


























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
HBase多模数据库的机遇与挑战_V4
HBase多模数据库的机遇与挑战_V4
展开查看详情
1 .开发者专场 HBase多模的机遇与挑战 Opportunities and challenges of HBase Multi-Model DB 阿里云数据库团队 HBase多模式与分析负责人、高级技术专家 封神
2 .• 业务挑战带来的架构演进 • ApsaraDB For HBase多模式数据库 • ApsaraDB For HBase核心场景
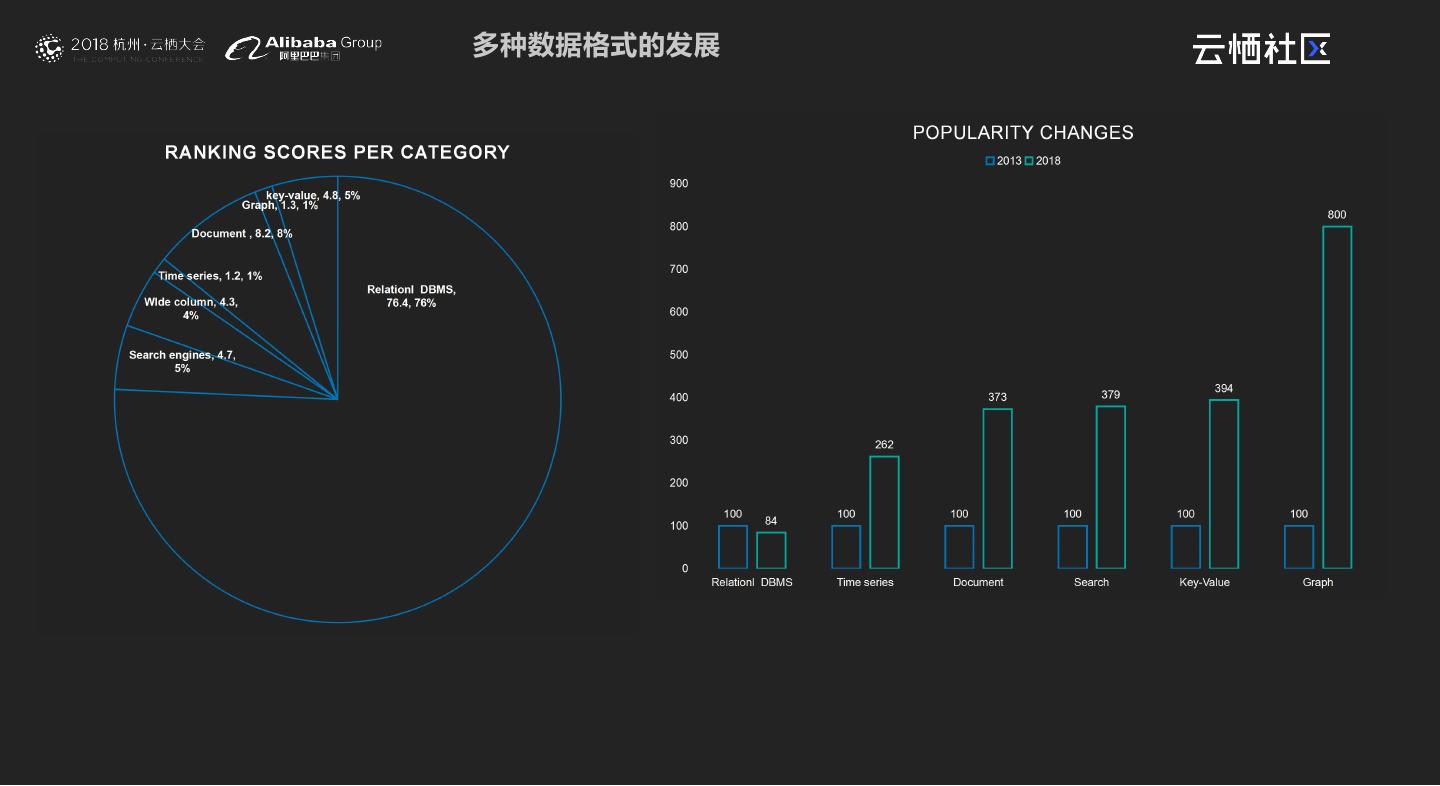
3 . 多种数据格式 K V Key Value Time Series Doucument Geospatial Relational Graph
4 .多种数据格式的发展
5 . 数据库的发展趋势 Multi Model HBase 分布式SQL Phoenix 第四代 分库分表 第三代 多模式 解决多种数据模型问题 MySQL NewSQL 第二代 解决自适应分区 第一代 分库分表 解决 数据量的问题 丰 富 模 型 单机关系型 解决 基本存取的问题 能 、 加 智 更
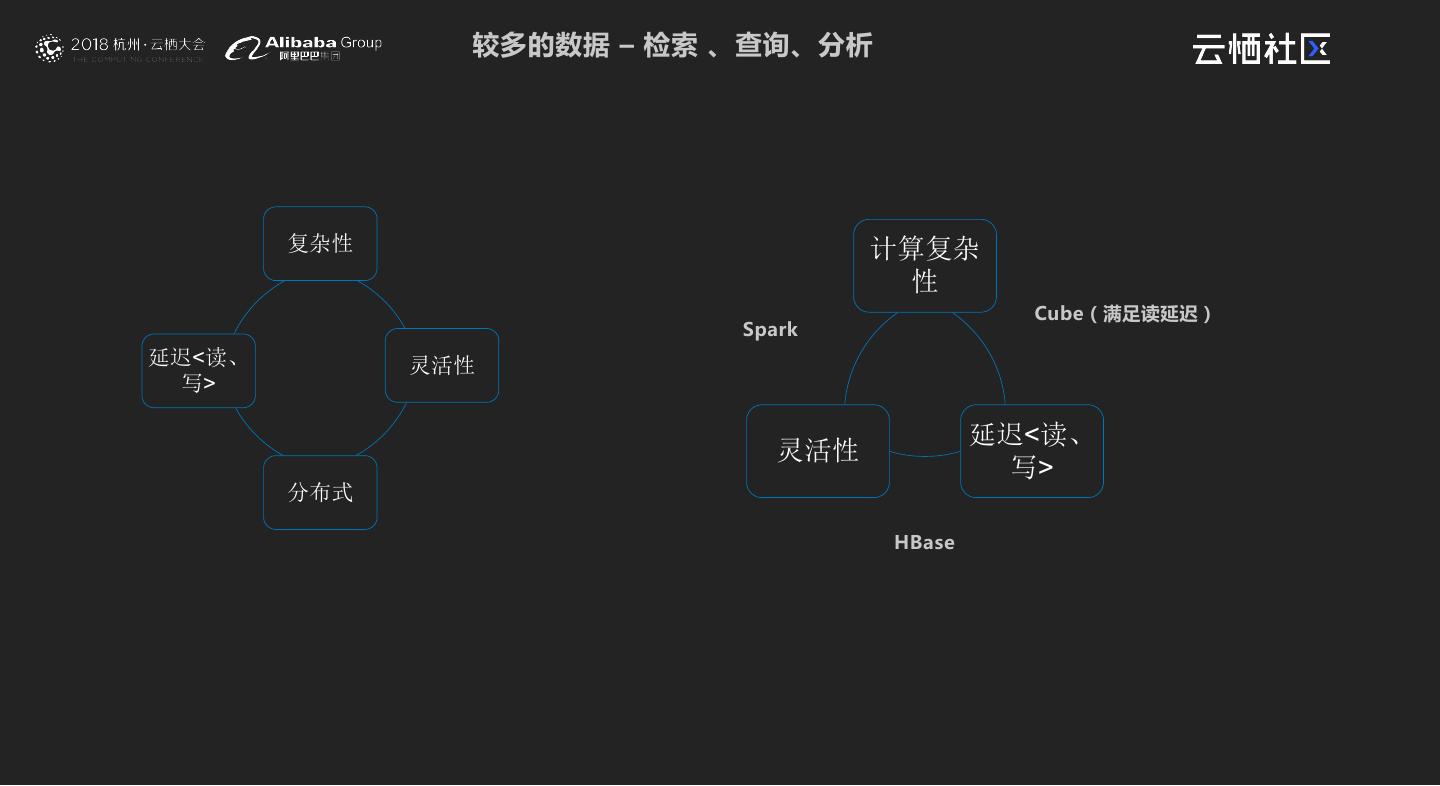
6 . 较多的数据 – 检索 、查询、分析 复杂性 计算复杂 性 Cube(满足读延迟) Spark 延迟<读、 灵活性 写> 延迟<读、 灵活性 写> 分布式 HBase
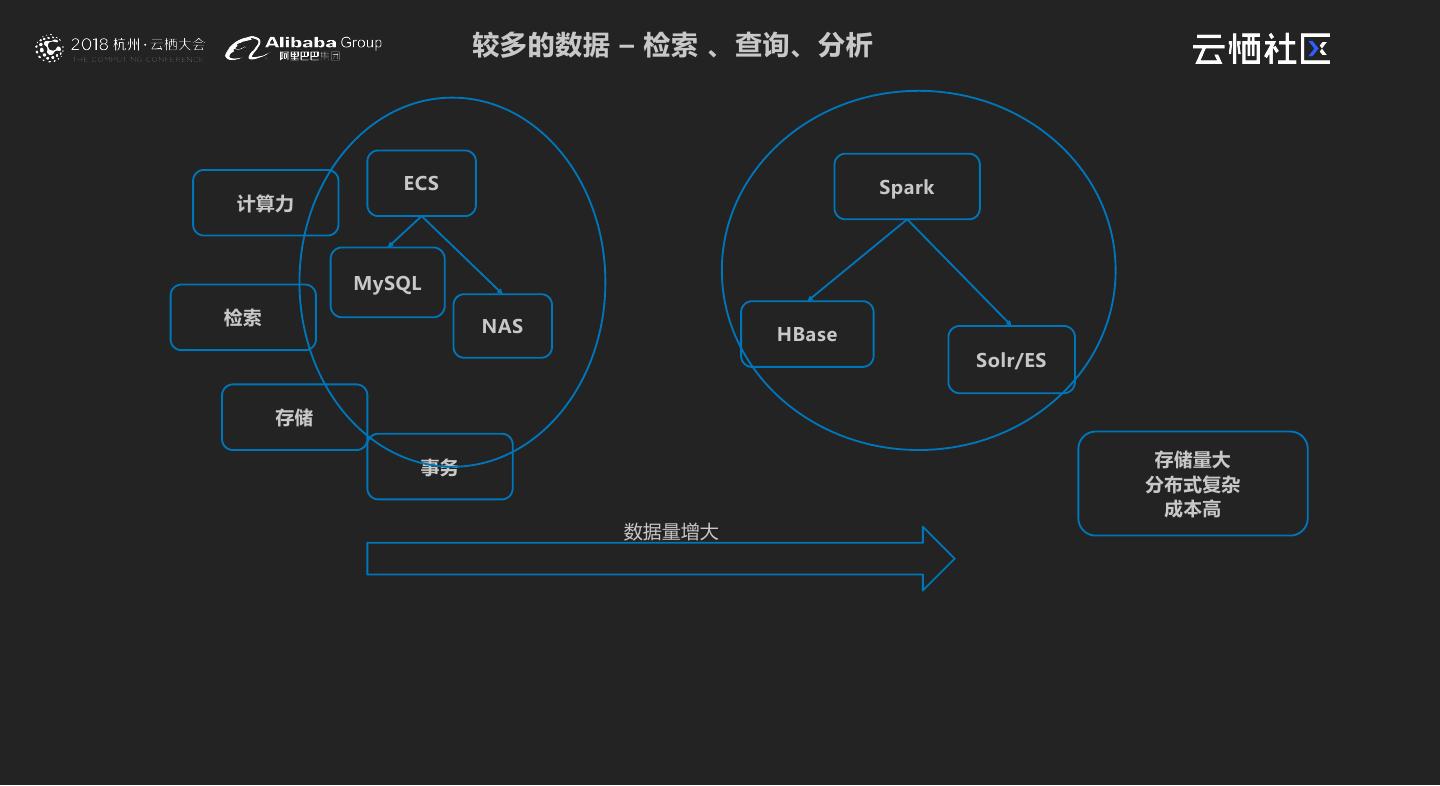
