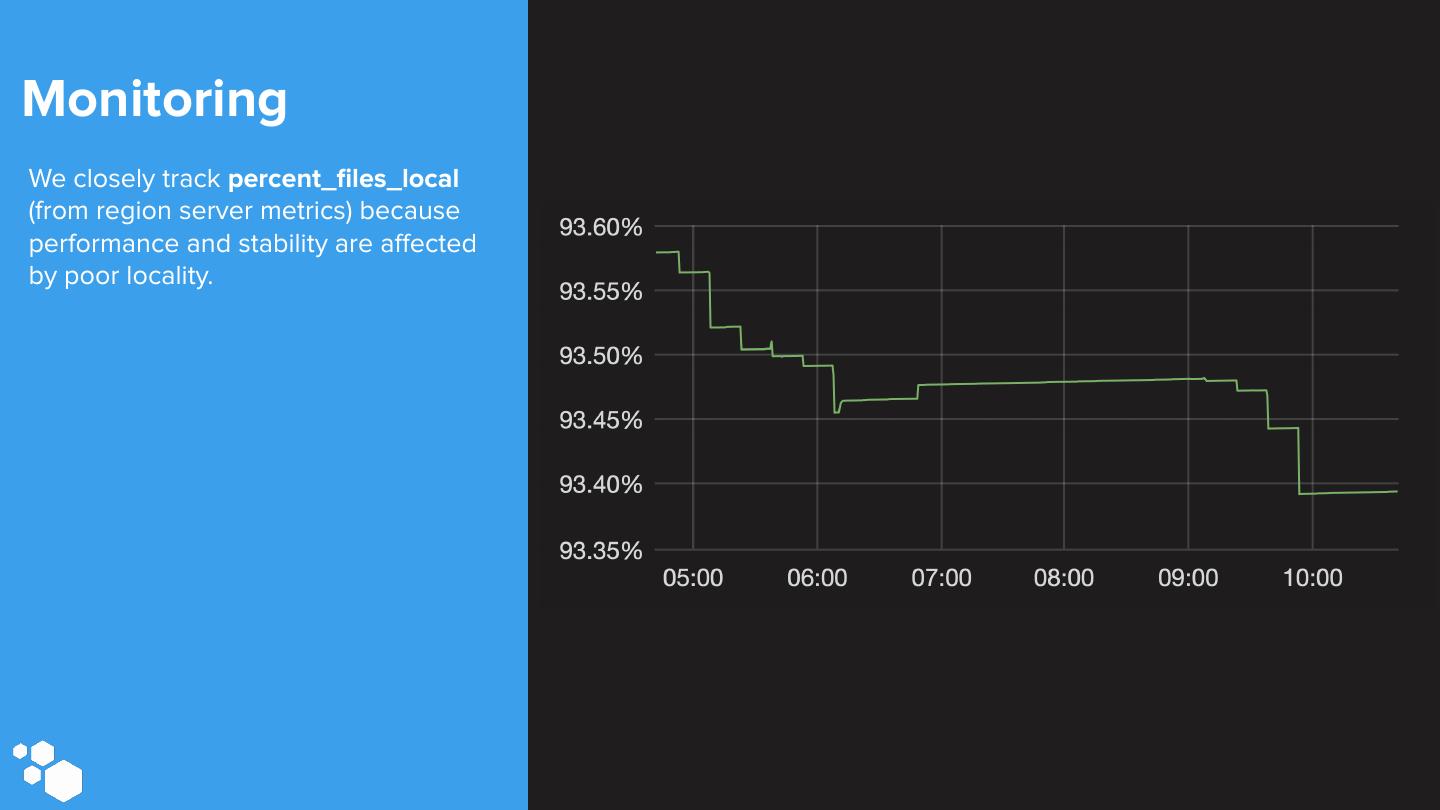
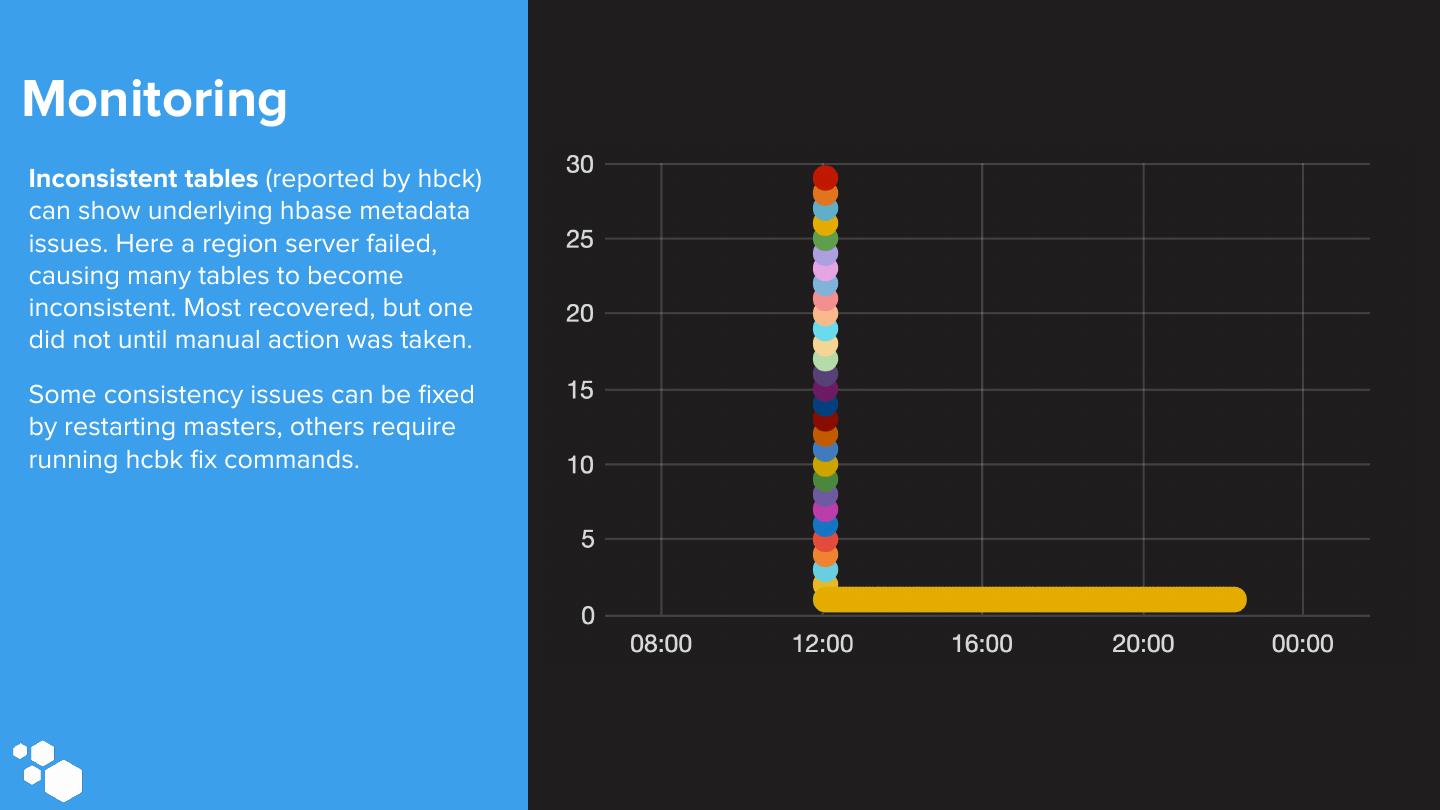
28 .Monitoring We collect detailed metrics from HBase region servers and masters using Grafana scollector. Metrics are sent to OpenTSDB and a separate HBase cluster. Region Region Server RegionServer Server TSDRelay TSDRelay Read TSDs We also use scollector to run hbck and scollector parse the output into metrics. TSDRelay TSDRelay TSDRelay TSDRelay TSDRelay Write TSDs Metrics Metrics are queried by Bosun for Region Region Server Server HBase Masters alerting and Grafana for visualization. scollector Bosun
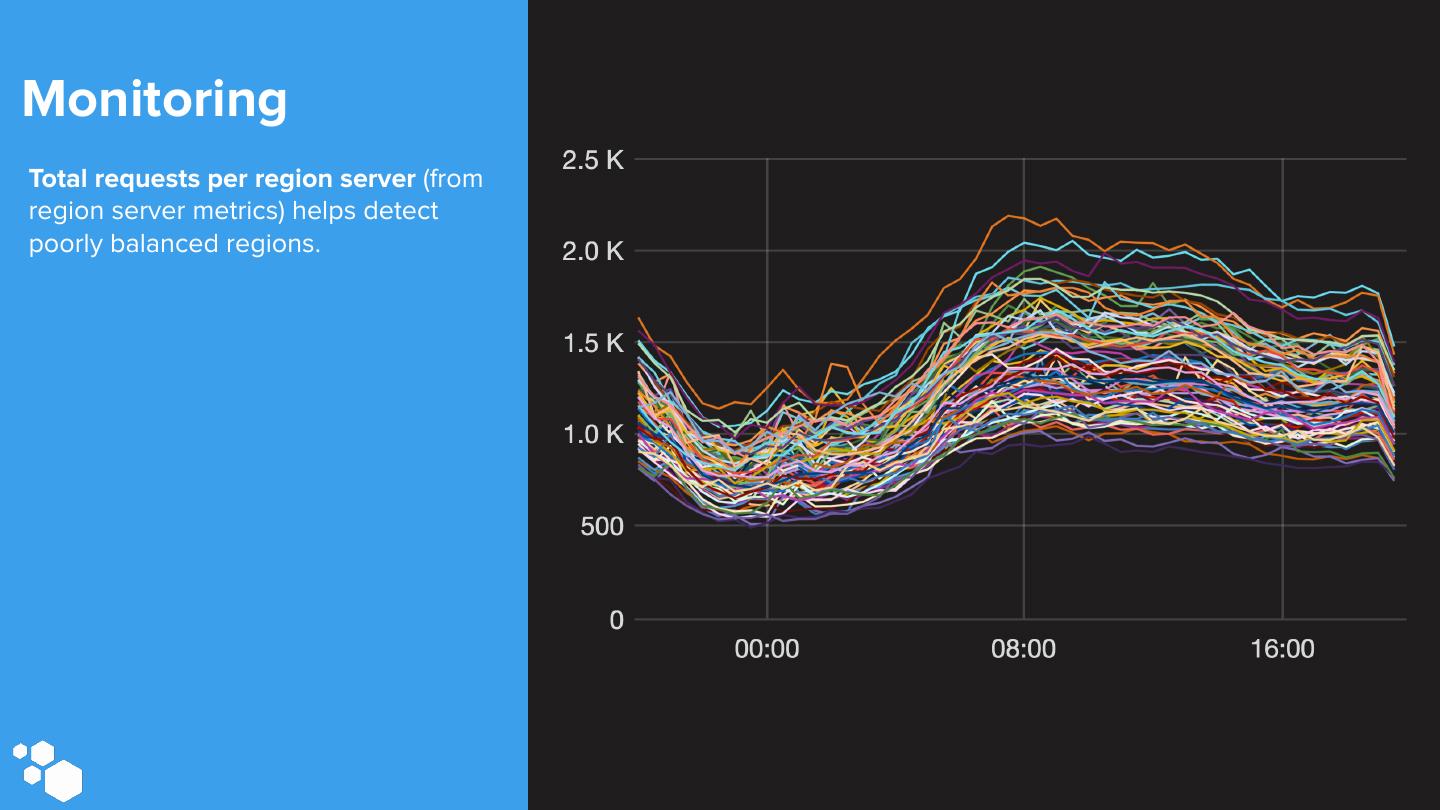
29 .Monitoring Total requests per region server (from region server metrics) helps detect poorly balanced regions.
3秒后跳转登录页面
去登陆