7 . 较多的数据 – 检索 、查询、分析 ECS Spark 计算力 MySQL 检索 NAS HBase Solr/ES 存储 事务 存储量大 分布式复杂 成本高 数据量增大
8 .ApsaraDB For HBase架构及改进
9 . 什么是 ApsaraDB For HBase Beyond Apache HBase Multi-Model Mixed Workloads KV Table 安全 SQL Spark 延迟 Graph On MTTR Geo xxx 性能 TimeSeries FullText-index
10 . 什么是 Apache HBase 毫秒级 读写延迟 亿级 QPS 10:1 压缩比 百万列 18年 2.0发布 稀疏表 万亿行 数据驱动业务 单表存储 PB级别 15年 1.0发布 单表存储 为互联网 、 物联网 而生 08年 Apache顶级项目 06年发起
11 . 什么是 Apache For HBase Hadoop Database,是一个基于Google LSM BigTable论文设计的高可靠性、高性能、 Tree 可伸缩的分布式存储系统。 松散表结构(Schema free) 自动 存储计算 分区 分离 原生 海量数据分布式存储 随机查询、范围查询 高吞吐,低延迟 Hadoop 生态 在线分布式数据库 多版本,增量导入,多维删除
12 . 核心使用场景 阿里巴巴集团 部署1.2W台 Lo g 公有云超过500+集群
13 . HBase生态组件 K V HBase API OpenTSDB Key Value Time Series Phoenix HGraphDB Relational Graph HBase API GeoMesa Doucument Geospatial
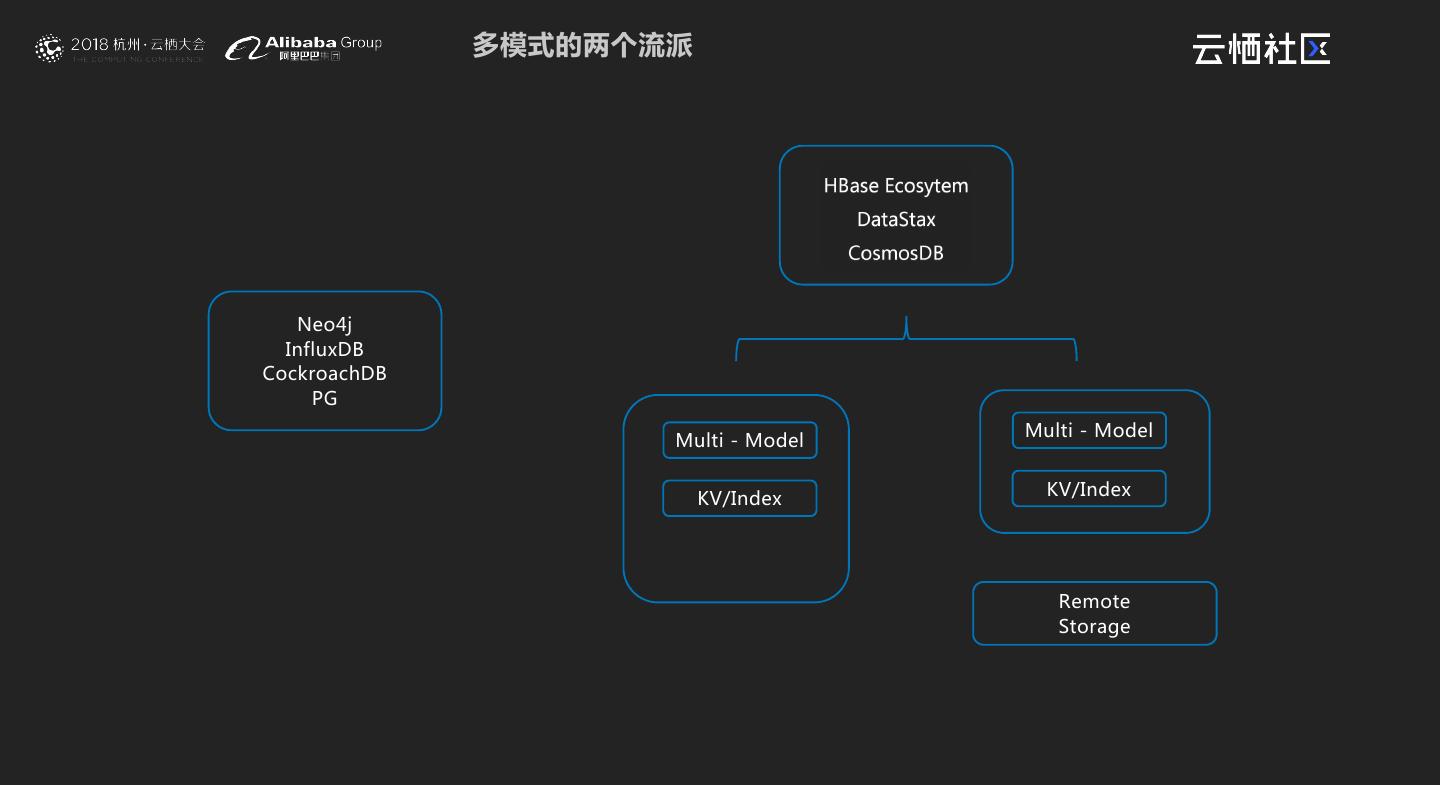
14 . 多模式的两个流派 Neo4j InfluxDB CockroachDB PG Multi - Model Multi - Model KV/Index KV/Index Remote Storage
15 . Cloud-Native好处 Cloud Native New Hardware Flexibility Cost Savings (TCO) End up paying for RDMA Fast Add/Remove features Flash Resource Flexibility GPU Insight self-driven Non-volatile memory Fix bugs in time Reduce human Self-driven ……
16 . 多模式的两个流派 Neo4j InfluxDB CockroachDB PG Multi - Model Multi - Model u d l o KV/Index c KV/Index Remote Storage
17 . ApsaraDB HBase Platform – Cloud Native SQL Graph Time Series Geospatial Phoenix HGraphDB OpenTSDB GeoMesa HBase Solr/ES (KV、Tabular 、Doucument) (Full Text Index) Spark Remote Read/Write use RDMA and 25G network Cold data on HDD Hot data on SSD and use EC like OSS
18 . ApsaraDB For HBase Platform优势 Item ApsaraDB For HBase (Aliyun Product) Apache HBase (Software) High availability 99.9% ~ 99.99% N/A Basic Data reliability 99.999999999% N/A Multi-master clustering Multi-master clustering,Multi-AZ/Regon NO Online Ability GC FGC NO,YGC 5ms GC 20s~100s,YGC 100ms+ Storage Cost Cut by 50%+ on share cloud disk,Total 3 Copy Maybe on Cloud Disk,Total 9 Copy Reduce Cost Support Cold Storage Support OSS,Cut by 70% at less read NO KV,Tabular,SQL,Graph,Time Series,Geospatial Multi-model DB Multi-model DB KV,Tabular Full Text index, Search Disaster recovery Backup and Restore NO,maybe3.0 Security user/password,ACL Kerberos,ACL Enterprise Characteristics Analytics Spark on HBase ,More optimization Spark on HBase Version upgrade Automatic upgrade N/A Database 15min Create a DB/Monitor N/A control system Online add storage and node/Elastic Power in future Self-driven Diagnostic System Big request ,Big Table merge,Hot Region …… NO
19 .ApsaraDB For HBase核心场景
20 .数据类型 存储对象 代表场景 组件 优势 简单kv信息 KV/表格存储 稀疏表 风控 画像表等稀疏表 HBase API 动态列 SQL语法 SQL 带类型的 替换单机关系数据库 HBase - Phoenix 具备Hbase 所有的优势 文档数据 json/xml/html 新闻 HBase API 存储空间大 性能与存储空间 对象数据 图片/视频等 小对象存储 HBase 兼备 HBase 时序数据 传感器数据 监控数据 HBase - OpenTSDB 写性能高、存储量大 HBase 时空数据 轨迹 轨迹、时空数据 HBase - GeoMesa 写性能高、存储量大 图关系数据 关系 欺诈场景 Hbase - HGraphDB 分布式图 计算前置 OLAP cube 报表 Kylin或自己构建 实时查询
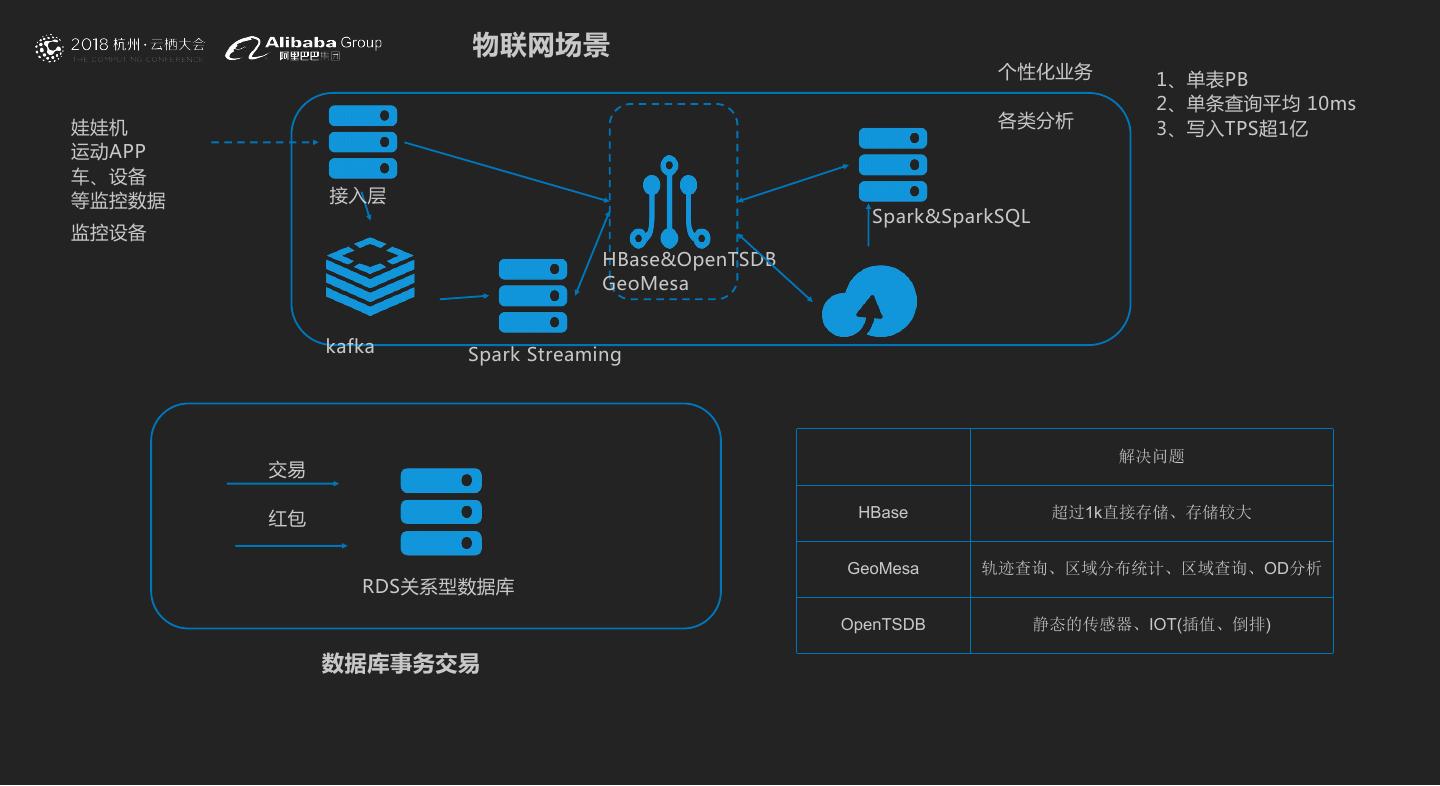
21 . 物联网场景 个性化业务 1、单表PB 2、单条查询平均 10ms 娃娃机 各类分析 3、写入TPS超1亿 运动APP 车、设备 等监控数据 接入层 Spark&SparkSQL 监控设备 HBase&OpenTSDB GeoMesa kafka Spark Streaming 解决问题 交易 红包 HBase 超过1k直接存储、存储较大 GeoMesa 轨迹查询、区域分布统计、区域查询、OD分析 RDS关系型数据库 OpenTSDB 静态的传感器、IOT(插值、倒排) 数据库事务交易
22 . 用户标签 – 稀疏表 C1 …… C10000000 列/行 Value Value Value Value 用户画像、标签 Value …… Value Value 动态列,可以数万列 Value 稀疏表,不存数据,不占空间 Value Value Value Value 1万亿行 Value
23 . 实时小对象存储 场景:读取每个组的全量数据 1、其中 90% 左右的组 含有1 ~ 10张人脸 元数据 与 存储 统一管理!! 3、其余组 人脸数范围为 10 ~ 20000张脸左右 业务 性能提升500倍!! 业务 4、其中每张脸 2k 左右 宽表存储 - 一次性读取一行 2、查询小对象 1、查询元数据 OSS MySQL HBase 10000个脸时,读性能10s 性能提升 500+倍 当一个组10000个脸 的性能 20ms
24 . 历史记录查询 查询系统 电商交易 红包 水电单 索引查询条件说 查询示例 平均查询时间 Solr查询时 明 (ms) 间 精确查询 qd_s:QD030000545472 91 34 模糊查询 sj_s:SJ0600004*613 303 228 范围查询 rq_i:[100000 TO 200000] 252 180 精确查询 rq_i:2571198 AND yd_s:YD040000657960 86 73 模糊查询 xm_s:EEE?MP*FFFFF AND sj_s:SJ0800007*123 358 342 AND 组合 范围查询 rq_i:[8000 TO 82000] AND zt_s:ZT0000000004 343 259 HBase Solr 组合查询 ys_s:YS0000000004 AND xm_s:LLL*Q*MMMMM AND rq_i:[80000 TO 9000000] 611 530 精确查询 rq_i:175948 OR rq_i:175971 223 160 模糊查询 xm_s:AAA?MP*FFFFF OR xm_s:AAA*AE*FFFFF 249 239 消息队列 OR 组合 范围查询 rq_i:[175900 TO 175950] OR rq_i:[175951 TO 17600] 197 172 rq_i:175948 OR xm_s:AAA?MP*FFFFF OR xm_s:AAA*AE*FFFFF OR 组合查询 220 212 架构要点: rq_i:[175900 TO 175950] 精确查询 (rq_i:175948 OR rq_i:175971) AND yd_s:YD100000583175 76 62 1、全量数据与索引数据分开,大概30:1数据量关系 (xm_s:GGG?MP*MMMMM AND xm_s:GGG*E*MMMMM) OR 模糊查询 xm_s:GGG?QG*MMMMM 233 226 比如 原始数据30T,索引数据1T左右 AND + OR 组合 (rq_i:[8000 TO 82000] AND rq_i:[9000 TO 10000]) OR rq_i:[175951 TO 范围查询 17600] 206 198 2、Solr数据尽量缓存在内存 (xm_s:JJJ*BQ*CCCCC OR rq_i:[1320000 TO 1400000]) AND 组合查询 xm_s:JJJ*AE*CCCCC 259 252 3、HBase内置同步逻辑,保障数据不丢失 4、90%查询走HBase API,10%走solr
25 .我看人才的成长
26 . PS:人才的成长 引领-带领 7-10年 无中生有 4-6年成为专家 2-3年夯实基础
27 . PS:人才的成长 行动 自我驱动 意愿
28 . PS:人才的成长 心力 体力 脑力
29 . PS:人才的成长 关注社区 项目中成长 多写文章 坚持 请教高手 保持敬畏
3秒后跳转登录页面
去登陆

